Adam Lofting: The week ahead: 26 Jan 2015 |

I should have started the week by writing this, but I’ll do it quickly now anyway.
My current todo list.
List status: Pretty good. Mostly organized near the top. Less so further down. Fine for now.
Objectives to call out for this week.
+ some things that carry over from last week
http://feedproxy.google.com/~r/adamlofting/blog/~3/5f4U-RQTy4s/
|
|
Mozilla Fundraising: Should we put payment provider options directly on the snippet? |
https://fundraising.mozilla.org/should-we-put-payment-provider-options-directly-on-the-snippet/
|
|
Nick Desaulniers: Writing my first technical book chapter |
It’s a feeling of immense satisfaction when we complete a major achievement. Being able to say “it’s done” is such a great stress relief. Recently, I completed work on my first publication, a chapter about Emscripten for the upcoming book WebGL Insights to be published by CRC Press in time for SIGGRAPH 2015.
One of the life goals I’ve had for a while is writing a book. A romantic idea it seems to have your ideas transcribed to a medium that will outlast your bones. It’s enamoring to hold books from long dead authors, and see that their ideas are still valid and powerful. Being able to write a book, in my eyes, provides some form of life after death. Though, one could imagine ancestors reading blog posts from long dead relatives via utilities like the Internet Archive’s WayBack Machine.
Writing about highly technical content places an upper limit on the usefulness of the content, and shows as “dated” quickly. A book I recently ordered was Scott Meyers’ Effective Modern C++. This title strikes me, because what exactly do we consider modern or contemporary? Those adjectives only make sense in a time limited context. When C++ undergoes another revolution, Scott’s book may become irrelevant, at which point the adjective modern becomes incorrect. Not that I think Scott’s book or my own is time-limited in usefulness; more that technical books’ duration of usefulness is significantly less than philosophical works like 1984 or Brave New World. Almost like having a record in a sport is a feather in one’s cap, until the next best thing comes along and you’re forgotten to time.
Somewhat short of my goal of writing an entire book, I only wrote a single chapter for a book. It’s interesting to see that a lot of graphics programming books seem to follow the format of one author per chapter or at least multiple authors. Such book series as GPU Gems, Shader X, and GPU Pro follow this pattern, which is interesting. After seeing how much work goes into one chapter, I think I’m content with not writing an entire book, though I may revisit that decision later in life.
How did this all get started? I had followed Graham Sellers on Twitter and saw a tweet from him about a call to authors for WebGL Insights. Explicitly in the linked to page under the call for authors was interest in proposals about Emscripten and asm.js.
Want to contribute to a book? @pjcozzi is calling for authors for the new #WebGL Insights. Go here: http://t.co/n7wrXVb4Vl.
— Graham Sellers (@grahamsellers) August 28, 2014
At the time, I was headlong into a project helping Disney port Where’s My Water from C++ to JavaScript using Emscripten. I was intimately familiar with Emscripten, having been trained by one of its most prolific contributors, Jukka Jyl"anki. Also, Emscripten’s creator, Alon Zakai, sat on the other side of the office from me, so I was constantly pestering him about how to do different things with Emscripten. The #emscripten irc channel on irc.mozilla.org is very active, but there’s no substitute for being able to have a second pair of eyes look over your shoulder when something is going wrong.
Knowing Emscripten’s strengths and limitations, seeing interest in the subject I knew a bit about (but wouldn’t consider myself an expert in), and having the goal of writing something to be published in book form, this was my opportunity to seize.
I wrote up a quick proposal with a few figures about why Emscripten was important and how it worked, and sent it off with fingers crossed. Initially, I was overjoyed to learn when my proposal was accepted, but then there was a slow realization that I had a lot of work to do. The editor, Patrick Cozzi, set up a GitHub repo for our additional code and figures, a mailing list, and sent us a chapter template document detailing the process. We had 6 weeks to write the rough draft, then 6 weeks to work with reviewers to get the chapter done. The chapter was written as a Google Doc, so that we could have explicit control over who we shared the document with, and what kinds of editing power they had over the document. I think this approach worked well.
I had most of the content written by week 2. This was surprising to me, because I’m a heavy procrastinator. The only issue was that the number of pages I wrote was double the allowed amount; way over page count. I was worried about the amount of content, but told myself to try not to be attached to the content, just as you shouldn’t stay attached with your code.
I took the additional 4 weeks I had left to finish the rough draft to invite some of my friends and coworkers to provide feedback. It’s useful to have a short list of people who have ever offered to help in this regard or owe you one. You’ll also want a diverse team of reviewers that are either close to the subject matter, or approaching it as new information. This allows you to stay technically correct, while not presuming your readers know everything that you do.
The strategy worked out well; some of the content I had initially written about how JavaScript VMs and JITs speculate types was straight up wrong. While it played nicely into the narrative I was weaving, someone more well versed in JavaScript virtual machines would be able to call BS on my work. The reviewers who weren’t as close to subject matter were able to point out when logical progressions did not follow.
Fear of being publicly corrected prevents a lot of people from blogging or contributing to open source. It’s important to not stay attached to your work, especially when you need to make cuts. When push came to shove, I did have difficulty removing sections.
Lets say you have three sequential sections: A, B, & C. If section A and section B both set up section C, and someone tells you section B has to go, it can be difficult to cut section B because as the author you may think it’s really important to include B for the lead into C. My recommendation is sum up the most important idea from section B and add it to the end of section A.
