������ ����� ������ ���� ������������
���.
��� ������ � ������������� Excel ����� ��� ������ openpyxl
��� ���������� ����������, ���� �� ������ ������ � ������������� ����� .xlsx, xlsm, xltx � xltm.
���������� openpyxl using pip.
����� ������������ �� ��������� ���� ���������� � ������� ��� � ����������� ����� Python ��� ��������� ���������. �� ������ ������������ ����������� ����� ��� �������� ������������� ���� Python: ��� ������� �����, ���������� ��� ����������� �����, ��� ������������� ���������, ������� ����������� ��� Python.
��������� � ����������, � ������� ��������� ��� ������, � �������� ����������� ����������� ����� venv. ����� ��������� � ��������� openpyxl � ������� pip, ����� ���������, ��� �� ������ ������ � ���������� � ��� �����:
# Activate virtualenv
$ source activate venv
# Install `openpyxl` in `venv`
$ pip install openpyxl
������, ����� �� ���������� openpyxl, �� ������ ������ �������� ������.
�� ��� ������ ��� �� ������? ��������, � ����� � �������, ������� �� ��������� �������� �� Python, ���� ��������� �����:

������� load_workbook () ��������� ��� ����� � �������� ��������� � ���������� ������ ������� �����, ������� ������������ ����. ��� ����� ��������� �������� type (wb). �� �������� ���������, ��� �� ���������� � ���������� ����������, ��� ����������� ����������� �������. � ��������� ������ �� �������� ��������� �� ������ ��� �������.
# Import `load_workbook` module from `openpyxl`
from openpyxl import load_workbook
# Load in the workbook
wb = load_workbook('./test.xlsx')
# Get sheet names
print(wb.get_sheet_names())
�������, �� ������ �������� ������� ������� � ������� os.chdir (). �������� ���� ���� ���������� ����� ������ �����, ����������� � Python. �� ������ ������������ ��� ���������� ��� ��������� ��������� ������ �����. ����� �� ������ ���������, ����� ���� ������� � ��������� ������ � ������� wb.active. � ����������� ���� ����, �� ����� ������ ������������ ��� ��� �������� ������ �� ������ ����� �����:
# Get a sheet by name
sheet = wb.get_sheet_by_name('Sheet3')
# Print the sheet title
sheet.title
# Get currently active sheet
anotherSheet = wb.active
# Check `anotherSheet`
anotherSheet
�� ������ ������, � ����� ��������� Worksheet ���� ��� ����� �������. ������, ����� ��������� �������� �� ������������ ����� �� ����� �����, ��������� ���������� ������ [], � ������� ����� ���������� ������ ������, �� ������� �� ������ �������� ��������.
�������� ��������, ��� ������ �� �����, ��������� � �������������� �������� NumPy � Pandas DataFrames, �� ��� ��� �� ���, ��� ����� �������, ����� �������� ��������. ����� ��� �������� �������� ��������:
# Retrieve the value of a certain cell
sheet['A1'].value
# Select element 'B2' of your sheet
c = sheet['B2']
# Retrieve the row number of your element
c.row
# Retrieve the column letter of your element
c.column
# Retrieve the coordinates of the cell
c.coordinate
������ value, ���� � ������ ��������, ������� ����� ������������ ��� �������� ������, � ������ row, column � coordinate:
������� row ������ 2;
���������� �������� column � �є ���� ��� �B�;
coordinate ������ �B2�.
�� ����� ������ �������� �������� ����� � ������� ������� cell (). ��������� ��������� row � column, �������� �������� � ���� ����������, ������� ������������� ��������� ������, ������� �� ������ ��������, �, ������� ��, �� �������� �������� ������� value:
# Retrieve cell value
sheet.cell(row=1, column=2).value
# Print out values in column 2
for i in range(1, 4):
print(i, sheet.cell(row=i, column=2).value)
�������� ��������: ���� �� �� ������� �������� �������� value, �� ��������
, ������� ������ �� ������� � ��������, ������� ���������� � ���� ���������� ������.
