Chris H-C: This Week in Glean: Project FOG Update, end of H12020 |
(“This Week in Glean” is a series of blog posts that the Glean Team at Mozilla is using to try to communicate better about our work. They could be release notes, documentation, hopes, dreams, or whatever: so long as it is inspired by Glean. You can find an index of all TWiG posts online.)
It’s been a while since last I wrote on Project FOG, so I figure I should update all of you on the progress we’ve made.
A reminder: Project FOG (Firefox on Glean) is the year-long effort to bring the Glean SDK to Firefox. This means answering such varied questions as “Where are the docs going to live?” (here) “How do we update the SDK when we need to?” (this way) “How are tests gonna work?” (with difficulty) and so forth. In a project this long you can expect updates from time-to-time. So where are we?
First, we’ve added the Glean SDK to Firefox Desktop and include it in Firefox Nightly. This is only a partial integration, though, so the only builtin ping it sends is the “deletion-request” ping when the user opts out of data collection in the Preferences. We don’t actually collect any data, so the ping doesn’t do anything, but we’re sending it and soon we’ll have a test ensuring that we keep sending it. So that’s nice.
Second, we’ve written a lot of Design Proposals. The Glean Team and all the other teams our work impacts are widely distributed across a non-trivial fragment of the globe. To work together and not step on each others’ toes we have a culture of putting most things larger than a bugfix into Proposal Documents which we then pass around asynchronously for ideation, feedback, review, and signoff. For something the size and scope of adding a data collection library to Firefox Desktop, we’ve needed more than one. These design proposals are Google Docs for now, but will evolve to in-tree documentation (like this) as the proposals become code. This way the docs live with the code and hopefully remain up-to-date for our users (product developers, data engineers, data scientists, and other data consumers), and are made open to anyone in the community who’s interested in learning how it all works.
Third, we have a Glean SDK Rust API! Sorta. To limit scope creep we haven’t added the Rust API to mozilla/glean and are testing its suitability in FOG itself. This allows us to move a little faster by mixing our IPC implementation directly into the API, at the expense of needing to extract the common foundation later. But when we do extract it, it will be fully-formed and ready for consumers since it’ll already have been serving the demanding needs of FOG.
Fourth, we have tests. This was a bit of a struggle as the build order of Firefox means that any Rust code we write that touches Firefox internals can’t be tested in Rust tests (they must be tested by higher-level integration tests instead). By damming off the Firefox-adjacent pieces of the code we’ve been able to write and run Rust tests of the metrics API after all. Our code coverage is still a little low, but it’s better than it was.
Fifth, we are using Firefox’s own network stack to send pings. In a stroke of good fortune the application-services team (responsible for fan-favourite Firefox features “Sync”, “Send Tab”, and “Firefox Accounts”) was bringing a straightforward Rust networking API called Viaduct to Firefox Desktop almost exactly when we found ourselves in need of one. Plugging into Viaduct was a breeze, and now our “deletion-request” pings can correctly work their way through all the various proxies and protocols to get to Mozilla’s servers.
Sixth, we have firm designs on how to implement both the C++ and JS APIs in Firefox. They won’t be fully-fledged language bindings the way that Kotlin, Python, and Swift are (( they’ll be built atop the Rust language binding so they’re really more like shims )), but they need to have every metric type and every metric instance that a full language binding would have, so it’s no small amount of work.
But where does that leave our data consumers? For now, sadly, there’s little to report on both the input and output sides: We have no way for product engineers to collect data in Firefox Desktop (and no pings to send the data on), and we have no support in the pipeline for receiving data, not that we have any to analyse. These will be coming soon, and when they do we’ll start cautiously reaching out to potential first customers to see whether their needs can be satisfied by the pieces we’ve built so far.
And after that? Well, we need to do some validation work to ensure we’re doing things properly. We need to implement the designs we proposed. We need to establish how tasks accomplished in Telemetry can now be accomplished in the Glean SDK. We need to start building and shipping FOG and the Glean SDK beyond Nightly to Beta and Release. We need to implement the builtin Glean SDK pings. We need to document the designs so others can understand them, best practices so our users can follow them, APIs so engineers can use them, test guarantees so QA can validate them, and grand processes for migration from Telemetry to Glean so that organizations can start roadmapping their conversions.
In short: plenty has been done, and there’s still plenty to do.
I guess we’d better be about it, then.
:chutten
https://chuttenblog.wordpress.com/2020/06/12/this-week-in-glean-project-fog-update-end-of-h12020/
|
|
Daniel Stenberg: 800 authors and counting |
Today marks the day when we merged the commit authored by the 800th person in the curl project.
We turned 22 years ago this spring but it really wasn’t until 2010 when we switched to git when we started to properly keep track of every single author in the project. Since then we’ve seen a lot of new authors and a lot of new code.
The “explosion” is clearly visible in this graph generated with fresh data just this morning (while we were still just 799 authors). See how we’ve grown maybe 250 authors since 1 Jan 2018.
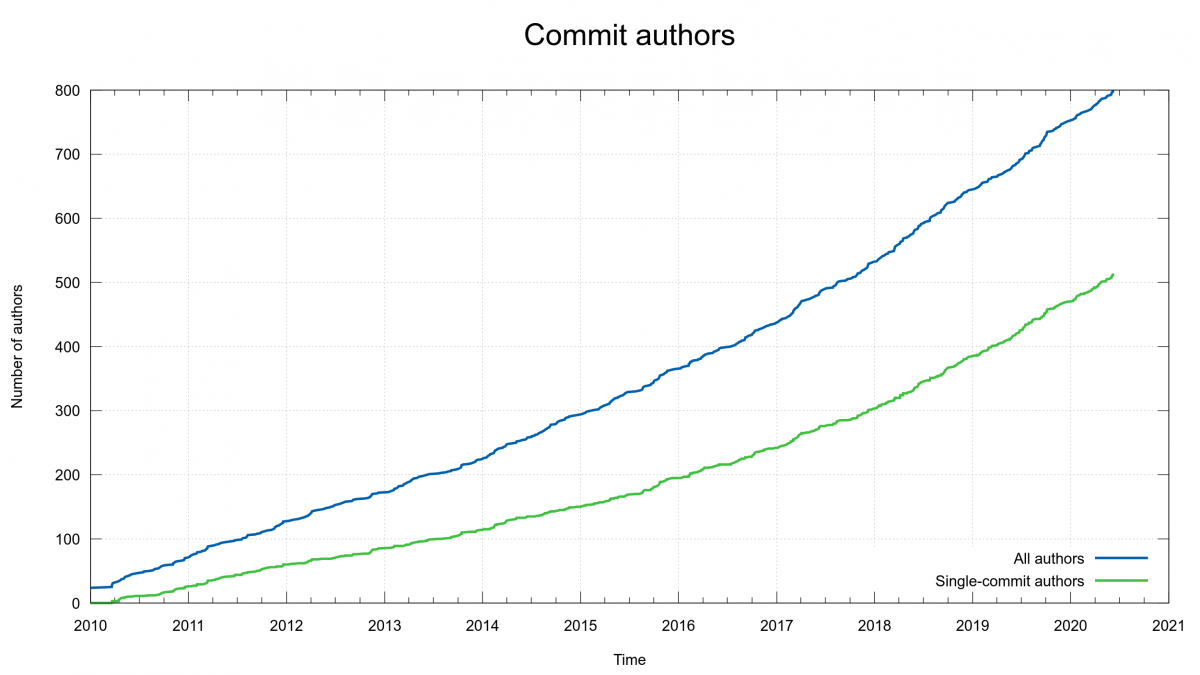
Author number 800 is named Nicolas Sterchele and he submitted an update of the TODO document. Appreciated!