For the last six weeks, the editor, some invited third parties, and other authors reviewed my chapter. It was great that others even followed along and pointed out when I was making assumptions based on specific compiler or browser. Eric Haines even reviewed my chapter! That was definitely a highlight for me.
We used a Google Sheet to keep track of the state of reviews. Reviewers were able to comment on sections of the chapter. What was nice was that you were able to keep use the comment as a thread, being able to respond directly to a criticism. What didn’t work so well was then once you edited that line, the comment and thus the thread was lost.
Once everything was done, we zipped up the assets to be used as figures, submitted bios, and wrote a tips and tricks section. Now, it’s just a long waiting game until the book is published.
As far as dealing with the publisher, I didn’t have much interaction. Since the book was assembled by a dedicated editor, Patrick did most of the leg work. I only asked that what royalties I would receive be donated to Mozilla, which the publisher said would be too small (est $250) to be worth the paperwork. It would be against my advice if you were thinking of writing a technical book for the sole reason of monetary benefit. I’m excited to be receiving a hard cover copy of the book when it’s published. I’ll also have to see if I can find my way to SIGGRAPH this year; I’d love to meet my fellow authors in person and potential readers. Just seeing the list of authors was really a who’s-who of folks doing cool WebGL stuff.
If you’re interested in learning more about working with Emscripten, asm.js, and WebGL, I sugguest you pick up a copy of WebGL Insights in August when it’s published. A big thank you to my reviewers: Eric Haines, Havi Hoffman, Jukka Jyl"anki, Chris Mills, Traian Stanev, Luke Wagner, and Alon Zakai.
So that was a little bit about my first experience with authorship. I’d be happy to follow up with any further questions you might have for me. Let me know in the comments below, on Twitter, HN, or wherever and I’ll probably find it!
http://nickdesaulniers.github.io/blog/2015/01/25/writing-my-first-book-chapter/
|
|
Gregory Szorc: Automatic Python Static Analysis on MozReview |
A bunch of us were in Toronto last week hacking on MozReview.
One of the cool things we did was deploy a bot for performing Python static analysis. If you submit some .py files to MozReview, the bot should leave a review. If it finds violations (it uses flake8 internally), it will open an issue for each violation. It also leaves a comment that should hopefully give enough detail on how to fix the problem.
While we haven't done much in the way of performance optimizations, the bot typically submits results less than 10 seconds after the review is posted! So, a human should never be reviewing Python that the bot hasn't seen. This means you can stop thinking about style nits and start thinking about what the code does.
This bot should be considered an alpha feature. The code for the bot isn't even checked in yet. We're running the bot against production to get a feel for how it behaves. If things don't go well, we'll turn it off until the problems are fixed.
We'd like to eventually deploy C++, JavaScript, etc bots. Python won out because it was the easiest to integrate (it has sane and efficient tooling that is compatible with Mozilla's code bases - most existing JavaScript tools won't work with Gecko-flavored JavaScript, sadly).
I'd also like to eventually make it easier to locally run the same static analysis we run in MozReview. Addressing problems locally before pushing is a no-brainer since it avoids needless context switching from other people and is thus better for productivity. This will come in time.
Report issues in #mozreview or in the Developer Services :: MozReview Bugzilla component.
http://gregoryszorc.com/blog/2015/01/24/automatic-python-static-analysis-on-mozreview
|
|
Gregory Szorc: End to End Testing with Docker |
I've written an extensive testing framework for Mozilla's version control tools. Despite it being a little rough around the edges, I'm a bit proud of it.
When you run tests for MozReview, Mozilla's heavily modified Review Board code review tool, the following things happen:
In the future, we'll likely also need to add support for various other services to support MozReview and other components of version control tools:
The entire setup is pretty cool. You have actual services running on your local machine. Mike Conley and Steven MacLeod even did some pair coding of MozReview while on a plane last week. I think it's pretty cool this is even possible.
There is very little mocking in the tests. If we need an external service, we try to spin up an instance inside a local container. This way, we can't have unexpected test successes or failures due to bugs in mocking. We have very high confidence that if something works against local containers, it will work in production.
I currently have each test file owning its own set of Docker containers and processes. This way, we get full test isolation and can run tests concurrently without race conditions. This drastically reduces overall test execution time and makes individual tests easier to reason about.
As cool as the test setup is, there's a bunch I wish were better.
Spinning up and shutting down all those containers and processes takes a lot of time. We're currently sitting around 8s startup time and 2s shutdown time. 10s overhead per test is unacceptable. When I make a one line change, I want the tests to be instantenous. 10s is too long for me to sit idly by. Unfortunately, I've already gone to great pains to make test overhead as short as possible. Fig wasn't good enough for me for various reasons. I've reimplemented my own orchestration directly on top of the docker-py package to achieve some significant performance wins. Using concurrent.futures to perform operations against multiple containers concurrently was a big win. Bootstrapping containers (running their first-run entrypoint scripts and committing the result to be used later by tests) was a bigger win (first run of Bugzilla is 20-25 seconds).
