Joel Maher: community hacking – thoughts on what works for the automation and tools team |
Community is a word that means a lot of things to different people. When there is talk of community at an A*Team meeting, some people perk up and others tune out. Taking a voluntary role in leading many community efforts on the A*Team over the last year, here are some thoughts I have towards accepting contributions, growing community, and making it work within the team.
Contributions:
Historically on the A*Team we would file bugs which are mentored (and discoverable via bugsahoy) and blog/advertise help wanted. This is always met with great enthusiasm from a lot of contributors. What does this mean for the mentor? There are a few common axis here:
We need to appreciate all types of contributions and ensure we do our best to encourage folks to participate. As a mentor if you have a lot of high-touch, low-reward, short-term contributors, it is exhausting and de-moralizing. No wonder a lot of people don’t want to participate in mentoring folks as they contribute. It is also unrealistic to expect a bunch of seasoned coders to show up and implement all the great features, then repeat for years on end.
The question remains, how do you find low-touch contributors or identify ones that are high-touch at the start and end up learning fast (some of the best contributors fall into this latter category).
Growing Community:
The simple answer here is file a bunch of bugs. In fact whenever we do this they get fixed real fast. This turns into a problem when you have 8 new contributors, 2 mentors, and 10 good first bugs. Of course it is possible to find more mentors, and it is possible to file more bugs. In reality this doesn’t work well for most people and projects.
The real question to ask is what kind of growth are you looking for? To answer this is different for many people. What we find of value is slowly growing our long-term/low-touch contributors by giving them more responsibility (i.e. ownership) and really depending on them for input on projects. There is also a need to grow mentors and mentors can be contributors as well! Lastly it is great to have a larger pool of short-term contributors who have ramped up on a few projects and enjoy pitching in once in a while.
How can we foster a better environment for both mentors and contributors? Here are a few key areas:
Just focusing on the relationships and what comes after the good first bugs will go a long way in retaining new contributors and reducing the time spent helping out.
How we make it work in the A*Team:
The A*Team is not perfect. We have few mentors and community is not built into the way we work. Some of this is circumstantial, but a lot of it is within our control. What do we do and what does and does not work for us.
Once a month we meet to discuss what is going on within the community on our team. We have tackled topics such as project documentation, bootcamp tools/docs, discoverability, good next bugs, good first projects, and prioritizing our projects for encouraging new contributors.
While that sounds good, it is the work of a few people. There is a lot of negative history of contributors fixing one bug and taking off. Much frustration is expressed around helping someone with basic pull requests and patch management, over and over again. While we can document stuff all day long, the reality is new contributors won’t read the docs and still ask questions.
The good news is in the last year we have seen a much larger impact of contributors to our respective projects. Many great ideas were introduced, problems were solved, and experiments were conducted- all by the growing pool of contributors who associate themselves with the A*Team!
Recently, we discussed the most desirable attributes of contributors in trying to think about the problem in a different way. It boiled down to a couple things, willingness to learn, and sticking around at least for the medium term.
Going forward we are working on growing our mentor pool, and focusing on key projects so the high-touch and timely learning curve only happens in areas where we can spread the love between domain experts and folks just getting started.
Keep an eye out for most posts in the coming week(s) outlining some new projects and opportunities to get involved.

|
|
Mozilla Security Blog: May 2015 CA Communication |
Mozilla has sent a Communication to the Certification Authorities (CAs) who have root certificates included in Mozilla’s program. Mozilla’s CA Certificate Program governs inclusion of root certificates in Network Security Services (NSS), a set of open source libraries designed to support cross-platform development of security-enabled client and server applications. The NSS root certificate store is not only used in Mozilla products such as the Firefox browser, but is also used by other companies in a variety of applications.
The CA Communication has been emailed to the Primary Point of Contact (POC) for each CA in Mozilla’s program, and they have been asked to respond to 5 action items:
The full action items can be read here. Responses to the survey will be collated using Salesforce and the answers published in June.
With this CA Communication, we re-iterate that participation in Mozilla’s CA Certificate Program is at our sole discretion, and we will take whatever steps are necessary to keep our users safe. Nevertheless, we believe that the best approach to safeguard that security is to work with CAs as partners, to foster open and frank communication, and to be diligent in looking for ways to improve.
Mozilla Security Team
https://blog.mozilla.org/security/2015/05/12/may-2015-ca-communication/
|
|
Mozilla Open Policy & Advocacy Blog: Congress has only days left to reform surveillance law |
UPDATE: The House passed the USA FREEDOM Act today 338-88. The following statement can be attributed to Mozilla Head of Public Policy Chris Riley:
“Mozilla is pleased to see the House vote overwhelmingly today to pass the USA FREEDOM Act. This legislation significantly curtails bulk collection under the Patriot Act and other authorities, and puts us on a path to a more private and secure Internet.
We urge the Senate to swiftly follow suit and vote to pass the bipartisan USA FREEDOM Act. We are staunchly opposed to any short- or long-term reauthorization of these sections of the Patriot Act absent meaningful reforms. Now is not the time to delay on these much needed reforms.”
Original post:
This week, the U.S. House of Representatives is scheduled to vote on the USA FREEDOM Act, a bipartisan, bicameral piece of legislation that would significantly reform surveillance activities conducted under the USA PATRIOT Act.
Mozilla supports this legislation, which passed out of the House Judiciary Committee on a 25-2 vote. This version of USA FREEDOM Act would:
While we believe many more surveillance reforms are needed, this legislation would be a significant step forward to enhancing user privacy and security. Indeed, the 2nd Circuit ruled last week that the government’s mass surveillance of call detail records — information about who you called, when you called, for how long you spoke, an incredibly detailed map of your private life — under Section 215 is illegal. Congress must act now to reform these surveillance authorities.
Despite the 2nd Circuit ruling and significant grassroots pressure (including from the Mozilla community), some senators are pushing for a reauthorization of these illegal surveillance activities without any reforms. Any delay in passing the USA FREEDOM Act is likely to lead to weakened reforms, so we urge Members of Congress to reject even a short term reauthorization of Section 215 and the two other PATRIOT Act statutes which are set to expire at the end of the month.
We hope the House will overwhelmingly approve the USA FREEDOM Act this week, reflecting the significant and diverse support for this legislation, and we hope that the Senate will swiftly follow suit in passing the bill without harmful amendments.
|
|
Mozilla Open Policy & Advocacy Blog: French National Assembly advances dangerous mass surveillance law |
Mozilla is deeply concerned with last week’s overwhelming approval by the French National Assembly of the Projet de Loi Relatif au Renseignement, which intends to restructure the legal framework for French intelligence activities.
