Support.Mozilla.Org: SUMO A/B Experiments |
This year the SUMO team is focused on learning what to improve on our site. As part of that, we spent January setting support.mozilla.org up for A/B testing and last week we ran our first test!
The goal of the test was to run a series of experiments on individual Knowledge Base articles to:
The two tests we are running are trying a bunch of different things, such as screengrabs, video clips, highlights, better feedback options on articles, and better navigation.
Version A: Breadcrumbs

A breadcrumb menu should make it clearer to users where they are.

Feedback points through up/down icons with a follow up question to understand to allow for more feedback.

Highlights in the text to help the user see the important areas.
Version B: Hamburger menu – Categories

Hamburger menu to allow for users to focus on the content not the menu.

Drop down to see wider menu.
The test will run for the next 2-3 weeks and we will report back on here and our weekly SUMO meeting on the results and next steps.
The test is currently serving for 50% of visitors and you can ‘maybe’ see the tests by going here or here.
SUMO staff team
https://blog.mozilla.org/sumo/2019/03/22/sumo-a-b-experiments/
|
|
Mozilla Localization (L10N): L10n report: March edition |
Firefox 66 has been released on March 19, which means:
The deadline to ship updates for Beta will be on April 30. Also don’t forget that Firefox 68 is going to be the next ESR version: ideally you should be localizing it early in Nightly, in order to have a good amount of time for testing before it reaches the release channel.
This is not an action that we take lightly, because it’s demoralizing for the Community and potentially confusing for users, but in some cases we have to remove locales from Firefox builds. As outlined in the document, we try our best to revive the localization effort, and only act when it’s clear that we can’t solve the problem in other ways.
In Firefox 68 we’re going to remove the following locales: Assamese (as), South-African English (en-ZA), Maithili (mai), Malayalam (ml), Odia (or).
We’re also working with the Bengali community to unify two locales – Bengali India (bn-IN) and Bengali Banglashed (bn-BD) – under a single locale (bn), to optimize the Community resources we have.
The add-on for Firefox Monitor is now localized as part of the main Firefox projects. If you want to test it:
Just like for Firefox Desktop, the deadline to ship updates for Fennec Beta will be on April 30. Read the previous section of this report for more details surrounding that.
A notable Android update this month (that we’ve just announced on the dev-l10n mailing list – please consider following if it’s not yet the case) is that we’ve exposed on Pontoon the new Android-Components strings as part of the new Android-l10n project, to a small subset of locales.
Fenix browser strings are right around the corner as well, and will be exposed very soon in that same project, so stay tuned. Read up here for more details on all this.
On Firefox iOS side, we’re still working hard on shipping the upcoming version, which will be v16. Deadline for localization was today (March 21st), and with this new version we are adding one new locale: Vietnamese! Congrats to the team for shipping their first localized version of Firefox iOS!
Mozilla is partnering with the European Union to promote its Facebook Container extension in advance of the upcoming EU elections. We have translated the listing for the extension on addons.mozilla.org into 24 languages primarily used within the EU, and we could use your help localizing the user interface for addons.mozilla.org so people can have a more complete experience when downloading the extension. AMO frontend and server are two huge projects. If your locale has a lot to catch up, you can focus on these top priority strings the team has identified (note there are two tabs). You can search for them in the AMO Frontend project in Pontoon.
In order to promote the extension in 24 languages, we need to enable AMO server and AMO Frontend in all the languages, including Maltese, of which we don’t have a community. We also added a few languages out of product requirement without communities’ agreement. These languages are on the “read-only” locale list. They are Croatian, Estonian, Latvian, and Lithuanian for AMO Frontend, and Estonian and Latvian for AMO Server. If any of these communities are interested in localizing at least the high priority strings, please email the l10n-drivers so we can change the language setting.
There are a few updates coming soon. To prioritize, make sure to focus on shared files first (main.lang, download_button.lang), then the rest by star priority rating, or by deadline if applicable. You may see a few of the same strings appearing in several files. We usually leverage existing translations into a brand new file, but less so for updated file. In the latter case, please rely on Pontoon’s `Machinery` feature to leverage from your previous work.
Many new contributors joined the Mozilla localization communities through this project and are only interested in this project. Though there is an existing community that has been localizing other projects, the new contributors are new to localization, to Pontoon, to Mozilla localization process. They need your help with onboarding. Many have contributed to the project and are waiting for constructive feedback. Locale managers, please check the Common Voice project to see if there are strings waiting to be reviewed in your locale. Try to arrange resources to provide feedback in a timely manner. Based on the quality of the new contributors’ work and their interest, you can grant them broader permission at project level.
A very quick update on the misinformation campaign — the scorecard mentioned last month won’t be released, due to external changes. The good news is that a lot of the work done by the team is being reused and multiple campaigns will be launched instead. Details are evolving quickly, so there’s not much to share yet. We will keep you posted!
Translate.Next. Soon we’ll begin testing of the rewritten translation interface of Pontoon. The look & feel will largely remain the same, but the codebase will be completely different, allowing us to fulfill user requests in a more timely manner. Stay tuned for more updates in the usual l10n channels!
Improving experience for 3rd party installations. While used internally at Mozilla, Pontoon is a general purpose TMS with good support for popular localization file formats, ready to localize a variety of open source projects, apps or websites. Vishal started improving experience for 3rd party deployments by making Pontoon homepage customizable instead of hardcoding the Mozilla-specific content used on pontoon.mozilla.org. The path to setting up a first project for localization is now also more obvious.

Under the hood changes. Thanks to Jotes and Aniruddha, our Python test coverage has improved. On top of that, Jotes started making first steps towards migrating our codebase to Python3.
Did you enjoy reading this report? Let us know how we can improve by reaching out to any one of the l10n-drivers listed above.
https://blog.mozilla.org/l10n/2019/03/21/l10n-report-march-edition-2/
|
|
Firefox UX: Look over here! Results from a Firefox user research study about interruptions. |
The Attention War. There have been many headlines related to it in the past decade. This is the idea that apps and companies are stealing attention. It’s the idea that technologists throw up ads on websites in a feeble attempt to get the attention of the people who visit the website.
In tech, or any industry really, people often say something to the effect of, “well if the person using this product or service only read the instructions, or clicked on the message, or read our email, they’d understand and wouldn’t have any problems”. We need people’s attention to provide a product experience or service. We’re all in the “attention war”, product designers and users alike.
