Mozilla Open Policy & Advocacy Blog: Mozilla weighs in on India’s draft data protection bill |
Yesterday, on July 27th, 2018, the Justice Srikrishna Committee of Experts, set up by the Government of India, made public its final report and the draft of India’s first comprehensive data protection law. We have long argued that the enactment of a baseline data protection law should be a national policy priority for India, and we’re pleased to see India take an important step forward towards enacting real privacy protections.
The legislation is groundbreaking in several respects, codifying principles and enforcement mechanisms that Mozilla has advocated are foundational to a robust data protection framework. But the law is not without loopholes, many of which threaten to dislodge these strong foundations.
Mozilla Chairwoman Mitchell Baker observed: “India’s data protection law will shape the relationship between users and the companies and government entities they entrust with their data. This draft bill is a strong start, but to truly protect the privacy of all Indians, we can’t afford loopholes such as the bill’s broad exceptions for government use of data and data localization requirements. Mozilla will continue to advocate for changes; with this bill, India has the opportunity to be a model to the world.”
As this bill makes its way to law, an open and consultative process is essential. We will continue to advocate to the Government to make necessary changes in the bill.
Top level highlights from the bill include:
Some Particularly Worrying Provisions
The post Mozilla weighs in on India’s draft data protection bill appeared first on Open Policy & Advocacy.
https://blog.mozilla.org/netpolicy/2018/07/27/indian-draft-data-protection-bill/
|
|
K Lars Lohn: Things Gateway - Bonding Philips HUE Lights Together |
|
|
Support.Mozilla.Org: State of Mozilla Support: 2018 Mid-year Update – Part 3 |
We are continuing our series of mid-year posts regarding the state and future of Mozilla Support. If you missed the previous posts, part one and part two are still online. This time we are going to talk a bit more about (Support) Localization and the plans for the second half of the year.
Over the years, localizer activity on the Support site went up and down, influenced by Firefox popularity, new released on different platforms, and general localization needs across Mozilla. Peaking at over 200 people around three years ago, it is now oscillating at 40-50% of that number.
While Mozilla keep continuously shipping new Firefox releases and experimenting with new ideas, the global audience will keep increasing in numbers and languages – and we want to make sure that the site stays relevant and informative to as many users out there as possible.
The Support site has long been overdue to get a facelift that would make it on par with the modern and clean look of mozilla.org. Recently, we have seen the first (preview & github issue) steps towards that.
At the moment, the preview is not fully localized, but once the updated English wording and new layout are finalized, we will be promoting
You could argue that this is only tangentially related to localization, but it may actually have a significant impact on the site’s usability for speakers of different languages. Therefore, reporting any issues found on the non-English versions of the site is very important for a successful visual refresh of support.mozilla.org. We will also keep tracking site usage and interactions by users around the globe to make sure the changes have not negatively impacted site traffic.
With over 700 individual pieces of content in the Knowledge Base at the moment of writing, it is one of the biggest repositories of useful product information around Mozilla – and probably the most useful one for users of Firefox (and not only) around the world.
Changes to Mozilla’s product strategy and line-up have naturally affected the Knowledge Base and its localization profile over time. Experiments or projects become products, products become obsolete, etc. – and the content we present to the users should be displayed accordingly and evolve with the changes.
This means you can expect (or have already seen) some content going away into the archive (we do our best never to delete anything) – and new products or projects popping up as well. One of the bigger near future additions to the Knowledge Base, for example, will be the Pocket support content, at the moment hosted here.
Similarly to products, languages come and go, by popularity. While we do aim to maintain as many languages available as possible, very often the amount of content to be localized across Mozilla is already a big challenge for smaller communities around the world. You can read more about the idea and reasons behind it here. As of the writing of this post:
Bengali
Hindi
Gujarati
Bosnian
Slovak
Arabic
Tamil
Telugu
Albanian
Greek
Thai
Yoruba
Hebrew
Estonian
Croatian
Kazakh
Norwegian
Romanian
Vietnamese
Serbian
Sorbian (Lower/Upper)
Euskara
Gaelic
Lithuanian
Malay
Swahili
At the moment, because of the distributed nature of product development, marketing, and support, almost all of the requests for each of those separate areas come separately and are not reviewed or prioritized as a unified part of internationalization efforts at Mozilla.
This localization “request firehose” may work for separate teams or tools, but definitely does not make it easier for localization coordinators and localizers in distributed communities. Missing a single “source of truth” for localization needs for each bigger release or project introduces confusion, false expectations, and difficulties in organizing local communities around localization sprints.
Optimizing the way localization requests are filed (including new or updated Support content) through a unified process should, in turn, make it easier for localization coordinators to message contributors around the world using a single, reliable channel (for example, the Localization blog). This could also influence the way resources for organizing localization events are requested (making it easier for everyone to track and handle such requests), and have a positive impact on transparency, expectations, and timely content localization.
In short, less should be more. Less noise and confusion = more fun and better results.
Conversely, it may also mean that in some cases, the localization work for the Support site might be contracted through paid localization agencies in order to expedite the process – but we will never close contribution options for Mozillians around the world.
As all localization coordinators around Mozilla are increasingly working together on streamlining the process, we will be announcing smaller and bigger tweaks to the way localization happens at Mozilla.
Other that the points made above, there is quite a lot of the daily and mundane that will be happening, depending on timing, community engagement and developer support. To name a few:
Learning materials for new localizers, global locale style guides, best practices, cool tricks, tweaks to existing tools… and the list can go on. We already have some of these in place, while others still need to be identified, defined, discussed, and experimented with.
Together with the Open Innovation team, we hope to set up an easy to maintain collection of dashboards for the Support site, using Bitergia’s open source software. If the project takes places (pending resource and timing allocation, just like anything else around Mozilla), localization will definitely be a part of it.
Always a hot topic across Mozilla, it is no different for localization. Swag goes only so far (and some of you don’t necessarily like t-shirts or stickers, which we can absolutely understand), so a bit of experimentation and soul-searching on our side may be required to make sure we show how much we appreciate your involvement in all the languages that Mozilla speaks, thanks to you.
