Advancing Content: Announcing Firefox Tiles Going Live |
With the 10th anniversary update to Firefox, there was an important update to the new tab experience, promoting Tiles to the Firefox stable build, and making them available to hundreds of millions of users around the world. Today we are excited to announce our first two sponsored Tiles partners: CVS Health and their media agency Mindshare North America, and Booking.com.
What are Tiles for?
For years, the new tab page in Firefox was unique in being intentionally blank – but by 2012, we learned that we could facilitate many users’ workflow through the new tab page. We added thumbnails based on a calculation of “freceny” (frequency and recency of a user’s browsing history, essentially the same way that the Awesome bar calculates relevance). We learned that many users find these history thumbnails useful; but we were not entirely satisfied with the feature. Thumbnails might be broken, and the experience could be much more dynamic.
We need to be able to use our voice with our users, for example to raise awareness around issues that affect the future of the Internet, and to promote those causes that we believe are important to that future.
We have been exploring the content discovery space. There are many aspects of digital advertising that concern us: from the overall integrity of the advertising system on the Web, to the user having control over what happens to their data, and then to what happens to the data once the user has given their consent. I have been writing for a while on this blog about the principles we follow and the ideas we have to improve digital advertising.
Lastly, we wanted to explore ways to contribute to the sustainability of the project in a way that we felt could align with Mozilla’s values.
Tiles are our first iteration on starting to solve these problems. They create a more useful, attractive and dynamic new tab page. Tiles also represent an important part of our efforts to create new communications, content and advertising experiences over which Firefox users maintain control.
Partnering with Mozilla
We’re very excited to have partnered with CVS Health (and Mindshare/GroupM) in the United States and Booking.com globally as our first two Firefox sponsored Tiles partners. We are live in 8 languages and 25 different countries*, and will continue to iterate with Mindshare/GroupM and Booking.com, as well as with our community, as we continue to improve on the experience.
We have been delighted to work with Mindshare/GroupM and Booking.com. When we collaborate, we need to understand the vision and objectives of the partner, and to understand if that partner is able to work within the framework of Mozilla’s principles. Running sponsored content in Tiles is results-based, not surveillance-based. We do not allow tracking beacons or code in Tiles. We are not collecting, or providing you with, the data about our audience that most digital ad networks do. There are certain categories that require screening, or have other sensitivities, that we will stay away from, such as alcohol and pharmaceuticals.
The user’s experience

