CodeSOD: Strictly Speaking |
I used to work in a VB.Net shop. It wasn't my favorite place, but it gave me an appreciation for modern VisualBasic, instead of old VB6 (which I also had to work on).
Part of what made VB.Net better was that it had more sane defaults. By default it enabled Option Explicit (require variables to be declared before use), and Option Strict (error on any narrowing conversions between data-types). One of its biggest weaknesses, however, was that you could turn those features off, something which was frequently done to make old-style VB6 code more compatible with VB.Net. Arguably, the biggest WTF was that Microsoft promised an "easy" path to upgrade VB6 code to VB.Net, through a mix of compatibility libraries and conversion tools that didn't work.
Which brings us to this VB.Net code that Stephen inherited. It's a small WTF, but so representative of the ways in which things could go very wrong.
Private m_intErrorCode As Integer
Public Property ErrorCode() As String
Get
Return m_intErrorCode
End Get
Set(ByVal Value As String)
m_intErrorCode = Value
End Set
End Property
The private member is an Integer. The public interface is a String. Every get/set ends up converting between these two data-types. This is the kind of thing that someone has to go out of their way to enable. And yes, if the input value isn't a valid number, this throws an exception.
And this small example hints at a much larger problem: you know this is codebase is a pile of string-ly typed data getting chucked around between modules, stuffed into strongly typed values only at the lowest layers, and is stuffed with unexpected crashes when runtime type checks fail.
|
Метки: CodeSOD |
CodeSOD: Clever And Or Not |
The transition from Python 2 to Python 3 has been a long running challenge. Arguably, too long running, but those are the challenges when you introduce breaking changes into a widely used language.
Now, one of those breaking changes was around string handling and encoding- Unicode versus ASCII. This meant that, if you wanted code to run on both versions of Python, you'd need to check which version you were on to handle encodings properly.
Ryan J's predecessor wanted to implement logic where, on Python 2, they just handled the strings without transformation, while in Python 3, they'd force the string to be encoded in "latin1". The traditional way of writing this would be something like:
if sys.version_info[0] < 3:
_b = lambda(x: x)
else:
_b = lambda(x: x.encode('latin1')
Now, anyplace you have to handle a string, you can stringVar = _b(stringVar). On Python 2 it's a no-op, on Python 3 it re-encodes the string. It's maybe not the most elegant or Pythonic way of solving the problem, but it's a common enough practice.
But that doesn't show off how clever you are. It needs to be a one-liner. You could do something like this, using Python's version of a ternary:
_b = (lambda x: x) if (sys.version_info[0] < 3) else (lambda x: x.encode('latin1'))
But that's not clever enough. No, you have to show your absolute mastery over the language, using constructs to do things they were never intended to do.
_b=sys.version_info[0]<3 and (lambda x:x) or (lambda x:x.encode('latin1'))
There we go. This exploits the fact that boolean functions don't return boolean types- they return the non-falsy value that satisfied their condition.
Let's walk through it and start with the and. If we're on Python 2, the first term of the and is true, so we have to evaluate the second. Now a lambda is always going to be truth-y, so the and is satisfied and is true. We don't need to evaluate the or, because regardless of what the second expression is, the whole thing is true. So this returns (lambda x:x) and stores it in _b.
If we're on Python 3, then the entire and is false, so we don't need to look at the second term in the and. But the or now matters, so we evaluate the second term in the or, and thus return (lambda x:x.encode('latin1')).
Code where you need to write out a truth-table to understand its operation is way more clever than a basic conditional expression, thus this code succeeds at its core goal: establishing that the author was Very Smart™.
|
Метки: CodeSOD |
CodeSOD: Doc Block |
We've all seen documentation blocks like this:
/**
* Get the value of instructions
*
* @return string|null
*/
public function getInstructions()
{
return $this->instructions;
}
It's that specific kind of useless: it's bigger than the function it describes, which isn't automatically a bad thing, but it contains no more information than the function itself. I suppose it gives us some type information, which I don't hate.
That particular block come from Sandra, still at InitAg. And while that block doesn't really rise to the level of a WTF, the way documentation is used in the codebase does: it's just doc-blocks like these. They basically all recount the signature of the method and fail to add anything more. It took Sandra hours of combing through the code to understand what the "instructions" in question here actually were.
It's a perfect case of "working to the metric". Someone had a requirement that every function needs to be documented. Now every function is documented. That this documentation gives you no clue about the role of any given property or object is irrelevant: the linter will pass because every function has comments. Mostly useless comments, but comments.
But just to confuse things a bit more, I suspect the previous developer got their start in Python, just based on their setter method:
/**
* Set the value of instructions
*
* @param string|null $instructions
*
* @return self
*/
public function setInstructions($instructions)
{
$this->instructions = $instructions;
return $this;
}
Return "self", eh? I suppose I should give them bonus points for attempting to make a fluent API for their setters- you could theoretically do something like:
myObj.setInstructions("some instructions")
.setRecurrence(someRecurrenceInterval)
.setOtherProperty(someValue)
Of course, despite including the hook for it, no one has written any code that does that. If only there were some better documentation to make that clear to developers.
|
Метки: CodeSOD |
CodeSOD: Four Sellers |
Andrew had to touch some Pascal code. Yes, really. He writes: "I came across this section of code today and really wanted to find out who wrote it. Then I really wanted to find out who added the comment."
