Mozilla Reps Community: New council members – Winter 2015 |
We are happy to announce that the four new members of the Council have been already on boarded.




Welcome Umesh, Faisal, Rara and Arturo! They bring with them skills they have picked up as Reps mentors, and as community leaders both inside Mozilla and in other fields. A HUGE thank you to the outgoing council members – San James, Luis, Ankit and Bob. We are hoping you continue to use your talents and experience to continue in a leadership role in Reps and Mozilla.
The new members have been gradually on boarded during the last 3 weeks.
The Mozilla Reps Council is the governing body of the Mozilla Reps Program. It provides the general vision of the program and oversees day-to-day operations globally. Currently, 7 volunteers and 2 paid staff sit on the council. Find out more on the ReMo wiki.
Congratulate new Council members on this Discourse topic!
https://blog.mozilla.org/mozillareps/2016/01/11/new-council-members-winter-2015/
|
|
David Burns: Public Source vs Open Source |
A few weeks ago I had an interesting conversation on twitter and then on instant messaging about a bit of software that was open sourced. Some thought, and might still do, the new piece of software might not be supported.
There was also recently a good blog post from James Long about how it can be hard to create open source code and then maintain it. Either life gets in the way or another project gets in the way.
I have always had a different view of code to most people. The idea is simple, at least in my head.
The idea of Open Source has changed over the years and this has meant the original meaning is not quite right. Open Source has started to have a certain aspect of community involved, from people submitting patches (PRs on Github).
Projects that have been around for a very long time have organically grown some kind of community. These tend to be people who believe in the project or see other people working on it that they get to know. We see meet ups forming as more an more people get involved.
This is best part of be source code! The openness with people and code all wrapped up in one!
However, not all code out in the open will achieve this! (And this is fine, not all pieces of code need to have community. Imagine if every package on NPM had a meet up!?!?).
Public source everything that open source has minus all community side of things. A really good example of Public Source is Android. You can see all the code, you derive your own work but want to submit a patch? Well Cryogen might take it but Google, seemingly, don't care.
Also, most projects on Github probably fall under this category. Especially if the person is a starter and not a maintainer, to use James' concept.
The thing to remember is that everyone wins when the code is in the public but before you start getting all hung up on "support" from people who have given up the code, and their time, to put it out there remember that open source needs to grow from public source!
http://www.theautomatedtester.co.uk/blog/2016/public-source-vs-open-source.html
|
|
Nick Cameron: Abstract return types, aka `impl Trait` |
There has been an idea around for a long time that we should allow functions to specify bounds on their return types, rather than give a concrete type. This has many benefits - better abstraction, less messy signatures, and so forth.
A function can take an argument by value or reference by choosing between generics and trait objects. This leads to either static or dynamic dispatch, the former at the cost of monomorphising the function. However, this doesn't work for return types, since the callee, not the caller decides on the concrete type. Therefore, the function must return a concrete type or a trait object, there is no generic, by value option.
This blog post by Aaron Turon and RFC PRs 105 and 1305 provide more background, and some design ideas.
I wanted to explore some of the details, and especially how we might consider such types in type-theoretic terms. I'm mostly going to explore an approach which could be considered a compromise between the inference and abstract type ideas from Aaron's blog, erring more on the side of abstract types. I believe Aaron has been pondering a similar approach, but I'm not sure if we agree on the details.
I thought I'd make an RFC out of this, but in the end, it doesn't seem different enough from existing proposals to warrant it. Still, I thought some of my observations might be useful.
The general idea is simple: you write impl T as the return type for a function, where T is a trait (impl T is strawman syntax, but I don't want to get in to syntax issues here). This means that the function returns some implementation of T. The caller must treat the returned value as just an instance of some implicit type variable X where X: T.
Although the type is only bounded, there must be just one concrete type. If there are data types A and B, both of which implement T, and function foo has the return type impl T. It is not OK for foo to return A in one branch and B in another, the programmer must choose one data type and return a value of that type in all branches.
An interesting design choice is whether the programmer must declare this concrete type or whether it is inferred. Some kind of inference is preferable, since part of the motivation is dealing with types which are painful to write (iterators) or impossible to write (closures).
To see why we must only return one type, consider the caller: let x = foo();. The compiler must be able to reserve enough room on the stack for x, for which it needs to know at code generation time the exact size of the value returned from foo. Part of the motivation here is to avoid trait objects, so we want to store x by value, not as a pointer. If foo could return different types depending on the branch taken at runtime, the compiler can't know the size of x. (We also need to know the type to be able to look up methods called on x, so even if A and B have the same sizes, we can't allow foo to return both).
It is worth making a distinction between using impl Type with functions and with trait methods. With trait methods there are some extra issues. If we declare a trait method to have impl Type as a return type, we would like each implementation to be able to return a different concrete type.
Furthermore, in the presence of specialisation, we would like specialised implementations to be able to return different concrete types. Part of the motivation for this is to support use cases which could be handled by specialising associated types, however, it is not clear how specialising associated types should work - none of the options are particularly attractive (see discussion for more details). My favoured option is not to support it at all. So having impl Trait as an alternative would be useful.
So, in the trait method case, although we want each function to return only one concrete type, we want each implementation of a method signature to be able to return different concrete types. That is selecting the concrete type happens when we implement a method, not when we declare it.
In working out the details for impl Trait it would be useful to have an idea of a formal representation (a lowering into a core Rust language). There seem two choices: either existential types or associated types.
The idea that we must pick a single concrete type (witness) and hide it with an abstract type known only by its bounds immediately suggests existential types. One could imagine impl T as something like exists.X (as we'll see below, this is not quite right).
On the other hand, considering trait methods, there is an approach using associated types. This is attractive because associated types already exist in Rust (as opposed to existential types) and because it has the obviously correct behaviour when considering different impls of a trait.
So a trait Foo with method foo returning impl T would be represented as:
trait Foo {
type X: T;
fn foo(&self) -> Self::X;
}
impl Foo {
type X = ConcreteType;
fn foo(&self) -> Self::X { ... }
}
However, the downside of this approach is that it does not extend to free functions. It also has a problem with specialisation - if we want to forbid specialising associated types, then we cannot return a different type from methods in specialised implementations.
(Niko has proposed treating impl Trait as a group of a function and an associated type, where specialising one means specialising the other. This seems so close to re-inventing existential types to me that I think it is profitable to investigate a pure existential types approach).
Therefore, let us consider an existential type-like approach. I'm not actually proposing adding such a type to Rust, only using it as a tool for understanding (and possibly implementation).
RFC PR 1305 actually proposes adding something like this to Rust. Since the goal is different (a programming language feature rather than a tool for formalisation), the approaches are a bit different.
Let's start with some syntax: we'll make the universal quantification in function signatures explicit using for.Sig. So a function in Rust fn foo(x: &X) is written fn foo for.(x: &X). Likewise, we'll allow existential quantification using exists.
A function with an impl Trait return type, e.g., fn foo() -> impl Clone is written fn foo exists.() -> X. Note that the quantification is outside the whole signature, not just around the return type.
In a generic function we want to be able to use the function's type parameters in the impl Trait return type, so any universal quantification must come before the existential quantification. E.g., fn foo is written fn foo for.
So far, the extension to trait methods is trivial.
Existential types are introduced using a pack expression and eliminated using an unpack expression. The syntax of these is pack (T, e) as exists.U (where e is the expression being packed, T is the witness type that will be hidden by X and B* are bounds on X) and unpack e as (X, x) in e' (where e is the expression being unpacked, e' is the scope of the unpacking, x is a variable with scope e' with type X (also with scope e', and with bounds from the type of e)). (If you're interested, the type rules and semantics for existential types are standard and can be found online or in a textbook, I recommend TaPL by Pierce).
I propose that packing can only take place on functions and occurs where the function is implemented. I.e., in a pack expression, e must always be an entire function.
An existential function must be unpacked before it can be called. The scope of the unpack expression must include any uses of the value returned from the function. Since we do not support packing arbitrary expressions, the only way to take the returned value out of the scope is to make it into a trait object (which are, fundamentally, also existential types, but of a different flavour).
In real Rust, packing is implicit, and the witness type of pack expressions and the scope of unpack expressions would be inferred by the compiler. We make them explicit in this formal model.
For example, consider the Rust functions
fn foo() -> impl Clone {
Bar::new() // : Bar, where Bar: Clone
}
fn main() {
let x: impl Clone = foo();
...
let y: &Clone = &x;
...
}
These would be encoded as
fn foo exists.() -> X =
pack (Bar, fn() -> Bar { // Note hand-waving anon function syntax
Bar::new()
}) as exists.Fn_4a5f() -> X;
// Note, using Fn_4a5f to mean an anonymous function type.
fn main() {
let y: &Clone = unpack foo() as (Z, z) in {
let x: Z = z;
...