That’s it, then (more or less)! Please, stay tuned for more updates from the world of Support and localization – and remember that your work to make Mozilla happen in so many languages does not pass unnoticed. Thank you for being there for the millions of users who can experience the internet in an open source way thanks to you all :)
https://blog.mozilla.org/sumo/2018/07/27/state-of-mozilla-support-2018-mid-year-update-part-3/
|
|
Gregory Szorc: Benefits of Clone Offload on Version Control Hosting |
Back in 2015, I implemented a feature in Mercurial 3.6 that allows
servers to advertise URLs of pre-generated bundle files. When a
compatible client performs a hg clone against a repository leveraging
this feature, it downloads and applies the bundle from a URL then goes
back to the server and performs the equivalent of an hg pull to obtain
the changes to the repository made after the bundle was generated.
On hg.mozilla.org, we've been using this feature since 2015. We host bundles in Amazon S3 and make them available via the CloudFront CDN. We perform IP filtering on the server so clients connecting from AWS IPs are served S3 URLs corresponding to the closest region / S3 bucket where bundles are hosted. Most Firefox build and test automation is run out of EC2 and automatically clones high-volume repositories from an S3 bucket hosted in the same AWS region. (Doing an intra-region transfer is very fast and clones can run at >50 MB/s.) Everyone else clones from a CDN. See our official docs for more.
I last reported on this feature in October 2015. Since then, Bitbucket also deployed this feature in early 2017.
I was reminded of this clone bundles feature this week when kernel.org posted Best way to do linux clones for your CI and that post was making the rounds in my version control circles. tl;dr git.kernel.org apparently suffers high load due to high clone volume against the Linux Git repository and since Git doesn't have an equivalent feature to clone bundles built in to Git itself, they are asking people to perform equivalent functionality to mitigate server load.
(A clone bundles feature has been discussed on the Git mailing list before. I remember finding old discussions when I was doing research for Mercurial's feature in 2015. I'm sure the topic has come up since.)
Anyway, I thought I'd provide an update on just how valuable the clone bundles feature is to Mozilla. In doing so, I hope maintainers of other version control tools see the obvious benefits and consider adopting the feature sooner.
In a typical week, hg.mozilla.org is currently serving ~135 TB of data. The overwhelming majority of this data is related to the Mercurial wire protocol (i.e. not HTML / JSON served from the web interface). Of that ~135 TB, ~5 TB is served from the CDN, ~126 TB is served from S3, and ~4 TB is served from the Mercurial servers themselves. In other words, we're offloading ~97% of bytes served from the Mercurial servers to S3 and the CDN.
If we assume this offloaded ~131 TB is equally distributed throughout the week, this comes out to ~1,732 Mbps on average. In reality, we do most of our load from California's Sunday evenings to early Friday evenings. And load is typically concentrated in the 12 hours when the sun is over Europe and North America (where most of Mozilla's employees are based). So the typical throughput we are offloading is more than 2 Gbps. And at a lower level, automation tends to perform clones soon after a push is made. So load fluctuates significantly throughout the day, corresponding to when pushes are made.
By volume, most of the data being offloaded is for the mozilla-unified Firefox repository. Without clone bundles and without the special stream clone Mercurial feature (which we also leverage via clone bundles), the servers would be generating and sending ~1,588 MB of zstandard level 3 compressed data for each clone of that repository. Each clone would consume ~280s of CPU time on the server. And at ~195,000 clones per month, that would come out to ~309 TB/mo or ~72 TB/week. In CPU time, that would be ~54.6 million CPU-seconds, or ~21 CPU-months. I will leave it as an exercise to the reader to attach a dollar cost to how much it would take to operate this service without clone bundles. But I will say the total AWS bill for our S3 and CDN hosting for this service is under $50 per month. (It is worth noting that intra-region data transfer from S3 to other AWS services is free. And we are definitely taking advantage of that.)
Despite a significant increase in the size of the Firefox repository and clone volume of it since 2015, our servers are still performing less work (in terms of bytes transferred and CPU seconds consumed) than they were in 2015. The ~97% of bytes and millions of CPU seconds offloaded in any given week have given us a lot of breathing room and have saved Mozilla several thousand dollars in hosting costs. The feature has likely helped us avoid many operational incidents due to high server load. It has made Firefox automation faster and more reliable.
Succinctly, Mercurial's clone bundles feature has successfully and largely effortlessly offloaded a ton of load from the hg.mozilla.org Mercurial servers. Other version control tools should implement this feature because it is a game changer for server operators and results in a better client-side experience (eliminates server-side CPU bottleneck and may eliminate network bottleneck due to a geo-local CDN typically being as fast as your Internet pipe). It's a win-win. And a massive win if you are operating at scale.
http://gregoryszorc.com/blog/2018/07/27/benefits-of-clone-offload-on-version-control-hosting
|
|
Cameron Kaiser: NetSpectre: not much of a PowerPC threat either |
The next generation is making Spectre go remote, and while long hypothesized it was never demonstrated until the newest, uh, "advance" called NetSpectre (PDF). The current iteration comes in two forms.
The first and more conventional version is like Spectre in that it relies on CPU cache timing. A victim application would have to have something called a "leak gadget," similar to the one in Spectre where network-facing code processes some network packet with a condition that's usually true and sets a flag based on a data bit of interest in memory. The processor, after enough training by the attacker, then is induced to mispredict, which means the flag is now in the cache even though it never observably changed. This could be done as with the example in the paper, where an attacker sends packets with multiple normal bitstream lengths, training the predictor, and then suddenly sends one with an abnormal or out-of-bound one. The flag isn't actually set, but the misprediction caused it to be loaded into the CPU cache. Later on, the application executes a "transmit gadget" that uses that flag to do a network-observable operation. The flag is in the cache, so the transmit gadget runs just a little bit faster, and the attacker can infer that data bit.