{ Ugly code follows, a loop would be nice }
{ Seller #1 }
if not EOF then
begin
lsSName := FieldByName('txtname').AsString;
if Length(FieldByName('txtsname').AsString) > 0 then
begin
lsSName := Concat(lsSName,', ' + FieldByName('txtsname').AsString);
end;
Next;
sctevarS1Name.AsString := lsSName;
end
else
begin
Close;
Exit;
end; { else }
{ Seller #2 }
if not EOF then
begin
lsSName := FieldByName('txtname').AsString;
if Length(FieldByName('txtsname').AsString) > 0 then
begin
lsSName := Concat(lsSName,', ' + FieldByName('txtsname').AsString);
end;
Next;
sctevarS2Name.AsString := lsSName;
end
else
begin
Close;
Exit;
end; { else }
{ Seller #3 }
if not EOF then
begin
lsSName := FieldByName('txtname').AsString;
if Length(FieldByName('txtsname').AsString) > 0 then
begin
lsSName := Concat(lsSName,', ' + FieldByName('txtsname').AsString);
end;
Next;
sctevarS3Name.AsString := lsSName;
end
else
begin
Close;
Exit;
end; { else }
{ Seller #4 }
if not EOF then
begin
lsSName := FieldByName('txtname').AsString;
if Length(FieldByName('txtsname').AsString) > 0 then
begin
lsSName := Concat(lsSName,', ' + FieldByName('txtsname').AsString);
end;
Next;
sctevarS4Name.AsString := lsSName;
end
else
begin
Close;
Exit;
end; { else }
Yes, a loop would have been nice. Pity we couldn't do that, for some reason.
|
Метки: CodeSOD |
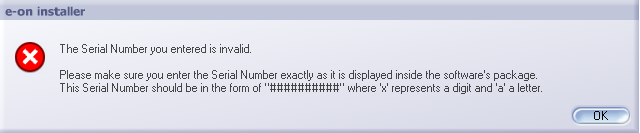
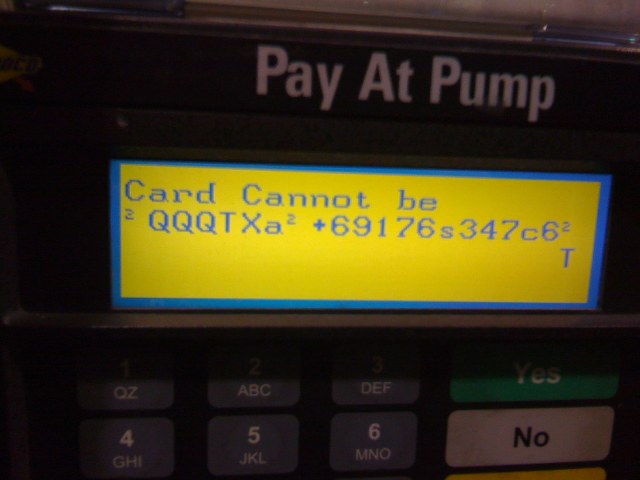
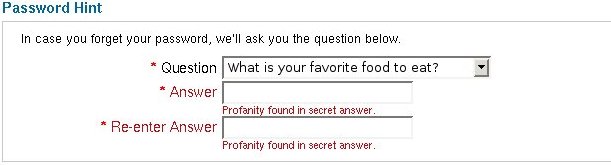
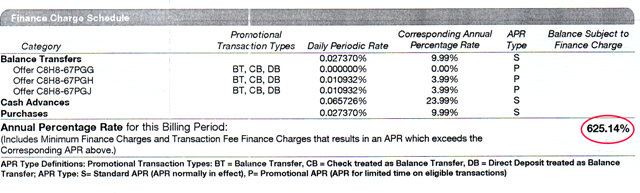
Error'd: Classic Errord: Phone Pain |
We're reaching back for a blast-from-the-past for today's Errord, all the way from 2009. How little things really change. Original - Remy
"This phone booth in Windhoek is obviously in distress," Chris Pliers writes, "who should I call?"
Matt got this message while installing Vue 5 Infinite.
"I came across this at a Sunoco station while trying to get some fuel," Luke notes, "I guess I can't really argue with it."
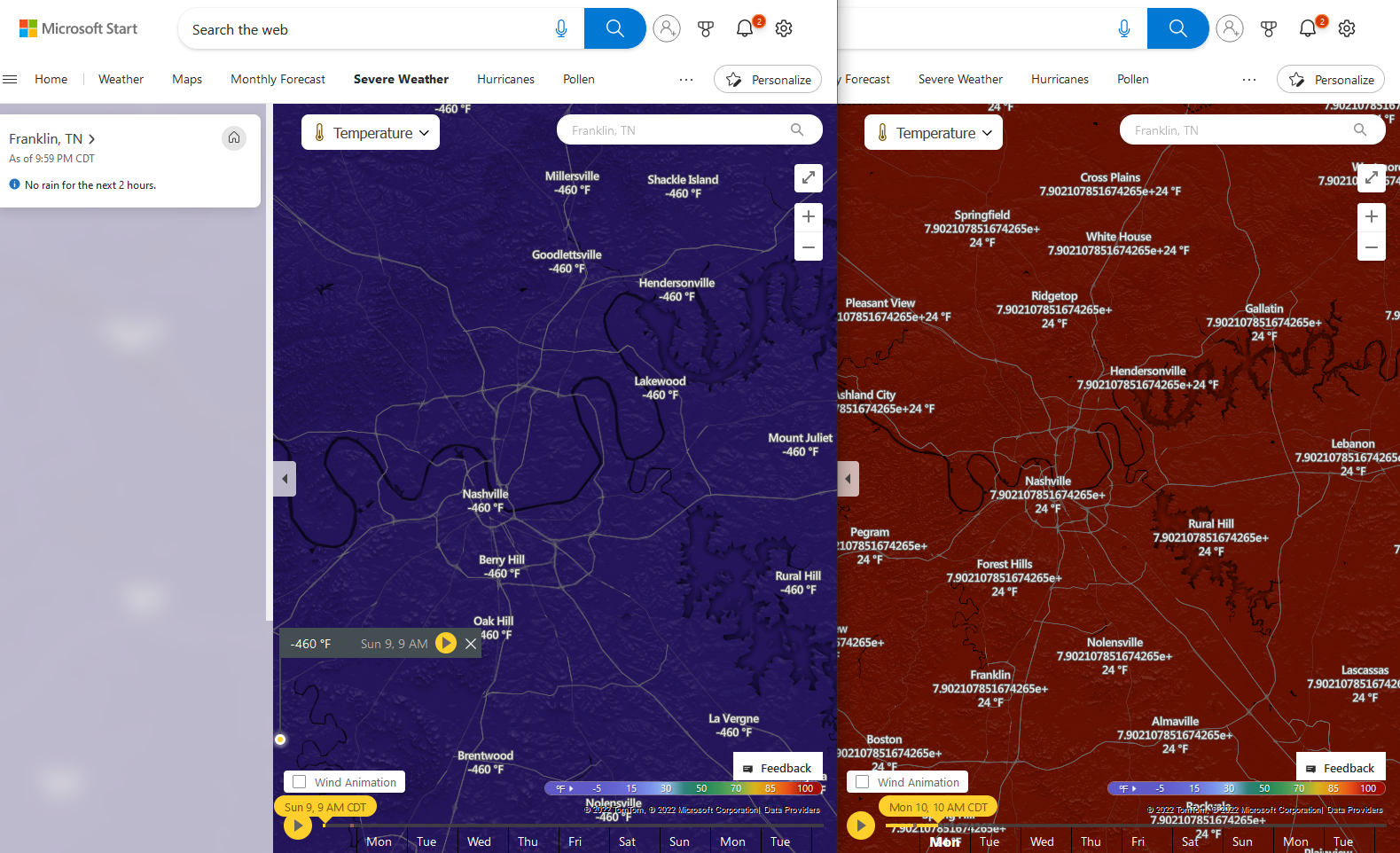
"I was taking an introductory course to DB2 when I spotted this page," Abel Morelos writes, "somebody, please explain this figure to me!"