As the graph above also shows, a majority of all authors only ever authored a single commit. If you did 10 commits in the curl project, you reach position #61 among all the committers while 100 commits takes you all the way up to position #13.
If you too want to become one of the cool authors of curl, I fine starting point for that journey could be the Help Us document. If that’s not enough, you’re also welcome to contact me privately or maybe join the IRC channel for some socializing and “group mentoring”.
If we keep this up, we could reach a 1,000 authors in 2022…
https://daniel.haxx.se/blog/2020/06/12/800-authors-and-counting/
|
|
Cameron Kaiser: TenFourFox FPR23 for Intel available |
Ken's patches have also been incorporated into the tree along with a workaround submitted by Rapha"el Guay to deal with Twitch overflowing our JIT stack. This is probably due to something we don't support causing infinite function call recursion since with the JIT disabled it correctly just runs out of stack and stops. There is no way to increase stack further since we are strictly 32-bit builds and the stack already consumes 1GB of our 2.2-ish GB available, so we need to a) figure out why the stack overflow happens without being detected and b) temporarily disable that script until we do. It's part B that is implemented as a second blacklist which is on unless disabled, since other sites may do this, until we find a better solution to part A. This will be in FPR24 along with probably some work on MP3 compliance issues since TenFourFox gets used as a simple little Internet radio a lot more than I realized, and a few other odds and ends.
In case you missed it, I am now posting content I used to post here as "And now for something completely different" over on a new separate blog christened Old Vintage Computing Research, or my Old VCR (previous posts will remain here indefinitely). Although it will necessarily have Power Mac content, it will also cover some of my other beloved older systems all in one place. Check out properly putting your old Mac to Terminal sleep (and waking it back up again), along with screenshots of the unscreenshotable, including grabs off the biggest computer Apple ever made, the Apple Network Server. REWIND a bit and PLAY.
http://tenfourfox.blogspot.com/2020/06/tenfourfox-fpr23-for-intel-available.html
|
|
Mozilla Addons Blog: Recommended extensions — recent additions |
![]() When the Recommended Extensions program debuted last year, it listed about 60 extensions. Today the program has grown to just over a hundred as we continue to evaluate new nominations and carefully grow the list. The curated collection grows slowly because one of the program’s goals is to cultivate a fairly fixed list of content so users can feel confident the Recommended extensions they install will be monitored for safety and security for the foreseeable future.
When the Recommended Extensions program debuted last year, it listed about 60 extensions. Today the program has grown to just over a hundred as we continue to evaluate new nominations and carefully grow the list. The curated collection grows slowly because one of the program’s goals is to cultivate a fairly fixed list of content so users can feel confident the Recommended extensions they install will be monitored for safety and security for the foreseeable future.
Here are some of the more exciting recent additions to the program…
DuckDuckGo Privacy Essentials provides a slew of great privacy features, like advanced ad tracker and search protection, encryption enforcement, and more.
Read Aloud: Text to Speech converts any web page text (even PDF’s) to audio. This can be a very useful extension for everyone from folks with eyesight or reading issues to someone who just wants their web content narrated to them while their eyes roam elsewhere.
SponsorBlock addresses the nuisance of this newer, more intrusive type of video advertising.
Metastream Remote has been extremely valuable to many of us during pandemic related home confinement. It allows you to host streaming video watch parties with friends. Metastream will work with any video streaming platform, so long as the video has a URL (in the case of paid platforms like Netflix, Hulu, or Disney+, they too will work provided all watch party participants have their own accounts).
Cookie AutoDelete summarizes its utility right in the title. This simple but powerful extension will automatically delete your cookies from closed tabs. Customization features include whitelist support and informative visibility into the number of cookies used on any given site.
AdGuard AdBlocker is a popular and highly respected content blocker that works to block all ads—banner, video, pop-ups, text ads—all of it. You may also notice the nice side benefit of faster page loads, since AdGuard prohibits so much content you didn’t want anyway.
If you’re the creator of an extension you feel would make a strong candidate for the Recommended program, or even if you’re just a huge fan of an extension you think merits consideration, please submit nominations to amo-featured [at] mozilla [dot] org. Due to the high volume of submissions we receive, please understand we’re unable to respond to every inquiry.
The post Recommended extensions — recent additions appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2020/06/11/recommended-extensions-recent-additions/
|
|
Hacks.Mozilla.Org: Introducing the MDN Web Docs Front-end developer learning pathway |
The MDN Web Docs Learning Area (LA) was first launched in 2015, with the aim of providing a useful counterpart to the regular MDN reference and guide material. MDN had traditionally been aimed at web professionals, but we were getting regular feedback that a lot of our audience found MDN too difficult to understand, and that it lacked coverage of basic topics.
Fast forward 5 years, and the Learning Area material is well-received. It boasts around 3.5–4 million page views per month; a little under 10% of MDN Web Docs’ monthly web traffic.
At this point, the Learning Area does its job pretty well. A lot of people use it to study client-side web technologies, and its loosely-structured, unopinionated, modular nature makes it easy to pick and choose subjects at your own pace. Teachers like it because it is easy to include in their own courses.
However, at the beginning of the year, this area had two shortcomings that we wanted to improve upon:
To remedy these issues, we created the Front-end developer learning pathway (FED learning pathway).
Take a look at the Front-end developer pathway linked above — you’ll see that it provides a clear structure for learning front-end web development. This is our opinion on how you should get started if you want to become a front-end developer. For example, you should really learn vanilla HTML, CSS, and JavaScript before jumping into frameworks and other such tooling. Accessibility should be front and center in all you do. (All Learning Area sections try to follow accessibility best practices as much as possible).
While the included content isn’t completely exhaustive, it delivers the essentials you need, along with the confidence to look up other information on your own.
The pathway starts by clearly stating the subjects taught, prerequisite knowledge, and where to get help. After that, we provide some useful background reading on how to set up a minimal coding environment. This will allow you to work through all the examples you’ll encounter. We explain what web standards are and how web technologies work together, as well as how to learn and get help effectively.
The bulk of the pathway is dedicated to detailed guides covering:
Throughout the pathway we aim to provide clear direction — where you are now, what you are learning next, and why. We offer enough assessments to provide you with a challenge, and an acknowledgement that you are ready to go on to the next section.
