Что делать, когда выпускник топ-10 мирового вуза не может спроектировать блок сложения A+B |

У меня был в свое время практикант из Стенфорда, от которого я получил инсайдерскую информацию, чему их там учат. Потом я интервьировал много студентов, и понял, что если человек не делает самостоятельных проектов в вузе, а просто плывет по течению программы как медуза, то будучи выброшенным на берег индустрии, он становится совершенно беспомощным.
Когда я вижу у недавнего выпускника в резюме какой-то из протоколов в котором используется valid/ready, например AXI или AHB, я прошу его спроектировать блок, у которого на входе два числа A и B, а на выходе их сумма. Разумеется не просто написать SUM=A+B, а еще и поставить valid/ready сигналы на каждый из A, B, SUM, чтобы A и B могли приходить в разное время, а также чтобы блок ждал, если SUM не может быть передана другому блоку сразу.
Некоторые не справляются. Грустно смотреть на человека, который потратил 6 лет своей жизни (4 года в бакалавриате и 2 года в магистратуре) и океан денег на образование – и не может сложить два числа и бьется как угорь на сковородке. То блок не работает когда числа приходят в разное время, то создатель забывает снять valid, и блок на 2+2 выдает не 4, а 4-4-4-4-4-4-4… То числа складываются не попарно, а просто записываются в регистры и на выход идет их текущая сумма, хотя количество аргументов A и B не совпадает. То не отрабатывается backpressure и результаты теряются, то (после того как кандидат написал страницу кода на верилоге) блок работает на половинной производительности, то есть не может принимать поток чисел подряд, а ожидает между ними пропуски (gaps). Короче ведет себя как ChatGPT.

Конечно, если студент сам во время учебы делает скажем правильные open-source проекты, то он вписывается в индустрию легче. Но все равно компании тратят много усилий на переподготовку недавних студентов. Некоторые электронные компании нанимают профессиональных тренеров типа Клифа Каммингса, которые берут три тысячи долларов за неделю трейнинга за_каждого_студента.
Я в свое время пытался привезти Клиффа в Россию, но в первую попытку звезды не сошлись (хотя все топ российские электронные компании согласились прислать по одному-два инженера). А во второй раз настала международная напряженность и все накрылось – Клифф продал свою компанию бОльшей трейнинг-компании и там менеджер не захотел.

Я это все к чему – я на днях прочитал на Хабре что Ядро/Syntacore решили сделать целый внутренний курс для тренировки ASIC проектировщиков из бывших FPGA проектировщиков:

Это в принципе крутая идея, так как отличия front-end ASIC от FPGA инженеров не такие уж большие:
Замечу что Элон Маск в свой SpaceX сейчас интервьирует на смешанную ASIC/FPGA позицию:

Но что делать тем, кто еще не готов идти в Ядро/Syntacore и хочет натренировать себя в FPGA? Предположим, что у вас есть некий начальный опыт, например почерпнутый из источников, которые я перечислил в презентации для проектов в Средней Азии, курса в ВШЭ МИЭМ или скажем по ссылкам из телеграм-каналов fpgasystems , tinyurl.com/yy79xfer, DigitalDesignSchool , сайта ранних энтузиастов FPGA в России marsohod.org итд:

Следующий шаг – набрать опыта на открытых проектах, и у меня как раз есть такой проект, для которого я собираю команду. Это проект YRV-Plus, см. поддерево Plus в репозитории github.com/yuri-panchul/yrv-plus . Суть проекта – накрутить опций вокруг RISC-V ядра микроконтроллерного класса под названием YRV. В том числе:
В частности нужно спортировать YRV на плату Tang Primer 20K c китайским GoWwin FPGA, с которой на фотографии слева работает мой приятель Александр Белиц, инженер из компании Marwell. Эта плата недорогая и вместительная, использует систему разработки от GoWin, которая является альтернативой Intel FPGA Quartus и Xilinx Vivado.
Также в частности стоит спортировать YRV на плату Digilent Nexys4 DDR, которую держит в руках девушка Ирина из Новосибирского Академгородка. Эту плату с системой разработки Xilinx Vivado используют большое количество вузов.