�� ����������� ���� � ������� ������� range (), ����� ������ ��� ������� �������� �����, ������� ����� �������� � ������� 2. ���� ��� ���������� ������ �����, �� �������� None.
����� ����, ���������� ����������� �������, ������� �� ������ �������, ����� �������� ������ ��������, �������� get_column_letter () � column_index_from_string.
� ���� �������� ��� ����� ��� ����� �������, ��� �� ������ ��������, ��������� ��. �� ����� ����� ������� �� ������: ���� �� ������ �������� ����� �������� �������, ����� ������� �������� ��� �������� ������ �������, ��������� ����� �� ������. ��� ��� ��������:
# Import relevant modules from `openpyxl.utils`
from openpyxl.utils import get_column_letter, column_index_from_string
# Return 'A'
get_column_letter(1)
# Return '1'
column_index_from_string('A')
�� ��� �������� �������� ��� �����, ������� ����� �������� � ������������ �������, �� ��� ����� �������, ���� ����� ������� ������ �����, �� ���������������� ������ �� ����� �������?
�������, ������������ ������ ����.
��������, �� ������ ��������������� �� �������, ����������� ����� �A1� � �C3�, ��� ������ ��������� ����� ������� ����, � ������ � ������ ������ ���� �������, �� ������� �� ������ ���������������. ��� ������� ����� ��� ���������� cellObj, ������� �� ������ � ������ ������ ���� ����. ����� �� ����������, ��� ��� ������ ������, ������� ��������� � ���� �������, �� ������ ������� ���������� � ��������, ������� ���������� � ���� ������. ����� ��������� ������ ������ �� ������ �������� ���������-������ � ���, ��� ������ ���� ������� cellObj ���� ��������.
# Print row per row
for cellObj in sheet['A1':'C3']:
for cell in cellObj:
print(cells.coordinate, cells.value)
print('--- END ---')
�������� ��������, ��� ����� ������� ����� ����� �� �����, ��������� � �������������� ������ � �������� NumPy, ��� �� ����� ����������� ���������� ������ � ��������� ����� ������� �������, �� ������� �� ������ �������� ��������. ����� ����, ��������������� ���� ����� ������ ���������� �������� ������!
����� ��������������� ��������� ����, ��������, �� �������� ��������� ���������, ������� ������ ��� ����������� ����:
('A1', u'M')
('B1', u'N')
('C1', u'O')
� END � ('A2', 10L)
('B2', 11L)
('C2', 12L)
� END � ('A3', 14L)
('B3', 15L)
('C3', 16L)
� END ---
�������, ���� ��������� ��������, ������� �� ������ ������������ ��� �������� ���������� �������, � ������ max_row � max_column. ��� ��������, �������, �������� ������ ��������� ����������� ���������� �������� ������, �� ��� �� ����� � ������ ������ ��� ����� � ����� �������.
# Retrieve the maximum amount of rows
sheet.max_row
# Retrieve the maximum amount of columns
sheet.max_column
��� ��� ����� �������, �� �� ����� ������, ��� �� ������ �������, ��� ��� ������ ������� ������ �������� � �������, �������� ���� ����� ��� � ��������� �������.
������ ���� ���-�� �����, �� ��� ��? �� ���!
Openpyxl ����� ��������� Pandas DataFrames. � ����� ������������ ������� DataFrame () �� ������ Pandas, ����� ��������� �������� ����� � DataFrame:
# Import `pandas`
import pandas as pd
# Convert Sheet to DataFrame
df = pd.DataFrame(sheet.values)
���� �� ������ ������� ��������� � �������, ��� ����� �������� ������� ������ ����:
# Put the sheet values in `data`
data = sheet.values
# Indicate the columns in the sheet values
cols = next(data)[1:]
# Convert your data to a list
data = list(data)
# Read in the data at index 0 for the indices
idx = [r[0] for r in data]
# Slice the data at index 1
data = (islice(r, 1, None) for r in data)
# Make your DataFrame
df = pd.DataFrame(data, index=idx, columns=cols)
����� �� ������ ������ ��������� ������� ��� ������ ���� �������, ������� ���� � Pandas. �� �������, ��� �� ���������� � ����������� �����, �������, ���� ���������� ��� �� ����������, ��� ����� ����� ���������� �� ����� ����� pip.
