Robert O'Callahan: Welcoming Richard Dawkins |
Richard Dawkins wants New Zealand to invite Trump/Brexit-refugee scientists to move here to create "the Athens of the modern world".
I appreciate the compliment he pays my country (though, to be honest, I don't know why he singled us out). I would be delighted to see that vision happen, but in reality it's not going to. Every US election the rhetoric ratchets up and people promise to move here, but very very few of them follow through. Even Dawkins acknowledges it's a pipe-dream. This particular dream is inconceivable because "the Athens of the modern world" would need a gigantic amount of steady government funding for research, and that's not going to happen here.
To be honest it's a little bit frustrating to keep hearing people talk about moving to New Zealand without following through ... it feels like being treated more as a rhetorical device than a real place and people. That said, I personally would be delighted to welcome any science/technology people who really want to move here, and New Zealand's immigration system makes that relatively easy. I'd be especially delighted for Richard Dawkins to follow his own lead.
http://robert.ocallahan.org/2016/11/richard-dawkins-wants-new-zealand-to.html
|
|
Support.Mozilla.Org: What’s Up with SUMO – 10th November |
Greetings, SUMO Nation!
How have you been? Many changes around and we haven’t been slacking either – we are getting closer to the soft launch of the new community platform (happening next week), so be there when it happens :-) More details below…
If you just joined us, don’t hesitate – come over and say “hi” in the forums!
We salute you!
So, next week is (soft) migration week! Get ready to kick the tires of our new ride ;-) We’re all looking forward to a new start there – but with all of you, the best friends we could imagine to take on this adventure together with us. TTFN!
https://blog.mozilla.org/sumo/2016/11/10/whats-up-with-sumo-10th-november/
|
|
Air Mozilla: Connected Devices Weekly Program Update, 10 Nov 2016 |
 Weekly project updates from the Mozilla Connected Devices team.
Weekly project updates from the Mozilla Connected Devices team.
https://air.mozilla.org/connected-devices-weekly-program-update-20161110/
|
|
Christian Heilmann: Decoded Chats – fourth edition featuring Sarah Drasner on SVG |
At SmashingConf Freiburg I took some time to interview Sarah Drasner on SVG.
In this interview we covered what SVG can bring, how to use it sensibly and what pitfalls to avoid.
You can see the video and get the audio recording of our chat over at the Decoded blog:

Sarah is a dear friend and a lovely person and knows a lot about animation and SVG.
Here are the questions we covered:
|
|
Yunier Jos'e Sosa V'azquez: Firefox nunca m'as pedir'a repetidamente contrase~nas |
Desde hace algunos a~nos, todos los que usamos servidores proxy para acceder a Internet mediante Firefox, de una forma u otra alguna vez hemos tenido problemas con la autenticaci'on. Molestas ventanas emergentes pidiendo el usuario y contrase~na saltaban cuando menos te lo imaginabas, y, aunque la p'agina about:config nos permite llevar el nivel de configuraci'on del navegador al m'aximo, estos “trucos” no funcionaban para nada.
Despu'es de esperar un avance palpable en torno a este problema, hace pocos d'ias en Bugzilla actualizaron el estado de los bugs relacionados a RESOLVED FIXED y una agradable sorpresa me he llevado al probar varias veces y comprobar que funciona perfectamente.
Desde aqu'i llegue nuestro m'as sincero agradecimiento a Honza Bambas, Gary Lockyer, Patrick McManus y a todas las personas involucradas que de una forma u otra ayudaron a solucionar este bug.
Este parche se puede encontrar en el canal Nighlty (actualmente 52), invito a todos los interesados a descargar y probar esta versi'on para encontrar posibles errores antes de ser liberada en el canal Release (planificado para marzo de 2017).
Si te ha gustado esta noticia, d'ejanos saber tu opini'on en un comentario ;-).
https://firefoxmania.uci.cu/firefox-no-pedira-nunca-mas-repetidamente-contrasenas/
|
|
Air Mozilla: Reps Weekly Meeting Nov. 10, 2016 |
 This is a weekly call with some of the Reps to discuss all matters about/affecting Reps and invite Reps to share their work with everyone.
This is a weekly call with some of the Reps to discuss all matters about/affecting Reps and invite Reps to share their work with everyone.
|
|
Mozilla Reps Community: Rep of the Month – October 2016 |
Hossain al Ikram is a passionate contributor from Bangladesh community. He is frontrunner for QA community from past two years and has been setting examples of remarkable leadership and value contribution under several functional areas. Ikram has shown great potential and he is proving his mettle at every instance.

