[Перевод] Обработка данных NBA за 30 лет с помощью MongoDB Aggregation
|
|
Пятница, 19 Декабря 2014 г. 16:30
+ в цитатник
Прим. перев.: Американский писатель Майкл Льюис известен не только своими историями о трейдерах с Уолл Стрит, но и (в первую очередь) книгой Moneyball, по которой впоследствии был снят одноименный фильм («Человек, который изменил все»). Главный ее герой – Билли Бин, генеральный менеджер бейсбольной команды «Oakland Athleticks», создает конкурентоспособную команду исключительно на основе анализа статистических показателей игроков.
Памятуя об этом, мы решили опубликовать один любопытный материал о том, к каким интересным и нетривиальным выводам можно прийти, анализируя публично доступную статистику игр NBA за последние 30 лет с помощью фреймворка MongoDB Aggregation. Несмотря на то, что в данном примере автор анализирует показатели команд в целом, а не статистику по отдельным игрокам (она также находится в открытом доступе), он приходит к весьма занимательным выводам – руководствуясь его выкладками вполне реально провести самостоятельный анализ, подобно тому, как в свое время поступили герои Moneyball.
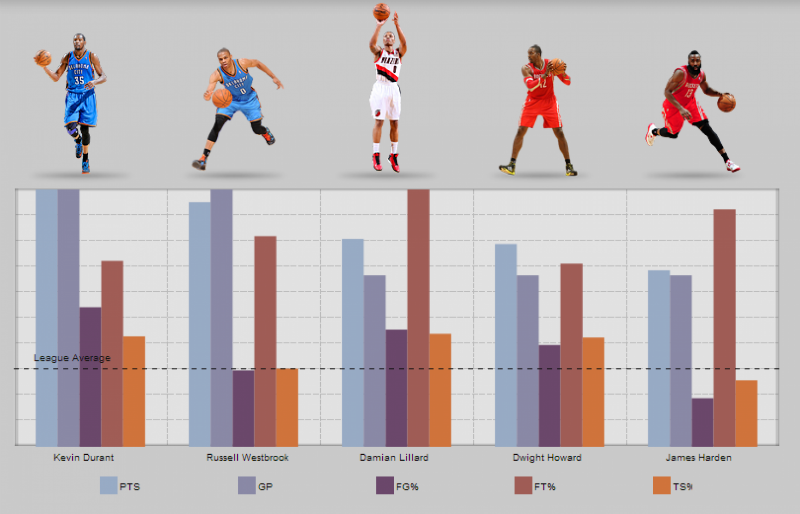
При поиске средства анализа массивов данных больших объемов и сложной структуры вы можете инстинктивно обратиться к Hadoop. С другой стороны, если вы храните свои данные в MongoDB, использование Hadoop Connector кажется излишним, особенно если все ваши данные помещаются на ноутбук. К счастью, встроенный
фреймворк MongoDB Aggregation предлагает быстрое решение для проведения комплексной аналитики прямо с экземпляра MongoDB без установки дополнительного ПО.
Читать дальше → http://habrahabr.ru/post/246317/
Метки:
Блог компании ITinvest
Big Data
Администрирование баз данных
mongodb
Разработка
НБА
Майкл Льюс
статистика
анализ данных
-
Запись понравилась
-
0
Процитировали
-
0
Сохранили
-