����� �������� Pandas DataFrames ������� � ���� Excel, ����� ������������ ������� dataframe_to_rows () �� ������ utils:
# Import `dataframe_to_rows`
from openpyxl.utils.dataframe import dataframe_to_rows
# Initialize a workbook
wb = Workbook()
# Get the worksheet in the active workbook
ws = wb.active
# Append the rows of the DataFrame to your worksheet
for r in dataframe_to_rows(df, index=True, header=True):
ws.append�
�� ��� ����������� �� ���! ���������� openpyxl ���������� ��� ������� �������� � ��������� ����, ��� �� ����������� ���� ������ � ����� Excel, ��������� ����� ����� ��� ����������� ����� ������ ��� ������. ��� ������ �� ����� �� ��� ���������, ������� ��� ����� ���������� �����, ���� �� ����� ��������� � ������������ ���������.
� �� �������� �������������� ����������� �����, ����� ��������� ������ � �������!
������ ������� ���������� ��������� ������ ����������, ������� �� ������ ������������ ��� ��������� ������ � ����������� ������� �� Python.
������ ������ ������?
������ � �������������� Excel ������ xlrd
��� ���������� ��������, ���� �� ������ ������ ������ � ������������� ������ � ������ � ����������� .xls ��� .xlsx.
# Import `xlrd`
import xlrd
# Open a workbook
workbook = xlrd.open_workbook('example.xls')
# Loads only current sheets to memory
workbook = xlrd.open_workbook('example.xls', on_demand = True)
���� �� �� ������ ������������� ��� �����, ����� ������������ ����� �������, ��� sheet_by_name () ��� sheet_by_index (), ����� ��������� �����, ������� ���������� ������������ � �������.
# Load a specific sheet by name
worksheet = workbook.sheet_by_name('Sheet1')
# Load a specific sheet by index
worksheet = workbook.sheet_by_index(0)
# Retrieve the value from cell at indices (0,0)
sheet.cell(0, 0).value
�������, ����� �������� �������� �� ������������ �����������, ������������ ���������.
� ���, ��� xlwt � xlutils, ����������� � xlrd ��������� ������.
������ ������ � Excel ���� ��� ������ xlrd
���� ����� ������� ����������� �������, � ������� ���� ������, ����� ���������� XlsxWriter ����� ������������ ���������� xlwt. Xlwt �������� �������� ��� ������ � �������������� ������ � ����� � ����������� .xls.
����� �� ������� ������ �������� � ����, ��� ����� ��������� ���:
# Import `xlwt`
import xlwt
# Initialize a workbook
book = xlwt.Workbook(encoding=�utf-8�)
# Add a sheet to the workbook
sheet1 = book.add_sheet(�Python Sheet 1�)
# Write to the sheet of the workbook
sheet1.write(0, 0, �This is the First Cell of the First Sheet�)
# Save the workbook
book.save(�spreadsheet.xls�)
���� ����� �������� ������ � ����, �� ��� ����������� ������� ����� ����� ���������� � ����� for. ��� �������� ������� ���������������� �������. ������ ������, � ������� ��������� �����, � ������� ����������� ����. ����� ��������� ������ �� ��������� � �� ����������, ������� ����� ���������� �� ������� ����.
���� for ����� ������� �� ���, ����� ��� �������� �������� � ����: ������, ��� � ������ ��������� � ��������� �� 0 �� 4 (5 �� ��������) �� ���������� ����������� ��������. ����� ��������� �������� ������ �� �������. ��� ����� ��������� row �������, ������� ����� ��������� � ������ �����. � ����� � ��� ��������� for ����, ������� ��������� �� �������� �����. ������ �������, ��� ��� ������ ������ �� ����� ������� �� ������� � ��������� �������� ��� ������� ������� � ������. ����� ��������� ��� ������� ������ ����������, ��������� � ��������� ������, ���� �� �������� ��� ��������� ������.