I'm at the point of optimizing startup where the longest pole is the initialization of the services inside Docker containers themselves. MySQL takes a few seconds to start accepting connections. Apache + Bugzilla has a semi-involved initialization process. RabbitMQ takes about 4 seconds to initialize. There are some cascading dependencies in there, so the majority of startup time is waiting for processes to finish their startup routine.
Another concern with running all these containers is memory usage. When you start running 6+ instances of MySQL + Apache, RabbitMQ, + ..., it becomes really easy to exhaust system memory, incur swapping, and have performance fall off a cliff. I've spent a non-trivial amount of time figuring out the minimal amount of memory I can make services consume while still not sacrificing too much performance.
It is quite an experience having the problem of trying to minimize resource usage and startup time for various applications. Searching the internet will happily give you recommended settings for applications. You can find out how to make a service start in 10s instead of 60s or consume 100 MB of RSS instead of 1 GB. But what the internet won't tell you is how to make the service start in 2s instead of 3s or consume as little memory as possible. I reckon I'm past the point of diminishing returns where most people don't care about any further performance wins. But, because of how I'm using containers for end-to-end testing and I have a surplus of short-lived containers, it is clearly I problem I need to solve.
I might be able to squeeze out a few more seconds of reduction by further optimizing startup and shutdown. But, I doubt I'll reduce things below 5s. If you ask me, that's still not good enough. I want no more than 2s overhead per test. And I don't think I'm going to get that unless I start utilizing containers across multiple tests. And I really don't want to do that because it sacrifices test purity. Engineering is full of trade-offs.
Another takeaway from implementing this test harness is that the pre-built Docker images available from the Docker Registry almost always become useless. I eventually make a customization that can't be shoehorned into the readily-available image and I find myself having to reinvent the wheel. I'm not a fan of the download and run a binary model, especially given Docker's less-than-stellar history on the security and cryptography fronts (I'll trust Linux distributions to get package distribution right, but I'm not going to be trusting the Docker Registry quite yet), so it's not a huge loss. I'm at the point where I've lost faith in Docker Registry images and my default position is to implement my own builder. Containers are supposed to do one thing, so it usually isn't that difficult to roll my own images.
There's a lot to love about Docker and containerized test execution. But I feel like I'm foraging into new territory and solving problems like startup time minimization that I shouldn't really have to be solving. I think I can justify it given the increased accuracy from the tests and the increased confidence that brings. I just wish the cost weren't so high. Hopefully as others start leaning on containers and Docker more for test execution, people start figuring out how to make some of these problems disappear.
http://gregoryszorc.com/blog/2015/01/24/end-to-end-testing-with-docker
|
|
Karl Dubost: Working With Transparency Habits. Something To Learn. |
I posted this following text as a comment 3 days ago on Mark Surman's blog on Transparency habits, but it is still in the moderation queue. So instead of taking the chance to lose it. I'm reposting that comment here. This might need to be develop by a followup post.
Mark says:
I encourage everyone at Mozilla to ask themselves: how can we all build up our transparency habits in 2015? If you already have good habits, how can you help others? If, like me, you’re a bit rusty, what small things can you do to make your work more open?
The mistake we often do with transparency is that we think it is obvious for most people. But working in a transparent way requires a lot of education and mentoring. It’s one thing we should try to improve at Mozilla when onboarding new employees. Teaching what it means to be transparent. I’m not even sure everyone has the same notion of what transparency means already.
For example, too many times, I receive emails in private. That’s unfortunate because it creates information silos and it becomes a lot harder to open up a conversation which started in private. Because I was kind of tired of this, I created a set of slides and explanation for learning how to work with emails. Available in French and English.
Some people are afraid of working in the open for many reasons. They may come from a company where secrecy was very strong, or they had a bad experience by being too open. It takes then time to re-learn the benefits of working in the open.
So because you asked an open question :) Some items.
Let's learn together how to work in a transparent way or in the open.
Otsukare.
http://www.otsukare.info/2015/01/25/working-and-transparency
|
|
Stormy Peters: Working in the open is hard |
A recent conversation on a Mozilla mailing list about whether IRC channels should be archived or not shows what a commitment it is to remain open. It’s hard work and not always comfortable to work completely in the open.
Most of us in open source are used to “working in the open”. Everything we send to a mailing list is not only public, but archived and searchable via Google or Yahoo! forever. Five years later, you can go back and see how I did my job as Executive Director of GNOME. Not only did I blog about it, but many of the conversations I had were on open mailing lists and irc channels.
There are many benefits to being open.
Being open means that anybody can participate, so you get much more help and diversity.
Being open means that you are transparent and accountable.
Being open means you have history. You can also go back and see exactly why a decision was made, what the pros and cons were and see if any of the circumstances have changed.
But it’s not easy.
Being open means that when you have a disagreement, the world can follow along. We warn teenagers about not putting too much on social media, but can you imagine every disagreement you’ve ever had at work being visible to all your future employers. (And spouses!)
But those of us working in open source have made a commitment to be open and we try hard.