For users with no browsing history (typically a new installation), they will see Directory Tiles offering an updated, interactive design and suggesting useful sites. A separate feature, Enhanced Tiles, will improve upon the existing new tab page experience for users who already have a history in their browser.
Tiles provides Mozilla (including our local communities) new ways to interact with and communicate with our users. (If you’ve been using a pre-release Firefox build, you might have seen promotions for Citizenfour, a documentary about Edward Snowden and the NSA, appearing in your new tab in the past few weeks.)
Tiles also offers Mozilla new partnership opportunities with advertisers and publishers all while respecting and protecting our users. These sponsorships serve several important goals simultaneously by balancing the benefits to users of improved experience, control and choice, with sustainability for Mozilla.
What users currently see in the New:Tab page on Firefox desktop will continue to evolve, just like any digital product would. And it will evolve along the lines I discussed earlier here. Above all, we need to earn and maintain users’ trust.
Looking ahead
User control and transparency are embedded in all of our design and architecture, and principles that we seek to deliver our users throughout their online life: trust is something that you earn every day. The Tiles-related user data we collect is anonymized after we receive it – as it is for other parts of Firefox that we instrument to ensure a good experience. And of course, a user can simply switch the new tab page Tiles feature off. One thing I must note: users of ad blocking add-ons such as Ad Block Plus will see adverts by default and will need to switch Tiles off in Firefox if they wish to see no ads in their New Tab page. You can read more about how we design for trust here.
With the testing we’ve done, we’re satisfied that users will find this an experience that they understand and trust – but we will always have that as a development objective. You can expect us to iterate frequently, but we will never assume trust – we will always work to earn it. And if we do have and maintain that trust, we can create potentially the best digital advertising medium on the planet.
We believe that we can do this, and offer a better way to deliver and to receive adverts that users find useful and relevant. And we also believe that this is a great opportunity for advertisers who share our vision, and who wish to reach their audience in a way that respects them and their trust. If that’s you, we want to hear from you. Feel free to reach out to contentservices@mozilla.com.
And a big thank you to our initial launch partners, CVS Health, Booking.com, and Citizenfour who see our vision and are supporting Mozilla to have greater impact in the world.
* that list in full:
Argentina, Australia, Austria, Belarus, Belgium, Brazil, Canada, Chile, Colombia, Ecuador, France, Germany, Hong Kong, Japan, Kazakhstan, Mexico, New Zealand, Peru, Russia, Saudi Arabia, Spain, Switzerland, United Kingdom, United States and Venezuela.
https://blog.mozilla.org/advancingcontent/2014/11/13/announcing-firefox-tiles-going-live/
|
|
Robert O'Callahan: Relax, Scaling User Interfaces By Non-Integer Scale Factors Is Okay |
About seven years ago we implemented "full zoom" in Firefox 3. An old blog post gives some technical background to the architectural changes enabling that feature. When we first implemented it, I expected non-integer scale factors would never work as well as scaling by integer multiples. Apple apparently thinks the same, since (I have been told) on Mac and iOS, application rendering is always to a buffer whose size is an integer multiple of the "logical window size". GNOME developers apparently also agree since their org.gnome.desktop.interface scaling-factor setting only accepts integers. Note that here I'm conflating user-initiated "full zoom" with application-initiated "high-DPI rendering"; technically, they're the same problem.
Several years of experience shows I was wrong, at least for the Web. Non-integer scale factors work just as well as integer scale factors. For implementation reasons we restrict scale factors to 60/N for positive integers N, but in practice this gives you a good range of useful values. There are some subtleties to implementing scaling well, some of which are Web/CSS specific.
For example, normally we snap absolute scaled logical coordinates to screen pixels at rendering time, to ensure rounding error does not accumulate; if the distance between two logical points is N logical units, then the distance between the rendered points stays within one screen pixel of the ideal distance S*N (where S is the scale factor). The downside is that a visual distance of N logical units may be rendered in some places as ceil(S*N) screen pixels and elsewhere as floor(S*N) pixels. Such inconsistency usually doesn't matter much but for CSS borders (and usually not other CSS drawing!), such inconsistent widths are jarring. So for CSS borders (and only CSS borders!) we round each border width to screen pixels at layout time, ensuring borders with the same logical width always get the same screen pixel width.
I'm willing to declare victory in this area. Bug reports about unsatisfactory scaling of Web page layouts are very rare and aren't specific to non-integral scale factors. Image scaling remains hard; the performance vs quality tradeoffs are difficult --- but integral scale factors are no easier to handle than non-integral.
It may be that non-Web contexts are somehow more inimical to non-integral scaling, though I can't think why that would be.
http://robert.ocallahan.org/2014/11/relax-scaling-user-interfaces-by-non.html
|
|
Mic Berman: An exercise for creating space, saying ‘no’ and redefining your next chapter: The Mason Jar Exercise for Spaciousness, Choice and Resonance |
How much space do you have in your life? How much of it is filled with obligations you’ve accepted for others? What percentage do you give to yourself for pursuits that are just for you? Could you stand to make a little more space in your life just for you? Could less commitments mean more quality time to focus on your Vision for your life?
I asked myself these questions recently and discovered that my life was almost entirely filled with obligations, guilt and hardly any room to pursue my own passions, or time to rejuvenate. One of my core values is to be of service to people - I love being helpful, creating value, offering support and transformation as a coach. Because of this, I felt obligated to serve my clients whenever they needed, whether it cut in to personal commitments or not . I would feel guilty if I wasn’t able to be available for them. It became that I was always putting everyone else first, and I was way at the bottom of the list —or sometimes I never made it on to the list at all.
When I noticed how busyness had taken over, I devised what I call “the Mason Jar Exercise”. I needed to create space and reconnect with Vision and Purpose and, have time to contemplate what’s next so that I can choose actions that support my next big chapter.
Many of the folks I coach have similar challenges. They feel overwhelmed, have no time for themselves and feel so busy in their lives they’ve lost their way, lost their deep connection to their vision and purpose.Do you find that any of what I’m talking about applies to you?? Can you check in with how your life is resonating with you, how much you feel in tune with your values in all of your pursuits, supporting roles and actions?
If you find, like so many of us, you could use more space and time in your life, try out the Mason Jar exercise for yourself. Here’s how:
The Mason Jar Exercise for Spaciousness, Choice and Resonance
1. Take a Mason Jar and fill it with gravel (or any other small rocks) in proportion to how full you feel your life is out of integrity with your values. It’s a great way to visualize the things taking up space in your life, I was at about 85%.
2. Fill the remaining space with some of your favourite things e.g. momentoes, shells, etc.
3. As you stare at this now full, or even over full jar, contemplate what you want for your life and write out your ‘stake’—the mantra or statement that propels you forward in integrity. For me it was “with laughter and steadfast focus I open the door to my new way”.
4. Each day choose a stone to ‘throw back into nature’. In my case, I would declare my stake, open my front door and toss it into our forest. Then you must challenge yourself in the day to let go of or get rid of an obligation or choice you’ve made that’s out of line with your values until the jar is empty save for your few favourite things. For example, ‘Today I am ridding myself of the obligation to ___ and this is making room for me to embrace ___". Now you can begin a study of the space, the singular beauty and significance of the items that remain. Notice what you want more of and where the draw is to fill it back up again.
This was a powerful and transformative exercise for me. It took me about a month to complete. I noticed how full my life was in activity and distraction and that I felt out of integrity with my values and that I wasn’t making resonant choices. The result was a beautiful appreciation for my life and a deep acknowledgement of how I want to live. Less has become more. Stillness has expanded my perspectives. Now I feel like I can take on my next mountain.
What are you noticing?
|
|
Roberto A. Vitillo: Recommending Firefox add-ons with Spark |
We are currently evaluating possible replacements for our Telemetry map-reduce infrastructure. As our current data munging machinery isn’t distributed, analyzing days worth of data can be quite a pain. Also, many algorithms can’t easily be expressed with a simple map/reduce interface.
So I decided to give Spark another try. “Another” because I have played with it in the past but I didn’t feel it was mature enough to be run in production. And I wasn’t the only one to think that apparently. I feel like things have changed though with the latest 1.1 release and I want to share my joy with you.
What is Spark?
In a nutshell, “Spark is a fast and general-purpose cluster computing system. It provides high-level APIs in Java, Scala and Python, and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools including Spark SQL for SQL and structured data processing, MLlib for machine learning, GraphX for graph processing, and Spark Streaming.”
Spark primary abstraction is the Resilient Distributed Dataset (RDD), which one can imagine as a distributed pandas or R data frame. The RDD API comes with all kinds of distributed operations, among which also our dear map and reduce. Many RDD operations accept user-defined Scala or Python functions as input which allow average Joe to write distributed applications like a pro.
A RDD can also be converted to a local Scala/Python data structure, assuming the dataset is small enough to fit in memory. The idea is that once you chopped the data you are not interested in, what you are left with fits comfortably on a single machine. Oh and did I mention that you can issue Spark queries directly from a Scala REPL? That’s great for performing exploratory data analyses.
The greatest strength of Spark though is the ability to cache RDDs in memory. This allows you to run iterative algorithms up to 100x faster than using the typical Hadoop based map-reduce framework! It has to be remarked though that this feature is purely optional. Spark works flawlessly without caching, albeit slower. In fact in a recent benchmark Spark was able to sort 1PB of data 3X faster using 10X fewer machines than Hadoop, without using the in-memory cache.
Setup
A Spark cluster can run in standalone mode or on top of YARN or Mesos. To the very least for a cluster you will need some sort of distributed filesystem, e.g. HDFS or NFS. But the easiest way to play with it though is to run Spark locally, i.e. on OSX:
brew install spark spark-shell --master "local[]"
The above commands start a Scala shell with a local Spark context. If you are more inclined to run a real cluster, the easiest way to get you going is to launch an EMR cluster on AWS:
aws emr create-cluster --name SparkCluster --ami-version 3.3 --instance-type m3.xlarge \ --instance-count 5 --ec2-attributes KeyName=vitillo --applications Name=Hive \ --bootstrap-actions Path=s3://support.elasticmapreduce/spark/install-spark
Then, once connected to the master node, launch Spark on YARN:
yarn-client /home/hadoop/spark/bin/spark-shell --num-executors 4 --executor-cores 8 \ --executor-memory 8g —driver-memory 8g
The parameters of the executors (aka worker nodes) should obviously be tailored to the kind of instances you launched. It’s imperative to spend some time understanding and tuning the configuration options as Spark doesn’t automagically do it for you.
Now what?
Time for some real code. Since Spark makes it so easy to write distributed analyses, the bar for a Hello World application should be consequently be much higher. Let’s write then a simple, albeit functional, Recommender Engine for Firefox add-ons.
In order to do that, let’s first go over quickly the math involved. It turns out that given a matrix of the rankings of each user for each add-on, the problem of finding a good recommendation can be reduced to matrix factorization problem:

The model maps both users and add-ons to a joint latent factor space of dimensionality 
But wait, Firefox users don’t really rate add-ons. In fact the only information we have in Telemetry is binary: either a user has a certain add-on installed or he hasn’t. Let’s assume that if someone has a certain add-on installed, he probably likes that add-on. That’s not true in all cases and a more significant metric like “usage time” or similar should be used.
I am not going to delve into the details, but having binary ratings changes the underlying model slightly from the conceptual one we have just seen. The interested reader should read this paper. Mllib, a machine learning library for Spark, comes out of the box with a distributed implementation of ALS which implements the factorization.
Implementation
Now that we have an idea of the theory, let’s have a look at how the implementation looks like in practice. Let’s start by initializing Spark:
val conf = new SparkConf().setAppName("AddonRecommender")
val sc = new SparkContext(conf)
As the ALS algorithm requires tuples of (user, addon, rating), let’s munge the data into place:
val ratings = sc.textFile("s3://mreid-test-src/split/").map(raw => {
val parsedPing = parse(raw.substring(37))
(parsedPing \ "clientID", parsedPing \ "addonDetails" \ "XPI")
}).filter{
// Remove sessions with missing id or add-on list
case (JNothing, _) => false
case (_, JNothing) => false
case (_, JObject(List())) => false
case _ => true
}.map{ case (id, xpi) => {
val addonList = xpi.children.
map(addon => addon \ "name").
filter(addon => addon != JNothing && addon != JString("Default"))
(id, addonList)
}}.filter{ case (id, addonList) => {
// Remove sessions with empty add-on lists
!addonList.isEmpty
}}.flatMap{ case (id, addonList) => {
// Create add-on ratings for each user
addonList.map(addon => (id.extract[String], addon.extract[String], 1.0))
}}
Here we extract the add-on related data from our json Telemetry pings and filter out missing or invalid data. The ratings variable is a RDD and as you can see we used the distributed map, filter and flatMap operations on it. In fact it’s hard to tell apart vanilla Scala code from the distributed one.
As the current ALS implementation doesn’t accept strings for the user and add-on representations, we will have to convert them to numeric ones. A quick and dirty way of doing that is to hash the strings:
// Positive hash function
def hash(x: String) = x.hashCode & 0x7FFFFF
val hashedRatings = ratings.map{ case(u, a, r) => (hash(u), hash(a), r) }.cache
val addonIDs = ratings.map(_._2).distinct.map(addon => (hash(addon), addon)).cache
We are nearly there. To avoid overfitting, ALS uses regularization, the strength of which is determined by a parameter 
// Use cross validation to find the optimal number of latent factors
val folds = MLUtils.kFold(hashedRatings, 10, 42)
val lambdas = List(0.1, 0.2, 0.3, 0.4, 0.5)
val iterations = 10
val factors = 100 // use as many factors as computationally possible
val factorErrors = lambdas.flatMap(lambda => {
folds.map{ case(train, test) =>
val model = ALS.trainImplicit(train.map{ case(u, a, r) => Rating(u, a, r) }, factors, iterations, lambda, 1.0)
val usersAddons = test.map{ case (u, a, r) => (u, a) }
val predictions = model.predict(usersAddons).map{ case Rating(u, a, r) => ((u, a), r) }
val ratesAndPreds = test.map{ case (u, a, r) => ((u, a), r) }.join(predictions)
val rmse = sqrt(ratesAndPreds.map { case ((u, a), (r1, r2)) =>
val err = (r1 - r2)
err * err
}.mean)
(model, lambda, rmse)
}
}).groupBy(_._2)
.map{ case(k, v) => (k, v.map(_._3).reduce(_ + _) / v.length) }
Finally, it’s just a matter of training ALS on the whole dataset with the optimal 
// Train model with optimal number of factors on all available data
val model = ALS.trainImplicit(hashedRatings.map{case(u, a, r) => Rating(u, a, r)}, factors, iterations, optimalLambda._1, 1.0)
def recommend(userID: Int) = {
val predictions = model.predict(addonIDs.map(addonID => (userID, addonID._1)))
val top = predictions.top(10)(Ordering.by[Rating,Double](_.rating))
top.map(r => (addonIDs.lookup(r.product)(0), r.rating))
}
recommend(hash("UUID..."))
I omitted some details but you can find the complete source on my github repository.
To submit the packaged job to YARN run:
spark-submit --class AddonRecommender --master yarn-client --num-executors 4 \ --executor-cores 8 --executor-memory 8g addon-recommender_2.10-1.0.jar
So what?
Question is, how well does it perform? The mean squared error isn’t really telling us much so let’s take some fictional user session and see what the recommender spits out.
For user A that has only the add-on Ghostery installed, the top recommendations are, in order:
One could argue that 1 out of 10 recommendations isn’t appropriate for a security aficionado. Now it’s the turn of user B who has only the Firebug add-on installed:
There are just a couple of add-ons that don’t look that great but the rest could fit the profile of a developer. Now, considering that the recommender was trained only on a couple of days of data for Nightly, I feel like the result could easily be improved with more data and tuning, like filtering out known Antivirus, malware and bloatware.

http://robertovitillo.com/2014/11/12/using-spark-to-recommend-add-ons-for-firefox/
|
|
Kim Moir: Scaling capacity while saving cash |
 |
| Scale in the Market ©Clint Mickel, Creative Commons by-nc-sa 2.0 |
 |
| Cost per push from Oct 2012 until Oct 2014. This does not include costs for on premise equipment. It reflects our monthly AWS bill divided by the number of monthly pushes (commits). The chart reflects costs from October 2012-2014. |
http://relengofthenerds.blogspot.com/2014/11/scaling-capacity-while-saving-cash.html
|
|
Kim Moir: Mozilla pushes - October 2014 |



http://relengofthenerds.blogspot.com/2014/11/mozilla-pushes-october-2014.html
|
|
Mozilla Reps Community: New dashboard and a first VIP action item: documenting impact |
We’re very proud to announce that we have a new Reps Dashboard that lists your action items! You will be able to find most of the action items that you have in the Reps program, it will help you organize your activities and plan better your time. We’re also hoping that this will help mentors and council members manage the work load, be able to prioritize and ultimately keep the program running smoothly.
Check out the dashboard and let us know your thoughts. We know there might be some improvements to be done, so your feedback will help us figure this out.

This dashboard comes at the perfect time, we have a first mission for ALL Reps and the dashboard will allow you to do this in no time. We want to understand the impact of the Reps program in 2014 so we are asking all of you to please update ALL the post event metrics for this year. It won’t take much time and at the end you’ll help us articulate better the impact that we’re having with the Reps program. We are introducing text fields, so that you can add important links to your post events metrics. So any links to the makes created, the press articles generated, the social media impact would be of great help!

Help us understand how much reach your event had. How many people attended, how many people did you reach on social media, how many through press articles or blog posts? Let’s work together on making the impact of our work understandable. We have so much to be proud of, let’s document it!
|
|
Daniel Stenberg: Keyboard key frequency |
A while ago I wrote about my hunt for a new keyboard, and in my follow-up conversations with friends around that subject I quickly came to the conclusion I should get myself better analysis and data on how I actually use a keyboard and the individual keys on it. And if you know me, you know I like (useless) statistics.
 So, I tried out the popular and widely used Linux key-logger software ‘logkeys‘ and immediately figured out that it doesn’t really support the precision and detail level I wanted so I forked the project and modified the code to work the way I want it: keyfreq was born. Code on github. (I forked it because I couldn’t find any way to send back my modifications to the upstream project, I don’t really feel a need for another project.)
So, I tried out the popular and widely used Linux key-logger software ‘logkeys‘ and immediately figured out that it doesn’t really support the precision and detail level I wanted so I forked the project and modified the code to work the way I want it: keyfreq was born. Code on github. (I forked it because I couldn’t find any way to send back my modifications to the upstream project, I don’t really feel a need for another project.)
Then I fired up the logging process and it has been running in the background for a while now, logging every key stroke with a time stamp.
Counting key frequency and how it gets distributed very quickly turns into basically seeing when I’m active in front of the computer and it also gave me thoughts around what a high key frequency actually means in terms of activity and productivity. Does a really high key frequency really mean that I was working intensely or isn’t that purpose more a sign of mail sending time? When I debug problems or research details, won’t those periods result in slower key activity?
In the end I guess that over time, the key frequency chart basically says that if I have pressed a lot of keys during a period, I was working on something then. Hours or days with a very low average key frequency are probably times when I don’t work as much.
The weekend key frequency is bound to be slightly wrong due to me sometimes doing weekend hacking on other computers where I don’t log the keys since my results are recorded from a single specific keyboard only.
So what did I learn? Here are some conclusions and results from 1276614 keystrokes done over a period of the most recent 52 calendar days.
I have a 105-key keyboard, but during this period I only pressed 90 unique keys. Out of the 90 keys I pressed, 3 were pressed more than 5% of the time – each. In fact, those 3 keys are more than 20% of all keystrokes. Those keys are:
Only 29 keys were used more than 1% of the presses, giving this a really long tail with lots of keys hardly ever used.
Over this logged time, I have registered key strokes during 46% of all hours. Counting only the hours in which I actually used the keyboard, the average number of key strokes were 2185/hour, 36 keys/minute.
The average week day (excluding weekend days), I registered 32486 key presses. The most active sinngle minute during this logging period, I hit 405 keys. The most active single hour I managed to do 7937 key presses. During weekends my activity is much lower, and then I average at 5778 keys/day (7.2% of all activity were weekends).
When counting most active hours over the day, there are 14 hours that have more than 1% activity and there are 5 with less than 1%, leaving 5 hours with no keyboard activity at all (02:00- 06:59). Interestingly, the hour between 23-24 at night is the single most busy hour for me, with 12.5% of all keypresses during the period.
Longest contiguous time without keys: 26.4 hours
Longest key sequence without backspace: 946
There are 7 keys I only pressed once during this period; 4 of them are on the numerical keypad and the other three are F10, F3 and
I’ll try to keep the logging going and see if things change over time or if there later might end up things that can be seen in the data when looked over a longer period.
http://daniel.haxx.se/blog/2014/11/12/keyboard-key-frequency/
|
|
Karl Dubost: How To Properly Configure Your Browser For Web Compatibility Forensics |
When testing a Web Compatibility issue, many things can interfere with your testing. The most neutral environment will help to identify the issue. For example, ads blockers, user stylesheets, etc will lead to sites malfunctionning or will create a false sense of a site working when it is not. Basically, we need to start the testing with an empty clean profile of a browser. As you do not want to have to restart your main browser all the time, you need to setup a different profile. So you have your normal browser and your webcompat browser side by side.
I will explain below my own configuration but you may adjust to your own specific needs. I'm running Aurora Firefox Developer Edition as my main browser.