This sounds very slow and error-prone, and it is. In fact, it would be even worse on our slower systems: besides the fact that it presupposes the machine is vulnerable to Spectre in the first place (G3 and 7400 systems don't seem to be), we would generate packets much slower than a modern system, meaning the attacker would have to wait even longer to differentiate a response and the difference between the flag being and not being in the cache is likely to be drowned out by the other code that needs to execute to generate a network response. Looking at the histogram for the ARM core they tested, which is more comparable to the PowerPC than an Intel CPU, there is substantial overlap between the '1' and '0'; if network latency intervenes, it could take literally millions of measurements to extract even a single bit. And that's assuming the attacker knows enough about the innards of your network-facing application (like TenFourFox, or what have you) to even know the memory location they're looking for. Even with that sizeable advantage, even when attacking a far faster computer over a local network, it took 30 minutes for the researchers to exfiltrate just a single byte of data. Under the most optimal conditions for such an attack, a Quad G5 would probably require several times longer; a 7450 would take longer still.
The researchers, however, recognized this and looked for other kinds of network-observable side channels that could be faster to work with than the CPU cache. The vast majority of modern CPUs these days have some sort of SIMD instruction set for working on big chunks of data at once. We have the 128-bit AltiVec (VMX) in Power Mac land on G4s and G5s, for example, and later Power ISA chips like the POWER9 have an extension called VSX; Intel for its part historically offered MMX and the SSE series of instructions all the way up to things like AVX2. AltiVec and VSX are pretty well-designed and reasonably power-efficient extensions but only work on 128 bits of data at once, whereas AVX2 was extended to 256 (AVX-512 even supports 512-bit registers). Intel's larger SIMD implementations require more power to run and the processor actually turns off the circuitry operating on the upper 128 bits of its AVX vector registers when they aren't needed. With that crucial bit of knowledge you can probably write the end of this paragraph already, but turning on the upper 128 bits is not instantaneous and can incur a noticeable penalty on execution if the upper bits aren't already activated. If you can get the processor to speculatively execute an AVX2 instruction operating on the upper bits based on the data bit of interest, you can then infer from how quickly that instruction executed what the data bit was, the execution time itself inferred from a later network-visible operation that also uses the AVX2 upper unit. The AVX2 upper unit cycles on and off with roughly a 1ms latency, an eternity in computing, but it requires very few network measurements to distinguish bits and reduces the time to exfiltrate a byte to around 8 minutes in the paper.
No PowerPC chip used in any Power Mac behaves in this fashion, even with AltiVec instructions. The G3 doesn't have AltiVec (duh), and the AltiVec units in the 7400/G5 (they use similar designs) and the 7450 are always active. AltiVec instructions weren't implemented on "big POWER" until the POWER6, and even for the POWER6 through POWER9, I can't find anything in IBM's technical documentation that says any chip-internal functional unit, whether FPU, LSU, vector unit or otherwise, is dynamically powered down when not in use.
I think we've got bigger things to worry about than this.
http://tenfourfox.blogspot.com/2018/07/netspectre-not-much-of-powerpc-threat.html
|
|
Francois Marier: Recovering from a botched hg histedit on a mercurial bookmark |
If you are in the middle of a failed
Mercurial hg histedit, you can normally
do hg histedit --abort to cancel it, though sometimes you also have to
reach out for hg update -C. This is the equivalent of
git's git rebase --abort and it does what you'd
expect.
However, if you go ahead and finish the history rewriting and only notice
problems later, it's not as straighforward. With git, I'd look into the
reflog
(git reflog) for the previous value of the branch pointer and simply git
reset --hard to that value. Done.
Based on a Stack Overflow answer, I thought I could undo my botched histedit using:
hg unbundle ~/devel/mozilla-unified/.hg/strip-backup/47906774d58d-ae1953e1-backup.hg
but it didn't seem to work. Maybe it doesn't work when using bookmarks.
Here's what I ended up doing to fully revert my botched Mercurial histedit. If you know of a simpler way to do this, feel free to leave a comment.
The first step was to collect all of the commits hashes I needed to restore. Luckily, I had sumitted my patch to Try before changing it and so I was able to look at the pushlog to get all of the commits at once.
If I didn't have that, I could also go to the last bookmark I pushed and click on parent commits until I hit the first one that's not mine. Then I could collect all of the commits using the browser's back button:
For that last one, I had to click on the changeset commit hash link in order to
get the commit hash instead of the name of the bookmark (/rev/hashstore-crash-1434206).
This is what did to export patches for each commit and then re-import them one after the other:
for c in 3c31c543e736 7ddfe5ae2fa6 c04b620136c7 2d1bf04fd155 e194843f5b7a 47906774d58d f6a657bca64f 0d7a4e1c0079 976e25b49758 a1a382f2e773 b1565f3aacdb 3fdd157bb698 b1b041990577 220bf5cd9e2a c927a5205abe ; do hg export $c > ~/$c.patch ; done
hg up ff8505d177b9
hg bookmarks hashstore-crash-1434206-new
for c in 3c31c543e736 7ddfe5ae2fa6 c04b620136c7 2d1bf04fd155 e194843f5b7a 47906774d58d f6a657bca64f 0d7a4e1c0079 976e25b49758 a1a382f2e773 b1565f3aacdb 3fdd157bb698 b1b041990577 220bf5cd9e2a c927a5205abe 4140cd9c67b0 ; do hg import ~/$c.patch ; done
As an aside, if you want to make a copy of a bookmark before you do an hg
histedit, it's not as simple as:
hg up hashstore-crash-1434206
hg bookmarks hashstore-crash-1434206-copy
hg up hashstore-crash-1434206
While that seemed to work at the time, the histedit ended up messing with
both of them.
An alternative that works is to push the bookmark to another machine. That
way if worse comes to worse, you can hg clone from there and hg export
the commits you want to re-import using hg import.
http://feeding.cloud.geek.nz/posts/recovering-from-botched-mercurial-bookmark-histedit/
|
|
The Rust Programming Language Blog: What is Rust 2018? |
Back in March, we announced something new:
This year, we will deliver Rust 2018, marking the first major new edition of Rust since 1.0 (aka Rust 2015).