He is actively mentoring people from different countries for QA initiative, He recently helped Indian community in setting up QA team. He also organized MozActivate campaign in Bangladesh. Check some examples QA events from Rajshahi, Sylhet, Chittagong , mentoring in Varenda or mentoring in Rajshahi. Also he started a ToT for WebCompat with more editions in November. You can read about his awesome work on his website.
Geraldo has been one of the most active members in Brazilian community over the last 3 months. Helping to coordinate Mozilla presence at FISL (one of the biggest OpenSource events in Brazil), engaging with the community, running events like Sao Paulo workday , or Latinoware, and even assisting to MozFest!

He is a very engaged mozillian, that also helps run events for Webcompat and SUMO hackatons. This November, you will see Geraldo doing more of his stuff in the upcoming events, promoting Mozilla mission, being an awesome Mozilla Club member, and spreading some #mozlove. Be sure to check his Medium account for more news about his work!
Please join us in congratulating them as Reps of the Month for October 2016!
https://blog.mozilla.org/mozillareps/2016/11/10/rep-of-the-month-october-2016/
|
|
Chris H-C: Data Science is Hard – Case Study: Latency of Firefox Crash Rates |
Firefox crashes sometimes. This bothers users, so a large amount of time, money, and developer effort is devoted to keep it from happening.
That’s why I like that image of Firefox Aurora’s crash rate from my post about Firefox’s release model. It clearly demonstrates the result of those efforts to reduce crash events:
So how do we measure crashes?
That picture I like so much comes from this dashboard I’m developing, and uses a very specific measure of both what a crash is, and what we normalize it by so we can use it as a measure of Firefox’s quality.
Specifically, we count the number of times Firefox or the web page content disappears from the user’s view without warning. Unfortunately, this simple count of crash events doesn’t give us a full picture of Firefox’s quality, unless you think Firefox is miraculously 30% less crashy on weekends:
So we need to normalize it based on some measure of how much Firefox is being used. We choose to normalize it by thousands of “usage hours” where a usage hour is one hour Firefox was open and running for a user without crashing.
Unfortunately, this choice of crashes per thousand usage hours as our metric, and how we collect data to support it, has its problems. Most significant amongst these problems is the delay between when a new build is released and when this measure can tell you if it is a good build or not.
Crashes tend to come in quickly. Generally speaking, when a user’s Firefox disappears out from under them, they are quick to restart it. This means this new Firefox instance is able to send us information about that crash usually within minutes of it happening. So for now, we can ignore the delay between a crash happening and our servers being told about it.
The second part is harder: when should users tell us that everything is fine?
We can introduce code into Firefox that would tell us every minute that nothing bad happened… but could you imagine the bandwidth costs? Even every hour might be too often. Presently we record this information when the user closes their browser (or if the user doesn’t close their browser, at the user’s local midnight).
The difference between the user experiencing an hour of un-crashing Firefox and that data being recorded is recording delay. This tends to not exceed 24 hours.
If the user shuts down their browser for the day, there isn’t an active Firefox instance to send us the data for collection. This means we have to wait for the next time the user starts up Firefox to send us their “usage hours” number. If this was a Friday’s record, it could easily take until Monday to be sent.
The difference between the data being recorded and the data being sent is the submission delay. This can take an arbitrary length of time, but we tend to see a decent chunk of the data within two days’ time.
This data is being sent in throughout each and every day. Somewhere at this very moment (or very soon) a user is starting up Firefox and that Firefox will send us some Telemetry. We have the facilities to calculate at any given time the usage hours and the crash numbers for each and every part of each and every day… but this would be a wasteful approach. Instead, a scheduled task performs an aggregation of crash figures and usage hour records per day. This happens once per day and the result is put in the CrashAggregates dataset.
The difference between a crash or usage hour record being submitted and it being present in this daily derived dataset is aggregation delay. This can be anywhere from 0 to 23 hours.
This dataset is stored in one format (parquet), but queried in another (prestodb fronted by re:dash). This migration task is performed once per day some time after the dataset is derived.
The difference between the aggregate dataset being derived and its appearance in the query interface is migration delay. This is roughly an hour or two.
Many queries run against this dataset and are scheduled sequentially or on an ad hoc basis. The query that supplies the data to the telemetry crash dashboard runs once per day at 2pm UTC.
The difference between the dataset being present in the query interface and the query running is query scheduling delay. This is about an hour.
This provides us with a handy equation:
latency = reporting delay + submission delay + aggregation delay + migration delay + query scheduling delay
With typical values, we’re seeing:
latency = 6 hours + 24 hours + 12 hours + 1 hour + 1 hour
latency = 2 days
And since submission delay is unbounded (and tends to be longer than 24 hours on weekends and over holidays), the latency is actually a range of probable values. We’re never really sure when we’ve heard from everyone.
