Air Mozilla: The Joy of Coding (mconley livehacks on Firefox) - Episode 29 |
 Watch mconley livehack on Firefox Desktop bugs!
Watch mconley livehack on Firefox Desktop bugs!
https://air.mozilla.org/the-joy-of-coding-mconley-livehacks-on-firefox-episode-29/
|
|
Christian Heilmann: Of impostor syndrome and running in circles (part 3) |
These are the notes of my talk at SmartWebConf in Romania. Part 1 covered how Impostor Syndrome cripples us in using what we hear about at conferences. It covered how our training and onboarding focuses on coding instead of human traits. In Part 2 I showed how many great things browsers do for us we don’t seem to appreciate. In this final part I’ll explain why this is and why it is a bad idea. This here is a call to action to make yourself feel better. And to get more involved without feeling inferior to others.
This is part 3 of 3.
Part 2 of this series ended with the explanation that JavaScript is not fault tolerant, and yet we rely on it for almost everything we do. The reason is that we want to control the outcome of our work. It feels dangerous to rely on a browser to do our work for us. It feels great to be in full control. We feel powerful being able to tweak things to the tiniest detail.

There is no doubt that JavaScript is the duct-tape of the web: you can fix everything with it. It is a programming language and not a descriptive language or markup. We have all kind of logical constructs to write our solutions in. This is important. We seem to crave programmatic access to the things we work with. That explains the rise of CSS preprocessors like Sass. These turn CSS into JavaScript. Lately, PostCSS even goes further in merging these languages and ideas. We like detailed access. At the same time we complain about complexity.
No matter what we do – the problem remains that on the client side JavaScript is unreliable. Because it is fault intolerant. Any single error – even those not caused by you – result in our end users getting an empty screen instead of the solution they came for. There are many ways JavaScript can fail. Stuart Langridge maintains a great flow chart on that called “Everyone has JavaScript, right?“.
There is a bigger issue with fixing browser issues with JavaScript. It makes you responsible and accountable for things browser do. You put it onto yourself to fix the web, now it is your job to keep doing that – for ever, and ever and ever…
Taking over things like page rendering, CSS support and page loading with JavaScript feels good as it fixes issues. Instead of a slow page load we can show a long spinner. This makes us feel good, but doesn’t help our end users much. Especially when the spinner has no timeout error case – like browser loading has.
Fixing a problem with JavaScript is fun. It looks simple enough and it removes an unknown browser support issue. It allows us to concentrate on building bigger and better things. And we don’t have to worry about browser issues.
It is an inspiring feeling to be the person who solved a web-wide issue. It boosts our ego to see that people rely on our brains to solve issues for them. It is great to see them become more effective and faster and free to build the next Facebook.
It gets less amazing when you want to move on and do something else. And when people have outrageous demands or abuse your system. Remy Sharp lately released a series of honest and important blog posts on that matter. “The toxic side of free” is a great and terrifying read.
Publishing something new in JavaScript as “open source” is easy these days. GitHub made it more or less a one step process. And we get a free wiki, issue tracker and contribution process with it to boot. That, of course, doesn’t mean we can make this much more complex if we wanted to. And we do as Eric Douglas explains.

Releasing software or solutions as open source is not the same as making it available for free. It is the start of a long conversation with users and contributors. And that comes with all the drama and confusion that is human interaction. Open Source is free as in puppy. It comes with responsibilities. Doing it wrong results in a badly behaving product and community around it.

If you embrace the idea that open source and publishing on the web is a team effort, you realise that there is no need to be on the bleeding edge. On the opposite – any “out there” idea needs a group of peers to review and use it to get data on how sensible the idea really is. We tend to skip that part all too often. Instead of giving feedback or contributing to a solution we discard it and build our own. This means all we have to do is to deal with code and not people. It also means we pile on to the already unloved and unused “amazing solutions” for problems of the past that litter the web.
The average web page is 2MB with over 100 http requests. The bulk of this is images, but there is also a lot of JS and CSS magical solutions in the mix.
If we consider that the next growth of the internet is not in the countries we are in, but in emerging places with shaky connectivity, our course of action should be clear: clean up the web.
Of course we need to innovate and enhance our web technology stack. At the same time it is important to understand that the web is an unprecedented software environment. It is not only about what we put in, it is also about what we can’t afford to lose. And the biggest part of this is universal access. That also means it needs to remain easy to turn from consumer into creator on the web.
If you watch talks about internet usage in emerging countries, you’ll learn about amazing numbers and growth predictions.
You also learn about us not being able to control what end users see. Many of our JS solutions will get stripped out. Many of our beautiful, crafted pictures optimised into a blurry mess. And that’s great. It means the users of the web of tomorrow are as empowered as we were when we stood up and fought against browser monopolies.
So there you have it: you don’t have to be the inventor of the next NPM module to solve all our issues. You can be, but it shouldn’t make you feel bad that you’re not quite interested in doing so. As Bill Watterson of Calvin and Hobbes fame put it:
We all have different desires and needs, but if we don’t discover what we want from ourselves and what we stand for, we will live passively and unfulfilled.
So, be active. Don’t feel intimidated by how clever other people appear to be. Don’t be discouraged if you don’t get thousands of followers and GitHub stars. Find what you can do, how you can help the merging of bleeding edge technologies and what goes into our products. Above all – help the web get leaner and simpler again. This used to be a playground for us all – not only for the kids with the fancy toys.
You do that by talking to the messy kids. Those who build too complex and big solutions for simple problems. Those doing that because clever people told them they have to use all these tools to build them. The people on the bleeding edge are too busy to do that. You can. And I promise, by taking up teaching you end up learning.
https://www.christianheilmann.com/2015/09/30/of-impostor-syndrome-and-running-in-circles-part-3/
|
|
John Ford: Taskcluster Component Loader |
bin/server.js file for each service. This script basically loads up our config system, loads our Azure Entity library, loads a Pulse publisher, a JSON Schema validator and a Taskcluster-base App. Each background worker has its own bin/something.js which basically has a very similar loop. Services with unit tests have a test/helper.js file which initializes the various components for testing. Furthermore, we might have things initialize inside of a given before() or beforeEach().string, number, function, Promise or an object without a create property, we just give that exact value back as a resolved Promise. If the component is an object with a create property, we initialize the dependencies specified by the 'requires' list property, pass those values as properties on an object to the function at the 'create' property. The value of that function's return is stored as a resolved promise. Components can only depend on other components non-flat dependencies.
// lib/components.js
let loader = require('taskcluster-base').loader;
let fakeEntityLibrary = require('fake');
module.exports = loader({
fakeEntity: {
requires: ['connectionString'],
setup: async deps => {
let conStr = await deps.connectionString;
return fakeEntityLibrary.create(conStr);
},
},
},
['connectionString'],
);
// bin/server.js
let config = require('taskcluster-base').config('development');
let loader = require('../lib/components.js');
let load = loader({
connectionString: config.entity.connectionString,
});
let configuredFakeEntity = await load('fakeEntity') http://blog.johnford.org/2015/09/taskcluster-component-loader.html
|
|
Joel Maher: Say hi to Gabriel Machado- a newer contributor on the Perfherder project |
Earlier this summer, I got an email from Gabriel asking how he could get involved in Automation and Tools projects at Mozilla. This was really cool and I was excited to see Gabriel join the Mozilla Community. Gabriel is knows as :goma on IRC and based on his interests and projects with mentors available, hacking on TreeHerder was a good fit. Gabriel also worked on some test cases for the Firefox-UI-Tests. You can see the list of bugs he has been involved with and check him out on Github.