As currently written, the bill threatens the integrity of Internet infrastructure, user privacy, and data security. More specifically, the current bill authorizes France’s intelligence services to:
We’ve previously voiced our concerns against this legislation, as did an impressive number of very diverse stakeholders ranging from Internet users, civil society groups, businesses, lawyers’ and magistrates’ unions, the French association of victims of terrorism, the French Digital Council, as well as administrative authorities such as the CNIL (French Data Protection authority), CNCDH (French National Consultative Committee for Human Rights). The legislators seem to have given little consideration to these myriad voices and, unfortunately, all of the proposed provisions we warned about in our previous post have been included in the bill that passed the National Assembly.
There is a stark discrepancy between the open and constructive discussions being held in international fora and France’s trajectory and disregard for the expressed concerns in these matters. For instance, while France was a founding member of the Freedom Online Coalition, a group of 26 governments committed to Internet freedom, the French government was disappointingly nowhere to be seen at the Coalition’s annual conference this week in Mongolia.
The Intelligence Bill now moves to the French Senate for consideration. We urge the French senators to uphold France’s international commitments, engage in a meaningful way with the concerns that have been raised by numerous stakeholders, and update the bill accordingly. All concerned actors can and should continue to speak out against the bill, for instance, through the Sous Surveillance campaign run by La Quadrature du Net and other civil society groups.
Finally, we call on France, as an international leader in upholding human rights around the world, to set a positive example for other governments rather than continuing on a course of eroding protections for users and undermining the open Internet.
|
|
Henrik Skupin: Firefox Automation report – Q1 2015 |
As you may have noticed I was not able to come up with status reports of the Firefox Automation team during the whole last quarter. I feel sad about it, but there was simply no time to keep up with those blog posts. Even now I’m not sure how often I will be able to blog. So maybe I will aim to do it at least once a quarter or if possible once a month.
You may ask how it comes? The answer is simple. Our team faced some changes and finally a massive loss of core members. Which means from the former 6 people only myself are remaining. Since end of February all 5 former team members from Softvision are no longer participating in any of the maintained projects. Thanks to all of them for the great help over all the last months and years! But every project we own is now on my own shoulders. And this is kinda hell of work with downsides like not being able to do as many reviews as I want for side projects. One positive thing at least was that I got pulled back into the A-Team at the same time. With that move I’m once more closer again to all the people who care about the basics of all test infrastructure at Mozilla. I feel back home.
So what have I done the whole last quarter… First, it was always the ongoing daily work for maintaining our Mozmill CI system. This was usually a job for a dedicated person all the last months. The amount of work can sometimes eat up a whole day. Especially if several regressions have been found or incompatible changes in Firefox have been landed. Seeing my deliverables for Q1 it was clear that we have to cut down the time to spent on those failures. As result we started to partially skip tests which were failing. There was no time to get any of those fixed. Happily the latest version of Mozmill is still working kinda nicely so no other work had to be dedicated for this project.
Most of my time during the last quarter I actually had to spent on Marionette, especially building up wrapper scripts for being able to use Marionette as test framework for Firefox Desktop. This was a kinda large change for us but totally important in terms of maintenance burden and sustainability. The code base of Mozmill is kinda outdated and features like Electrolysis (e10s) will totally break it. Given that a rewrite of the test framework is too cost-intensive the decision has been made to transition our Mozmill tests over to Marionette. Side-effect was that a lot of missing features had to be implemented in Marionette to bring it at a level as what Mozmill offers. Thanks for the amazing work goes to Andrew Halberstadt, David Burns, Jonathan Griffin, and especially Chris Manchester.
For the new UI driven tests for Firefox Desktop we created the firefox-ui-tests repository at Github. We decided on that name to make it clear to which product the tests belong to, and also to get rid of any relationship to the underling test framework name. This repository contains the harness extensions around Marionette, a separate puppeteer library for back-end and UI modules, and last but not least the tests themselves. As goal for Q1 we had to get the basics working including the full set of remote security tests, and most important the update tests. A lot of help on the security tests we got from Barbara Miller our intern from December to March. She did great amount of work here, and also assisted other community members in getting their code done. Finally we got all the security tests converted.
My own focus beside the harness pieces were the update tests. Given the complete refactoring of those Mozmill tests we were able to easily port them over to Marionette. We tried to keep the class structure as is, and only did enhancements where necessary. Here Bob Silverberg helped with two big chunks of work which I’m gladly thankful about! Thanks a lot! With all modules in-place I finally converted the update tests and got them running for each version of Firefox down to 38.0, which will be the next ESR release and kinda important to be tested with Marionette. For stability and ease of contribution we added support for Travis CI to our new repository. It helps us a lot with reviews of patches from community members, and they also can see immediately if changes they have done are working as expected.
The next big chunk of work will be to get those tests running in Mozmill CI (to be renamed) and the test reporting to use Treeherder. Also we want to get our update tests for Firefox releases executed by the RelEng system, to further reduce the amount of time for signoffs from QE. About this work I will talk more in my next blog post. So please stay tuned.
If you are interested in further details and discussions you might also want to have a look at the meeting agendas, the video recordings, and notes from the Firefox Automation meetings. Please note that since end of February we no longer host a meeting due to the low attendance and other meetings like the A-team ones, where I have to report my status.
http://www.hskupin.info/2015/05/12/firefox-automation-report-q1-2015/
|
|
Gregory Szorc: Notes from Git Merge 2015 |
Git Merge 2015 was a Git user conference held in Paris on April 8 and 9, 2015.
I'm kind of a version control geek. I'm also responsible for a large part of Mozilla's version control hosting. So, when the videos were made public, you can bet I took interest.
This post contains my notes from a few of the Git Merge talks. I try to separate content/facts from my opinions by isolating my opinions (within parenthesis).
Git at Google: Making Big Projects (and everyone else) Happy is from a Googler (Dave Borowitz) who works on JGit for the Git infrastructure team at Google.
"Everybody in this room is going to feel some kind of pain working with Git at scale at some time in their career."
First Git usage at Google in 2008 for Android. 2011 googlesource.com launches.
24,000 total Git repos at Google. 77.1M requests/day. 30-40 TB/day. 2-3 Gbps.
Largest repo is 210GB (not public it appears).
800 repos in AOSP. Google maintains internal fork of all Android repos (so they can throw stuff over the wall). Fresh AOSP tree is 17 GiB. Lots of contracts dictating access.
Chrome repos include Chromium, Blink, Chromium OS. Performed giant Subversion migration. Developers of Chrome very set in their ways. Had many workflows integrated with Subversion web interface. Subversion blame was fast, Git blame slow. Built caching backend for Git blame to make developers happy.