So what’s to blame, and what can we do about it?
The design of Firefox’s Telemetry data reporting system is responsible for reporting delay and submission delay: two of the worst offenders. submission delay could be radically improved if we devoted engineering resources to submitting Telemetry (both crash numbers and “usage hour” reports) without an active Firefox running (using, say, a small executable that runs as soon as Firefox crashes or closes). reporting delay will probably not be adjusted very much as we don’t want to saturate our users’ bandwidth (or our own).
We can improve aggregation delay simply by running the aggregation, migration, and query multiple times a day, as information is coming in. Proper scheduling infrastructure can remove all the non-processing overhead from migration delay and query scheduling delay which can bring them easily down below a single hour, combined.
In conclusion, even given a clear and specific metric and a data collection mechanism with which to collect all the data necessary to measure it, there are still problems when you try to use it to make timely decisions. There are technical solutions to these technical problems, but they require a focused approach to improve the timeliness of reported data.
:chutten

|
|
Mozilla Security Blog: Enforcing Content Security By Default within Firefox |
Enforcing Content Security Historically

Enforcing Content Security By Default

https://blog.mozilla.org/security/2016/11/10/enforcing-content-security-by-default-within-firefox/
|
|
The Rust Programming Language Blog: Announcing Rust 1.13 |
The Rust team is happy to announce the latest version of Rust, 1.13.0. Rust is a systems programming language focused on safety, speed, and concurrency.
As always, you can install Rust 1.13.0 from the appropriate page on our website, and check out the detailed release notes for 1.13.0 on GitHub. 1448 patches were landed in this release.
It’s been a busy season in Rust. We enjoyed three Rust conferences, RustConf, RustFest, and Rust Belt Rust, in short succession. It was great to see so many Rustaceans in person, some for the first time! We’ve been thinking a lot about the future, developing a roadmap for 2017, and building the tools our users tell us they need.
And even with all that going on, we put together a new release filled with fun new toys.
The 1.13 release includes several extensions to the language, including the
long-awaited ? operator, improvements to compile times, minor feature
additions to cargo and the standard library. This release also includes many
small enhancements to documentation and error reporting, by many contributors,
that are not individually mentioned in the release notes.
This release contains important security updates to Cargo, which depends on curl and OpenSSL, which both published security updates recently. For more information see the respective announcements for curl 7.51.0 and OpenSSL 1.0.2j.
? operatorRust has gained a new operator, ?, that makes error handling more pleasant by
reducing the visual noise involved. It does this by solving one simple
problem. To illustrate, imagine we had some code to read some data from a file:
fn read_username_from_file() -> Result<String, io::Error> {
let f = File::open("username.txt");
let mut f = match f {
Ok(file) => file,
Err(e) => return Err(e),
};
let mut s = String::new();
match f.read_to_string(&mut s) {
Ok(_) => Ok(s),
Err(e) => Err(e),
}
}
This code has two paths that can fail, opening the file and reading the data
from it. If either of these fail to work, we’d like to return an error from
read_username_from_file. Doing so involves matching on the result of the I/O
operations. In simple cases like this though, where we are only propagating
errors up the call stack, the matching is just boilerplate - seeing it written
out, in the same pattern every time, doesn’t provide the reader with a great
deal of useful information.
With ?, the above code looks like this:
fn read_username_from_file() -> Result<String, io::Error> {
let mut f = File::open("username.txt")?;
let mut s = String::new();
f.read_to_string(&mut s)?;
Ok(s)
}
The ? is shorthand for the entire match statements we wrote earlier. In other
words, ? applies to a Result value, and if it was an Ok, it unwraps it and
gives the inner value. If it was an Err, it returns from the function you’re
currently in. Visually, it is much more straightforward. Instead of an entire
match statement, now we are just using the single “?” character to indicate that
here we are handling errors in the standard way, by passing them up the
call stack.
Seasoned Rustaceans may recognize that this is the same as the try! macro
that’s been available since Rust 1.0. And indeed, they are the same. Before
1.13, read_username_from_file could have been implemented like this:
fn read_username_from_file() -> Result<String, io::Error> {
let mut f = try!(File::open("username.txt"));
let mut s = String::new();
try!(f.read_to_string(&mut s));
Ok(s)
}
So why extend the language when we already have a macro? There are multiple
reasons. First, try! has proved to be extremely useful, and is used often in
idiomatic Rust. It is used so often that we think it’s worth having a sweet
syntax. This sort of evolution is one of the great advantages of a powerful
macro system: speculative extensions to the language syntax can be prototyped
and iterated on without modifying the language itself, and in return, macros that
turn out to be especially useful can indicate missing language features. This
evolution, from try! to ? is a great example.