"Good idea, United States Postal Service website," writes Nick, "I'd hate to offend the database server."
Bruce Carson writes, "my Harris Bank statement shows an interest rate that would make Mafia bosses blush!"
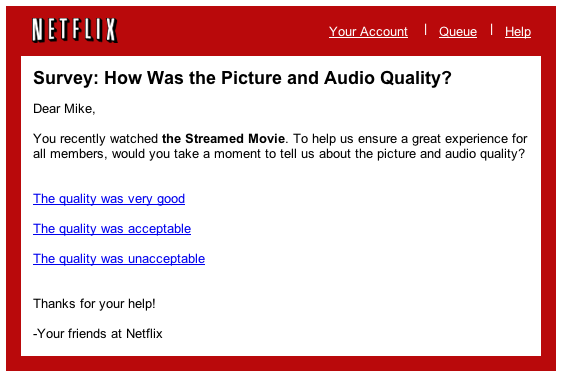
"It turns out that Netflix has only one streaming movie," Mike Ely notes, "am I also the only streaming customer? Or can we start a fan club for this film?"
"What with all this talk about the economic crisis," writes Paul Keating, "it's always great to find a genuine bargain Like this one from Toys R Us!"
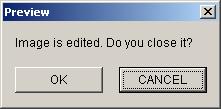
"Pop quiz, hot shot," writes Michael Moore, "there's an image in an editor. And guess what, it is edited. Do you close it? Huh, do you close it?"
"This USB stick cover gracefully evades the whole '1000 vs 1024' issue," Sergey Shelukhin notes, "well, almost."
|
Метки: Error'd |
CodeSOD: Foreign to Administration |
Doug's co-workers were creating a database to manage a set of custom application services and their associated metadata. So one of them threw together this table:
create table applications (
name varchar(20) primary key,
attribute varchar(20) not null,
listen_port integer not null unique,
admin_user varchar(20) not null
)
This was fine, until one of the users decided they wanted a second admin for an application. So someone went ahead and updated the table:
create table applications (
name varchar(20) primary key,
attribute varchar(20) not null,
listen_port integer not null unique,
admin1 varchar(20) not null,
admin2 varchar(20)
)
Doug helpfully pointed out that they could normalize this data and store the list of admins as a table with foreign keys. Something like:
create create table application_admins (
name varchar(20) references applications,
admin varchar(20) not null
);
Now, they could just join the tables and have an arbitrary number of admins per application.
Everyone agreed this was probably the right way to do it, but all of the code which depended on the table needed the columns to be admin1 and admin2. Sure, that code could be updated, but what might break? It was too risky.
So Doug helpfully provided this query, comment included, to imitate the existing schema:
-- Um, this is evil. Really, you should to do a separate query against the
-- admins table to get the list of admins for each list, instead of this
-- ugly ugly query.
select admins.name, attribute, listen_port, admin1, admin2
from admins
left outer join (
select name, MIN(admin) as admin1 from
application_admins
group by name ) as AD1 using name
left outer join (
select name, MAX(admin) as admin2 from
application_admins
group by name ) as AD1 using name
This was fine until someone realized that they needed more than two admins per application. So they helpfully updated the application_admins table.
create create table application_admins (
name varchar(20) references applications,
admin1 varchar(20) not null,
admin2 varchar(20) not null,
admin3 varchar(20) not null,
admin4 varchar(20) not null,
admin5 varchar(20) not null
);
And then modified the query to match:
select admins.name, attribute, listen_port,
admin1, admin2, admin3, admin4, admin5
from admins
left outer join (
select name, MIN(admin1) as admin1 from
application_admins
group by name ) as AD1 using name
left outer join (
select name, MAX(admin2) as admin2 from
application_admins
group by name ) as AD2 using name
left outer join (
select name, MAX(admin3) as admin3 from
application_admins
group by name ) as AD3 using name
left outer join (
select name, MAX(admin4) as admin4 from
application_admins
group by name ) as AD4 using name
left outer join (
select name, MAX(admin5) as admin5 from
application_admins
group by name ) as AD5 using name
These modifications, of course, were unnecessary, especially the table change, which isn't just unnecessary, it's just wrong. The way relationships work in databases appears to be foreign to some people.
|
Метки: CodeSOD |
CodeSOD: Background Threads |
Nyegomi supports a system with a load of actor objects tied to a bus, and supporting huge numbers of concurrent users. Once per second, the server looks at all the active objects and calls their update method, which gives them a chance to do vital housekeeping. Many of the objects may spin up background threads during that time.
Like a lot of threading code, this leads to loads of problems in the wrong hands. Extra problematic in Python.
class Service(object):
…
def update(self):
if not self.task_complete_yet or not self.can_do_background_task(self.target):
Thread(target=self.try_to_do_background_task).start()
if self.will_do_background_task:
Thread(target=self.do_background_task).start()
def try_to_do_background_task(self):
while not self.task_complete_yet:
time.sleep(0.1)
time.sleep(0.15)
if not self.task_complete_yet and not self.can_do_background_task(self.target):
if not self.task_complete_yet:
self.will_do_background_task = True
Thread(target=self.try_to_do_background_task).start()
return
self.update()
def do_background_task(self):
if not self.can_do_background_task(self.target):
return
self.world.do_background_task(self.target)
self.task_complete_yet = True
self.will_do_background_task = False
def _end_task():
time.sleep(1.0)
self.task_complete_yet = False
Thread(target=_end_task).start()
The details of what the background task is or what the target is are really irrelevant. Let's see if we can trace through what this thing is actually doing.
