Mozilla Security Blog: Updates to Firefox’s Breach Alert Policy |
 Your personal data is yours – and it should remain yours! Unfortunately data breaches that reveal your personal information on the internet are omnipresent these days. In fact, fraudulent use of stolen credentials is the 2nd-most common threat action (after phishing) in Verizon’s 2020 Data Breach Investigations report and highlights the problematic situation of data breaches.
Your personal data is yours – and it should remain yours! Unfortunately data breaches that reveal your personal information on the internet are omnipresent these days. In fact, fraudulent use of stolen credentials is the 2nd-most common threat action (after phishing) in Verizon’s 2020 Data Breach Investigations report and highlights the problematic situation of data breaches.
In 2018, we launched Firefox Monitor which instantly notifies you in case your data was involved in a breach and further provides guidance on how to protect your personal information online. Expanding the scope of protecting our users across the world to stay in control of their data and privacy, we integrated alerts from Firefox Monitor into mainstream Firefox. We integrated this privacy enhancing feature into your daily browsing experience so Firefox can better protect your data by instantly notifying you when you visit a site that has been breached.
While sites continue to suffer password breaches, other leaks or lose other types of data. Even though we consider all personal data as important, notifying you for every one of these leaks generates noise that’s difficult to act on. The better alternative is to only alert you in case it’s critical for you to act to protect your data. Hence, the primary change is that Firefox will only show alerts for websites where passwords were exposed in the breach.
In detail, we are announcing an update to our initial Firefox breach alert policy for when Firefox alerts for breached sites:
“Firefox shows a breach alert when a user visits a site where passwords were exposed and added to Have I Been Pwned within the last 2 months.”
To receive the most comprehensive breach alerts we suggest to sign up for Firefox Monitor to check if your account was involved in a breach. We will keep you informed and will alert you with an email in case your personal data is affected by a data breach. Our continued commitment to protect your privacy and security from online threats is critical for us and aligns with our mission: Individuals’ security and privacy on the internet are fundamental and must not be treated as optional.
If you are a Firefox user, you don’t have to do anything to benefit from this new privacy protection. If you aren’t a Firefox user, download Firefox to start benefiting from all the ways that Firefox works to protect your privacy.
The post Updates to Firefox’s Breach Alert Policy appeared first on Mozilla Security Blog.
https://blog.mozilla.org/security/2021/05/25/updates-to-firefoxs-breach-alert-policy/
|
|
The Mozilla Blog: Why I’m joining Mozilla’s Board of Directors |

Hugh Molotsi
I was born and raised in Zambia and came to the United States for university. Even though growing up, I had almost no exposure to computers, I chose to study computer engineering. Fortunately for me, this leap of faith proved to be a great decision, as I’ve been very blessed with the career that came after.
When I started my tenure at Intuit, my first job was working as a developer on QuickBooks for DOS. In what would turn out to be a 22-year run, I got a front row seat in watching technology evolve by working on Windows, Mac, and eventually online and mobile offerings. I was fortunate to play a leading role in the development of new Intuit products, which further fueled my passion for innovation.
From this vantage point, there is no doubt that the internet has been the most transformational technology in my years working in the industry. The internet has not only expanded the possibilities of problems to solve and how to solve them, but it has also expanded the reach of who can benefit from the solutions.
From the beginning, Mozilla has had an important vision: for the internet to benefit everyone, it should remain a global resource that is open and accessible. With this vision in mind, Mozilla has played a prominent role in the advancement of open source and community collaboration. The impact of Mozilla has catalyzed the internet as a force for good, as it touches lives in some of the least developed parts of the world.
I believe Mozilla’s mission is today more important than ever. In these polarized times, the internet is blamed for the rise of monoliths and the rapid spread of disinformation. Mozilla is the trusted entity ensuring the internet-as-a-public-resource is effective and enriches the lives of not just the privileged few. The challenges of a polarized world may feel daunting, but with human ingenuity and collaboration, I’m convinced the internet will play a key part in a better future. For someone who grew up in Africa, I’m especially excited about how the internet is enabling “leapfrog” solutions in meeting the needs of emerging economies.
I’m excited to help the Mozilla Corporation drive new innovations that will benefit the global community. This is why I am truly honored to serve on the Mozilla Corporation Board.
(Photographer credit: Danny Ortega)
The post Why I’m joining Mozilla’s Board of Directors appeared first on The Mozilla Blog.
|
|
Patrick Cloke: celery-batches 0.5 released! |
A new version (v0.5) of celery-batches is available which adds support for Celery 5.1 and fixes storing of results when using the RPC result backend.
As explored previously, the RPC result backend works by having a results queue per client, unfortunately celery-batches was attempting to store the results …
https://patrick.cloke.us/posts/2021/05/24/celery-batches-0.5-released/
|
|
Daniel Stenberg: The curl user survey 2021 |
For the eighth consecutive year we run the annual curl user survey again in 2021. The form just went up and I would love to have you spend 10 minutes of your busy life to tell us how you think curl works, what doesn’t work and what we should do next.
We have no tracking on the website and we have no metrics or usage measurements of the curl tool or the libcurl library. The only proper way we have left to learn how users and people in general think of us and how curl works, is to ask. So this is what we do, and we limit the asking to once per year.
You can also view this from your own “selfish” angle: this is a way for you to submit your input, your opinions and we will listen.
The survey will be up two weeks during which I hope to get as many people as possible to respond. If you have friends you know use curl or libcurl, please have them help us out too!
Yes really, please take the survey!
Bonus: see the extensive analysis of the 2020 user survey. There’s a lot of user feedback to learn from it.
https://daniel.haxx.se/blog/2021/05/24/the-curl-user-survey-2021/
|
|
The Firefox Frontier: Behind the design of the fresh new Firefox coming June 1 |
A new Firefox is coming your way on June 1 with a fresh look designed for today’s modern life online. We pored over the browser’s user interface pixel by pixel, … Read more
The post Behind the design of the fresh new Firefox coming June 1 appeared first on The Firefox Frontier.
|
|
Mozilla Attack & Defense: Browser fuzzing at Mozilla |
Mozilla has been fuzzing Firefox and its underlying components for a while. It has proven to be one of the most efficient ways to identify quality and security issues. In general, we apply fuzzing on different levels: there is fuzzing the browser as a whole, but a significant amount of time is also spent on fuzzing isolated code (e.g. with libFuzzer) or whole components such as the JS engine using separate shells. In this blog post, we will talk specifically about browser fuzzing only, and go into detail on the pipeline we’ve developed. This single pipeline is the result of years of work that the fuzzing team has put into aggregating our browser fuzzing efforts to provide consistently actionable issues to developers and to ease integration of internal and external fuzzing tools as they become available.