MDN’s aim is to document native web technologies — those supported in browsers. We don’t tend to document tooling built on top of native web technologies because:
Therefore, it came as a surprise to some that we were looking to document such tooling. So why did we do it? Well, the word here is pragmatism. We want to provide the information people need to build sites and apps on the web. Client-side frameworks and other tools are an unmistakable part of that. It would look foolish to leave out that entire part of the ecosystem. So we opted to provide coverage of a subset of tooling “essentials” — enough information to understand the tools, and use them at a basic level. We aim to provide the confidence to look up more advanced information on your own.
In the Tools and testing Learning Area topic, we’ve provided the following new modules:
The intention is not just to stop here and call the FED learning pathway done. We are always interested in improving our material to keep it up to date and make it as useful as possible to aspiring developers. And we are interested in expanding our coverage, if that is what our audience wants. For example, our frameworks tutorials are fairly generic to begin with, to allow us to use them as a test bed, while providing some immediate value to readers.
We don’t want to just copy the material provided by tooling vendors, for reasons given above. Instead we want to listen, to find out what the biggest pain points are in learning front-end web development. We’d like to see where you need more coverage, and expand our material to suit. We would like to cover more client-side JavaScript frameworks (we have already got a Svelte tutorial on the way), provide deeper coverage of other tool types (such as transformation tools, testing frameworks, and static site generators), and other things besides.
To enable us to make more intelligent choices, we would love your help. If you’ve got a strong idea abou tools or web technologies we should cover on MDN Web Docs, or you think some existing learning material needs improvement, please let us know the details! The best ways to do this are:
So that draws us to a close. Thank you for reading, and for any feedback you choose to share.
We will use it to help improve our education resources, helping the next generation of web devs learn the skills they need to create a better web of tomorrow.
The post Introducing the MDN Web Docs Front-end developer learning pathway appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2020/06/introducing-the-mdn-web-docs-front-end-developer-learning-pathway/
|
|
Mozilla Addons Blog: Improvements to Statistics Processing on AMO |
We’re revamping the statistics we make available to add-on developers on addons.mozilla.org (AMO).
These stats are aggregated from add-on update logs and don’t include any personally identifiable user data. They give developers information about user adoption, general demographics, and other insights that might help them make changes and improvements.
The current system is costly to run, and glitches in the data have been a long-standing recurring issue. We are addressing these issues by changing the data source, which will improve reliability and reduce processing costs.
Until now, add-on usage statistics have been based on add-on updates. Firefox checks AMO daily for updates for add-ons that are hosted there (self-distributed add-ons generally check for updates on a server specified by the developer). The server logs for these update requests are aggregated and used to calculate the user counts shown on add-on pages on AMO. They also power a statistics dashboard for developers that breaks down the usage data by language, platform, application, etc.
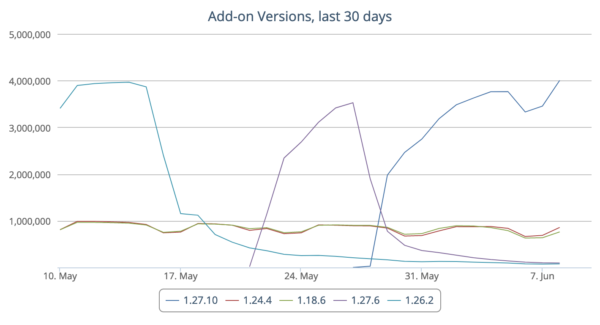
Stats dashboard showing new version adoption for uBlock Origin
In a few weeks, we will stop using the daily pings as the data source for usage statistics. The new statistics will be based on Firefox telemetry data. As with the current stats, all data is aggregated and no personally identifiable user data is shared with developers.
The data shown on AMO and shared with developers will be essentially the same, but the move to telemetry means that the numbers will change a little. Firefox users can opt out of sending telemetry data, and the way they are counted is different. Our current stats system counts distinct users by IP address, while telemetry uses a per-profile ID. For most add-ons you should expect usage totals to be lower, but usage trends and fluctuations should be nearly identical.
Telemetry data will enable us to show data for add-on versions that are not listed on AMO, so all developers will now be able to analyze their add-on usage stats, regardless of how the add-on is distributed. This also means some add-ons will have higher usage numbers, since the average will be calculated including both AMO-hosted and self-hosted versions.
Other changes that will happen due to this update:
We will begin gradually rolling out the new dashboard on June 11. During the rollout, a fraction of add-on dashboards will default to show the new data, but they will also have a link to access the old data. We expect to complete the rollout and discontinue the old dashboards on July 9. If you want to export any of your old stats, make sure you do it before then.
We plan to make a similar overhaul to download statistics in the coming months. For now they will remain the same. You should expect an announcement around August, when we are closer to switching over to the new download data.
The post Improvements to Statistics Processing on AMO appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2020/06/10/improvements-to-statistics-processing-on-amo/
|
|
This Week In Rust: This Week in Rust 342 |
Hello and welcome to another issue of This Week in Rust! Rust is a systems language pursuing the trifecta: safety, concurrency, and speed. This is a weekly summary of its progress and community. Want something mentioned? Tweet us at @ThisWeekInRust or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub. If you find any errors in this week's issue, please submit a PR.
Check out this week's This Week in Rust Podcast
This week's crate is cargo-spellcheck, a cargo subcommand to spell-check your docs.
Thanks to Bernhard Schuster for the suggestion!
Submit your suggestions and votes for next week!
quote! macroAlways wanted to contribute to open-source projects but didn't know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
If you are a Rust project owner and are looking for contributors, please submit tasks here.
350 pull requests were merged in the last week
&mut *x into x-Z span-debug to allow for easier debugging of proc macrosty::Error in generatorsSmallVec or Box for stalled_onimpl AsRef<[T]> for vec::IntoIterdefault() forwarding to Default::default()std::io::Buf{Reader, Writer}::capacityMIN/MAX for WrappingWorkspace::new{prefix} and {lowerprefix} markers in config.json dl keyChanges to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
No RFCs were approved this week.
Every week the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
No RFCs are currently in the final comment period.
impl ToSocketAddrs for (String, u16)Option::zipvec::Drain::as_sliceNo new RFCs were proposed this week.
If you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
Tweet us at @ThisWeekInRust to get your job offers listed here!
You don't declare lifetimes. Lifetimes come from the shape of your code, so to change what the lifetimes are, you must change the shape of the code.
Thanks to RustyYato for the suggestions!
Please submit quotes and vote for next week!
This Week in Rust is edited by: nellshamrell, llogiq, and cdmistman.
https://this-week-in-rust.org/blog/2020/06/10/this-week-in-rust-342/
|
|
The Rust Programming Language Blog: 2020 Event Lineup - Update |
In 2020 the way we can do events suddenly changed. In the past we had in-person events all around the world, with some major conferences throughout the year. With everything changed due to a global pandemic this won't be possible anymore. Nonetheless the Rust community found ways to continue with events in some form or another. With more and more events moving online they are getting more accessible to people no matter where they are.
Below you find updated information about Rust events in 2020.
Do you plan to run a Rust online event? Send an email to the Rust Community team and the team will be able to get your event on the calendar and might be able to offer further help.
Unfortunately the Latin American event Rust LATAM had to be canceled this year. The team hopes to be able to resume the event in the future.