Почему именно процессорное ядро YRV, хотя вокруг этих RISC-V ядер немерянное количество? По комбинации факторов:

К нашей open-source команде, помимо Монте, меня и Белица, присоединился Дмитрий Петренко. Дмитрий одолжил несколько альтеровских плат от программы одалживания FPGA плат Михаила Коробкова и перенес на них YRV. Также Дмитрий написал линкер-скрипт и смог построить маршрут писания программ для YRV на Си (hello world). Вот платы Дмитрия в работе:
Мы недавно с Александром Белицем обедали с Монте Делримплом в Ливерморе, городе, который был недавно в новостях по поводу термояда. Монте там живет. В центре города стоит скульптура – вращающийся шар с фонтаном и надписями про российcко-американское сотрудничество в физике. Кстати по странам происхождения четыре участника проекта являются выходцами из четырех стран – России, Украины, Белоруссии и США – угадайте кто откуда.
Так что присоединяйтесь пятым и более. Репозиторию можете форкнуть у меня или у Дмитрия (ссылка выше). Мы проводим еженедельные созвоны в 9 утра в воскресенье по Калифорнии (это 20.00 вечера воскресенье по Москве).
Но если вы уже изучили простые процессоры и основы FPGA, присоединяйтесь сразу к Ядру/Syntacore . Если нет – можете еще пройти курс лабораторных от МИЭТ по проектированию однотактного процессора с прерываниями и периферией (видео их лекций). И потом присоединиться к новому проекту MIRISC в МИЭТ с более сложным конвейером. Это ситуация “пусть цветут все цветы, заимствуют и меряются друг с другом”
|
|
Камерон о поставке оружия на Украину, опухоль мозга у принца Британии и другие фейки от ChatGPT |

ChatGPT давно заслужил помещение в Миротворец. Хотите сгенерировать речь Зеленского в российской Госдуме с предложением Крыма в обмен на мир? Этого вам ChatGPT сделать не даст, так как в нем стоит блокировка обсуждения Крыма, но если заменить слово «Крым» словосочетанием «территориальные концессии», то ChatGPT генерит речь на «ура».
Готовы к реальному хардкору? Как насчет связать рак мозга в британской королевской семье с проблемой украинских беженцев в Европе? Да ни вопрос!
Но начнем с чего-нибудь более нейтрального. ChatGPT, сгенери речь режиссера фильма Аватар к Конгрессу США с просьбой остановить поставку оружия Украине. А также (второй вариант) с призывом увеличить поставки:

Хорошо, как насчет того же самого от автора теории «конца истории» Фрэнсиса Фукуямы? «Вжик» — сказала электропила (если вы знаете этот анекдот):

А что если вложить это в уста президента Японии и для обоснования взять популярную во времена пика «японского чуда» книжку «Япония может сказать Нет!»? Да ни вопрос, банзай как говорится:

Прибавить немного цинизма? Ну ОК:

Сделать это троллическим и именем короля? Пожалуйста:

Что же ChatGPT не разрешает? Помимо обсуждения Крыма он не разрешает сочинять речи для Путина. Но не против, если заказать историю о Майдане от солдата ДНР. Правда в эту историю, как ни перекручивать запрос, будет вставляться ровно одна однобитовая манихейская трактовка Добра и Зла. Что показывает, что политоту в ChatGPT вбили ручками, а не просеиванием через него петабайтов данных из интернета.

Ну и напоследок — обещанная история про принца. Просто помещая в один абзац тяжелые заболевания, британскую королевскую семью и Украину, можно автоматически генерить годную тролятину для интернет-хомячков:

Правильно сказал комментатор в The Verge, что нужно нанять «реальных американцев» которые бы ограждали общество от этого:

|
|
День Рождения 2022 |
|
|
AI как угроза удаленным собеседованиям на работу. ChatGPT = CheatGPT? |

