Mozilla Addons Blog: Extending the deadline for add-on signing |
After listening to your feedback, bug 1203584 was filed last week to turn off signing requirements in Firefox 41 and 42. This extends the signing deadline to Firefox 43, which will be released around December 15, 2015.
While the new unlisted queues have maintained a quick turnaround time (thanks to the tireless efforts of Andreas Wagner, aka TheOne), many developers are telling us they simply don’t have enough time to implement the requested changes before the September 22 deadline when 42 hits the beta channel. In addition to giving you some extra breathing room, we’re also going to use this time on our side to make some improvements to the submission experience to make it clearer what level of review is needed, which you can follow in bug 1186369.
Thanks for your patience as we roll out this new process. Special thanks to those of you who have already gotten your extensions signed…you’re awesome.
https://blog.mozilla.org/addons/2015/09/16/extending-the-deadline-for-add-on-signing/
|
|
Andrea Wood: Movement Building and Web Literacy: What’s Next |
This is the second of a two-part blog (see part I here)
Integrate grassroots advocacy into the Mozilla community. This means deeper investment in building our ground game for the web. Though the landscape could change, policy priorities and community interest intersect in the European Union and in India at the moment (on issues like net neutrality, data retention, surveillance). India is home to a very large number of people just coming online. It’s a tremendous opportunity for Mozilla to engage on net neutrality and web literacy — and what happens in India will influence how a huge % of the planet comes to understand the importance of these issues.
Invest in our email list so that we can mobilize at a moment’s notice. Right now, Mozilla has one of the largest email advocacy lists dedicated to web issues in the world. We can empower millions more people by engaging them via email. A global email list is a powerful weapon for protecting the largest public resource on the planet. It’s also an audience for other things Mozilla has to offer — including products and learning opportunities. Not all populations rely on email the same way — its usage isn’t universal. We also have to invest in non-email channels where needed.
Fill the information gap. “Online life” is quickly just melding into “life” and threats to that life mean more people are paying attention. in fact, we know from research that people are worried. How can I avoid phishing scams? How can I fight government overreach into my private data? What’s a good password look like? What can I do if my credit card is hacked online? How do I hide my search history? People want and need to know more about how to be good web citizens; how to be empowered and smart online. Yet, where’s the creative, clever, poignant, share-ready content to fill in the blanks? How do people get answers so they become confident web citizens?
Here’s where I recommend we focus some energy, and invest in tactical experiments:
Map an agile path for grassroots community building. I use “agile path” because we need to approach the challenge with a beginner’s mind. There’s a lot we don’t know about building a grassroots organizing infrastructure as Mozilla. How will Mozilla’s community respond to calls to action? Who will raise their hand to help build advocacy strategy in a given region, country, or city? What’s the best way to support local leaders? How do we listen to the community members telling us which issues should be priority for Mozilla? How do we partner with policy, brand, participation, communications, product and other teams who also care about community engagement?
Invest in email best practice and the best practitioners. This means as an organization we need to grasp the importance of a virtual community (such as an email list) as a living, breathing thing that needs careful care and nurturing. Right now this work is under-resourced and therefore under-performing in many respects. Peer organizations have staffs larger than ours managing email lists smaller than ours. Email list and community management is a skill, science, art, and craft and the very best at it are in demand (in a growing number of sectors). Better resourcing will lead to careful and smart engagement strategies that keep our community primed for calls to act on the things we all care about.
Invest in design and community-generated content. There’s been much written lately about how important design is to business — I would argue that design can also play a crucial role in the business of movement building. How can we make content with the right look and feel, in the right voice, delivered at the right moment?
Mozilla is like no other organization, and leaning into what makes Mozilla so special will yield incredible growth, and impact — we’ve seen it work for our nascent digital advocacy program. Leveraging our incredible community + building email capacity + investing in great content will help many more m(b)illions become web citizens — not just passive consumers.
http://valianttry.us/movement-building-and-web-literacy-a-proposal/
|
|
Andrea Wood: Movement Building at Mozilla: What We’ve Learned |
(This is Part I in a two-part series)
Mark asks in his blog post: How can we help m(b)illions more people understand how the web works and how to wield it?
Before joining Mozilla I worked with organizations like Change.org, Habitat for Humanity, and CREDO. Though none of them are quite like Mozilla, these organizations provide useful context for understanding how Mozilla’s change-making work is typical (or isn’t). I tend to view Mozilla’s work through a movement-builder’s lens.