You will need to create an additional profile. Follow the steps on using the Firefox profile manager.
When the profile manager window opens, choose "Create Profile…" and name it webcompat (or the name of your choice). Quit the profile manager. Now you can restart your normal browser (Developer Edition for me), the profile manager will automatically pop up a window, you will select default for example. Then click on your test browser (normal Firefox for me) and select this time webcompat profile.
We said that we wanted a browser that each time we were starting it is clean of any interactions with other environments, be present or past.
Go to the Firefox Preferences and follow these steps:


The only add-on I have installed is User Agent Switcher for testing by faking the User Agent string of mobile devices or other browsers on Firefox.
Restart your test browser one more time. You are now in a clean profile mode. Each time you want to test something new or you are afraid that your previous actions have created interferences, just restart the browser. You will also notice how fast the browser is without all the accumulated history.
Enjoy testing and analyze Web Compatibility bugs
Otsukare.
http://www.otsukare.info/2014/11/12/configure-webcompat-browser
|
|
Mozilla Privacy Blog: Mozilla’s Data Privacy Principles Revisited |
https://blog.mozilla.org/privacy/2014/11/11/mozillas-data-privacy-principles-revisited/
|
|
Yunier Jos'e Sosa V'azquez: Firefox Developer Edition esta aqu'i |
Despu'es de una semana anunciado por Mozilla y muchos sitios en Internet, coincidiendo con el 10o Aniversario de Firefox, Mozilla ha introducido a su canal de actualizaciones Firefox Developer Edition, el primer navegador dise~nado especialmente para los desarrolladores web.  Se trata de una edici'on enfocada a encontrar y tener f'acilmente las herramientas para desarrolladores a la mano, en un ambiente propicio en aras de acelerar el desarrollo de aplicaciones. Su color azul me recuerda al Zorro Azul, una versi'on de Firefox con muchos complementos 'utiles en el desarrollo que por un tiempo estuvimos ofreciendo en Firefoxman'ia hasta la ida de Gustavo.
Se trata de una edici'on enfocada a encontrar y tener f'acilmente las herramientas para desarrolladores a la mano, en un ambiente propicio en aras de acelerar el desarrollo de aplicaciones. Su color azul me recuerda al Zorro Azul, una versi'on de Firefox con muchos complementos 'utiles en el desarrollo que por un tiempo estuvimos ofreciendo en Firefoxman'ia hasta la ida de Gustavo.
M'as all'a de la nueva elegante interfaz de usuario, se crearon herramientas innovadoras como Valence (anteriormente Adaptador de Herramientas de Firefox), un pre-instalado complemento que le permite depurar cualquier contenido de la web que se ejecute en Chrome para Android, Safari Mobile para iOS, y Firefox.
Tambi'en se ha a~nadido WebIDE, con el cual se podr'a ejecutar y depurar aplicaciones Firefox OS directamente en tu navegador, utilizando un dispositivo con Firefox OS o el Simulador. Otras herramientas clave en su navegador incluyen Vista de Dise~no Responsivo, Editor Web de Audio, Inspector de P'agina, Consola Web, depurador Java Script, Monitor de red y el Editor de estilo.
Esta y otras versiones de Firefox pueden ejecutarlas al mismo tiempo porque utilizan perfiles diferentes. Algunas capturas de Firefox DE en ejecuci'on.