While it is great to see a contributor become more comfortable in their programming skills, it is even better to get to know the people you are working with. As I have done before, I would like to take a moment to introduce Gabriel and let him do the talking:
Tell us about where you live –
I lived in Durham-UK since last year, where I was doing an exchange program. About Durham I can say that is a lovely place, it has a nice weather, kind people, beautiful castles and a stunning “medieval ambient”. Besides it is a student city, with several parties and cultural activities.
I moved back to Brazil 3 days ago, and next week I’ll move to the city of Ouro Preto to finish my undergrad course. Ouro Preto is another beautiful historical city, very similar to Durham in some sense. It is a small town with a good university and stunning landmarks. It’s a really great place, designated a world heritage site by UNESCO.
Tell us about your school –
In 2 weeks I’ll begin my third year in Computer Science at UFOP(Federal University of Ouro Preto). It is a really good place to study computer science, with several different research groups. In my second year I earned a scholarship from the Brazilian Government to study in the UK. So, I studied my second year at Durham University. Durham is a really great university, very traditional and it has a great infra-structure. Besides, they filmed several Harry Potter scenes there :P
Tell us about getting involved with Mozilla –
In 2014 I was looking for some open source project to contribute with when I found the Mozilla Contributing Guide. It is a really nice guide and helped me a lot. I worked on some minors bugs during the year. In July of 2015, as part of my scholarship to study in the UK, I was supposed to do a small final project and I decided to work with some open source project, instead of an academic research. I contacted jmaher by email and asked him about it. He answered me really kindly and guided me to contribute with the Treeherder. Since then, I’ve been working with the A-Team folks, working with Treeherder and Firefox-Ui-Tests.
I think Mozilla does a really nice job helping new contributors, even the new ones without experience like me. I used to think that I should be a great hacker, with tons of programming knowledge to contribute with an open source project. Now, I think that contributing with an open source project is a nice way to become a great hacker with tons of programming knowledge
Tell us what you enjoy doing –
I really enjoy computers. Usually I spent my spare time testing new operating systems, window managers or improving my Vim. Apart from that, I love music. Specially instrumental. I play guitar, bass, harmonica and drums and I really love composing songs. You can listen some of my instrumental musics here: https://soundcloud.com/goma_audio
Besides, I love travelling and meeting people from different cultures. I really like talking about small particularities of different languages.
Where do you see yourself in 5 years?
I hope be a software engineer, working with great and interesting problems and contributing for a better (and free) Internet.
If somebody asked you for advice about life, what would you say?
Peace and happiness comes from within, do not seek it without.
Please say hi to :goma on irc in #treeherder or #ateam.

|
|
Daniel Stenberg: libbrotli is brotli in lib form |
Brotli is this new cool compression algorithm that Firefox now has support for in Content-Encoding, Chrome will too soon and Eric Lawrence wrote up this nice summary about.
So I’d love to see brotli supported as a Content-Encoding in curl too, and then we just basically have to write some conditional code to detect the brotli library, add the adaption code for it and we should be in a good position. But…
There is (was) no brotli library!
It turns out the brotli team just writes their code to be linked with their tools, without making any library nor making it easy to install and use for third party applications.
 We can’t have it like that! I rolled up my imaginary sleeves (imaginary since my swag tshirt doesn’t really have sleeves) and I now offer libbrotli to the world. It is just a bunch of files and a build system that sucks in the brotli upstream repo as a submodule and then it builds a decoder library (brotlidec) and an encoder library (brotlienc) out of them. So there’s no code of our own here. Just building on top of the great stuff done by others.
We can’t have it like that! I rolled up my imaginary sleeves (imaginary since my swag tshirt doesn’t really have sleeves) and I now offer libbrotli to the world. It is just a bunch of files and a build system that sucks in the brotli upstream repo as a submodule and then it builds a decoder library (brotlidec) and an encoder library (brotlienc) out of them. So there’s no code of our own here. Just building on top of the great stuff done by others.
It’s not complicated. It’s nothing fancy. But you can configure, make and make install two libraries and I can now go on and write a curl adaption for this library so that we can get brotli support for it done. Ideally, this (making a library) is something the brotli project will do on their own at some point, but until they do I don’t mind handling this.
As always, dive in and try it out, file any issues you find and send us your pull-requests for everything you can help us out with!
http://daniel.haxx.se/blog/2015/09/30/libbrotli-is-brotli-in-lib-form/
|
|
William Lachance: Perfherder summer of contribution thoughts |
A few months ago, Joel Maher announced the Perfherder summer of contribution. We wrapped things up there a few weeks ago, so I guess it’s about time I wrote up a bit about how things went.
As a reminder, the idea of summer of contribution was to give a set of contributors the opportunity to make a substantial contribution to a project we were working on (in this case, the Perfherder performance sheriffing system). We would ask that they sign up to do 5-10 hours of work a week for at least 8 weeks. In return, Joel and myself would make ourselves available as mentors to answer questions about the project whenever they ran into trouble.
To get things rolling, I split off a bunch of work that we felt would be reasonable to do by a contributor into bugs of varying difficulty levels (assigning them the bugzilla whiteboard tag ateam-summer-of-contribution). When someone first expressed interest in working on the project, I’d assign them a relatively easy front end one, just to cover the basics of working with the project (checking out code, making a change, submitting a PR to github). If they made it through that, I’d go on to assign them slightly harder or more complex tasks which dealt with other parts of the codebase, the nature of which depended on what they wanted to learn more about. Perfherder essentially has two components: a data storage and analysis backend written in Python and Django, and a web-based frontend written in JS and Angular. There was (still is) lots to do on both, which gave contributors lots of choice.
This system worked pretty well for attracting people. I think we got at least 5 people interested and contributing useful patches within the first couple of weeks. In general I think onboarding went well. Having good documentation for Perfherder / Treeherder on the wiki certainly helped. We had lots of the usual problems getting people familiar with git and submitting proper pull requests: we use a somewhat clumsy combination of bugzilla and github to manage treeherder issues (we “attach” PRs to bugs as plaintext), which can be a bit offputting to newcomers. But once they got past these issues, things went relatively smoothly.
A few weeks in, I set up a fortnightly skype call for people to join and update status and ask questions. This proved to be quite useful: it let me and Joel articulate the higher-level vision for the project to people (which can be difficult to summarize in text) but more importantly it was also a great opportunity for people to ask questions and raise concerns about the project in a free-form, high-bandwidth environment. In general I’m not a big fan of meetings (especially status report meetings) but I think these were pretty useful. Being able to hear someone else’s voice definitely goes a long way to establishing trust that you just can’t get in the same way over email and irc.
I think our biggest challenge was retention. Due to (understandable) time commitments and constraints only one person (Mike Ling) was really able to stick with it until the end. Still, I’m pretty happy with that success rate: if you stop and think about it, even a 10-hour a week time investment is a fair bit to ask. Some of the people who didn’t quite make it were quite awesome, I hope they come back some day. 
—
On that note, a special thanks to Mike Ling for sticking with us this long (he’s still around and doing useful things long after the program ended). He’s done some really fantastic work inside Perfherder and the project is much better for it. I think my two favorite features that he wrote up are the improved test chooser which I talked about a few months ago and a get related platform / branch feature which is a big time saver when trying to determine when a performance regression was first introduced.