The Oxidize conference was relabeled to become Oxidize Global. From July 17-20 you will be able to learn about embedded systems and IoT in Rust. Over the course of 4 days you will be able to attend online workshops (July 17th), listen to talks (July 18th) and take part in the Impl Days, where you can collaborate with other Embedded Rust contributors in active programming sessions.
Tickets are on sale and the speakers & talks will be announced soon.
The official RustConf will be taking place fully online. Listen to talks and meet other Rust enthusiasts online in digital meetups & breakout rooms. See the list of speakers, register already and follow Twitter for updates as the event date approaches!
Rusty Days is a new conference and was planned to happen in Wroclaw, Poland. It now turned into a virtual Rust conference stretched over five days. You'll be able to see five speakers with five talks -- and everything is free of charge, streamed online and available to watch later.
The Call for Papers is open. Follow Twitter for updates.
RustLab 2020 is also turning into an online event. The details are not yet settled, but they are aiming for the original dates. Keep an eye on their Twitter stream for further details.
RustFest Netherlands was supposed to happen this June. The team decided to postpone the event and is now happening as an online conference in Q4 of this year. More information will be available soon on the RustFest blog and also on Twitter.
Conferences are not the only thing happening. More and more local meetups get turned into online events. We try to highlight these in the community calendar as well as in the This Week in Rust newsletter. Some Rust developers are streaming their work on the language & their Rust projects. You can get more information in a curated list of Rust streams.
Do you plan to run a Rust online event? Send an email to the Rust Community team and the team will be able to get your event on the calendar and might be able to offer further help.
https://blog.rust-lang.org/2020/06/10/event-lineup-update.html
|
|
Mozilla Future Releases Blog: Next steps in testing our Firefox Private Network browser extension beta |
Last fall, we launched the Firefox Private Network browser extension beta as a part of our Test Pilot experiments program. The extension offers safe, no-hassle network protection in the Firefox browser. Since our initial launch, we’ve released a number of versions offering different capabilities. We’ve also launched a Virtual Private Network (VPN) for users interested in full device protection.
Today we are pleased to announce the next step in our Firefox Private Network browser extension Beta. Starting soon, we will be transitioning from a free beta to a paid subscription beta for the Firefox Private Network browser extension. This version will be offered for a limited time for $2.99/mo and will provide unlimited access while using the Firefox Private Network extension. Like our existing extension, this version will be available in the U.S. first, but we hope to expand to other markets soon. Unlike our previous beta, this version will also allow users to connect up to three Firefox browsers at once using the same account. This will only be available for desktop users. For this release, we will also be updating our product icon to differentiate more clearly from the VPN. More information about our VPN as a stand-alone product offering will be shared in the coming weeks.
Last fall, when we first launched the Firefox Private Network browser extension, we saw a lot of early excitement around the product followed by a wave of users signing up. From September through December, we offered early adopters a chance to sign up for the extension with unlimited access, free of charge. In December, when the subscription VPN first launched, we updated our experimental offering to understand if giving participants a certain number of hours a month for browsing in coffee shops or at airports (remember those?) would be appealing. What we learned very quickly was that the appeal of the proxy came most of all from the simplicity of the unlimited offering. Users of the unlimited version appreciated having set and forget privacy, while users of the limited version often didn’t remember to turn on the extension at opportune moments.
These initial findings were borne out in subsequent research. Users in the unlimited cohort engaged at a high level, while users in the limited cohort often stopped using the proxy after only a few hours. When we spoke to proxy users, we found that for many the appeal of the product was in the set-it-and-forget-it protection it offered.
We also knew from the outset that we could not offer this product for free forever. While there are some free proxy products available in the market, there is always a cost associated with the network infrastructure required to run a secure proxy service. We believe the simplest and most transparent way to account for these costs is by providing this service at a modest subscription fee. After conducting a number of surveys, we believe that the appropriate introductory price for the Firefox Private Network browser extension is $2.99 a month.
So the next thing we want to understand is basically this: will people pay for a browser-based privacy tool? It’s a simple question really, and one we think is best answered by the market. Over the summer we will be conducting a series of small marketing tests to determine interest in the Firefox Private Network browser extension as both a standalone subscription product and as well as part of a larger privacy and security bundle for Firefox.
In conjunction, we will also continue to explore the relationship between the Firefox Private Network extension and the VPN. Does it make sense to bundle them? Do VPN subscribers want access to the browser extension? How can we best communicate the different values and attributes of each?
Starting in a few weeks, new users and users in the limited experiment will be offered the opportunity to subscribe to the unlimited beta for $2.99 a month. Shortly thereafter we will be asking our unlimited users to migrate as well.
The post Next steps in testing our Firefox Private Network browser extension beta appeared first on Future Releases.
|
|
The Mozilla Blog: Mozilla Announces Second Three COVID-19 Solutions Fund Recipients |
Innovations spanning food supplies, medical records and PPE manufacture were today included in the final three awards made by Mozilla from its COVID-19 Solutions Fund. The Fund was established at the end of March by the Mozilla Open Source Support Program (MOSS), to offer up to $50,000 each to open source technology projects responding to the COVID-19 pandemic. In just two months, the Fund received 163 applicants from 30 countries and is now closed to new applications.
OpenMRS is a robust, scalable, user-driven, open source electronic medical record system platform currently used to manage more than 12.6 million patients at over 5,500 health facilities in 64 countries. Using Kenya as a primary use case, their COVID-19 Response project will coordinate work on OpenMRS COVID-19 solutions emerging from their community, particularly “pop-up” hospitals, into a COVID-19 package for immediate use.
This package will be built for eventual re-use as a foundation for a suite of tools that will become the OpenMRS Public Health Response distribution. Science-based data collection tools, reports, and data exchange interfaces with other key systems in the public health sector will provide critical information needed to contain disease outbreaks. The committee approved an award of $49,754.
Open Food Network offers an open source platform enabling new, ethical supply chains. Food producers can sell online directly to consumers and wholesalers can manage buying groups and supply produce through networks of food hubs and shops. Communities can bring together producers to create a virtual farmers’ market, building a resilient local food economy.
At a time when supply chains are being disrupted around the world — resulting in both food waste and shortages — they’re helping to get food to people in need. Globally, the Open Food Network is currently deployed in India, Brazil, Italy, South Africa, Australia, the UK, the US and five other countries. They plan to use their award to extend to ten other countries, build tools to allow vendors to better control inventory, and scale up their support infrastructure as they continue international expansion. The Committee approved a $45,210 award.
Careables Casa Criatura Olinda in northeast Brazil is producing face shields for local hospitals based on an open source design. With their award, they plan to increase their production of face shields as well as to start producing aerosol boxes using an open source design, developed in partnership with local healthcare professionals.
Outside of North American ICUs, many hospitals cannot maintain only one patient per room, protected by physical walls and doors. In such cases, aerosol boxes are critical to prevent the spread of the virus from patient to patient and patient to physician. Yet even the Brazilian city of Recife (population: 1.56 million), has only three aerosol boxes. The Committee has approved a $25,000 award and authorized up to an additional $5,000 to help the organization spread the word about their aerosol box design.