Many of us get used to working in the open, and we think it feels comfortable and we think we’re good at it. And then something will remind us that it is a lot of work and it’s not always comfortable. Like a conversation about whether irc conversations should be archived or not. IRC conversations are public but not always archived. So people treat them as a place where anyone can drop in but the conversation is bounded in time and limited to the people you can see in the room. The fact that these informal conversations might be archived and read by anyone and everyone later means that you now have to think a lot more about what you are saying. It’s less of a chat and more of a weighed conversation.
The fact that people steeped in open source are having a heated debate about whether Mozilla IRC channels should be archived or not shows that it’s not easy being open. It takes a lot of work and a lot of commitment.
Related posts:
http://feedproxy.google.com/~r/StormysCornerMozilla/~3/uk1WR_hIRVU/working-in-the-open-is-hard.html
|
|
Doug Belshaw: Weeknote 04/2015 |
This week I’ve been:
I wasn’t at BETT this week. It’s a great place to meet people I haven’t seen for a while and last year I even gave a couple of presentations and a masterclass. However, this time around, my son’s birthday and party gave me a convenient excuse to miss it.
Next week I’m working from home as usual. In fact, I don’t think I’m away again until our family holiday to Dubai in February half-term!
Image CC BY Dave Fayram
|
|
Mike Hommey: Explicit rename/copy tracking vs. detection after the fact |
One of the main differences in how mercurial and git track files is that mercurial does rename and copy tracking and git doesn’t. So in the case of mercurial, users are expected to explicitly rename or copy the files through the mercurial command line so that mercurial knows what happened. Git simply doesn’t care, and will try to detect after the fact when you ask it to.
The consequence is that my git-remote-hg, being currently a limited prototype, doesn’t make the effort to inform mercurial of renames or copies.
This week, Ehsan, as a user of that tool, pushed some file moves, and subsequently opened an issue, because some people didn’t like it.
It was a conscious choice on my part to make git-remote-hg public without rename/copies detection, because file renames/copies are not happening often, and can just as much not be registered by mercurial users.
In fact, they haven’t all been registered for as long as Mozilla has been using mercurial (see below, I didn’t actually know I was so spot on when I wrote this sentence), and people haven’t been pointed at for using broken tools (and I’ll skip the actual language that was used when talking about Ehsan’s push).
And since I’d rather not make unsubstantiated claims, I dug in all of mozilla-central and related repositories (inbound, b2g-inbound, fx-team, aurora, beta, release, esr*) and here is what I found, only accounting files that have been copied or renamed without being further modified (so, using git diff-tree -r -C100%, and eliminating empty files), and correlating with the mercurial rename/copy metadata:
And that’s not counting all the copies and renames with additional modifications.
Fun fact, this is what I found in the Mercurial mercurial repository:
There are 1061 files in mercurial, versus 115845 in mozilla-central, so there is less occasion for renames/copies there, still, even they forget to use “hg move” and break their history as a result.
I think this shows how requiring explicit user input simply doesn’t pan out.
Meanwhile, I have prototype copy/rename detection for git-remote-hg working, but I need to tweak it a little bit more before publishing.
|
|
Mozilla Release Management Team: Firefox 36 beta2 to beta3 |
In this beta, as in beta 2, we have a bug fixes for MSE. We have also a few bugs found with the release of Firefox 35. As usual, beta 3 is a desktop only version.
| Extension | Occurrences |
| cpp | 17 |
| js | 13 |
| h | 7 |
| ini | 6 |
| html | 6 |
| jsm | 3 |
| xml | 1 |
| webidl | 1 |
| txt | 1 |
| svg | 1 |
| sjs | 1 |
| py | 1 |
| mpd | 1 |
| list | 1 |
| Module | Occurrences |
| dom | 20 |
| browser | 18 |
| toolkit | 6 |
| dom | 4 |
| dom | 4 |
| testing | 3 |
| gfx | 3 |
| netwerk | 2 |
| layout | 2 |
| mobile | 1 |
| media | 1 |
| docshell | 1 |
| build | 1 |
List of changesets:
| Steven Michaud | Bug 1118615 - Flash hangs in HiDPI mode on OS X running peopleroulette app. r=mstange a=sledru - 430bff48811d |
| Mark Goodwin | Bug 1096197 - Ensure SSL Error reports work when there is no failed certificate chain. r=keeler, a=sledru - a7f164f7c32d |
| Seth Fowler | Bug 1121802 - Only add #-moz-resolution to favicon URIs that end in ".ico". r=Unfocused, a=sledru - d00b4a85897c |
| David Major | Bug 1122367 - Null check the result of D2DFactory(). r=Bas, a=sledru - 57cb206153af |
| Michael Comella | Bug 1116910 - Add new share icons in the action bar for tablet. r=capella, a=sledru - f6b2623900f1 |
| Jonathan Watt | Bug 1122578 - Part 1: Make DrawTargetCG::StrokeRect stroke from the same corner and in the same direction as older OS X and other Moz2D backends. r=Bas, a=sledru - d3c92eebdf3e |
| Jonathan Watt | Bug 1122578 - Part 2: Test start point and direction of dashed stroking on SVG rect. r=longsonr, a=sledru - 7850d99485e6 |
| Mats Palmgren | Bug 1091709 - Make Transform() do calculations using gfxFloat (double) to avoid losing precision. r=mattwoodrow, a=sledru - 0b22d12d0736 |
| Hiroyuki Ikezoe | Bug 1118749 - Need promiseAsyncUpdates() before frecencyForUrl. r=mak, a=test-only - 4501fcac9e0b |
| Jordan Lund | Bug 1121599 - remove android-api-9-constrained and android-api-10 mozconfigs from all trees, r=rnewman a=npotb DONTBUILD - 787968dadb44 |
| Tooru Fujisawa | Bug 1115616 - Commit composition string forcibly when search suggestion list is clicked. r=gavin,adw a=sylvestre - 2d629038c57b |
| Ryan VanderMeulen | Bug 1075573 - Disable test_videocontrols_standalone.html on Android 2.3 due to frequent failures. a=test-only - a666c5c8d0ba |
| Ryan VanderMeulen | Bug 1078267 - Skip netwerk/test/mochitests/ on Android due to frequent failures. a=test-only - 0c36034999bb |
| Christoph Kerschbaumer | Bug 1121857 - CSP: document.baseURI should not get blocked if baseURI is null. r=sstamm, a=sledru - a9b183f77f8d |
| Christoph Kerschbaumer | Bug 1122445 - CSP: don't normalize path for CSP checks. r=sstamm, a=sledru - 7f32601dd394 |
| Christoph Kerschbaumer | Bug 1122445 - CSP: don't normalize path for CSP checks - test updates. r=sstamm, a=sledru - a41c84bee024 |
| Karl Tomlinson | Bug 1085247 enable remaining mediasource-duration subtests a=sledru - d918f7ea93fe |