I took the time to do a short email interview with him last week. Here’s what he had to say:
1. Tell us a little bit about yourself. Where do you live? What is it you do when not contributing to Perfherder?
I’m a postgraduate student of NanChang HangKong university in China whose major is Internet of things. Actually,there are a lot of things I would like to do when I am AFK, play basketball, video game, reading books and listening music, just name it ; )
2. How did you find out about the ateam summer of contribution program?
well, I remember when I still a new comer of treeherder, I totally don’t know how to start my contribution. So, I just go to treeherder irc and ask for advice. As I recall, emorley and jfrench talk with me and give me a lot of hits. Then Will (wlach) send me an Email about ateam summer of contribution and perfherder. He told me it’s a good opportunity to learn more about treeherder and how to work like a team! I almost jump out of bed (I receive that email just before get asleep) and reply with YES. Thank you Will!
3. What did you find most challenging in the summer of contribution?
I think the most challenging thing is I not only need to know how to code but also need to know how treeherder actually work. It’s a awesome project and there are a ton of things I haven’t heard before (i.e T-test, regression). So I still have a long way to go before I familiar with it.
4. What advice would give you to future ateam contributors?
The only thing you need to do is bring your question to irc and ask. Do not hesitate to ask for help if you need it! All the people in here are nice and willing to help. Enjoy it!
http://wrla.ch/blog/2015/09/perfherder-summer-of-contribution-thoughts/
|
|
Ehsan Akhgari: My experience adding a new build type using TaskCluster |
TaskCluster is Mozilla’s task queuing, scheduling and execution service. It allows the user to schedule a DAG representing a task graph that describes a some tasks and their dependencies, and how to execute them, and it schedules them to run in the needed order on a number of slave machines.
As of a while ago, some of the continuous integration tasks have been runing on TaskCluster, and I recently set out to enable static analysis optimized builds on Linux64 on top of TaskCluster. I had previously added a similar job for debug builds on OS X in buildbot, and I am amazed at how much the experience has improved! It is truly easy to add a new type of job now as a developer without being familiar with buildbot or anything like that. I’m writing this post to share my experience on how I did this.
The process of scheduling jobs in TaskCluster starts by a slave downloading a specific revision of a tree, and running the ./mach taskcluster-graph command to generate a task graph definition. This is what happens in a “gecko-decision” jobs that you can see on TreeHerder. The mentioned task graph is computed using the task definition information in testing/taskcluster. All of the definitions are in YAML, and I found the naming of variables relatively easy to understand. The build definitions are located in testing/taskcluster/tasks/builds and after some poking around, I found linux64_clobber.yml.
If you look closely at that file, a lot of things are clear from the names. Here are important things that this file defines:
Looking at the build definition file, you will find the steps run in the build, whether the build should trigger unit tests or Talos jobs, the environment variables used during the build, and most importantly the mozconfig and tooltool manifest paths. (In case you’re not familiar with Tooltool, it lets you upload your own tools to be used during the build time. This can be new experimental toolchains, custom programs your build needs to run, which is useful for things such as performing actions on the build outputs, etc.)
This basically gave me everything I needed to define my new build type, and I did that in bug 1203390, and these builds are now visible on TreeHerder as “[Tier-2](S)” on Linux64. This is the gist of what I came up with.
](http://www.liveinternet.ru/journal_proc.php?action=redirect&url=http://ehsanakhgari.org/wp-content/uploads/2015/09/Tier2S.png)
I think this is really powerful since it finally allows you to fully control what happens in a job. For example, you can use this to create new build/test types on TreeHerder, do try pushes that test changes to the environment a job runs in, do highly custom tasks such as creating code coverage results, which requires a custom build step and custom test steps and uploading of custom artifacts! Doing this under the old BuildBot system is unheard of. Even if you went out of your way to learn how to do that, as I understand it, there was a maximum number of build types that we were getting close to which prevented us from adding new job types as needed! And it was much much harder to iterate on (as I did when I was working on this on the try server bootstrapping a whole new build type!) as your changes to BuildBot configs needed to be manually deployed.
Another thing to note is that I found out all of the above pretty much by myself, and didn’t even have to learn every bit of what I encountered in the files that I copied and repurposed! This was extremely straightforward. I’m already on my way to add another build type (using Ted’s bleeding edge Linux to OS X cross compiling support)! I did hit hurdles along the way but almost none of them were related to TaskCluster, and with the few ones that were, I was shooting myself in the foot and Dustin quickly helped me out. (Thanks, Dustin!)
Another near feature of TaskCluster is the inspector tool. In TreeHerder, you can click on a TaskCluster job, go to Job Details, and click on “Inspect Task”. You’ll see a page like this. In that tool you can do a number of neat things. One is that it shows you a “live.log” file which is the live log of what the slave is doing. This means that you can see what’s happening in close to real time, without having to wait for the whole job to finish before you can inspect the log. Another neat feature is the “Run locally” commands that show you how to run the job in a local docker container. That will allow you to reproduce the exact same environment as the ones we use on the infrastructure.
I highly encourage people to start thinking about the ways they can harness this power. I look forward to see what we’ll come up with!
http://ehsanakhgari.org/blog/2015-09-29/my-experience-adding-new-build-type-taskcluster
|
|
Air Mozilla: Martes mozilleros |
 Reuni'on bi-semanal para hablar sobre el estado de Mozilla, la comunidad y sus proyectos.
Reuni'on bi-semanal para hablar sobre el estado de Mozilla, la comunidad y sus proyectos.
|
|
Daniel Stenberg: daniel weekly 42, switching off Nagle |
See you at ApacheCon on Friday!
14% HTTP/2 thanks to nginx ?
Brotli everywhere! Firefox, libbrotli
The –libcurl flaw is fixed (and it was GONE from github for a few hours)
No, the cheat sheet cannot be in the man page. But…
bug of the week: the http/2 performance fix
option of the week: -k
Talking at the GOTO Conference next week
http://daniel.haxx.se/blog/2015/09/29/daniel-weekly-42-switching-off-nagle/
|
|
George Roter: Participation Team: Getting organized and focused |
The Participation Team was created back in January of this year with an ambitious mandate to simultaneously a) get more impact, for Mozilla’s mission and its volunteers, from core contributor participation methods we’re using today, and b) to find and develop new ways that participation can work at Mozilla.
This mandate stands on the shoulders of people and teams who lead this work around Mozilla in the past, including the Community Building Team. As a contrast with these past approaches, our team concentrates staff from around Mozilla, has a dedicated budget, and has the strong support of leadership, reporting to Mitchell Baker (the Executive Chair) and Mark Surman (CEO of the foundation).
For the first half of the year, our approach was to work with and learn from many different teams throughout Mozilla. From Dhaka to Dakar — and everywhere in between — we supported teams and volunteers around the world to increase their effectiveness. From MarketPulse to the Webmaker App launches we worked with different teams within Mozilla to test new approaches to building participation, including testing out what community education could look like. Over this time we talked with/interviewed over 150 staff around Mozilla, generated 40+ tangible participation ideas we’d want to test, and provided “design for participation” consulting sessions with 20+ teams during the Whistler all-hands.
Toward the end of July, we took stock of where we were. We established a set of themes for the rest of 2015 (and maybe beyond), are focused especially on enabling Mozilla’s Core Contributors, and I put in place a new team structure.
You can see these themes reflected in our Q3 Objectives and Key Results.