One of the reasons try! needs a sweeter syntax is that it is quite
unattractive when multiple invocations of try! are used in
succession. Consider:
try!(try!(try!(foo()).bar()).baz())
as opposed to
foo()?.bar()?.baz()?
The first is quite difficult to scan visually, and each layer of error handling
prefixes the expression with an additional call to try!. This brings undue
attention to the trivial error propagation, obscuring the main code path, in
this example the calls to foo, bar and baz. This sort of method chaining
with error handling occurs in situations like the builder pattern.
Finally, the dedicated syntax will make it easier in the future to produce nicer
error messages tailored specifically to ?, whereas it is difficult to produce
nice errors for macro-expanded code generally (in this release, though, the ?
error messages could use improvement).
Though this is a small feature, in our experience so far, ? feels like a solid
ergonomic improvement to the old try! macro. This is a good example of the
kinds of incremental, quality-of-life improvements Rust will continue to
receive, polishing off the rough corners of our already-powerful base language.
Read more about ? in RFC 243.
There has been a lot of focus on compiler performance lately. There’s good news in this release, and more to come.
Mark Simulacrum and Nick Cameron have been refining perf.rust-lang.org, our tool for tracking compiler performance. It runs the rustc-benchmarks suite regularly, on dedicated hardware, and tracks the results over time. This tool records the results for each pass in the compiler and is used by the compiler developers to narrow commit ranges of performance regressions. It’s an important part of our toolbox!
We can use this tool to look at a graph of performance over the 1.13 development cycle, shown below. This cycle covered the dates from August 16 through September 29 (the graph begins from Augest 25th though and is filtered in a few ways to eliminate bogus, incomplete, or confusing results). There appear to be some big reductions, which are quantified on the corresponding statistics page.
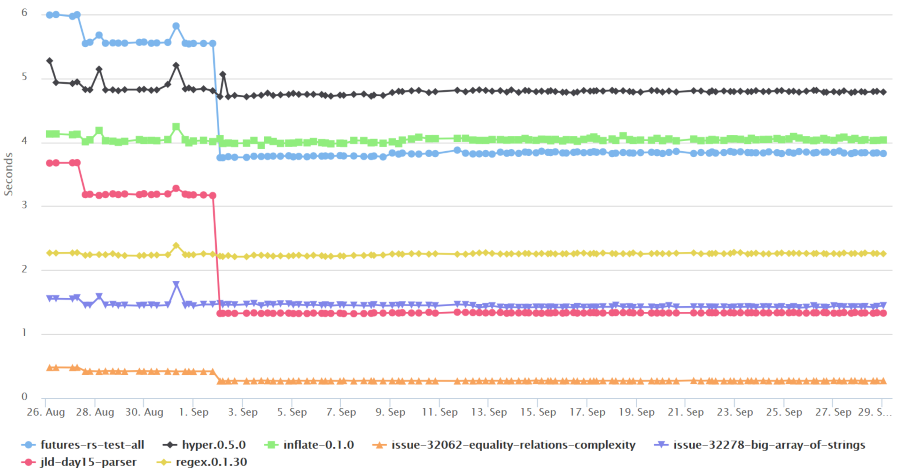
The big improvement demonstrated in the graphs, on September 1, is from an optimization from Niko to cache normalized projections during translation. That is to say, during generation of LLVM IR, the compiler no longer recomputes concrete instances of associated types each time they are needed, but instead reuses previously-computed values. This optimization doesn’t affect all code bases, but in code bases that exhibit certain patterns, like futures-rs, where debug mode build-time improved by up to 40%, you’ll notice the difference.
Another such optimization, that doesn’t affect every crate but does affect some
in a big way, came from Michael Woerister, and improves compile time for crates
that export many inline functions. When a function is marked #[inline], in
addition to translating that function for use by the current crate, the compiler
stores its MIR representation in the crate rlib, and translates the function to
LLVM IR in every crate that calls it. The optimization Michael did is obvious in
retrospect: there are some cases where inline functions are only for the
consumption of other crates, and never called from the crate in which they are
defined; so the compiler doesn’t need to translate code for inline functions in
the crate they are defined unless they are called directly. This saves the
cost of rustc converting the function to LLVM IR and LLVM optimizing and
converting the function to machine code.