Gracias a un canal de comunicaci'on que han creado, y a trav'es de los comentarios y sugerencias que reciban de sus usuarios, en Mozilla ir'an iterando y evolucionando esta edici'on de Firefox. Pueden descargar Firefox Developer Edition o el zorro desde la secci'on Aurora de nuestra secci'on de Descargas. All'i debe elegir la versi'on que termina en developer.
En lo particular me gustar'ia que del canal Release/Estable (recomendando a los usuarios) quiten muchas de estas herramientas que podemos encontrar ahora en Developer pues no todos los usuarios de Firefox somos desarrolladores y un gran por ciento no las utiliza para nada. Esto har'a un Firefox m'as ligero al quitar c'odigo que pocas veces se necesita (no innecesario). ?Qu'e opinan ustedes?
!Feliz hacking!
http://firefoxmania.uci.cu/firefox-developer-edition-esta-aqui/
|
|
Adam Lofting: #DALMOOC structure |
I hesitantly post this, as I’m spending the evening looking at DALMOOC and hope to take part, but know I’m short on free time right now (what with a new baby and trying to buy a house) and starting the course late.
This is either the first in a series of blog posts about this course, or, we shall never talk about this again.
The course encourages open and distributed publishing of work and assessments, which makes answering this first ‘warm-up’ task feel like more of a commitment to the course than I can really make. But here goes…
Competency 0.1: Describe and navigate the distributed structure of DALMOOC, different ways to engage with peers and various technologies to manage and share personal learning.
DALMOOC offers and encourages learning experiences that span many online products from many providers but which all connect back to a core curriculum hosted on the edX platform. This ranges from learning to use 3rd party tools and software to interacting with peers on commercial social media platforms like Twitter and Facebook. Learners can pick the tools and engagement best suited to them, including an option to follow just the core curriculum within edX if they prefer to do so.
It actually feels a lot like how we work at Mozilla, which is overwhelming and disorientating at first but empowering in the long run.
Writing this publically, however lazily, has forced me to engage with the task much more actively than I might have just sitting back and watching a lecture and answering a quiz.
But I suspect that a fear of the web, and a lack of experience ‘working open’ would make this a terrifying experience for many people. The DALMOOC topic probably pre-selects for people with a higher than average disposition to work this way though, which helps.
http://feedproxy.google.com/~r/adamlofting/blog/~3/zvNiri1hFuU/
|
|
Nicholas Nethercote: Quantifying the effects of Firefox’s Tracking Protection |
A number of people at Mozilla are working on a wonderful privacy initiative called Polaris. This will include activities such as Mozilla hosting its own high-capacity Tor middle relays.
But the part of Polaris I’m most interested in is Tracking Protection, which is a Firefox feature that will make it trivial for users to avoid many forms of online tracking. This not only gives users better privacy; experiments have shown it also speeds up the loading of the median page by 20%! That’s an incredible combination.
I decided to evaluate the effectiveness of Tracking Protection. To do this, I used Lightbeam, a Firefox extension designed specifically to record third-party tracking. On November 2nd, I used a trunk build of the mozilla-inbound repository and did the following steps.
I then repeated these steps, but before visiting the sites I added the following step.
The sites I visited directly are marked as “Visited”. All the third-party sites are marked as “Third Party”.
Connected with 86 sites Type Website Sites Connected ---- ------- --------------- Visited google.com 3 Third Party gstatic.com 5 Visited techcrunch.com 25 Third Party aolcdn.com 1 Third Party wp.com 1 Third Party gravatar.com 1 Third Party wordpress.com 1 Third Party twitter.com 4 Third Party google-analytics.com 3 Third Party scorecardresearch.com 6 Third Party aol.com 1 Third Party questionmarket.com 1 Third Party grvcdn.com 1 Third Party korrelate.net 1 Third Party livefyre.com 1 Third Party gravity.com 1 Third Party facebook.net 1 Third Party adsonar.com 1 Third Party facebook.com 4 Third Party atwola.com 4 Third Party adtech.de 1 Third Party goviral-content.com 7 Third Party amgdgt.com 1 Third Party srvntrk.com 2 Third Party voicefive.com 1 Third Party bluekai.com 1 Third Party truste.com 2 Third Party advertising.com 2 Third Party youtube.com 1 Third Party ytimg.com 1 Third Party 5min.com 1 Third Party tacoda.net 1 Third Party adadvisor.net 2 Third Party dictionary.com 1 Visited reference.com 32 Third Party sfdict.com 1 Third Party amazon-adsystem.com 1 Third Party thesaurus.com 1 Third Party quantserve.com 1 Third Party googletagservices.com 1 Third Party googleadservices.com 1 Third Party googlesyndication.com 3 Third Party imrworldwide.com 3 Third Party doubleclick.net 5 Third Party legolas-media.com 1 Third Party googleusercontent.com 1 Third Party exponential.com 1 Third Party twimg.com 1 Third Party tribalfusion.com 2 Third Party technoratimedia.com 2 Third Party chango.com 1 Third Party adsrvr.org 1 Third Party exelator.com 1 Third Party adnxs.com 1 Third Party securepaths.com 1 Third Party casalemedia.com 2 Third Party pubmatic.com 1 Third Party contextweb.com 1 Third Party yahoo.com 1 Third Party openx.net 1 Third Party rubiconproject.com 2 Third Party adtechus.com 1 Third Party load.s3.amazonaws.com 1 Third Party fonts.googleapis.com 2 Visited nytimes.com 21 Third Party nyt.com 2 Third Party typekit.net 1 Third Party newrelic.com 1 Third Party moatads.com 2 Third Party krxd.net 2 Third Party dynamicyield.com 2 Third Party bizographics.com 1 Third Party rfihub.com 1 Third Party ru4.com 1 Third Party chartbeat.com 1 Third Party ixiaa.com 1 Third Party revsci.net 1 Third Party chartbeat.net 2 Third Party agkn.com 1 Visited cnn.com 14 Third Party turner.com 1 Third Party optimizely.com 1 Third Party ugdturner.com 1 Third Party akamaihd.net 1 Third Party visualrevenue.com 1 Third Party batpmturner.com 1
Connected with 33 sites Visited google.com 3 Third Party google.com.au 0 Third Party gstatic.com 1 Visited techcrunch.com 12 Third Party aolcdn.com 1 Third Party wp.com 1 Third Party wordpress.com 1 Third Party gravatar.com 1 Third Party twitter.com 4 Third Party grvcdn.com 1 Third Party korrelate.net 1 Third Party livefyre.com 1 Third Party gravity.com 1 Third Party facebook.net 1 Third Party aol.com 1 Third Party facebook.com 3 Third Party dictionary.com 1 Visited reference.com 5 Third Party sfdict.com 1 Third Party thesaurus.com 1 Third Party googleusercontent.com 1 Third Party twimg.com 1 Visited nytimes.com 3 Third Party nyt.com 2 Third Party typekit.net 1 Third Party dynamicyield.com 2 Visited cnn.com 7 Third Party turner.com 1 Third Party optimizely.com 1 Third Party ugdturner.com 1 Third Party akamaihd.net 1 Third Party visualrevenue.com 1 Third Party truste.com 1
86 site connections were reduced to 33. No wonder it’s a performance improvement as well as a privacy improvement. The only effect I could see on content was that some ads on some of the sites weren’t shown; all the primary site content was still present.
google.com was the only site that didn’t trigger Tracking Protection (i.e. the shield icon didn’t appear in the address bar).
The results are quite variable. When I repeated the experiment the number of third-party sites without Tracking Protection was sometimes as low as 55, and with Tracking Protection it was sometimes as low as 21. I’m not entirely sure what causes the variation.