The Participation Team is focused on activating, growing and increasing the effectiveness of our community of core contributors. Our modified team structure has 5 areas/groups, each with a Lead and a bottom-line accountability. You’ll note that all of these team members are staff — our aim in the coming months is to integrate core contributors into this structure, including existing leadership structures like the ReMo Council.
| Participation Partners | Global-Local Organizing | Developing Leaders | Participation Technology | Performance and Learning |
| Lead:
William Quiviger Brian King |
Lead:
Rosana Ardila Ruben Martin Guillermo Movia Konstantina Papadea Francisco Picolini |
Lead:
George Roter (acting) Emma Irwin |
Lead:
Pierros Papadeas Nemo Giannelos Tasos Katsoulas Nikos Roussos |
Lead:
Lucy Harris |
| Bottom Line:
Catalyze participation with product and functional teams to deliver and sustain impact |
Bottom Line:
Grow the capacity of Mozilla’s communities to engage volunteers and have impact |
Bottom Line:
Grow the capacity of Mozilla’s volunteer leaders and volunteers to have impact |
Bottom Line:
Enable large scale, high impact participation at Mozilla through technology |
Bottom Line:
Develop a high performing team, and drive learning and synthesize best practice through the Participation Lab |
We have also established a Leadership and Strategy group accountable for:
This is made up of Rosana Ardila, Lucy Harris, Brian King, Pierros Papadeas, William Quiviger and myself.
As always, I’m excited to hear your feedback on any of this — it is most certainly a work in progress. We also need your help:
As always, feel free to reach out to any member of the team; find us on IRC at #participation; follow along with what we’re doing on the Blog and by following [@MozParticipate on Twitter](https://twitter.com/mozparticipate); have a conversation on Discourse; or follow/jump into any issues on GitHub.

http://georgeroter.org/2015/09/28/participation-team-getting-organized-and-focused/
|
|
The Servo Blog: This Week In Servo 35 |
In the last week, we landed 37 PRs in the Servo repository!
In addition to a rustup by Manish and a lot of great cleanup, we also saw:
Servo on Windows! Courtesy of Vladimir Vukicevic.
Text shaping improvements in Servo:
At last week’s meeting, we discussed the outcomes from the Paris layout meetup, how to approach submodule updates, and trying to reduce the horrible enlistment experience with downloading Skia.
|
|
Air Mozilla: Mozilla Weekly Project Meeting |
 The Monday Project Meeting
The Monday Project Meeting
https://air.mozilla.org/mozilla-weekly-project-meeting-20150928/
|
|
Christian Heilmann: Of impostor syndrome and running in circles (part 2) |
These are the notes of my talk at SmartWebConf in Romania. Part 1 covered how Impostor Syndrome cripples us in using what we hear about at conferences. It also covered how our training and onboarding focuses on coding. And how it lacks in social skills and individuality. This post talks about the current state of affairs. We have a lot of great stuff to play with but instead of using it we always chase the next.
This is part 2 of 3.
When reading about the state of the web there is no lack of doom and gloom posts. Native development is often quoted as “eating our lunch”. Native-only interaction models are sold to us as things “people use these days”. Many of them are dependent on hardware or protected by patents. But they look amazing and in comparison the web seems to fall behind.
This is true, but it also not surprising. Flash showed many things that are possible that HTML/CSS/JS couldn’t do. Most of these were interesting experiments. They looked like a grand idea at the time. And they went away without an outcry of users. What a native environment have and what we do on the web is a comparison the web can’t win. And it shouldn’t try to.
The web per definition is independent of hardware and interaction model. Native environments aren’t – on the contrary. Success on native is about strict control. You control the interaction, the distribution and what the user can and can’t see. You can lock out users and not let them get to the next level. Unless they pay for it or buy the next version of your app or OS. The web is a medium that puts the user in control. Native apps and environments do not. They give users an easy to digest experience. An experience controlled by commercial ideas and company goals. Yes, the experience is beautiful in a lot of cases. But all you get is a perishable good. The maintainer of the app controls what stays in older versions and when you have to pay the next version. The maintainers of the OS dictate what an app can and can not do. Any app can close down and take your data with it. This is much harder on the web as data gets archived and distributed.
Evolution happens and we are seeing this right now. Browsers on desktop machines are not the end-all of human-computer interaction. That is one way of consuming and contributing to the web. The web is ubiquitous now. That means it is not as exciting for people as it was for us when we discovered and formed it. It is plumbing. How much do you know about the electricity and water grid that feeds your house? You never cared to learn about this – and this is exactly how people feel about the web now.
This doesn’t mean the web is dead – it just means it is something people use. So our job should be to make that experience as easy as possible. We need to provide a good service people can trust and rely on. Our aim should be reliability, not flights of fancy.
It is interesting to go back to the promises HTML5 gave us. Back when it was the big hype and replacement for Flash/Flex. When you do this, you’ll find a lot of great things that we have now without realising them. We complained when they didn’t work and now that we have them – nobody seems to use them.
Take forms for example. You can see the demos I’m about to show here on GitHub.
When it comes down to it, most “apps” in their basic form are just this: forms. You enter data, you get data back. Games are the exception to this, but they are only a small part of what we use the web for.
When I started as a web developer forms meant you entered some data. Then you submitted the form and you got an error message telling you what fields you forgot and what you did wrong.
span> action="/cgi-bin/formmail.pl"> span> class="error"> >There were some errors: > >span> href="#name">Name is required>> >span> href="#birthday">Birthday needs to be in the format of DD/MM/YYYY>> >span> href="#phone">Phone can't have any characters but 0-9>> >span> href="#age">Age needs to be a number>> > > > >span> for="name">Contact Name *> span> type="text" id="name" name="name">> >span> for="bday">Birthday> span> type="text" id="bday" name="bday">> >span> for="lcolour">Label Colour> span> type="text" id="lcolour" name="lcolour">> >span> for="phone">Phone> span> type="text" id="phone" name="phone">> >span> for="age">Age> span> type="text" id="age" name="age">> span> class="sendoff"> span> type="submit" value="add to contacts"> > > |
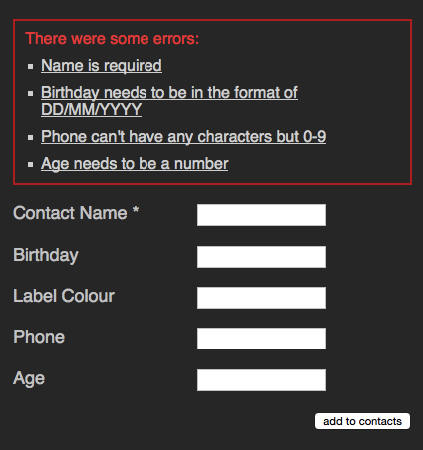
This doesn’t look much, but let’s just remember a few things here:
Nothing ground-breaking, I admit, but a lot of useful functionality. Functionality you’d have to simulate if you did it all with SPANs and DIVs. And all this without a single line of JavaScript.
Then we got JavaScript. This enabled us to create higher fidelity forms. Forms that tell the user when something went wrong before submitting. No more uneccesary page reloads. We started to build richer interaction models like forms with optional fields depending on the content of others. In my 2006 book Beginning JavaScript with DOM Scripting in Ajax I had a whole chapter dedicated to forms (code examples are here). All of these enhancements had the problem that when JavaScript for some reason or another didn’t work, the form still was happily submitting data to the server. That meant and still means that you have to validate on the server in addition to relying on client-side validation. Client side validation is a nice-to-have, not a security measure.
HTML5 supercharged forms. One amazing thing is the required attribute we can put on any form field to make it mandatory and stop the form from submitting. We can define patterns for validation and we have higher fidelity form types that render as use-case specific widgets. If a browser doesn’t support those, all the end user gets is an input field. No harm done, as they can just type the content.