And what’s a sure-fire way to grab someone’s attention? Interruptions. Regardless if they’re good, bad, or neutral. Interruptions are not necessarily a “bad” thing, they can also lead to good behavior, actions, or knowledge.
Here are a couple questions the Firefox Team had about interruptions:
To answer the questions, I ran a user research study about the interruptions people receive while using Firefox. Eight participants were in a week-long study. Each participant used Firefox as their main browser on their laptop. Four participants agreed to record their browsing sessions over the course of the week, and six participants agreed to share their browsing analytics with us. I logged interruptions that came from the operating system, desktop software, Firefox, and websites. All participants were interviewed on the first day and last day. On the last day, I asked each participant to complete five tasks that would trigger interruptions to gauge understanding, behavior, and attitudes towards interruptions.
Before I answer the two questions from above, I’ll describe how I categorized interruptions.
Stopping Power
To analyze the data, I coded each interruption in terms of its stopping power. Mehrotra et al. coded interruptions as “low priority” and “high priority” depending on if the interruption stopped a person from completing their task [1]. Similarly, I coded each interruption as “low stopping power”, “medium stopping power”, and “high stopping power” (examples in the figures below). I defined stopping power as how much the design & implementation of an interruption makes it so that the user must interact with it to continue using the system. From the recorded interviews and browsing sessions (excluding the five tasks that triggered interruptions), I logged 83 low stopping power interruptions, 37 medium, and 15 high.
Now I’ll move on to answer our two research questions.
Participants care about their safety and saving time
When I asked participants how they felt about the 5 interruptions they experienced during the post interview, a clear theme was safety. One task was for participants to visit a “Bad SSL*” page. This happens when a website has a malformed or outdated security certificate. An error will appear and you’ll see a message like the screenshot below: “Your connection is not secure”.
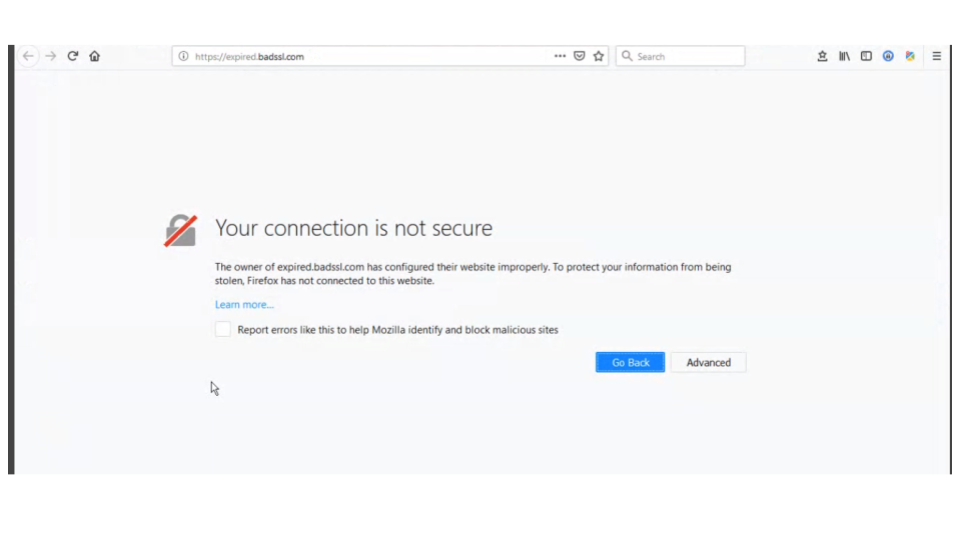
A couple participants were frustrated at first with the idea of encountering this page, because they would not be able to get to the website they wanted to get to, but then participants expressed an appreciation for it saying, like one participant: “now that I’ve read it, I suppose it’s trying to help” and another saying “I like that it’s protecting me”.
*SSL stands for Secure Sockets Layer and is a security protocol where websites share a certificate to verify their identity. Without a certificate to verify their identity, Firefox can’t be sure that the website is who it says it is.
Some participants were annoyed by interruptions, others could care less.
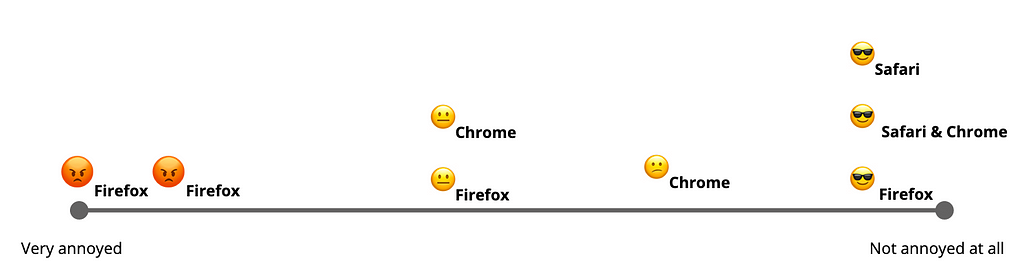
Participants reacted to interruptions differently, as shown by the scale above. This study was not able to determine the factors that impacted their level of annoyance — we would need to gather more data to determine that. However, it’s important to note that not everyone will react the same to interruptions. Some will make comments like one of the participants that it “feels like a gun shooting range” (where interruptions appear all over the place), and others will barely notice interruptions at all.
Most participants could not tell you the source of the interruption.
Only two of the eight participants could differentiate between all sources. They confidently knew if an interruption was from the operating system, website, or browser.
Four of the eight participants could differentiate between an operating system and a browser/website notification but NOT between a browser and a website notification. For example, a participant could tell that operating system was asking to perform an update. However, a participant could not tell if the website or browser was asking to save their credit card information.
One of the eight participants could not tell the difference between any of them. They thought that a notification from desktop email software was coming from Firefox, and wondered why other browsers did not do that.
Why is this important?
Do people really need to know the source of an interruption, if it does not hinder them from completing their task? Yes. An understanding of the source of the interruption is important for safety (i.e. people know where their data is and who it’s being shared with), and for mitigating potential annoyance with Firefox for things that Firefox is not responsible for.
Every time your product or service is considering interrupting someone, ask:
As I saw from the hours of browser recordings, we live in a vast sea of interruptions. Let’s be careful how we add to the ever-growing pile.