If you want to try this experiment yourself, note that Lightbeam was broken by a recent change. If you are using mozilla-inbound, revision db8ff9116376 is the one immediate preceding the breakage. Hopefully this will be fixed soon. I also found Lightbeam’s graph view to be unreliable. And note that the privacy.trackingprotection.enabled preference was recently renamed browser.polaris.enabled. [Update: that is not quite right; Monica Chew has clarified the preferences situation in the comments below.]
Finally, Tracking Protection is under active development, and I’m not sure which version of Firefox it will ship in. In the meantime, if you want to try it out, get a copy of Nightly and follow these instructions.
|
|
Christie Koehler: Building a learning resource directory for Mozilla |
The Learning Resource Directory (LRD) is a project (overview here) I’m leading to help organize and make discoverable all the information for learning about Mozilla and how to participate in our many projects. This post introduces the project, explains the current working prototype and gives information about how to get involved.
Mozillians have created a sizeable knowledge base over the project’s 15+ year history. We have a significant number of resources documenting and teaching the tools, policies, processes and procedures necessary for contributing to Mozilla.
Unfortunately for contributors, new and experienced alike, these resources are spread across a multitude of sources. These sources include websites, mailing-list archives, forums, blogs, social media, source code repositories, videos, and more. Some of these properties are hosted by Mozilla, others are not. Some are publicly available, others restricted to volunteers who have signed an NDA or are otherwise vouched and some are reserved for Mozilla paid staff.
What these resources have in common is the absence of a central index or directory that links them all together and makes them easily discoverable. It’s this gap that we’re addressing with the LRD.
As such, the goal of the Learning Resource Directory project is to provide an inclusive directory of all learning resources across Mozilla. The complete project plan, including timeline and KPIs is available here.
In order for directories of this sort to be successful, the information they provide needs to be: complete, current, relevant and contextual.
In order to be complete and current, Mozillians not only need to have the ability to contribute freely to the directory, but they also need to feel a sense of ownership and empowerment to ensure they become an integral, active part of its curation.
In order to be relevant and contextual, the data in the directory needs to be structured such that multiple views into the data can be created easily. That is, different learner types need different views of the directory. A new contributor who first requires basic competence of our essential communication tools presents a very different use case than an active contributor looking to branch out and work with a different team.
Two related projects to the Learning Resource Directory are Webmaker’s Web Literacy Mapper and MDN’s Learning Area documentation plan.
How the LRD differs from these projects is that the LRD is specifically about learning resources related to contributing to Mozilla and as such serves a different, if at times overlapping audience. There will certainly be some overlap between what MDN covers as part of their Learning Area plan and what the web literacy mapper covers. However, there is a lot to learn with regard to web literacy skills that has nothing to do with contributing to Mozilla. The same applies to developing web apps and other knowledge areas that MDN covers.
Do you know of other related projects or efforts? Let me know!
Taking the requirements into consideration, MozillaWiki quickly came to mind as a possible platform for creating the index. Powered by Mediawiki, MozillaWiki is already set up in a way that anyone can participate in content generation and curation. This is demonstrated by a significant active contributor base (MozillaWiki has 600+ active daily users). And, the Semantic Mediawiki extension, already in use, provides a way to store and view data in a structured manner.
So, I set about designing and implementing a prototype of the Learning Resource Directory. It’s far enough long that it’s now ready for people to take a look, try it out and provide feedback: https://wiki.mozilla.org/Learning_Resources
 Prototype of Learning Resource Directory homepage on MozillaWiki
Prototype of Learning Resource Directory homepage on MozillaWiki Prototype of Learning Resource entry creation form.
Prototype of Learning Resource entry creation form. Prototype of Learning Resource entry page/article. Wiki users can easily edit without needing to use wikitext by clicking ‘edit with form’ button.
Prototype of Learning Resource entry page/article. Wiki users can easily edit without needing to use wikitext by clicking ‘edit with form’ button.Each ‘learning resource’ has its own wiki page. Unlike regular wiki articles, these pages are created and edited in a guided way with a form. As such, any wiki user can create and edit learning resource pages without needing to know wikitext.
Each learning resource has:
Try editing an existing resource or creating a new one.
Storing learning resource data in this way allows us to create different views for the data. Rather than creating these views with a static list of links that needs to be manually updated, we can create them with semantic media queries.
Here’s the beginnings of the learning resource index home page where resources are grouped by their learning area: https://wiki.mozilla.org/Learning_Resource_Index
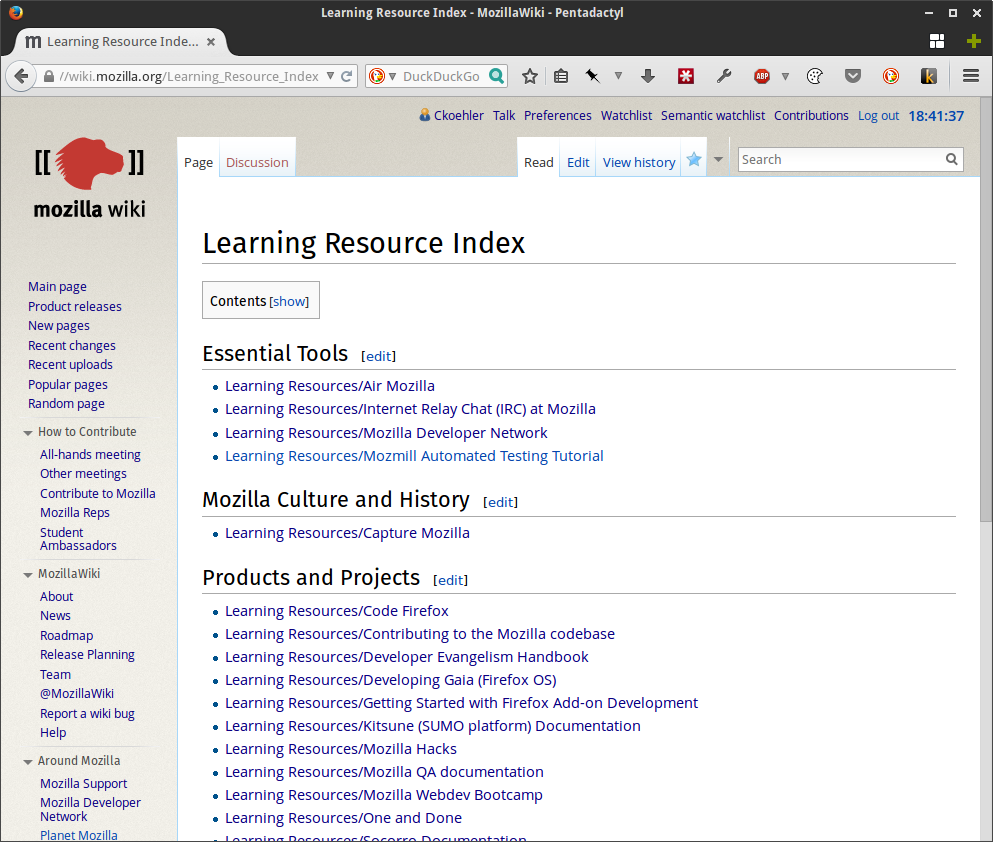 Prototype of learning resource index page.
Prototype of learning resource index page.And here’s an example of how a team might use queries of the learning resource index to create topic and audience-specific information such as new webdev contributors: https://wiki.mozilla.org/User:Ckoehler/Demos/Webdev_Get_Involved.
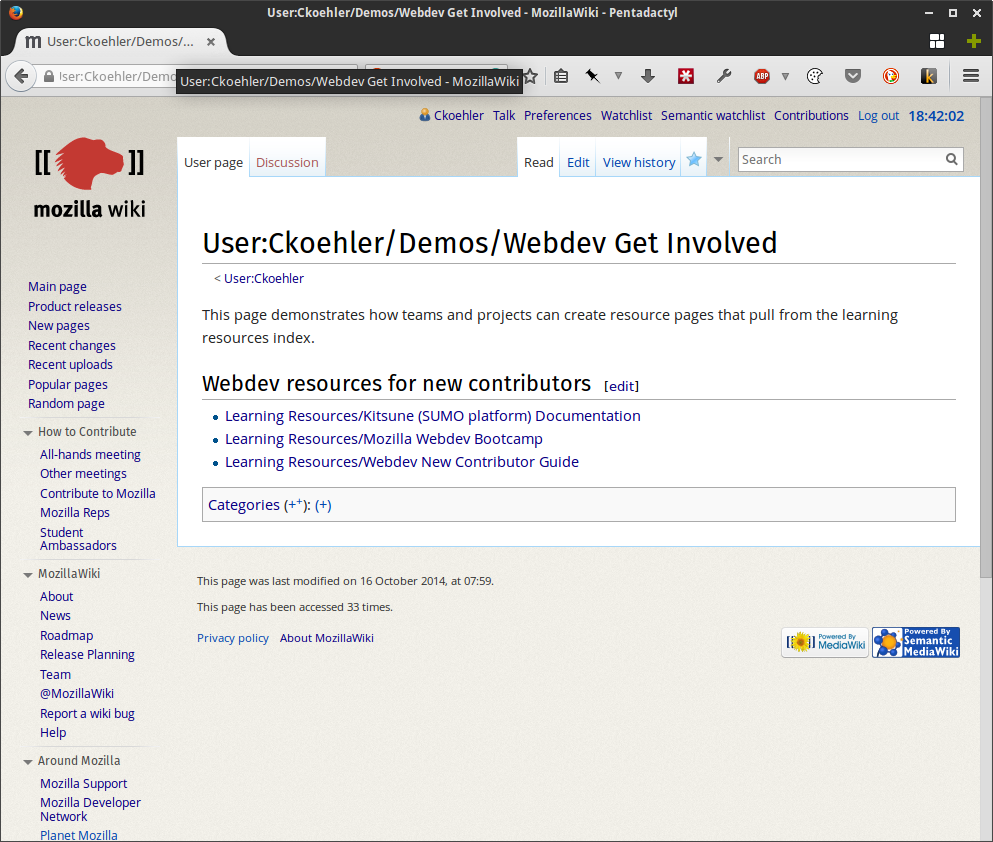 Prototype of team page with resources selectively display for a specific audience (in this case new webdev contributors).
Prototype of team page with resources selectively display for a specific audience (in this case new webdev contributors).These examples may not look like much, but keep in mind that they are dynamically created based on which resources have been entered that match the given criteria. This means that as new resources are added, or old ones updated, these pages will be updated as well.
The easiest way to get involved is to take a look at the learning resource index prototype, edit some entries, create some new ones and then leave feedback in one of these places:
Note: You’ll need to have a MozillaWiki account and be logged in to edit and create resources. You may request an account if you don’t have one already.
If you’re feeling adventures, try and create some views using semantic mediawiki queries. I’m in the process of documenting how to do this here, or you can take a look at one of the demos, copy its code and experiment with modifying it.
As you’re experimenting with the LRD and developing your feedback, please keep these questions in mind:
Additionally, I’m hosting a set of community calls to gather input and organize volunteers. Here are the dates of the calls:
Connection details for Vidyo meetings:
Connection details for IRC meetings:
Please join if you have comments, questions, general feedback or otherwise want to be involved!
http://subfictional.com/2014/11/11/building-a-learning-resource-directory-for-mozilla/
|
|
David Boswell: What does radical participation look like? |
I recently got back from my first Mozilla Festival and I’ve been thinking about what I experienced there. There is too much to fit in one post, so I want to focus on the question that came up in Mitchell’s keynote: What does radical participation look like?