In addition to this, browsers added conveniences for users. Browsers remember content for aptly named and typed input elements so you don’t have to type in your telephone number repeatedly. This gives us quite an incredible user experience. A feature we fail to value as it appears so obvious.
Take this example.
span> action="/cgi-bin/formmail.pl"> >span> for="name">Contact Name *> span> type="text" required id="name" name="name">> >span> for="bday">Birthday> span> type="date" id="bday" name="bday" placeholder="DD/MM/YYYY">> >span> for="lcolour">Label Colour> span> type="color" id="lcolour" name="lcolour">> >span> for="phone">Phone> span> type="tel" id="phone" name="phone">> >span> for="age">Age> span> type="number" id="age" name="age">> span> class="sendoff"> span> type="submit" value="add to contacts"> > > |
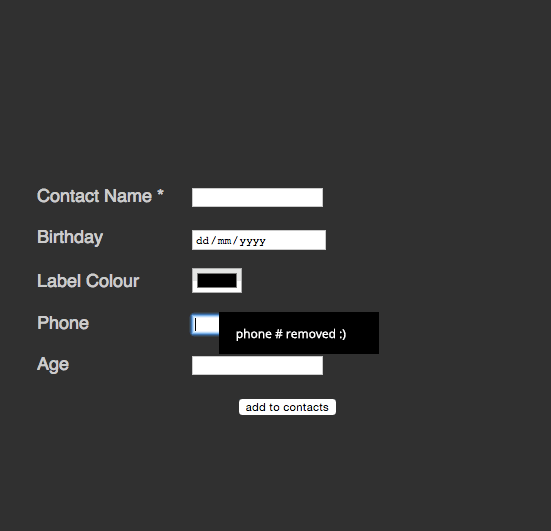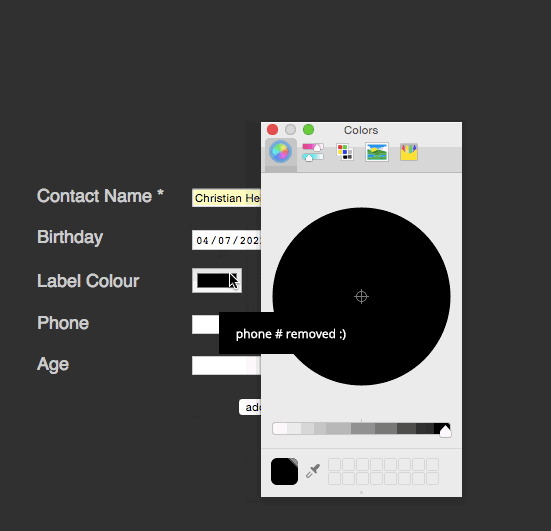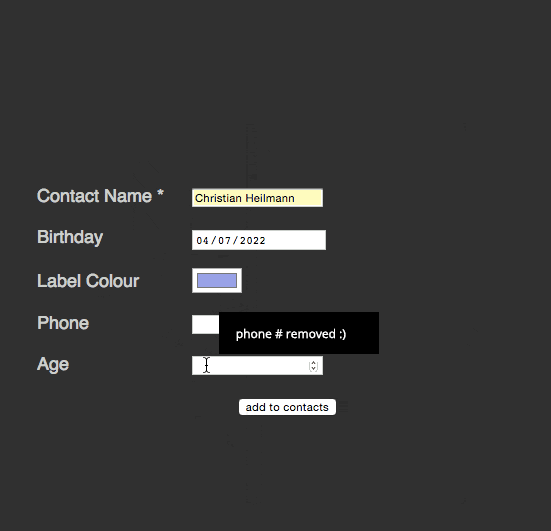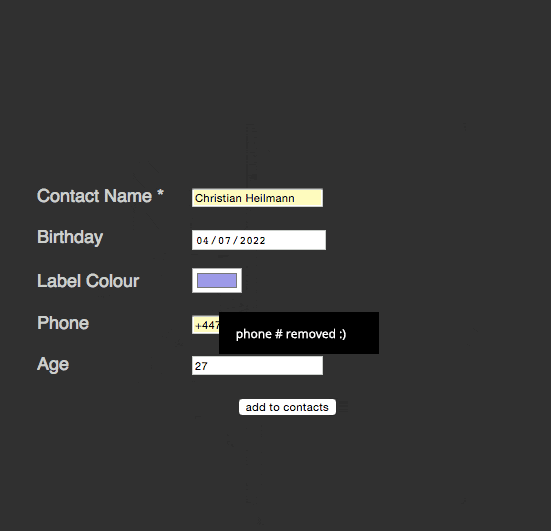
There’s a lot of cool stuff happening here:
required attribute does. No JavaScript needed here. You even can rename the error message or intercept it.date field has a placeholder telling the user what format is expected. You can type a date in or use the arrows up and down to enter it. The form automatically realises that there is no 13th month and that some months have less than 31 days. Other browsers even give you a full calendar popup.tel and number types do not only limit the allowed characters to use, but also switch to the appropriate on-screen keyboards on mobile devices.That’s a lot of great interaction we get for free. What about cutting down on the display of data to make the best of limited space we have?
Originally, this is what we had select boxes for, which render well, but are not fun to use. As someone living in England and having to wonder if it is “England”, “Great Britain” or “United Kingdom” in a massive list of countries, I know exactly how that feels. Especially on small devices on touch/stylus devices they can be very annoying.