On an update, if its task isn't complete or it can't do the task at all, it calls try_to_do_background_task as a thread. This thread just idle loops until the task is finished. Then it sleeps a little longer, once the task is done, then it checks: if the task isn't complete (again) and it can't do the background task, and then if the task isn't complete yet (checking a third time), we set a flag to say we will do the background task. Then we start a new copy of this thread.
Now, here's the key problem with this. The resources needed for performing the background task (the logic behind can_do_background_task) are shared, and this particular actor might not get access to them for many seconds. But every second, this spins up a new copy of the try_to_do_background_task thread. Which sleeps until the task is complete, but the task is completed in do_background_task, which is only invoked if will_do_background_task is set to true, which only happens after the task_complete_yet flag is true. And if two trains meet at a crossing, neither may continue until the other has passed.
Even if it wasn't just an endless loop factory, nothing about this uses any locking or mutexes. Now, while Python's GIL prevents that from being a problem in many cases, if a thread is sleeping the variables it shares with other threads may mutate a bunch- which means a thread could easily sleep through the window when task_complete_yet is true.
And yes, this baffling code does end up creating huge piles of race conditions and conflicts with other threads in the system. Nothing about this threading logic makes sense.
|
Метки: CodeSOD |
CodeSOD: Double Checking Your Validation |
Let's say you wanted to express the difference between two numbers as a percentage of the first number. And then let's say that you have no idea how to properly handle a situation where that first number is zero.
In that situation, you might end up with C code much like what Gaetan found.
double delta(double number1,double number2)
{
double delta=1e19;
if ( fabs(number1) > 0 )
{
delta = (number1 - number2)/number1 ;
} else {
delta = number1 - number2 ;
}
delta = fabs(delta);
return delta ;
}
This code is used to "validate" a temporary file by computing a percentage difference between two values. It's part of a "too intricate to be abandoned" pile of C/C++ software written around the turn of the century and gradually expanded over the past two decades.
For such a simple method, I find myself puzzling over nearly every line.
Why is delta defaulted to a small number, especially when it's definitely getting set so that value is discarded anyway? Why fabs(number1) > 0, and not, I don't know, number1 != 0?
But then the real puzzle is in the logic. If number1 isn't a zero, we can divide by it. But if it is zero we're just going to return the absolute value of number2. Which seems like a mistake.
In the specific calling case, Gaetan identifies some more problems:
- the two arguments are physical values. So the result either has the original physical dimension, or no dimension
- The context of the calls clearly expects a number with no physical dimension, so we are bound to encounter problems (or we would have had there been good test cases).
If the file is not valid according to this twisted logic, the caller leaves a whole structure uninitialized
https://thedailywtf.com/articles/double-checking-your-validation
|
Метки: CodeSOD |
CodeSOD: A Matter of Timing |
Juan M inherited some broken code. Upon investigation, the result turned out to be caused by a mix of assumptions.
The first assumption was in the way their users would interact with their scheduling system. Part of the assumption there was that they wouldn't try and schedule any events outside of the scope of a few human lifetimes. The other part of the assumption was that their serialization framework would have a consistent representation of datetimes that was reliably the number of seconds past the Unix epoch.
Their serialization framework had another assumption: that any sufficiently large timestamps must be in milliseconds.
# if greater than this, the number is in ms, if less than or equal it's in seconds
# (in seconds this is 11th October 2603, in ms it's 20th August 1970)
MS_WATERSHED = int(2e10)
def from_unix_seconds(seconds: Union[int, float]) -> datetime:
if seconds > MAX_NUMBER:
return datetime.max
elif seconds < -MAX_NUMBER:
return datetime.min
while abs(seconds) > MS_WATERSHED:
seconds /= 1000
dt = EPOCH + timedelta(seconds=seconds)
return dt.replace(tzinfo=timezone.utc)
This method is called from_unix_seconds, but in fact, if the number is larger than MS_WATERSHED it treats it as milliseconds. And this was almost certainly a hack, merging two different behaviors into one method because when you're round-tripping from JSON you just have a unitless number and have to guess at what it represents.
This code itself isn't something I'd say is a WTF, but its existence is. In today's most popular serialization format, JSON, there is not only no canonical date-time datatype representation, there also isn't any way to extend the format with new datatypes. I know we all hate XML for its complexity, but at least I could specify whether a number represented milliseconds or seconds in the data format itself, and not send my deserializer guessing when parsing the file.
|
Метки: CodeSOD |
Error'd: Fire and Ice |
Some say the world will end in fire , a great American poet once penned. Not wanting to run afoul of his heirs and assigns, I'll leave you to find the rest of it for yourselves. For my own two bits, let me say that while ice may suffice, nothing but nothing is quite like twice.
Gordon S. writes to alert us to an unusual weather event next week. Good news, though. The boss says you can take the day off.
Optimist Michael R. writes "I got this by email today (2022-10-09). Wow, I should better fire up the DeLorean to go back to ${Date_Function} and make sure it is before 23:59 20/07/2022 to claim." Can't be a US style date, can it? 7th August '23? I know, that's terribly optimistic considering Gordon's Revelation.
