Mozilla Reps Community: RepsNext – Introduction Video |
At the 2015 Reps Leadership Meeting in Paris it became clear that the program was ready for “a version 2”. As the Reps Council had recently become a formal part of Mozilla Leadership, it was time to bring the program to the next level. Literally building on that idea, the RepsNext initiative was born.
Since then several working groups were formed to condense reflections on the past and visions for the future into new program proposals.
At our last Council meetup from 14-17 April 2016 in Berlin we recorded interviews with Council and Peers explaining RepsNext and summarizing our current status.
You can find a full transcript at the end of this blog post. Thanks to Yofie for editing the video!
Please share this video broadly, creating awareness for the exciting future of the Reps program.
Getting involved
We will focus our work at the London All Hands from June 12th to June 17th to work on open questions around the working groups. We will share our outcomes and open up for discussions after that. For now, there are several discussions to jump in and shape the future of the Reps program:
Additionally, you can help out and track our Council efforts on the Reps GitHub repository.
Moving beyond RepsNext
It took us a little more than a year to come up with this “new release” of the Reps program. For the future we plan to take smaller steps improving the program beyond RepsNext. So expect experiments and tweaks arriving in smaller bits and with a higher clockspeed (think Firefox Rapid Release Model).
Video transcript
Question: What is RepsNext?
[Arturo] I think we have reached a point of maturity in the program that we need to reinvent ourselves to be adaptors of Mozilla’s will and to the modern times.
Question: How will the Reps program change?
[Pierros] What we’re really interested in and picking up as a highlight are the changes on the governance level. There are a couple of things that are coming. The Council has done really fanstastic work on bringing up and framing really interesting conversations around what RepsNext is, and PeersNext as a subset of that, and how do we change and adapt the leadership structure of Mozilla Reps to be more representative of the program that we would like to see.
[Brian] The program will still remain a grassroots program, run by volunteers for volunteers.
[Henrik] We’ve been working heavily on it in various working groups over the last year, developed a very clear understanding of the areas that need work and actually got a lot of stuff done.
[Konstantina] I think that the program has a great future ahead of it. We’re moving to a leadership body where our role is gonna be to empower the rest of the volunteer community and we’re gonna try to minimize the bureacracy that we already have. So the Reps are gonna have the same resources that they had but they are gonna have tracks where they can evolve their leadership skills and with that empower the volunteer communities. Reps is gonna be the leadership body for the volunteer community and I think that’s great. We’re not only about events but we’re something more and we’re something the rest of Mozilla is gonna rely on when we’re talking about volunteers.
Question: What’s important about this change?
[Michael] We will have the Participation team’s support to have meetings together, to figure out the strategy together.
[Konstantina] We are bringing the tracks where we specialize the Reps based on their interest.
Question: Why do we need changes?
[Christos] There is the need of that. There is the need to reconsider the mentoring process, reconsidering budgets, interest groups inside of Reps. There is a need to evolve Reps and be more impactful in our regions.
Question: Is this important for Mozilla?
[Arturo] We’re going to have mentors and Reps specialized in their different contribution areas.
Question: How is RepsNext helping local communities?
[Guillermo] Our idea, what we’re planning with the changes on RepsNext is to bring more people to the program. More people is more diversity, so we’re trying to find new people, more people with new interests.
Question: What excites you about RepsNext?
[Faisal] We have resources for different types of community, for example if somebody needs hardware or somebody training material, a variety of things not just what we used to have. So it will open up more ways on how we can support Reps for more impactful events and making events more productive.
https://blog.mozilla.org/mozillareps/2016/06/16/repsnext-introduction-video/
|
|
QMO: Firefox 48 Beta 3 Testday, June 24th |
Hello Mozillians,
We are happy to announce that next Friday, June 24th, we are organizing Firefox 48 Beta 3 Testday. We’ll be focusing our testing on the New Awesomebar feature, bug verifications and bug triage. Check out the detailed instructions via this etherpad.
No previous testing experience is required, so feel free to join us on #qa IRC channel where our moderators will offer you guidance and answer your questions.
Join us and help us make Firefox better! See you on Friday!
https://quality.mozilla.org/2016/06/firefox-48-beta-3-testday-june-24th/
|
|
Tanvi Vyas: Contextual Identities on the Web |
The Containers Feature in Firefox Nightly enables users to login to multiple accounts on the same site simultaneously and gives users the ability to segregate site data for improved privacy and security.
We all portray different characteristics of ourselves in different situations. The way I speak with my son is much different than the way I communicate with my coworkers. The things I tell my friends are different than what I tell my parents. I’m much more guarded when withdrawing money from the bank than I am when shopping at the grocery store. I have the ability to use multiple identities in multiple contexts. But when I use the web, I can’t do that very well. There is no easy way to segregate my identities such that my browsing behavior while shopping for toddler clothes doesn’t cross over to my browsing behavior while working. The Containers feature I’m about to describe attempts to solve this problem: empowering Firefox to help segregate my online identities in the same way I can segregate my real life identities.
With Containers, users can open tabs in multiple different contexts – Personal, Work, Banking, and Shopping. Each context has a fully segregated cookie jar, meaning that the cookies, indexeddb, localStorage, and cache that sites have access to in the Work Container are completely different than they are in the Personal Container. That means that the user can login to their work twitter account on twitter.com in their Work Container and also login to their personal twitter on twitter.com in their Personal Container. The user can use both mail accounts in side-by-side tabs simultaneously. The user won’t need to use multiple browsers, an account switcher[1], or constantly log in and out to switch between accounts on the same domain.

Simultaneously logged into Personal Twitter and Work Twitter accounts.
Note that the inability to efficiently use “Contextual Identities” on the web has been discussed for many years[2]. The hard part about this problem is figuring out the right User Experience and answering questions like:
We don’t have the answers to all of these questions yet, but hope to start uncovering some of them with user research and feedback. The Containers implementation in Nightly Firefox is a basic implementation that allows the user to manage identities with a minimal user interface.
We hope to gather feedback on this basic experience to see how we can iterate on the design to make it more convenient, elegant, and usable for our users. Try it out and share your feedback by filling out this quick form or writing to containers@mozilla.com.
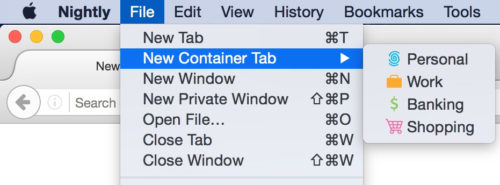
You can start using Containers in Nightly Firefox 50 by opening a New Container Tab. Go the File Menu and select the “New Container Tab” option. (Note that on Windows you need to hit the alt key to access the File Menu.) Choose between Personal, Work, Shopping, and Banking.
Notice that the tab is decorated to help you remember which context you are browsing in. The right side of the url bar specifies the name of the Container you are in along with an icon. The very top of the tab has a slight border that uses the same color as the icon and Container name. The border lets you know what container a tab is open in, even when it is not the active tab.