To be as effective as possible we make use of different methods of detecting errors. These include sanitizers such as AddressSanitizer (with LeakSanitizer), ThreadSanitizer, and UndefinedBehaviorSanitizer, as well as using debug builds that enable assertions and other runtime checks. We also make use of debuggers such as rr and Valgrind. Each of these tools provides a different lens to help uncover specific bug types, but many are incompatible with each other or require their own custom build to function or provide optimal results. Besides providing debugging and error detection, some tools cannot work without build instrumentation, such as code coverage and libFuzzer. Each operating system and architecture combination requires a unique build and may only support a subset of these tools.
Last, each variation has multiple active branches including Release, Beta, Nightly, and Extended Support Release (ESR). The Firefox CI Taskcluster instance builds each of these periodically.
Taskcluster makes it easy to find and download the latest build to test. We discussed above the number of variants created by different instrumentation types, and we need to fuzz them in automation. Because of the large number of combinations of builds, artifacts, architectures, operating systems, and unpacking each, downloading is a non-trivial task.
To help reduce the complexity of build management, we developed a tool called fuzzfetch. Fuzzfetch makes it easy to specify the required build parameters and it will download and unpack the build. It also supports downloading specified revisions to make it useful with bisection tools.
As the goal of this blog post is to explain the whole pipeline, we won’t spend much time explaining fuzzers. If you are interested, please read “Fuzzing Firefox with WebIDL” and the in-tree documentation. We use a combination of publicly available and custom-built fuzzers to generate test cases.
For fuzzers that target the browser, Grizzly manages and runs test cases and monitors for results. Creating an adapter allows us to easily run existing fuzzers in Grizzly.

To make full use of available resources on any given machine, we run multiple instances of Grizzly in parallel.
For each fuzzer, we create containers to encapsulate the configuration required to run it. These exist in the Orion monorepo. Each fuzzer has a configuration with deployment specifics and resource allocation depending on the priority of the fuzzer. Taskcluster continuously deploys these configurations to distribute work and manage fuzzing nodes.
Grizzly Target handles the detection of issues such as hangs, crashes, and other defects. Target is an interface between Grizzly and the browser. Detected issues are automatically packaged and reported to a FuzzManager server. The FuzzManager server provides automation and a UI for triaging the results.
Other more targeted fuzzers use JS shell and libFuzzer based targets use the fuzzing interface. Many third-party libraries are also fuzzed in OSS-Fuzz. These deserve mention but are outside of the scope of this post.
Running multiple fuzzers against various targets at scale generates a large amount of data. These crashes are not suitable for direct entry into a bug tracking system like Bugzilla. We have tools to manage this data and get it ready to report.
The FuzzManager client library filters out crash variations and duplicate results before they leave the fuzzing node. Unique results are reported to a FuzzManager server. The FuzzManager web interface allows for the creation of signatures that help group reports together in buckets to aid the client in detecting duplicate results.
Fuzzers commonly generate test cases that are hundreds or even thousands of lines long. FuzzManager buckets are automatically scanned to queue reduction tasks in Taskcluster. These reduction tasks use Grizzly Reduce and Lithium to apply different reduction strategies, often removing the majority of the unnecessary data. Each bucket is continually processed until a successful reduction is complete. Then an engineer can do a final inspection of the minimized test case and attach it to a bug report. The final result is often used as a crash test in the Firefox test suite.

Code coverage of the fuzzer is also measured periodically. FuzzManager is used again to collect code coverage data and generate coverage reports.
Our goal is to create actionable bug reports to get issues fixed as soon as possible while minimizing overhead for developers.
We do this by providing:
Grizzly Replay is a tool that forms the basic execution engine for Bugmon and Grizzly Reduce, and makes it easy to collect rr traces to submit to Pernosco. It makes re-running browser test cases easy both in automation and for manual use. It simplifies working with stubborn test cases and test cases that trigger multiple results.
As mentioned, we have also been making use of Pernosco. Pernosco is a tool that provides a web interface for rr traces and makes them available to developers without the need for direct access to the execution environment. It is an amazing tool developed by a company of the same name which significantly helps to debug massively parallel applications. It is also very helpful when test cases are too unreliable to reduce or attach to bug reports. Creating an rr trace and uploading it can make stalled bug reports actionable.
The combination of Grizzly and Pernosco have had the added benefit of making infrequent, hard to reproduce issues, actionable. A test case for a very inconsistent issue can be run hundreds or thousands of times until the desired crash occurs under rr. The trace is automatically collected and ready to be submitted to Pernosco and fixed by a developer, instead of being passed over because it was not actionable.
To request new features get a proper assessment, the fuzzing team can be reached at fuzzing@mozilla.com or on Matrix. This is also a great way to get in touch for any reason. We are happy to help you with any fuzzing related questions or ideas. We will also reach out when we receive information about new initiatives and features that we think will require attention. Once fuzzing of a component begins, we communicate mainly via Bugzilla. As mentioned, we strive to open actionable issues or enhance existing issues logged by others.
Bugmon is used to automatically bisect regression ranges. This notifies the appropriate people as quickly as possible and verifies bugs once they are marked as FIXED. Closing a bug automatically removes it from FuzzManager, so if a similar bug finds its way into the code base, it can be identified again.
Some issues found during fuzzing will prevent us from effectively fuzzing a feature or build variant. These are known as fuzz-blockers, and they come in a few different forms. These issues may seem benign from a product perspective, but they can block fuzzers from targeting important code paths or even prevent fuzzing a target altogether. Prioritizing these issues appropriately and getting them fixed quickly is very helpful and much appreciated by the fuzzing team.
PrefPicker manages the set of Firefox preferences used for fuzzing. When adding features behind a pref, consider adding it to the PrefPicker fuzzing template to have it enabled during fuzzing. Periodic audits of the PrefPicker fuzzing template can help ensure areas are not missed and resources are used as effectively as possible.
As in other fields, measurement is a key part of evaluating success. We leverage the meta bug feature of Bugzilla to help us keep track of the issues identified by fuzzers. We strive to have a meta bug per fuzzer and for each new component fuzzed.
For example, the meta bug for Domino lists all the issues (over 1100!) identified by this tool. Using this Bugzilla data, we are able to show the impact over the years of our various fuzzers.