As we look at how Mozilla can impact web literacy in the next 1 – 3 years I wanted to explore what we’ve discovered doing digital issue advocacy at Mozilla, and how that might shape our planning. I think at this moment we have an opportunity to leverage Mozilla’s unique strengths — including our incredible community + building email capacity + investing in great content will help many more m(b)illions become web citizens (more details in a follow-up post here).
In a few fundamental ways, we’ve learned that Mozilla is like many other global grassroots movements.
Our movement is as diverse as the people who use the web. Like with any issue movement, people discover Mozilla’s campaigns in lots of different contexts and their investment may vary. (My colleague Sara Haghdoosti wrote a great post about how we might think about these levels of engagement.)
Our issues are in the mainstream. Mozilla’s issues are now in the mainstream. We can thank whistleblowers like Edward Snowden, data breaches by major retailers and credit card companies, and government surveillance overreach for an upswell in concern and interest. There’s never been such high demand for clarity and practical insight from so much of the global public on issues previously relegated to the “geeks.”
Mozilla needs allies. Working in coalition is vital — just as it has been, for example, for the climate movement. We’ve connected with dozens of organizations on our priority issues — from Electronic Frontier Foundation on net neutrality to Digitale Gesellschaft on German data retention to savetheinternet.in on net neutrality in India.
The organizations caring about the web around the world are legion, and together we are much stronger than if we stand alone.
We grapple with scalability, logistics, and infrastructure challenges. Every global organization is tackling how to build, facilitate, and manage grassroots community at scale — and localization is but one of the challenges. Should we build a centralized, top-down campaign structure? Or should we build an infrastructure that gives tools for organizing to people around the world? How can we use software like Constituent Relationship Management (CRM) to reach the right people at the right moment? How do we localize campaigns quickly when a crucial moment hits? These are tough logistical challenges that face any movement building organization today. Mozilla is no different.
After a few years of digital advocacy, we also know more about what makes Mozilla unique compared with other movements — and how our “unicorn-ness” helps us win campaigns for the web:
Read the next blog (Part II here)
http://valianttry.us/movement-building-at-mozilla-what-weve-learned/
|
|
Air Mozilla: "Service workers in gecko" Presented by Catalin Badea |
 Service workers in gecko Catalin Badea will talk about his work in the DOM team during the summer of 2015.
Service workers in gecko Catalin Badea will talk about his work in the DOM team during the summer of 2015.
|
|
Air Mozilla: "GIF me your memory!" Presented by Mihai Volmer |
GIF me your memory! Mihai Volmer will talk about the benefits of making animated GIFs render through the media library.
|
|
Air Mozilla: "Keeping up in a fast moving world" Presented by Robert Bindar |
Keeping up in a fast moving world Robert Bindar will be talking about the importance of a good notifications system in scheduling everyday events.
|
|
Eitan Isaacson: Firefox for Android Accessibility Refresh |
When we first made Firefox accessible for Android, the majority of our users were using Gingerbread. Accessibility in Android was in its infancy, and certain things we take for granted in mobile screen readers were not possible.
For example, swiping and explore by touch were not available in TalkBack, the Android screen reader. The primary mode of interaction was with the directional keys of the phone, and the only accessibility event was “focus”.
The bundled Android apps were hardly accessible, so it was a challenge to make a mainstream, full featured, web browser accessible to blind users. Firefox for Android at the time was undergoing a major overhaul, so it was a good time to put some work into our own screen reader support.
We were governed by two principals when we designed our Android accessibility solution:
It was a real source of pride to have the most accessible and blind-friendly browser on Android. Since our initial Android support our focus has gone elsewhere while we continued to maintain our offering. In the meantime, Google has upped its game. Android has gotten a lot more sophisticated on the accessibility front, and Chrome integrated much better with TalkBack (I would like to believe we inspired them).
Now that Android has good web accessibility support, it is time that we integrate with those features to offer our users the seamless experience they expect. In tomorrows Nightly, you will see a few improvements:
That’s it, for now! We hope to prove our commitment to accessibility as Firefox branches out to other platforms. Expect more to come.

http://blog.monotonous.org/2015/09/15/firefox-for-android-accessibility-refresh/
|
|
John O'Duinn: A Release Engineer’s view on rapid releases of books |
As a release engineer, I’ve designed and built infrastructure for companies that used the waterfall-model and for companies that used a rapid release model. I’m now writing a book, so recently I have been looking at a very different industry through this same RelEng lens.