&x
};
...
}
So far, this is a pretty standard use of existential types. Rust has an additional requirement that often complicates such formal treatments though - we must be able to statically know the types (and sizes) of all values. (Trait objects are an escape hatch here, but not relevant to this case).
In formal terms, I believe this constraint can be thought of as: all unpack expressions can be eliminated after monomorphisation. I.e., we allow applying the pack/'unpack' reduction rule during code generation (after monomorphisation). After which there must be no remaining unpack expressions. My conjecture is that we can choose rules for the use of impl Trait such that this is true for any program that type checks.
That reduction rule looks like
unpack (pack (T, e) as exists.U) as (X, x) in e'
---->
[e/x, T/X]e'
For this to work, we must suppose that monomorphisation 'inline's the pack expression from an existential function. That seems like a reasonable counterpart to monomorphisation of universally quantified functions.
Continuing the above example, after monomorphisation our main function looks like
fn main() {
let y: &Clone = unpack
(pack (Bar, foo'()) as exists.Fn_4a5f() -> X)
as (Z, z) in {
let x: Z = z;
...
&x
};
...
}
I'm using foo' as shorthand for the inner function in the declaration of foo. This is analogous to the monomophised version of a generic function, but in this case there is no need to actually generate monomorphised code, the 'generic' code is exactly what is needed.
Then after applying the reduction rule:
fn main() {
let y: &Clone = {
let x: Bar = foo'();
...
&x
};
...
}
No unpacks left - means we statically know the types we require. Also note that the call foo'() is just the call foo().
Finally, lets look at first-class functions, we could write let f = &foo; to get a function pointer to foo, if foo is defined as above, what is the type? And where does unpacking happen?
Rust does not allow generic function types and functions must be explicitly monomorphised before we can reference them, e.g., let f = bar::. The rules for existential quantification should follow: function types may not include existential quantifiers and the function must be unpacked before we take a reference. So, let f = &foo; is more explicitly thought of as
unpack foo as (Z, z) in {
let f = &z; // f: &Z, where Z: Clone (from the signature of foo)
}
Note that just because we have made a function pointer, does not mean that f can escape the scope of the unpack, we must use f within that scope only. We can pass it to a higher-order function with a signature like
fn bar(f: &F)
where F: Fn() -> Y,
Y: Clone
{
...
}
A more flexible alternative would be to allow existentially quantified function types. In the surface syntax we would allow Fn() -> impl Clone as a type. In the formal model, let f = &foo; is unchanged, and f has type &exists.Fn() -> X. We must then unpack f before it is called:
// let x = f(); becomes
unpack f as (Z, z) in { // z: &Fn() -> Z
let x = z(); // x: Z
}
Clearly, x cannot escape the scope of this unpack. Note there is a little hand-waving here around the reference type - I silently moved the & inside the quantifier before unpacking.
However, if f is an argument to a function, then even after monomorphising, we cannot eliminate the unpack - we have no corresponding pack expression to eliminate it with. So this fails our test for how existentials can be used. At a less theoretical level, this also makes sense - how can we know the type and size of z when f is known only by its type? Thus, we must take the earlier approach.
So far, we've only considered free functions, but trait methods follow quite easily - a method declaration has the existential type you would expect, but no packing. Any implementation must have the same type and must include a pack. Default methods must also pack, but this is part of the default body, not the signature.
When calling a trait method, if we have the static type of the receiver (i.e., calling using UFCS or method call syntax on an object with concrete type) then calling is exactly the same as for free functions.
Where the receiver is generic things work, but are a little more complicated. Time for another example:
trait Foo {
fn foo(&self) -> impl Clone;
}
impl Foo for A {
fn foo(&self) -> impl Clone {
...
}
}
fn bar(x: X) {
let a = x.foo(); // a: impl Clone
let _b = a.clone();
}
which is encoded as
trait Foo {
fn foo exists.(&self) -> X;
}
impl Foo for A {
fn foo exists.(&self) -> X = pack (Bar, {
fn(&self) -> Bar {
...
}
}) as exists.(&Self) -> X
}
fn bar(x: X) {
unpack X::foo as (Z, z) in { // Z: Clone, z: Fn(&X) -> Z
let a = z(x); // a: Z
let _b = a.clone();
}
}
And when we monomorphise the universal quantification of bar, substituting A we get
fn bar(x: A) {
unpack ::foo as (Z, z) in { // Z: Clone, z: Fn(&A) -> Z
let a = z(x); // a: Z
let _b = a.clone();
}
}
And then monomorphising the existential quantification
fn bar(x: A) {
unpack (pack (Bar, foo') as exists...) as (Z, z) in {
let a = z(x); // a: Z
let _b = a.clone();
}
}
And applying the pack/unpack reduction rules gives
fn bar(x: A) {
{
let a = foo'(x); // a: Bar
let _b = a.clone();
}
}
No unpack remains, so we're all good.
The third way to call a trait method is via a trait object, e.g., &Foo. However, in this case there is no monomorphisation to do, and so we would end up with unpacks left in the program at code generation time that we can't eliminate. This means we cannot allow impl Trait methods to be called on trait objects. Likewise, in intuitive terms, how could we know the size of the result if we don't know which implementation of the method is called until runtime?
Thus, methods which return impl Trait must make a trait not object safe.
One of the requirements for impl Trait was that it should work with specialisation, that is a specialised method implementation can return a different concrete type compared with the less specialised version.
I won't go through another example here, but that works out just fine. Each implementation does its own pack, so there is no constraint for the concrete/witness types to be the same. Even with specialisation, after monomorphisation we have a concrete type for the impl and thus a single method, and so we can eliminate unpacks. As long as we don't have trait objects, we're fine.
An OIBIT is the worst-named feature in Rust - they are neither opt-in, nor built-in types. But they are types which are automatically derived. One issue with impl Trait is that we want OIBITs to leak to the abstract type without having to name them.
In the existential model we can make this work in a kind of principled way: if the caller is generic, then we can assume only the explicit bounds, e.g., if we call x.foo() where x: X and X: Foo and foo: (&self) -> impl Clone, then we can only assume the bound Clone. However, if we have a fully explicit type, e.g., x: A where A is a struct which impls Foo, then we can assume any OIBIT bounds from the witness type.
To be precise, the formal body for foo will look like
impl Foo for A {
fn foo exists.(&self) -> X = pack (Bar, {
fn(&self) -> Bar {
...
}
}) as exists.(&Self) -> X
}
Here the witness type is Bar. But in real Rust, this would all be inferred, as long as Bar implements Send, for example, then we could infer
impl Foo for A {
fn foo exists.(&self) -> X = pack (Bar, {
fn(&self) -> Bar {
...
}
}) as exists.(&Self) -> X
}
Note the type in the pack expression. We rely on subtyping that
exists.(&Self) -> X <: exists.(&Self) -> X
Now in the caller of foo, we only have the abstract type exists.(&Self) -> X, but (since the code is not generic) we can inline the pack from the function definition at type checking, rather than during monomorphisation. We'll have something like:
unpack (pack (Bar, foo'()) as exists.Fn_4a5f() -> X) as (Z, z) in { ... }
Now we can type-check the body (...) with Z: Clone + Send (taking the bounds from the pack expression), rather than Z: Clone (from the function type). Note that we don't want to actually do the pack/unpack reduction at this stage, because then we would substitute the witness type for the abstract type (e.g., Bar for Z) and that would allow the caller to access methods and fields of the witness type that should have been abstracted away.
A conditional bound is of the form X: A => Y: B or Y: B if X: A or something. They are a way of saying a bound only holds if another does. These are useful in conjunction with impl Trait (in fact, they might only be useful with impl Trait), for example,
trait Foo {
fn foo(&self) -> impl Clone + (Baz if Self: Bar);
}
Now, if we implement Foo for A and A is Bar, then the type returned from foo implements Baz, otherwise it does not.
Obviously adding conditional bounds would be a big addition to Rust and would require a fair bit of design and implementation work. I'm not aware of a theoretical underpinning for them. They do seem to me to be orthogonal to the existential model of impl Trait. If we can make them work in the general case, then I think they should work with impl Trait as outlined here without much hassle.
impl Type in other positionsWe have so far only discussed using impl Trait in return type position where the existential quantifier would implicitly cover the function signature.