We will continue to publish releases every six weeks as usual. But we will designate a release in the latter third of the year (Rust 1.29 - 1.31) as Rust 2018. This new ‘edition’ of Rust will be the culmination of feature stabilization throughout the year, and will ship with polished documentation, tooling, and libraries that tie in to those features.
Now that some time has passed, we wanted to share more about what this actually means for Rust and Rust developers.
One of the key questions facing language developers is “how do you manage change over time”? How does that work for your users? We believe quite strongly that language stability is of utmost importance. A language is the foundation that you build your application on top of, and you cannot build reliable, long-living things on a foundation of sand. The very second post on our blog, way back in October of 2014, was “Stability as a Deliverable”. This laid out our plans for the six week release schedule that we still follow to this day. It also described how stability was important:
It’s important to be clear about what we mean by stable. We don’t mean that Rust will stop evolving. We will release new versions of Rust on a regular, frequent basis, and we hope that people will upgrade just as regularly. But for that to happen, those upgrades need to be painless.
We put in a lot of work to make upgrades painless; for example, we run a tool (called “crater”) before each Rust release that downloads every package on crates.io and attempts to build their code and run their tests. We have a strong culture of testing, and we use tooling to ensure that every single pull request is tested on every platform. While we still believe that the six-week process is a fantastic engineering strategy, it has some flaws.
Increasing the number of releases means that each release is smaller. That’s the point! From an engineering perspective, this is great. But from a user-facing perspective, it’s harder to keep track of what’s going on in Rust unless you pay close attention every six weeks. And for those of us who do pay such attention, it’s easy to lose sight of the big picture. Rust has come a long way in the last three years! Finally, for people who have tried Rust and stopped using it for whatever reason, it’s hard to know if the concerns have been addressed: they’d have to pay attention every six weeks, which is not something that is likely to happen.
Especially in a language with static types, almost any release can contain something that breaks someone’s code. Rust’s RFC 1105 lays out what kinds of changes we can make when incrementing a major, minor, or patch version of the language. However, the concept of “2.0” is extremely overloaded in the minds of developers. 2.0 is major breaking change. Time to throw everything out and start again. As such, we are very wary of releasing a Rust 2.0. There are some small changes that would be nice to make without needing to bump to 2.0, however. For example, the addition of a new keyword is a breaking change. But sometimes, new features require a new keyword to work properly. In many ways, Rust is about taking tradeoffs and bending the curve. Can we have our cake and eat it too?
The release of Rust 1.31.0 on December 6th will be the first release of “Rust 2018.” This marks a culmination of the last three years of Rust’s development, and brings it together in one neat package. For example, there will be a 2018 edition of the book that incorporates features stabilized since the print edition was considered finalized.
You’ll be able to put edition = '2018' into your Cargo.toml, and cargo
new will add it by default for new projects. At first, this will unlock
some new features that are not possible without it, and eventually, it will
enable some new lints that nudge you towards new idioms. You can also choose
'2015', and if you don’t have an edition key at all, it will default to
this value. These projects will continue on as before. We’ll be shipping a
tool, that helps you automatically upgrade your code to use these new features
and idioms. Running cargo fix will get your code ready in an automated
fashion.
From one perspective, editions are mostly about that cohesive package: they’re
about celebrating what we’ve accomplished, and telling the world about it. From
another, editions are a way for us to make “breaking” changes without breaking
your code. For example, try will become a keyword in Rust 2018. We can’t
make that change in Rust 2015, as it may break code that uses it as a variable
name. But since you opt-in to Rust 2018, we can. We can also turn some warnings
into hard errors. But these changes are extremely limited; without getting too
deep into the technical details, editions can only change surface-level
features; the core of Rust is still the same.
It goes even further than that: these two universes are compatible with one another. We are quite sensitive to the issues in other language ecosystems, where new code and old code can’t interoperate. Making sure that this worked well was a key aspect of the design of editions. In some sense, editions are following in the steps of Java and C++, two languages that are known for their stability stories.
In short, the Rust compiler will know how to compile both editions of code.
This is similar to how javac can compile both Java 9 and Java 10, or how
gcc and clang support both C++14 and C++17. Additionally, each compiler
will understand how to link both kinds of code together. This means that if
you’re using Rust 2018, you can use dependencies that use Rust 2015 with zero
problems. If you’re sticking with Rust 2015, you can use libraries that use
Rust 2018. It all works together. This lets people who want to use new things
start immediately, while others that want to take it slower can upgrade on
their own time schedule.
Beyond that, it’s also important to mention that this release will be the initial release of Rust 2018; in some sense, it’s the start, not the end. We haven’t formally committed to a schedule for editions, but it’s likely that the next one will be Rust 2021. We’ll continue to add features to Rust 2018 after its release, just like we continued to add features to Rust after the Rust 1.0 release.
It’s also important to note that Rust 2015 is not frozen. Anything that does not require being a part of Rust 2018 will work on Rust 2015 as well. This is due to the way editions work; given the small nature of possible changes, the compiler uses the same internal representation for all editions.
The Rust project currently only supports the most recent version of the stable compiler. Some have wondered if the concept of editions ties into some form of longer support. It does not, however, we’ve been talking about introducing some sort of LTS policy, and may do so in the future.
We’ll be doing several preview releases of Rust 2018. The most adventurous Rust users are already giving it a try on nightly; once we get feedback from them and do some polishing, we’ll announce a beta that’s ready for more wide usage for you to try here on the blog.
https://blog.rust-lang.org/2018/07/27/what-is-rust-2018.html
|
|
Mozilla Open Policy & Advocacy Blog: Indian telecom regulator recommends data protection norms for the internet |
The Telecom Regulatory Authority of India launched a new salvo this past week into the ongoing debate on the shape of the country’s first data protection law, with the release of their recommendations on data privacy in the telecom sector. While TRAI makes many recommendations that strengthen user rights, they also propose to extend the telecom regulatory framework to “all entities in the digital ecosystem”, a change that would result in significant harm for users and the internet ecosystem. TRAI argues that until India has a comprehensive data protection law, the licence conditions that apply to telecom companies must apply to “telecom service providers, devices, operating systems, browsers, applications etc”. We respectfully disagree with TRAIs claim that this framework is “fairly robust” in protecting user privacy. The license terms are not only an awkward fit in the context of non-telecom companies, but several conditions, like those relating to data localization, encryption, and law enforcement access, are themselves in need of urgent reform.