In days of old, here’s a simplistic description of what typically happened. Book authors would write their great masterpiece on their computer, in MSWord/Scrivener/emacs/typewriter/etc. Months (or years!) later, when the entire book was written, the author would deliver the “complete” draft masterpiece to the book company. Editors at the book company would then start reading from page1 and wade through the entire draft, making changes, fixing typos, looking for plot holes, etc. Sometimes they could make these corrections themselves, sometimes the changes required sending the manuscript back to the author to rewrite portions. Later, external reviewers would also provide feedback, causing even more changes. If all this took a long time, sometimes the author had to update the book with new developments to make sure the book would be up-to-date when it finally shipped. Tracking all these changes was detailed, time-pressured and chaotic work. Eventually, a book would finally go to press. You could reduce risk as well as simplify some printing and shipping logistics by having bookshops commit to pre-buy bulk quantities – but this required hiring a staff of sales reps selling the unwritten books in advance to bookstores before the books were fully written. Even so, you could still over/under estimate the future demand. And lets not forget that once people start reading the book, and deciding if they like it, you’ll get word-of-mouth, book reviews and bestseller-lists changing the demand unpredictably.
If people don’t like the book, you might have lots of copies of an unsellable book on your hands, which represents wasted paper and sunk costs. The book company is out-of-pocket for all the salaries and expenses from the outset, as well as the unwanted printed books and would hope to recover those expenses later from other more successful books. Similar to the Venture Capital business model, the profits from the successful books help recoup the losses from the other unprofitable books.
If people do like the book, and you have a runaway success, you can recoup the losses of the other books so long as you avoid being out-of-stock, which could cause people to lose interest in the book because of back order delays. Also, any errors missed in copy-editing and proofreading could potentially lead to legal exposure and/or forced destruction of all copies of printed books, causing further back order delays and unexpected costs. Two great examples are The Sinner’s Bible and the Penguin cook book.
This feels like the classic software development “waterfall” model.
By contrast, one advantage with the rapid release model is that you get quick feedback on the portions you have shipped so far, allowing you to revisit and quickly adjust/fix as needed… even while you are still working on completing and shipping the remaining portions. By the time you ship the last portion of the project, you’ve already adjusted and fixed a bunch of surprise gotchas found in the earlier chunks. By the time you ship your last portion, your overall project is much healthier and more usable. After all, for the already shipped portions, any problems discovered in real-world-use have already been fixed up. By comparison, a project where you write the same code for 18-24 months and then publish it all at the same time will have you dealing with all those adjustments/fixes for all the different chunks *at the same time*. Delivering smaller chunks helps keep you honest about whether you are still on schedule, or let you quickly see whether you are starting to slip the schedule.
The catch is that this rapid release requires sophisticated automation to make the act of shipping each chunk as quick, speedy and reliable as possible. It also requires dividing a project into chunks that can be shipped separately – which is not as easy to do as you might hope. Doing this well requires planning out the project carefully in small shippable chunks, so you can ship when each chunk is written, tested and ready for public consumption. APIs and contractual interfaces need to be understood and formalized. Dependencies between each chunk needs to figured out. Work estimates for writing and testing each module need to be guessed. A calendar schedule is put together. The list goes on and on… Aside: You probably should do this same level of planning also for waterfall model releases, but its easy to miss hidden dependencies or impact of schedule slips until the release date when everything was supposed to come together on the day.
So far, nothing new here to any release engineer reading this.
One of the (many) reasons I went with O’Reilly as the publisher for this book was their decision to invest in their infrastructure and process. O’Reilly borrowed a page from Release Engineers and invested in automation to switch their business from a waterfall model to a rapid release model. This change helps keep schedules realistic, as schedule slips can be spotted early. It helps get early feedback which helps ship a better final product, so the ratio of successful book vs unprofitable books should improve. It helps judge demand, which helps the final printing production planning to reduce cost wasting with less successful books, and to improve profits and timeliness for successful books. This capability is a real competitive advantage in a very competitive business market. This is an industry game changer.
When you know you want “rapid release for books”, you discover a lot of tools were already there, with a different name and slightly-different-use-cases. Recent technologies advances help make the rest possible. The overall project (“table of contents”). The breaking up of the overall project into chunks (“book chapters”). Delivering usable portions as they are ready (print on demand, electronic books + readers, online updates). Users (“readers”) who get the electronic versions will get update notices when newer versions become available. At O’Reilly, the process now looks like this:
Book authors and editors agree on a table of contents and an approximate ship date (write a project plan with scope) before signing contracts.