In some cases this results in dramatic improvements. Build times for the ndarray crate improved by 50%, and in the (unreleased) winapi 0.3 crate, rustc now emits no machine code at all.
But wait, there’s more still! Nick Nethercote has turned his focus to compiler performance as well, focusing on profiling and micro-optimizations. This release contains several fruits of his work, and there are more in the pipeline for 1.14.
This release contains important security updates to Cargo, which depends on curl and OpenSSL, which both published security updates recently. For more information see the respective announcements for curl 7.51.0 and OpenSSL 1.0.2j.
Macros can now be used in type position (RFC 873), and attributes can be applied to statements (RFC 16):
// Use a macro to name a type
macro_rules! Tuple {
{ $A:ty,$B:ty } => { ($A, $B) }
}
let x: Tuple!(i32, i32) = (1, 2);
// Apply a lint attribute to a single statement
#[allow(uppercase_variable)]
let BAD_STYLE = List::new();
Inline drop flags have been removed. Previously, in case of a conditional move, the compiler would store a “drop flag” inline in a struct (increasing its size) to keep track of whether or not it needs to be dropped. This means that some structs take up some unexpected extra space, which interfered with things like passing types with destructors over FFI. It also was a waste of space for code that didn’t have conditional moves. In 1.12, MIR became the default, which laid the groundwork for many improvements, including getting rid of these inline drop flags. Now, drop flags are stored in an extra slot on the stack frames of functions that need them.
1.13 contains a serious bug in code generation for ARM targets using hardware floats (which is most ARM targets). ARM targets in Rust are presently in our 2nd support tier, so this bug was not determined to block the release. Because 1.13 contains a security update, users that must target ARM are encouraged to use the 1.14 betas, which will soon get a fix for ARM.
Reflect trait is deprecated. See the explanation of what this means
for parametricity in Rust.checked_abs, wrapping_abs, and overflowing_absRefCell::try_borrow, and RefCell::try_borrow_mutassert_ne! and debug_assert_ne!AsRef<[T]> for std::slice::IterCoerceUnsized for {Cell, RefCell, UnsafeCell}Debug for std::path::{Components,Iter}charSipHasher is deprecated. Use DefaultHasher.std::io::ErrorKindSee the detailed release notes for more.
We had 155 individuals contribute to 1.13.0. Thank you so much!
|
|
Sean McArthur: RustConf 2016 |
I got to attend RustConf in September1, and felt these talks in particular may interest someone working on FxA2:
Futures - The Rust community has been working rapidly on a very promising concept to write asynchronous code in Rust. You likely are pretty comfortable with how Promises work in JavaScript. The Futures library in Rust feels very similar to JavaScript Promises, but! But! They compile down to an optimized state machine, without the need to allocate a whole bunch of closures like JavaScript does.
On top of the Futures library, the community is working on a library that is “futures + network IO”, and that’s tokio. It’s a framework designed to help anyone build a network protocol library. A big user of this is hyper. The examples in hyper show how expressive this pattern can be, while still being super fast.
How to do community RFCs - Rust has a method for the community to suggest improvements to the language, which they call RFCs. These are very similar in practice to Python’s PEPs. It’s been quite successful, and other notable projects have adopted it as well, such as Ember.js. In fact, the RFC process from Rust is what I looked at when we were adjusting how to do our FxA Features. This talk showed how truly impressive it is that the community can work together at designing a better feature.
Rust is a great way to learn how to do systems programming - This was a really special talk about how someone who may be scared of the ominous “systems programming” can actually dive right in without worrying about blowing off a (computer’s) leg. If you’ve mostly used “higher level” languages, and wondered how in the world to dive in, Julia has a great message for you.
If you don’t check out any other talk, at least look at this one. If videos aren’t your thing, try the written article form instead.
|
|
Air Mozilla: The Joy of Coding - Episode 79 |
 mconley livehacks on real Firefox bugs while thinking aloud.
mconley livehacks on real Firefox bugs while thinking aloud.
https://air.mozilla.org:443/the-joy-of-coding-episode-78-20161109/
|
|
Yunier Jos'e Sosa V'azquez: !Firefox cumple sus primeros 12 a~nos! |
Un d'ia como hoy, pero 12 a~nos atr'as fue liberada de forma oficial Firefox 1.0, un navegador diferente y alternativo al IE de aquellos tiempos.
Desde aquel glorioso 9 de noviembre de 2004, Firefox ha incluido funcionalidades que han revolucionado la web, sorteado problemas y navegado con astucia para convertirse en unos de los proyectos de software libre m'as importantes del mundo. Sin dudas debemos sentirnos felices por eso.