Chromium 2.9 GiB, 3.6M objects, 390k commits. Blink 5.3 GiB, 3.1M objects, 177k commits. They merged them into a monorepo. Mention of Facebook's monorepo talk and Mercurial scaling efforts for a repo larger then Chromium/Blink monorepo. Benefits to developers for doing atomic refactorings, etc.
"Being big is hard."
AOSP: 1 Gbps -> 2 minutes for 17 GiB. 20 Mbps -> 3 hours. Flaky internet combined with non-resumable clone results in badness. Delta resolution can take a while. Checkout of hundreds of thousands of files can be slow, especially on Windows.
"As tool developers... it's hard to tell people don't check in large binaries, do things this way, ... when all they are trying to do is get their job done." (I couldn't agree more: tools should ideally not impose sub-optimal workflows.)
They prefer scaling pain to supporting multiple tools. (I think this meant don't use multiple VCSs if you can just make one scale.)
Shallow clone beneficial. But some commands don't work. log not very useful.
Narrow clones mentioned. Apparently talked about elsewhere at Git Merge not captured on video. Non-trivial problem for Git. "We have no idea when this is going to happen."
Split repos until narrow clone is available. Google wrote repo to manage multiple repos. They view repo and multiple repos as stop-gap until narrow clone is implemented.
git submodule needs some love. Git commands don't handle submodules or multiple repos very well. They'd like to see repo features incorporated into git submodule.
Transition to server operation.
Pre-2.0, counting objects was hard. For Linux kernel, 60s 100% CPU time per clone to count objects. "Linux isn't even that big."
Traditionally Git is single homed. Load from users. Load from automation.
Told anecdote about how Google's automation once recloned the repo after a failed Git command. Accidentally made a change one day that caused a command to persistently fail. DoS against server. (We've had this at Mozilla.)
Garbage collection on server is CPU intensive and necessary. Takes cores away from clients.
Reachability bitmaps implemented in JGit, ported to Git 2.0. Counting objects for Linux clones went from 60s CPU to ~100ms.
Google puts static, pre-generated bundles on a CDN. Client downloads bundle then does incremental fetch. Massive reduction in server load. Bundle files better for users. Resumable.
They have ideas for integrating bundles into git fetch, but it's "a little way's off." (This feature is partially implemented in Mercurial 3.4 and we have plans for using it at Mozilla.) It's feature in repo today.
Shared filesystem would be really nice to spread CPU load. NFS "works." Performance problems with high throughput repositories.
Master-mirror replication can help. Problems with replication lag. Consistency is hard.
Google uses a distributed Git store using Bigtable and GFS built on JGit. Git-aware load balancer. Completely separate pool of garbage collection workers. They do replication to multiple datacenters before pushes. 6 datacenters across world. Some of their stuff is open source. A lot isn't.
Humans have difficulty managing hundreds of repositories. "How do you as a human know what you need to modify?" Monorepos have this problem too. Inherent with lots of content. (Seemed to imply it is worse with multiple repos than with a monorepo.)
Porting changes between forks is hard. e.g. cherry picking between internal and external Android repos.
ACLs are a mess.
Google built Gerrit code review. It does ACLs, auto rebasing, release branch management. It's a swiss army knife. (This aligns with my vision for MozReview and code-centric development.)
Wilhelm Bierbaum from Twitter talks about Scaling Git at Twitter.
"We've decided it's really important to make Twitter a good place to work for developers. Source control is one of those points where we were lacking. We had some performance problems with Git in the past."
Twitter runs a monorepo. Used to be 3 repos. "Working with a single repository is the way they prefer to develop software when developing hundreds of services." They also have a single build system. They have a geo diverse workforce.
They use normal canonical implementation of Git + some optimizations.
Benefits of a monorepo:
Visibility. Easier for people to find code in one repo. Code search tools tailored towards single repos.
Single toolchain. single set of tools to build, test, and deploy. When improvements to tools made, everyone benefits because one toolchain.
Easy to share code (particularly generated code like IDL). When operating many small services, services developed together. Code duplication is minimized. Twitter relies on IDL heavily.
Simpler to predict the impact of your changes. Easier to look at single code base then to understand how multiple code bases interact. Easy to make a change and see what breaks rather than submit changes to N repos and do testing in N repos.
Makes refactoring less arduous.
Surfaces architecture issues earlier.
Breaking changes easier to coordinate
Drawbacks of monorepos:
Large disk footprint for full history.
Tuning filesystem only goes so far.
Forces some organizations to adopt sparse checkouts and shallow clones.
Submodules aren't good enough to use. add and commit don't recognize submodule boundaries very well and aren't very usable.
"To us, using a tool such as repo that is in effect a secondary version control tool on top of Git does not feel right and doesn't lead to a fluid experience."
Twitter has centralized use of Git. Don't really benefit from distributed version control system. Feature branches. Goal is to live as close to master as possible. Long-running branches discouraged. Fewer conflicts to resolve.
They have project-level ownership system. But any developer can change anything.
They have lots of read-only replicas. Highly available writable server.
They use reference repos heavily so object exchange overhead is manageable.
Scaling issues with many refs. Partially due to how refs are stored on disk. File locking limits in OS. Commands like status, add, and commit can be slow, even with repo garbage collected and packed. Locking issues with garbage collection.
Incorporated file alteration monitor to make status faster. Reference to Facebook's work on watchman and its Mercurial integration. Significant impact on OS X. "Pretty much all our developers use OS X." (I assume they are using Watchman with Git - I've seen patches for this on the Git mailing list but they haven't been merged into core yet.)
They implemented a custom index format. Adopted faster hashing algorithm that uses native instructions.
Discovery with many refs didn't scale. 13 MB of raw data for refs exchange at Twitter. (!!) Experimenting with clients sending a bloom filter of refs. Hacked it together via HTTP header.
Fetch protocol is expensive. Lots of random I/O. Can take minutes to do incremental fetches. Bitmap indices help, but aren't good enough for them. Since they have central and well-defined environment, they changed fetch protocol to work like a journal: send all changed data since client's last fetch. Server work is essentially a sendfile system call. git push appends push packs to a log-structured journal. On fetch, clients "replay" the transactions from the journal. Similar to MySQL binary log replication. (This is very similar to some of the Mercurial replication work I'm doing at Mozilla. Yay technical validation.) (Append only files are also how Mercurial's storage model works by default.)
Log-structured data exchange means server side is cheap. They can insert HTTP caches to handle Range header aware requests.
Without this hack, they can't scale their servers.
Initial clone is seeded by BitTorrent.
It sounds like everyone's unmerged feature branches are on the one central repo and get transferred everywhere by default. Their journal fetch can selectively fetch refs so this isn't a huge problem.