| Sotaro Ikeda | Bug 1121658 - Remove DestroyDecodedStream() from MediaDecoder::SetDormantIfNecessary() r=roc a=sledru - 731843c58e0d |
| Jean-Yves Avenard | Bug 1123189: Use sourceended instead of loadeddata to check durationchanged count r=karlt a=sledru - 09df37258699 |
| Karl Tomlinson | Bug 1123189 Queue "durationchange" instead of dispatching synchronously r=cpearce a=sledru - 677c75e4d519 |
| Jean-Yves Avenard | Bug 1123269: Better fix for Bug 1121876 r=cpearce a=sledru - 56b7a3953db2 |
| Jean-Yves Avenard | Bug 1123054: Don't check VDA reference count. r=rillian a=sledru - a48f8c55a98c |
| Andreas Pehrson | Bug 1106963 - Resync media stream clock before destroying decoded stream. r=roc, a=sledru - cdffc642c9b9 |
| Ben Turner | Bug 1113340 - Make sure blob urls can load same-prcess PBackground blobs. r=khuey, a=sledru - c16ed656a43b |
| Paul Adenot | Bug 1113925 - Don't return null in AudioContext.decodeAudioData. r=bz, a=sledru - 46ece3ef808e |
| Masatoshi Kimura | Bug 1112399 - Treat NS_ERROR_NET_INTERRUPT and NS_ERROR_NET_RESET as SSL errors on https URLs. r=bz, a=sledru - ba67c22c1427 |
| Hector Zhao | Bug 1035400 - 'restart to update' button not working. r=rstrong, a=sledru - 8a2a86c11f7c |
| Ryan VanderMeulen | Backed out the code changes from changeset c16ed656a43b (Bug 1113340) since Bug 701634 didn't land on Gecko 36. - e8effa80da5b |
| Ben Turner | Bug 1120336 - Land the test-only changes on beta. r=khuey, a=test-only - a6e5dedbd0c0 |
| Sami Jaktholm | Bug 1001821 - Wait for eyedropper to be destroyed before ending tests and checking for leaks. r=pbrosset, a=test-only - 4036f72a0b10 |
| Mark Hammond | Bug 1117979 - Fix orange by not relying on DNS lookup failure in the 'error' test. r=gavin, a=test-only - e7d732bf6091 |
| Honza Bambas | Bug 1123732 - Null-check uri before trying to use it. r=mcmanus, a=sledru - 3096b7b44265 |
| Florian Qu`eze | Bug 1103692 - ReferenceError: bundle is not defined in webrtcUI.jsm. r=felipe, a=sledru - 9b565733c680 |
| Bobby Holley | Bug 1120266 - Factor some machinery out of test_BufferingWait into mediasource.js and make it Promise-friendly. r=jya, a=sledru - ff1b74ec9f19 |
| Jean-Yves Avenard | Bug 1120266 - Add fragmented mp4 sample videos. r=cajbir, a=sledru - 53f55825252a |
| Paul Adenot | Bug 698079 - When using the WASAPI backend, always output audio to the default audio device. r=kinetik, a=sledru - 20f7d44346da |
| Paul Adenot | Bug 698079 - Synthetize the clock when using WASAPI to prevent A/V desynchronization issues when switching the default audio output device. r=kinetik, a=sledru - 0411d20465b4 |
| Matthew Noorenberghe | Bug 1079554 - Ignore most UITour messages from pages that aren't visible. r=Unfocused, a=sledru - e35e98044772 |
| Markus Stange | Bug 1106906 - Always return false from nsFocusManager::IsParentActivated in the parent process. r=smaug, a=sledru - 0d51214654ad |
| Bobby Holley | Bug 1121148 - Move constants that we should not be using directly into a namespace. r=cpearce, a=sledru - 1237ddff18be |
| Bobby Holley | Bug 1121148 - Make QUICK_BUFFERING_LOW_DATA_USECS a member variable and adjust it appropriately. r=cpearce, a=sledru - 62f7b8ea571f |
| Chris AtLee | Bug 1113606 - Use app-specific API keys. r=mshal, r=nalexander, a=gavin - b3836e49ae7f |
| Ryan VanderMeulen | Bug 1121148 - Add missing detail:: to fix bustage. a=bustage - b3792d13df24 |
http://release.mozilla.org/statistics/36/2015/01/24/fx-36-b2-to-b3.html
|
|
Mozilla WebDev Community: Beer and Tell – January 2015 |
Once a month, web developers from across the Mozilla Project get together to trade and battle Pok'emon. While we discover the power of friendship, we also find time to talk about our side projects and drink, an occurrence we like to call “Beer and Tell”.
There’s a wiki page available with a list of the presenters, as well as links to their presentation materials. There’s also a recording available courtesy of Air Mozilla.
Our first presenter, Osmose (that’s me!), shared a Gameboy emulator, written in Python, called gamegirl. The emulator itself is still very early in development and only has a few hundred CPU instructions implemented. It also includes a console-based debugger for inspecting the Gameboy state while executing instructions, powered by urwid.
Next, groovecoder shared some wisdom about his new favorite continuous deployment setup. The setup involves hosting your code on Github, running continuous integration using Travis CI, and hosting the site on Heroku. Travis supports deploying your app to Heroku after a successful build, and groovecoder uses this to deploy his master branch to a staging server.
Once the code is ready to go to production, you can make a pull request to a production branch on the repo. Travis can be configured to deploy to a different app for each branch, so once that pull request is merged, the site is deployed to production. In addition, the pull request view gives a good overview of what’s being deployed. Neat!
This system is in use on codesy, and you can check out the codesy Github repo to see how they’ve configured their project to deploy using this pattern.
Friend of the blog peterbe showed off django-screencapper, a microservice that generates screencaps from video files using ffmpeg. Developed as a test to see if generating AirMozilla icons via an external service was viable, it queues incoming requests using Alligator and POSTs the screencaps to a callback URL once they’ve been generated.
A live example of the app is available at http://screencapper.peterbe.com/receiver/.
Motorcycle enthusiast tofumatt hates the Github contributor streak graph. To be specific, he hates the one on his own profile; it’s distracting and leads to bad behavior and imposter syndrome. To save himself and others from this terror, he created a Firefox add-on called the GitHub Contribution Hider that hides only the contribution graph on your own profile. You can install the addon by visiting it’s addons.mozilla.org page. Versions of the add-on for other browsers are in the works.
Fun fact: The power of friendship cannot, in fact, overcome type weaknesses.
If you’re interested in attending the next Beer and Tell, sign up for the dev-webdev@lists.mozilla.org mailing list. An email is sent out a week beforehand with connection details. You could even add yourself to the wiki and show off your side-project!
See you next month!
https://blog.mozilla.org/webdev/2015/01/23/beer-and-tell-january-2015/
|
|
Adam Lofting: Weeknotes: 23 Jan 2015 |