TRAI’s recommendations are just one of the many attempts by Indian regulators to fill the void left by the repeated delays in the release of the Justice Srikrishna Committee bill — the Committee established nearly a year ago by the Indian Ministry of Electronics and Information Technology to write the country’s first data protection law. Other regulators getting into the fight include the Reserve Bank of India (RBI), which made the controversial announcement requiring all financial data to be localized in India, and the Health Ministry, which has proposed its own health data privacy bill. Sectoral regulation can have many benefits under certain circumstances. But as regulators grow impatient with the delays in developing a comprehensive data protection framework, India risks splintering into problematic sectoral regulation that both expands these regulators’ mandates and provides insufficient protections for users.
So what does TRAI actually say?
Applying telecom license conditions to the entire “digital ecosystem”: Making a bad problem worse
TRAI Recommendation 3.1.b reads
“Till such time a general data protection law is notified by the Government, the existing Rules/ License conditions applicable to TSPs for protection of users’ privacy be made applicable to all the entities in the digital ecosystem”
Steps in the right direction: user rights, meaningful choice, breach notifications
Finally, TRAI also recommends the “Electronic Consent Framework” developed by the Ministry of Electronics & IT as a model technical solution to digitise the giving and revocation of consent as well as data transfers between entities. While the goal of empowering users is a noble one, before jumping to technical solutions, fundamental protections for users must be enshrined in law.
As Mozilla has long argued, India requires a comprehensive privacy and data protection law, grounded in individual rights and following the high standard set by the Puttaswamy judgment. Patchwork sectoral laws in the absence of a comprehensive data protection law are too weak a foundation for the protection of the fundamental right to privacy.
The post Indian telecom regulator recommends data protection norms for the internet appeared first on Open Policy & Advocacy.
https://blog.mozilla.org/netpolicy/2018/07/26/indian-telecom-regulator-data-protection/
|
|
Mozilla Addons Blog: Collections and User Profiles have a new look |
As part of the larger redesign of addons.mozilla.org (AMO), the user profile and collections pages just got an overhaul. They now match the new style of the rest of the site, but there are also some functional changes you might be interested in.
Collections let you save and share lists of add-on listings on AMO. Lots of people use them as a way to bookmark add-ons they want to get back to. They can even act as a sort of backup of what they have installed on their profile. Others create collections to share them online.
Here’s how they look after the update:
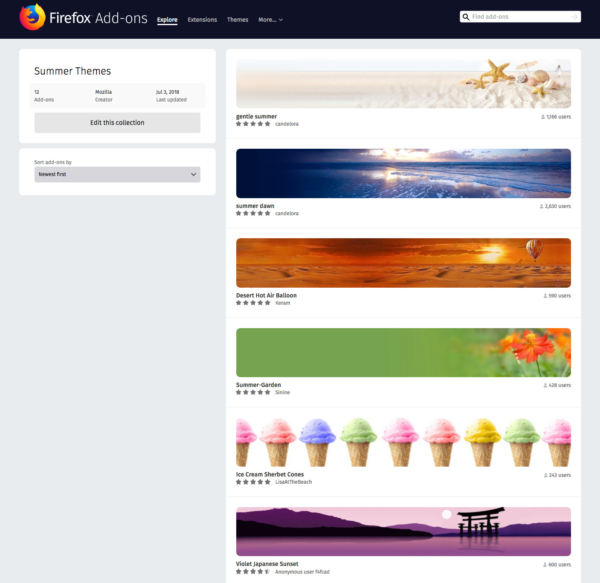
Collections were initially created as a social feature. This included features like voting, following, and multiple contributors for a single collection. However, these features weren’t used much by the majority of our users, and have become a maintenance burden. Because of this, we decided to remove these secondary features.
Another big change is that it won’t be possible to browse and search through collections on the site. If you want to share any of your collections, you can use their URL and post them anywhere on the web. We’re making this change because they have become a common vector for spam. This change shouldn’t disrupt how most people use them at present.
User profiles also got a style refresh:
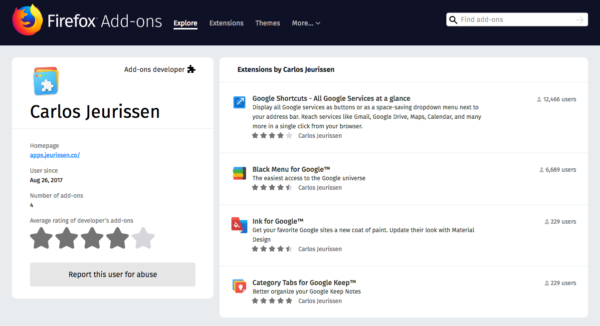
The main difference is that, on the new site, only developer profiles are public. If you’re not an add-on developer, you can still access your own profile page, but other people can’t. Like with collections, this is a mitigation against spam. The main use for profile pages is to find other add-ons created by a developer, so that’s why those profiles will remain public.
Collections and user profiles were the last big features to move to the new design. There are still a number of small features that need to be ported over, and they will be handled in the next month or two. We expect to shut down the old site next quarter, so if you switched to the old design early in the migration process, this is a good time to give the new design another try.
The post Collections and User Profiles have a new look appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2018/07/26/collections-user-profiles-new-look/
|
|
Rabimba: Immersive Technology Conference at Houston |


https://blog.rabimba.com/2018/07/immersive-technology-conference-at.html
|
|
Andy McKay: Tesla Model 3 |
About a month ago we got our Tesla Model 3. This is a rambling post about it.
