Joel Maher: backlogs, lag, and waiting |
Many times each week I see a ping on IRC or Slack asking “why are my jobs not starting on my try push?” I want to talk about why we have backlogs and some things to consider in regards to fixing the problem.
It a frustrating experience when you have code that you are working on or ready to land and some test jobs have been waiting for hours to run. I personally experienced this the last 2 weeks while trying to uplift some test only changes to esr68 and I would get results the next day. In fact many of us on our team joke that we work weekends and less during the week in order to get try results in a reasonable time.
It would be a good time to cover briefly what we run and where we run it, to understand some of the variables.
In general we run on 4 primary platforms:
In addition to the platforms, we often run tests in a variety of configs:
In some cases a single test can run >90 times for a given change when iterated through all the different platforms and configurations. Every week we are adding many new tests to the system and it seems that every month we are changing configurations somehow.
In total for January 1st to June 30th (first half of this year) Mozilla ran >25M test jobs. In order to do that, we need a lot of machines, here is what we have:
You will notice that OSX, some windows laptops, and android phones are a limited resource and we need to be careful for what we run on them and ensure our machines and devices are running at full capacity.
These limited resource machines are where we see jobs scheduled and not starting for a long time. We call this backlog, it could also be referred to as lag. While it would be great to point to a public graph showing our backlog, we don’t have great resources that are uniform between all machine types. Here is a view of what we have internally for the Android devices: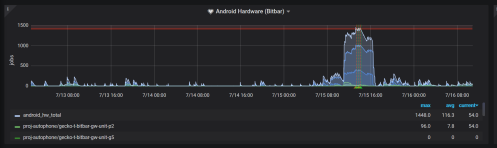
What typically happens when a developer pushes their code to a try server to run all the tests, many jobs finish in a reasonable amount of time, but jobs scheduled on resource constrained hardware (such as android phones) typically have a larger lag which then results in frustration.
How do we manage the load:
I would like to talk about how to reduce the number of jobs. This is really important when dealing with limited resources, but we shouldn’t ignore this on all platforms. The things to tweak are:
I find that for 1, we want to run everything everywhere if possible, this isn’t possible, so one of our tricks is to run things on mozilla-central (the branch we ship nightlies off of) and not on our integration branches. A side effect here is a regression isn’t seen for a longer period of time and finding a root cause can be more difficult. One recent fix was when PGO was enabled for android we were running both regular tests and PGO tests at the same time for all revisions- we only ship PGO and only need to test PGO, the jobs were cut in half with a simple fix.
Looking at 2, the frequency is something else. Many tests are for information or comparison only, not for tracking per commit. Running most tests once/day or even once/week will give a signal while our most diverse and effective tests are running more frequently.
The last option 3 is where all developers have a chance to spoil the fun for everyone else. One thing is different for try pushes, they are scheduled on the same test machines as our release and integration branches, except they are put in a separate queue to run which is priority 2. Basically if any new jobs get scheduled on an integration branch, the next available devices will pick those up and your try push will have to wait until all integration jobs for that device are finished. This keeps our trees open more frequently (if we have 50 commits with no tests run, we could be backing out changes from 12 hours ago which maybe was released or maybe has bitrot while performing the backout). One other aspect of this is we have >10K jobs one could possibly run while scheduling a try push and knowing what to run is hard. Many developers know what to run and some over schedule, either out of difficulty in job selection or being overly cautious.
Keeping all of this in mind, I often see many pushes to our try server scheduling what looks to be way too many jobs on hardware. Once someone does this, everybody else who wants to get their 3 jobs run have to wait in line behind the queue of jobs (many times 1000+) which often only get ran during night for North America.
I would encourage developers pushing to try to really question if they need all jobs, or just a sample of the possible jobs. With tools like |/.mach try fuzzy| , |./mach try chooser| , or |./mach try empty| it is easier to schedule what you need instead of blanket commands that run everything. I also encourage everyone to cancel old try pushes if a second try push has been performed to fix errors from the first try push- that alone saves a lot of unnecessary jobs from running.
https://elvis314.wordpress.com/2019/07/16/backlogs-lag-and-waiting/
| Комментировать | « Пред. запись — К дневнику — След. запись » | Страницы: [1] [Новые] |