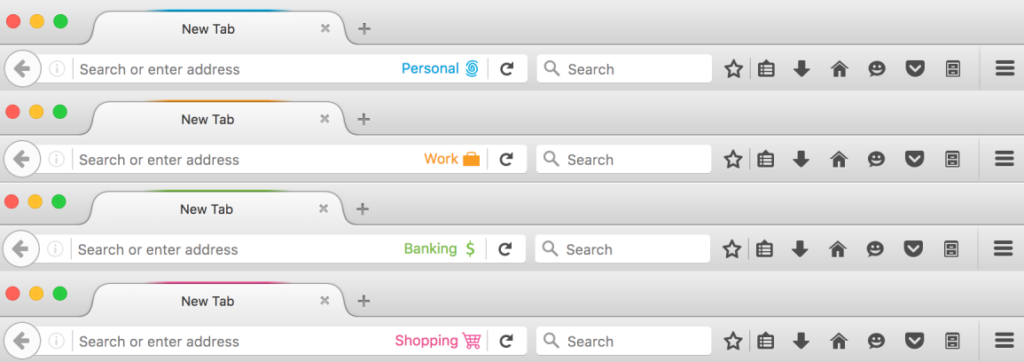
You can open multiple tabs in a specific container at the same time. You can also open multiple tabs in different containers at the same time:

2 Work Containers tabs, 2 Shopping Container tabs, 1 Banking Container tab
Your regular browsing context (your “default container”) will not have any tab decoration and will be in a normal tab. See the next section to learn more about the “default container”
Containers are also accessible via the hamburger menu. Customize your hamburger menu by adding in the File Cabinet icon. From there you can select a container tab to open. We are working on adding more access points for container tabs; particularly on long-press of the plus button.
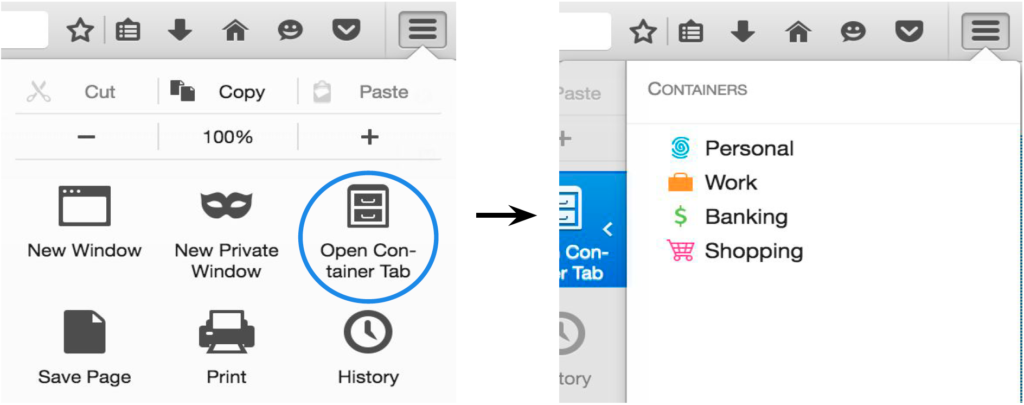
The containers feature doesn’t change the normal browsing experience you get when using New Tab or New Window. The normal tab will continue to access the site data the browser has already stored in the past. The normal tab’s user interface will not change. When browsing in the normal context, any site data read or written will be put in what we call the “default container”.
If you use the containers feature, the different container tabs will not have access to site data in the default container. And when using a normal tab, the tab won’t have access to site data that was stored for a different container tab. You can use normal tabs along side other containers:

2 normal tabs (“Default Container tabs”), 2 Work Container tabs, 1 Banking Container tab
In principle, any data that a site has read or write access to should be segregated.
Assume a user logins into example.com in their Personal Container, and then loads example.com in their Work Container. Since these loads are in different containers, there should be no way for the example.com server to tie these two loads together. Hence, each container has its own separate cookies, indexedDB, localStorage, and cache.

Assume the user then opens a Shopping Container and opens the History menu option to look for a recently visited site. example.com will still appear in the user’s history, even though they did not visit example.com in the Shopping Container. This is because the site doesn’t have access to the user’s locally stored History. We only segregate data that a site has access to, not data that the user has access to. The Containers feature was designed for a single user who has the need to portray themselves to the web in different ways depending on the context in which they are operating.
By separating the data that a site has access to, rather than the data that a user has access to, Containers is able to offer a better experience than some of the alternatives users may be currently using to manage their identities.
This is an experimental feature in Nightly only. We would like to collect feedback and iterate on the design before the containers concept goes beyond Nightly. Moreover, we would like to get this in the hands of Nightly users so they can help validate the OriginAttribute architecture we have implemented for this feature and other features. We have also planned a Test Pilot study for the Fall.
To be clear, this means that when Nightly 50 moves to Aurora/DevEdition 50, containers will not be enabled.
What do users do if they have two twitter accounts and want to login to them at the same time? Currently, users may login to one twitter account using their main browser, and another using a secondary browser. This is not ideal, since then the user is running two browsers in order to accomplish their tasks.
Alternatively, users may open a Private Browsing Window to login to the second twitter account. The problem with this is that all data associated with Private Browsing Windows is deleted when they are closed. The next time the user wants to use their secondary twitter account, they have to login again. Moreover, if the account requires two factor authentication, the user will always be asked for the second factor token, since the browser shouldn’t remember that they had logged in before when using Private Browsing.
Users may also use a second browser if they are worried about tracking. They may use a secondary browser for Shopping, so that the trackers that are set while Shopping can’t be associated with the tasks on their primary browser.
Yes, by following these steps:
Although the privacy.userContext.enabled preference described above may be present in other versions of Firefox, the feature may be incomplete, outdated, or buggy. We currently only recommend enabling the feature in Nightly, where you’ll have access to the newest and most complete version.
An origin is defined as a combination of a scheme, host, and port. Browsers make numerous security decisions based on the origin of a resource using the same-origin-policy. Various features require additional keys to be added to the origin combination. Examples include the Tor Browser’s work on First Party Isolation, Private Browsing Mode, the SubOrigin Proposal, and Containers.
Hence, Gecko has added additional attributes to the origin called OriginAttributes. When trying to determine if two origins are same-origin, Gecko will not only check if they have matching schemes, hosts, and ports, but now also check if all their OriginAttributes match.
Containers adds an OriginAttribute called userContextId. Each container has a unique userContextId. Stored site data (i.e. cookies) is now stored with a scheme, host, port, and userContextId. If a user has https://example.com cookies with the userContextId for the Shopping Container, those cookies will not be accessible by https://example.com in the Banking Container.
Note that one of the motivations in enabling this feature in Nightly is to help ensure that we iron out any bugs that may exist in our OriginAttribute implementation before features that depend on it are rolled out to users.
The Containers feature offers users some control over the techniques websites can use to track them. Tracking cookies set while shopping in the Shopping Container won’t be accessible to sites in the Personal Container. So although a tracker can easily track a user within their Shopping Container, they would have to use device fingerprinting techniques to link that tracking information with tracking information from the user’s Personal Container.