Personally I don't mind spending money on some things, but I absolutely hate spending money on depreciating assets. Since I'm lucky enough to have money to save, I feel it should be in boring assets that make a solid return every year.
I've liked looking at fast and expensive cars, but when it comes to actually spending lots of money on them, I've always thought its a terrible idea. I've wanted a Porsche forever, but I've never wanted to spend the money on one. We've gone to buy cars and I've come away feeling grumpy and miserable that I've spent that much money on something that will depreciate.
And then along came Tesla. Sure Elon Musk and Tesla have a few problems at the moment, but here is a person who is actually trying to do something about the fact that our planet is burning up. This is a man on a mission to do good.
This is a company that released the Model S, a car so revolutionary that it broke Consumer Reports scoring. A car that has taken over the luxury model class. We test drove a Model S and it was amazing. Everything we drove after that felt like it was ancient technology. But there's no way in hell I'd spend that kind of money on a Model S.
Then along came the Model 3 and we put our refundable deposit down predicting we'd need a new car eventually. And waited and waited. Finally our spot came up and we had to buy the premium version which sucked. It meant more money and that made me grumpy. We thought about it, I got more grumpy but eventually we went for it.
There's a few reasons why. The time is right for electric cars. The infrastructure is in place. Most car manufacturers, spurred by Tesla, are producing electric cars. There's a tipping point and its happening over the next few years. In BC over 90% of electricity comes from hydro electricity. A car is rarely a green choice in terms of the plastic, metal and other materials used, the manufacturing process, the amount of road infrastructure dedicated to it and so on. But this is about as good as a car gets.
So how is it?

Amazeballs. I irrationally love this thing. I'm still making excuses to go places so I can drive the car.
The car is minimalist on the the inside and I like it. So many cars have a billion buttons and knobs for every function. Everything apart from lights, indicators and wipers are controlled through the tablet mounted in the middle. But most of those are automatic anyway, so hey why bother. Sitting in my Toyota now feels fussy and complicated.

It goes fast. Really fast. You put your foot down and it just goes and keep going. Silently and with power. It accelerates faster than that Porsche Boxster I wanted. And thats more than fast enough for me thank you. It's got a 500km range and we barely do that in a few weeks around town. Because of the huge battery in the bottom it goes round corners amazingly well. Everytime we get in it, its like driving a sports car. A quiet and amazing sports car.
For a car this price, I wanted a few more things like an automatically closing and opening trunk and front trunk. But then you've got other things like a great tablet as a dashboard that's fast and responsive and helpful. When you are on the phone its loud and clear. It's got full time LTE for traffic routing. I could go on and on. And no we didn't get autopilot, that is scary.
This feels like a car from the future that doesn't destroy the environment. Driving it is amazing and I still love it. Way more than I should.
Oh and my other favourite toy, my Cerv'elo S3, fits perfectly in the boot.
If you plan on buying one, here's my affiliate code.
|
|
Marco Zehe |
I'm totally aware of how meta this is*, but nevertheless: Let's start a funny experiment of assembling a list of webmention capable websites and blogs (What is this anyway?). I know the following from my filter bubble: webrocker.de / @webrocker matthiasott.com / @m_ott boffosocko.com / @ChrisAldrich...
|
|
Marco Zehe: Firefox 63 will cut subtrees marked with aria-hidden |
aria-hidden="true" will have their sub trees completely removed from the accessibility tree.
The aria-hidden attribute can be set on an element to mark it and all of its descendants as hidden from accessibility, and therefore any assistive technology, while at the same time retaining visible status on the screen itself. In this form, it is different from CSS properties such as display:none; and visibility:hidden;, which truly hide content from both the seeing eye as well as the accessibility programming interfaces.
As noted in the ARIA 1.1 specification, extreme caution should be used when using this attribute. It may hide content from users of assistive technologies such as speech recognition, switch control, or magnifier users that they actually need to access. For more information on the different way of hiding things, I recommend this read by the Paciello Group.
Both Chrome and Safari have traditionally always unconditionally cut the element marked with aria-hidden=”true” from the accessibility tree on all platforms. But as soon as a focusable element was within that tree, this means that there is no accessible object associated with that focusable element, so the screen reader in use would not speak anything. And despite many criticisms and discussions over the years, this has never been addressed other than the above mentioned warnings in the specification.
Up to and including Firefox 62, the Gecko engine, however, advertised for a different model where aria-hidden content was merely marked as hidden, but still included in the accessibility tree. Assistive technologies could then decide whether to expose, and interact with, such elements or not. For us, this solved the problems that focusable aria-hidden elements were still speaking when focus was set to them. They also remained accessible to magnifiers and other assistive technologies.
However, this approach did not gain any traction since it was implemented, and it caused more confusion with web developers than it solved problems. So, in the spirit of better interoperability among browsers, we heavy-heartedly decided that it was time to fully go with the specification as it stands today and finally cut the aria-hidden tree in Firefox 63 and later. This means that stuff marked with aria-hidden=”true” will now fully disappear from the accessibility tree, also reflected in our Accessibility Inspector, as it does in other browsers.
Despite of this, some questions remain, like the disconnect between user expectation, gained from what’s visible on the screen, and what is exposed via the accessibility tree. Especially users of magnifiers, speech recognition products, and switch control users could be adversely affected by the wrong use of aria-hidden if such elements that are hidden acutually comprise operable controls. The same is true for keyboard focus.
But for certain situations, such as marking a whole section as “not available” or “inert” as a modal popup is opened, for example, there is currently no solution available other than aria-hidden, to properly hide content that is, for a given situation, considered to be non-operable. As long as elements such as the dialog element aren’t fully supported on all browsers (Firefox included), or the specification for the inert attribute is not solid enough to be considered implementable, the beast that is aria-hidden is the only one we have to wrestle such situations.