I have also used impl Trait as the type of variables taking values returned from such functions. In this case, impl Trait means the opened existential type. These types have different semantics, in particular, subtyping is reflexive for impl Trait in function types, but not (necessarily) for local variables. E.g.,
let a: impl Foo = ...; // desugared to X where X: Foo
let b: impl Foo = ...; // desugared to Y where Y: Foo
assert!(type_of::() == type_of::()); // Might fail, depending on the ...s
We could allow the compiler to infer the desugared variables with the right scopes, so if b = a.clone(), then a and b would be type compatible, but if a and b were separate calls to foo, then they would be type incompatible. I believe this is perfectly possible to implement, but the semantics here are pretty confusing. In particular, we have types which are expressible, but not denotable. Java wildcards also introduced such types and they caused much confusion in the Java world.
On the other hand it is certainly desirable to assign the result of an impl Trait function into a variable and whether we can write the type or not, it still exists. An alternative is to introduce syntax for a new type, however, without making the scope of unpacks explicit (which seems undesirable), we still have types which are expressible but not denotable.
In the case of fields, statics and consts, and function arguments, I think that the existential notion of impl Trait is a very simple sugar for adding a type parameter with the same bounds at the nearest scope. E.g., fn foo(x: impl Clone) { ... } is equivalent to fn foo(x: X) where X is not used elsewhere. (This conversion is a simple kind of skolemisation. Return types can't be skolemised like this because the witness type/actual type parameter is chosen by the callee, not the caller).
So, that makes three different meanings for impl Trait, which seems excessive. Although, I guess they are each useful in their way. I think that we can probably get away with the three different uses without anyone getting too confused - the intuition for what will happen in each case seems about right (except for type compatibility for local variables, but I don't see a way to avoid that). However, this situation does not make me very happy.
Since type aliases are effectively erased before type checking, impl Trait should be usable on the right-hand side of a type alias. Where that type alias is used may be restricted.
It is also fine to use impl Trait as an actual type parameter - thanks to monomorphisation, everything should just work with regards to code generation. If the corresponding formal type parameter is used as the return type of the function, then the implicit pack (and corresponding unpack at the call site) are assumed to only exist where the function is monomorphised with impl Trait as the actual type parameter.
Finally, allowing impl Trait to instantiate an associated type. I think this should work too, but honestly at this point I'm running out of energy and this blog post is way too long already. Somebody should think about this some more.
http://www.ncameron.org/blog/abstract-return-types-aka-`impl-trait`/
|
|
Will Kahn-Greene: Me: 2015 retrospective |
My 2015 retrospective. Kind of like 2014, but less terrible and more snow.
Read more… (8 mins to read)
|
|
Christian Heilmann: Don’t use Slack? |

When I joined my current company last year, we introduced Slack as the tool to communicate with each other. Of course we have the normal communication channels like email, video calls, phones, smoke signs, flag semaphore and clandestinely tapped Morse code stating “please let it end!” during meetings. But Slack seemed cool and amazing much like BaseCamp used to. And Wikis. And CampFire. And many other tools that came and went.
Here’s the thing though: I really like Slack. I have a soft spot for the team behind it and I know the beauty they are capable of. Flickr was the bomb and one of the most rewarding communities to be part of.
Slack is full of little gems that make it a great collaboration tool. The interface learns from your use. The product gently nudges you towards new functionality and it doesn’t overwhelm you with a “here’s 11452 features that will make your more productive” interface. You learn it while you use it, not after watching a few hours of video training or paying for a course how to use it. I went through many other “communication tools” that required those.
Another thing I love about Slack is that it can be extended. You can pull all kind of features and notifications in. It is a great tool, still frolicking in the first rounds of funding and untainted by a takeover by a large corporation and smothered in ads and “promoted content”.
Seeing that I enjoy Slack at work, I set out to consider running a community on my own. Then life and work happened. But when yesterday my friend Tomomi Imura asked if there are any evangelism/developer advocacy Slack groups, I told her I’d started one a few weeks ago and we now have it filling up nicely with interesting people sharing knowledge on a specialist subject matter.
And then my friend and ex-colleague Marco Zehe wanted to be part of this. And, by all means, he should. Except, there is one small niggle: Marco can’t see and uses a screen reader to navigate the web. And Slack’s interface is not accessible to screen readers as – despite the fact that it is HTML - there is no semantic value to speak of in it. It’s all DIVs and SPANs, monkeys and undergrowth – nothing to guide you.
What followed was a quick back and forth on Twitter about the merits of Slack vs. open and accessible systems like IRC. The main point of Marco was that he can not use Slack and it isn’t open, that’s why it is a bad tool to use for team communication. IRC is open, accessible, time-proven and – if used properly – turns X-Factor dropouts into Freddy Mercury and pot noodles into coq au vin.
Marco has a point: there is a danger that Slack will go away, that Slack will have to pivot into something horrible like many other community tools have. It is a commercial product that isn’t open, meaning it can not easily be salvaged or forked should it go pear shaped. And it isn’t as accessible as IRC is.
But: it is an amazing product and it does everything right in terms of interface that you can. Everything IRC is not.
I love IRC. I used IRC before I used email – on a Commodore 64 with a 2400 baud modem and 40 character per line display. I spent a long time on #html getting and publishing HTML documentation via XDCC file transfer. Some of my longest standing friends and colleagues I know from IRC.
If you introduce someone who is used to apps and messaging on mobile devices to IRC though, you don’t see delight but confusion on their faces. Rachel Nabors complained a lot about this in her State of Web Animation talks. IRC is very accessible, but not enjoyable to use. I am sure there are clients that do a good job at that, but most have an interface and features that only developers can appreciate and call usable.
Using IRC can be incredibly effective. If you are organised and use it with strict channel guidelines. Used wrongly, IRC is an utter mess resulting in lots of log files you only can make sense of if you’re good with find and grep.
I have been sitting on this for a long time, and now I want to say it: open and accessible doesn’t beat usable and intelligent. It is something we really have to get past in the open source and web world if we want what we do to stay relevant. I’m tired of crap interfaces being considered better because they are open. I’m tired of people slagging off great tools and functionality because they aren’t open. I don’t like iOS, as I don’t want to locked into an ecosystem. But damn, it is pretty and I see people being very effective with it. If you want to be relevant, you got to innovate and become better. And you have to keep inventing new ways to use old technology, not complain about the problems of the closed ones.
So what about the accessibility issue of Slack? Well, we should talk to them. If Slack wants to be usable in the Enterprise and government, they’ll have to fix this. This is an incentive – something Hipchat tries to cover right now as Jira is already pretty grounded there.
As the people who love open, free, available and accessible we have to ask ourselves one question: why is it much easier to create an inaccessible interface than an accessible one? How come this is the status quo? How come that in 2016 we still have to keep repeating basic things like semantic HTML, alternative text and not having low contrast interfaces? When did this not become a simple delivery step in any project description? It has been 20 years and we still complain more than we guide.
How come that developer convenience has became more important than access for all – a feature baked into the web as one of its main features?
When did we lose that fight? What did we do to not make it obvious that clean, semantic HTML gives you nothing but benefits and accessibility as a side effect? What did we do to become the grouchy people shouting from the balcony that people are doing it wrong instead of the experts people ask for advice to make their products better?
Accessibility can not be added at a later stage. You can patch and fix and add some ARIA magic to make things work to a degree, but the baby is thrown out with the bath water already. Much like an interface built to only work in English is very tough to internationalise, adding more markup to make something accessible is frustrating patchwork.
Slack is hot right now. And it is lovely. We should be talking to them and helping them to make it accessible, helping with testing and working with them. I will keep using Slack. And I will meet people there, it will make me effective and its features will delight the group and help us get better.
Slack is based on web technologies. It very much can be accessible to all.
What we need though is a way to talk to the team and see if we can find some low hanging fruit bugs to fix. Of course, this would be much easier in an open source project. But just consider what a lovely story it would be to tell that by communicating we made Slack accessible to all.
Closed doesn’t have to evil. Mistakes made doesn’t mean you have to disregard a product completely. If we do this and keep banging on about old technology that works but doesn’t delight everybody loses.
So, use Slack. And tell them when you can’t and that you very much would like to. Maybe that is exactly the feature they need to remain what they are now rather than being yet another great tool to die when the money runs dry.
Photo by CogDogBlog
https://www.christianheilmann.com/2016/01/10/dont-use-slack/
|
|
Roberto A. Vitillo: Detecting Talos regressions |
This post is about modelling Talos data with a probabilistic model which can be applied to different use-cases, like detecting regressions and/or improvements over time.
Talos is Mozilla’s multiplatform performance testing framework written in python that we use to run and collect statistics of different performance tests after a push.