They'd like to experiment with sparse repos. But they haven't gotten to that yet. They'd like a better storage abstraction in Git to enable necessary future scalability. They want a network-aware storage backend. Local objects not necessary if the network has them.
They are running a custom Git distribution/fork on clients. But they don't want to maintain forever. Prefer to send upstream.
http://gregoryszorc.com/blog/2015/05/12/notes-from-git-merge-2015
|
|
The Mozilla Blog: Update on Digital Rights Management and Firefox |
A year ago, we announced the start of efforts to implement support for a component in Firefox that would allow content wrapped in Digital Rights Management (DRM) to be played within the HTML5 video tag. This was a hard decision because of our Mission and the closed nature of DRM. As we explained then, we are enabling DRM in order to provide our users with the features they require in a browser and allow them to continue accessing premium video content. We don’t believe DRM is a desirable market solution, but it’s currently the only way to watch a sought-after segment of content.
Today, Firefox includes an integration with the Adobe Content Decryption Module (CDM) to playback DRM-wrapped content. The CDM will be downloaded from Adobe shortly after you upgrade or install Firefox and will be activated when you first interact with a site that uses Adobe CDM. Premium video services, including Netflix, have started testing this solution in Firefox.
Because DRM is a ‘black-box’ technology that isn’t open source, we have designed a security sandbox that sits around the CDM. We can’t be sure how other browsers have handled the “black-box” issue but a sandbox provides a necessary layer of security. Additionally, we’ve also introduced the ability to remove the CDM from your copy of Firefox. We believe that these are important security and choice mechanisms that allow us to introduce this technology in a manner that lessens the negative impacts of integrating this type of black-box.

We also recognize that not everybody wants DRM, so we are also offering a separate Firefox download without the CDM enabled by default for those users who would rather not have the CDM downloaded to their browser on install.
As we’ve discussed, DRM is a complicated issue. We want our users to understand its implications and we have developed a teaching kit to introduce DRM, its challenges, and why some content publishers use it.
https://blog.mozilla.org/blog/2015/05/12/update-on-digital-rights-management-and-firefox/
|
|
David Humphrey: Learning to git bisect |