Number of bugs reported by Domino over time
These dashboards help evaluate the return on investment of a fuzzer.
There are many components in the fuzzing pipeline. These components are constantly evolving to keep up with changes in debugging tools, execution environments, and browser internals. Developers are always adding, removing, and updating browser features. Bugs are being detected, triaged, and logged. Keeping everything running continuously and targeting as much code as possible requires constant and ongoing efforts.
If you work on Firefox, you can help by keeping us informed of new features and initiatives that may affect or require fuzzing, by prioritizing fuzz-blockers, and by curating fuzzing preferences in PrefPicker. If fuzzing interests you, please take part in the bug bounty program. Our tools are available publicly, and we encourage bug hunting.
https://blog.mozilla.org/attack-and-defense/2021/05/20/browser-fuzzing-at-mozilla/
|
|
Daniel Stenberg: “I could rewrite curl” |
Collected quotes and snippets from people publicly sneezing off or belittling what curl is, explaining how easy it would be to make a replacement in no time with no effort or generally not being very helpful.
These are statements made seriously. For all I know, they were not ironic. If you find others to add here, please let me know!
Listen. I’ve been young too once and I’ve probably thought similar things myself in the past. But there’s a huge difference between thinking and saying. Quotes included here are mentioned for our collective amusement.

[source]
(The yellow marking in the picture was added by me.)

[source]
Maybe not exactly in the same category as the two ones above, but still a significant “I know this” vibe:

[source]
Some people deliberately decides to play for the other team.

[source]
It’s easy to say things on Twitter…

This tweet was removed by its author after I and others replied to it so I cannot link it. The name has been blurred on purpose because of this.
https://daniel.haxx.se/blog/2021/05/20/i-could-rewrite-curl/
|
|
The Firefox Frontier: How to actually enjoy being online again |
COVID-19 accelerated changes in our behaviors that drove our lives increasingly online. Screens became our almost exclusive discovery point to the world. There were some benefits to this rapid shift. … Read more
The post How to actually enjoy being online again appeared first on The Firefox Frontier.
https://blog.mozilla.org/firefox/how-to-enjoy-being-online-again/
|
|
Hacks.Mozilla.Org: Improving Firefox stability on Linux |
Roughly a year ago at Mozilla we started an effort to improve Firefox stability on Linux. This effort quickly became an example of good synergies between FOSS projects.
Every time Firefox crashes, the user can send us a crash report which we use to analyze the problem and hopefully fix it:
This report contains, among other things, a minidump: a small snapshot of the process memory at the time it crashed. This includes the contents of the processor’s registers as well as data from the stacks of every thread.
Here’s what this usually looks like:

If you’re familiar with core dumps, then minidumps are essentially a smaller version of them. The minidump format was originally designed at Microsoft and Windows has a native way of writing out minidumps. On Linux, we use Breakpad for this task. Breakpad originated at Google for their software (Picasa, Google Earth, etc…) but we have forked, heavily modified for our purposes and recently partly rewrote it in Rust.
Once the user submits a crash report, we have a server-side component – called Socorro – that processes it and extracts a stack trace from the minidump. The reports are then clustered based on the top method name of the stack trace of the crashing thread. When a new crash is spotted we assign it a bug and start working on it. See the picture below for an example of how crashes are grouped:

To extract a meaningful stack trace from a minidump two more things are needed: unwinding information and symbols. The unwinding information is a set of instructions that describe how to find the various frames in the stack given an instruction pointer. Symbol information contains the names of the functions corresponding to a given range of addresses as well as the source files they come from and the line numbers a given instruction corresponds to.
In regular Firefox releases, we extract this information from the build files and store it into symbol files in Breakpad standard format. Equipped with this information Socorro can produce a human-readable stack trace. The whole flow can be seen below:

Here’s an example of a proper stack trace:

If Socorro doesn’t have access to the appropriate symbol files for a crash the resulting trace contains only addresses and isn’t very helpful:

When it comes to Linux things work differently than on other platforms: most of our users do not install our builds, they install the Firefox version that comes packaged for their favourite distribution.
This posed a significant problem when dealing with stability issues on Linux: for the majority of our crash reports, we couldn’t produce high-quality stack traces because we didn’t have the required symbol information. The Firefox builds that submitted the reports weren’t done by us. To make matters worse, Firefox depends on a number of third-party packages (such as GTK, Mesa, FFmpeg, SQLite, etc.). We wouldn’t get good stack traces if a crash occurred in one of these packages instead of Firefox itself because we didn’t have symbols for them either.
To address this issue, we started scraping debug information for Firefox builds and their dependencies from the package repositories of multiple distributions: Arch, Debian, Fedora, OpenSUSE and Ubuntu. Since every distribution does things a little bit differently, we had to write distro-specific scripts that would go through the list of packages in their repositories and find the associated debug information (the scripts are available here). This data is then fed into a tool that extracts symbol files from the debug information and uploads it to our symbol server.
With that information now available, we were able to analyze >99% of the crash reports we received from Linux users, up from less than 20%. Here’s an example of a high-quality trace extracted from a distro-packaged version of Firefox. We haven’t built any of the libraries involved yet the function names are present and so are the file and line numbers of the affected code:

The importance of this cannot be overestimated: Linux users tend to be more tech-savvy and are more likely to help us solve issues, so all those reports were a treasure trove for improving stability even for other operating systems (Windows, Mac, Android, etc). In particular, we often identified Fission bugs on Linux first.
The first effect of this newfound ability to inspect Linux crashes is that it greatly sped up our response time to Linux-specific issues, and often allowed us to identify problems in the Nightly and Beta versions of Firefox before they reached users on the release channel.
We could also quickly identify issues in bleeding-edge components such as WebRender, WebGPU, Wayland and VA-API video acceleration; oftentimes providing a fix within days of the change that triggered the issue.
We didn’t stop there: we could now identify distro-specific issues and regressions. This allowed us to inform package maintainers of the problems and have them resolved quickly. For example, we were able to identify a Debian-specific issue only two weeks after it was introduced and fixed it right away. The crash was caused by a modification made by Debian to one of Firefox dependencies that could cause a crash on startup, it’s filed under bug 1679430 if you’re curious about the details.
Another good example comes from Fedora: they had been using their own crash reporting system (ABRT) to catch Firefox crashes in their Firefox builds, but given the improvements on our side they started sending Firefox crashes our way instead.
We could also finally identify regressions and issues in our dependencies. This allowed us to communicate the issues upstream and sometimes even contributed fixes, benefiting both our users and theirs.
For example, at some point, Debian updated the fontconfig package by backporting an upstream fix for a memory leak. Unfortunately, the fix contained a bug that would crash Firefox and possibly other software too. We spotted the new crash only six days after the change landed in Debian sources and only a couple of weeks afterwards the issue had been fixed both upstream and in Debian. We sent reports and fixes to other projects too including Mesa, GTK, glib, PCSC, SQLite and more.
Nightly versions of Firefox also include a tool to spot security-sensitive issues: the probabilistic heap checker. This tool randomly pads a handful of memory allocations in order to detect buffer overflows and use-after-free accesses. When it detects one of these, it sends us a very detailed crash report. Given Firefox’s large user-base on Linux, this allowed us to spot some elusive issues in upstream projects and report them.
This also exposed some limitations in the tools we use for crash analysis, so we decided to rewrite them in Rust largely relying on the excellent crates developed by Sentry. The resulting tools were dramatically faster than our old ones, used a fraction of the memory and produced more accurate results. Code flowed both ways: we contributed improvements to their crates (and their dependencies) while they expanded their APIs to address our new use-cases and fixed the issues we discovered.
Another pleasant side-effect of this work is that Thunderbird now also benefits from the improvement we made for Firefox.
This goes on to show how collaboration between FOSS projects not only benefits their users but ultimately improves the whole ecosystem and the broader community that relies on it.
Special thanks to Calixte Denizet, Nicholas Nethercote, Jan Auer and all the others that contributed to this effort!
The post Improving Firefox stability on Linux appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2021/05/improving-firefox-stability-on-linux/
|
|
Mozilla Open Policy & Advocacy Blog: Mozilla publishes position paper on EU Digital Services Act |
In December 2020 the European Commission published the draft EU Digital Services Act. The law seeks to establish a new paradigm for tech sector regulation, and we see it as a crucial opportunity to address many of the challenges holding back the internet from what it should be. As EU lawmakers start to consider amendments and improvements to the draft law, today we’re publishing our substantive perspectives and recommendations to guide those deliberations.