Solo nos queda desear muchas felicidades y muchos a~nos m'as de vida a Firefox y a la Comunidad Mozilla por mantenerlo.


Los dejo con algunas fotos de nuestras anteriores celebraciones.









|
|
Air Mozilla: Weekly SUMO Community Meeting Nov. 09, 2016 |
 This is the sumo weekly call
This is the sumo weekly call
https://air.mozilla.org:443/weekly-sumo-community-meeting-nov-09-2016/
|
|
Doug Belshaw: How to use a VPN to ensure good 'digital hygiene' while travelling |
I travel reasonably often as part of my work. One trend I’ve noticed recently is for hotels to provide unsecured wifi, without even so much as a landing page. While this means a ‘frictionless’ experience for guests connecting to the internet, it’s also extremely bad practice from a security point of view.
Unless you know and trust the person or organisation providing your internet connection, you should proceed with caution. Your data are valuable - the business model of Facebook is testament to that! Protect your digital identity.
A Virtual Private Network (VPN) is a way to route your traffic through a trusted server. You could run your own, but the usual way is to pay for this kind of service to ensure there are no bandwidth bottlenecks. A nice little bonus to using VPNs is the ability to make it look like you are based in another country, meaning you get access to content that might be restricted in your own country.
I’m still a fan of iPREDator but it can be cumbersome to set up. That’s why I’m currently using TunnelBear as it’s super-simple to configure, works across all of my devices, and they promise not to keep any logs of your activity (which could be shared with the authorities, etc.)
I’m not going to screenshot every step, but I’m sure you can figure it out.
1) Download TunnelBear from the App Store.

2) Open the app and sign up for a new account. You could use a throwaway email account like Mailinator if you’re willing to keep setting up new accounts, I guess.
3) Allow TunnelBear to change the VPN settings for your device.
4) Once these VPN settings are installed, you don’t actually have to use the app, as you can connect by going to Settings -> General -> VPN and toggling the switch to ON.
When this toggle switch is on, all of your traffic is being routed through the VPN.
There’s also TunnelBear apps for Mac and Windows, and a one-click install process for Chrome and Opera web browsers. This is great news for users of Chromebooks (like me!)

I’d recommend setting up TunnelBear (or whatever VPN you choose) before travelling. That way, you don’t have to connect to an unsecured wifi network at all. For more advanced users, there’s Tor and the Tor browser, based on Firefox. This works slightly differently, bouncing your traffic around the internet, and is actually what I use on Android for private browsing.
Comments? Questions? I’m @dajbelshaw or you can email me: hello@dynamicskillset.com
|
|
Andy McKay: If you've got nothing to hide... |
When it was revealed that every Government in the world was using technology to spy unlawfully on every other country, there was an arugment that this was acceptable "as long as you have nothing to hide". That argument is, of course, complete rubbish and individual freedoms and rights to privacy are extremely important.
But we've just witnessed in the US another problem with this argument. It's acceptable "as long as you have nothing to hide from every single government and authority that is going to possibly come after". For example, the current Canadian Liberal government might be "ok", but who's going to get elected next. And next? What happens if one of those governments is like the one coming into the US?
There is a chilling example of this in history. In the Netherlands they recorded peoples information in a census and that included peoples religion. In 1941 there were about 140,000 Dutch Jews living in the Netherlands. After the Nazi invasion there were an estimated 35,000 left. Because the Government had census data for them, it was easy for the Nazis to find and eliminate them using that data.
Some 75% of the Dutch-Jewish population perished, an unusually high percentage compared with other occupied countries in western Europe.
As Cory Doctrow said today:
All those times we said, "When you build mass surveillance, you don't just put power in the hands of those you trust, but also the next guy"
— Cory Doctorow (@doctorow) November 9, 2016
Most of my (admittedly small) readership lives in North America or Europe. That means there's likely a Government surveillance operation monitoring you. It could be internal (in my case CSIS) or external (in my case the NSA). Even worse, they share their information with each other through Five Eyes to get around laws. There is a:
"supra-national intelligence organisation that doesn't answer to the known laws of its own countries"
Edward Snowden, via Wikipedia
The US has just elected someone who repeatedly spews lies, rascism, sexism, hatred and profiling and has said he will go after his enemies [1]. That person will soon oversee the largest surveillance operation in the history of mankind. A surveillance operation that spys on the majority of people reading this blog. That should worry you.
|
|
Niko Matsakis: Associated type constructors, part 4: Unifying ATC and HKT |
This post is a continuation of my posts discussing the topic of associated type constructors (ATC) and higher-kinded types (HKT):
So far we have seen “associated-type constructors” and “higher-kinded types” as two distinct concepts. The question is, would it make sense to try and unify these two, and what would that even mean?