As a concrete example, this is how the performance data of a test might look like over time:
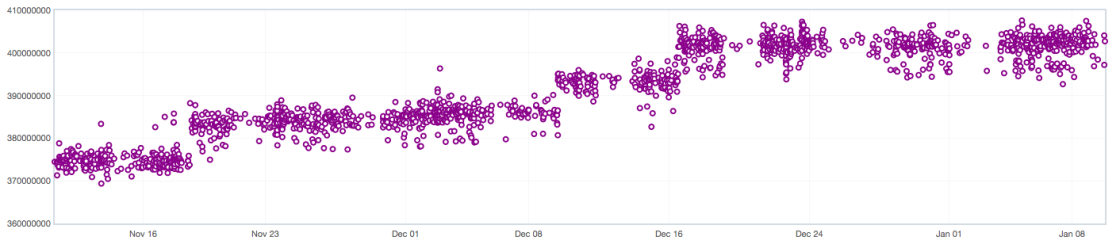
Even though there is some noise, which is exacerbated in this graph as the vertical axis doesn’t start from 0, we clearly see a shift of the distribution over time. We would like to detect such shifts as soon as possible after they happened.
Talos data has been known for a while to generate in some cases bi-modal data points that can break our current alerting engine.
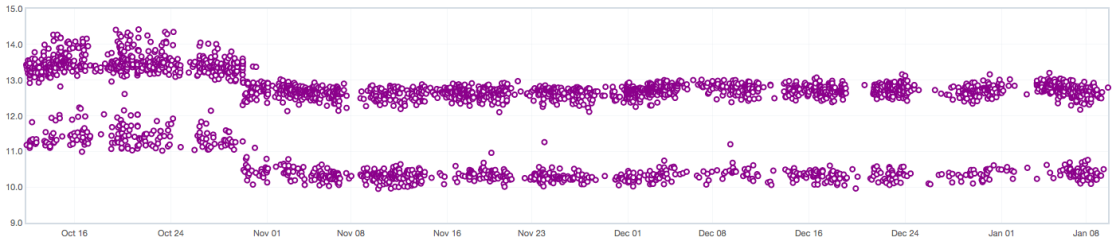
Possible reasons for bi-modality are documented in Bug 908888. As past efforts to remove the bi-modal behavior at the source have failed we have to deal with it in our model.
The following are some notes originated from conversations with Joel, Kyle, Mauro and Saptarshi.
Mixture of Gaussians
The data can be modelled as a mixture of 
The first obstacle is to estimate the parameters of the mixture from a set of data points. Let’s state this problem formally; if you are not interested in the mathematical derivation it suffices to know that scikit-learn has an efficient implementation of it.
EM Algorithm
We want to find the probability density ")


where 


Now, given a set of 


To find a maximum of 
then
But, by Bayes’ Theorem, }{\sum_{j=1}^{N}p_jg(x_i; \mu_j, \sigma_j)}")


")
By applying a similar procedure to compute the partial derivative with respect to
The first two equations turn out to be simply the sample mean and standard deviation of the data weighted by the conditional probability that component
Since the terms
Intuitively, in the E-step the parameters of the components are assumed to be given and the data points are soft-assigned to the clusters. In the M-step we compute the updated parameters for our clusters given the new assignment.
Determine K
Now that we have a way to fit a mixture of
Regression Detection
A simple approach to detect changes in the series is to use a rolling window and compare the distribution of the first half of the window to the distribution of the second half. Since we are dealing with Gaussians, we can use the z-statistic to compare the mean of each component in the left window to mean of its corresponding component in the right window:
In the following plots the red dots are points at which the regression detection would have fired. Ideally the system would generate a single alert per cluster for the first point after the distribution shift.
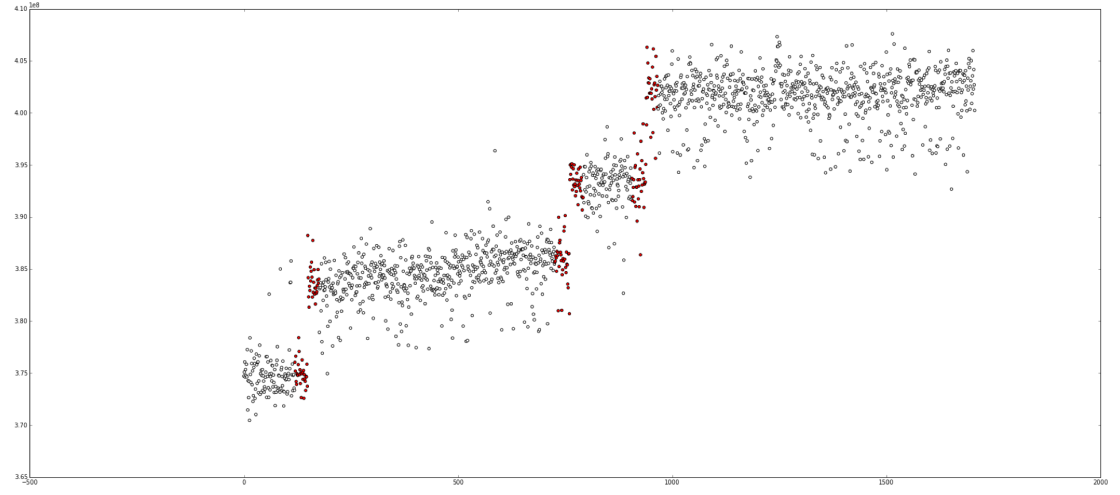

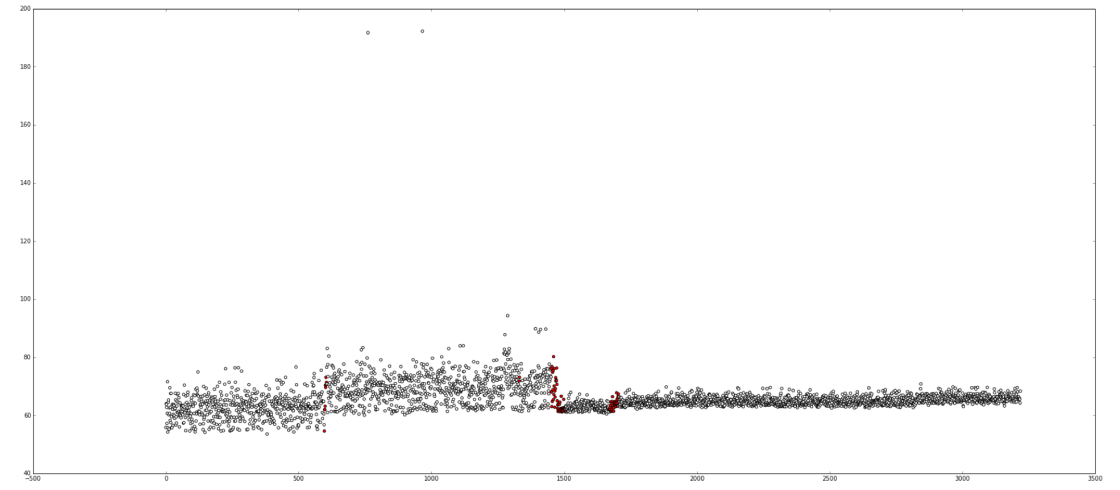
Talos generates hundreds of different time series, some with dominating and peculiar noise patterns. As such it’s hard to come up with a generic model that solves the problem for good and represents the data perfectly.
Since the API to access this data is public, it provides an exciting opportunity for a contributor to come up with better ways of representing it. Feel free to join us on #perf if you are interested. Oh and, did I mentions we are hiring a Senior Data Engineer?

http://robertovitillo.com/2016/01/10/detecting-talos-regressions/
|
|
Daniel Pocock: Comments about people with mental illness |
A quote:
As the Buddha said 2500 years ago... we're all out of our fucking minds. (Albert Ellis)
There have been a few occasions over the last year where people suffering mental illnesses have been the subject of much discussion.
In March 2015 there was the tragic loss of Germanwings flight 9525. It was discovered that the co-pilot, Andreas Lubitz, had been receiving treatment for mental illness. Under strict privacy laws, nobody at his employer, the airline, had received any information about the diagnosis or treatment.

During the summer, the private mailing list for a large online community discussed the mental illness of a contributor to a project. Various people expressed opinions that appeared to be generalizations about all those with mental illness. Some people hinted the illness was a lie to avoid work while others speculated about options for treatment. Nobody involved mentioned having any medical expertise.
It is ironic that on the one hand, we have the dramatic example of an aircraft crashing at the hands of somebody who is declared unfit to work but working anyway and on the other hand when somebody else couldn't do something, the diagnosis is being disputed by people who find it inconvenient or don't understand it.