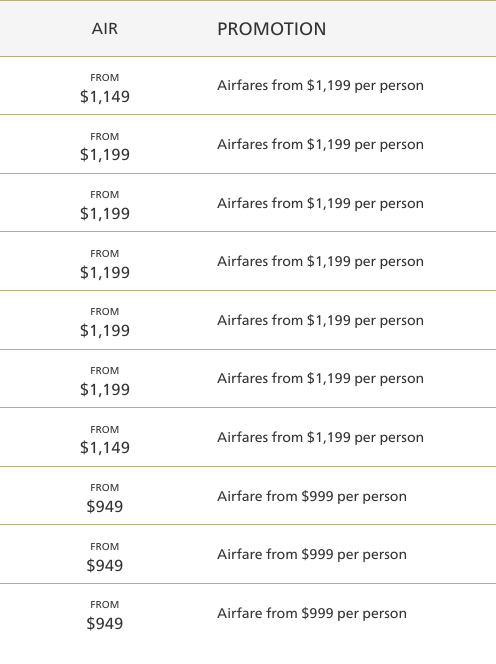
B.J. H. dreams of cruising to Avignon. The US Dollar is strong, but it's nothing compared to the axe that Viking cruise lines is willing to take to their prices. "The normal promotion is the same as the normal price," B.J. writes, "and the special promotions are $50 more. (And prices are per person so most people get to double the promotion.)" I don't understand how that works. Won't only half of most people double the promotion?
An anonymous cinephile crows "This movie looks terrific - where can I see it?" I'm hoping New York Theater got half their money back.
Finally, another anonymous wtfer rubs our noses in it. "This was sitting at the bottom of an article making fun of "1th October". I'm gonna skip dinner tonight, the irony is too rich and delicious." Crow again? We may need to fork this column soon.
Enjoy your breakfast, mes amis.
|
Метки: Error'd |
Protocol Zero |
Ten years ago, James was working for a small company that made electronic components. That company got eaten by Initech, who wanted to connect all those smart electronic devices to their own products. This meant that the two companies had to agree on what that communication protocol would look like. More than that, this was on the critical path to completing the merger- Initech wouldn't go through with the purchase if they couldn't integrate with the systems they were purchasing.
Negotiations were difficult. A lot of the challenge came from Initech's side, because they wanted to make the protocol a "do everything" system for managing data, which just wasn't something the embedded components were designed for. Over the course of many months, a design document gradually took shape.
Since the messages passing through the protocol might be arbitrary lengths, one of the key decision points was "how do we determine the length of the message?" James's team advocated for a byte length in the header, but Initech protested: "We might not know the length of the message until after we've sent it."
They couldn't explain how that could be- the protocol didn't support streaming- but Initech wasn't having any of it. The obvious other solution was to just simply ensure that the message ended with a null byte- a \0.
Everyone went off to work on their implementations, and for a few months, everything seemed like it was going smooth. James and his team whipped up some testing tools, implemented the protocol, sent test messages, and everything worked great. Then it came time to integrate with Initech's implementation.
And everything broke.
Specifically, it looked like Initech had failed to actually terminate their messages.
"See, there's no termination character," James said, highlighting the hex dump which ended with 0x30. Every message ended with 0x30.
"I don't know what you're showing me," the Initech developer said, "because here's how I send the message." The dev highlighted the relevant section of code.
buffer[idx] = '0';
return buffer;
"See? The last index is always set to a zero."
"That's… the character zero."
"It's a zero."
Cue the round of blamestorming. Initech's side pointed to the specification which said the last byte had to be a zero, and that they had successfully made the last byte a zero. Therefore James's team was wrong. James countered that bytes were traditionally numeric values, and they were using a character value, to which Initech countered: the specification doesn't say that explicitly.
As this was happening during a protracted purchasing process, which meant a third party arbitrator got involved. Arbitration found that zero was a zero, and it was James's team who would have to change their code: they had to accept (and send) messages that all terminated with 0x30.
There was just one problem with that: the message body might legitimately contain a 0x30. This meant that they wouldn't know for sure if they'd parsed the whole message. Someone on James's team threw together a hack that kept reading for 0x30s until they hit an arbitrary size threshold that was roughly where they expected messages to be. Most messages were that size or smaller, and for the rare message that was actually longer, well- they just failed to parse it fully. This was rare enough that no one ever raised a stink about it.
James's team was compliant. Initech was happy their new acquisition could go through. And ten years later, that hack remains in place, and the protocol still tries to terminate with 0x30.
|
Метки: Feature Articles |
CodeSOD: An Explosion of Strings |
Rich was digging through some legacy PHP code, trying to track down where some apparently magical values were coming from. This involved tracing through function after function after function.
Here's a sampling of some of those functions:
function iif($cond,$a,$b)
{
return $cond?$a:$b;
}
iif is a common convention in VB, Excel, and Cold Fusion. That gives us a sense of this developer's background, and the fact that they want to force it into a language where you've already got constructs for inline ifs.
But there's a lovely pile of string mangling:
function append(&$string,$append="
")
{
if(empty($string)) $string = $append;
else $string = "$string$append";
}
function appendln(&$string,$append="
")
{
if(empty($string)) $string = $append;
else $string = "$string\n$append";
}
function singleQuote($string)
{
return "'$string'";
}
Or, the wonderfully potent and common reinvention of numeric parsing:
function str2int($string, $concat = true)
{
if(is_numeric($string)) return $string;
$length = strlen($string);
for ($i = 0, $int = '', $concat_flag = true; $i < $length; $i++)
{
if (is_numeric($string[$i]) && $concat_flag)
{
$int .= $string[$i];
} elseif(!$concat && $concat_flag && strlen($int) > 0) {
$concat_flag = false;
}
}
return (int) $int;
}
This parses a string a character at a time, and then turns into a busy loop if it encounters a non-numeric character.
It's okay, though, because if you wanted to split on characters (or "explode" in PHP parlance), there's this handy method.
function explodeByCharacter($delimiters,$str)
{
$del = array_unique(str_split($delimiters));
$ret = array($str);
foreach($del as $cur)
{
if(empty($ret)) { return array(); }
$ret2 = $ret;
unset($ret);
foreach($ret2 as $s) {
$t = explode($cur,$s);
foreach($t as $n) {
if(!empty($n)) {
$ret[] = $n;
}
}
}
}
return $ret;
}
The core logical flow is that they want to split a string by multiple delimiters, and don't want to use regexes. So the core logic is to split the string, then split all the substrings, etc., for every delimiter. But it does this through swapping around temporary variables and unsetting things.