Containers also offers the user a way to compartmentalize sensitive information. For example, users could be careful to only use their Banking Container to log into banking sites, protecting themselves from potential XSS and CSRF attacks on these sites. Assume a user visits attacker.com in an non-banking-container. The malicious site may try to use a vulnerability in a banking site to obtain the user’s financial data, but wouldn’t be able to since the user’s bank’s authentication cookies are shielded off in a separate container that the malicious site can’t touch.
There are some caveats to data separation with Containers.
The first is that all requests by your browser still have the same IP address, user agent, OS, etc. Hence, fingerprinting is still a concern. Containers are meant to help you separate your identities and reduce naive tracking by things like cookies. But more sophisticated trackers can still use your fingerprint to identify your device. The Containers feature is not meant to replace the Tor Browser, which tries to minimize your fingerprint as much as possible, sometimes at the expense of site functionality. With Containers, we attempt to improve privacy while still minimizing breakage.
There are also some bugs still open related to OriginAttribute separation. Namely, the following areas are not fully separated in Containers yet:
We are working on fixing these last remaining bugs and hope to do so during this Nightly 50 cycle.
I encourage you to try out the feature and provide your feedback via:
Thanks to everyone who has worked to make this feature a reality! Special call outs to the containers team:
Andrea Marchesini
Kamil Jozwiak
David Huseby
Bram Pitoyo
Yoshi Huang
Tim Huang
Jonathan Hao
Jonathan Kingston
Steven Englehardt
Ethan Tseng
Paul Theriault
[1] Some websites provide account switchers in their products. For websites that don’t support switching, users may install addons to help them switch between accounts.
[2] http://www.ieee-security.org/TC/W2SP/2013/papers/s1p2.pdf, https://blog.mozilla.org/ladamski/2010/07/contextual-identity/
[3] Containers Slide Deck
https://blog.mozilla.org/tanvi/2016/06/16/contextual-identities-on-the-web/
|
|
David Burns: The final major player is set to ship WebDriver |
It was nearly a year ago that Microsoft shipped their first implementation of WebDriver. I remember being so excited as I wrote a blog post about it.
This week, Apple have said that they are going to be shipping a version of WebDriver that will allow people to drive Safari 10 in macOS. In the release notes they have created safari driver that will be shipping with the OS.
In addition to new Web Inspector features in Safari 10, we are also bringing native WebDriver support to macOS. https://t.co/PfwmkRIBIV
— WebKit (@webkit) June 15, 2016
If you have ever wondered why this is important? Have a read of my last blog post. In Firefox 47 Selenium caused Firefox to crash on startup. The Mozilla implementation of WebDriver, called Marionette and GeckoDriver, would never have hit this problem because test failures and crashes like this would lead to patches being reverted and never shipped to end users.
Many congratulations to the Apple team for making this happen!
http://www.theautomatedtester.co.uk/blog/2016/the-final-major-player-is-set-to-ship-webdriver.html
|
|
Anjana Vakil: I want to mock with you |
This post brought to you from Mozilla’s London All Hands meeting - cheers!
When writing Python unit tests, sometimes you want to just test one specific aspect of a piece of code that does multiple things.
For example, maybe you’re wondering:
Finding the answers to such questions is super simple if you use mock: a library which “allows you to replace parts of your system under test with mock objects and make assertions about how they have been used.” Since Python 3.3 it’s available simply as unittest.mock, but if you’re using an earlier Python you can get it from PyPI with pip install mock.
So, what are mocks? How do you use them?
Well, in short I could tell you that a Mock is a sort of magical object that’s intended to be a doppelg"anger for some object in your code that you want to test. Mocks have special attributes and methods you can use to find out how your test is using the object you’re mocking. For example, you can use Mock.called and .call_count to find out if and how many times a method has been called. You can also manipulate Mocks to simulate functionality that you’re not directly testing, but is necessary for the code you’re testing. For example, you can set Mock.return_value to pretend that an function gave you some particular output, and make sure that the right thing happens in your program.
But honestly, I don’t think I could give a better or more succinct overview of mocks than the Quick Guide, so for a real intro you should go read that. While you’re doing that, I’m going to watch this fantastic Michael Jackson video:
Oh you’re back? Hi! So, now that you have a basic idea of what makes Mocks super cool, let me share with you some of the tips/tips/trials/tribulations I discovered when starting to use them.
tl;dr: Learn where to patch if you don’t want to be sad!
When you import a helper module into a module you’re testing, the tested module gets its own namespace for the helper module. So if you want to mock a class from the helper module, you need to mock it within the tested module’s namespace.
For example, let’s say I have a Super Useful helper module, which defines a class HelperClass that is So Very Helpful:
# helper.py
class HelperClass():
def __init__(self):
self.name = "helper"
def help(self):
helpful = True
return helpful
And in the module I want to test, tested, I instantiate the Incredibly Helpful HelperClass, which I imported from helper.py:
# tested.py
from helper import HelperClass
def fn():
h = HelperClass() # using tested.HelperClass
return h.help()
Now, let’s say that it is Incredibly Important that I make sure that a HelperClass object is actually getting created in tested, i.e. that HelperClass() is being called. I can write a test module that patches HelperClass, and check the resulting Mock object’s called property. But I have to be careful that I patch the right HelperClass! Consider test_tested.py:
# test_tested.py
import tested
from mock import patch
# This is not what you want:
@patch('helper.HelperClass')
def test_helper_wrong(mock_HelperClass):
tested.fn()
assert mock_HelperClass.called # Fails! I mocked the wrong class, am sad :(
# This is what you want:
@patch('tested.HelperClass')
def test_helper_right(mock_HelperClass):
tested.fn()
assert mock_HelperClass.called # Passes! I am not sad :)
OK great! If I patch tested.HelperClass, I get what I want.
But what if the module I want to test uses import helper and helper.HelperClass(), instead of from helper import HelperClass and HelperClass()? As in tested2.py:
# tested2.py
import helper
def fn():
h = helper.HelperClass()
return h.help()
In this case, in my test for tested2 I need to patch the class with patch('helper.HelperClass') instead of patch('tested.HelperClass'). Consider test_tested2.py:
# test_tested2.py
import tested2
from mock import patch
# This time, this IS what I want:
@patch('helper.HelperClass')
def test_helper_2_right(mock_HelperClass):
tested2.fn()
assert mock_HelperClass.called # Passes! I am not sad :)
# And this is NOT what I want!
# Mock will complain: "module 'tested2' does not have the attribute 'HelperClass'"
@patch('tested2.HelperClass')
def test_helper_2_right(mock_HelperClass):
tested2.fn()
assert mock_HelperClass.called
Wonderful!
In short: be careful of which namespace you’re patching in. If you patch whatever object you’re testing in the wrong namespace, the object that’s created will be the real object, not the mocked version. And that will make you confused and sad.
I was confused and sad when I was trying to mock the TestManifest.active_tests() function to test BaseMarionetteTestRunner.add_test, and I was trying to mock it in the place it was defined, i.e. patch('manifestparser.manifestparser.TestManifest.active_tests').
Instead, I had to patch TestManifest within the runner.base module, i.e. the place where it was actually being called by the add_test function, i.e. patch('marionette.runner.base.TestManifest.active_tests').