Book authors “write their text” (commit their changes) into a shared hosted repository, as they are writing throughout the writing creative process, not just at the end. This means that O’Reilly editors can see the state of the project as changes happen, not just when the author has finished the entire draft manuscript. It also means that O’Reilly reduces risk of catastrophic failure if an author’s laptop crashes, or is stolen without a backup.
A hosted automation system reads from the repository, validates the contents and then converts that source material into every electronic version of the book that will be shipped, including what is sent to the print-on-demand systems for generating the ink-on-paper versions. This is similar to how one source code revision is used to generate binaries for different deliverables – OSX, Windows, linux, iOS, Android,…
O’Reilly has all the automation and infrastructure you would expect from a professional-grade Release Engineering team. Access controls, hosted repos, hosted automation, status dashboards, tools to help you debug error messages, teams to help answer any support questions as well as maintain and improve the tools. Even a button that says “Build!”!! 
The only difference is that the product shipped from the automation is a binary that you view in an e-reader (or send to a print-on-demand printing press), instead of a binary that you invoke to run as an application on your phone/desktop/server. With this mindset, and all this automation, it is no surprise that O’Reilly also does rapid releases of books, for the same reasons software companies do rapid releases. Very cool to see.
I’ve been thinking about this a lot recently because I’m now putting together my first “early release” of my book-in-progress. More info on the early release in the coming days when it is available. As a release engineer and first time author, I’ve found the entire process both totally natural and self-evident and at the same time a little odd and scary. I’d be very curious to hear what people think… both of the content of the actual book-in-progress, and also of this “rapid release of books” approach.
Meanwhile, it’s time to refill my coffee mug and get back to typing.
John.
|
|
Gervase Markham: Top 50 DOS Problems Solved: Recursive Delete |
Q: What is the quickest way to delete all the files in a sub-directory, plus all the files in any sub-directories inside it, and so on as deep as directories go, along with the sub-directories themselves? In other words how do you delete an entire branch of sub-directories within sub-directories without typing a lot of DEL, CD and RD commands?
A: There is no easy way for DOS to do this unassisted. The nearest any version comes is DR DOS which can delete the files, but not remove the sub-directories themselves. The relevant command is:
XDEL *.* /S
No version of MS-DOS can automatically delete files in sub-directories. To do the job in its entirety you need a third-party tree pruning utility. You can often find these in PD/shareware libraries. Alternatively, commercial disk utilities such as Xtree will do it.
Leaving aside the amazingness of not having recursive delete, I wonder why the DR-DOS folk decided to produce a command which removed the files but not the directories?
http://feedproxy.google.com/~r/HackingForChrist/~3/NBR2g3qoR5w/
|
|
Air Mozilla: Martes mozilleros |
 Reuni'on bi-semanal para hablar sobre el estado de Mozilla, la comunidad y sus proyectos.
Reuni'on bi-semanal para hablar sobre el estado de Mozilla, la comunidad y sus proyectos.
|
|
QMO: Firefox 42.0 Aurora Testday Results |
Hey all!
Last Friday, September 11th, we held Firefox 42.0 Aurora Testday. It was another successful event (please see the results section below), we had quite a number of participants
https://quality.mozilla.org/2015/09/firefox-42-0-aurora-testday-results/
|
|
Gervase Markham: 10 Reasons Not To Use Open Source |
I was browsing the Serena website today, and came across a white paper: “Time to harden the SDLC. Open Source: does it still make sense? (10 reasons enterprises are changing their policies)”. You are required to supply personal information to download a copy, and they force this by only providing the link by email. However, intrigued, I requested one.
Apparently, enterprises are questioning their use of Open Source software (presumably in the specific area of software development) because:
The list ends with this wonderfully inconsistent paragraph:
All of this seems very alarmist: what is the true situation? The truth is no one really knows because no one is talking about it. There is a clear, present and obvious danger from using open source solutions in support of your technology stack. You have to decide if the risk is worth it.
No-one really knows, but there’s a clear, present and obvious danger? I see. The only clear, present and obvious danger demonstrated here is the one that git is posing to Serena’s business…
http://feedproxy.google.com/~r/HackingForChrist/~3/PFRBNgvpqYM/
|
|
Daniel Stenberg: Yours truly on “kodsnack” |
 Kodsnack is a Swedish-speaking weekly podcast with a small team of web/app- developers discussing their experiences and thoughts on and around software development.
Kodsnack is a Swedish-speaking weekly podcast with a small team of web/app- developers discussing their experiences and thoughts on and around software development.