span> action="/cgi-bin/formmail.pl"> > span> for="lang">Language> span> id="lang" name="lang"> >arabic> >bulgarian> >catalan> […] >kinyarwanda> >wolof> >dari> >scottish_gaelic> > > span> class="sendoff"> span> type="submit" value="add to contacts"> > > |
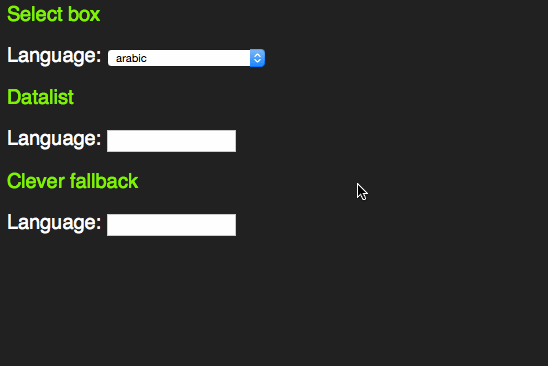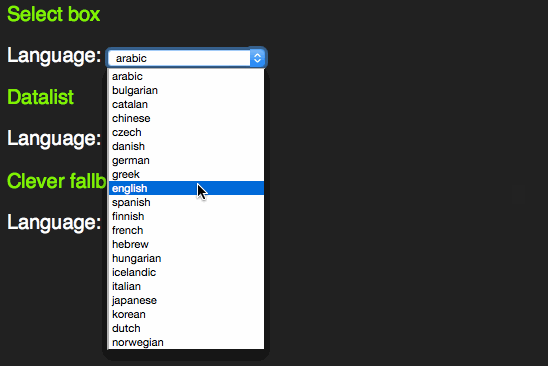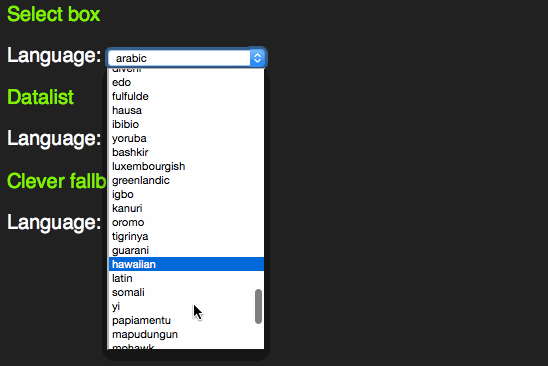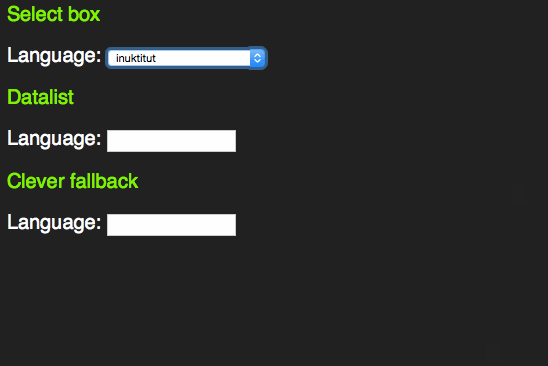
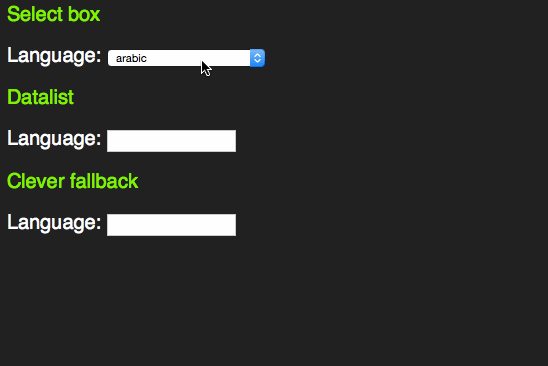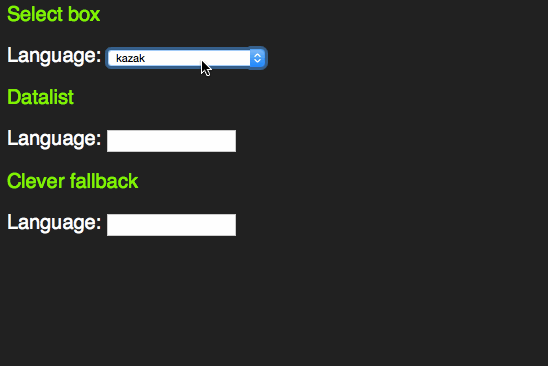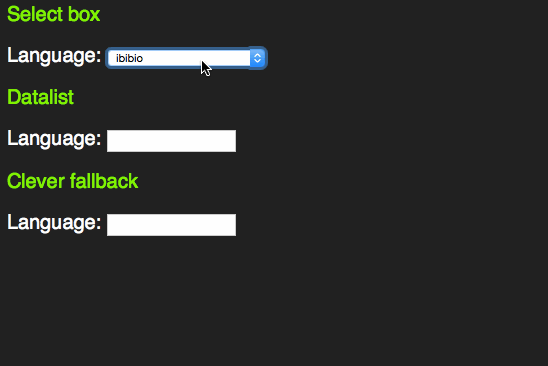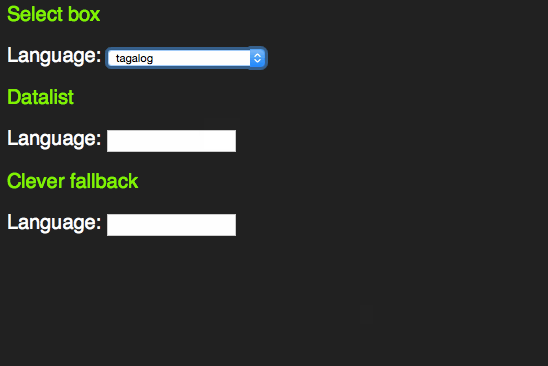
However, as someone who uses the keyboard to navigate through forms, I learned early enough that these days select boxes have become more intelligent. Instead of having to scroll through them by clicking the tiny arrows or using the arrow keys you can start typing the first letter of the option you want to choose. That way you can select much faster.
This only works with words beginning with the letter sequence you type. A proper autocomplete should also match character sequences in the middle of an option. For this, HTML5 has a new element called datalist.
span> action="/cgi-bin/formmail.pl"> > span> for="lang">Language> span> type="text" name="lang" id="lang" list="languages"> span> id="languages"> >arabic> >bulgarian> >catalan> […] >kinyarwanda> >wolof> >dari> >scottish_gaelic> > > span> class="sendoff"> span> type="submit" value="add to contacts"> > > |
This one extends an input element with a list attribute and works like you expect it to:
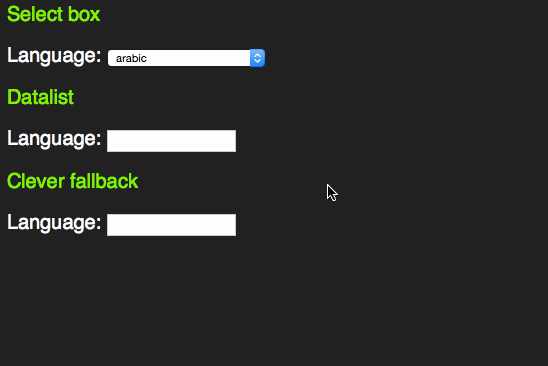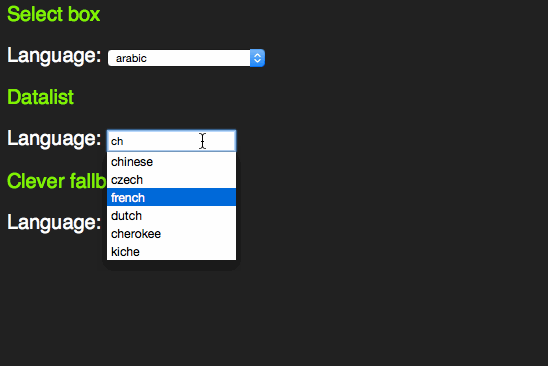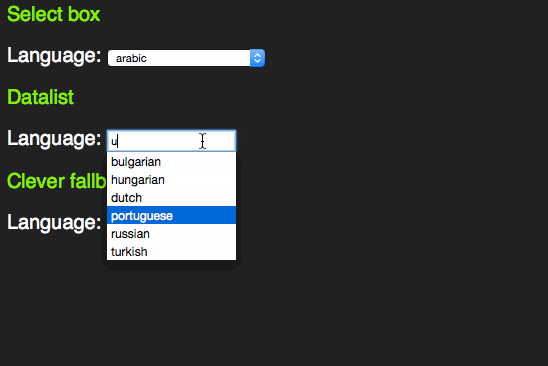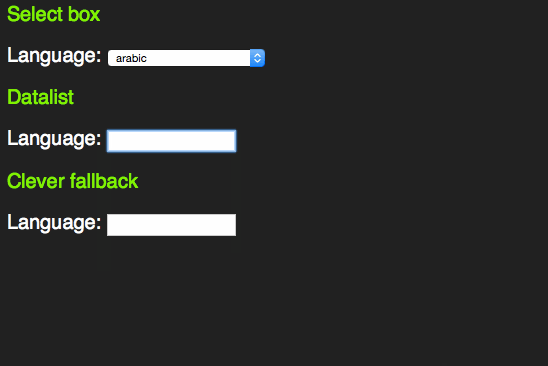
There is an interesting concept here. Instead of making the select box have the same feature and roll it up into a combo box that exists in other UI libraries, the working group of HTML5 chose to enhance an input element. This is consistent with the other new input types.