Acknowledgements (alphabetical by first name)
Thank you to my colleagues at Mozilla for helping with this study! Thanks to Aaron Benson, Alice Rhee, Amy Lee, Amy Tsay, Betsy Mikel, Brian Jones, Bryan Bell, Chris More, Chuck Harmston, Cindy Hsiang, Emanuela Damiani, Frank Bertsch, Gemma Petrie, Grace Xu, Heather McGaw, Javaun Moradi, Kamyar Ardekani, Kev Needham, Maria Popova, Meridel Walkington, Michelle Heubusch, Peter Dolanjski, Philip Walmsley, Romain Testard, Sharon Bautista, Stephen Horlander, Tim Spurway
Reference
[1] Mehrotra, A., Pejovic, V., Vermeulen, J., Hendley, R., & Musolesi, M. (2016). My Phone and Me (pp. 1021–1032). Presented at the the 2016 CHI Conference, New York, New York, USA: ACM Press. http://doi.org/10.1145/2858036.2858566.
Look over here! Results from a Firefox user research study about interruptions. was originally published in Firefox User Experience on Medium, where people are continuing the conversation by highlighting and responding to this story.
|
|
Botond Ballo: Trip Report: C++ Standards Meeting in Kona, February 2019 |
| Project | What’s in it? | Status |
| C++20 | See below | On track |
| Library Fundamentals TS v3 | See below | Under active development |
| Concepts TS | Constrained templates | Merged into C++20, including abbreviated function templates! |
| Parallelism TS v2 | Task blocks, library vector types and algorithms, and more | Published! |
| Executors | Abstraction for where/how code runs in a concurrent context | Not headed for C++20 |
| Concurrency TS v2 | See below | Under active development |
| Networking TS | Sockets library based on Boost.ASIO | Published! Not headed for C++20. |
| Ranges TS | Range-based algorithms and views | Merged into C++20! |
| Coroutines TS | Resumable functions, based on Microsoft’s await design |
Merged into C++20! |
| Modules v1 | A component system to supersede the textual header file inclusion model | Published as a TS |
| Modules v2 | Improvements to Modules v1, including a better transition path | Merged into C++20! |
| Numerics TS | Various numerical facilities | Under active development |
| Reflection TS | Static code reflection mechanisms | Approved for publication! |
| C++ Ecosystem TR | Guidance for build systems and other tools for dealing with Modules | Early development |
| Pattern matching | A match-like facility for C++ |
Under active development, targeting C++23 |
A few weeks ago I attended a meeting of the ISO C++ Standards Committee (also known as WG21) in Kona, Hawaii. This was the first committee meeting in 2019; you can find my reports on 2018’s meetings here (November 2018, San Diego), here (June 2018, Rapperswil), and here (March 2018, Jacksonville). These reports, particularly the San Diego one, provide useful context for this post.
This week marked the feature-complete deadline of C++20, so there was a heavy focus on figuring out whether certain large features that hadn’t yet merged into the working draft would make it in. Modules and Coroutines made it; Executors and Networking did not.
Attendance at this meeting wasn’t quite at last meeting’s record-breaking level, but it was still quite substantial. We continued the experiment started at the last meeting of running Evolution Incubator (“EWGI”) and Library Evolution Incubator (“LEWGI”) subgroups to pre-filter / provide high-level directional guidance for proposals targeting the Evolution and Library Evolution groups (EWG and LEWG), respectively.
Another notable procedural development is that the committee started to track proposals in front of the committee in GitHub. If you’re interested in the status of a proposal, you can find its issue on GitHub by searching for its title or paper number, and see its status — such as which subgroups it has been reviewed by and what the outcome of the reviews were — there.
Here are the new changes voted into C++20 Working Draft at this meeting. For a list of changes voted in at previous meetings, see my San Diego report. (As a quick refresher, major features voted in at previous meetings include default comparisons (<=>), concepts, contracts, and ranges.)
make_unique() and vector::emplace_back() to work with aggregates. It had a bit of a bumpy ride, as it was discovered that making it behave exactly as if the aggregate type had an invented constructor (which was the direction as of the last meeting) had unexpected implications; the final semantics are a mixture of brace initialization and a real constructor call.<=> != ==, an important fix to the default comparisons design.noexcept and explicitly defaulted functions).char16_t/char32_t string literals be UTF-16/32.polymorphic_allocator<> as a vocabulary type.std::midpointssize() functions, unsigned size() functions in spanistream_iterator.std::spancreate_directory() intuitive. std::underlying_type SFINAE-friendly.In addition to the C++ International Standard (IS), the committee publishes Technical Specifications (TS) which can be thought of experimental “feature branches”, where provisional specifications for new language or library features are published and the C++ community is invited to try them out and provide feedback before final standardization.
At this meeting, the committee iterated on a number of TSes under development.
The Reflection TS was sent out for its PDTS ballot two meetings ago. As described in previous reports, this is a process where a draft specification is circulated to national standards bodies, who have an opportunity to provide feedback on it. The committee can then make revisions based on the feedback, prior to final publication.
The ballot results (often referred to as “NB comments”, as they are comments from national bodies in response to the ballot) were published between the last meeting and this one, and the TS authors prepared proposed resolutions, which various subgroups reviewed this week. I am pleased to report that the committee addressed all the comments this week, and subsequently voted to publish the TS as amended by the comment resolutions. The final draft is not prepared yet, but I expect it will be in the committee’s next mailing, and will then be transmitted to ISO for official publication.
(I mentioned previously that a procedural snafu necessitated rebasing the TS onto {C++17 + Concepts TS} as it could not reference the not-yet-published C++20 working draft which contains Concepts in their current form. I was slightly mistaken: as the Concepts TS, which was published in 2015, is based on C++14, the Reflection TS actually had to be rebased onto {C++14 + Concepts TS}. Geneva: 1, common sense: 0.)
I wish I could tell you that there is an implementation of the Reflection TS available for experimentation and encourage you to try it out. Unfortunately, to my knowledge there is no such implementation, nor is one imminent. (There is a WIP implementation in a clang branch, but I didn’t get the impression that it’s actively being worked on. I would be delighted to be mistaken on that point.) This state of affairs has led me to reflect (pun intended) on the TS process a bit.