I was invited to participate a week ago or so, and I had a great time. Not surprisingly, the topics at hand moved a lot around curl, Firefox and HTTP/2. The recorded episode has now gone live, today.
You can find kodsnack episode 120 here, and again, it is all Swedish.
http://daniel.haxx.se/blog/2015/09/15/yours-truly-on-kodsnack/
|
|
Emma Irwin: My Volunteer Opportunities this Heartbeat |
I am returning from a couple of weeks away: rested and super-energized about what’s coming next for the Participation Team and community leadership.
Based on research in the last two heartbeats we have now have an v.1 of Participation Leadership Framework, and we’re fired up and ready to go for the next three weeks developing and testing curriculum in line with that framework.
Volunteer sub-tasks volunteer for my heartbeat are: Curriculum QA and ‘Workshop Co-pilot’. The first is really just about staying connected to the work, and providing feedback and suggestions through review. The second is more of a role for this heartbeat, for someone interested in improving as a facilitator by co-piloting a couple of online workshops with me, and then running an offline version with local contributors in their region. Please reach out in the task comments if you are excited about doing something like this! As with previous volunteer tasks, there are more details in the issue.
Note: we also have ongoing development work on a fork of teach.mozilla.org in an effort to test the import and display external markdown files as content. Thanks to @asdofindia for his great work and recent Pull Request to help this along.
For more on contributing with the Participation Team and the Heartbeat process check out our contribute.md.
That’s it! Except as a final thing I thought I would share all the books that were recommended to me when I asked for suggestions for my time away. I highly recommend time away with books.
http://tiptoes.ca/my-volunteer-opportunities-this-heartbeat/
|
|
Mark C^ot'e: MozReview Meet-Up |
Two weeks ago the MozReview developers got together to do some focussed hacking. It was a great week, we got a lot of stuff done, and we clarified our priorities for the coming months. We deployed several new features and improvements during the week, and we made good progress on several other goals.
For this week, we actually opted to not go to a Mozilla office and instead rented an AirBNB in Montreal—our own little hacker house! It was a great experience. There was no commuting (except for me, since I live here and opted to sleep at my house) and no distractions. One evening when we were particularly in the zone, we ordered a bunch of pizzas instead of going out, although we made sure to take breaks and go outside regularly on all the other days, in order to refresh our minds. Five out of five participants said they’d do it again!
See also dminor’s post about the week, with a bit more detail on what he worked on.
My main contribution to the week was finally switching MozReview to Bugzilla’s API-key-based authentication-delegation system. I’d been working on this for the last couple months when I found time, and it was a big relief to finally see it in action. I won’t go into detail here, since I’ve already blogged about it and announced it to dev.platform.
gps, working amazingly fast as always, got API-key support working on the command line almost immediately after UI support was deployed. No more storing credentials or login cookies!
Moving on, we know the MozReview’s UI could… stand some improvement, to say the least. So we split off some standalone work from Autoland around clarifying the status of reviews. Now in the commit table you’ll see something like this:
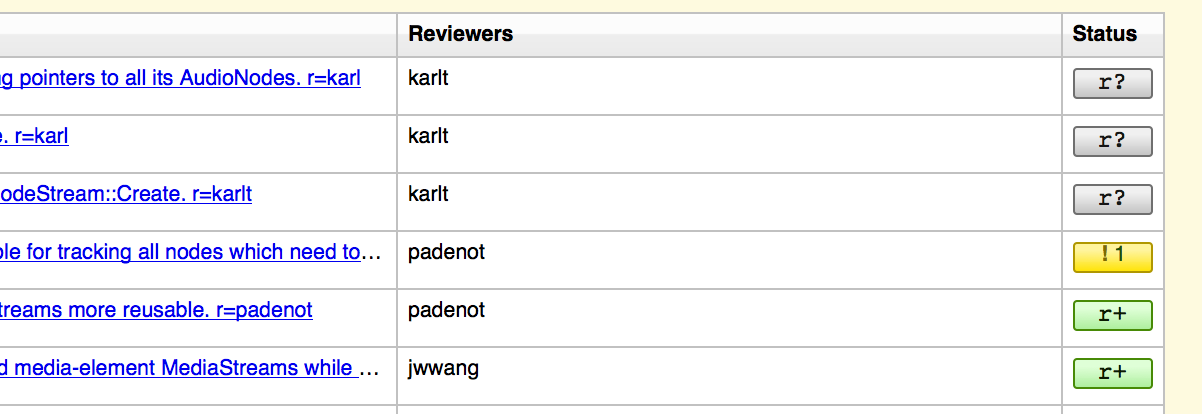
This warrants a bit of explanation, since we’re reusing some terms from Bugzilla but changing them a little.