Consider this trait definition:
trait Iterable {
type Iter<'a>: Iterator<Item=Self::Item>;
type Item;
fn iter<'a>(&'a self) -> Self::Iter<'a>;
}
In the ATC world-view, this trait definition would mean that you can now specify a type like the following
::Iter<'a>
Depending on what the type T and lifetime 'a are, this might get
“normalized”. Normalization basically means to expand an associated
type reference using the types given in the appropriate impl. For
example, we might have an impl like the following:
impl<A> Iterable for Vec<A> {
type Item = A;
type Iter<'a> = std::vec::Iter<'a, A>;
fn iter<'a>(&'a self) -> Self::Iter<'a> {
self.clone()
}
}
In that case, as Iterable>::Iter<'x> could be normalized
to std::vec::Iter<'x, Foo>. This is basically exactly the same way
that associated type normalization works now, except that we have
additional type/lifetime parameters that are placed on the associated
item itself, rather than having all the parameters come from the trait
reference.
Another way to view an ATC is as a kind of function, where the
normalization process plays the role of evaluating the function when
applied to various arguments. In that light, as
Iterable>::Iter could be viewed as a “type function” with a signature
like lifetime -> type; that is, a function which, given a type and a
lifetime, produces a type:
as Iterable>::Iter<'x>
^^^^^^^^^^^^^^^^^^^^^^^^^^^^ ^^
function argument
When I write it this way, it’s natural to ask how such a function is
related to a higher-kinded type. After all, lifetime -> type could
also be a kind, right? So perhaps we should think of as
Iterable>::Iter as a type of kind lifetime -> type? What would that mean?
Well, in the last post, we saw that, in order to ensure that inference is tractable, HKT in Haskell comes with pretty strict limitations on the kinds of “type functions” we can support. Whatever we chose to adopt in Rust, it would imply that we need similar limitations on ATC values that can be treated as higher-kinded.
That wouldn’t affect the impl of Iterable for Vec that we saw
earlier. But imagine that we wanted Range, which is the type
produced by 0..22, to act as an Iterable. Now, ranges like 0..22
are already iterable – so the type of an iterator could just be
Self, and iter() can effectively just be clone(). So you might
think you could just write:
impl<u32> Iterable for Range<u32>
type Item = u32;
type Iter<'a> = Range<u32>;
// ^^^^ doesn't use `'a'` at all
fn iter(&self) -> Range<u32> {
*self
}
}
However, this impl would be illegal, because Range doesn’t use
the parameter 'a. Presuming we adopted the rule I suggested in the
previous post, every value for Iter<'a> would have to use the 'a
exactly once, as the first lifetime argument. So Foo<'a, u32> would
be ok, as would &'a Bar, but Baz<'static, 'a> would not.
You could work around this limitation above by introducing a newtype. Something like this:
struct RangeIter<'a> {
range: Range<u32>,
dummy: PhantomData<&'a ()>,
// ^^ need to use `'a` somewhere
}
We can then implement Iterator for RangeIter<'a> and just proxy
next() on to self.range.next(). But this is kind of a drag.
For a long time, I had assumed that if we were going to introduce HKT,
we would do so by letting users define the kinds more explicitly. So,
for example, if we wanted the member Iter to be of kind lifetime ->
type, we might declare that explicitly. Using the <_> and <'_>
notation I was using in earlier posts, that might look like this:
trait Iterable {
type Iter<'_>;
}
Now the trait has declared that impls must supply a valid, partially
applied struct/enum name as the value for Iter.
I’ve somewhat soured on this idea, for a variety of reasons. One big one is that we are forcing trait users to mak this choice up front, when it may not be obvious whether a HKT or an ATC is the better fit. And of course it’s a complexity cost: now there are two things to understand.
Finally, now that I realize that HKT is going to require bounds, not
having names for things means it’s hard to see how we’re going to
declare those bounds. In fact, even the Iterable trait probably has
some bounds; you can’t just use any old lifetime for the
iterator. So really the trait probably includes a condition that
Self: 'iter, meaning that the iterable thing must outlive the
duration of the iteration:
trait Iterable {
type Iter<'iter>: Iterator<Item=Self::Item>
where Self: 'iter; // <-- bound I was missing before
type Item;
fn iter<'iter>(&'iter self) -> Self::Iter<'iter>;
}
You might wonder why I said that we should consider lifetime -> type rather than saying
that Iterable::Iter would be something of kind type -> lifetime ->
type. In other words, what about the input types to the trait itself?