However, it feels odd that for browsers that don’t support the datalist element all this content in the page would be useless. Jeremy Keith thought the same and came up with a pattern that allows for a select element in older browsers and a datalist in newer ones:
span> action="/cgi-bin/formmail.pl"> > span> for="lang">Language> span> id="languages"> span> name="lang"> >arabic> >bulgarian> >catalan> […] >kinyarwanda> >wolof> >dari> >scottish_gaelic> > > >or specify: > span> type="text" name="lang" id="lang" list="languages"> > span> class="sendoff"> span> type="submit" value="add to contacts"> > > |
This works as a datalist in HTML5 compliant browsers.
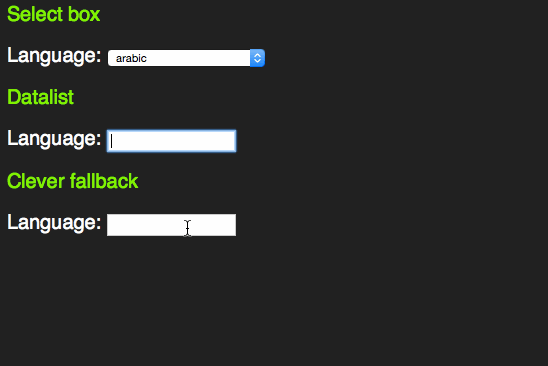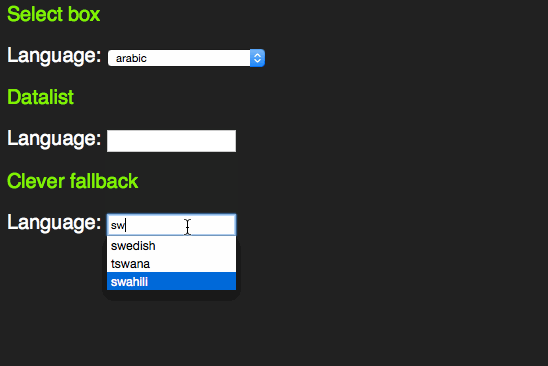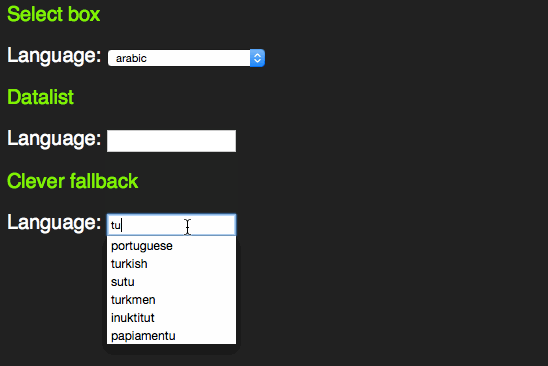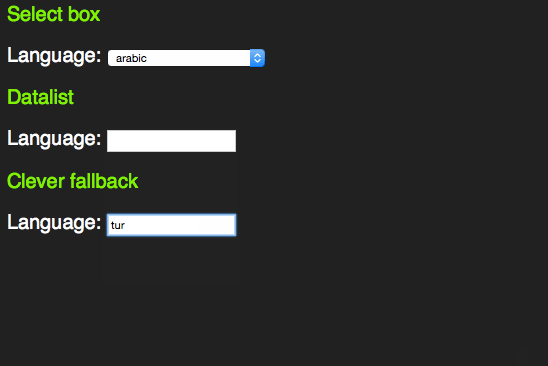
In older browsers, you get a sensible fallback, re-using all the option elements that are in the document.
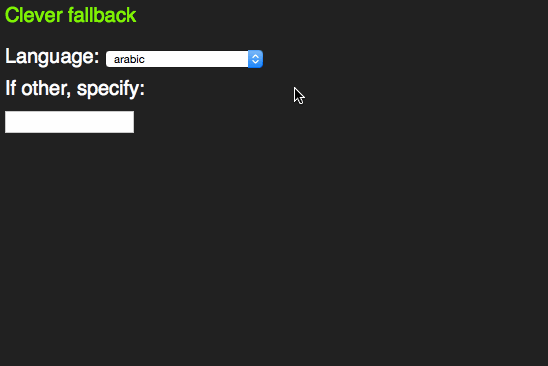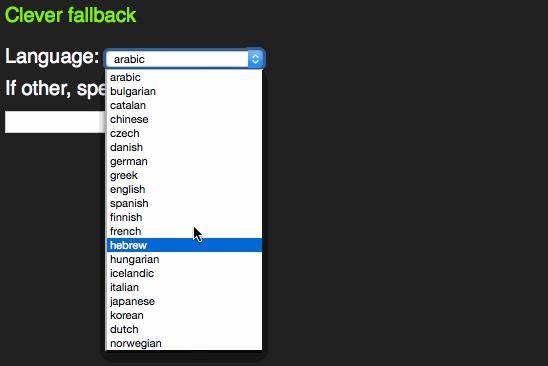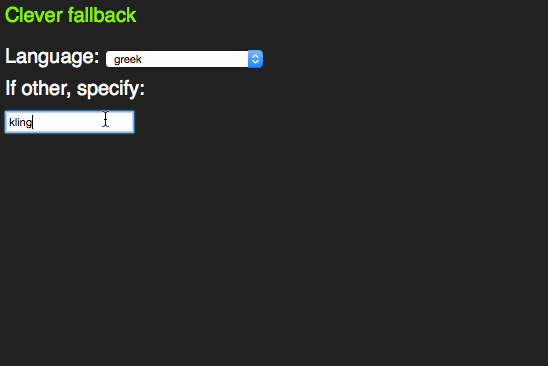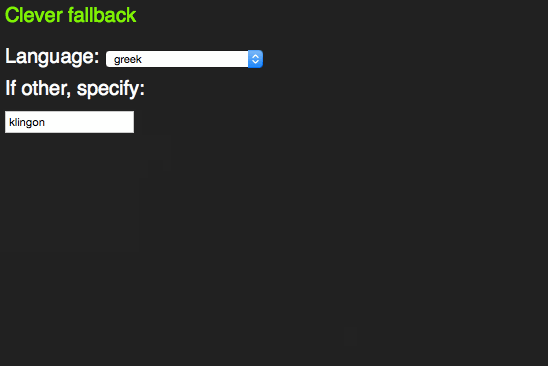
This is not witchcraft, but is based on a firm understanding of how HTML and CSS work. Both these are fault tolerant. This means if a mistake happens, it gets skipped and the rest of the document or style sheet keeps getting applied.
In this case, older browsers don’t know what a datalist is. All they see is a select box and an input element as browsers render content of unknown elements. The unknown list attribute on the input element isn’t understood, so the browser skips that, too.
HTML5 browsers see a datalist element. Per standard, all this can include are option elements. That’s why neither the select, nor the input and the text above it get rendered. They are not valid, so the browser removes them. Everybody wins.
Browsers and the standards they implement are full of clever and beautiful things like that these days. And we’ve loudly and angrily demanded to have them when they got defined. We tested, we complained, we showed what needed to be done to make the tomorrow work today and then we forgot about it. And we moved on to chase the next innovation.
How come that repeatedly happens? Why don’t we at some point stop and see how much great toys we have to play with? It is pretty simple: control.