# Initialize a workbook
book = xlwt.Workbook()
# Add a sheet to the workbook
sheet1 = book.add_sheet(�Sheet1�)
# The data
cols = [�A�, �B�, �C�, �D�, �E�]
txt = [0,1,2,3,4]
# Loop over the rows and columns and fill in the values
for num in range(5):
row = sheet1.row(num)
for index, col in enumerate(cols):
value = txt[index] + num
row.write(index, value)
# Save the result
book.save(�test.xls�)
� �������� ������� �������� ��������������� �����:
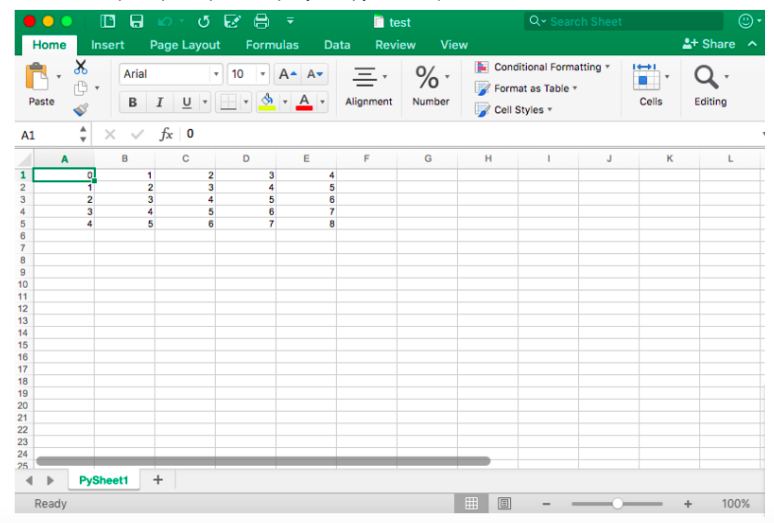
������, ����� �� ������, ��� xlrd � xlwt ��������������� ������, ������ ����� ���������� �� ����������, ������� ����� ������� � ����� �����: xlutils.
��������� ������ xlutils
��� ���������� � �������� ������������ ����� ����� ������, ��� ������� ��������� ��� xlrd, ��� � xlwt. �������� � ���� ����������� ���������� � ��������/����������� ������������ �����. ������ ������, ��� ���� ������ ��������� ������ ��� openpyxl.
������������� pyexcel ��� ������ ������ .xls ��� .xlsx
��� ���� ����������, ������� ����� ������������ ��� ������ ������ ������ � Python � pyexcel. ��� Python Wrapper, ������� ������������� ���� API ��� ������, ��������� � ������ ������ � ������ .csv, .ods, .xls, .xlsx � .xlsm.
����� �������� ������ � �������, ����� ������������ ������� get_array (), ������� ���������� � ������ pyexcel:
# Import `pyexcel`
import pyexcel
# Get an array from the data
my_array = pyexcel.get_array(file_name=�test.xls�)
����� ����� �������� ������ � ������������� ������� �������, ��������� ������� get_dict ():
# Import `OrderedDict` module
from pyexcel._compact import OrderedDict
# Get your data in an ordered dictionary of lists
my_dict = pyexcel.get_dict(file_name=�test.xls�, name_columns_by_row=0)
# Get your data in a dictionary of 2D arrays
book_dict = pyexcel.get_book_dict(file_name=�test.xls�)
������, ���� �� ������ ������� � ������� ��������� ������� ���, ����� �������, �������� ��� ����� ����� � ����� �������, ����� ������������ ������� get_book_dict ().