“Healthcare has for too long been assumed to be too high risk for open source development. These awards highlight how critical open source technologies are to helping communities around the world to cope with the pandemic,” said Jochai Ben-Avie, Head of International Public Policy and Administrator of the Program at Mozilla. “We are indebted to the talented global community of open source developers who have found such vital ways to put our support to good use.”
Information on the first three recipients from the Fund can be found here.
The post Mozilla Announces Second Three COVID-19 Solutions Fund Recipients appeared first on The Mozilla Blog.
|
|
Henri Sivonen: chardetng: A More Compact Character Encoding Detector for the Legacy Web |
|
|
Mozilla Privacy Blog: Mozilla releases recommendations on EU Data Strategy |
Mozilla recently submitted our response to the European Commission’s public consultation on its European Strategy for Data. The Commission’s data strategy is one of the pillars of its tech strategy, which was published in early 2020 (more on that here). To European policymakers, promoting proper use and management of data can play a key role in a modern industrial policy, particularly as it can provide a general basis for insights and innovations that advance the public interest.
Our recommendations provide insights on how to manage data in a way that protects the rights of individuals, maintains trust, and allows for innovation. In addition to highlighting some of Mozilla’s practices and policies which underscore our commitment to ethical data and working in the open – such as our Lean Data Practices Toolkit, the Data Stewardship Program, and the Firefox Public Data Report – our key recommendations for the European Commission are the following:
We’ll continue to build out our thinking on these recommendations, and will work with the European Commission and other stakeholders to make them a reality in the EU data strategy. For now, you can find our full submission here.
The post Mozilla releases recommendations on EU Data Strategy appeared first on Open Policy & Advocacy.
https://blog.mozilla.org/netpolicy/2020/06/05/eudatastrategy/
|
|
About:Community: Firefox 77 new contributors |
With the release of Firefox 77, we are pleased to welcome the 38 developers who contributed their first code change to Firefox in this release, 36 of whom were brand new volunteers! Please join us in thanking each of these diligent and enthusiastic individuals, and take a look at their contributions:
https://blog.mozilla.org/community/2020/06/01/firefox-77-new-contributors/
|
|
Christopher Arnold: Money, friction and momentum on the web |

https://ncubeeight.blogspot.com/2020/05/money-friction-and-momentum-on-web.html
|
|
Daniel Stenberg: on-demand buffer alloc in libcurl |
Okay, so I’ll delve a bit deeper into the libcurl internals than usual here. Beware of low-level talk!
There’s a never-ending stream of things to polish and improve in a software project and curl is no exception. Let me tell you what I fell over and worked on the other day.
We have users who are running curl on tiny devices, often put under the label of Internet of Things, IoT. These small systems typically have maybe a megabyte or two of ram and flash and are often too small to even run Linux. They typically run one of the many different RTOS flavors instead.
It is with these users in mind I’ve worked on the tiny-curl effort. To make curl a viable alternative even there. And believe me, the world of RTOSes and IoT is literally filled with really low quality and half-baked HTTP client implementations. Often certainly very small but equally as often with really horrible shortcuts or protocol misunderstandings in them.
Going with curl in your IoT device means going with decades of experience and reliability. But for libcurl to be an option for many IoT devices, a libcurl build has to be able to get really small. Both the footprint on storage but also in the required amount of dynamic memory used while executing.
Being feature-packed and attractive for the high-end users and yet at the same time being able to get really small for the low-end is a challenge. And who doesn’t like a good challenge?
I’ve set myself on a quest to make it possible to build libcurl smaller than before and to use less dynamic memory. The first tiny-curl releases were only the beginning and I already then aimed for a libcurl + TLS library within 100K storage size. I believe that goal was met, but I also think there’s more to gain.
I will make tiny-curl smaller and use less memory by making sure that when we disable parts of the library or disable specific features and protocols at build-time, they should no longer affect storage or dynamic memory sizes – as far as possible. Tiny-curl is a good step in this direction but the job isn’t done yet – there’s more “dead meat” to carve off.
One example is my current work (PR #5466) on making sure there’s much less proxy remainders left when libcurl is built without support for such. This makes it smaller on disk but also makes it use less dynamic memory.
To decrease the maximum amount of allocated memory for a typical transfer, and in fact for all kinds of transfers, we’ve just switched to a model with on-demand download buffer allocations (PR #5472). Previously, the download buffer for a transfer was allocated at the same time as the handle (in the curl_easy_init call) and kept allocated until the handle was cleaned up again (with curl_easy_cleanup). Now, we instead lazy-allocate it first when the transfer starts, and we free it again immediately when the transfer is over.
It has several benefits. For starters, the previous initial allocation would always first allocate the buffer using the default size, and the user could then set a smaller size that would realloc a new smaller buffer. That double allocation was of course unfortunate, especially on systems that really do want to avoid mallocs and want a minimum buffer size.
The “price” of handling many handles drastically went down, as only transfers that are actively in progress will actually have a receive buffer allocated.
A positive side-effect of this refactor, is that we could now also make sure the internal “closure handle” actually doesn’t use any buffer allocation at all now. That’s the “spare” handle we create internally to be able to associate certain connections with, when there’s no user-provided handles left but we need to for example close down an FTP connection as there’s a command/response procedure involved.
Downsides? It means a slight increase in number of allocations and frees of dynamic memory for doing new transfers. We do however deem this a sensible trade-off.
I always hesitate to bring up numbers since it will vary so much depending on your particular setup, build, platform and more. But okay, with that said, let’s take a look at the numbers I could generate on my dev machine. A now rather dated x86-64 machine running Linux.
For measurement, I perform a standard single transfer getting a 8GB file from http://localhost, written to stderr:
curl -s http://localhost/8GB -o /dev/null
With all the memory calls instrumented, my script counts the number of memory alloc/realloc/free/etc calls made as well as the maximum total memory allocation used.
The curl tool itself sets the download buffer size to a “whopping” 100K buffer (as it actually makes a difference to users doing for example transfers from localhost or other really high bandwidth setups or when doing SFTP over high-latency links). libcurl is more conservative and defaults it to 16K.
This command line of course creates a single easy handle and makes a single HTTP transfer without any redirects.
Before the lazy-alloc change, this operation would peak at 168978 bytes allocated. As you can see, the 100K receive buffer is a significant share of the memory used.
After the alloc work, the exact same transfer instead ended up using 136188 bytes.
102,400 bytes is for the receive buffer, meaning we reduced the amount of “extra” allocated data from 66578 to 33807. By 49%
Even tinier tiny-curl: in a feature-stripped tiny-curl build that does HTTPS GET only with a mere 1K receive buffer, the total maximum amount of dynamically allocated memory is now below 25K.
The numbers mentioned above only count allocations done by curl code. It does not include memory used by system calls or, when used, third party libraries.