We are encouraged that the draft DSA includes many of the policy recommendations that Mozilla and our allies had advocated for in recent years. For that we commend the European Commission. However, many elements of the DSA are novel and complex, and so there is a need for elaboration and clarification in the legislative mark-up phase. We believe that with targeted amendments the DSA has the potential to serve as the effective, balanced, and future-proof legal framework.
Given the sheer breath of the DSA, we’re choosing to focus on the elements where we believe we have a unique contribution to make, and where we believe the DSA can constitute a real paradigm shift. That is not to say we don’t have thoughts on the other elements of the proposal, and we look forward to supporting our allies in industry and civil society who are focusing their efforts elsewhere.
Broadly speaking, our position can be summarised as follows:
This position paper is the latest milestone in our long-standing engagement on issues of content regulation and platform responsibility in the EU. In the coming months we’ll be ramping up our efforts further, and look forward to supporting EU lawmakers in turning these recommendations into reality.
Ultimately, we firmly believe that if developed properly, the DSA can usher in a new global paradigm for tech regulation. At a time when lawmakers from Delhi to Washington DC are grappling with questions of platform accountability and content responsibility, the DSA is indeed a once-in-a-generation opportunity.
The post Mozilla publishes position paper on EU Digital Services Act appeared first on Open Policy & Advocacy.
|
|
Mozilla Security Blog: Introducing Site Isolation in Firefox |
When two major vulnerabilities known as Meltdown and Spectre were disclosed by security researchers in early 2018, Firefox promptly added security mitigations to keep you safe. Going forward, however, it was clear that with the evolving techniques of malicious actors on the web, we needed to redesign Firefox to mitigate future variations of such vulnerabilities and to keep you safe when browsing the web!
We are excited to announce that Firefox’s new Site Isolation architecture is coming together. This fundamental redesign of Firefox’s Security architecture extends current security mechanisms by creating operating system process-level boundaries for all sites loaded in Firefox for Desktop. Isolating each site into a separate operating system process makes it even harder for malicious sites to read another site’s secret or private data.
We are currently finalizing Firefox’s Site Isolation feature by allowing a subset of users to benefit from this new security architecture on our Nightly and Beta channels and plan a roll out to more of our users later this year. If you are as excited about it as we are and would like to try it out, follow these steps:
To enable Site Isolation on Firefox Nightly:
To enable Site Isolation on Firefox Beta or Release:
With this monumental change of secure browser design, users of Firefox Desktop benefit from protections against future variants of Spectre, resulting in an even safer browsing experience. If you aren’t a Firefox user yet, you can download the latest version here and if you want to know all the technical details about Firefox’s new security architecture, you can read it here.
The post Introducing Site Isolation in Firefox appeared first on Mozilla Security Blog.
https://blog.mozilla.org/security/2021/05/18/introducing-site-isolation-in-firefox/
|
|
Hacks.Mozilla.Org: Introducing Firefox’s new Site Isolation Security Architecture |
Like any web browser, Firefox loads code from untrusted and potentially hostile websites and runs it on your computer. To protect you against new types of attacks from malicious sites and to meet the security principles of Mozilla, we set out to redesign Firefox on desktop.
Site Isolation builds upon a new security architecture that extends current protection mechanisms by separating (web) content and loading each site in its own operating system process.
This new security architecture allows Firefox to completely separate code originating from different sites and, in turn, defend against malicious sites trying to access sensitive information from other sites you are visiting.
In more detail, whenever you open a website and enter a password, a credit card number, or any other sensitive information, you want to be sure that this information is kept secure and inaccessible to malicious actors.
As a first line of defence Firefox enforces a variety of security mechanisms, e.g. the same-origin policy which prevents adversaries from accessing such information when loaded into the same application.
Unfortunately, the web evolves and so do the techniques of malicious actors. To fully protect your private information, a modern web browser not only needs to provide protections on the application layer but also needs to entirely separate the memory space of different sites – the new Site Isolation security architecture in Firefox provides those security guarantees.
In early 2018, security researchers disclosed two major vulnerabilities, known as Meltdown and Spectre. The researchers exploited fundamental assumptions about modern hardware execution, and were able to demonstrate how untrusted code can access and read memory anywhere within a process’ address space, even in a language as high level as JavaScript (which powers almost every single website).
While band-aid countermeasures deployed by OS, CPU and major web browser vendors quickly neutralized the attacks, they came with a performance cost and were designed to be temporary. Back when the attacks were announced publicly, Firefox teams promptly reduced the precision of high-precision timers and disabled APIs that allowed such timers to be implemented to keep our users safe.