Rich writes:
Need I go on? I haven't even gotten to the date functions yet!
|
Метки: CodeSOD |
CodeSOD: List All Your Arguments |
Pedro inherited a PHP application, and the previous developer had some opinions about how to handle arguments to functions. This is the pattern they used everywhere:
public function concatName($firstName, $lastName) {
$names = array ($firstName, $lastName);
$fullName = 'Mr.' . $names[1] . ' ' . $name[2];
return $names[0] . ' ' . $names[1];
}
There's a lot to unpack here. First, the $fullName line doesn't work as intended, since arrays in PHP are zero indexed. I suspect the developer responsible was trying to figure out how to do this task, and left behind one of their experiments.
But "smash the arguments into an array" is a common feature of this developer's code. It happens in nearly every method. Why? No idea. Do they also use argument unpacking to pass arrays as arguments? Is it all just arrays? Is everything an array? Am I an array?
Did I just type array too many times? Can you get semantic satiation in text?
|
Метки: CodeSOD |
Clbuttic Consequences |

ComCorp went through a rather lengthy process to rebuild its website. One of the many changes implemented was to stop using titles as part of customer names. The lead developer on the project decided that removing the titles from all the places where they appeared was simply too much work.
"We'll just default to 'Mister' and then hide it wherever customer names are shown," he explained.
A few months later, our brave submitter delved into the code and examined this particular function:
It would dutifully remove "mr" (in any case) from any name given. I quickly noticed it wasn't picky about where the "mr" was in the name.
A quick orders search revealed it had mangled 150 peoples' names in their emails and parcel labels. I was horrified to discover this had inadvertently white-washed many people called "Imran" to "Ian".
A quick word with my manager and 1 hotfix later and all was well.
|
Метки: Feature Articles |
Error'd: Agreements and Documentation |
Let's get right into it, because Mark T's day is off to a great start.
Back when the COVID-19 pandemic started, a lot of folks were comparing it to the 1918 influenza epidemic. The application Abby used to document her vaccinations took that comparison somewhat literally.

Dealing with credit card companies is a maze of legalistic nonsense where they redefine common words to mean something completely different and you'll get punished if you don't read the agreement very carefully. Look at what happened to Rob H, where they changed the meaning of the word "optional".

Of course, Mike T ended up having an even harder time reading the agreements. This is what he saw when signing up for a new card:

Joking aside: nobody actually reads those agreements. And as developers, we also never read documentation, so it's a surprise that Terry found this bit of JSON garbage in an Android documentation site.

https://thedailywtf.com/articles/agreements-and-documentation
|
Метки: Error'd |
CodeSOD: Brillant Perls |
Many years ago, a Paula Bean type was hired to make a Perl-based website. It became the company's flagship product, at least briefly, until a better version of the product was ready. But early adopters adopted it, and thus it had to keep operating, because you can't throw a way a 800kLOC web application just because it's fragile and unmaintainable.
And then the site got hacked. So now, fixing everything becomes incredibly important, and the task fell to Erik. He needed to do a security audit and identify vulnerabilities. Alone. In a 800kLOC application of extremely questionable code quality. For bonus challenges, there is no testing environment available and no budget to stand one up- even if anyone knew exactly what actually needs to be in that environment, because there's a bunch of databases and packages and extra software and no one is entirely sure what the production environment is.
Erik started by opening the first file he saw and giving it a skim. It was a small one, with only about two hundred lines in it. The first line was:
$ENV{DOCUMENT_ROOT} = $ENV{DOCUMENT_ROOT};
That wasn't an auspicious start, but Perl is a finicky beast. "Maybe," Erik thought, "this was a workaround for an interpreter bug, or a line that once made sense but no longer does after refactoring."
Things went downhill quickly, though.
$pwd = $1000001 + int rand(1 + 1999999 - 1000001);
What is this? Is $pwd a password? Not based on how it's used in the rest of the code. What is the variable $1000001 (this is Perl, we know it's a scalar variable because it starts with a $)? Is it even defined? Or was it a typo and that $ shouldn't be there?
What was true was that it wasn't a security hole, so Erik didn't touch the line and kept moving on.
As he scrolled, he hit a point where the syntax highlighter just gave up and started spamming out nonsense. It wasn't hard to track it back to this line:
$html .= "Click below for" more information.
";
A spurious quote in the middle of the string. Based on the revision history, that change was added three years earlier. So this script had been broken and failing due to syntax errors for three years- but it still kept getting invoked. Fortunately, the interpreter kept failing to compile it, so it never did anything.
Erik marked the file as "free from security vulnerabilities" based on "it doesn't do anything", and moved onto the next file. 200 lines down, only 799,800 more to go.
|
Метки: CodeSOD |
CodeSOD: Throw it $$OUT |
If there's one thing worse in code than magic numbers, it's magic strings. Sean inherited an antique Visual C++ application, and the previous developers were very careful to make sure every string was a named constant.
const char $$B[] = "$$B";
const char $$E[] = "$$E";
const char $$L[] = "$$L";
const char $$IN[] = "$$IN";
const char $$OUT[] = "$$OUT";
const char $CODE[] = "$CODE";
const char $ENDE[] = "$ENDE";
There, isn't that much clearer? You don't have to worry what a cryptic string like "$$B" means in the program, you can now use a helpful constant, $$B.
Now, if these strings were used in the output somehow, like columns is a CSV file or maybe some sort of Domain Specific Language, this might make sense. That doesn't appear to be the case, however, and Sean is actually unclear precisely what these are actually used for, even if they do get referenced in code a fair bit.
|
Метки: CodeSOD |
CodeSOD: Unification of Strings |
As a general rule of thumb, when you see a class called StringConverter you know something is going to be wrong in there. That's at least what Erik thought when examining a bug in a totally different section of string handling code that just happened to depend on StringConverter.
StringConverter might sound like some sort of utility belt class with a huge pile of methods in it, but no- it's only got two. So we should take a look at both.
Let's start with the method called Escape.
public static string Escape(string s)
{
if (string.IsNullOrEmpty(s))
return s;
StringBuilder sb = new StringBuilder(s);
sb.Replace(""A", "Ae");
sb.Replace(""O", "Oe");
sb.Replace(""U", "Ue");
sb.Replace(""a", "ae");
sb.Replace(""o", "oe");
sb.Replace(""u", "ue");
sb.Replace("ss", "ss");
return sb.ToString();
}
This isn't terrible. If the input is a null, we return that null, otherwise we convert some extended characters into their equivalents. I'm not sure "escape" is exactly the right name for this, but there's nothing absolutely wrong here. So let's instead turn our attention to UnifyString.