So don’t be confused or sad, mock the thing where it is used, not where it was defined!
mock_openOne thing I find particularly annoying is writing tests for modules that have to interact with files. Well, I guess I could, like, write code in my tests that creates dummy files and then deletes them, or (even worse) just put some dummy files next to my test module for it to use. But wouldn’t it be better if I could just skip all that and pretend the files exist, and have whatever content I need them to have?
It sure would! And that’s exactly the type of thing mock is really helpful with. In fact, there’s even a helper called mock_open that makes it super simple to pretend to read a file. All you have to do is patch the builtin open function, and pass in mock_open(read_data="my data") to the patch to make the open in the code you’re testing only pretend to open a file with that content, instead of actually doing it.
To see it in action, you can take a look at a (not necessarily great) little test I wrote that pretends to open a file and read some data from it:
def test_nonJSON_file_throws_error(runner):
with patch('os.path.exists') as exists:
exists.return_value = True
with patch('__builtin__.open', mock_open(read_data='[not {valid JSON]')):
with pytest.raises(Exception) as json_exc:
runner._load_testvars() # This is the code I want to test, specifically to be sure it throws an exception
assert 'not properly formatted' in json_exc.value.message
See that patch('os.path.exists') in the test I just mentioned? Yeah, that’s probably not a great idea. At least, I found it problematic.
I was having some difficulty with a similar test, in which I was also patching os.path.exists to fake a file (though that wasn’t the part I was having problems with), so I decided to set a breakpoint with pytest.set_trace() to drop into the Python debugger and try to understand the problem. The debugger I use is pdb++, which just adds some helpful little features to the default pdb, like colors and sticky mode.
So there I am, merrily debugging away at my (Pdb++) prompt. But as soon as I entered the patch('os.path.exists') context, I started getting weird behavior in the debugger console: complaints about some ~/.fancycompleterrc.py file and certain commands not working properly.
It turns out that at least one module pdb++ was using (e.g. fancycompleter) was getting confused about file(s) it needs to function, because of checks for os.path.exists that were now all messed up thanks to my ill-advised patch. This had me scratching my head for longer than I’d like to admit.
What I still don’t understand (explanations welcome!) is why I still got this weird behavior when I tried to change the test to patch 'mymodule.os.path.exists' (where mymodule.py contains import os) instead of just 'os.path.exists'. Based on what we saw about namespaces, I figured this would restrict the mock to only mymodule, so that pdb++ and related modules would be safe - but it didn’t seem to have any effect whatsoever. But I’ll have to save that mystery for another day (and another post).
Still, lesson learned: if you’re patching a commonly used function, like, say, os.path.exists, don’t forget that once you’re inside that mocked context, you no longer have access to the real function at all! So keep an eye out, and mock responsibly!
Those are just a few of the things I’ve learned in my first few weeks of mocking. If you need some bedtime reading, check out these resources that I found helpful:
I’m sure mock has all kinds of secrets, magic, and superpowers I’ve yet to discover, but that gives me something to look forward to! If you have mock-foo tips to share, just give me a shout on Twitter!
|
|
Chris Ilias: Who uses voice control? |
Voice control (Siri, Google Now, Amazon Echo, etc.) is not a very useful feature to me, and wonder if I’m in the minority.
Why it is not useful:
The only times I use Siri are:
When I saw Apple introduce tvOS, the dependence on Siri turned me off from upgrading my Apple TV.
Am I in the minority here?
I get the feeling I’m not. I cannot recall anyone I know using Siri for other anything than entertainment with friends. Controlling devices with your voice in public must be Larry David’s worst nightmare.
|
|
Jen Kagan: day 18: the case of the missing vine api and the add-on sdk |
i’m trying to add vine support to min-vid and realizing that i’m still having a hard time wrapping my head around the min-vid program structure.
what does adding vine support even mean? it means that when you’re on vine.co, i want you to be able to right click on any video on the website, send it to the corner of your browser, and watch vines in the corner while you continue your browsing.
i’m running into a few obstacles. one obstacle is that i can’t find an official vine api. what’s an api? it stands for “application programming interface” (maybe? i think? no, i’m not googling) and i don’t know the official definition, but my unofficial definition is that the api is documentation i need from vine about how to access and manipulate content they have on their website. i need to be able to know the pattern for structuring video URLs. i need to know what functions to call in order to autoplay, loop, pause, and mute their videos. since this doesn’t exist in an official, well-documented way, i made a gist of their embed.js file, which i think/hope maybe controls their embedded videos, and which i want to eventually make sense of by adding inline comments.
another obstacle is that mozilla’s add-on sdk is really weirdly structured. i wrote about this earlier and am still sketching it out. here’s what i’ve gathered so far:
so far, i can get the vine video to show up in the panel, but only after i’ve sent a youtube video to the panel. i can’t the vine video to show up on its own, and i’m not sure why. this makes me sad. here is a sketch:

http://www.jkitppit.com/2016/06/15/day-18-the-case-of-the-missing-vine-api-and-the-add-on-sdk/
|
|
Doug Belshaw: Why we need 'view source' for digital literacy frameworks |
Apologies if this post comes across as a little jaded, but as someone who wrote their doctoral thesis on this topic, I had to stifle a yawn when I saw that the World Economic Forum have defined 8 digital skills we must teach our children.
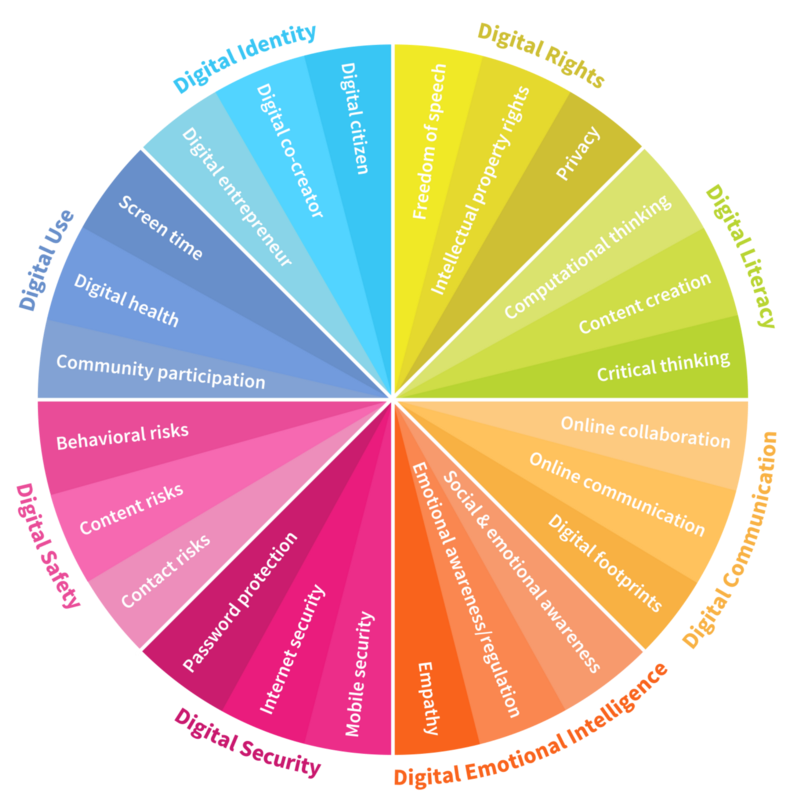
In a move so unsurprising that it’s beyond pastiche, they’ve also coined a new term:
Digital intelligence or “DQ” is the set of social, emotional and cognitive abilities that enable individuals to face the challenges and adapt to the demands of digital life.