The changes mentioned in this blog post have landed in the master branch and will ship in the next release: curl 7.71.0.
https://daniel.haxx.se/blog/2020/05/30/on-demand-buffer-alloc-in-libcurl/
|
|
Cameron Kaiser: TenFourFox FPR23 available |
http://tenfourfox.blogspot.com/2020/05/tenfourfox-fpr23-available.html
|
|
Asa Dotzler: 20 Years with Mozilla |
Today marks 20 years I’ve been working full-time for Mozilla.
As the Mozilla organization evolved, I moved with it. I started with staff@mozilla.org at Netscape 20 years ago, moved to the Mozilla Foundation ~17 years ago, and the Mozilla Corporation ~15 years ago.
Thank you to Mitchell Baker for taking a chance on me. I’m eternally grateful for that opportunity.
|
|
Mozilla VR Blog: WebXR Viewer 2.0 Released |

We are happy to announce that version 2.0 of WebXR Viewer, released today, is the first web browser on iOS to implement the new WebXR Device API, enabling high-performance AR experiences on the web that don't share pictures of your private spaces with third party Javascript libraries and websites.
It's been almost a year since the previous release (version 1.17) of our experimental WebXR platform for iOS, and over the past year we've been working on two major changes to the app: (1) we updated the Javascript API to implement the official WebXR Device API specification, and (2) we ported our ARKit-based WebXR implementation from our minimal single-page web browser to the full-featured Firefox for iOS code-base.
The first goal this release is to update the browser's Javascript API for WebXR to support the official WebXR Device API, including an assortment of approved and proposed AR features. The original goal with the WebXR Viewer was to give us an iOS-based platform to experiment with AR features for WebXR, and we've written previous posts about experimenting with privacy and world structure, computer vision, and progressive and responsive WebXR design. We would like to continue those explorations in the context of the emerging standard.
We developed the API used in the first version of the WebXR Viewer more than 3 years ago (as a proposal for how WebXR might combine AR and VR; see the WebXR API proposal here, if you are interested), and then updated it a year ago to match the evolving standard. While very similar to the official API, this early version of the official API is not compatible with the final standard, in some substantial ways. Now that WebXR is appearing in mainstream browsers, it's confusing to developers to have an old, incompatible API out in the world.
Over the past year, we rebuilt the API to conform to the official spec, and either updated our old API features to match current proposals (e.g., anchors, hit testing, and DOM overlay), marked them more explicitly as non-standard (e.g., by adding a nonStandard_ prefix to the method names), or removed them from the new version (e.g., camera access). Most WebXR AR examples on the web now work with the WebXR Viewer, such as the "galaxy" example from the WebXR Samples repository shown in the banner above.
(The WebXR Viewer's Javascript API is entirely defined in the Javascript library in the webxr-ios-js repository linked above, and the examples are there as well; the library is loaded on demand from the github master branch when a page calls one of the WebXR API calls. You can build the API yourself, and change the URL in the iOS app settings to load your version instead of ours, if you want to experiment with changes to the API. We'd be happy to receive PRs, and issues, at that github repository.)

In the near future, we're interested in continuing to experiment with more advanced AR capabilities for WebXR, and seeing what kinds of experimentation developers do with those capabilities. Most AR use cases need to integrate virtual content with meaningful things in the world; putting cute dinosaurs or superheros on flat surfaces in the world makes for fun demos that run anywhere, but genuinely useful consumer and business applications need to sense, track, and augment "people, places, and things" and have content that persists over time. Enhancing the Immersive Web with these abilities, especially in a "webby" manner that offers privacy and security to users, is a key area Mozilla will be working on next. We need to ensure that there is a standards-based solution that is secure and private, unlike the proprietary solutions currently in the market that are siloed to create new, closed markets controlled by single companies.
While purely vision-based AR applications (implemented inside web pages using direct access to camera video) are showing great engagement, failing to use the underlying platform technology limits their capabilities, as well as using so much CPU and GPU resources that they can only run for a few seconds to minutes before thermal throttling renders them unusable (or your battery dead). WebXR offers the possibility for the underlying vision-based sensing techniques to be implemented natively so they can take advantage of the underlying platform APIs (both to maximize performance and to minimize CPU, GPU, and battery use).
It is too early to standardize some of these capabilities and implement them in a open, cross-platform way (e.g., persistent anchors), but others could be implemented now (e.g., the face and image tracking examples shown below). In the newly announced Firefox Reality for Hololens2, we're experimenting with exposing hand tracking into WebXR for input, a key sort of sensing that will be vital for head-worn-display-based AR (Oculus is also experimenting with exposing hand tracking into VR in the Oculus Browser on Quest). APIs like ARKit and Vuforia let you detect and track faces, images, and objects in the world, capabilities that we explored early on with the WebXR Viewer. We've kept versions of the APIs we developed in the current WebXR Viewer, and are keen to see these capabilities standardized in the future.
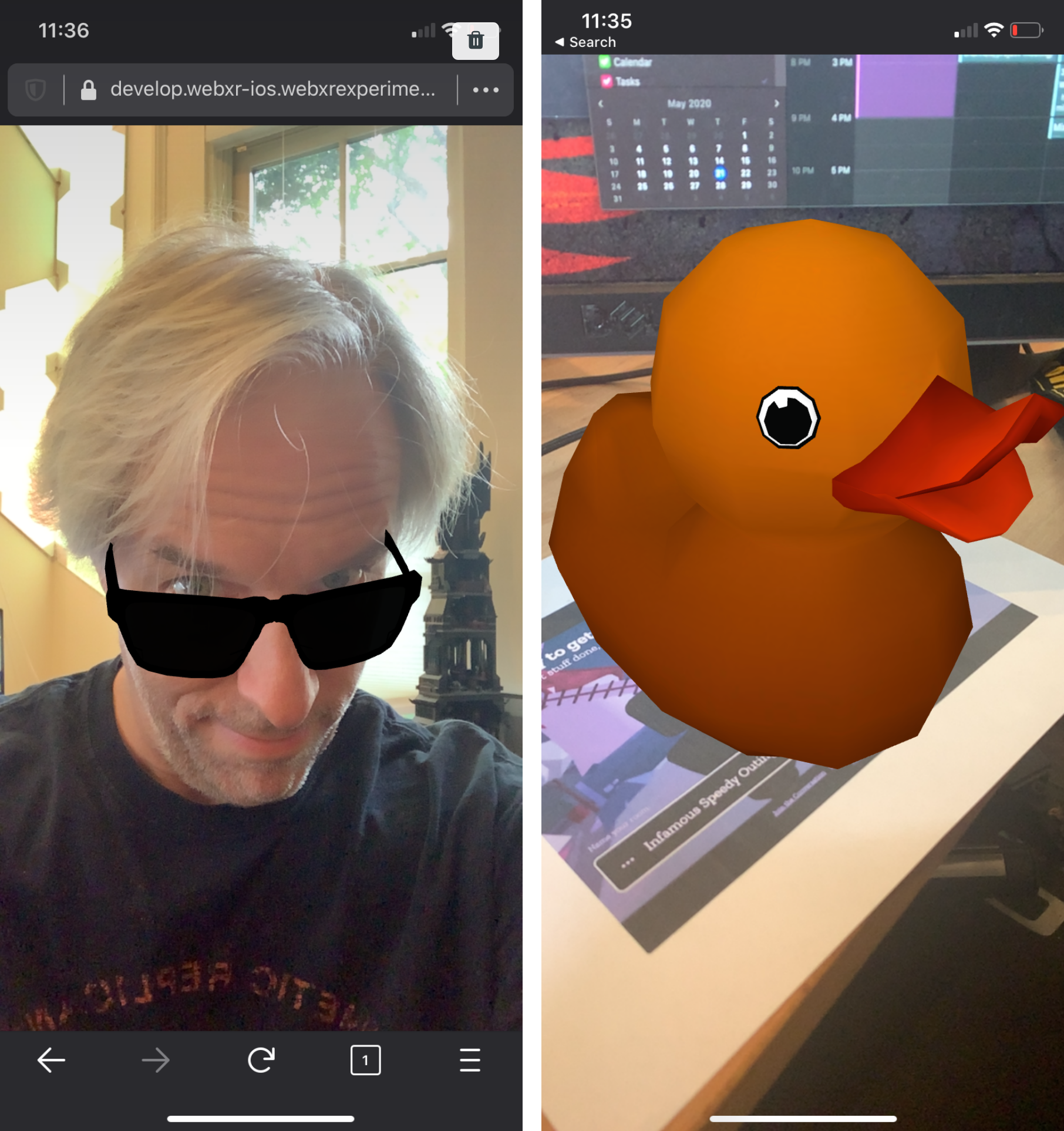
The second change will be immediately noticeable: when you launch the app, you'll be greeted by the familiar Firefox for iOS interface, and be able to take advantage of many of the features of its namesake (tabs, history, private browsing, and using your Firefox account to sync between devices, to name a few). While not all Firefox features work, such as send-to-device from Firefox, the experience of using the WebXR Viewer should be more enjoyable and productive.