This third iteration (v3) of the Library Fundamentals TS is under active development, and gained its first new feature at this meeting, a generic scope guard and RAII wrapper. (The remaining contents of the TS working draft are features from v2 which haven’t been merged into the C++ IS yet.)
This meeting was the deadline for merging published TSes into C++20, so naturally a large amount of attention on the outstanding ones such as Modules and Coroutines.
As mentioned in my previous report, Modules gained design approval at the end of the last meeting, in San Diego. This was the culmination of a multi-year effort to reconcile and merge two different approaches to Modules — the design from the Modules TS, which has its roots in Microsoft’s early implementation work, and the Atom proposal which was inspired by Clang Modules — into a unified and cohesive language feature.
I found it interesting to see how the conversation around Modules shifted as the two approaches achieved convergence. For much of the past few years, the discussions and controversies focused on the differences between the two proposals, such as macro support, incremental transition mechanisms, and module organization (preambles and partitions and such).
Now that the compiler implementers have achieved consensus on the language feature, the focus has shifted to parts of the C++ ecosystem outside of the compilers themselves that are affected by Modules — notably, build systems and other tools. The tooling community has a variety of outstanding concerns about Modules, and these concerns dominated the conversation around Modules at this meeting. I talk about this in more detail in the SG15 (Tooling) section below, but my point here is that consensus among compiler implementers does not necessarily imply consensus among the entire C++ community.
All the same, the Core Working Group proceeded with wording review of Modules at full speed, and it was completed in time to hold a plenary vote to merge the feature into C++20. As mentioned, this vote passed, in spite of concerns from the tooling community. That is to say, Modules are now officially in the C++20 working draft!
It’s important to note that this does not mean the committee doesn’t care about the tooling-related concerns, just that it has confidence that the concerns can be addressed between now and the publication of C++20 (or, in the case of issues whose resolution does not require a breaking change to the core language feature, post-C++20).
The proponents of the Coroutines TS have been trying to merge it into C++20 for quite some time. Each of the three previous meetings saw an attempt to merge it, with the latter two making it to a plenary vote, only to fail there. The reason it had failed to achieve consensus so far was that there were some concerns abouts its design, and a couple of alternative proposals which attempt to address those concerns (namely, Core Coroutines, which had been under development for a few meetings now, and a new one at this meeting, Symmetric Coroutines).
We are sufficiently late in the cycle that the alternative proposals had no chance of getting into C++20, so the decision the Committee needed to make is, are the improvements these alternatives purport to bring worth delaying the feature until C++23 or later. Thus far, the Committee had been delaying this decision, in the hopes that further development on the alternative proposals would lead to a more informed decision. With this meeting being the deadline for merging a TS into C++20, the opportunities for delay were over, and the decision needed to be made this week.
Knowing that we’re down to the wire, the EWG chair instructed the authors of the various proposals to collaborate on papers exploring the design space, putting the respective proposals into context, and comparing their approaches in detail.
The authors delivered on this request, with commendably thorough analysis papers. I talk about the technical issues a bit below, but the high level takeaways were as follows:
Importantly, all of the authors were more or less in agreement on these points; their differences remained only in the conclusions they drew from them.
This allowed the Committee to make what I believe was a well-informed final decision, which was that merging the Coroutines TS into C++20 gained consensus both in EWG and subsequently in plenary. Notably, it wasn’t “just barely consensus,” either — the ratio of the final vote in plenary was on the order of 10 in favour to 1 against.
The Networking TS did not make C++20, in part due to concerns about its design based on usage experience, and in part because it depends on Executors which also didn’t make it (not even a subset, as was hoped at the last meeting).
Disclaimer: This section reflects my personal opinions on potentially controversial topics. Caveat lector / feel free to skip / etc.
Recall that using Technical Specifications as a vehicle to allow large proposals to mature before final standardization is a procedural experiment that the Committee embarked on after C++11, and which is still ongoing. I’ve mentioned that opinions on how successful this experiment has been, vary widely within the Committee.
I’ve previously characterized Concepts and Modules as examples of success stories for the TS process, as both features improved significantly between their TS and IS forms.
However, one realization has been on my mind of late: we don’t seem to have a great track record for motivating compiler vendors to implement language features in their TS form. Let’s survey a few examples:
constexpr-based reflection facilities that are targeting C++23.(If I’m mistaken on any of these points, I apologize in advance; please do point it out in a comment, and I will amend the above list accordingly.)
The Coroutines TS, which has multiple shipping implementations, is a notable exception to the above pattern. Library TS’es such as Networking, Filesystem, Library Fundamentals, and Parallelism also have a good track record of implementation. The fact remains, though, that the majority of our core language TS’es have not managed to inspire complete implementations.
This somewhat calls into question the value of language TS’s as vehicles for gathering use experience: you can’t collect use experience if users don’t have an implementation to use. (By contrast, implementation experience can be gathered from partial implementation efforts, and certainly has been for both Concepts and Modules.)
It also calls into question claims along the lines of “choosing to standardize [Feature X] as a TS first doesn’t mean you [users] have to wait longer to get it; you can just use the TS!” — a claim that I admit to have made myself, multiple times, on this blog.
What are the takeaways from this? Are language TS’es still a good idea? I’m still trying to work that out myself, but I will suggest a couple of takeaways for now:
Perhaps the actionable suggestion here is to downplay the role of a TS as a way to get a core language feature in front of users early. They do play other roles as well, such as providing a stabilized draft of a feature’s specification to write proposed changes against, and arguably they remain quite useful in that role.
Update: since publishing this, I’ve received private feedback that included suggestions of other advantages of core language TS’es, which I’ve found compelling, and wanted to share:
Continuing with the example of Modules, both of the above considerations were in play, and contributed to the high quality of the feature now headed for C++20.
I spent most of the week in EWG, as usual, although I did elope to some Study Group meetings, and to EWGI for a day.
Here I will list the papers that EWG reviewed, categorized by topic, and also indicate whether each proposal was approved, had further work on it encouraged, or rejected. Approved proposals are targeting C++20 unless otherwise mentioned; “further work” proposals are not, as this meeting was the deadline for EWG approval for C++20.