More recently, there has been openly public discussion about whether another developer may have had mental illness. Once again, there doesn't appear to be any evidence from people with any medical expertise or documentation whatsoever. Some of the comments appear to be in the context of a grudge or justifying some other opinion.
What's worse, some comments appear to suggest that mental illness can be blamed for anything else that goes wrong in somebody's life. If somebody is shot and bleeds to death, do you say low blood pressure killed him or do you just say he was shot? Likewise, if somebody is subject to some kind of bullying and abused, does this have no interaction with mental illness? In fact, Google reveals an enormous number of papers from experts in this field suggesting that mental illness can arise or be exacerbated by bad experiences. Although it may not have been clear at that point in time, when we look back at Alan Turing's death today, suicide was not a valid verdict and persecution was a factor.
Statistics tell us that 1 in 4 people experience a mental health problem in the UK each year. In the USA it is 26% of the adult population, each year. These may be long term conditions or they may be short term conditions. They may arise spontaneously or they may be arising from some kind of trauma, abuse or harassment in the home, workplace or some other context.
For large online communities, these statistics imply it is inevitable that some participants will be suffering from mental illness and others will have spouses, parents or children suffering from such conditions. These people will be acutely aware of the comments being made publicly about other people in the community. Social interaction also relates to the experience of mental illness, people who are supported by their community and society are more likely to recover while those who feel they are not understood or discriminated against may feel more isolated, compounding their condition.
As a developer, I wouldn't really like the idea of doctors meddling with my code, so why is it that some people in the IT and business community are so happy to meddle around in the domain of doctors, giving such strong opinions about something they have no expertise in?
Despite the tragic loss of life in Germanwings 9525, observing some of these other discussions that have taken place reminds me why Germany and some other countries do have such strict privacy laws for people who seek medical treatment.
http://danielpocock.com/comments-about-people-with-mental-illness
|
|
Karl Dubost: [worklog] Life meets work |
This is again a light week due to some major changes in my life. Good ones.
Starting Saturday, 10 January 2016, I will be out of contacts for a couple of weeks. Very happy event in my life. See you in two weeks.
Otsukare!
|
|
Henrik Skupin: Review of automation work – Q4 2015 |
The last quarter of 2015 is gone and its time to reflect what happened in Q4. In the following you will find a full overview again for the whole quarter. It will be the last time that I will do that. From now on I will post in shorter intervals to specific topics instead of covering everything. This was actually a wish from our latest automation survey which I want to implement now. I hope you will like it.
So during the last quarter my focus was completely on getting our firefox-ui-tests moved into mozilla-central, and to use mozharness to execute firefox-ui-tests in mozmill-ci via the test archive. As result I had lesser time for any other project. So lets give some details…
One thing you really want to have with tests located in the tree is that those are not failing. So I spent a good amount of time to fix our top failures and all those regressions as caused by UI changes (like the security center) in Firefox as preparation for the move. I got them all green and try my best to keep that state now while we are in the transition.
The next thing was to clean-up the repository and split apart all the different sub folders into their own package. With that others could e.g. depend on our firefox-puppeteer package for their own tests. The whole work of refactoring has been done on bug 1232967. If you wonder why this bug is not closed yet it’s because we still have to wait with the landing of the patch until mozmill-ci production uses the new mozharness code. This will hopefully happen soon and only wait of some other bugs to be fixed.
But based on those created packages we were able to use exactly that code to get our harness, puppeteer, and tests landed on http://hg.mozilla.org/mozilla-central. We also package them into the common.tests.zip archive for use in mozmill-ci. Details about all that can be found on bug 1212609. But please be aware that we still use the Github repository as integration repository. I regularly mirror the code to hg, which has to happen until we can also use the test package for localized builds and update tests.
Beside all that there were also a couple of mozharness fixes necessary. So I implemented a better fetching of the tooltool script, added the uninstall feature, and also setup the handling of crash symbols for firefox-ui-tests. Finally the addition of test package support finished up my work on mozharness for Q4 in 2015.
During all the time I was also sheriffing our test results on Treeherder (e.g. mozilla-central) because we are still Tier-3 level and sheriffs don’t care about it.
Our Jenkins based CI system is still called mozmill-ci even it doesn’t really run any mozmill tests anymore. We decided to not change its name given that it will only be around this year until we can run all of our tests in TaskCluster. But lots of changes have been landed, which I want to announce below:
I also had some time to work on supporting tools. Together with the help of contributors we got the following done:
So all in all it was a productive quarter with lots of things accomplished. I’m glad that we got all of this done. Now in Q1 it will continue and more interesting work is in-front of me, which I’m excited about. I will announce that soon in my next blog post.
Until then I would like to give a little more insight into our current core team for Firefox automation. A picture taken during our all hands work week in Orlando early in December shows Syd, Maja, myself, and David:

Lets get started into 2016 with lots of ideas, discussions, and enough energy to get those things done.
http://www.hskupin.info/2016/01/09/review-of-automation-work-q4-2015/
|
|
Chris Cooper: RelEng & RelOps Weekly Highlights - January 8, 2016 |
Happy new year from all of us in releng! Here’s a quick rundown of what’s happened over the holidays.
Modernize infrastructure:
We are now running 100% of our Windows builds (including try) in AWS. This greatly improves the scalability of our Windows build infrastructure. It turns out these AWS instances are also much faster than the in-house hardware we were using previously. On AWS, we save over 45 minutes per try run on Windows, with more modest improvements on the integration branches. Thanks to Rob, Mark, and Q for making this happen!
Dustin added a UI frontend to the TaskCluster “secrets” service and landed numerous fixes to it and to the hooks service.
Rob implemented some adjustments to 2008 userdata in cloud-tools that allow us to re-enable puppetisation of 2008 golden AMIs.
Callek added buildbot master configuration that enables parallel t-w732 testing prototype instances in EC2. This is an important step as we try to virtualize more of our testing infrastructure to reduce our maintenance burden and improve burst capacity.
Q implemented a working mechanism for building Windows 7/10 cloud instance AMIs that behave as other EC2 Windows instances (EC2Config, Sysprep, etc) and can be configured for test duty.
Mark landed Puppet code for base Windows 7 support including secrets and ssh keys management.
Improve CI pipeline:
Dustin completed modifications to the docker worker to support “coalescing”, the successor to what is now known as queue collapsing or BuildRequest merging.
Release:
Ben modernized Balrog’s toolchain, including switching it from Vagrant to Docker, enabling us to start looking at a more modern deployment strategy.
Operational:
Hal introduced the team learned about Lean Coffee at Mozlando. The team has adopted it wholeheartedly, and is using it for both project and team meetings with success. We’re using Trello for virtual post-it notes in vidyo meetings.
Rob fixed a problem where our AWS instances in us-west-2 were pulling mercurial bundles from us-east-1. This saves us a little bit of money every month in transfer costs between AWS regions. (bug 1232501)
See you all next week!
|
|
Kim Moir: Tips from a resume nerd |
 | |
|
 |
| Picture by Mufidah Kassalias - Creative Commons Attribution-NonCommercial-NoDerivs 2.0 Generic (CC BY-NC-ND 2.0) https://www.flickr.com/photos/mufidahkassalias/10519774073/sizes/o/ |
 |
| Picture by mugley - Creative Commons Attribution-NonCommercial-NoDerivs 2.0 Generic (CC BY-NC-ND 2.0) https://www.flickr.com/photos/mugley/4221455156/sizes/o/ |
 |
| Picture by Jim Bauer - Creative Commons Attribution-NonCommercial-NoDerivs 2.0 Generic (CC BY-NC-ND 2.0) https://www.flickr.com/photos/lens-cap/10320891856/sizes/l |
 |
| Photo by https://www.flickr.com/photos/wocintechchat/ https://www.flickr.com/photos/wocintechchat/22506109386/sizes/l |
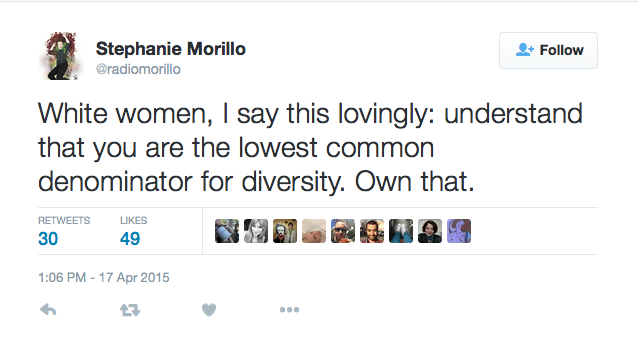 |
| The entire thread on this tweet is excellent https://twitter.com/radiomorillo/status/589158122108932096 |
http://relengofthenerds.blogspot.com/2016/01/tips-from-resume-nerd.html
|
|
Support.Mozilla.Org: What’s up with SUMO – 8th January |
Hello, SUMO Nation!