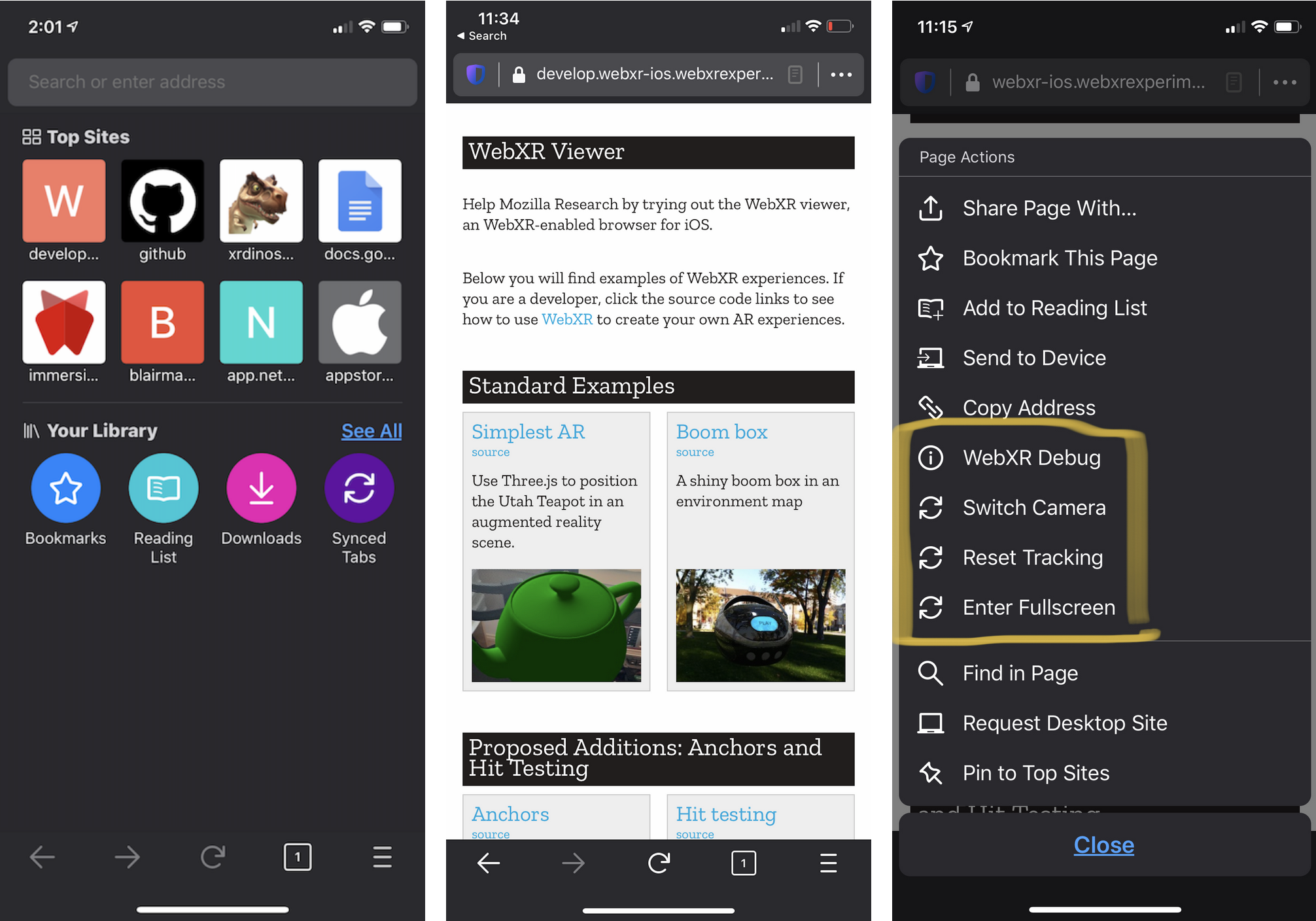
Our goal for moving this code to the Firefox code-base wasn't just to create a better browsing experience for the WebXR Viewer, though. This is an experimental app, after all, aimed at developers hoping to explore web-based AR on iOS, and we don't plan on supporting it as a separate product over the long term. But Apple hasn't shown any sign of implementing WebXR, and it's critically important for the success of the immersive web that an implementation exists on all major platforms. Toward this end, we moved this implementation into the Firefox for iOS code-base to see how this approach to implementing WebXR would behave inside Firefox, with an eye towards (possibly) integrating these features into Firefox for iOS in the future. Would the WebXR implmentation work at all? (Yes.) Would it perform better or worse than in the old app? (Better, it turns out!) What UI and usability issues would arise? (Plenty.) While there is still plenty of UI work to do before moving this to a mainstream browser, we're quite happy with the performance; WebXR demos run better in this version of the app than they did in the previous one, and the impact on non-WebXR web pages seems minimal.
We'd love for you to download the new version of the app and try out your WebXR content on it. If you do, please let us know what your experience is.
|
|
Jeff Klukas: Encoding Usage History in Bit Patterns |
Originally published as a cookbook on docs.telemetry.mozilla.org to instruct data users within Mozilla how to take advantage of the usage history stored in our BigQuery tables.

