[�� ���������] ������� WebScraping �� R ����� API hh.ru |
�� ��� ����� ������������� ��� �������: c������ ������ � ���������� ����� �� �����. �� ���� ������, �� ������, ��� ������ ��� � ������ � ��� hh.ru.
����� ����� ������: "� ��� �� ���������� ����� ����������?", ���� �� ����� ������� 5 ���. ������ � 100.000 ��������.
����� ����������, ������ �������� ��� �������� �������� � �������, � ������ � ��������� ������ "data science" � ������������. ����� ���� �� ������������� ������� �������� ������ �������� � ������? ����� ������, ����� ������������ ��������� � ������ ������. ��� ����� ������ ������������ ������ GoogleTrends.
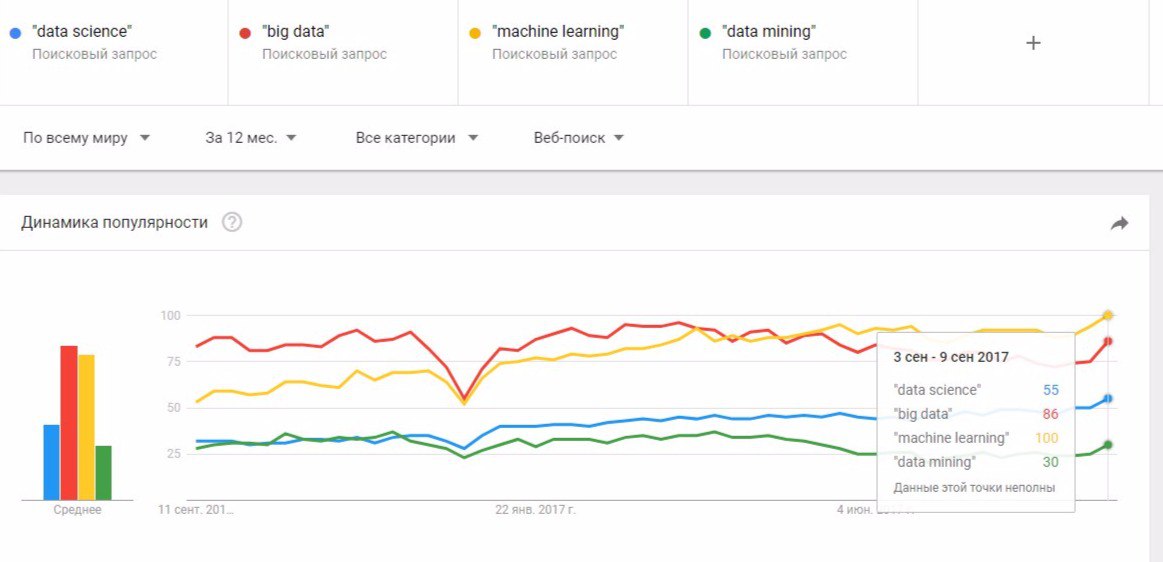
������ �����, ��� �������� ����� ������ �� ������� "machine learning". ������, ��� ������������� ���.
������� ������� ��������. �� �������� ����, ����� 411. API hh.ru ������������ ����� �� ���������, ������� ������ ���������� �����������. ������������, ��� ���������� �������� � JSON. ��� ���� ���� � ����������� ����� jsonlite � ��� ����� fromJSON() ����������� �� ���� URL � ������������ ����������� ��������� ������.
data <- fromJSON(paste0("https://api.hh.ru/vacancies?text=\"machine+learning\"&page=", pageNum) # ����� pageNum - ����� ��������. �� �������� ������������ 20 ��������.# Scrap vacancies
vacanciesdf <- data.frame(
Name = character(), # �������� ��������
Currency = character(), # ������
From = character(), # ����������� ������
Area = character(), # �����
Requerement = character(), stringsAsFactors = T) # ��������� ������
for (pageNum in 0:20) { # ����� �������
data <- fromJSON(paste0("https://api.hh.ru/vacancies?text=\"machine+learning\"&page=", pageNum))
vacanciesdf <- rbind(vacanciesdf, data.frame(
data$items$area$name, # �����
data$items$salary$currency, # ������
data$items$salary$from, # ����������� ������
data$items$employer$name, # �������� ��������
data$items$snippet$requirement)) # ��������� ������
print(paste0("Upload pages:", pageNum + 1))
Sys.sleep(3)
}������� ��� ������ � DataFrame, ������� ������� ��� ��������. ��������� ��� �������� � ����� � ��������� �� ������� Currency, ��� �� ������� NA �������� � Salary �� �������.