Contracts — which have been added into the C++20 working draft at the last meeting — have been the subject of very extensive mailing list discussions, and what I understand to be fairly heated in-person debates in EWG. I wasn’t in the room for them (I was in EWGI that day), but my understanding is that issues that have come up related to (1) undefined behaviour caused by compilers assuming the truth of contact predicates, and (2) incremental rollout of contracts in a codebase where they may not initially be obeyed at the time of introduction, have led to a plurality of stakeholders to believe that the Contracts feature as currently specified is broken.
To remedy this, three different solutions were proposed. The first two — “Avoiding undefined behaviour in contracts” and “Contracts that work” — attempted to fix the feature in the C++20 timeframe, with different approaches.
The third proposal was to just remove Contracts from C++20.
However, none of these proposals gained EWG consensus, so for now the status quo — a feature believed to be a broken in the working draft — remains.
I expect that updated proposals to resolve this impasse will forthcome at the next meeting, though I cannot predict their direction.
EWG did manage to agree on one thing: to rename the context-sensitive keywords that introduce pre- and post-conditions from expects and ensures (respectively) to pre and post. Another proposed tweak, to allow contract predicates on non-first decarations, failed to gain consensus.
EWG reviewed a handful of Modules-related proposals:
A couple of informational papers were also looked at:
make.Coroutines was probably the most talked-about subject at this meeting. I summarized the procedural developments that led to the Coroutines TS ultimately being merged into C++20, above.
Preceding that consequential plenary vote was an entire day of design discussion in EWG. The papers that informed the high-level directional discussion included:
I’d say the paper that had the biggest impact on the outcome was the analysis paper about the language and implementation impact. This is what discussed, in detail, what I described above as an “implementation challenge” shared by Core Coroutines and Symmetric Coroutines. The issue here is that both of these proposals aim to expose the coroutine frame — the data structure that stores the coroutine state, including local variables that persist across suspension points — as a first-class object in C++. The reason this is challenging is that first-class C++ objects have certain properties, such as their sizeof being known at constant expression evaluation time, which happens in the compiler front-end; however, the size of a coroutine frame is not known with any reasonable amount of accuracy until after optimizations and other tasks more typically done by the middle- or back-end stages of a compiler. Implementer consensus was that introducing this kind of depedency of the front-end on optimization passes is prohibitive in terms of implementation cost. The paper explores alternatives that involve language changes, such as introducing the notion of “late-sized types” whose size is not available during constant expression evaluation; some of these were deemed to be implementable, but the required language changes would have been extensive and still required a multi-year implementation effort. (The problem space here also has considerable overlap with variable-length arrays, which the committee has not been able to agree on to date.)
This, I believe was the key conclusion that convinced EWG members that if we go with the alternatives, we’re not likely to have Coroutines until the C++26 timeframe, and in light of that choice, to choose having the Coroutines TS now.
EWG also looked at a couple of specific proposed changes to the Coroutines TS, both of which were rejected:
coroutine_traits. This would have enhanced the ability of a programmer to customize the behaviour of a third-party coroutine type. I think the main reason for rejection was that the proposal involved new syntax, but the specific syntax had not been decided on, and there wasn’t time to hash it out in the C++20 timeframe. The proposal may come back as an enhancement in C++23.constexprThe march to make ever more things possible in constexpr continued this week:
constexpr contexts. “Trivial default initialization” refers to things like int x; at local scope, which leaves x uninitialized. This is currently ill-formed in a constexpr context; this proposal relaxes it so that it’s only ill-formed if you actually try to read the uninitialized value. The interesting use cases here involve arrays, such as the one used to implement a small-vector optimization.constinit keyword. This is a new keyword that can be used on a variable declaration to indicate that the initial value must be computed at compile time, without making the variable const (so that the value can be modified at runtime).constexpr structured bindings. This is targeting C++23; EWG didn’t request any specific design changes, but did request implementation experience.constexpr containers”. This proposal was previously approved by EWG, and had two parts: first, allowing dynamic allocation during constant evaluation; and second, allowing the results of the dynamic allocation to survive to runtime, at which time they are considered static storage. Recent work on this proposal unearthed an issue with the second part, related to what is mutable and what is constant during the constant evaluation. The authors proposed a solution, but EWG found the solution problematic for various reasons. After lengthy discussion, people agreed that a better solution is desired, but we don’t have time to find one for C++20, and the “promotion to static storage” ability can’t go forward without a solution, so this part of the proposal was yanked and will be looked at again for C++23. (The first part, dynamic allocations without promotion to static storage, remains on track for C++20.)<=> != ==. This is a revised version of a proposal approved at the last meeting to fix usability issues with <=>. The revisions were motivated by concerns brought up during Core wording review. The chosen direction from among the alternatives presented in the paper was that defaulting <=> always declared a default == as well.<=>. Another <=> fix revised after Core wording review. The revisions were accepted with the tweak that strong and weak ordering are both synthesized from == and < only.strong_order a customization point._ usage in C++20 for pattern matching in C++23. By the same authors as the pattern matching proposal, this paper tried to land-grab the _ identifier in C++20 for future use as a wildcard pattern in C++23 pattern matching. EWG wasn’t on board, due to concerns over existings uses of _ in various libraries, and the availability of other potential symbols. This does mean that the wildcard pattern in C++23 pattern matching will (very likely) have to be spelt some other way than _.for loop that can iterate over tuple-like objects, constexpr ranges, and parameter packs. The feature has been revised to address previous EWG feedback and use a single syntax, for...using enum. This allows bringing all the enumerators of an enumeration, or just a specific enumerator, into scope such that they can be referenced without typing the enumeration name or enclosing type name. Approved with the modification that it acts like a series of using-declarations.(Disclaimer: don’t read too much into the categorization here. One person’s bug fix is another’s feature.)
char8_t backwards compatibility remediation. This contains a couple of minor, library-based mitigations for the backwards compatibility breakage caused by u8 literals changing from type char to char8_t. Additional library and language-based mitigations were mentioned but not proposed.malloc() to allocate a POD object, defined. It also introduces a new “barrier operation” std::bless, a kind of counterpart to std::launder, which facilities writing custom operations that implicitly create objects like malloc(). One point that came up during discussion is that this proposal makes things like implementing a small vector optimization in constexpr possible (recall that things which trigger undefined behaviour at runtime are ill-formed during constant evaluation).volatile. Despite the provocative title, which is par for the course from our esteemed JF Bastien, this only deprecates uses of volatile which have little to no practical use, such as volatile-qualified member functions.[[nodiscard("should have a reason")]]. This extends the ability to annotate an attribute with a reason string, which [[deprecated]] already has, to [[nodiscard]].Notable among proposals that didn’t come up this week is Herb’s static exceptions proposal. As this is a C++23-track proposal, it was deliberately kept out of EWG so far to avoid distracting from C++20, but it is expected to come up at the next meeting in Cologne.