Welcome to the first proper post of the year! We’re happy to have you read these words – it most likely means you’re getting ready for your weekend (or are in the middle of it). You’re probably curious what’s going on, hm? I shall not keep you waiting – let’s go!
We salute you!
The workshop was held December 5, 2015 in Abidjan’s AYIYIKOH FabLab. More than fifty people were present. The AYIYIKOH FabLab is a space of collective intelligence for many young Ivorian technology lovers who meet there once a week to share their common passion for technology.
During the workshop several points were addressed in the following order:
Introduction to SUMO: how to get involved, what your contributions mean, what can you learn or practice;
Local SUMO team presentation: a presentation of all the current SUMO team members in Ivory Coast;
Contribution session: in groups for mentoring and SUMO account creation. Demos of Army of Awesome and localization;







Additionally, the Firefox Student Ambassadors in Ivory Coast will do the following for all events organized in the future:
1. Set up a booth or arrange a help-session of Orange Klif and other Firefox OS devices.
2. Organize Firefox clinics
3. Organize sessions for users on Twitter (through Army of Awesome)
4. L10n sessions for French or Nouchi (the local language of Ivory Coast)
And that’s it for this week’s updates. We’re all very happy to see most of you back in the forums, IRC channels, and all the other usual Mozillian places that the SUMO Nation inhabits :-). See you around!
https://blog.mozilla.org/sumo/2016/01/08/whats-up-with-sumo-8th-january/
|
|
Nicholas Nethercote: Fast starring of oranges on try pushes |
If you do lots of try pushes it’s worth learning to star oranges using the keyboard instead of the mouse. It’s much faster that way.
The important keystrokes are as follows.
So a typical keystroke sequence to star multiple jobs would be: j, space, j, space, j, space, ctrl-enter. Between each j and space you should, of course, check that the failure matches an existing one.
This information, along with lots of other interesting tidbits, is in the Treeherder User Guide.
Thank you to Phil Ringnalda for teaching me this.
https://blog.mozilla.org/nnethercote/2016/01/09/fast-starring-of-oranges-on-try-pushes/
|
|
Nicholas Nethercote: Getting my bluetooth keyboard working again after an Ubuntu upgrade |
I have a wireless bluetooth keyboard (a Logitech diNovo ultra-flat, about seven years old) that I love. Every time I update my Ubuntu installation there’s a ~50% chance that it’ll stop working, and on the update to 15.10 that I just did I got unlucky.
To get it working again I had to comment out the following two lines in /lib/udev/rules.d/97-hid2hci.rules and then reboot.
KERNEL=="hiddev*", ATTRS{idVendor}=="046d", ATTRS{idProduct}=="c70[345abce]|c71[3bc]", \
RUN+="hid2hci --method=logitech-hid --devpath=%p"
I’ve had to do something similar on more than one previous occasion. The idea originated here, but note that the name of the rules file has changed since that was written.
(When I updated to 15.04 this problem did not manifest. However, I got unlucky and the batteries in the keyboard died while the update was occurring. Batteries in this keyboard typically last 4–5 months, and diagnosing dead batteries is normally easy — hey, the keyboard stopped working suddenly! — but because Ubuntu updates had caused troubles with this keyboard in the past I assumed the update was the cause. I didn’t think to try new batteries until I’d spent a couple of tedious hours deep in the bluetooth configuration weeds. Lesson learned.)
|
|
John O'Duinn: “Distributed” ER#4 now available! |
 To start off the new year on a good note, “Distributed” Early Release #4 is now publicly available.
To start off the new year on a good note, “Distributed” Early Release #4 is now publicly available.
Early Release #4 (ER#4) adds five (yes, five!) new chapters:
* Ch.3 disaster planning
* Ch.5 physical setup
* Ch.6 video etiquette
* Ch.19 career path (around choosing the right employers)
* Ch.20 feed your soul (around mental sanity for long term “remoties”)
…as well as many tweaks/fixes to pre-existing Chapters.
You can buy ER#4 by clicking here, or clicking on the thumbnail of the book cover. ER#4 comes just over one month after ER#3. Anyone who already has ER#1, ER#2 or ER#3 should get prompted with a free update to ER#4 – if you don’t please let me know! And yes, you’ll get updated when ER#5 comes out at the end of the month.
As always, please let me know what you think of the book so far. Is there anything you found worked for you, as a “remotie” or person in a distributed team, which you wish you knew when you were starting? If you knew someone about to setup a distributed team, what would you like them to know before they started?
Thank you to everyone who’s already sent me feedback/opinions/corrections – I track all of them and review/edit/merge as fast as I can. To make sure that any feedback doesn’t get lost or caught in spam filters, please email comments to feedback at oduinn dot com.
Thanks again to everyone for their ongoing encouragement, proof-reading help and feedback so far.
Happy New Year!
John.
=====
ps: For the curious, here is the current list of chapters and their status:
Chapter 1: Remoties trend – AVAILABLE
Chapter 2: The real cost of an office – AVAILABLE
Chapter 3: Disaster Planning – AVAILABLE
Chapter 4: Mindset – AVAILABLE
Chapter 5: Physical Setup – AVAILABLE
Chapter 6: Video Etiquette – AVAILABLE
Chapter 7: Own your calendar – AVAILABLE
Chapter 8: Meetings – AVAILABLE
Chapter 9: Meeting Moderator – AVAILABLE
Chapter 10: Single Source of Truth
Chapter 11: Email Etiquette – AVAILABLE
Chapter 12: Group Chat Etiquette
Chapter 13: Culture, Trust and Conflict
Chapter 14: One-on-Ones and Reviews – AVAILABLE
Chapter 15: Joining and Leaving
Chapter 16: Bring Humans Together – AVAILABLE
Chapter 17: Career path – AVAILABLE
Chapter 18: Feed your soul – AVAILABLE
Chapter 19: Final Chapter
http://oduinn.com/blog/2016/01/08/distributed-er4-now-available/
|
|
Ben Hearsum: Collision Detection and History with SQLAlchemy |
Balrog is one of the more crucial systems that Release Engineering works on. Many of our automated builds send data to it and all Firefox installations in the wild regularly query it to look for updates. It is an SQLAlchemy based app, but because of its huge importance it became clear in the early stages of development that we had a couple of requirements that went beyond those of most other SQLAlchemy apps, specifically:
Implementing these two requirements ended up being a interesting project and I'd like to share the details of how it all works.
Anyone who's used Bugzilla for awhile has probably encountered this screen before:
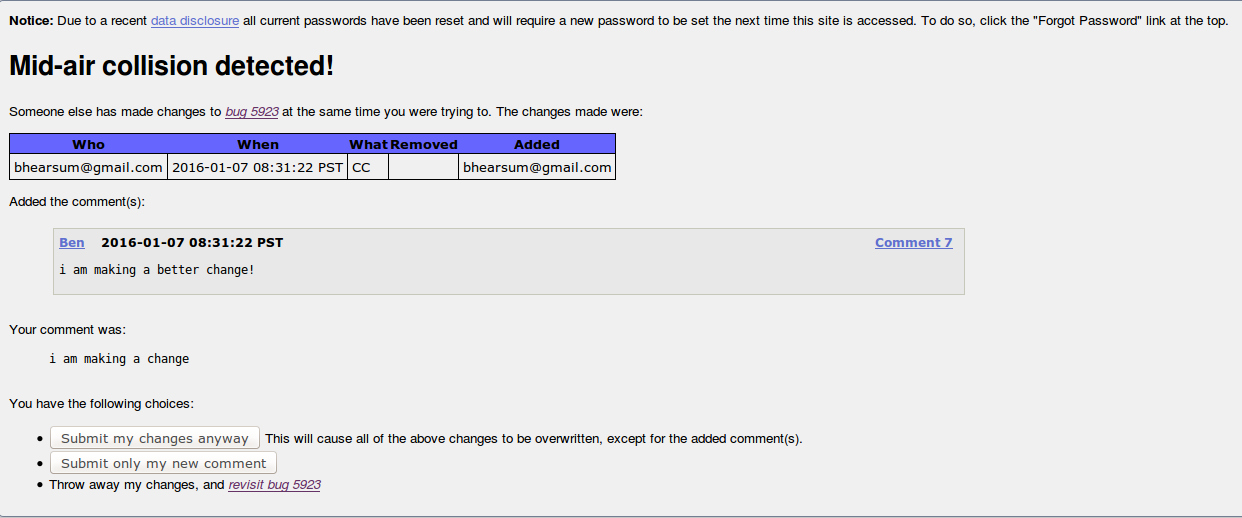
This screenshot shows how Bugzilla detects and warns if you try to make a change to a bug before loading changes someone else has made. While it's annoying when this screen slows you down, it's important that Bugzilla doesn't let you unknowingly overwrite other folks' changes. This is very similar to what we wanted to do in Balrog, except that we needed to enforce it at the API level, not just in the UI. In fact, we decided it was best to enforce it at the lowest level possible to minimize the change of needing to duplicate it in different parts of the app.