We’re not happy, but at least now, we’re consistent.
https://www.marcozehe.de/2018/07/24/firefox-63-will-cut-subtrees-marked-with-aria-hidden/
|
|
QMO: Firefox 62 Beta 14 Testday, August 3rd |
Greetings Mozillians!
We are happy to let you know that Friday, August 3rd, we are organizing Firefox 62 Beta 14 Testday. We’ll be focusing our testing on Pocket, Customization and Bookmarks features. We will also have fixed bugs verification and unconfirmed bugs triage ongoing.
Check out the detailed instructions via this etherpad.
No previous testing experience is required, so feel free to join us on #qa IRC channel where our moderators will offer you guidance and answer your questions.
Join us and help us make Firefox better!
See you on Friday!
https://quality.mozilla.org/2018/07/firefox-62-beta-14-testday-august-3rd/
|
|
Nicholas Nethercote: Ad Hoc Profiling |
I have used a variety of profiling tools over the years, including several I wrote myself.
But there is one profiling tool I have used more than any other. It is capable of providing invaluable, domain-specific profiling data of a kind not obtainable by any general-purpose profiler.
It’s a simple text processor implemented in a few dozen lines of code. I use it in combination with logging print statements in the programs I am profiling. No joke.
The tool is called counts, and it tallies line frequencies within text files, like an improved version of the Unix command chain sort | uniq -c. For example, given the following input.
a 1 b 2 b 2 c 3 c 3 c 3 d 4 d 4 d 4 d 4
counts produces the following output.
10 counts: ( 1) 4 (40.0%, 40.0%): d 4 ( 2) 3 (30.0%, 70.0%): c 3 ( 3) 2 (20.0%, 90.0%): b 2 ( 4) 1 (10.0%,100.0%): a 1
It gives a total line count, and shows all the unique lines, ordered by frequency, with individual and cumulative percentages.
Alternatively, when invoked with the -w flag, it assigns each line a weight, determined by the last integer that appears on the line (or 1 if there is no such integer). On the same input, counts -w produces the following output.
30 counts: ( 1) 16 (53.3%, 53.3%): d 4 ( 2) 9 (30.0%, 83.3%): c 3 ( 3) 4 (13.3%, 96.7%): b 2 ( 4) 1 ( 3.3%,100.0%): a 1
The total and per-line counts are now weighted; the output incorporates both frequency and a measure of magnitude.
That’s it. That’s all counts does. I originally implemented it in 48 lines of Perl, then later rewrote it as 48 lines of Python, and then later again rewrote it as 71 lines of Rust.
In terms of benefit-to-effort ratio, it is by far the best code I have ever written.
counts in actionAs an example, I added print statements to Firefox’s heap allocator so it prints a line for every allocation that shows its category, requested size, and actual size. A short run of Firefox with this instrumentation produced a 77 MB file containing 5.27 million lines. counts produced the following output for this file.
5270459 counts: ( 1) 576937 (10.9%, 10.9%): small 32 (32) ( 2) 546618 (10.4%, 21.3%): small 24 (32) ( 3) 492358 ( 9.3%, 30.7%): small 64 (64) ( 4) 321517 ( 6.1%, 36.8%): small 16 (16) ( 5) 288327 ( 5.5%, 42.2%): small 128 (128) ( 6) 251023 ( 4.8%, 47.0%): small 512 (512) ( 7) 191818 ( 3.6%, 50.6%): small 48 (48) ( 8) 164846 ( 3.1%, 53.8%): small 256 (256) ( 9) 162634 ( 3.1%, 56.8%): small 8 (8) ( 10) 146220 ( 2.8%, 59.6%): small 40 (48) ( 11) 111528 ( 2.1%, 61.7%): small 72 (80) ( 12) 94332 ( 1.8%, 63.5%): small 4 (8) ( 13) 91727 ( 1.7%, 65.3%): small 56 (64) ( 14) 78092 ( 1.5%, 66.7%): small 168 (176) ( 15) 64829 ( 1.2%, 68.0%): small 96 (96) ( 16) 60394 ( 1.1%, 69.1%): small 88 (96) ( 17) 58414 ( 1.1%, 70.2%): small 80 (80) ( 18) 53193 ( 1.0%, 71.2%): large 4096 (4096) ( 19) 51623 ( 1.0%, 72.2%): small 1024 (1024) ( 20) 45979 ( 0.9%, 73.1%): small 2048 (2048)
Unsurprisingly, small allocations dominate. But what happens if we weight each entry by its size? counts -w produced the following output.
2554515775 counts: ( 1) 501481472 (19.6%, 19.6%): large 32768 (32768) ( 2) 217878528 ( 8.5%, 28.2%): large 4096 (4096) ( 3) 156762112 ( 6.1%, 34.3%): large 65536 (65536) ( 4) 133554176 ( 5.2%, 39.5%): large 8192 (8192) ( 5) 128523776 ( 5.0%, 44.6%): small 512 (512) ( 6) 96550912 ( 3.8%, 48.3%): large 3072 (4096) ( 7) 94164992 ( 3.7%, 52.0%): small 2048 (2048) ( 8) 52861952 ( 2.1%, 54.1%): small 1024 (1024) ( 9) 44564480 ( 1.7%, 55.8%): large 262144 (262144) ( 10) 42200576 ( 1.7%, 57.5%): small 256 (256) ( 11) 41926656 ( 1.6%, 59.1%): large 16384 (16384) ( 12) 39976960 ( 1.6%, 60.7%): large 131072 (131072) ( 13) 38928384 ( 1.5%, 62.2%): huge 4864000 (4866048) ( 14) 37748736 ( 1.5%, 63.7%): huge 2097152 (2097152) ( 15) 36905856 ( 1.4%, 65.1%): small 128 (128) ( 16) 31510912 ( 1.2%, 66.4%): small 64 (64) ( 17) 24805376 ( 1.0%, 67.3%): huge 3097600 (3100672) ( 18) 23068672 ( 0.9%, 68.2%): huge 1048576 (1048576) ( 19) 22020096 ( 0.9%, 69.1%): large 524288 (524288) ( 20) 18980864 ( 0.7%, 69.9%): large 5432 (8192)
This shows that the cumulative count of allocated bytes (2.55GB) is dominated by a mixture of larger allocation sizes.