I don’t mean to demean what is obviously thoughtful and important work, but I do wonder how (and who!) came up with this. They’ve got an online platform which helps develop the skills they’ve identified as important, but it’s difficult to fathom why some things were included and others left out.
An audit-trail of decision-making is important, as it reveals both the explicit and implicit biases of those involved in the work, as well as lazy shortcuts they may have taken. I attempted to do this in my work as lead of Mozilla’s Web Literacy Map project through the use of a wiki, but even that could have been clearer.
What we need is the equivalent of ‘view source’ for digital literacy frameworks. Specifically, I’m interested in answers to the following 10 questions:
I’d be interested in your thoughts and feedback around this post. Have you seen a digital literacy framework that does this well? What other questions would you add?
Note: I haven’t dived into the visual representation of digital literacy frameworks. That’s a whole other can of worms…
Get in touch! I’m @dajbelshaw and you can email me: hello@dynamicskillset.com
|
|
Mozilla Open Policy & Advocacy Blog: A Step Forward for Net Neutrality in the U.S. |
We’re thrilled to see the D.C. Circuit Court upholding the FCC’s historic net neutrality order, and the agency’s authority to continue to protect Internet users and businesses from throttling and blocking. Protecting openness and innovation is at the core of Mozilla’s mission. Net neutrality supports a level playing field, critical to ensuring a healthy, innovative, and open Web.
Leading up to this ruling Mozilla filed a joint amicus brief with CCIA supporting the order, and engaged extensively in the FCC proceedings. We filed a written petition, provided formal comments along the way, and engaged our community with a petition to Congress. Mozilla also organized global teach-ins and a day of action, and co-authored a letter to the President.
We’re glad to see this development and we remain steadfast in our position that net neutrality is a critical factor to ensuring the Internet is open and accessible. Mozilla is committed to continuing to advocate for net neutrality principles around the world.
https://blog.mozilla.org/netpolicy/2016/06/15/a-step-forward-for-net-neutrality-in-the-u-s/
|
|
Daniel Stenberg: No websockets over HTTP/2 |
There is no websockets for HTTP/2.
By this, I mean that there’s no way to negotiate or upgrade a connection to websockets over HTTP/2 like there is for HTTP/1.1 as expressed by RFC 6455. That spec details how a client can use Upgrade: in a HTTP/1.1 request to switch that connection into a websockets connection.
Note that websockets is not part of the HTTP/1 spec, it just uses a HTTP/1 protocol detail to switch an HTTP connection into a websockets connection. Websockets over HTTP/2 would similarly not be a part of the HTTP/2 specification but would be separate.
(As a side-note, that Upgrade: mechanism is the same mechanism a HTTP/1.1 connection can get upgraded to HTTP/2 if the server supports it – when not using HTTPS.)

There’s was once a draft submitted that describes how websockets over HTTP/2 could’ve been done. It didn’t get any particular interest in the IETF HTTP working group back then and as far as I’ve seen, there has been very little general interest in any group to pick up this dropped ball and continue running. It just didn’t go any further.
This is important: the lack of websockets over HTTP/2 is because nobody has produced a spec (and implementations) to do websockets over HTTP/2. Those things don’t happen by themselves, they actually require a bunch of people and implementers to believe in the cause and work for it.
Websockets over HTTP/2 could of course have the benefit that it would only be one stream over the connection that could serve regular non-websockets traffic at the same time in many other streams, while websockets upgraded on a HTTP/1 connection uses the entire connection exclusively.
So what do users do instead of using websockets over HTTP/2? Well, there are several options. You probably either stick to HTTP/2, upgrade from HTTP/1, use Web push or go the WebRTC route!
If you really need to stick to websockets, then you simply have to upgrade to that from a HTTP/1 connection – just like before. Most people I’ve talked to that are stuck really hard on using websockets are app developers that basically only use a single connection anyway so doing that HTTP/1 or HTTP/2 makes no meaningful difference.
Sticking to HTTP/2 pretty much allows you to go back and use the long-polling tricks of the past before websockets was created. They were once rather bad since they would waste a connection and be error-prone since you’d have a connection that would sit idle most of the time. Doing this over HTTP/2 is much less of a problem since it’ll just be a single stream that won’t be used that much so it isn’t that much of a waste. Plus, the connection may very well be used by other streams so it will be less of a problem with idle connections getting killed by NATs or firewalls.
The Web Push API was brought by W3C during 2015 and is in many ways a more “webby” way of doing push than the much more manual and “raw” method that websockets is. If you use websockets mostly for push notifications, then this might be a more convenient choice.
Also introduced after websockets, is WebRTC. This is a technique introduced for communication between browsers, but it certainly provides an alternative to some of the things websockets were once used for.
Websockets over HTTP/2 could still be done. The fact that it isn’t done just shows that there isn’t enough interest.
Recall how browsers only speak HTTP/2 over TLS, while websockets can also be done over plain TCP. In fact, the only way to upgrade a HTTP connection to websockets is using the HTTP/1 Upgrade: header trick, and not the ALPN method for TLS that HTTP/2 uses to reduce the number of round-trips required.
If anyone would introduce websockets over HTTP/2, they would then probably only be possible to be made over TLS from within browsers.
https://daniel.haxx.se/blog/2016/06/15/no-websockets-over-http2/
|
|
David Burns: Selenium WebDriver and Firefox 47 |
With the release of Firefox 47, the extension based version FirefoxDriver is no longer working. There was a change in Firefox that when Selenium started the browser it caused it to crash. It has been fixed but there is a process to get this to release which is slow (to make sure we don't break anything else) so hopefully this version is due for release next week or so.
This does not mean that your tests need to stop working entirely as there are options to keep them working.
Firstly, you can use Marionette, the Mozilla version of FirefoxDriver to drive Firefox. This has been in Firefox since about 24 as we, slowly working against Mozilla priorities, getting it up to Selenium level. Currently Marionette is passing ~85% of the Selenium test suite.
I have written up some documentation on how to use Marionette on MDN
I am not expecting everything to work but below is a quick list that I know doesn't work.
It would be great if we could raise bugs.
If you don't want to worry about Marionette, the other option is to downgrade to Firefox 45, preferably the ESR as it won't update to 47 and will update in about 6-9 months time to Firefox 52 when you will need to use Marionette.