r+ indicates at least one ship-it, subject to the following:
The reason for the L3 requirement is for Autoland. Since a human won’t necessarily be looking at your patch between the time that a review is granted and the commit landing in tree, we want some checks and balances. If you have L3 yourself, you’re trusted enough to not require an L3 reviewer, and vice versa. We know this is a bit different from how things work right now with regards to the checkin-needed flag, so we’re going to open a discussion on mozilla.governance about this policy.
If one or more reviewers have left any issues, the icon will be the number of open issues beside an exclamation mark on a yellow backgroud. If that or any other reviewer has also left a ship-it (the equivalent of an “r+ with minor issues”), the issue count will switch to an r+ when all the issues have been marked as fixed or dropped.
If there are no open issues nor any ship-its, a grey r? will be displayed.
We’ve also got some work in progress to make it clearer who has left what kind of review that should be live in a week or two.
We also removed the ship-it button. While convenient if you have nothing else to say in your review, it’s caused confusion for new users, who don’t understand the difference between the “Ship It!” and “Review” buttons. Instead, we now have just one button, labelled “Finalize Review”, that lets you leave general comments and, if desired, a ship-it. We plan on improving this dialog to make it easier to use if you really just want to leave just a ship-it and no other comments.
Finally, since our automation features will be growing, we moved the Autoland-to-try button to a new Automation menu.
As alluded to above, we’re actively working on Autoland and trying to land supporting features as they’re ready. We’re aiming to have this out in a few weeks; more posts to come.
Much of the rest of our plan for the next quarter or two is around user experience. For starters, MozReview has to support the same feature set as Splinter/Bugzilla. This means implementing things like marking files as reviewed and passing your review onto someone else. We also need to continue to improve the user interface by further differentiating between parent review requests, which are intended only to provide an overview of the whole commit series, and child review requests, which is where the actual reviews should happen. Particularly confusing is when there’s only one child, which means the parent and the child are nearly indistinguishable (of course in this case the parent isn’t really needed, but hiding or otherwise doing away with the parent in this case could also be confusing).
And then we have some other big-ticket items like static analysis, which we started a while back; release-management tools; enabling Review Board’s rich emails; partial-series landing (being able to land earlier commits as they are reviewed without confusing MozReview in the next push); and, of course, git support, which is going to be tricky but will undoubtedly make a number of people happy.
Our priorities are currently documented on our new road map, which we’ll update at least once or twice a quarter. In particular, we’ll be going over it again soon once we have the results from our engineering-productivity survey.
|
|
Air Mozilla: Mozilla Weekly Project Meeting |
 The Monday Project Meeting
The Monday Project Meeting
https://air.mozilla.org/mozilla-weekly-project-meeting-20150914/
|
|
Henrik Skupin: mozdownload 1.18 released |
Today we have released mozdownload 1.18 to PyPI. The reason why I think it’s worth a blog post is that with this version we finally added support for a sane API. With it available using the mozdownload code in your own script is getting much easier. So there is no need to instantiate a specific scraper anymore but a factory scraper is doing all the work depending on the options it gets.
Here some examples:
from mozdownload import FactoryScraper
scraper = FactoryScraper('release', version='40.0.3', locale='de')
scraper.download()
from mozdownload import FactoryScraper
scraper = FactoryScraper('candidate', version='41.0b9', platform='win32')
scraper.download()
from mozdownload import FactoryScraper
scraper = FactoryScraper('daily', branch='mozilla-aurora')
scraper.download()
If you are using mozdownload via its API you can also easily get the remote URL and the local filename:
from mozdownload import FactoryScraper
scraper = FactoryScraper('daily', branch='mozilla-aurora')
print scraper.url
print scraper.filename
Hereby the factory class is smart enough to only select those passed-in options which are appropriate for the type of scraper. If you have to download different types of builds you will enjoy that feature given that only the scraper type has to be changed and all other options could be still passed-in.
We hope that this new feature will help you by integrating mozdownload into your own project. There is no need anymore by using its command line interface through a subprocess call.