We love to be in control and we like to call the shots. That’s why we continuously try to style form elements and create our own sliders, scroll bars and dropdown boxes. That’s why we use non-support by a few outdated browsers of a standard as an excuse to discard it completely and write a JavaScript solution instead. We don’t have time to wait for browsers to get their act together, so it is up to us to save the day. Well, no, it isn’t.
Just because you can do everything with JavaScript, doesn’t mean that you should do it. We invented HTML5 as the successor and replacement of XHTML as it had one flaw: a single wrong encoding or nesting of elements and the document wouldn’t render. End users would be punished for our mistakes. That’s why HTML5 is fault tolerant.
JavaScript is not. Any mistake that happens means the end user looks at an endless spinner or an empty page. This isn’t innovation, this is building on a flaky foundation. And whilst we do that, we forgot to re-visit the foundation we have in browsers and standards support. This is a good time to do that. You’d be surprised how many cool things you’ll find you only thought possible by using a JavaScript UI framework.
But more on that in part 3 of this post.
https://www.christianheilmann.com/2015/09/28/of-impostor-syndrome-and-running-in-circles-part-2/
|
|
Yunier Jos'e Sosa V'azquez: C'omo se hace? Cambiar la contrase~na maestra en Firefox y Thunderbird |
Hace poco nos preguntaba como cambiar la contrase~na maestra y hoy compartimos contigo los pasos para restaurar la contrase~na en el navegador y en el cliente de correo. Si no lo sab'ias, mediante la contrase~na maestra, puedes proteger tus nombres de usuario y tus contrase~nas almacenadas localmente mediante una contrase~na maestra. Si has olvidado tu contrase~na maestra, debes restablecerla.
Por seguridad y en aras de evitar el robo de tus datos, al restablecer tu contrase~na maestra, borrar'as todos las contrase~nas y todos los nombres de usuario que tengas almacenados localmente.
Pasos para restablecer la contrase~na en Firefox:
chrome://pippki/content/resetpassword.xul
Pasos para restablecer la contrase~na en Thunderbird:


Por 'ultimo, si deseas aumentar y fortalecer a'un m'as la seguridad y tu privacidad en Firefox puedes instalar algunos de los complementos publicados en nuestra galer'ia.
Fuente: Suppot Mozilla y MozillaES
http://firefoxmania.uci.cu/como-se-hace-cambiar-la-contrasena-maestra-en-firefox-y-thunderbird/
|
|
Dave Hunt: Firefox Cufflinks |
The custom made Firefox cufflinks have arrived! I’ll be working out shipping costs, and posting them out this week.





|
|
This Week In Rust: This Week in Rust 98 |
Hello and welcome to another issue of This Week in Rust! Rust is a systems language pursuing the trifecta: safety, concurrency, and speed. This is a weekly summary of its progress and community. Want something mentioned? Tweet us at @ThisWeekInRust or send us an email! Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub. If you find any errors in this week's issue, please submit a PR.
This week's edition was edited by: nasa42, brson, and llogiq.
88 pull requests were merged in the last week.
higher_ranked_sub()./DEBUG flag to MSVC linker.drop_in_place elements of Vec if T doesn't need dropping.BufWriter in fasta-redux for a nice speedup.no_default_libraries target linker option.box(PLACE) syntax.AsMut for Vec.Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
Every week the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now. This week's FCPs are:
libc crate from the nursery.alias attribute to #[link] and -l.If you are running a Rust event please add it to the calendar to get it mentioned here. Email Erick Tryzelaar or Brian Anderson for access.
No jobs listed for this week. Tweet us at @ThisWeekInRust to get your job offers listed here!
This Week, Crate of the Week is BurntSushi's quickcheck. Out of all quickcheck implementations, this is probably one of the more impressive ones. Thanks to DanielKeep, who had this to say:
It helps write property-based tests: you define some property and how to test it, and quickcheck feeds your test random inputs as it tries to narrow down the ranges within which the property fails to hold. Handy when the set of possible test cases is very large.
I'd like to add an appeal to all supporters of "repeatable tests". Don't let the worthy goal of repeatability override the worthier goal of actually finding bugs. Your deterministic tests usually cannot even make a dent in the vast space of possible inputs. With a bit of randomness thrown in, you can greatly improve you chances and thus make your tests more valuable. Also with quickcheck, you get to see a minimized input that makes your test fail, which you can then turn into a repeatable test easily.
If one regards Rust as a critique to C++, it certainly should be seen as a constructive critique. — llogiq on /r/cpp.
Thanks to msiemens for the tip. Submit your quotes for next week!
http://this-week-in-rust.org/blog/2015/09/28/this-week-in-rust-98/
|
|
Robert Longson: transform-origin for SVG elements |
Firefox has supported transform-origin on html elements since version 16 (even earlier if you count -moz-transform-origin), but it’s been a bit hit and miss using it on SVG elements.
Percentage units on SVG elements did not work at all, neither did center of course since that’s just an alias for 50%.
Fortunately that’s all about to change. Firefox 41 and 42 have a new pref svg.transform-origin.enabled that you can use to enable transform-origin support for SVG elements. Even better, Firefox 43 will not require a pref at all, it will support transform-origin straight out of the box.

https://longsonr.wordpress.com/2015/09/27/transform-origin-for-svg-elements/
|
|
Aaron Thornburgh: Experience Director vs. Logo Design |
 I used to loath designing logos.
I used to loath designing logos.
Once upon a time, I had to create 50+ logo options for any given client, simply because the Creative Director demanded it. Few appreciate (or remember) the mental effort and creative time it takes to make just one, polished concept. So producing pages and pages of logo variations required weeks of work… Meaning that nearly all of my billable time was devoted to 49 throw-away-ideas for the sake charging the client 80 hours and maybe winning a trophy. From my perspective, it was traumatic, tedious, and totally unnecessary.
But times have changed, and so has my role.
Today, there’s no fussy CD looming behind my desk dictating changes. Being both the Maker and the Boss, I instead work directly with my clients on the Content Services team, or elsewhere at Mozilla. This affords me the freedom to explore several, distinct ideas, instead of dozens.
So when the team asked me to create a logo for Zenko, I actually looked forward to the assignment.
+++++
Zenko is a reporting system used by Content Services at Mozilla for analyzing Directory or Suggested Site campaign data running in Firefox.
Developed by Data Scientist Matthew Ruttley, Zenko reports only aggregate numbers for several key user interactions. This data provides our team the information they need to assess the performance of a campaign, without using personal data. (Because the data is aggregated, it’s therefore anonymous.)
It’s simple. It’s helpful. It’s brilliant.
But how does one communicate any of these salient points through a logo?
![]()
The name itself provided the inspiration for this first option. According to Matthew, Zenko means “helpful fox” in Japanese (
http://autodidacticdesigner.com/2015/09/26/experience-director-vs-logo-design/
|
|
Patrick McManus: Thanks Google for Open Source TCP Fix! |
http://bitsup.blogspot.com/2015/09/thanks-google-tcp-team-for-open-source.html
|
|
Kim Moir: The mystery of high pending counts |

 |
| Mystery by ©Stuart Richards, Creative Commons by-nc-sa 2.0 |
 |
| Increase in seconds that new jobs added to the total compute time per push. (Some existing jobs also reduced their compute time for a total difference about about 2.5 more hours per push on Windows) |
http://relengofthenerds.blogspot.com/2015/09/the-mystery-of-high-pending-counts-and.html
|
|