What was radical when Mozilla started is standard practice today (for example, Microsoft now runs open source communities). We can’t win by doing the same thing others are doing, so how can Mozilla invite people to participate in ways that no one else is able or willing to do?
I have some thoughts about this and I’m interested in hearing what other people think. To get the conversation going, I’ll share one idea about what it would look like for Mozilla to have radical participation today.
Staff as scaffolding
In most areas of Mozilla, staff are directly doing the work and volunteers are involved with those teams to differing degrees. We have good metrics for coding and we can see that volunteers are committing around 40-50% of the patches.

For a comparison with another volunteer-based organization, at the American Red Cross volunteers constitute about 90% of the workforce. The Red Cross staff are mostly supporting those volunteers rather than doing the work of responding to disasters themselves.
We should measure the percentage of tasks done by volunteers across the whole project and set goals to get it closer to the example set by the Red Cross. Some areas, like SUMO and Location Services, are close to this today. Let’s take the knowledge they’re gaining and bring it to other teams to help them scale contributions.

There will certainly be challenges doing this and it might not make sense for all teams. For instance, with the coding example above it might not be productive to have more volunteers submitting patches. This is an assumption that should be tested though.
For example, Dietrich Ayala has had great results bringing in many students to help work on long-term features on the Firefox OS roadmap. Their work is removed from the day-to-day of staff developers shipping the next release, so he avoids the Mythical Man Month problem.
We could use Dietrich’s model to support large groups focused on innovating in areas that will be relevant to us 2 or 3 years out, such as looking into how we can shape an open Internet of Things. We couldn’t hire 1,000 staff to focus on an Internet of Things research effort, but we could build a community of 1,000 volunteers to do that.
Wikipedia says that there are about 1,000 employees of Microsoft Research. I’m assuming Microsoft wouldn’t be willing to close that department and replace their R&D efforts with volunteers.
So having volunteers do more of the tasks with staff focused on supporting them feels to me like one part of radical participation. What do you think? What else could we be doing to get to a point of radical participation?

http://davidwboswell.wordpress.com/2014/11/11/what-does-radical-participation-look-like/
|
|
Peter Bengtsson: Why is it important to escape & in href attributes in tags? |
Here’s an example of unescaped & characters in a A HREF tag attribute.
http://jsfiddle.net/32zbogfw/
It’s working fine.
I know it might break XML and possibly XHTML but who uses that still?

And I know an unescaped & in a href shows as red in the View Source color highlighting.
What can go wrong? Why is it important? Perhaps it used to be in 2009 but no longer the case.
This all started because I was reviewing some that uses python urllib.urlencode(...) and inserts the results into a Django template with href="{{ result_of_that_urlencode }}" which would mean you get un-escaped & characters and then I tried to find how and why that is bad but couldn't find any examples of it.
|
|
Rick Eyre: Lessons on Best Practices from Mozilla |
One of the ways we facilitate improvement in development processes and the like at EventMobi is by having lunch and learns where someone will present on something interesting. Sometimes that's a cool technology they've used or a good development practice they've discovered or have had experience with. To that end I gave a presentation on some of the lessons I've learnt on best practices while working in the Mozilla open-source community.
Allthough many of these best practices may seem like no brainers to seasoned developers, I still hear way to many horror stories through the grapevine about software being built under seriously bad conditions. So, without further ado.
One of the things I think Mozilla does really well is the idea of code ownership. This essentially means identifying those who have a level of knowledge about a particular area or module of code and thrusting upon them the responsibility to oversee it. From a practical point of view this means answering questions about the module that others have and also reviewing all of the changes that are being made to the module in order to ensure that they are sane and fit into the larger architecture of the module as a whole.
Mozilla does this really well by having clear definitions of what code ownership means, who code owners are, and who in the owners absence, can make decisions about that module.
The key part to this set up in my opinion is that it makes it clear what the requirements to become a code owner are and what their responsibilities are as a code owner. Too often I feel like, as with other things, if they aren't formalized they become subject to, well, subjectivity. And the details of code ownership and responsibility get lost in translation and hence, not enacted.
Bottom line, formalizing your code ownership policies and processes are a foundation for success. Without that it becomes unclear even who to ask to review code, is it the person in the blame? Possibly. Maybe not. Maybe that person didn't make correct changes, or made changes under the guidance of someone else. Maybe the code your changing has never even had a true 'owner'. No one knows the big picture for that piece of code and so no one knows enough about it to make informed decisions. That's a problem. If a code owner had been designated when that code was written that would never have been an issue.
We all know testing is a must for any sane development process. What I've learned through Mozilla is that having an insane amount of tests is okay. And honestly, preferable to just enough. As just enough is hard to gauge. The more tests I have in general, the more confident I feel in my code. Having a gauntlet of tests for your code makes it that much stronger.
Not only that, but it's important to be staying on top of tests. As a rule, not accepting code before it has a test and adding regression tests for bugs that are fixed. In exceptional cases code can merged without tests, but it should be tracked so that tests for it will be added later. Ten minutes spent writing a test now could save hours of developer time in the future tracking down bugs.
This is one of my personal favourites. And especially relevant I think in companies which are, in my experience, more driven to say yes—in order to hit that extra profit margin, to please that extra customer, to do whatever—as opposed to open-source projects who are able to say no because most of the time they have no deadline. They're driven by desire to build that next cool thing, to build it well, and to do it in a sane way.
From my experience working in Mozilla's and other open-source communities I've found it's important to say no when a feature isn't ready, when it's not good enough yet, when it needs an extra test, when it's not necessary, or when you just ain't got no time for that. I do think, however, that it's hard to say no sometimes while working under the constraints of a profit driven process. There is a healthy balance one can achieve though. We have to strive to achieve this zen like state.
One of the main ways I've seen this done is by ceating tickets for everything. See something off about the code? Log a ticket. See something in need of refactoring? Log a ticket. See something that needs a test? Log a ticket. Any kind of piece of work that you think needs to get done, any kind of open question that needs to be answered about the state of the code, log a ticket for it.
Logging tickets for the problem gives it visibility and documents it somewhere. This enables a few things to happen. It enables communication about the state of your code base across your team and makes that information easily accessible as it's documented in your tracking system. It also puts the problems that are not necessarily bugs—your stinky, ugly, untested code, or otherwise—to be in your teams face all the time. It's not just getting swept under the rug and not being paid attention too. It forces your team to deal with it and be aware of it.
The key part of this strategy then becomes managing all these tickets and attempting to understand what they are telling you. One of the ways you can do this is by doing regular triages. This means going through the open tickets and getting an idea of what state your code is in and prioritizing how to go about fixing it. This is key as it turns the information that your team has been generating into something actionable and something that you can learn from.
|
|
Doug Belshaw: Toward a history of Web Literacy |
As part of my work with Mozilla around Web Literacy Map v2.0 I want to use the web to tell the story of the history of web literacy. It might seem obvious to start from the 1990s, but it’s worth saying that developments in new literacies pre-date that decade. Check out Chapter 4 of my thesis for more detail on this.