It turns out that this idea doesn’t really make sense. First off, it
would naturally affect existing associated types. So Iterator::Item,
for example, would be something of kind type -> type, where the
argument is the type of the iterator. as Iterator>::Item
would be the syntax for applying Iterator::Item to Range.
Since we can write generic functions with higher-kinded parameters
like fn foo>(), that means that I here might be
Iterator::Item, and hence I> would be equivalent to
as Iterator>::Item.
But remember that, to make inference tractable, we want to know that
?X if and only if ?X = ?Y. That means that we could
not allow as Iterator>::Item to normalize to the same
thing as as SomeOtherTrait>::Foo. You can see that this
doesn’t even remotely resemble associated types as we know them, which
are just plain one-way functions.
This is kind of the “capstone” post for the series that I set out to write. I’ve tried to give an overview of what associated type constructors are; the ways that they can model higher-kinded patterns; what higher-kinded types are; and now what it might mean if we tried to combine the two ideas.
I hope to continue this series a bit further, though, and in particular to try and explore some case studies and further thoughts. If you’re interested in the topic, I strongly encourage you to hop over to the internals thread and take a look. There have been a lot of insightful comments there.
That said, currently my thinking is this:
So currently I lean towards accepting ATC with no restrictions and modeling HKT using families. That said, I agree that the potential to feel like a lot of “boilerplate”. I sort of suspect that, in practice, HKT would require a fair amount of its own boilerplate (i.e, to abstract away bounds and so forth), and/or not be suitable for Rust, but perhaps further exploration of example use-cases will be instructive in this regard.
Please leave comments on this internals thread.
|
|
Air Mozilla: Martes Mozilleros November 8, 2016 |
 Reuni'on bi-semanal para hablar sobre el estado de Mozilla, la comunidad y sus proyectos. Bi-weekly meeting to talk (in Spanish) about Mozilla status, community and...
Reuni'on bi-semanal para hablar sobre el estado de Mozilla, la comunidad y sus proyectos. Bi-weekly meeting to talk (in Spanish) about Mozilla status, community and...
|
|
Cameron Kaiser: Happy 6th birthday, TenFourFox |
Hail to the Chief!
http://tenfourfox.blogspot.com/2016/11/happy-6th-birthday-tenfourfox.html
|
|
Doug Belshaw: Digital literacies have a civic element |
My ‘Essential Elements of Digital Literacies’ (thesis / book) looks like this:

Unlike some other people who seemed to need a subject for their latest blog post or journal article, this wasn’t something I just sat down and thought about for half an hour. This was the result of a few years worth of work, and a large meta-analysis of theory and practice.
The elements that most people seem to take issue with when looking at the above diagram are 'Confident’ and 'Civic’. The top row, the four 'skillsets’ seem to pose no problem, but people wonder how they can teach the bottom four 'mindsets’ - particularly the two just highlighted.
The latest episode of the Techgypsies podcast by Audrey Watters and Kin Lane does a great job of explaining the Civic element of digital literacies. I’ve embedded the player below, or click here. Listen to the whole thing as it’s fascinating, but the bit that we’re interested here starts at about the 20-minute mark.
Audrey and Kin use the 'scandal’ around Hillary Clinton’s private email server as a lens to show how poor our understanding of everyday tech actually is. What I thought was particularly enlightening was their likening the 'learn to code’ movement to standard IT practices. In other words: “oh, this is too hard for you? well, just leave it to us and we’ll sort it out for you”. In other words, passive, uncritical use of technology is fine unless, you know, you’re a 'techie’.
In learning organisations, in businesses, and in families, there are practices built upon technologies that need to be learned. As Audrey and Kin outline, although it’s entirely unsexy, an understanding of difference between POP, SMTP, and IMAP would have meant people could have seen the email 'scandal’ as entirely a non-event.
What I really appreciated was Audrey’s reframing of this kind of thing as a social studies issue. We shouldn’t have to have separate classes for this kind of thing any more. Instead, our society should have a baseline understanding of how the tech we use every day works. That also applies to web domains, and to the way that data flows around the web.
Of course, a lot of this is covered in Mozilla’s Web Literacy Map. Not all of what we need to know pertains to the 'web’, of course - which is where the Essential Elements of Digital Literacies come in. They’re plural, context-dependent, and should be co-defined in your community. As well as raising awareness of the latest shiny technologies (e.g. blockchain, AI) we should be ensuring people are comfortable with the tech they’re using right now.
Questions? Comments? I’m @dajbelshaw or you can email me: hello@dynamicskillset.com
|
|