Going forward, it was clear that we needed to fundamentally re-architecture the security design of Firefox to mitigate future variations of such vulnerabilities.
Let’s take a closer look at the following example which demonstrates how an attacker can access your private data when executing a Spectre-like attack.
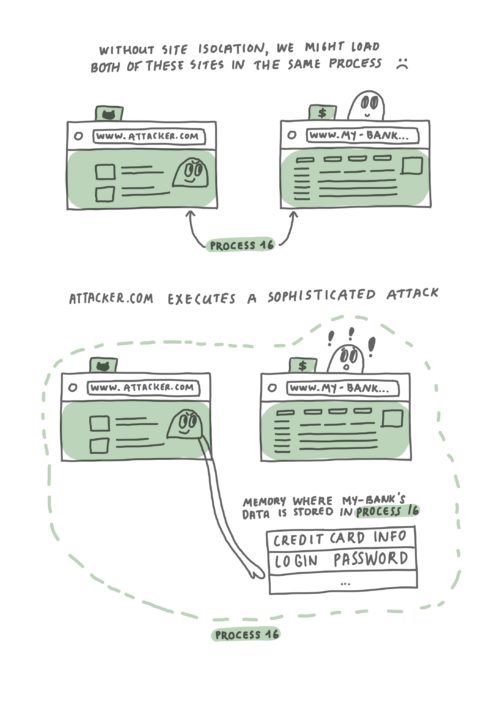
Without Site Isolation, Firefox might load a malicious site in the same process as a site that is handling sensitive information. In the worst case scenario, a malicious site might execute a Spectre-like attack to gain access to memory of the other site.
Suppose you have two websites open – www.my-bank.com and www.attacker.com. As illustrated in the diagram above, with current web browser architecture it’s possible that web content from both sites ends up being loaded into the same operating system process. To make things worse, using a Spectre-like attack would allow attacker.com to query and access data from the my-bank.com website.
Despite existing security mitigations, the only way to provide memory protections necessary to defend against Spectre-like attacks is to rely on the security guarantees that come with isolating content from different sites using the operating system’s process separation.
Upon being launched, the Firefox web browser internally spawns one privileged process (also known as the parent process) which then launches and coordinates activities of multiple (web) content processes – the parent process is the most privileged one, as it is allowed to perform any action that the end-user can.
This multi-process architecture allows Firefox to separate more complicated or less trustworthy code into processes, most of which have reduced access to operating system resources or user files. As a consequence, less privileged code will need to ask more privileged code to perform operations which it itself cannot.
For example, a content process will have to ask the parent process to save a download because it does not have the permissions to write to disk. Put differently, if an attacker manages to compromise the content process it must additionally (ab)use one of the APIs to convince the parent process to act on its behalf.
In great detail, (as of April 2021) Firefox’s parent process launches a fixed number of processes: eight web content processes, up to two additional semi-privileged web content processes, and four utility processes for web extensions, GPU operations, networking, and media decoding.
While separating content into currently eight web content processes already provides a solid foundation, it does not meet the security standards of Mozilla because it allows two completely different sites to end up in the same operating system process and, therefore, share process memory. To counter this, we are targeting a Site Isolation architecture that loads every single site into its own process.
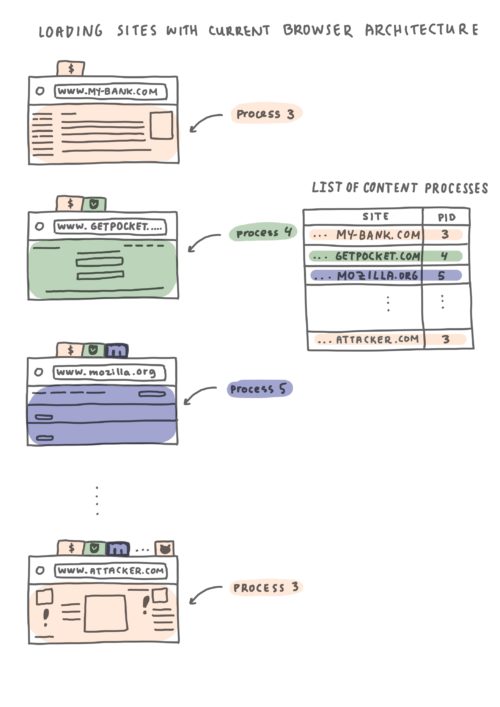
Without Site Isolation, Firefox does not separate web content into different processes and it’s possible for different sites to be loaded in the same process.
Imagine you open some websites in different tabs: www.my-bank.com, www.getpocket.com, www.mozilla.org and www.attacker.com. As illustrated in the diagram above, it’s entirely possible that my-bank.com and attacker.com end up being loaded in the same operating system process, which would result in them sharing process memory. As we saw in the previous example, with this separation model, an attacker could perform a Spectre-like attack to access my-bank.com’s data.
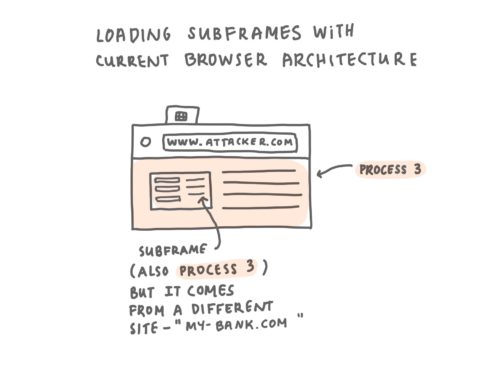
Without Site Isolation, the browser will load embedded pages, such as a bank page or an ad, in the same process as the top level document.
While straightforward to understand sites being loaded into different tabs, it’s also possible that sites are embedded into other sites through so-called subframes – if you ever visited a website that had ads on it, those are probably subframes. If you ever had a personal website and you embedded a YouTube video with your favourite song within it, the YouTube video was embedded in a subframe.
In a more dangerous scenario, a malicious site could embed a legitimate site within a subframe and try to trick you into entering sensitive information. With the current architecture, if a page contains any subframes from a different site, they will generally be in the same process as the outer tab.
This results in both the page and all of its subframes sharing process memory, even if the subframes originate from different sites. In the case of a successful Spectre-like attack, a top-level site might access sensitive information it should not have access to from a subframe it embeds (and vice-versa) – the new Site Isolation security architecture within Firefox will effectively make it even harder for malicious sites to execute such attacks.
When enabling Site Isolation in Firefox for desktop, each unique site is loaded in a separate process. In more detail, loading “https://mozilla.org” and also loading “http://getpocket.com” will cause Site Isolation to separate the two sites into their own operating system process because they are not considered “same-site”.
Similarly, “https://getpocket.com” (note the difference between http and https) will also be loaded into a separate process – so ultimately all three sites will load in different processes.
For the sake of completeness, there are some domains such as “.github.io” or “.blogspot.com” that would be too general to identify a “site”. This is why we use a community-maintained list of effective top level domains (eTLDs) to aid in differentiating between sites.