Yesterday one of my students hit a bug in Brackets. We're working on an extension for Thimble that adds an autocomplete option to take a selfie when you are typing a URL that might be an image (e.g., background-image: url(...). Except it doesn't work in the latter case. I advised him to file a bug in the Brackets repo, and the response was, "This used to work, must be a regression."
I told my student he should bisect and find the commit that caused the regression (i.e., code change that introduced the bug). This was a new idea for him, so I did it with him, and promised I'd write something later to walk through the process. Now that it's "later," I'm writing a short walkthrough on what I did.
As I write this, there are 16,064 commits in the adobe/brackets repo on github. That's a lot of coming and going, where a bug could easily hitch a ride and quietly find its way into the product. How does one hope to find what is likely a tiny needle in such a huge haystack? The answer is git bisect.
Having a large number of commits in which to locate a bad commit is only difficult if we try and manually deal with those commits. If I remembered that this code worked yesterday, I might quickly look through the diffs for everything that landed recently, and figure things out that way. But when we're talking about months, or maybe years since this last worked, that strategy won't be efficient.
Luckily git is designed to help us here. Because git knows about every commit, both what changed, and what change(s) came before, we can take a huge range of commits and slice and dice them in order to expose the first bad one.
In order for this process to work, you need a reproducible test case. In an ideal world, this is a unit test that's in your git history, and is stable across all the commits you'll be checking. In the real world you often have to write one yourself, or get a set of steps that quickly exposes the bug.
For the bug I was tracking, I had a simple way to test in the editor manually. When the code works, it should give us a list of filenames to use for the URL, and look like this:
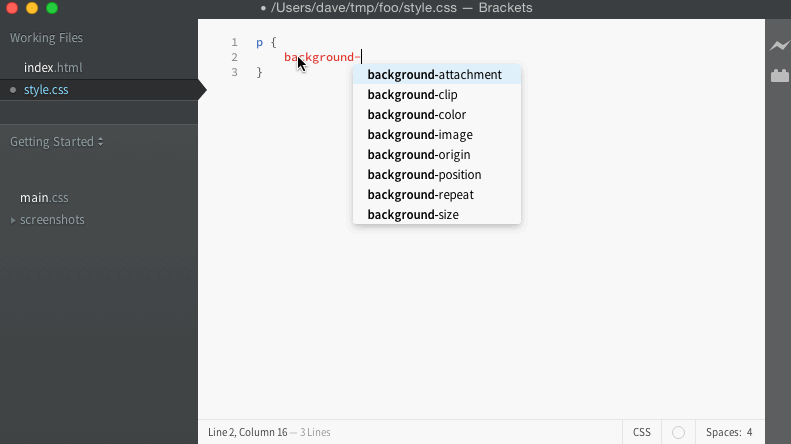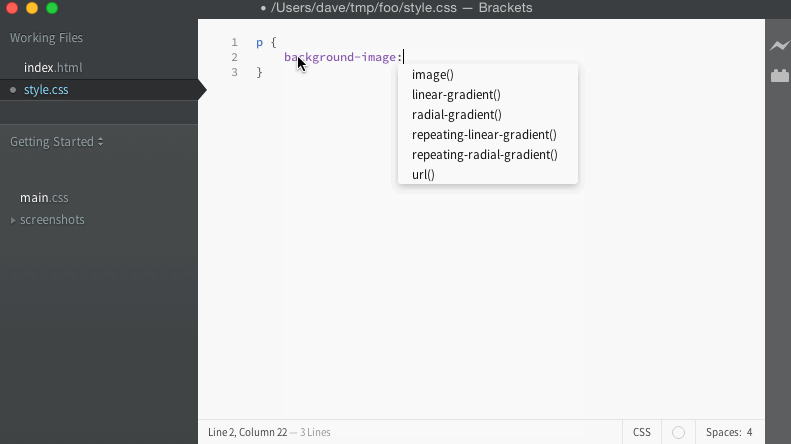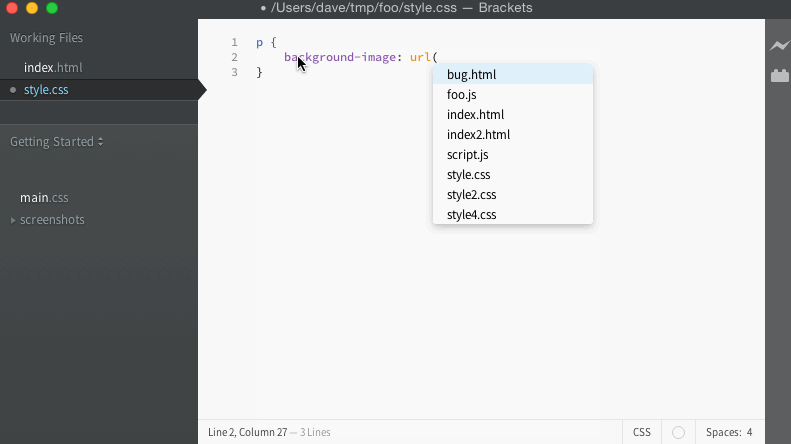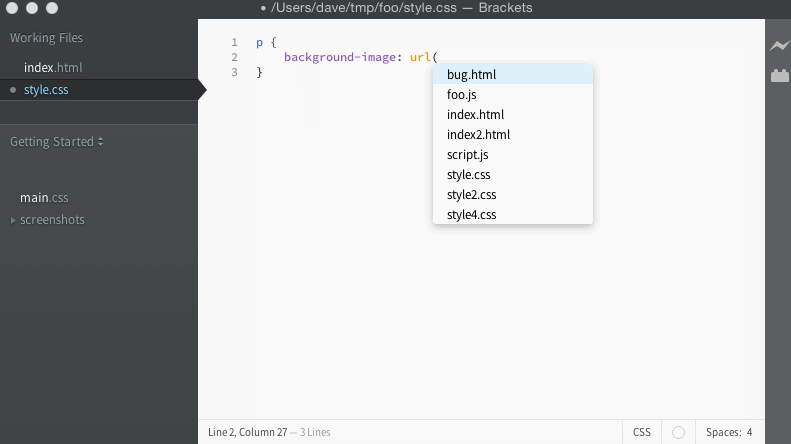
When it fails, it keeps giving the list of completions for background-image instead, and looks like this:
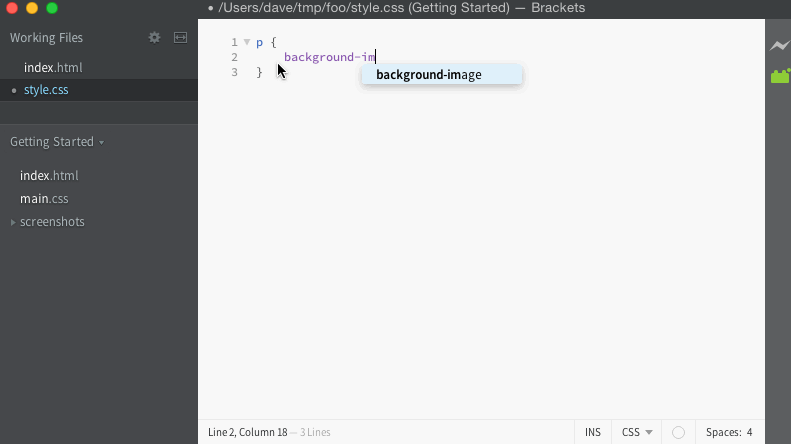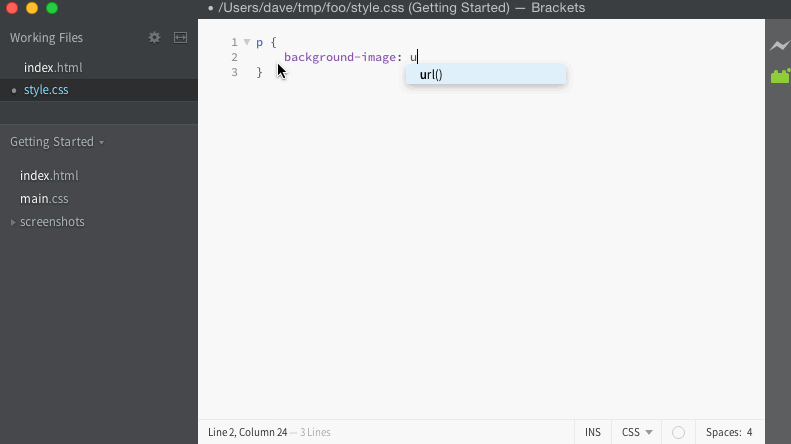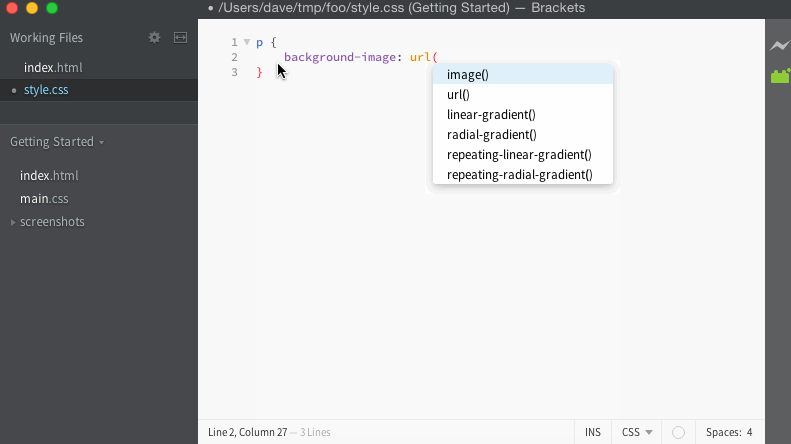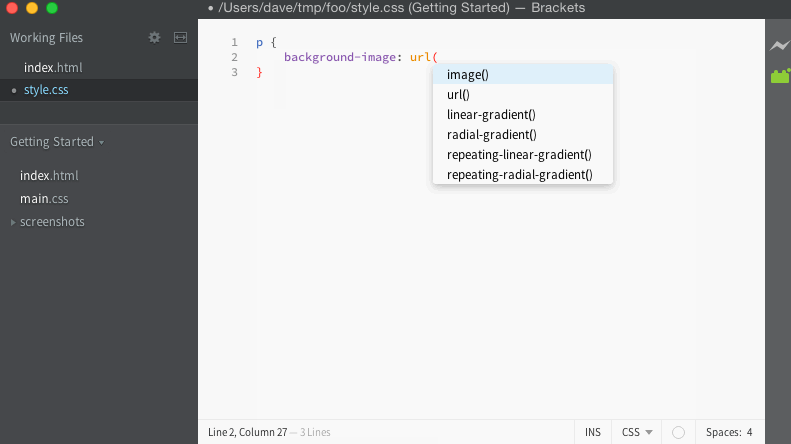
Now that I have a simple way to confirm whether or not the bug is present in a particular version of the code, I need to quickly eliminate commits and narrow down exactly where it came from.