Marionette will be turned on by default from Selenium 3, which is currently being worked on by the Selenium community. Ideally when Firefox 52 comes around you will just update to Selenium 3 and, fingers crossed, all works as planned.
http://www.theautomatedtester.co.uk/blog/2016/selenium-webdriver-and-firefox-47.html
|
|
Robert O'Callahan: Nastiness Works |
One thing I experienced many times at Mozilla was users pressuring developers with nastiness --- ranging from subtle digs to vitriolic abuse, trying to make you feel guilty and/or trigger an "I'll show you! (by fixing the bug)" response. I know it happens in most open-source projects; I've been guilty of using it myself.
I particularly dislike this tactic because it works on me. It really makes me want to fix bugs. But I also know one shouldn't reward bad behavior, so I feel bad fixing those bugs. Maybe the best I can do is call out the bad behavior, fix the bug, and avoid letting that same person use that tactic again.
Perhaps you're wondering "what's wrong with that tactic if it gets bugs fixed?" Development resources are finite so every bug or feature is competing with others. When you use nastiness to manipulate developers into favouring your bug, you're not improving quality generally, you're stealing attention away from other issues whose proponents didn't stoop to that tactic and making developers a little bit miserable in the process. In fact by undermining rational triage you're probably making quality worse overall.
|
|
Mitchell Baker: Expanding Mozilla’s Boards |
This post was originally published on the Mozilla Blog.
In a post earlier this month, I mentioned the importance of building a network of people who can help us identify and recruit potential Board level contributors and senior advisors. We are also currently working to expand both the Mozilla Foundation and Mozilla Corporation Boards.
The role of a Mozilla Board member
I’ve written a few posts about the role of the Board of Directors at Mozilla.
At Mozilla, we invite our Board members to be more involved with management, employees and volunteers than is generally the case. It’s not that common for Board members to have unstructured contacts with individuals or even sometimes the management team. The conventional thinking is that these types of relationships make it hard for the CEO to do his or her job. We feel differently. We have open flows of information in multiple channels. Part of building the world we want is to have built transparency and shared understandings.
We also prefer a reasonably extended “get to know each other” period for our Board members. Sometimes I hear people speak poorly of extended process, but I feel it’s very important for Mozilla. Mozilla is an unusual organization. We’re a technology powerhouse with a broad Internet openness and empowerment mission at its core. We feel like a product organization to those from the nonprofit world; we feel like a non-profit organization to those from the Internet industry.
It’s important that our Board members understand the full breadth of Mozilla’s mission. It’s important that Mozilla Foundation Board members understand why we build consumer products, why it happens in the subsidiary and why they cannot micro-manage this work. It is equally important that Mozilla Corporation Board members understand why we engage in the open Internet activities of the Mozilla Foundation and why we seek to develop complementary programs and shared goals.
I want all our Board members to understand that “empowering people” encompasses “user communities” but is much broader for Mozilla. Mozilla should be a resource for the set of people who care about the open Internet. We want people to look to Mozilla because we are such an excellent resource for openness online, not because we hope to “leverage our community” to do something that benefits us.
These sort of distinctions can be rather abstract in practice. So knowing someone well enough to be comfortable about these takes a while. We have a couple of ways of doing this. First, we have extensive discussions with a wide range of people. Board candidates will meet the existing Board members, members of the management team, individual contributors and volunteers. We’ve been piloting ways to work with potential Board candidates in some way. We’ve done that with Cathy Davidson, Ronaldo Lemos, Katharina Borchert and Karim Lakhani. We’re not sure we’ll be able to do it with everyone, and we don’t see it as a requirement. We do see this as a good way to get to know how someone thinks and works within the framework of the Mozilla mission. It helps us feel comfortable including someone at this senior level of stewardship.
What does a Mozilla Board member look like
Job descriptions often get long and wordy. We have those too but, for the search of new Board members, we’ve tried something else this time: a visual role description.

Board member job description for Mozilla Corporation

Board member job description for Mozilla Foundation
Here is a short explanation of how to read these visuals:
I invite you to look at these documents and provide input on them. If you have candidates that you believe would be good Board members, send them to the boarddevelopment@mozilla.com mailing list. We will use real discretion with the names you send us.
We’ll also be designing a process for how to broaden participation in the process beyond other Board members. We want to take advantage of the awareness and the cluefulness of the organization. That will be part of a future update.
http://blog.lizardwrangler.com/2016/06/14/expanding-mozillas-boards/
|
|
The Mozilla Blog: Expanding Mozilla’s Boards |
In a post earlier this month, I mentioned the importance of building a network of people who can help us identify and recruit potential Board level contributors and senior advisors. We are also currently working to expand both the Mozilla Foundation and Mozilla Corporation Boards.
The role of a Mozilla Board member
I’ve written a few posts about the role of the Board of Directors at Mozilla.
At Mozilla, we invite our Board members to be more involved with management, employees and volunteers than is generally the case. It’s not that common for Board members to have unstructured contacts with individuals or even sometimes the management team. The conventional thinking is that these types of relationships make it hard for the CEO to do his or her job. We feel differently. We have open flows of information in multiple channels. Part of building the world we want is to have built transparency and shared understandings.
We also prefer a reasonably extended “get to know each other” period for our Board members. Sometimes I hear people speak poorly of extended process, but I feel it’s very important for Mozilla. Mozilla is an unusual organization. We’re a technology powerhouse with a broad Internet openness and empowerment mission at its core. We feel like a product organization to those from the nonprofit world; we feel like a non-profit organization to those from the Internet industry.
It’s important that our Board members understand the full breadth of Mozilla’s mission. It’s important that Mozilla Foundation Board members understand why we build consumer products, why it happens in the subsidiary and why they cannot micro-manage this work. It is equally important that Mozilla Corporation Board members understand why we engage in the open Internet activities of the Mozilla Foundation and why we seek to develop complementary programs and shared goals.
I want all our Board members to understand that “empowering people” encompasses “user communities” but is much broader for Mozilla. Mozilla should be a resource for the set of people who care about the open Internet. We want people to look to Mozilla because we are such an excellent resource for openness online, not because we hope to “leverage our community” to do something that benefits us.
These sort of distinctions can be rather abstract in practice. So knowing someone well enough to be comfortable about these takes a while. We have a couple of ways of doing this. First, we have extensive discussions with a wide range of people. Board candidates will meet the existing Board members, members of the management team, individual contributors and volunteers. We’ve been piloting ways to work with potential Board candidates in some way. We’ve done that with Cathy Davidson, Ronaldo Lemos, Katharina Borchert and Karim Lakhani. We’re not sure we’ll be able to do it with everyone, and we don’t see it as a requirement. We do see this as a good way to get to know how someone thinks and works within the framework of the Mozilla mission. It helps us feel comfortable including someone at this senior level of stewardship.
What does a Mozilla Board member look like
Job descriptions often get long and wordy. We have those too but, for the search of new Board members, we’ve tried something else this time: a visual role description.