First, I'd like you to take a moment and ask yourself: what should a method called UnifyString do? What's the purpose of a method with that name?
Compare what you expect with this implementation:
public static string UnifyString(string aInputString, int aMaxLength, bool aEscape = true)
{
string result = "";
if(aEscape)
result = Escape(aInputString);
if (aInputString != null && aInputString.Length > aMaxLength)
result = aInputString.Substring(0, aMaxLength);
return result;
}
Before we even get into the code, we have to comment on the use of Hungarian notation, which helps us distinguish which variables are arguments versus variables. I don't like it, but it's at least better than encoding types in the prefix, but we've looked at two methods thus far and already we don't agree as to whether or not this is an important standard.
But UnifyString is a substring tool, which should have been immediately clear from name alone, and why would you expect anything different? Were you expecting a join method or something? It's a substring that sometimes escapes characters! And, also, most important, it doesn't actually work as intended.
If aEscape is true (which is both its default value, and also the only way in which this method is ever called), all the extended characters are replaced with equivalents and stored in result. Then, if aInputString is not null and longer than a maximum length, we substring it and store that in result- right over top the escaped characters.
So the way this method works: if the input string is shorter than maxlength, we return that string with the extended characters replaced (possibly increasing its length beyond max length in the process), or we return an unescaped version of the string no longer than maxlength.
Erik writes:
The codebase is full of stuff like this, especially ill-named and illogical stuff. I already came close to sending in code several times, but this high-density bug-fest (which is solely running on pure luck and ignorance) pushed me over the edge.
|
Метки: CodeSOD |
Special Validation |
.jpg)
Ah, routers. The one piece of networking hardware that seems inescapable; even the most tech-illiterate among us needs to interface with their router at least once, to set up their home network so they can access the internet. Router technology has changed a lot over the years, including how you interface with the admin portal: instead of having to navigate to a specific IP address, some of them have you navigate to a URL that is intercepted by the router and redirected to the admin interface, making it easier for laymen to recall. But routers have their share of odd problems. I recently had to buy a new one because the one I was using was incompatible with my company's VPN for cryptic reasons even helpdesk had no real understanding of.
Today's submission concerns a Vodafone router. Our submitter was setting up a network for a friend, and to make things easier, they set up a low-security password initially so they could type it repeatedly without worrying about messing it up. Once the network was set up, however, they wanted to change it to something long and cryptic to prevent against brute-force attacks. They generated a password like 6Y9^}Ky.SK50ZR84.p,5u$380(G;m;bI%NZG%zHd?lOStqRzS}Z?t;8qSg;[gy@ and plugged it in, only to be told it was a "weak" password.
What? Length and variance both seem quite sufficient for the task—after all, it's not like there's roving bands of street gangs hacking into everyone's wifi routers and mucking about with the settings. There's no need for 300-character passwords.
Curious, our submitter opened the Javascript source for the change password page to see what checks they failed, since the UI wasn't helping much:
function CheckPasswordStrength(password) {
var password_strength = document.getElementById("password_strength");
var flag = 0;
var len = password.length;
var arr = [];
var sum = 0;
var cnt = 0;
//TextBox left blank.
if (password.length == 0) {
password_strength.innerHTML = "";
}
var passwordComplexity = $.validator.methods.passwordAtleast.call();
var passwordLength = $.validator.methods.passwordLength.call(); //rule a
var passwordAuhtorizedCharacter = $.validator.methods.PasswordAuhtorizedCharacter.call();
for (var i=0; i < len; i++) {
if ((password.split(password[i]).length-1) > 1)
cnt++;
if (i == 0)
arr.push({pasChar:password[0],val:4});
else if (i < 8)
arr.push({pasChar:password[i],val:2});
else if (i < 21)
arr.push({pasChar:password[i],val:1.5});
else if (i > 20)
arr.push({pasChar:password[i],val:1});
}
if (passwordComplexity == true && len > 8) {
arr.push({pasChar:password[i],val:6});
}
for (var i=0; iif ((sum < 18) || (passwordAuhtorizedCharacter == false) || (cnt >= (len/2)))
flag = 1;
else if ((sum >= 18) && (sum <= 30))
flag = 2;
else if (sum > 30)
flag = 3;
//Display status.
var strength = "";
var appliedClass = "";
switch (flag) {
case 0:
case 1:
strength = translator.getTranslate("PAGE_DEVICE_PASSWORD_POPUP_PASSWORD_STRENGTH_WEAK");
$(".weak").show();
$(".good").hide();
$(".strong").hide();
appliedClass = "passwordWeak";
break;
case 2:
strength = translator.getTranslate("PAGE_DEVICE_PASSWORD_POPUP_PASSWORD_STRENGTH_STRONG");
$(".good").show();
$(".weak").hide();
$(".strong").hide();
appliedClass = "passwordGood";
break;
case 3:
strength = translator.getTranslate("PAGE_DEVICE_PASSWORD_POPUP_PASSWORD_STRENGTH_VERY_STRONG");
$(".strong").show();
$(".weak").hide();
$(".good").hide();
appliedClass = "passwordStrong";
break;
}
password_strength.innerHTML = strength;
$("#password_level").removeClass("passwordWeak passwordGood passwordStrong");
$("#password_level").addClass(appliedClass);
}```So this code is combining the input, output, and algorithm all in one place: easy to write, easy to read. Each character in the password adds a given weight to the total, with earlier characters having a heavier weight than later ones. The sum of the weights is transformed into a classification flag: 1 is bad (does not pass the UI), 2 is okay-ish and 3 (meaning a sum of 20 or higher) is great.
The password our submitter entered has a weight of over 80, so it ought to pass—and yet, it does not. (cnt >= (len/2)) is the condition that's failing. cnt is incremented every time it sees a character more than once in a password, meaning if there's too many repeated characters, the password will fail. This is probably meant to stop passwords like aaaaaaaaaaaaaaaaaaaa from passing muster just based on length alone. And yet, given that the only valid characters are the Latin alphabet, Arabic numerals, and some few special characters, the chance to randomly hit the same character more than once goes up dramatically the longer the password is. So the longer your password is, the more likely it fails this check.