You begin a bisect session with git by doing: git bisect start. In order to have git bisect for me, I need to create a range, and to do this I need two end points (i.e., two commits): one where the bug is not present (good commit); and one where I know it's broken (bad commit). Finding a bad commit is usually pretty easy, since you already know you have the bug--in my case I can use master. I tell git this is the bad commit by doing git bisect bad (note: I was sitting on the master branch when I typed this. You can also explicitly give a commit or branch/tag).
But for the last-known-good commit, I obviously don't know exactly where it happened. As a result, I'm going to need to overshoot and go back far enough to get to something that works.
Brackets is currently preparing for version 1.4 on master, and there are 80 previous released (i.e., tagged) versions. These tagged versions are useful for quickly jumping back in time, since they represent versions of the editor that are most likely to run (i.e,. they didn't tag and release broken commits). So I start checking out old releases: 1.1 (broken), 1.0 (broken), release 0.44 (broken). It looks like this is an old problem, so I jump further back so as to not waste my time testing too many.
Eventually I checkout version 0.32 from Oct 4, 2013, and the bug isn't there. Now I can tell git about the other end of my bisect range by doing: git bisect good.
Now git can do its magic. It will take my good and bad commits, and checkout a commit half way between them. It looks like this:
Bisecting: 3123 revisions left to test after this (roughly 12 steps)
[940fb105ecde14c7b5aab5191ec14e766e136648] Make the window the holder
A couple of things to notice. First, git has checked out commit 940fb105ecde14c7b5aab5191ec14e766e136648 automatically. It has let me know that there are 12 steps left before it can narrow down the problematic commit. That's not too bad, given that I'm trying to find one bad commit in thousands from the past two years!
At this point I need to run the editor for commit 940fb105ecde14c7b5aab5191ec14e766e136648 and test to see if it has the bug. If it does, I type git bisect bad. If it doesn't, I type git bisect good. In this case the bug is there, and I enter git bisect bad. Git responds:
Bisecting: 1558 revisions left to test after this (roughly 11 steps)
[829d231440e7fa0399f8e12ef031ee3fbd268c79] Merge branch 'master' into PreferencesModel
A new commit has been checked out, eliminating half of the previous commits in the range (was 3132, now it's 1558), and there are 11 steps to go. This process continues, sometimes the bug is there, sometimes it isn't. After about 5 minutes I get to the first bad commit, and git shows me this:
6d638b2049d6e88cacbc7e0c4b2ba8fa3ca3c6f9 is the first bad commit
commit 6d638b2049d6e88cacbc7e0c4b2ba8fa3ca3c6f9
Author:
Date: Mon Apr 7 15:23:47 2014 -0700
fix css value hints
:040000 040000 547987939b1271697d186c73533e044209169f3b 499abf3233f1316f75a83bf00acbb2955b777262 M src
Now I know which commit caused the bug to start happening. Neither git nor I know why this commit did what it did, but it doesn't matter. We also know what changed, which bug was being fixed, who did it, and when they did it. Armed with this info we can go talk to people on irc, and add notes to a few bugs: the bug where the bad commit was added (this will alter people who know about the code, and could more easily fix it), and our bug where we've filed the issue. Often you don't need to solve the bug, just find it, and let the person who knows the code well help with a fix.
The last step is to tell git that we're done bisecting: git bisect reset. This takes us back to the commit we were on before we started our bisect.
Despite being quite skilled with git, I don't think that any of my students had used bisect before. Lots of people haven't. It's worth knowing how to do it for times like this when you need to quickly narrow down a regression.
|
|
Gervase Markham: You Couldn’t Make It Up |
I was in the middle of debugging some code when a background Slashdot tab from 10 minutes ago suddenly started playing a sponsored video. Truly and genuinely, the opening of this video contained the following:
Did you know that it takes you 15 minutes to get back into the work zone after being interrupted by an alert or message?
Yes. Yes, Slashdot, I did…
http://feedproxy.google.com/~r/HackingForChrist/~3/6SuKxccDnxU/
|
|
Byron Jones: happy bmo push day! |
the following changes have been pushed to bugzilla.mozilla.org:
discuss these changes on mozilla.tools.bmo.
https://globau.wordpress.com/2015/05/12/happy-bmo-push-day-140/
|
|
Joel Maher: Re-Triggering for a [root] cause – some notes from doing it |
With all this talk of intermittent failures and folks coming up with ideas on how to solve them, I figured I should dive head first into looking at failures. I have been working with a few folks on this, specifically :parkouss and :vaibhav1994. This experiment (actually the second time doing so) is where I take a given intermittent failure bug and retrigger it. If it reproduces, then I go back in history looking for where it becomes intermittent. This weekend I wrote up some notes as I was trying to define what an intermittent is.
Lets outline the parameters first for this experiment:
Here are what comes out of this:
The next step was to look at each of the 25 bugs and see if it makes sense to do this. In fact 13 of the bugs I decided not to take action on (remember this is an experiment, so my reasoning for ignoring these 13 could be biased):
This leaves us with 12 bugs to investigate. The premise here is easy, find the first occurrence of the intermittent (branch, platform, testjob, revision) and re-trigger it 20 times (picked for simplicity). When the results are in, see if we have reproduced it. In fact, only 5 bugs reproduced the exact error in the bug when re-triggered 20 times on a specific job that showed the error.
Moving on, I started re-triggering jobs back in the pushlog to see where it was introduced. I started off with going back 2/4/6 revisions, but got more aggressive as I didn’t see patterns. Here is a summary of what the 5 bugs turned out like:
In summary, out of 356 bugs 2 root causes were found by re-triggering. In terms of time invested into this, I have put about 6 hours of time to fine the root cause of the 5 bugs.

|
|
Karl Dubost: Benefits on fixing a Web site with regards to Web Compatibility |
Someone asked me recently
Is there any benefit for site owners to fix their web sites?
Context: Someone reports a bug about a Web site, we analyze, diagnose, provide a fix (or an idea) on how to fix it, find a contact, and then try to get it fixed.
Yesterday, I posted an article on how to find contact. My first recommendation is:
- Be tactful: People we are trying to reach have their own set of constraints, bosses, economic choices, etc. "Your web site sucks" will not lead anywhere, except NOT getting the site fixed.
When contacting people, we come with a request which has a cost for the person and/or structure which will need to fix it. Never ever forget this.
When the person is asking you why they should fix it, here are a couple of reasons:
When a user is being denied access because of the browser they used, it will very often lead to a loss, specifically if this person can use another site for the same type of service. Asking the user to change browsers may lead to annoyance to total sense of frustration. Some platforms, companies do not authorize another browser.
If the Web site is not properly working on the browser that a person has chosen, it leads to two main feelings: The browser is broken or the site is broken. In the latter case, the user will lower the trust for the company's brand. This is even worse when the company has a kind of monopoly, because the user is both frustrated and forced. Never a good feeling.