This is the first of a (proposed) series of posts leading up to my keynote at the Literacy Research Association conference in Miami at the beginning of December.
Note: there’s lots of histories of the web itself. If you’re interested in that, just start with the relevant Wikipedia page. Here, I’m focusing on the discourse around the skills required to use the web.
The easiest way to get started is to use a couple of Google tools. Here’s what we get when we plug web literacy as a search term into Google Books Ngram Viewer, focusing on books published between 1990 and today:

Just to put that into context, here’s web literacy charted against information literacy, digital literacy, and media literacy:

A Google Books search only gives us search terms from books - and then, of course, only those books that have been scanned by Google.
Let’s have a look at Google Trends. This contains search queries by users entering terms into the Google search engine. These trends are constrained (unfortunately) to queries from 2004 onwards:

Again, in context:

So what do these graphs tell us? Well, not much by themselves, to be honest. It’s s shame that Google Trends only goes back as far as 2004 and, as far as I can ascertain, there’s no competitors to this product. Yahoo’s Clue service closed earlier this year, as have similar startups and services. So we only have Google’s view in this regard.
I need to do some more research, but from the years I spent researching digital literacy, my feeling is that we can talk about three periods for web literacy.
‘Web literacy’ was the term used by academics in the late 1990s to describe the differences between the page and the screen. There was a lot of discussion of hypertext. The focus was on understanding the similarities and differences between the page and the screen.
There was a lot of excitement about the affordances of the web as a new medium and, in particular, the ways that stories could be told. It fit in well to postmodern descriptions of the world around us as being fractal and contingent.
In the first decade of the 21st century, 'web literacy’ programmes (some of which still exist) became common in educational institutions. These focused on basic web skills for staff and students. Many of these were wrapped up in wider 'information literacy’ or 'digital literacy’ programmes and included procedural skills as well as learning how to spot internet hoaxes. This would be termed 'Credibility’ on the Web Literacy Map v1.1
In the main, however, due to Marc Prensky’s (damaging) article on 'digital natives’ and 'digital immigrants’, there was a feeling that young people just grew up’ understanding this stuff so there’s was no particular need to teach it. This idea was demolished by a 2008 article in the British Journal of Educational Technology.
There’s been a shift in the last few years to understanding that literacy practices relating to the web constitute more than just: 1) reading and writing using different tools, and 2) spotting internet hoaxes. The web is something we carry around with us everywhere, accessed through devices we still call 'mobile phones’. The web mediates our lives.
Most recently, due to the Snowden revelations, there’s been a realisation that that these devices aren’t neutral. They can shape the way we view the world, how we interact with one another, and the way others view us. The revelations showed us that our reliance on 'free’ services has led to corporate surveillance and government surveillance on a massive scale.
Although 'web literacy’ is a term that’s still gaining traction, there’s a growing movement of people who feel that the skills and competencies required to read, write and participate on the web are something that need to be learned and taught.
It’s into this world that we launched v1.1 of the Web Literacy Map. We hope to do even better and promote the Web Literacy Map as a platform with version 2.0.
Comments? Questions? Direct them to doug@mozillafoundation.org
|
|
Mozilla Reps Community: MozFest 2014: what a year! |

MozFest encapsulates many of the crazy wonders of Mozilla and every year new ideas emerge, new projects are created and new communities come together. 2014 was a great year for Reps; not only have the Reps lead many of the maker parties in the summer, but they are also pushing the Mozilla mission forward in every corner of the world. Having the Reps in London added expertise from all our communities
We would have loved to invite everyone who has been doing wonderful things around the Webmaker projects, but unfortunately we had a limited number of invitations. In London we had a great mix of passionate Reps from all around the world making us so proud of this incredible community who will share their experiences with everyone who couldn’t attend this year.
This year the Reps made a very significant contribution to MozFest! Not only did they facilitate many sessions, including one on community building, but they kept the show going in the background. Big kudos to Robby and all the MozFest helpers. On Sunday Reps literally saved the day! As the fox arrived with a bag full of 1000 phones the Reps (a.k.a Marcia’s flashing Gurus) spent Sunday flashing every phone ensuring that the participants of MozFest had the latest version.

The Flashing Gurus in action
It is very humbling to see the energy, the kindness and the commitment of the Reps and we got a lot of recognition, from Mark and Mitchell on the main stage routing for Reps and wearing their Reps hoodies and from the Mozilla community and our friends.
The Reps on the ground also inspired and were inspired by the other participants and brought all the local experiences to MozFest. It is this mix of hands-on work and diversity that opens the horizons for all of us who care about the web and think that this is a critical time to defend the open web and imagine a future where everyone can make active use of this tool for the good of everyone.
We know that the Reps will take their experiences and ignite the Mozfesters in their communities to get together and imagine the world we want to live in. One great example is how our Reps in East Africa pioneered the first MozFest outside of London. This is an exciting model, where Reps and Mozillians take the lead and bring the Mozilla spirit to hundreds of people. And we know that more of this greatness will come in 2015!
There are some amazing blog posts about Mozfest, from the personal experiences of everyone to great descriptions of the sessions, I recommend you check them out. Andre’s blog post is a great read to understand all the amazing things going on at MozFest and how the energy in Ravensbourne leads to so many new ideas. From other Reps we have great blog posts about their experience of MozFest:
Andre Garzia: A free agent at MozFest
Robby Sayles: Behind the scenes
Manel Rhaiem: my first experience at MozFest
Umesh Agarwal: Mozilla Festival 2014
One HUGE thanks to Ioana and Christos who were Chief Reps Wranglers and shined with professionalism, enthusiasm and made us all have a lot of fun. Also, pro tip, if you want to start a party, get some Reps to dance on stage ![]()

https://blog.mozilla.org/mozillareps/2014/11/11/mozfest-2014-what-a-year/
|
|
Henrik Skupin: Firefox Automation report – week 37/38 2014 |
In this post you can find an overview about the work happened in the Firefox Automation team during week 37 and 38.
After 7 months without a new release we finally were able to release mozdownload 1.12 with a couple of helpful enhancements and fixes.
We released Mozmill 2.0.7 and mozmill-automation 2.0.7 mainly for adding support of the v2 signed Firefox application bundles on OS X. Sadly we quickly had to follow-up with an appropriate 2.0.8 release for both tools, because a let change in the JS Engine caused a complete bustage of Mozmill. More details can be found in my appropriate blog post.
We were even able to finally release Memchaser 0.6, which is fixing a couple of outstanding bugs and brought in the first changes to fully support Australis.
One of our goals was to get the failure rate of Mozmill tests for release and beta candidate builds under 5%. To calculate that Cosmin wrote a little script, which pulls the test report data for a specific build from out dashboard and outputs the failure rate per executed testrun. We were totally happy to see that the failure rate for all Mozmill tests was around 0.027%!
During the merge process for the Firefox 32 release Andrei has seen some test inconsistencies between our named branches in the Mozmill-Tests repository. Some changes were never backported, and only present on the default branch for a very long time. He fixed that and also updated our documentation for branch merges
Something else worth for highlighting is also bug 1046645. Here our Mozmill tests found a case when Firefox does not correctly show the SSL status of a website if you navigate quickly enough. The fix for this regression caused by about:newtab made it even into the release notes
Last but not least Andreea started planning our Automation Training day for Q3. So she wrote a blog post about this event on QMO.
For more granular updates of each individual team member please visit our weekly team etherpad for week 37 and week 38.
If you are interested in further details and discussions you might also want to have a look at the meeting agenda, the video recording, and notes from the Firefox Automation meetings of week 37 and week 38.
http://www.hskupin.info/2014/11/11/firefox-automation-report-week-37-38-2014/
|
|