The EWG Incubator group (EWGI), meeting for the second time since its inception at the last meeting, continued to do a preliminary round of review on EWG-bound proposals.
I wasn’t there for most of the week, but here are the papers the group forwarded to EWG:
this (which was previously seen by EWG)ptrdiff_t and size_tNumerous other proposals were asked to return to EWGI with revisions. I’ll call out a few particularly interesting ones:
memcpy rather than invoking a move constructor and destructor, but the infrastructure for identifying such types is not present.enums, to C++, as an alternative to the library-based std::variant.Having sat in the Evolution groups, I haven’t been able to follow the Library groups in any amount of detail, but I’ll call out some of the more notable library proposals that have gained design approval at this meeting:
std::format), including chrono integration.string_view and spanranges::toSemiregular (which includes copyability) in many places.find_backwardstrong_order a customization point. This allows you to define a user-defined strong order on a type even if its default order might be e.g. just partial.<=> into the standard library.source_locationflat_setostream_joinerjthread (cooperatively interruptible joining thread, including stop tokens)unique_function (move-only std::function)out_ptr (a scalable output pointer abstraction)C++20-track work reviewed this week included revisions to joining thread, and deprecating volatile.
v1 of the Concurrency TS will be withdrawn; v2 continues to be under active development, with asymmetric fences approved for it this week.
Executors continue to be a hot topic. SG 1 forwaded two papers related to them onward to the Library Evolution Working Group, while three others remain under review. An earlier plan to ship a subset of executors in C++20 had to be scrapped, because LEWG requested the the “property” mechanism it relies on be generalized, but it was too late in the cycle to progress that for C++20. As a result, Executors are now targeting C++23.
Other proposals under active review in SG 1 concern fibers, concurrent associative data structures, memory model issues, volatile_load and volatile_store, customization points for atomic_ref, and thread-local storage.
The main topic in SG 7 continues to be deciding on the high-level direction for constexpr-based reflection in the (hopefully) C++23 timeframe. The two proposals on the table are scalable reflection in C++ and constexpr reflexpr; their main point of divergence is whether they use a single type (meta::info) to represent all compile-time reflection metadata objects (also known as reflections), or whether there should be a family / hierarchy (not necessarily inheritance-based) of such types (meta::variable, meta::function, etc.).
SG 7 expressed a preference for the “family of types” approach at the last meeting, however the point continues to be debated as the proposal authors gather more experience. The “single type” approach has been motivated by implementation experience in the EDG and Clang compilers, which has suggested this can achieve better compile-time performance. The “family of types” approach is motivated more by API design considerations, as expressed in the position paper constexpr C++ is not constexpr C.
While a consensus on this point is yet to emerge, a possible (and potentially promising) direction might be to build the “family of types” approach as a layer on top of the “single type” approach, which would be the one implemented using compiler primitives.
SG 7 also reviewed a proposal for a modern version of offsetof, which was forwaded to LEWG.
The Tooling Study Group (SG 15) met for an evening session, primarily to discuss tooling-related concerns around Modules.
As mentioned above, now that Modules has achieved consensus among compiler implemeters, tooling concerns (nicely summarized in this paper) are the remaining significant point of contention.
The concerns fall into two main areas: (1) how build systems interact with Modules, and (2) how non-compiler tools that consume source code (such as static analyzers) can continue to do so in a Modular world. The heart of the issue is that components of the C++ ecosystem that previously needed to rely only on behaviour specified in the C++ standard, and some well-established conventions (e.g. that compilers find included headers using a search path that can be disclosed to tools as well), now in a Modular world need to rely on behaviours that are out of scope of the C++ standard and for which established conventions are yet to emerge (such as how module names are mapped to module interface files, or how translation of imported modules is invoked / performed).
To address these concerns, SG 15 has announced what I view as probably the most exciting development since the group’s inception: that it will aim to produce and publish a C++ Ecosystem Technical Report containing guidance regarding the above-mentioned areas.
A Technical Report (TR) is a type of published ISO document which is not a specification per se, but contains guidance or discussion pertaining to topics covered by other specifications. The committee has previously published a TR in 2006, on C++ performance.
A TR seems like an appropriate vehicle for addressing the tooling-related concerns around Modules. While the committee can’t mandate e.g. how module names should map to file names, by providing guidance about it in the C++ Ecosystem TR, hopefully we can foster the emergence of widely followed conventions and best practices, which can in turn help maintain a high level of interoperability for tools.
The announcement of plans for a C++ Ecosystem TR did not completely assuage tool authors’ concerns; some felt that, while it was a good direction, Modules should be delayed and standardized in tandem with the TR’s publication in the C++23 timeframe. However, this was a minority view, and as mentioned Modules went on to successfully merge into the C++20 working draft at the end of the meeting.
Other Study Groups that met at this meeting include:
The next meeting of the Committee will be in Cologne, Germany, the week of July 15th, 2019.
This was an eventful and productive meeting, and it seems like the progress made at this meeting has been well-received by the user community as well! With Modules and Coroutines joining the ranks of Concepts, Ranges, contracts, default comparisons and much else in the C++20 working draft, C++20 is promising to the most significant language update since C++11.
Due to sheer number of proposals, there is a lot I didn’t cover in this post; if you’re curious about a specific proposal that I didn’t mention, please feel free to ask about it in the comments.
https://botondballo.wordpress.com/2019/03/20/trip-report-c-standards-meeting-in-kona-february-2019/
|
|
Mozilla GFX: WebRender newsletter #42 |
WebRender is a GPU based 2D rendering engine for web written in Rust, currently powering Mozilla’s research web browser servo and on its way to becoming Firefox‘s rendering engine.
Kvark made a few refactorings improving the internation code as well as framebuffer coordinates and document origin semantics. Kvark also improved plane-splitting accuracy and the way GL driver errors are reported.
