Анатомия инцидента, или как работать над уменьшением downtime |
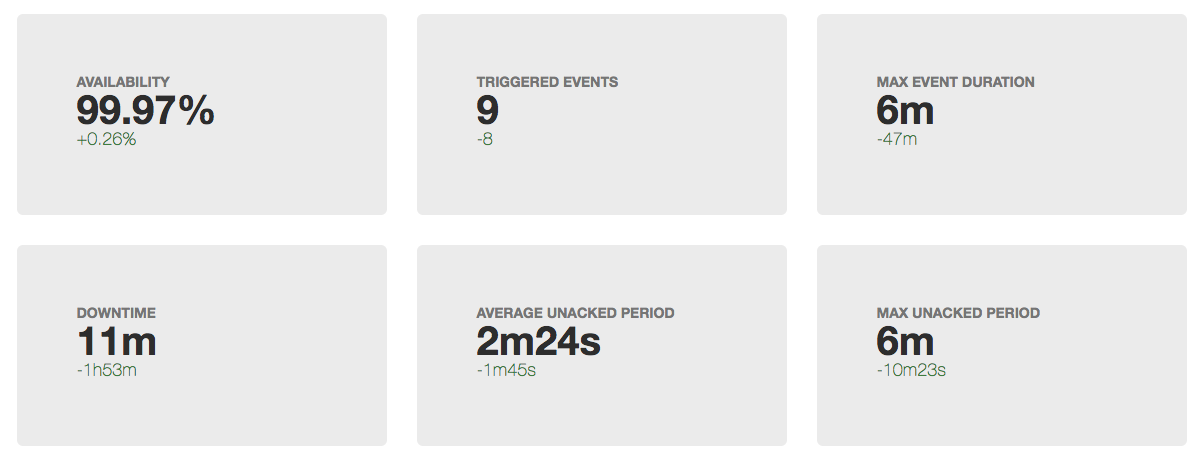
Рано или поздно в любом проекте настает время работать над стабильность/доступностью вашего сервиса. Для каких-то сервисов на начальном этапе важнее скорость разработки фич, в этот момент и команда не сформирована полностью и технологии выбираются не особо тщательно. Для других сервисов (чаще технологические b2b) для завоевания доверия клиентов необходимость обеспечения высокого uptime возникает с первым публичным релизом. Но допустим, что момент X все-таки настал и вас начало волновать, сколько времени в отчетный период "лежит" ваш сервис. Под катом я предлагаю посмотреть, из чего складывается время простоя, и как эффективнее всего работать над его уменьшением.
Читать дальше ->https://habr.com/post/422973/?utm_source=habrahabr&utm_medium=rss&utm_campaign=422973
| Комментировать | « Пред. запись — К дневнику — След. запись » | Страницы: [1] [Новые] |