To do this, we started by creating a thin wrapper around SQLAlchemy which ensures that each table has a "data_version" column, and requires an "old_data_version" to be passed when doing an UPDATE or DELETE. Here's a slimmed down version of how it works with UPDATE:
class AUSTable(object):
"""Base class for Balrog tables. Subclasses must create self.table as an
SQLAlchemy Table object prior to calling AUSTable.__init__()."""
def __init__(self, engine):
self.engine = engine
# Ensure that the table has a data_version column on it.
self.table.append_column(Column("data_version", Integer, nullable=False))
def update(self, where, what, old_data_version):
# Enforce the data_version check at the query level to eliminate
# the possibility of a race condition between the time we can
# retrieve the current data_version, and when we can update the row.
where.append(self.table.data_version == old_data_version)
with self.engine.connect().begin() as transaction:
row = self.select(where=where, transaction=transaction)
row["data_version"] += 1
for col in what:
row[col] = what[col]
query = self.table.update(values=what):
for cond in where:
query = query.where(cond)
ret = transaction.execute(query)
if ret.rowcount != 1:
raise OutdatedDataError("Failed to update row, old_data_version doesn't match data_version")
And one of our concrete tables:
class Releases(AUSTable):
def __init__(self, engine, metadata):
self.table = Table("releases", metadata,
Column("name", String(100), primary_key=True),
Column("product", String(15), nullable=False),
Column("data", Text(), nullable=False),
)
def updateRelease(self, name, old_data_version, product, data):
what = {
"product": product,
"data": data,
}
self.update(where=[self.table.name == name], what=what, old_data_version=old_data_version)
As you can see, the data_version check is added as a clause to the UPDATE statement - so there's no way we can race with other changes. The usual workflow for callers is to retrieve the current version of the data, modify it, and pass it back along with old data_version (most of the time retrieval and pass back happens through the REST API). It's worth pointing out that a client could pass a different value as old_data_version in an attempt to thwart the system. This is something we explicitly do not try to protect against (and honestly, I don't think we could) -- data_version is a protection against accidental races, not against malicious changes.
Having history of all changes to Balrog's database is not terribly important on a day-to-day basis, but when we have issues related to updates it's extremely important that we're able to look back in time and see why a particular issue happened, how long it existed for, and who made the change. Like collision detection, this is implemented at a low level of Balrog to make sure it's difficult to bypass when writing new code.
To achieve it we create a History table for each primary data table. For example, we have both "releases" and "releases_history" tables. In addition to all of the Releases columns, the associated History table also has columns for the account name that makes each change and a timestamp of when it was made. Whenever an INSERT, UPDATE, or DELETE is executed, the History table has a new row inserted with the full contents of the new version. These are done is a single transaction to make sure it is an all-or-nothing operation.
Building on the code from above, here's a simplified version of how we implement History:
class AUSTable(object):
"""Base class for Balrog tables. Subclasses must create self.table as an
SQLAlchemy Table object prior to calling AUSTable.__init__()."""
def __init__(self, engine, history=True, versioned=True):
self.engine = engine
self.versioned = versioned
# Versioned tables (generally, non-History tables) need a data_version.
if versioned:
self.table.append_column(Column("data_version", Integer, nullable=False))
# Well defined interface to the primary_key columns, needed by History tables.
self.primary_key = []
for col in self.table.get_children():
if col.primary_key:
self.primary_key.append(col)
if history:
self.history = History(self.table.metadata, self)
else:
self.history = None
def update(self, where, what, old_data_version=None, changed_by=None):
# Because we're a base for History tables as well as normal tables
# these must be optional parameters, but enforced when the features
# are enabled.
if self.history and not changed_by:
raise ValueError("changed_by must be passed for Tables that have history")
if self.versioned and not old_data_version:
raise ValueError("update: old_data_version must be passed for Tables that are versioned")
# Enforce the data_version check at the query level to eliminate
# the possibility of a race condition between the time we can
# retrieve the current data_version, and when we can update the row.
where.append(self.table.data_version == old_data_version)
with self.engine.connect().begin() as transaction:
row = self.select(where=where, transaction=transaction)
row["data_version"] += 1
for col in what:
row[col] = what[col]
query = self.table.update(values=what):
for cond in where:
query = query.where(cond)
ret = transaction.execute(query)
if self.history:
transaction.execute(self.history.forUpdate(row, changed_by))
if ret.rowcount != 1:
raise OutdatedDataError("Failed to update row, old_data_version doesn't match data_version")
class History(AUSTable):
def __init__(self, metadata, baseTable):
self.baseTable = baseTable
self.Table("%s_history" % baseTable.table.name, metadata,
Column("change_id", Integer(), primary_key=True, autoincrement=True),
Column("changed_by", String(100), nullable=False),
Column("timestamp", BigInteger(), nullable=False),
)
self.base_primary_key = [pk.name for pk in baseTable.primary_key]
# In addition to the above columns, we need a copy of each Column
# from our base table.
for col in baseTable.table.get_children():
newcol = col.copy()
# We have our own primary_key Column, and don't want our
# base table's PK to be part of it.
if col.primary_key:
newcol.primary_key = False
# And while the base table's primary key is always required for
# history rows, all other columns (including those that are
# required in the base table) must be nullable.
else:
newcol.nullable = True
self.table.append_column(newcol)
AUSTable.__init__(self, history=False, versioned=False)
def forUpdate(self, rowData, changed_by):
row = {}
# Copy in the data that's about to be updated in the base table...
for k in rowData:
row[k] = rowData[k]
# ...and add the extra data that we need to track history accurately.
row["changed_by"] = changed_by
row["timestamp"] = time.time()
return self.table.insert(values=rows)
A key thing to notice here is that the History tables are maintained automatically with only a minor tweak to the query interface (addition of "changed_by"). And while not shown here, it's important to note that the History table objects are not queryable directly through any exposed API. Even if an attacker got access to Balrog's REST API with admin permissions, they cannot delete rows from those tables.
If you'd like to see the complete implementation of either of these, you can find it over in the Balrog repository.
These things were implemented a few years ago, and since then we've discovered a couple of rough edges that would be nice to fix.
The biggest complaint is that the History tables are extremely inefficient. Many of our Release objects are a few hundred kilobytes, which means every change to them (thousands per day) significantly grows the releases_history table. We've dealt with this by limiting how long we keep history for certain types of releases, but it's far less than ideal. We'd love to have a more efficient way of storing history. We've discussed storing history as diffs rather than full copies or compressing the data before inserting the rows, but haven't settled on anything yet. If you have any ideas about this we'd love to hear them!
I mentioned earlier how annoying it is when Bugzilla throws you a mid-air collision, and it's no different in Balrog. We get hundreds of them a day when locales l10n repacks all try to update the same Releases. These can be dealt with by retrying but it's very inefficient. We might be able to do a better here if we inspected the details of changes that collide, and only reject them if they try to modify the same parts of an object.
Finally, all of this awesome collision detection and history code is in no way tied to Balrog - the classes that implement it are already very generic. I would love to pull out these features and ship them as their own module, which Balrog (and hopefully others!) can then consume.
http://hearsum.ca/blog/collision-detection-and-history-with-sqlalchemy.html
|
|
Dan Minor: Using masked writes with ARM NEON intrinsics |
I recently fixed Bug 1105513 which was to provide an ARM NEON optimized version of the AudioBlockPanStereoToStereo for the case where the “OnTheLeft” is an array. This is used by the StereoPanner node when the value is set at a future time, for instance with code like the following:
panner = oac.createStereoPanner();
panner.pan.setValueAtTime(-0.1, 0.0);
panner.pan.setValueAtTime(0.2, 0.5);
The “OnTheLeft” values determine whether the sound is on the left or right of the listener at a given time, which controls the interpolation calculation performed when panning. If this changes with time, then this is passed as an array rather than as a constant.
The unoptimized version of this function checks each value of “OnTheLeft” and performs the appropriate calculation. This isn’t an option for NEON which lacks this kind of conditional execution.
The bright side is that NEON does provide masked writes where a variable controls which components of a vector are written. Unfortunately, the NEON documentation is spare at best, so it took a few tries to get things right.