Kvark also extracted a useful bit of WebRender into the copyless crate. This crate makes it possible to push large structures into standard vectors and hash maps in a way that llvm is better able to optimize than when using, says, Vec::push. This lets the large values get initialized directly in the container’s allocated memory without emitting extra memcpys.
Kats has fixed a number of scrolling related bugs, and is improving the automatic synchronization of WebRender’s code between the mozilla-central and github repositories.
Nical is investigating optimizations of the render task tree (with the idea of turning it into a graph rather than a tree strictly speaking). Currently WebRender does not provide a way for the output of a render task to be read by several other render tasks. In other words, if an element has a dozen shadows, we currently re-compute the blur for that element a dozen times. There are ongoing experiments with various render graph scheduling strategies in a separate repository and some of the findings from these experiments are being ported to WebRender.
Sotaro has landed a series of improvements around the way we handle cross-process texture sharing and how GL contexts are managed.
Timothy is working on a GPU implementation of the component transfer SVG filter. Avoiding the CPU fallback for this particular filter is important because of its use in Google docs.
Jeff has been doing a lot WebRender bug triage and profiling. He also fixed a very bad interaction between tiled blob images and filters which was causing the whole filtered area to be re-rendered from scratch for tile.
Doug continues his work on document splitting. A large part of it has already been reviewed.
Jessie got some glitchy gfx team stickers printed. It’s not a WebRender news per se, but I didn’t want to pass on an occasion to put a fun picture on the blog.

I originally made this (absolutely unofficial) logo to decorate the blog by simply flipping random bits in a png image of the Firefox Nightly logo. I recently re-did the logo in SVG using Inkscape to get a high enough resolution for the stickers.
In about:config, enable the pref gfx.webrender.all and restart the browser.
The best place to report bugs related to WebRender in Firefox is the Graphics :: WebRender component in bugzilla.
Note that it is possible to log in with a github account.
WebRender is available as a standalone crate on crates.io (documentation)
https://mozillagfx.wordpress.com/2019/03/20/webrender-newsletter-42/
|
|
Daniel Stenberg: Happy 21st, curl! |

Another year has passed. The curl project is now 21 years old.
I think we can now say that it is a grown-up in most aspects. What have we accomplished in the project in these 21 years?
We’ve done 179 releases. Number 180 is just a week away.
We estimate that there are now roughly 6 billion curl installations world-wide. In phones, computers, TVs, cars, video games etc. With 4 billion internet users, that’s like 1.5 curl installation per Internet connected human on earth
669 persons have authored patches that was merged.
The curl source code now consists of 160,000 lines of code made in over 24,000 commits.
1,927 persons have helped out so far. With code, bug reports, advice, help and more.
The curl repository also hosts 429 man pages with a total of 36,900 lines of documentation. That count doesn’t even include the separate project Everything curl which is a dedicated book on curl with an additional 10,165 lines.
In this time we have logged more than 4,900 bug-fixes, out of which 87 were security related problems.
We keep doing more and more CI builds, auto-builds, fuzzing and static code analyzing on our code day-to-day and non-stop. Each commit is now built and tested in over 50 different builds and environments and are checked by at least four different static code analyzers, spending upwards 20-25 CPU hours per commit.
We have had 2 curl developer conferences, with the third curl up about to happen this coming weekend in Prague, Czech Republic.
The curl project was created by me and I’m still the lead developer. Up until today, almost 60% of the commits in the project have my name on them. I have done most commits per month in the project every single month since August 2015, and in 186 months out of the 232 months for which we have logged data.
|
|
Hacks.Mozilla.Org: Firefox 66: The Sound of Silence |
Firefox 66 is out, and brings with it a host of great new features like screen sharing, scroll anchoring, autoplay blocking for audible media, and initial support for the Touch Bar on macOS.
These are just highlights. For complete information, see:
Starting with version 66, Firefox will block audible autoplaying video and audio. This means media (audio and video) have to wait for user interaction before playing, unless the muted property is set on the associated HTMLMediaElement. Blocking can be disabled on a case-by-case basis in the site information overlay:
 Now you get to decide when to disturb the sound of silence.
Now you get to decide when to disturb the sound of silence.
Note: We’re rolling out blocking gradually to ensure that it doesn’t break legitimate use cases. All Firefox users should have blocking enabled within a few days.
Firefox now implements scroll anchoring, which prevents slow-loading content from suddenly appearing and pushing visible content off the page.
The Touch Bar on macOS is now supported, offering quick access to common browser features without having to learn keyboard shortcuts.

Too many tabs? The overflow menu sports a new option to search through your open tabs and switch to the right one.
 Astute users will note that clicking on “Search Tabs” focuses the Awesomebar and types a
Astute users will note that clicking on “Search Tabs” focuses the Awesomebar and types a % sign in front of your query. Thus, while the menu entry makes tab search much more discoverable, you can actually achieve the same effect by focusing the Awesomebar and manually typing a % sign or other modifier.
Speaking of shortcuts, you can now manage and change all of the shortcuts set by extensions by visiting about:addons and clicking “Manage Extension Shortcuts” under the gear icon on the Extensions overview page.
We’ve completely redesigned Firefox’s security warnings to better encourage safe browsing practices (i.e., don’t ignore the warnings!)
Firefox is the first browser to support animating the CSS Grid grid-template-rows and grid-template-columns properties, as seen in the video below.
We’re also the first browser to support the overflow-inline and overflow-block media queries, which make it possible to apply styles based on whether (and how) overflowing content is available to the user. For example, a digital billboard might report overflow-block: none, while an e-reader would match overflow-block: paged.
Furthermore, Firefox now supports:
[attr] selectors.min-content and max-content size keywords.The new getDisplayMedia API enables screen sharing on the Web similarly to how getUserMedia provides access to webcams. The resulting stream can be processed locally or shared over the network with WebRTC. See Using the Screen Capture API on MDN for more information.
Mozilla is using getDisplayMedia in Bugzilla to allow people to take and attach screenshots to their bug reports, directly from inside the browser.
Also, starting with Firefox 66, InputEvent now has a read-only property, inputType. This distinguishes between many different types of edits that can happen inside an input field, for example insertText versus insertFromPaste. To learn more, check out the documentation (and live demo) on MDN.