Since “github.io” is listed as an eTLD, “a.github.io” and “b.github.io” would load in different processes. In our running examples, websites “www.my-bank.com” and “www.attacker.com” are not considered “same-site” with each other and will be isolated in separate processes.
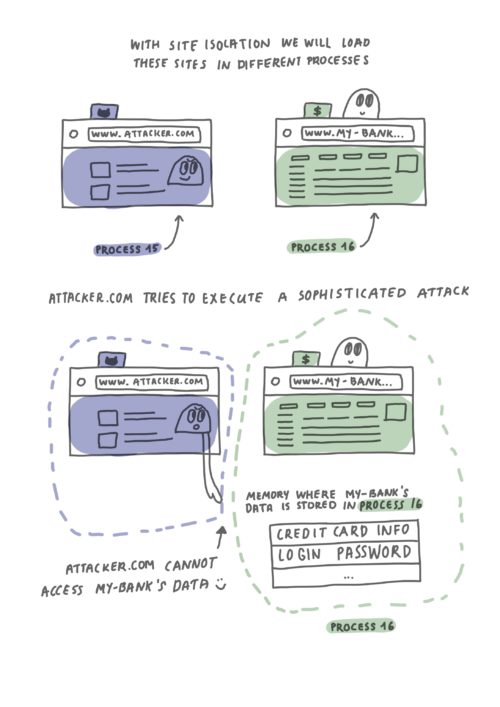
With Site Isolation, Firefox loads each site in its own process, thereby isolating their memory from each other, and relies on security guarantees of the operating system.
Suppose now, you open the same two websites: www.attacker.com and www.my-bank.com, as seen in the diagram above. Site isolation recognizes that the two sites are not “same-site” and hence the site isolation architecture will completely separate content from attacker.com and my-bank.com into separate operating system processes.
This process separation of content from different sites provides the memory protections required to allow for a secure browsing experience, making it even harder for sites to execute Spectre-like attacks, and, ultimately, provide a secure browsing experience for our users.
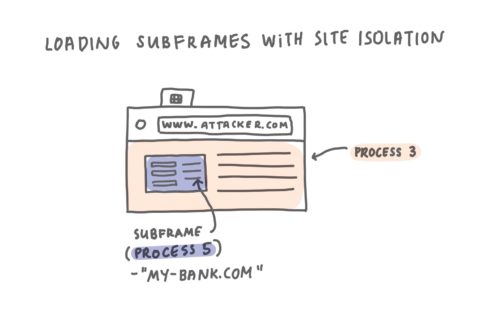
With Site Isolation, Firefox loads subframes from different sites in their own processes.
Identical to loading sites into two different tabs is the separation of two different sites when loaded into subframes. Let’s revisit an earlier example where pages contained subframes, with Site Isolation, subframes that are not “same-site” with the top level page will load in a different process.
In the diagram above, we see that the page www.attacker.com embeds a page from www.my-bank.com and loads in a different process. Having a top level document and subframes from different sites loaded in their own processes ensures their memory is isolated from each other, yielding profound security guarantees.
With Site Isolation architecture in place, we are able to bring additional security hardening to Firefox to keep you and your data safe. Besides providing an extra layer of defence against possible security threats, Site Isolation brings other wins:
We are currently testing Site Isolation on desktop browsers Nightly and Beta with a subset of users and will be rolling out to more desktop users soon. However, if you already want to benefit from the improved security architecture now, you can enable it by downloading the Nightly or Beta browser from here and following these steps:
To enable Site Isolation on Firefox Nightly:
To enable Site Isolation on Firefox Beta or Release:
For technical details on how we group sites and subframes together, you can check out our new process manager tool at “about:processes” (type it into the address bar) and follow the project at https://wiki.mozilla.org/Project_Fission.
With Site Isolation enabled on Firefox for Desktop, Mozilla takes its security guarantees to the next level and protects you against a new class of malicious attacks by relying on memory protections of OS-level process separation for each site. If you are interested in contributing to Mozilla’s open-source projects, you can help us by filing bugs here if you run into any problems with Site Isolation enabled.
Site Isolation (Project Fission), has been a massive multi-year project. Thank you to all of the talented and awesome colleagues who contributed to this work! It’s a privilege to work with people who are passionate about building the web we want: free, inclusive, independent and secure! In particular, I would like to thank Neha Kochar, Nika Layzell, Mike Conley, Melissa Thermidor, Chris Peterson, Kashav Madan, Andrew McCreight, Peter Van der Beken, Tantek Celik and Christoph Kerschbaumer for their insightful comments and discussions. Finally, thank you to Morgan Rae Reschenberg for helping me craft alt-text to meet the high standards of our web accessibility principles and allow everyone on the internet to easily gather the benefits provided by Site Isolation.
The post Introducing Firefox’s new Site Isolation Security Architecture appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2021/05/introducing-firefox-new-site-isolation-security-architecture/
|
|
Spidermonkey Development Blog: Ergonomic Brand Checks will ship with Firefox 90 |
When programming with Private Fields and methods, it can sometimes be desirable to check
if an object has a given private field. While the semantics of private fields allow doing that
check by using try...catch, the Ergonomic Brand checks proposal provides a simpler syntax,
allowing one to simply write #field in o.
As an example, the following class uses ergonomic brand checks to provide a more helpful custom error.
class Scalar {
#length = 0;
add(s) {
if (!(#length in s)) {
throw new TypeError("Expected an instance of Scalar");
}
this.#length += s.#length;
}
}
While the same effect could be accomplished with try...catch, it’s much uglier, and also doesn’t
work reliably in the presence of private getters which may possibly throw for different reasons.
This JavaScript language feature proposal is at Stage 3 of the TC39 process, and will ship in Firefox 90.
https://spidermonkey.dev/blog/2021/05/18/ergonomic-brand-checks.html
|
|
The Firefox Frontier: Class of Zoom: The reality of virtual graduation, prom & college orientation |
By Emily Gillespie Last spring, Norah W. took note of how former President Barack Obama, Beyonc'e and K-Pop band BTS broadcasted impassioned commencement speeches to the graduating class of 2020. … Read more
The post Class of Zoom: The reality of virtual graduation, prom & college orientation appeared first on The Firefox Frontier.
https://blog.mozilla.org/firefox/high-school-graduates-zoom-school-prom-graduation/
|
|
Daniel Stenberg: 200 OK |
One day in March 1998 I released a little file transfer tool I called curl. The first ever curl release. That was good.