The complete changelog can be found here.
http://www.hskupin.info/2015/09/14/mozdownload-1-18-released/
|
|
Niko Matsakis: LALRPOP |
Around four years ago, when I had first decided to start at Mozilla research, I had planned to write an LR(1) parser generator. It seemed like a good way to get to know Rust. However, I found that newborns actually occupy somewhat more time than anticipated (read: I was lucky to squeeze in a shower), and hence that never came to pass.
Well, I’m happy to say that, four years later, I’ve finally rectified
that. For a few months now I’ve been working on a side project while I
have my morning coffee: LALRPOP (pronounced like some sort of
strangely accented version of lollypop
). LALRPOP is an LR(1)
parser generator that emits Rust code. It is designed for ease of use,
so it includes a number of features that many parser generators are
missing:
Id* for any number of `Id`or
Id? for an optional `Id`.
Comma that
means comma separated list of `Id` with optional trailing comma.
{).matchable valueswill do.
If you’d like to learn more about LALRPOP, I recently started a tutorial that introduces LALRPOP in more depth and walks through most of its features. The tutorial doesn’t cover everything yet, but I’ll try to close the gaps.
Why LR(1)? After all, aren’t LR(1) generators kind of annoying, what with those weird shift/reduce errors? Well, after teaching compiler design for so many years, I think I may have developed Stockholm syndrome – I kind of enjoy diagnosing and solving shift/reduce failures. ;) But more seriously, I personally like that once I get my grammar working with an LR(1) generator, I know that it is unambiguous and will basically work. When I’ve used PEG generators, I usually find that they work great in the beginning, but once in a while they will just mysteriously fail to parse something, and figuring out why is a horrible pain. This is why with LALRPOP I’ve tried to take the approach of adding tools to make handling shift/reduce errors relatively easy – basically automating the workarounds that one typically has to do by hand.
That said, eventually I would like LALRPOP to support a bunch of
algorithms. In particular, I plan to add something that can handle
universal CFGs, though other deterministic techniques, like LL(k),
would be nice as well.
Performance. Another advantage of LR(1), of course, it that it offers linear performance. That said, I’ve found that in practice, parsing based on a parsing table is not particularly speedy. If you think about it, it’s more-or-less interpreting your grammar – you’ve basically got a small loop that’s loading data from a table and then doing an indirect jump based on the results, which happen to be the two operations that CPUs like least. In my experience, rewriting to use a recursive descent parser is often much faster.
LALRPOP takes a different approach. The idea is that instead of a
parsing table, we generate a function for every state. This ought to
be quite speedy; it also plays very nicely with Rust’s type system,
since types in Rust don’t have uniform size, and using distinct
functions lets us store the stack in local variables, rather than
using a Vec. At first, I thought maybe I had invented something new
with this style of parsing, but of course I should have known better:
a little research revealed that this technique is called
recursive ascent.
Now, as expected, recursive ascent is supposed to be quite fast. In fact, I was hoping to unveil some fantastic performance numbers with this post, but I’ve not had time to try to create a fair benchmark, so I can’t – since I haven’t done any measurements, LALRPOP’s generated code may in fact be quite slow. I just don’t know. Hopefully I’ll find some time to rectify that in the near future.
100% stable Rust. It’s probably worth pointing out that LALRPOP is 100% stable Rust, and I’m committed to keeping it that way.
Other parser generators. Should LALRPOP or LR(1) not be too your fancy, I just want to point out that the Rust ecosystem has grown quite a number of parser combinator and PEG libraries: nom, oak, peg, nailgun, peggler, combine, parser-combinators, and of course my own rusty-peg. I’m not aware of any other LR(1) (or GLL, GLR, etc) generators for Rust, but there may well be some.
Future plans. I’ve got some plans for LALRPOP. There are a host of new features I’d like to add, with the aim of eliminating more boilerplate. I’d also like to explore adding new parser algorithms, particularly universal algorithms that can handle any CFG grammar, such as GLL, GLR, or LL(*). Finally, I’m really interesting in exploring the area of error recovery, and in particular techniques to find the minimum damaged area of a parse tree if there is an incorrect parse. (There is of course tons of existing work here.)
Plea for help. Of course, if I wind up doing all of this myself, it might take quite some time. So if you’re interested in working on LALRPOP, I’d love to hear from you! I’d also love to hear some other suggestions for things to do with LALRPOP. One of the things I plan to do over the next few weeks is also spend some more time writing up plans in LALRPOP’s issue database, as well as filling out its wiki.
http://smallcultfollowing.com/babysteps/blog/2015/09/14/lalrpop/
|
|
Daniel Stenberg: The curl and wget war |
“To be honest, I often use wget to download files”
… some people tell me in a lowered voice, like if they were revealing one of their deepest family secrets to me. This is usually done with a slightly scared and a little ashamed look in their eyes – yet still intrigued, like it took some effort to say that straight in my face. How will I respond to that!?