unrelated photo
I managed to complete roughly five of my eleven goals for the week.
http://feedproxy.google.com/~r/adamlofting/blog/~3/52LRiLeimDU/
|
|
Jess Klein: Dino Dribbble |





|
|
Ehsan Akhgari: Running Microsoft Visual C++ 2013 under Wine on Linux |
The Wine project lets you run Windows programs on other operating systems, such as Linux. I spent some time recently trying to see what it would take to run Visual C++ 2013 Update 4 under Linux using Wine.
The first thing that I tried to do was to run the installer, but that unfortunately hits a bug and doesn’t work. After spending some time looking into other solutions, I came up with a relatively decent solution which seems to work very well. I put the instructions up on github if you’re interested, but the gist is that I used a Chromium depot_tools script to extract the necessary files for the toolchain and the Windows SDK, which you can copy to a Linux machine and with some DLL loading hackery you will get a working toolchain. (Note that I didn’t try to run the IDE, and I strongly suspect that will not work out of the box.)
This should be the entire toolchain that is necessary to build Firefox for Windows under Linux. I already have some local hacks which help us get past the configure script, hopefully this will enable us to experiment with using Linux to be able to build Firefox for Windows more efficiently. But there is of course a lot of work yet to be done.
http://ehsanakhgari.org/blog/2015-01-23/running-microsoft-visual-c-2013-under-wine-on-linux
|
|
Armen Zambrano: Backed out - Pinning for Mozharness is enabled for the fx-team integration tree |