This example gives just a taste of what counts can do.
(An aside: in both cases it’s good the see there isn’t much slop, i.e. the difference between the requested sizes and actual sizes are mostly 0. That 5432 entry at the bottom of the second table is curious, though.)
This technique is often useful when you already know something — e.g. a general-purpose profiler showed that a particular function is hot — but you want to know more.
Then use counts to aggregate the data. Often this domain-specific data is critical to fully optimize hot code.
Print statements are an admittedly crude way to get this kind of information, profligate with I/O and disk space. In many cases you could do it in a way that uses machine resources much more efficiently, e.g. by creating a small table data structure in the code to track frequencies, and then printing that table at program termination.
But that would require:
That is a pain, especially in a large program you don’t fully understand.
Alternatively, sometimes you want information that a general-purpose profiler could give you, but running that profiler on your program is a hassle because the program you want to profile is actually layered under something else, and setting things up properly takes effort.
In contrast, inserting print statements is trivial. Any measurement can be set up in no time at all. (Recompiling is often the slowest part of the process.) This encourages experimentation. You can also kill a running program at any point with no loss of profiling data.
Don’t feel guilty about wasting machine resources; this is temporary code. You might sometimes end up with output files that are gigabytes in size. But counts is fast because it’s so simple… and the Rust version is 3–4x faster than the Python version, which is nice. Let the machine do the work for you. (It does help if you have a machine with an SSD.)
For a long time I have, in my own mind, used the term ad hoc profiling to describe this combination of logging print statements and frequency-based post-processing. Wikipedia defines “ad hoc” as follows.
In English, it generally signifies a solution designed for a specific problem or task, non-generalizable, and not intended to be able to be adapted to other purposes
The process of writing custom code to collect this kind of profiling data — in the manner I disparaged in the previous section — truly matches this definition of “ad hoc”.
But counts is valuable specifically makes this type of custom profiling less ad hoc and more repeatable. I should arguably call it “generalized ad hoc profiling” or “not so ad hoc profiling”… but those names don’t have quite the same ring to them.
Use unbuffered output for the print statements. In C and C++ code, use fprintf(stderr, ...). In Rust code use eprintln!.
Pipe the stderr output to file, e.g. firefox 2> log.
Sometimes programs print other lines of output to stderr that should be ignored by counts. (Especially if they include integer IDs that counts -w would interpret as weights!) Prepend all logging lines with a short identifier, and then use grep $ID log | counts to ignore the other lines. If you use more than one prefix, you can grep for each prefix individually or all together.
Occasionally output lines get munged together when multiple print statements are present. Because there are typically many lines of output, having a few garbage ones almost never matters.
It’s often useful to use both counts and counts -w on the same log file; each one gives different insights into the data.
To find which call sites of a function are hot, you can instrument the call sites directly. But it’s easy to miss one, and the same print statements need to be repeated multiple times. An alternative is to add an extra string or integer argument to the function, pass in a unique value from each call site, and then print that value within the function.
It’s occasionally useful to look at the raw logs as well as the output of counts, because the sequence of output lines can be informative. For example, I recently diagnosed an occurrences of quadratic behaviour in the Rust compiler by seeing that a loop iterated 1, 2, 3, …, 9000+ times.
counts is available here.
I use counts to do ad hoc profiling all the time. It’s the first tool I reach for any time I have a question about code execution patterns. I have used it extensively for every bout of major performance work I have done in the past few years, as well as in plenty of other circumstances. I even built direct support for it into rustc-perf, the Rust compiler’s benchmark suite, via the profile eprintln subcommand. Give it a try!
https://blog.mozilla.org/nnethercote/2018/07/24/ad-hoc-profiling/
|
|
Marco Zehe: Sara Soueidan on designing a switch control |
It was important for me to make sure this demo is accessible even if it’s just a quick proof of concept for a talk. First of all, because the code for the demo will be public, so I have a bigger responsibility for making sure it’s accessible, because I wouldn’t want to spread any inaccessible code around, especially if there’s a chance people might be using it somewhere else.
Another reason I wanted this to be good is that I’ll probably want to reuse it for other components for my upcoming front-end components workshop.
https://www.marcozehe.de/2018/07/23/sara-soueidan-on-designing-a-switch-control/
|
|
The Servo Blog: These Months In Servo 112 |
In the last few months (whoops!), we merged 498 PRs in the Servo organization’s repositories. It should be easier to return to a regular publishing schedule now that we’re caught up!
Our roadmap is available online, including the overall plans for 2018. It has been updated to account for Servo’s new role in Mozilla’s mixed reality team.
This week’s status updates are here.
FileReaderSync API for web workers.beforeunload event when navigating a web page.adb binary in the path when making android builds.MutationObserver.border-image-outset CSS property.getParameter values.std::simd module.window.close to better match the specification.getUniform API.smallvec crate.Interested in helping build a web browser? Take a look at our curated list of issues that are good for new contributors!
|
|
Mozilla VR Blog: This Week in Mixed Reality: Issue 13 |

This week we focused on fixing bugs and delivering a seamless experience across our three areas: browsers, social, and the content ecosystem.
We spent this week improving performance and fixing bugs on Firefox Reality:
We added a bunch of new features on Hubs by Mozilla:
Another coming soon for #MozillaHubs... @mozillareality @aframevr #threejs pic.twitter.com/ttUOUsyEou
— Kevin Lee (@infinite_lee) July 13, 2018
Interested in joining our public Friday stand ups? For more details, join our public WebVR Slack #social channel
Found a critical bug on the Unity WebVR exporter? File it in our public GitHub repo or let us know on the public WebVR Slack #unity channel and as always, join us in our discussion!
Interested in learning more about what we're up to?
Check out the Mixed Reality team update from Josh Marinacci here on Youtube.
Stick around next week for more new features and improvements!
|
|