The first trick is to convert from a bool to a suitable mask. What a bool is, is of course platform dependent, but in this case I had an array of eight bytes, each containing a zero or a one. The best solution I came up with was to load them as a vector of 8 unsigned bytes and then load each corresponding float value in the mask individually:
isOnTheLeft = vld1_u8((uint8_t *)&aIsOnTheLeft[i]);
voutL0 = vsetq_lane_f32(vget_lane_u8(isOnTheLeft, 0), voutL0, 0);
voutL1 = vsetq_lane_f32(vget_lane_u8(isOnTheLeft, 1), voutL0, 1);
...
Once loaded, they can be converted into a suitable mask by using the vcgtq function which sets all bits to 1 in the first argument if it is greater than the second argument:
voutL0 = (float32x4_t)vcgtq_f32(voutL0, zero);
After that, the appropriate calculations are done for both the case where “OnTheLeft” is true and where it is false. These are then written to the result using vbsql function, which treats the mask as the output, and selects from the second two arguments based upon the value in the mask:
voutL0 = vbslq_f32((uint32x4_t)voutL0, onleft0, notonleft0);
I evaluated these changes on a StereoPanner benchmark where I saw a small performance improvement.
http://www.lowleveldrone.com/mozilla/webaudio/2016/01/08/masked-writes-arm-intrinsics.html
|
|
Mark C^ot'e: BMO in 2015 |
It’s been a whole year since my last BMO update, partly because I’ve been busy with MozReview (and blogging a lot about it), and partly because the BMO team got distracted from our goals by a few sudden priority changes, which I’ll get to later in this post.
Even with some large interruptions, we fully achieved three of our five goals for the year and made good progress on a fourth.
Have you tried out the new modal UI? Although not completely finished (it lacks a few features that the standard UI has), it’s very usable. I don’t remember the last time I had to switch back, and I’ve been using it for at least 6 months. Bonus: gone is the intermediate page when you change a bug’s product, a gripe from time immemorial!
Even though there are still a large number of controls, the new UI is a lot more streamlined. glob gave a brief presentation at a Mozilla Project Meeting in November if you’d like to learn more.
The part we haven’t yet undertaken is building on this new framework to provide alternate views of bug data depending on what the user is trying to accomplish. We want to experiment with stripping down the presented data to only what is needed for a particular task, e.g. developing, triaging, approving, etc. The new UI is a lot more flexible than the old, so in 2016 we’ll build out at least one new task-centric view.
If you haven’t noticed, you can log into BMO via GitHub. If you’ve never used BMO before, you’ll be prompted to set up an account after authenticating. As with Persona, only users with no special privileges (i.e. not admins nor people in security groups) can log in via GitHub.
Originally designed to smooth the process of logging into Review Board, auth delegation for API keys is actually a general-use feature that greatly improves the user experience, not to mention security, of third-party apps by allowing them to delegate authentication to BMO. There’s now no reason for apps to directly ask for your BMO credentials!
There’s now a panel just above the attachments table that shows all the MozReview commits associated with the displayed bug along with a bit of other info:

We’re currently sorting out a single method to display other relevant information, notably, status of reviews, and then we’ll add that to this table.
This is the big item we haven’t made much progress on. We’ve got a plan to mirror some data to an Elasticsearch cluster and wire it into Quick Search. We’ve even started on the implementation, but it’s not going to be ready until mid-2016. It will increase search speeds, understandably one of the more common complaints about BMO.
We had two sets of surprises in 2015. One was work that ended up consuming more time than we had expected, and the other was important work that suddenly got a big priority boost.
The first is that we moved the BMO failover out of a data center in Phoenix and into the cloud. IT did most of the work, but we had to make a series of changes to BMO to facilitate the move. We also had a lot of testing to do to. The upside is that our new failover system has had more testing than our old one had for quite some time!
In August we found out that an attacker had compromised a privileged BMO account, using a combination of a weak, reused password and an exploit in another web site. In addition to a huge forensics effort from the great security folks at Mozilla, the BMO team implemented a number of security enhancements to BMO, most notably two-factor authentication. This work naturally took high priority and is the main reason for the slippage of our big 2015 goals. Here’s to a more secure 2016!
As usual, the BMO team rolled out a pile of smaller fixes, enhancements, improvements, and new features. A few notable examples include
The guided bug-entry form got a nice refresh. This is the form
that users without the editbugs permission, i.e. new users, see
when entering bugs. You can always get to it via the “Switch to the
Bugzilla helper” link at the buttom of the advanced bug-entry form.
Note that if you’re an employee, you’ve been given editbugs by
default, so you’ve likely never seen the guided form. Check it
out—Bugzilla might be friendlier to new contributors than you expect.
The platform settings for new bugs now default to all hardware and OSes, with a “Use my platform” button to easily set this to the reporter’s system parameters. This should help clear up some confusion between the reporter’s platform versus the platform the bug applies to.
The ability to block requests for review, feedback, and needinfo.
The preferences page is now better organized.
HTML bugmail has microdata to make GMail display a “View bug” button. Thanks to Ed Morley for the patch!
You can always find the exhaustive list of recent changes to BMO on the wiki or on the mozilla.tools.bmo group/mailing list.
|
|
Air Mozilla: Ur/Web: A Simple Model for Programming the Web |
 Ur/Web is a domain-specific functional language for implementing all parts of a Web app -- client, server, database -- in one high-level language with rich...
Ur/Web is a domain-specific functional language for implementing all parts of a Web app -- client, server, database -- in one high-level language with rich...
https://air.mozilla.org/ur-web-a-simple-model-for-programming-the-web/
|
|







 = \sum_{k=1}^{K} p_k g(x; \mu_k, \sigma_k)")
 = \frac{1}{(\sqrt{2\pi\sigma_k})}e^{-\frac{(x - \mu_k)^2}{2\sigma_k^2}}")
 = \log\prod_{i=1}^{N} f(x_i; \theta)")
![\frac{\partial{g(x_i; \mu_k, \theta_k)}}{\partial{\mu_k}} = g(x_i; \mu_k, \theta_k) \frac{\partial}{\partial{\mu_k}} [-\frac{(x_i - \mu_k)^2}{2\sigma_k^2}] = \frac{g(x_i; \mu_k, \theta_k) (x_i - \mu_k)}{\sigma_k^2}](http://s0.wp.com/latex.php?latex=%5Cfrac%7B%5Cpartial%7Bg%28x_i%3B+%5Cmu_k%2C+%5Ctheta_k%29%7D%7D%7B%5Cpartial%7B%5Cmu_k%7D%7D+%3D+g%28x_i%3B+%5Cmu_k%2C+%5Ctheta_k%29+%5Cfrac%7B%5Cpartial%7D%7B%5Cpartial%7B%5Cmu_k%7D%7D+%5B-%5Cfrac%7B%28x_i+-+%5Cmu_k%29%5E2%7D%7B2%5Csigma_k%5E2%7D%5D+%3D+%5Cfrac%7Bg%28x_i%3B+%5Cmu_k%2C+%5Ctheta_k%29+%28x_i+-+%5Cmu_k%29%7D%7B%5Csigma_k%5E2%7D+&bg=ffffff&fg=444444&s=0 "\frac{\partial{g(x_i; \mu_k, \theta_k)}}{\partial{\mu_k}} = g(x_i; \mu_k, \theta_k) \frac{\partial}{\partial{\mu_k}} [-\frac{(x_i - \mu_k)^2}{2\sigma_k^2}] = \frac{g(x_i; \mu_k, \theta_k) (x_i - \mu_k)}{\sigma_k^2}")
}{\sum_{j=1}^{N}p_jg(x_i; \mu_j, \sigma_j)}(x_i - \mu_k)")
}{\sigma_k^2}(x_i - \mu_k)")
x_i}{\sum_{i=1}^{N}p(k|x_i)}")
(x_i - \mu_k)^2}{\sum_{n=1}^{N}p(k|x_i)}}")
")
}(k|x_i) = \frac{p_k^{(n)}g(x_i; \mu_k^{(n)}, \sigma_k^{(n)})}{\sum_{j=1}^{N}p_jg(x_i; \mu_j^{(n)}, \sigma_j^{(n)})}")
} = \frac{\sum_{i=1}^{N}p^{(n)}(k|x_i)x_i}{\sum_{i=1}^{N}p^{(n)}(k|x_i)}")
} = \sqrt{\frac{\sum_{i=1}^{N}p^{(n)}(k|x_i)(x_i - \mu^{(n+1)})^2}{\sum_{n=1}^{N}p^{(n)}(k|x_i)}}")
} = \frac{1}{N}\sum_{i=1}^{N}p^{(n)}(k|x_i)")