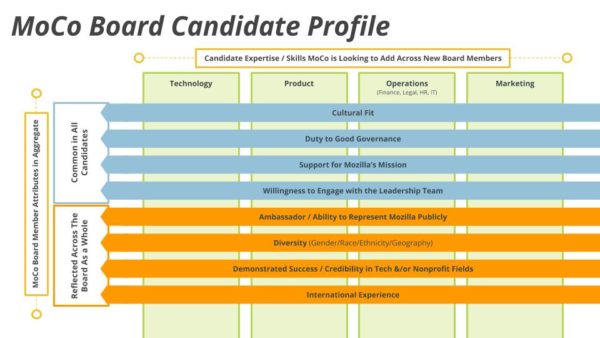
Board member job description for Mozilla Corporation
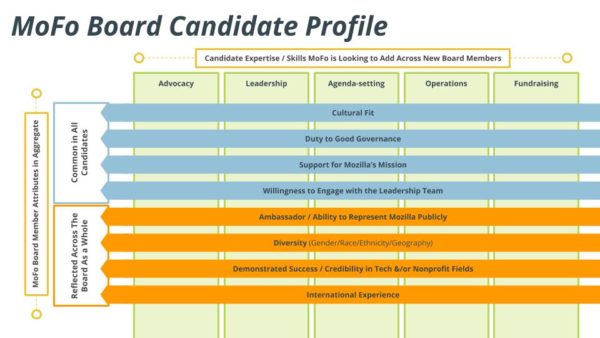
Board member job description for Mozilla Foundation
Here is a short explanation of how to read these visuals:
I invite you to look at these documents and provide input on them. If you have candidates that you believe would be good Board members, send them to the boarddevelopment@mozilla.com mailing list. We will use real discretion with the names you send us.
We’ll also be designing a process for how to broaden participation in the process beyond other Board members. We want to take advantage of the awareness and the cluefulness of the organization. That will be part of a future update.
https://blog.mozilla.org/blog/2016/06/14/expanding-mozilla-boards/
|
|
Robert O'Callahan: "Safe C++ Subset" Is Vapourware |
In almost every discussion of Rust vs C++, someone makes a comment like:
the subset of C++14 that most people will want to use and the guidelines for its safe use are already well on their way to being defined ... By following the guidelines, which can be verified statically at compile time, the same kind of safeties provided by Rust can be had from C++, and with less annotation effort.This promise is vapourware. In fact, it's classic vapourware in the sense of "wildly optimistic claim about a future product
(FWIW the claim quoted above is actually an overstatement of the goals of the C++ Core Guidelines to which it refers, which say "our design is a simpler feature focused on eliminating leaks and dangling only"; Rust provides important additional safety properties such as data-race freedom. But even just the memory safety claim is vapourware.)
To satisfy this claim, we need to see a complete set of statically checkable rules and a plausible argument that a program adhering to these rules cannot exhibit memory safety bugs. Notably, languages that offer memory safety are not just claiming you can write safe programs in the language, nor that there is a static checker that finds most memory safety bugs; they are claiming that code written in that language (or the safe subset thereof) cannot exhibit memory safety bugs.
AFAIK the closest to this C++ gets is the Core Guidelines Lifetimes I and II document, last updated December 2015. It contains only an "informal overview and rationale"; it refers to "Section III, analysis rules (forthcoming this winter)", which apparently has not yet come forth. (I'm pretty sure they didn't mean the New Zealand winter.) The informal overview shows a heavy dependence on alias analysis, which does not inspire confidence because alias analysis is always fragile. The overview leaves open critical questions about even trivial examples. Consider:
unique_ptrObviously this program is unsafe and must be forbidden, but what rule would reject it? The document saysp;
void foo(const int& v) {
p = nullptr;
cout << v;
}
void bar() {
p = make_unique(7);
foo(*p);
}
Clearly the body of foo is OK by those rules. For the call to foo from bar, it depends on what is meant by "anything that could be invalidated by the function". Does that include anything reachable via global variables? Because if it does, then you can't pass anything reachable from a global variable to any function by reference, which is crippling. But if it doesn't, then what rejects this code?
- In the function body, by default a Pointer parameter param is assumed to be valid for the duration of the function call and not depend on any other parameter, so at the start of the function lset(param) = param (its own lifetime) only.
- At a call site, by default passing a Pointer to a function requires that the argument’s lset not include anything that could be invalidated by the function.
Update Herb points out that example 7.1 covers a similar situation with raw pointers. That example indicates that anything reachable through a global variable cannot be passed by to a function by raw-pointer or reference. That still seems like a crippling limitation to me. You can't, for example, copy-construct anything (indirectly) reachable through a global variable:
unique_ptrp;
void bar() {
p = make_unique(...);
Foo xyz(*p); // Forbidden!
}
This is not one rogue example that is easily addressed. This example cuts to the heart of the problem, which is that understanding aliasing in the face of functions with potentially unbounded side effects is notoriously difficult. I myself wrote a PhD thesis on the subject, one among hundreds, if not thousands. Designing your language and its libraries from the ground up to deal with these issues has been shown to work, in Rust at least, but I'm deeply skeptical it can be bolted onto C++.
Aren't clang and MSVC already shipping previews of this safe subset? They're implementing static checking rules that no doubt will catch many bugs, which is great. They're nowhere near demonstrating they can catch every memory safety bug.
Aren't you always vulnerable to bugs in the compiler, foreign code, or mistakes in the safety proofs, so you can never reach 100% safety anyway? Yes, but it is important to reduce the amount of trusted code to the minimum. There are ways to use machine-checked proofs to verify that compilation and proof steps do not introduce safety bugs.
Won't you look stupid when Section III is released? Occupational hazard, but that leads me to one more point: even if and when a statically checked, plausibly safe subset is produced, it will take significant experience working with that subset to determine whether it's viable. A subset that rejects core C++ features such as references, or otherwise excludes most existing C++ code, will not be very compelling (as acknowledged in the Lifetimes document: "Our goal is that the false positive rate should be kept at under 10% on average over a large body of code").
http://robert.ocallahan.org/2016/06/safe-c-subset-is-vapourware.html
|
|
Jen Kagan: day 16: helpful git things |
it’s been important for me to get comfortable-ish with git. i’m slowly learning about best practices on a big open source project that’s managed through github.
one example: creating a separate branch for each feature i work on. in the case of min-vid, this means i created one branch to add youtu.be support, a different branch to add to the project’s README, a different branch to work on vine support, etc. that way, if my changes aren’t merged into the main project’s master, i don’t have to re-clone the project. i just keep working on the branch or delete it or whatever. this also lets me bounce between different features if i get stuck on one and need to take a break by working on another one. i keep the workflow on a post-it on my desktop so i don’t have to think about it (a la atul gawande’s so good checklist manifesto):
git checkout master
git pull upstream master
(to get new changes from the main project’s master branch)
git push origin master
(to push new changes up to my own master branch)
git checkout -b [new branch]
(to work on a feature)
npm run package
(to package the add-on before submitting the PR)
git add .
git commit -m '[commit message]
git push origin [new branch]
(to push my changes to my feature branch; from here, i can submit a PR)
git checkout master
another important git practice: squashing commits so my pull request doesn’t include 1000 commits that muddy the project history with my teensy changes. this is the most annoying thing ever and i always mess it up and i can’t even bear to explain it because this person has done a pretty good job already. just don’t ever ever forget to REBASE ON TOP OF MASTER, people!