I enjoy maintaining a notion that there is a “war” between curl and wget. Like the classics emacs vs vi or KDE vs GNOME. That we’re like two rivals competing for some awesome prize and both teams are glaring at the other one and throwing the occasional insult over the wall at the competing team. Mostly because people believe it and I sort of like the image it projects in my brain. So I continue doing jokes about it when I can.

In reality though, where some of us spend our lives, there is no such war. There’s no conflict or backstabbing going on. We’re quite simply two open source projects busy doing our own things and we’ve both been doing it for almost two decades. I consider the current wget maintainer, Giuseppe, a friend and I’m friends with the two former maintainers as well.
We have more things in common than what separates us. We’re like members of the fairly exclusive HTTP/FTP command line tool club that doesn’t have that many members.
We don’t have a lot of developer overlap, there are but a few occasional contributors sending patches to both projects and I’m one of them. We have some functional overlap in the curl tool with wget but really, I strongly recommend everyone to always use the best tool for the job and to use the tool they prefer. If wget does the job, use it. If it does the job better than curl, then switch to wget.
There’s been a line in the curl FAQ since over 15 years: “Never, during curl’s development, have we intended curl to replace wget or compete on its market.” and it tells the truth. We are believers in the Unix philosophy that each tool does what it does best and you get your job done best by combining the right set of tools. In the curl project we make one command line tool and we make it as good as we can, but we still urge our users to use the best tool for the job even when that means not using our tool.
All this said, there are plenty of things, protocols and features that curl does that you cannot find in wget and that wget doesn’t do. I’ve detailed some differences in my curl vs wget document. Some things that both can do are much easier to do with curl or offer you more control or power than in the wget counter part. Those are the things you should use curl for. Use the best tool for the job.
What takes the most effort in the curl project (and frankly that gets used by the largest amount of users in the world) is the making of the libcurl transfer library to which there is no alternative in the wget project. Writing a stable multi platform library with a sensible and solid API is much harder and lots of more work than writing a command line tool.
OK, I’ll stop tip-toeing and answer the question you really wanted to know while enduring all this text up until this point:
When do you suggest I use wget instead of curl?
For me, wget is for recursive gets and for doing more persistent and patient retries of continuing transfers over really bad connections and networks better. But then you really must take my bias into account and ignore anything I say because I live and breath the curl life.
http://daniel.haxx.se/blog/2015/09/14/the-curl-and-wget-war/
|
|
This Week In Rust: This Week in Rust 96 |
Hello and welcome to another issue of This Week in Rust! Rust is a systems language pursuing the trifecta: safety, concurrency, and speed. This is a weekly summary of its progress and community. Want something mentioned? Tweet us at @ThisWeekInRust or send us an email! Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub. If you find any errors in this week's issue, please submit a PR.
This week's edition was edited by: nasa42 and llogiq.
79 pull requests were merged in the last week.
Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
No RFCs were approved this week!
Every week the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now. This week's FCPs are:
std::net module to bind more low-level interfaces.Box::leak to leak Box to &'static mut T.repr(packed) structs should be unsafe.dropck) part of Rust's static analyses.If you are running a Rust event please add it to the calendar to get it mentioned here. Email Erick Tryzelaar or Brian Anderson for access.
No jobs listed for this week. Tweet us at @ThisWeekInRust to get your job offers listed here!
This is a new part of this weekly installation, where we will write about a crate that some of you may not know. Please nominate a crate of your choice at the rust-users thread so we can write about it next week.
This week, Crate of the Week is clap. Thanks go to eternaleye for the suggestion.
Quoting eternaleye verbatim:
I'm going to say kbknapp's clap crate - I have never, in any language I have ever worked in, had an argument parsing library that was so completely painless. I've found it especially nice for mocking up the skeleton of a tool where all roads lead to panic!(), then splitting it up further and further, pushing the panic!()s down the branching logic of what to actually do, until a whole utility has appeared from nowhere.
On #rust-offtopic IRC
03:46 < durka42> rust has a culture of small crates
03:47 < XMPPwocky> a Cargo cult, if you will
Thanks to Manishearth for the tip. Submit your quotes for next week!.
http://this-week-in-rust.org/blog/2015/09/14/this-week-in-rust-96/
|
|