Monthly active users (MAU) is a windowed metric that requires joining data
per client across 28 days. Calculating this from individual pings or daily
aggregations can be computationally expensive, which motivated creation of the
clients_last_seen dataset
for desktop Firefox and similar datasets for other applications.
A powerful feature of the clients_last_seen methodology is that it doesn’t
record specific metrics like MAU and WAU directly, but rather each row stores
a history of the discrete days on which a client was active in the past 28 days.
We could calculate active users in a 10 day or 25 day window just as efficiently
as a 7 day (WAU) or 28 day (MAU) window. But we can also define completely new
metrics based on these usage histories, such as various retention definitions.
https://jeff.klukas.net/writing/2020-05-29-encoding-usage-history-in-bit-patterns/
|
|
Marco Zehe: Welcome to Marco's Accessibility Blog 2.0! |
Yes, you read that right! This blog has just relaunched. It runs on a new platform. And it is a lot faster, and has a very slick look and feel to it. Read on to find out some more details.
Well, after 13 years, I felt it was time for something new. Also, as I wrote recently, Mozilla now has a dedicated accessibility blog, so I feel that I am free to do other things with my blog now. As a sign of that, I wanted to migrate it to a new platform.
This is not to say the old platform, WordPress, is bad or anything like that. But for my needs, it has become much too heavy-weight in features, and also in the way how it feels when performing day to day tasks. 80% of features it offers are features I don't use. This pertains both to the blog system itself as well as its new block editor. But those features don't get out of the way easily, so over the months and actually last two to three years, I felt that I was moving mountains just to accomplish simple things. It has nothing to do with the steadily improving accessibility, either. That is, as I said, getting better all the time. It just feels heavy-weight to the touch and keyboard when using it.
So one day earlier this year, I read a post on my favorite publishing editor's web site, where they told the story how they migrated to the Ghost platform. I must admit I had never heard of Ghost before, but was curious, so I started poking around.
As I did so, I quickly stumbled on the term JAMstack. Some of you may now ask: "Stumbled upon? What rock have you been living under these past 5 or 6 years?" Well, you know, I had heard of some of the software packages I am going to mention, but I didn't have the time, and more recently, energy, to actually dig into these technology stacks at all.
The truth is, I started asking myself this question as I became more familiar with Ghost itself, static site generators, and how this can all hang together. JAM stands for JavaScript, APIs and Markup, and describes the mental separation between how and where content is created, how it's being transferred, and then finally, output to the world.
In a nutshell - and this is just the way I understand things so far -, applications like WordPress or Drupal serve the content from a database every time someone visits a site or page. So every time an article on my blog was being brought up, database queries were made, HTML was put together, and then served to the recipient. This all happens in the same place.
However, there are other ways to do that, aren't there? Articles usually don't change every day, so it is actually not necessary to regenerate the whole thing each time. Granted, there are caching options for these platforms, but from past experience, I know that these weren't always that reliable, even when they came from the same vendor as the main platform.
JAMstack setups deal with this whole thing in a different way. The content is generated somewhere, by writers who feel comfortable with a certain platform. This can, for all intents and purposes, even be WordPress nowadays since it also offers a REST API. But it can also be Ghost. Or NetlifyCMS together with a static site generator. Once the content is done, like this blog post, it is being published to that platform.
What can happen then depends on the setup. Ghost has its own front-end, written in Ember, and can serve the content directly using one of the many templates available now. This is how my blog is set up right now. So this is not that much different from WordPress, only that Ghost is much more light-weight and faster, and built entirely, not just partially, on modern JS stacks.
However, it doesn't have to be that way. Through integrations, web hooks and by leveraging source code management systems like Github or Gitlab, every time my content updates, a machinery can be set in motion that publishes my posts to a static site generator or fast JavaScript application framework. That then serves the content statically, and thus much faster than a constant rebuild, whenever it is being called from a visitor.
Such static site generators are, for example, Hugo or Eleventy, which both serve static HTML pages to the audience with only minimal JavaScript. Or they can be application frameworks like Gatsby.js, which is a single page application serving the content blazing fast from a local build which is based off of the content created in the publishing platform. That way, the actual presentation is completely decoupled from the publishing workflow, and the developer who works on the front-end doesn't even have to know Ghost, WordPress, or what not, just the API, to get the content and present it, in a way they feel most comfortable with.
As I mentioned, my blog currently serves the content directly from Ghost. But if I feel like it, I might also set up a Gatsby mirror on another domain that will also be up to date whenever something is being published here. The steps to do that are not that difficult at all.
One path I was researching as a possible alternative to Ghost was going with Hugo. To get started, I read this excellent migration report by Sara Soueidan, and did some more research. One show stopper was that I like to blog from an iPad nowadays, and there was not a very elegant way to integrate Ulysses with Hugo or a Github repository. Yes, there is a workflow (umm, Siri Shortcut) available that could do that with an iOS Github client named WorkingCopy, but this all felt too fragile and cumbersome. So in the end, because I want to concentrate on the writing most, I decided not to go that route. Nothing beats native publishing from an app to the CMS.
The same was true for Eleventy, which I looked at just because there is such a great diverse community behind it, including quite a number of people I know and highly respect. And as hinted above, none of these packages is out of my mind yet when it comes to tinkering, researching, and getting up to speed with modern web technologies. After all, these packages are all interoperating with one another in an open fashion. They are the modern versioon of what the web stands for, an open, collaborative, interoperable resource for everyone.
And let's be honest, there are enough silos out there. Yes, even when open source, a platform that powers over a third of the web sites out there can be considered its own silo.
Here's another piece of good news: All these communities, which are interconnected and exchanging knowledge and wisdom, also have members with accessibility in mind. Some are strong advocates, some more the background worker, but all have in common that accessibility is no stranger to them. Ghost itself welcomes reports and pull requests, some theme authors have mentions of accessibility in their goals and theme features. Projects like Gatsby and Eleventy have people with strong voices among their staff or supporters, and just by looking at the project web sites shows that.
As for this blog, before I officially launched, I submitted some fixes to the theme I wanted to use, as well as Ghost itself, which were all quickly accepted. I am using a copy of the theme with these fixes on this blog already.
Yes, those have indeed gone from this site. They proved to be more trouble than they were worth in the last few years. Most of them were spam, and hardly any other comments came through. A recent informal survey I conducted on Twitter also showed that two thirds of my readers actually don't care much for comments.
Informal survey: When you read a blog post by someone, how important is the ability of publicly commenting on it?
— Marco Zehe (@MarcoInEnglish) May 25, 2020
So I decided that I am not going to integrate any commenting system into my Ghost setup for now, even though it is certainly possible using some 3rd party providers. If I change my mind in the future again, there are certainly some options available.
I hope you'll enjoy this new chapter of the journey with me, and stay a loyal reader! This blog will, as previously hinted, in the future focus more on personal topics, research, and other related items. For a glimpse, well, reread this post. ;-)
In a future article, I will go into some of the Ghost-specific details I dealt with when migrating from my WordPress setup.
Let's do this!
https://www.marcozehe.de/welcome-to-marcos-accessibility-blog-2-0/
|
|