Lastly, we’ve made a few changes to how Firefox works under the hood:
From all of us at Mozilla, thank you for choosing Firefox!
https://hacks.mozilla.org/2019/03/firefox-66-the-sound-of-silence/
|
|
The Mozilla Blog: Today’s Firefox Aims to Reduce Your Online Annoyances |
Almost a hundred years ago, John Maynard Keynes suggested that the industrial revolution would effectively end work for humans within a couple of generations, and our biggest challenge would be figuring what to do with that time. That definitely hasn’t happened, and we always seem to have lots to do, much of it online. When you’re on the web, you’re trying to get stuff done, and therefore online annoyances are just annoyances. Whether it’s autoplaying videos, page jumps or finding a topic within all your multiple tabs, Firefox can help. Today’s Firefox release minimizes those online inconveniences, and puts you back in control.
Ever open a new page and all of a sudden get bombarded with noise? Well, worry no more. Starting next week, we will be rolling out the peace that silence brings with our latest feature, block autoplay. Here’s how to use block autoplay:
There will be instances where there are some sites, like social media, that automatically mute the sound but will continue to play the video. In this case, the new Block Autoplay Feature will not stop the video from playing.
To enable autoplay on your favorite websites, add them to your permissions list by visiting the control center — which can be found by clicking the lowercase “i” with a circle in the address bar. From there go to Permissions and select “allow” in the drop down to automatically play media with sound.
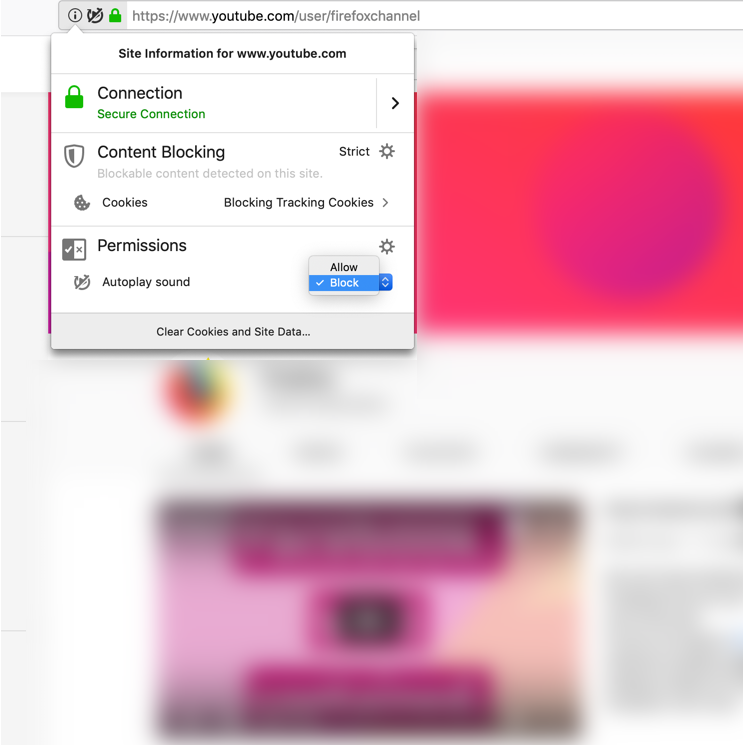
From Permissions, you can choose to allow or block
Do you ever find yourself immersed in an online article, then all of a sudden an image or ad loads from the top of the page and you lose your place. Images or ads load slower than the written content on a page, and without scroll anchoring in place, you’re left bouncing around the page. Today’s release features scroll anchoring. Now, the page remembers where you are so that you aren’t interrupted by slow loading images or ads.
Search is one of the most common activities that people do whenever they go online, so we are always looking for ways to streamline that experience. Today, we’re improving the search experience to make it faster, easier and more convenient by enabling:
For the complete list of what’s new or what we’ve changed, you can review today’s full release notes.
Check out and download the latest version of Firefox Quantum, available here.
![]()
Stop audio and video content from automatically playing, and say goodbye to jumpy pages, interrupted by ad and image loading, with smoother scrolling.
Firefox is made by Mozilla, the not-for-profit champions of a healthy internet.
The post Today’s Firefox Aims to Reduce Your Online Annoyances appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2019/03/19/todays-firefox-aims-to-reduce-your-online-annoyances/
|
|
Mozilla Security Blog: Passwordless Web Authentication Support via Windows Hello |
Firefox 66, being released this week, supports using the Windows Hello feature for Web Authentication on Windows 10, enabling a passwordless experience on the web that is hassle-free and more secure. Firefox has supported Web Authentication for all desktop platforms since version 60, but Windows 10 marks our first platform to support the new FIDO2 “passwordless” capabilities for Web Authentication.

PIN Prompt on Windows 10 2019 April release
As of today, Firefox users on the Windows Insider Program’s fast ring can use any authentication mechanism supported by Windows for websites via Firefox. That includes face or fingerprint biometrics, and a wide range of external security keys via the CTAP2 protocol from FIDO2, as well as existing deployed CTAP1 FIDO U2F-style security keys. Try it out and give us feedback on your experience.
For the rest of Firefox users on Windows 10, the upcoming update this spring will enable this automatically.
Akshay Kumar from Microsoft’s Windows Security Team contributed this support to Firefox. We thank him for making this feature happen, and the Windows team for ensuring that all the Web Authentication features of Windows Hello were available to Firefox users.
For Firefox users running older versions of Windows, Web Authentication will continue to use our Rust-implemented CTAP1 protocol support for U2F-style USB security keys. We will continue work toward providing CTAP2/FIDO2 support on all of our other platforms, including older versions of Windows.
For Firefox ESR users, this Windows Hello support is currently planned for ESR 60.0.7, being released mid-May.
If you haven’t used Web Authentication yet, adoption by major websites is underway. You can try it out at a variety of demo sites: https://webauthn.org/, https://webauthn.io/, https://webauthn.me/, https://webauthndemo.appspot.com/, or learn more about it on MDN.
If you want to try the Windows Hello support in Firefox 66 on Windows 10 before the April 2019 update is released, you can do so via the Windows Insider program. You’ll need to use the “fast” ring of updates.
The post Passwordless Web Authentication Support via Windows Hello appeared first on Mozilla Security Blog.
|
|
Andreas Tolfsen: Update from WebDriver meeting at TPAC |
|
|
Andreas Tolfsen: The case against visibility checks in WebDriver |
|
|