The submitter looked at the code and considered setting cnt to 1 in the debugger just to pass the check. The temptation was strong, but ultimately, they just cut the password in half and submitted it that way. After all, we're not yet in a post-apocalyptic cyberpunk universe where the aforementioned street gangs are looking to pick off easy targets. It's probably fine.
Probably.
|
Метки: Feature Articles |
Error'd: Oneth things frist |
... or maybe oneth things snecod, as it turns out. This week, two unique anonymeese have brought something to share, and our alien friend Skippy piles on to the Lenovo laugh-in. Guten Morgen!
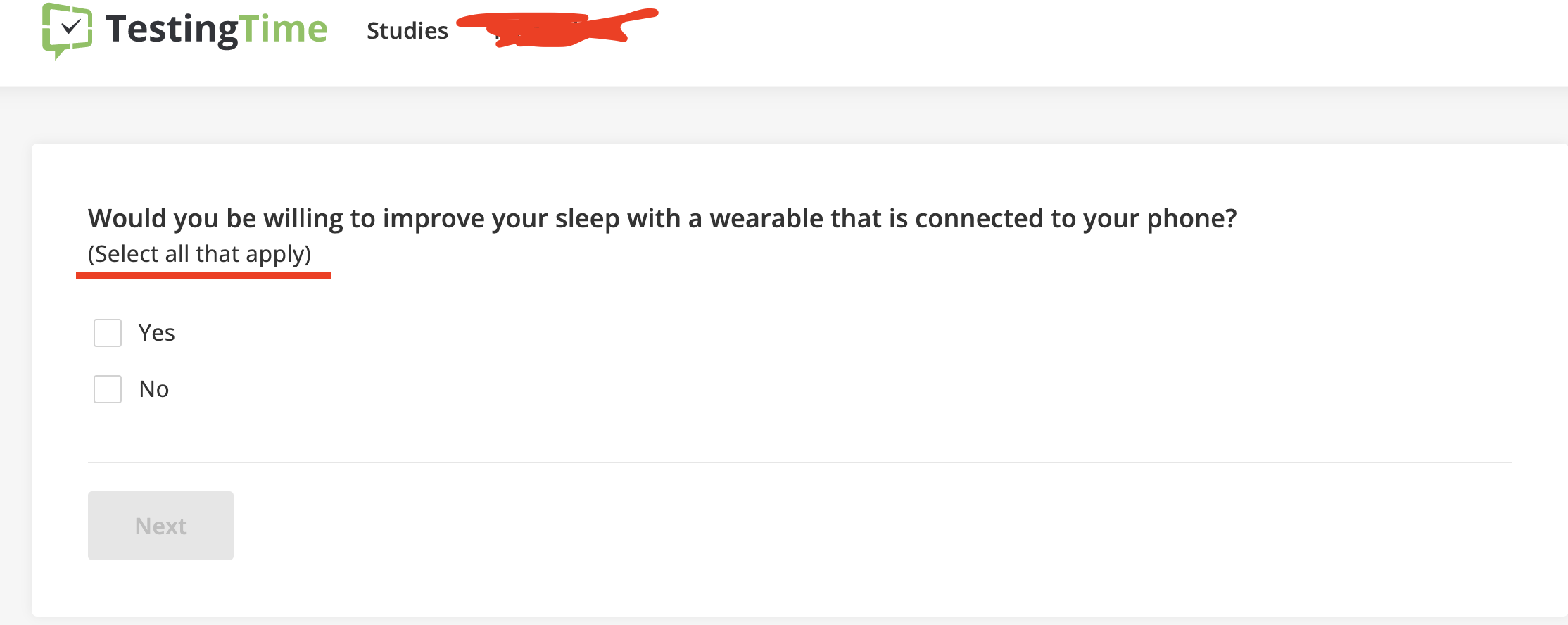
Decisive Michael R. is flummoxed by the law of the excluded middle. "YES," he assures us, "yes, those were checkboxes. And, no, not radios."
Elementary Counting Instructor Willy found an NHS formula that doesn't add up. Says Willy: "Got to get my son vaccinated, I think he's free on the 1th October." There's a joke in here about queues but I'm too tired to make it, maybe one of the peanut gallery can lend a hand?
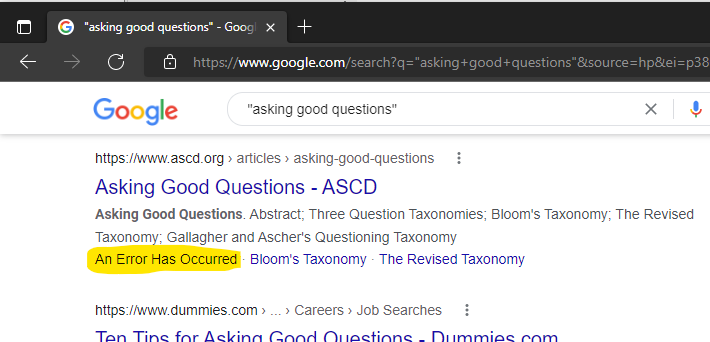
The first of our mouse members, styled Anon M. points out a simple truth: "Asking good questions doesn't guarantee good answers."
And the second anonymous styles nothing but sagely observes "I think the owner of this site is also unclear on what Operational Excellence means."
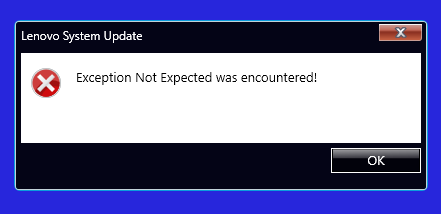
Winding up this week's set as promised, thanks go to the Austrian Kangaroo for yeeting this scrap on the schnitzelbank. "Today I came to the office and saw that my machine had to do an update. Before the update was started by some magic and unexpectedly restarts my system in the middle of me working on something, I started it by myself. As expected, it let me know that after the installation it would restart the system. So I was surprised when, after some time the attached error showed up. In the end, I could just continue with everything I did before without rebooting as the update just did not work, I just had to start all the applications I was working with again... What a nice Friday!"
|
Метки: Error'd |