last thing, which has been more important on my side project that i’m hosting on gh-pages: updating my gh-pages branch with changes from my master branch. this is crucial because the gh-pages branch, which displays my website, doesn’t automatically incorporate changes i make to my index.html file on my master branch. so here’s the workflow:
git checkout master
(work on stuff on the master branch)
git add .
git commit -m '[commit message]'
git push origin master
(the previous commands push your changes to your master branch. now, to update your gh-pages branch:)
git checkout gh-pages
git merge master
git push origin gh-pages
yes, that’s it, the end, congrats!
p.s. that all assumes that you already created a gh-pages branch to host your website. if you haven’t and want to, here’s how you do it:
git checkout master
(work on stuff on the master branch)
git add .
git commit -m '[message]'
git push origin master
(same as before. this is just normal, updating-your-master-branch stuff. so, next:)
git checkout -b gh-pages
(-b creates a new branch, gh-pages names the new branch “gh-pages”)
git push origin gh-pages
(this pushes changes from your origin/master branch to your new gh-pages branch)
yes, that’s it, the end, congrats!
http://www.jkitppit.com/2016/06/13/day-16-helpful-git-things/
|
|
Air Mozilla: Hackathon Open Democracy Now Day 2 |
 Hackathon d'ouverture du festival Futur en Seine 2016 sur le th`eme de la Civic Tech.
Hackathon d'ouverture du festival Futur en Seine 2016 sur le th`eme de la Civic Tech.
|
|
Robert O'Callahan: Some Dynamic Measurements Of Firefox On x86-64 |
This follows up on my previous measurements of static properties of Firefox code on x86-64 with some measurements of dynamic properties obtained by instrumenting code. These are mostly for my own amusement but intuitions about how programs behave at the machine level, grounded in data, have sometimes been unexpectedly useful.
Dynamic properties are highly workload-dependent. Media codecs are more SSE/AVX intensive than regular code so if you do nothing but watch videos you'd expect qualitatively different results than if you just load Web pages. I used a mixed workload that starts Firefox (multi-process enabled, optimized build), loads the NZ Herald, scrolls to the bottom, loads an article with a video, plays the video for several seconds, then quits. It ran for about 30 seconds under rr and executes about 60 billion instructions.
I repeated my register usage result analysis, this time weighted by dynamic execution count and taking into account implicit register usage such as push using rsp. The results differ significantly on whether you count the consecutive iterations of a repeated string instruction (e.g. rep movsb) as a single instruction execution or one instruction execution per iteration, so I show both. Unlike the static graphs, these results for all instructions executed anywhere in the process(es), including JITted code, not just libxul.


I was also interested in exploring the distribution of instruction execution frequencies:

A dot at position x, y on this graph means that fraction y of all instructions executed at least once is executed at most x times. So, we can see that about 19% of all instructions executed are executed only once. About 42% of instructions are executed at most 10 times. About 85% of instructions are executed at most 1000 times. These results treat consecutive iterations of a string instruction as a single execution. (It's hard to precisely define what it means for an instruction to "be the same" in the presence of dynamic loading and JITted code. I'm assuming that every execution of an instruction at a particular address in a particular address space is an execution of "the same instruction".)
Interestingly, the five most frequently executed instructions are executed about 160M times. Those instructions are for this line, which is simply filling a large buffer with 0xff000000. gcc is generating quite slow code:
132e7b2: cmp %rax,%rdxThat's five instructions executed for every four bytes written. This could be done a lot faster in a variety of different ways --- rep stosd or rep stosq would probably get the fast-string optimization, but SSE/AVX might be faster.
132e7b5: je 132e7d1
132e7b7: movl $0xff000000,(%r9,%rax,4)
132e7bf: inc %rax
132e7c2: jmp 132e7b2
http://robert.ocallahan.org/2016/06/some-dynamic-measurements-of-firefox-on.html
|
|
Air Mozilla: Hackathon Open Democracy Now |
Hackathon d'ouverture du festival Futur en Seine 2016 sur le th`eme de la Civic Tech.
|
|
Robert O'Callahan: Are Dynamic Control-Flow Integrity Schemes Worth Deploying? |
Most exploits against C/C++ code today rely on hijacking CPU-level control flow to execute the attacker's code. Researchers have developed schemes to defeat such attacks based on the idea of control flow integrity: characterize a program's "valid control flow", and prevent deviations from valid control flow at run time. There are lots of CFI schemes, employing combinations of static and dynamic techniques. Some of them don't even call themselves CFI, but I don't have a better term for the general definition I'm using here. Phrased in this general way, it includes control-transfer instrumentation (CCFIR etc), pointer obfuscation, shadow stacks, and even DEP and ASLR.
Vendors of C/C++ software need to consider whether to deploy CFI (and if so, which scheme). It's a cost/benefit analysis. The possible benefit is that many bugs may become significantly more difficult --- or even impossible --- to exploit. The costs are complexity and run-time overhead.
A key question when evaluating the benefit is, how difficult will it be for CFI-aware attackers to craft exploits that bypass CFI? That has two sub-questions: how often is it possible to weaponize a memory-safety bug that's exploited via control-flow hijacking today, with an exploit that is permitted by the CFI scheme? And, crucially, will it be possible to package such exploitation techniques so that weaponizing common C/C++ bugs into CFI-proof exploits becomes cheap? A very interesting paper at Oakland this year, and related work by other authors, suggests that the answer to the first sub-question is "very often" and the answer to the second sub-question is "don't bet against it".
Coincidentally, Intel has just unveiled a proposal to add some CFI features to their CPUs. It's a combination of shadow stacks with dynamic checking that the targets of indirect jumps/calls are explicitly marked as valid indirect destinations. Unlike some more precise CFI schemes, you only get one-bit target identification; a given program point is a valid destination for all indirect transfers or none.
So will CFI be worth deploying? It's hard to say. If you're offered a turnkey solution that "just works" with negligible cost, there may be no reason not to use it. However, complexity has a cost, and we've seen that sometimes complex security measures can even backfire. The tail end of Intel's document is rather terrifying; it tries to enumerate the interactions of their CFI feature with all the various execution modes that Intel currently supports, and leaves me with the impression that they're generally heading over the complexity event horizon.
Personally I'm skeptical that CFI will retain value over the long term. The Oakland DOP paper is compelling, and I think we generally have lots of evidence that once an attacker has a memory safety bug to work on, betting against the attacker's ingenuity is a loser's game. In an arms race between dynamic CFI (and its logical extension to dynamic data-flow integrity) and attackers, attackers will probably win, not least because every time you raise the CFI bar you'll pay with increased complexity and overhead. I suggest that if you do deploy CFI, you should do so in a way that lets you pull it out if the cost-benefit equation changes. Baking it into the CPU does not have that property...
One solution, of course, is to reduce the usage of C/C++ by writing code in a language whose static invariants are strong enough to give you CFI, and much stronger forms of integrity, "for free". Thanks to Rust, the old objections that memory-safe languages were slow, tied to run-time support and cost you control over resources don't apply anymore. Let's do it.
http://robert.ocallahan.org/2016/06/is-control-flow-integrity-worth.html
|
|