There are some cases fixing the Web site will make it compatible with the current deployed technology across the Web platform. Old WebKit flexbox syntax is the poster child of this. The new syntax is supported across all platforms.
Fix now when you have time to do so. Updating to a new syntax (even if keeping around the old syntax) when there is time is a lot better than having to change the full site in hurry because one browser is deprecating the old syntax. Basically you will save money and time by planning your efforts.
Basically, when we are contacting someone, we not only describe the issue but most of the time, we provide a way to fix it. So basically we help the company to get the code in good shape. We minimize their cost for something they might have to do in the future.
Do not preach about doing the right thing to someone who is asking about the benefits. It will be a lost battle.
A company is not a perfect entity, a person might say no, when someone just the desk beside think that your contact outreach effort makes sense. If there is too much resistance on one side, try with someone else. Still be mindful. Do not harass all people of the company.
Sometimes, all of this, will not be good enough. There is so much we can do in one day and it's better to focus your energy with people of good will. Just conclude that you can help in the future if they decide to move forward.
You will do mistakes when contacting people. It's ok. Everyone does.
Otsukare!
|
|
Christopher Arnold: Mesh Networking for app delivery in Apple OSX and Windows GWX |


http://ncubeeight.blogspot.com/2015/05/mesh-networking-for-app-delivery-in.html
|
|
Matjaz Horvat: Throwing Pontoon backend around |
Osmose pinged me the other day on IRC, pasting a link to his Pontoon branch and asking me to check out the stuff he’s been throwing around. I quickly realized he made substantial improvements to the backend, including things I’ve been resisting for too long, so I wanted to ship them as early as possible.
We worked together during the last week to make that happen and here it is – a preview of Pontoon with the new backend. Please give it a try and let us know if you run into any bugs. As soon as we’re all happy with it, we’ll deploy the changes to production.
The new codebase is way more robust and maintainable, simpler to setup for developers, easier to deploy and what matters most – it works considerably faster for localizers. The following are the most important changes that were made. The complete changelog is available on GitHub.
We also moved Pontoon repository under Mozilla organization on GitHub.
And now I’d like to take the opportunity to thank Michael for the heroic effort he has made by throwing stuff around!
|
|
Mike Conley: The Joy of Coding (Ep. 13): Printing. Again! |
Had to deal with some network issues during this video – sorry if people were getting dropped frames during the live show! I have personally checked this recording, and almost all frames are there.
The only frames that are missing are the ones where I scramble around to connect to the wired network, which was boring anyhow.
In this episode, I worked on proxying the print dialog from the content process on OS X. It was a wild ride, and I learned quite a bit about Cocoa stuff. It was also a throwback to my very first episode, where I essentially did the same thing for Linux!
We’ll probably polish this off in the next episode, or in the episode after.
Bug 1091112 – Print dialog doesn’t get focus automatically, if e10s is enabled – Notes
http://mikeconley.ca/blog/2015/05/11/the-joy-of-coding-ep-13-printing-again/
|
|
Air Mozilla: Mozilla Weekly Project Meeting |
 The Monday Project Meeting
The Monday Project Meeting
https://air.mozilla.org/mozilla-weekly-project-meeting-20150511/
|
|
Mozilla WebDev Community: Extravaganza – May 2015 |
Once a month, web developers from across Mozilla get together to write fake Amazon reviews for cash on the side. While we sing the praises of shoddy products from questionable dealers, we find time to talk about the work that we’ve shipped, share the libraries we’re working on, meet new folks, and talk about whatever else is on our minds. It’s the Webdev Extravaganza! The meeting is open to the public; you should stop by!
You can check out the wiki page that we use to organize the meeting, or view a recording of the meeting in Air Mozilla. Or just read on for a summary!
The shipping celebration is for anything we finished and deployed in the past month, whether it be a brand new site, an upgrade to an existing one, or even a release of a library.
ErikRose himself was up first, and shared the news that the upcoming version of DXR, which switches the site to using Elasticsearch to power its code-searching abilities, has been successfully deployed on its staging environment. A year in the making, the new version brings faster searches, parallel indexing, and support for multiple programming languages, such as Python.
jgmize shared the news that Bedrock, the codebase for the main mozilla.org website, has been successfully divorced from Playdoh, including removing funfactory as a dependency and removing the reliance on git submodules for managing dependencies. Bedrock now uses peep to install dependencies on production.
Here we talk about libraries we’re maintaining and what, if anything, we need help with for them.
Osmose (that’s me!) announced the 1.0 release of django-browserid, which mainly adds Django 1.8 support while removing support for older, unsupported versions of Django. Also, as the software is now 1.0, any backwards-incompatible changes will bump the version number as per the rules of Semantic Versioning.
Next up was ErikRose and his announcement of the release of pyelasticsearch 1.2.3, an API for interacting with elasticsearch. The release fixes a bug that caused doctype names to sometimes be treated as index names when _all was used.
ErikRose also informed us about several peep releases. peep, which is a wrapper around pip that cryptographically verifies packages installed from a requirements file, is now compatible with pip 6.1.x, supports pip command-line flags in requirements files, and passes flake8.
The last bit of news ErikRose had to share was about django-tidings, a library for sending emails to users in response to events on your site. The project is now part of the Mozilla Github organization, and jezdez has been added as a maintainer.
The Roundtable is the home for discussions that don’t fit anywhere else.
canuckistani stopped by to mention some of the exciting DevTools features coming to Firefox Developer Edition, including a new performance tool, breakpoints in unnamed eval scripts, recording networks requests before the Network Tab is opened, and more! Check out the etherpad for tracking new features as well as for finding links to what bugs could use some help!
If you are a fine purveyor of shoddy products and want to energize your marketing efforts with a grassroots campaign conveyed via customer reviews, give us a call! Our rates are very unreasonable!
If you’re interested in web development at Mozilla, or want to attend next month’s Extravaganza, subscribe to the dev-webdev@lists.mozilla.org mailing list to be notified of the next meeting, and maybe send a message introducing yourself. We’d love to meet you!
See you next month!
https://blog.mozilla.org/webdev/2015/05/11/extravaganza-may-2015/
|
|
Mozilla Science Lab: Mozilla Science Lab Week in Review, May 4 – May 10 |
The Week in Review is our weekly roundup of what’s new in open science from the past week. If you have news or announcements you’d like passed on to the community, be sure to share on Twitter with @mozillascience and @billdoesphysics, or join our mailing list and get in touch there.
http://mozillascience.org/mozilla-science-lab-week-in-review-may-4-may-10/
|
|
Benjamin Smedberg: Hiring at Mozilla: Beyond Resum'es and Interview Panels |
The standard tech hiring process is not good at selecting the best candidates, and introduces unconscious bias into the hiring process. The traditional resume screen, phone screen, and interview process is almost a dice-roll for a hiring manager. This year, my team has several open positions and we’re trying something different, both in the pre-interview screening process and in the interview process itself.