By the end of July the same year, I released the 10th curl release. I’ve always believed in release early release often as a service to users and developers alike.

In December 1998 I released the 20th curl release. I started to get a hang of this.

In January 2001, not even three years in, we shipped the 50th curl release (version 7.5.2). We were really cramming them out back then!

Next week. 23 years, two months and six days after the first release, we will ship the 200th curl release. We call it curl 7.77.0.

Yes, there are exactly 200 stickers used in the photo. But the visual comparison with 50 is also apt: it isn’t that big difference seen from a distance.
I’ve personally done every release to date, but there’s nothing in the curl release procedure that says it has to be me, as long as the uploader has access to put the new packages on the correct server.
The fact that 200 is an HTTP status code that is indicating success is an awesome combination.
In 2014 we formally switched to an eight week release cycle. It was more or less what we already used at the time, but from then on we’ve had it documented and we’ve tried harder to stick to it.
Assuming no alarmingly bad bugs are found, we let 56 days pass until we ship the next release. We occasionally slip up and fail on this goal, and then we usually do a patch release and cut the next cycle short. We never let the cycle go longer than those eight weeks. This makes us typically manage somewhere between 6 and 10 releases per year.

|
|
The Rust Programming Language Blog: Announcing Rustup 1.24.2 |
|
|
The Rust Programming Language Blog: Six Years of Rust |
Today marks Rust's sixth birthday since it went 1.0 in 2015. A lot has changed since then and especially over the past year, and Rust was no different. In 2020, there was no foundation yet, no const generics, and a lot organisations were still wondering whether Rust was production ready.
In the midst of the COVID-19 pandemic, hundreds of Rust's global distributed set of team members and volunteers shipped over nine new stable releases of Rust, in addition to various bugfix releases. Today, "Rust in production" isn't a question, but a statement. The newly founded Rust foundation has several members who value using Rust in production enough to help continue to support and contribute to its open development ecosystem.
We wanted to take today to look back at some of the major improvements over the past year, how the community has been using Rust in production, and finally look ahead at some of the work that is currently ongoing to improve and use Rust for small and large scale projects over the next year. Let's get started!
The Rust language has improved tremendously in the past year, gaining a lot of quality of life features, that while they don't fundamentally change the language, they help make using and maintaining Rust in more places even easier.
As of Rust 1.52.0 and the upgrade to LLVM 12, one of few cases of unsoundness around forward progress (such as handling infinite loops) has finally been resolved. This has been a long running collaboration between the Rust teams and the LLVM project, and is a great example of improvements to Rust also benefitting the wider ecosystem of programming languages.
On supporting an even wider ecosystem, the introduction of Tier 1 support for 64 bit ARM Linux, and Tier 2 support for ARM macOS & ARM Windows, has made Rust an even better place to easily build your projects across new and different architectures.
The most notable exception to the theme of polish has been the major improvements to Rust's compile-time capabilities. The stabilisation of const generics for primitive types, the addition of control flow for const fns, and allowing procedural macros to be used in more places, have allowed completely powerful new types of APIs and crates to be created.
Rustc wasn't the only tool that had significant improvements.
Cargo just recently stabilised its new feature resolver, that makes it easier to use your dependencies across different targets.
Rustdoc stabilised its "intra-doc links" feature, allowing you to easily and automatically cross reference Rust types and functions in your documentation.
Clippy with Cargo now uses a separate build cache that provides much more consistent behaviour.
Each year Rust's growth and adoption in the community and industry has been unbelievable, and this past year has been no exception. Once again in 2020, Rust was voted StackOverflow's Most Loved Programming Language. Thank you to everyone in the community for your support, and help making Rust what it is today.
With the formation of the Rust foundation, Rust has been in a better position to build a sustainable open source ecosystem empowering everyone to build reliable and efficient software. A number of companies that use Rust have formed teams dedicated to maintaining and improving the Rust project, including AWS, Facebook, and Microsoft.
And it isn't just Rust that has been getting bigger. Larger and larger companies have been adopting Rust in their projects and offering officially supported Rust APIs.
Of course, all that is just to start, we're seeing more and more initiatives putting Rust in exciting new places;
rust-gpu, a new compiler backend that allows writing graphics shaders using Rust for GPUs.Right now the Rust teams are planning and coordinating the 2021 edition of Rust. Much like this past year, a lot of themes of the changes are around improving quality of life. You can check out our recent post about "The Plan for the Rust 2021 Edition" to see what the changes the teams are planning.
And that's just the tip of the iceberg; there are a lot more changes being worked on, and exciting new open projects being started every day in Rust. We can't wait to see what you all build in the year ahead!
Are there changes, or projects from the past year that you're excited about? Are you looking to get started with Rust? Do you want to help contribute to the 2021 edition? Then come on over, introduce yourself, and join the discussion over on our Discourse forum and Zulip chat! Everyone is welcome, we are committed to providing a friendly, safe and welcoming environment for all, regardless of gender, sexual orientation, disability, ethnicity, religion, or similar personal characteristic.
https://blog.rust-lang.org/2021/05/15/six-years-of-rust.html
|
|
Daniel Stenberg: curl -G vs curl -X GET |
(This is a repost of a stackoverflow answer I once wrote on this topic. Slightly edited. Copied here to make sure I own and store my own content properly.)
You normally use curl without explicitly saying which request method to use.
If you just pass in a HTTP URL like curl http://example.com, curl will use GET. If you use -d or -F curl will use POST, -I will cause a HEAD and -T will make it a PUT.
If for whatever reason you’re not happy with these default choices that curl does for you, you can override those request methods by specifying -X [WHATEVER]. This way you can for example send a DELETE by doing curl -X DELETE [URL].
It is thus pointless to do curl -X GET [URL] as GET would be used anyway. In the same vein it is pointless to do curl -X POST -d data [URL]... But you can make a fun and somewhat rare request that sends a request-body in a GET request with something like curl -X GET -d data [URL].
curl -GET (using a single dash) is just wrong for this purpose. That’s the equivalent of specifying the -G, -E and -T options and that will do something completely different.
There’s also a curl option called --get to not confuse matters with either. It is the long form of -G, which is used to convert data specified with -d into a GET request instead of a POST.
(I subsequently used this answer to populate the curl FAQ to cover this.)
Modern versions of curl will inform users about this unnecessary and potentially harmful use of -X when verbose mode is enabled (-v) – to make users aware. Further explained and motivated here.
You can ask curl to convert a set of -d options and instead of sending them in the request body with POST, put them at the end of the URL’s query string and issue a GET, with the use of `-G. Like this:
curl -d name=daniel -d grumpy=yes -G https://example.com/
… which does the exact same thing as this command:
curl https://example.com/?name=daniel&grumpy=yes
https://daniel.haxx.se/blog/2021/05/14/curl-g-vs-curl-x-get/
|
|