|
|
Doug Belshaw: Ontology, mentorship and web literacy |
This week’s Web Literacy Map community call was fascinating. They’re usually pretty interesting, but today’s was particularly good. I’m always humbled by the brainpower that comes together and concentrates on something I spend a good chunk of my life thinking about!

I’ll post an overview of the entire call in on the Web Literacy blog tomorrow but I wanted to just quickly zoom out and focus on things that Marc Lesser and Jess Klein were discussing during the call. Others mentioned really useful stuff too, but I don’t want to turn this into an epic post!
Marc reminded us of Clay Shirky’s post entitled Ontology is Overrated: Categories, Links, and Tags. It’s a great read but the point Marc wanted to extract is that pre-defined ontologies (i.e. ways of classifying things) are kind of outdated now we have the Internet:

In the Web 2.0 era (only 10 years ago!) this was called a folksonomic approach. I remembered that I actually used Shirky’s post in one of my own for DMLcentral a couple of years ago. To quote myself:
The important thing here is that we – Mozilla and the community – are creating a map of the territory. There may be others and we don’t pretend we’re not making judgements. We hope it’s “useful in the way of belief” (as William James would put it) but realise that there are other ways to understand and represent the skills and competencies required to read, write and participate on the Web.
Given that we were gently chastised at the LRA conference for having an outdated approach to representing literacies, we should probably think more about this.
Meanwhile, Jess, was talking about the Web Literacy Map as an ‘API’ upon which other things could be built. I reminded her of the WebLitMapper, a prototype I suggested and Atul Varma built last year. The WebLitMapper allows users to tag resources they find around the web using competencies from the Web Literacy Map.
This, however, was only part of what Jess meant (if I understood her correctly). She was interested in multiple representations of the map, kind of like these examples she put together around learning pathways. This would allow for the kind of re-visualisations of the Web Literacy Map that came out of the MozFest Remotee Challenge:
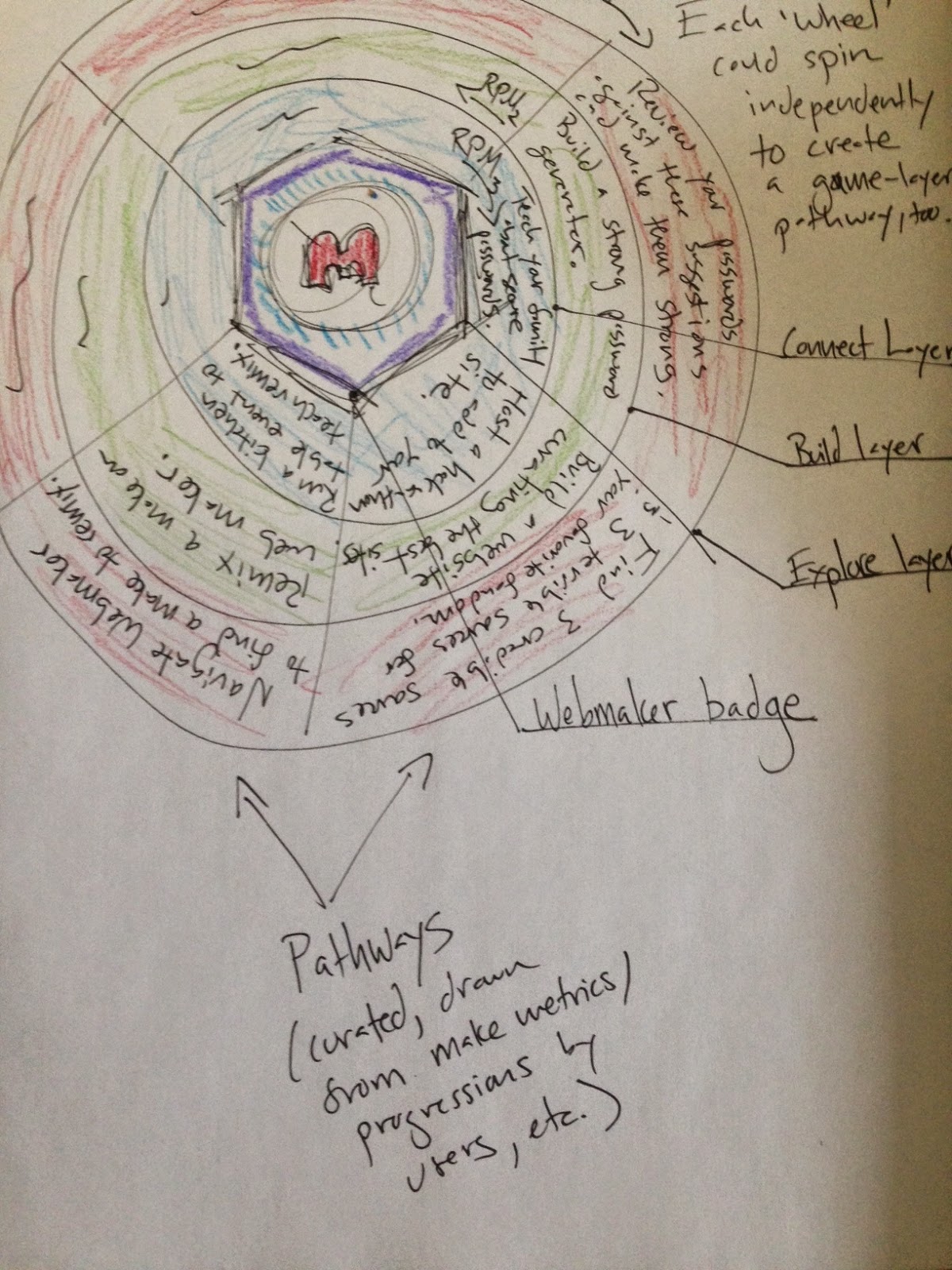
Capturing the complexity of literacy skill acquisition and development is particularly difficult given the constraints of two dimensions. It doubly-difficult if the representation has to be static.
Finally from Jess (for the purposes of this post, at least) she reminded us of some work she’d done around matching mentors and learners:

The overwhelming feeling on the call was that we should retain the competency view of the Web Literacy Map for v1.5. It’s familiar, and helps with adoption:

However, this decision doesn’t prevent us from exploring other avenues combining learning pathways, badges, and alternative ways to representing the overall skill/competency ecosystem. Perhaps diy.org/skills can teach us a thing or two?
Questions? Comments Tweet me (@dajbelshaw or email me (doug@mozillafoundation.org
|
|
Florian Qu`eze: Project ideas wanted for Summer of Code 2015 |
Google is running Summer of Code again in 2015.
Mozilla has had the pleasure of participating every year so far, and we
are hoping to participate again this year. In the next few weeks, we need
to prepare a list of suitable projects to support our application.
Can you think of a 3-month coding project you would love to guide a student through? This is your chance to get a student
focusing on it for 3 months! Summer of Code is a great opportunity to introduce new people to
your team and have them work on
projects you care about but that aren't on the critical path to shipping your next release.
Here are the conditions for the projects:
If
you have an idea, please put it on the Brainstorming page, which is our
idea development scratchpad. Please read the instructions at the top –
following them vastly increases chances of your idea getting added
to the formal Ideas page.
The deadline to submit project ideas and help us be selected by Google is February 20th.
Note for students: the student application period starts on March 16th, but the sooner you start discussing project ideas with potential mentors, the better.
Please feel free to discuss with me any question you may have related to Mozilla's participation in Summer of Code. Generic Summer of Code questions are likely already answered in the FAQ.
http://blog.queze.net/post/2015/01/22/Project-ideas-wanted-for-Summer-of-Code-2015
|
|
Benoit Girard: Gecko Bootcamp Talks |
Last summer we held a short bootcamp crash course for Gecko. The talks have been posted to air.mozilla.com and collected under the TorontoBootcamp tag. The talks are about an hour each but will be very informative to some. They are aimed at people wanting a deeper understanding of Gecko.
View the talks here: https://air.mozilla.org/search/?q=tag%3A+TorontoBootcamp