Hiring Firefox Platform Engineers now!
Earlier this year I attended a workshop for Mozilla managers by the Clayman Institute at Stanford. One of the key lessons is that when we (humans) don’t have clear criteria for making a choice, we tend alter our criteria to match subconscious preferences (see this article for some examples and more information). Another key lesson is that when humans lack information about a situation, our brain uses its subconscious associations to fill in the gaps.
I believe job descriptions are very important: not only do they help candidates decide whether they want a particular job, but they also serve as a guide to the kinds of things that will be required or important during the interview process. Please read the job description carefully before applying to any job!
In order to hire more fairly, I have changed the way I write job descriptions. Previously I mixed up job responsibilities and applicant requirements in one big bulleted list. Certainly every engineer on my team is going to eventually use C++ and JavaScript, and probably Python, and in the future Rust. But it isn’t a requirement that you know all of these coming into a job, especially as a junior engineer. It’s part of the job to work on a high-profile open-source project in a public setting. But that doesn’t mean you must have prior open-source experience. By separating out the job expectations and the applicant requirements, I was able to create a much clearer set of screening rules for incoming applications, and also clearer expectations for candidates.
Resum'es are a poor tool for ranking candidates and deciding which candidates are worth the investment in a phone screen or interview. Resum'es give facts about education or prior experience, but rarely make it clear whether somebody is an excellent engineer. To combat this, my team won’t be using only resum'es as a screening tool. If a candidate matches basic criteria, such as living in a reasonable time zone and having demonstrated expertise in C++, JavaScript, or Python on their resum'e or code samples, we will ask each candidate to submit a short written essay (like a blog post) describing their favorite debugging or profiling tool.
Why did I pick an essay about a debugging or profiling tool? In my experience, every good coder has a toolbox, and as coders gain experience they are naturally better toolsmiths. I hope that this essay requirement will be good way to screen for programmer competence and to gauge expertise.
With resum'es, essays, and code samples in hand, Vladan and I will go through the applications and filter the applications. Each passing candidate will proceed to phone screens, to check for technical skill but more importantly to sell the candidate on the team and match them up with the best position. My goal is to exclude applications that don’t meet the requirements, not to rank candidates against each other. If there are too many qualified applicants, we will select a random sample for interviews. In order to make this possible, we will be evaluating applications in weekly batches.
To the extent possible, the interview format should line up with the job requirements. The typical Mozilla technical interview is five or six 45-minute 1:1 interview sessions. This format heavily favors people who can think quickly on their feet and who are personable. Since neither of those attributes is a requirement for this job, that format is a poor match. Here are the requirements in the job description that we need to evaluate during the interview:
This is the interview format that we came up with to assess the requirements:
During the debrief and decision process, I intend to focus as much as possible on the job requirements. Rather than asking a simple “should we hire this person” question, I will ask interviewers to rate the candidate on each job requirement and responsibility, as well as any desired skillset. By orienting the feedback to the job description I hope that we can reduce the effects of unconscious bias and improve the overall hiring process.
This hiring procedure is experimental. My team and I have concerns about whether candidates will be put off by the essay requirement or an unusual interview format, and whether plagiarism will make the essay an ineffective screening tool. We’re concerned about keeping the hiring process moving and not introducing too much delay. After the first interview rounds, I plan on evaluating the process, and ask candidates to provide feedback about their experience.
If you’re interested, check out my prior post, How I Hire At Mozilla.
http://benjamin.smedbergs.us/blog/2015-05-11/hiring-at-mozilla-beyond-resumes-and-interview-panels/
|
|
About:Community: MDN Contributor of the Month for April 2015: Julien (Sphinx) |
As part of the recently launched recognition program for Mozilla Developer Network, I’m pleased to announce that our first Contributor of the Month, for April 2015, is Julien (a.k.a. Sphinx).

Julien (in the Batman t-shirt) with other Mozilla Francophone contributors at a localization sprint
The following is a lightly-edited interview with Julien, conducted via email.
When and how did you get started contributing to MDN?
When? During Spring in 2013 when I was studying in Edinburgh, where I had some time for my personal projects.
How? I had already done a translation project with a French association called Framasoft (which closely related to Mozilla in terms of community here in France) and from one pad to another I ended up translating a small piece of article for mozilla-fr (mostly thanks to Goofy who was part of both projects). One thing leading to another, I discovered IRC, the nebula of Mozilla projects, and then MDN. After some edits, I discovered that the article about the HTML tag was not available in French, so I localized it and that was it
![]()
How does what you do on MDN affect other parts of your life, or vice versa?
I’m not a developer but I have some background in IT and my job is about organizing projects with software, so I’d say it feels like two complementary part of what I want to learn and discover. With MDN, I can learn new things (like up-to-date JavaScript while localizing articles), see how an open project works, contribute to what I want, when I want. While at work, I can picture how this sometimes differs in companies where culture and methodologies are more classical. Both are really complementary in terms of skills, experience and knowledge.
Regarding the time I spend, I tend to contribute during evenings, almost every day (instead of watching TV ![]() ) Of course, it doesn’t have to be every day! One should just find the rythm he/she is comfortable with and go with this.
) Of course, it doesn’t have to be every day! One should just find the rythm he/she is comfortable with and go with this.
And technically, MDN is affecting me with travels recently ![]() From Paris, to Berlin [for the Hack-on-MDN weekend] and Vancouver [for the Whistler work week], this is very exciting to meet people around MDN, whether they are employees or contributors and I’m very lucky to have these opportunities.
From Paris, to Berlin [for the Hack-on-MDN weekend] and Vancouver [for the Whistler work week], this is very exciting to meet people around MDN, whether they are employees or contributors and I’m very lucky to have these opportunities.
What advice do you have for new contributors on MDN?
Do hang out on IRC and ask questions [in the #mdn channel]. Do send an e-mail on the dev-mdc mailing list saying who you are and where you’d like to contribute. There are many people waiting to help you. If you prefer Twitter, go for it.
Contributing to MDN (and to Mozilla in general) can be a bit confusing at the beginning since there is a lot of stuff going on: don’t worry about that!
The MDN team is very helpful and looking forward to helping you ![]() See you soon on #mdn
See you soon on #mdn
If you don’t know where to start, you can contribute to the Learning Area or localize the glossary in your language or simply go to the Getting Started guide.
|
|