# ������� ��������� �������� ��������
names(vacanciesdf) <- c("Area", "Currency", "Salary", "Name", "Skills")
# ������ �������� NA ����� �������
vacanciesdf[is.na(vacanciesdf$Salary),]$Salary <- 0
# ��������� �������� � �����
vacanciesdf[!is.na(vacanciesdf$Currency) & vacanciesdf$Currency == 'USD',]$Salary <- vacanciesdf[!is.na(vacanciesdf$Currency) & vacanciesdf$Currency == 'USD',]$Salary * 57
vacanciesdf[!is.na(vacanciesdf$Currency) & vacanciesdf$Currency == 'UAH',]$Salary <- vacanciesdf[!is.na(vacanciesdf$Currency) & vacanciesdf$Currency == 'UAH',]$Salary * 2.2
vacanciesdf <- vacanciesdf[, -2] # Currency ��� ������ �� �����
vacanciesdf$Area <- as.character(vacanciesdf$Area)����� ����� ����� DataFrame ����:

��������� �������, ��������� ������� �������� � ������� � ����� � ��� ������� ��������.
vacanciesdf %>% group_by(Area) %>% filter(Salary != 0) %>%
summarise(Count = n(), Median = median(Salary), Mean = mean(Salary)) %>%
arrange(desc(Count))
��� scraping`a � R ������ ������������ ����� rvest, ������� ��� �������� ������ read_html() � html_nodes(). ������ ��������� ��������� �������� �� ���������, � ������ ���������� � ��������� �������� � ������� xPath � CSS-���������. API �� ������������ ����������� ������ �� ������, �� ���� ����������� �������� ���������� � ��� �� id. ����� ��������� ��� id, � ����� ��� ����� API �������� ������ �� ������. ����� ������ �� ����� �� ������� ������� � 1049.
hhResumeSearchURL <- 'https://hh.ru/search/resume?exp_period=all_time&order_by=relevance&text=machine+learning&pos=full_text&logic=phrase&clusters=true&page=';
# �������� ��������� �������� � ������� pageNum
hDoc <- read_html(paste0(hhResumeSearchURL, as.character(pageNum)))
# ������� ��� ��������� ������ �� ��������
ids <- html_nodes(hDoc, css = 'a') %>% as.character()
# ������� �� ������ ����������� id ( ������������������ ���� � ���� ����� 38 )
ids <- as.vector(ids) %>% `[`(str_detect(ids, fixed('/resume/'))) %>%
str_extract(pattern = '/resume/.{38}') %>% str_sub(str_count('/resume/') + 1)
ids <- ids[4:length(ids)] # � ������ 3� ���������� ����� ��� ��������� ��� ������� fromJSON ������� ����������, ������������ � ������.
resumes <- fromJSON(paste0("https://api.hh.ru/resumes/", id))hhResumeSearchURL <- 'https://hh.ru/search/resume?exp_period=all_time&order_by=relevance&text=machine+learning&pos=full_text&logic=phrase&clusters=true&page=';
for (pageNum in 0:51) { # ����� 51 ��������
#������� id ������
hDoc <- read_html(paste0(hhResumeSearchURL, as.character(pageNum)))
ids <- html_nodes(hDoc, css = 'a') %>% as.character()
# ������� ��� ��������� ������ �� ��������
ids <- as.vector(ids) %>% `[`(str_detect(ids, fixed('/resume/'))) %>%
str_extract(pattern = '/resume/.{38}') %>% str_sub(str_count('/resume/') + 1)
ids <- ids[4:length(ids)] # � ������ 3� �����
Sys.sleep(1) # �������� �� ������ ������
for (id in ids) {
resumes <- fromJSON(paste0("https://api.hh.ru/resumes/", id))
skills <- if (is.null(resumes$skill_set)) "" else resumes$skill_set
buffer <- data.frame(
Age = if(is.null(resumes$age)) 0 else resumes$age, # �������
if (is.null(resumes$area$name)) "NoCity" else resumes$area$name,# �����
if (is.null(resumes$gender$id)) "NoGender" else resumes$gender$id, # ���
if (is.null(resumes$salary$amount)) 0 else resumes$salary$amount, # ��������
if (is.null(resumes$salary$currency)) "NA" else resumes$salary$currency, # ������
# ������ ������� ����� ������� ����� ,
str_c(if (!length(skills)) "" else skills, collapse = ","))
write.table(buffer, 'resumes.csv', append = T, fileEncoding = "UTF-8",col.names = F)
Sys.sleep(1) # �������� �� ������ ������
}
print(paste("������ �������:", pageNum))
}����� �������� ������������ DataFrame, ����������� ������ � ����� � ������ NA �� ��������.

SkillNameDF <- data.frame(SkillName = str_split(str_c(
resumes$Skills, collapse = ','), ','), stringsAsFactors = F)
names(SkillNameDF) <- 'SkillName'
mostSkills <- head(SkillNameDF %>% group_by(SkillName) %>%
summarise(Count = n()) %>% arrange(desc(Count)), 15 )
resumes %>% group_by(Gender) %>% filter(Salary != 0) %>%
summarise(Count = n(), Median = median(Salary), Mean = mean(Salary)
resumes %>% filter(Age!=0) %>% group_by(Age) %>%
summarise(Count = n()) %>% arrange(desc(Count))
| �������������� | « ����. ������ — � �������� — ����. ������ » | ��������: [1] [�����] |