Gecko Pipeline
In the talks you’ll find my first talk covering an overall discussion of the pipeline, what stages run when and how to skip stages for better performance. Kannan’s talk discusses Baseline, our first tier JIT. Boris’ talk discusses Restyle and Reflow. Benoit Jacob’s talk discusses the graphics stack (Rasterization + Compositing + IPC layer) but sadly the camera is off center for the first half. Jeff’s talk goes into depth into Rasterization, particularly path drawing. My second talk discusses performance analysis in Gecko using the gecko profiler where we look at real profiles of real performance problems.
I’m trying to locate two more videos about layout and graphics that were given at another session but would elaborate more the DisplayList/Layer Tree/Invalidation phase and another on Compositing.

https://benoitgirard.wordpress.com/2015/01/22/gecko-bootcamp-talks/
|
|
Matt Thompson: Mozilla Learning in 2015: our vision and plan |
This post is a shortened, web page version of the 2015 Mozilla Learning plan we shared back in December. Over the next few weeks, we’ll be blogging and encouraging team and community members to post their reflections and detail on specific pieces of work in 2015 and Q1. Please post your comments and questions here — or get more involved.

Within ten years, there will be five billion citizens of the web.
Mozilla wants all of these people to know what the web can do. What’s possible. We want them to have the agency, skills and know-how they need to unlock the full power of the web. We want them to use the web to make their lives better. We want them to know they are citizens of the web.
Mozilla Learning is a portfolio of products and programs that helps people learn how to read, write and participate in the digital world.
Building on Webmaker, Hive and our fellowship programs, Mozilla Learning is a portfolio of products and programs that help these citizens of the web learn the most important skills of our age: the ability to read, write and participate in the digital world. These programs also help people become mentors and leaders: people committed to teaching others and to shaping the future of the web.
Mark Surman presents the Mozilla Learning vision and plan in Portland, Dec 2015
By 2017, Mozilla will have established itself as the best place to learn the skills and know-how people need to use the web in their lives, careers and organizations. We will have:
At the end of these three years, we may have established something like a “Mozilla University” — a learning side of Mozilla that can sustain us for many decades. Or, we may simply have a number of successful learning programs. Either way, we’ll be having impact.
We may establish something like a “Mozilla University” — a learning side of Mozilla that can sustain us for many decades.

1) Learning Networks 2) Learning Products 3) Leadership Development
Our focus in 2015 will be to consolidate, improve and focus what we’ve been building for the last few years. In particular we will:
The short term goal is to make each of our products and programs succeed in their own right in 2015. However, we also plan to craft a bigger Mozilla Learning vision that these products and programs can feed into over time.

Mozilla Learning is notional at this point. It’s a stake in the ground that says:
Mozilla is in the learning and empowerment business for the long haul.
In the short term, the plan is to use “Mozilla Learning” as an umbrella term for our community-driven learning and leadership development initiatives — especially those run by the Mozilla Foundation, like Webmaker and Hive. It may also grow over time to encompass other initiatives, like the Mozilla Developer Network and leadership development programs within the Mozilla Reps program. In the long term: we may want to a) build out a lasting Mozilla learning brand (“Mozilla University?”), or b) build making and learning into the Firefox brand (e.g., “Firefox for Making”). Developing a long-term Mozilla Learning plan is an explicit goal for 2015. 
Practically, the first iteration of Mozilla Learning will be a portfolio of products and programs we’ve been working on for a number of years: Webmaker, Hive, Maker Party, Fellowship programs, community labs. Pulled together, these things make up a three-layered strategy we can build more learning offerings around over time.
One of our goals with Mozilla Learning is to grow the scope and scale of Mozilla’s education and empowerment efforts. The working theory is that we will create an interconnected set of offerings that range from basic learning for large numbers of people, to deep learning for key leaders who will help shape the future of the web (and the future of Mozilla). 
We want to increasing the scope and diversity of how people learn with Mozilla.
We’ll do that by building opportunities for people to get together to learn, hack and invent in cities on every corner of the planet. And also: creating communities that help people working in fields like science, news and government figure out how to tap into the technology and culture of the web in their own lives, organizations and careers. The plan is to elaborate and test out this theory in 2015 as a part of the Mozilla Learning strategy process. (Additional context on this here: http://mzl.la/depth_and_scale.) 
How will we contribute to Mozilla’s top-line goals? In 2015, We’ll measure success through two key performance indicators: relationships and reach.

In 2015, we will continue to grow and improve the impact of our local Learning Networks.

Grow a base of engaged desktop and mobile users for Webmaker.

Develop a leadership development program, building off our existing Fellows programs.
|
|
Air Mozilla: Community Building Forum |
 The Grow Mozilla Community Building Forum
The Grow Mozilla Community Building Forum
|
|