������ � ����, ��� ��� ���������� ��������� ������, ������� � ������� ����� ����������� �������, ��������� ��������� DataFrames ����� ������ � ������� pd.DataFrame (). ��� �������� ��������� ����� ������!
�������, �� ������ ������ �������� ������ � pyexcel ��������� ������� get_records (). ������ ��������� �������� file_name ������� � ������� �������� ������ ��������:
# Retrieve the records of the file
records = pyexcel.get_records(file_name=�test.xls�)
������ ������ ��� ������ pyexcel
��� ��, ��� ��������� ������ � ������� � ������� ����� ������, ����� ����� ����� �������������� ������� ������� � ����������� �������. ��� ����� ������������ ������� save_as () � ��������� ������� � ����� �������� ����� � �������� dest_file_name:
# Get the data
data = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
# Save the array to a file
pyexcel.save_as(array=data, dest_file_name=�array_data.xls�)
�������� ��������: ���� ������� �����������, �� ����� �������� �������� dest_delimiter � �������� ������, ������� ������ ������������, � �������� ����������� ����� ��.
������, ���� � ��� ���� �������, ����� ����� ������������ ������� save_book_as (). ��������� ��������� ������� � bookdict � ������� ��� �����, � ��� ��:
# The data
2d_array_dictionary = {'Sheet 1': [
['ID', 'AGE', 'SCORE']
[1, 22, 5],
[2, 15, 6],
[3, 28, 9]
],
'Sheet 2': [
['X', 'Y', 'Z'],
[1, 2, 3],
[4, 5, 6]
[7, 8, 9]
],
'Sheet 3': [
['M', 'N', 'O', 'P'],
[10, 11, 12, 13],
[14, 15, 16, 17]
[18, 19, 20, 21]
]}
# Save the data to a file
pyexcel.save_book_as(bookdict=2d_array_dictionary, dest_file_name=�2d_array_data.xls�)
�������, ��� ����� ����������� ���, ������� ��������� � ��������� ���� ����, ������� ������ � ������� �� ����� ��������!
������ � ������ .csv ������
���� �� ��� ��� ����� ����������, ������� ��������� ��������� � ���������� ������ � CSV-�����, ����� Pandas, ����������� ���������� csv:
# import `csv`
import csv
# Read in csv file
for row in csv.reader(open('data.csv'), delimiter=','):
print(row)
# Write csv file
data = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
outfile = open('data.csv', 'w')
writer = csv.writer(outfile, delimiter=';', quotechar='"')
writer.writerows(data)
outfile.close()
�������� ��������, ��� NumPy ����� ������� genfromtxt (), ������� ��������� ��������� ������, ������������ � CSV-������ � ��������, ������� ����� ����� �������� � DataFrames.
��������� �������� ������
����� ������ ������������, �� �������� ��������� ���: ��������� ������������ �������� ������. ���� �� ��������� ���� ������ � DataFrame, �� ������ ����� � ������ ���������, ��� �� ������ ��������, �������� ��������� �������:
# Check the first entries of the DataFrame
df1.head()
# Check the last entries of the DataFrame
df1.tail()
Note: ����������� DataCamp Pandas Cheat Sheet, ����� �� ���������� ��������� ����� � ���� Pandas DataFrames.
���� ������ � �������, �� ������ ��������� ���, ��������� ��������� �������� �������: shape, ndim, dtype � �.�.:
# Inspect the shape
data.shape
# Inspect the number of dimensions
data.ndim
# Inspect the data type
data.dtype
��� ������?
�����������, ������ �� ������, ��� ������ ����� Excel � Python :)
�� ������ ������ � ��� ������ ������ �������� �������� � ������� ������. ����� � ��� ���� ������ �� ����������� ������ � ����� �����, �� ������ ��������������� �� ���, ��� ������������� �����: �� ������� ������.
���� �� ������ ������ ����������� � ���� � ����������� � PyXll, ������� ��������� ���������� ������� � Python � �������� �� � Excel.
 | https://habrahabr.ru/post/331998/