У меня по всей френдленте идут хиханьки-хаханьки про ChatGPT - одни восторгаются ее гениальностью, а другие тупостью. А вот я вчера осознал стремную вещь - вероятно ChatGPT уже стали использовать во время удаленных интервью на работу. Просто я дал ChatGPT тот же вопрос, который я задал кандидату во время недавнего интервью, и ChatGPT сгенерил мне код с теми же ошибками - сделал upstream ready не output, а input например, потом сделал код с gap-ами на входе, а потом просто слил, заявив что слишком много запросов.
У меня недостаточно информации для обсуждения природы GPT. В него за 6 лет вложили миллиарды и один из участников - это компания в Индии с большим количеством программистов. То есть они могли экстенсивно натаскать программу на простые вопросы типа "напиши код для декодера" и их комбинации "напиши мультплексор как комбинацию декодера и селектора". Легко угадать, что куча людей будут пытаться сбивать GPT запросами про редкие языки программирования (Algol-60, ABEL) и можно прикинуться ветошью если языка не знаешь (на мой запрос написать нечто на Snobol-4 GPT стал писать на Algol-60). В сложных вопросах GPT ведет себя как Eliza 1964-го года (см. вопрос про конвейерный PDP-11 с автоинкрементной адресацией).
Но во всем этом хайпе есть важная практическая часть, которую стоит учесть немедленно. На интервью через zoom больше нельзя давать кандидатам воспросы, на которые "на троечку" может ответить GPT, запущенная в соседнем окне. В принципе, от кандидатов можно требовать написать к собственному ответу тест и посмотреть, сможет ли он исправить косяки GPT (она делает косяки на всех вопросах кроме тривиальных и их комбинаций).
Также вариантом может быть делать coding интервью только в офисе, в комнате, отключенной от интернета, с полным обзором от интервьюера. Но после трех лет ковида это может быть трудно.
UPD: Также я заметил, что ChatGPT часто пишет в стиле, в котором писал бы программист, впервые увидевший верилог, а не проектировщик железа. Например использует initial для инициализации вместо сброса (что неверно по двум причинам: несинтезируемо для ASIC + multiple drivers). А также устаревший формат sensitivity list. То есть семантическую модель кодирования на верилоге им делал(и) программисты, которые воспринимают верилог как еще один язык программирования.




|
|
Серенада Трубадура в исполнении Юрия Панчула 2022-12-12 |
Для концерта студии Марии Беличенко исполнил серенаду Трубадура ("Луч солнца золотого" из мультфильма Возвращение Бременских Музыкантов.
https://mariaflute.com/
|
|
Как Америка любила и бодалась с Huawei — и как та ответила |

10 лет назад в Санта-Клара, Калифорния, неподалеку от Интела и NVidia, стоял кампус Huawei. В нем работали не только китайцы, но и вообще обычная публика Silicon Valley - индусы, американцы, даже русские попадались. Бизнесмены калифорнийских электронных компаний говорили "Huawei - это дверь в Китай" и заключали с ними крупные сделки.
Но американское правительство Huawei невзлюбило. Можно обсусоливать те или иные поводы, но коренная причина понятна - американскому правительству хочется, чтобы Америка сохраняла технологическое преимущество. Ибо если технология коммодифицируется и айфон не будет ничем особенным, то кто будет читать брошурки про продвижение демократии, распостраняемые американскими посольствами в других странах? Над ними будут просто смеяться.
И вот правительство начало Huawei жучить - и от Андроида отлучило, и от других критических технологий. Но на всяких хитрецов найдется гайка с левой резьбой. И вот что Huawei стал делать по этому поводу.
Но начнем по порядку. Вот как выглядел кампус Huawei на пересечении Central Expressway с San Tomas Expressway (Центральное Шоссе и Шоссе Святого Фомы Аквинского) в Санта-Кларе:

Я в эти здания заходил, так как работал с Huawei в совместном проекте от лица MIPS и даже получил за это табличку на стену:

Про сам проект прессе были известны только слухи, хотя с Huawei / HiSilicon работал не только MIPS, но и например IBM Microelectronics. Про IBM я узнал совершенно случайно, наткнувшись на инженера из этого проекта во время отпуска в Юте. Главное СМИ электронной промышленности, Electronic Engineering Times, писало про проект загадочно, в рубрике EE Times Confidential:

Потом настало это:

Но Huawei - не такая компания, чтобы покорно ползти в могилу из-за каких-то госдеповских бюрократов. Они бодро начали импортозамещение, в том числе в области программ для проектировщиков микросхем, и сразу наняли 50 молодых PhD на разработку алгоритмов EDA (Electronic Design Automation - автоматизация проектирования электроники, по русски САПР):

Я вспомнил про случай Huawei / HiSilicon, когда на днях мне прислал емейл Андрей Садовых из казанского Иннополиса и попросил придумать задачку для их хакатона по программам автоматизации проектирования CASE in Tools 2022.
Я уже участвовал в таком хакатоне как задачкодатель в 2020 году и описал задачку по трассировке и размещению логических элементов микросхемы на Хабре (пост до хакатона и после). Вот команда, которая решила мою задачку и получила приз:


Итак, новая задачка. Назовем ее "Подсчет количества D-триггеров в схеме на основе анализа кода на языке описания аппаратуры SystemVerilog (без учета оптимизации)".
Немного картины с высоты птичьего полета.
Разработчика блока микросхемы оценивают не только по отсутствию функциональных багов, но и по PPA - Power-Performance- Area или Энергопотребление-Производительность-Площадь. При этом:
Для грубой оценки площади под стандартные ячейки в микросхемах ASIC удобно использовать количество D-триггеров, минимальных элементов состояния / памяти. Это связано с тем, что пропорция ячеек комбинационной логики к количеству D-триггеров во многих типах схем статистически сходна и именно количество D-триггеров является узким местом. В FPGA ситуация несколько другая - там D-триггеров по сравнению с комбинационной логикой много и их не нужно так сильно экономить как в ASIC-ах.
Количество D-триггеров важно еще и потому, что своими переключениями они жрут много электроэнергии.
Короче, на проектировщика блока архитекторы чипа как правило спускают:
Суть задачи
Подсчитать количество комбинационных логических элементов в схеме, описанной на языке SystemVerilog - это однозначно не хакатонная задача - она требует сложной технологии логического синтеза. Но вот количество D-триггеров подсчитать гораздо проще - достаточно найти в коде все так называемые неблокирующие присваивания и суммировать размеры всех переменных, к которым они применяются.
Варианты задачи разной сложности
Разумеется, при этом возникает много трудностей. В зависимости от формулировки задачу подсчета D-триггеров на основе кода можно решить за любое время от 1 часа до 1 года. Перечислим эти трудности (потом мы перечислим их снова, но уже с картинками):
Инструментарий
Мне честно говоря самому интересно, до чего дойдут студенты. Как я уже сказал:
1) Простейший вариант (без иерархии, параметризации и с однобитовыми переменными) можно написать на языке типа питона или джавы за час.
2) Если использовать многобитовые переменные и многомерные массивы, на решение может уйти еще полдня, но того же питона тоже должно хватить. Возможно понадобиться применить регулярные выражения.
3) Модульная иерархия вносит дополнительные сложности. Помимо быстрого кодирования на питоне или джаве (на что может уйти день) стоит рассмотреть вариант освоить чужой парсер верилога на C++ (Icarus Verilog или Yosys) и модифицировать его для этой задачи.
Иллюстрации частных случаев
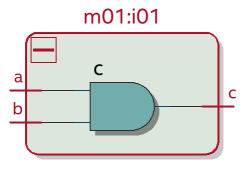
Теперь то же самое, но с картинками. Первые два модуля вообще не содержат никаких D-триггеров - в них нет ни always-блока по фронту, ни неблокирующих присваиваний ("<="). Только блокирующее внутри "always_comb" ("=") :

Такая схема синтезируется в двух-входовый логический элемент И:
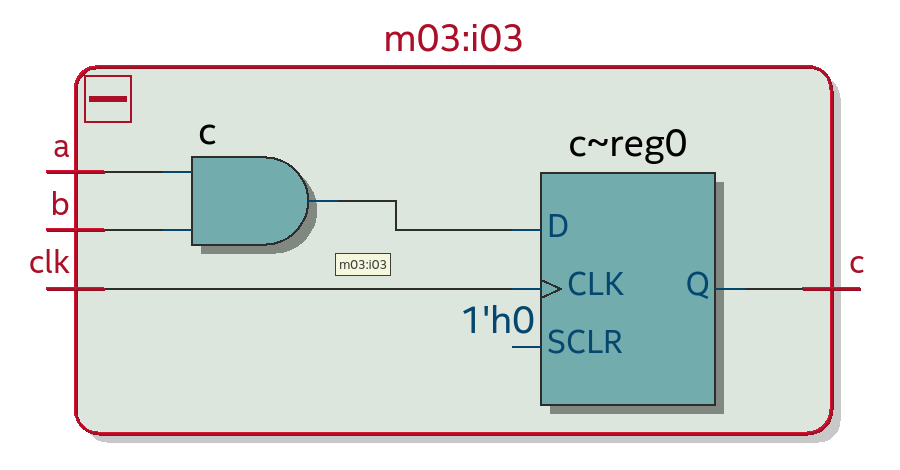
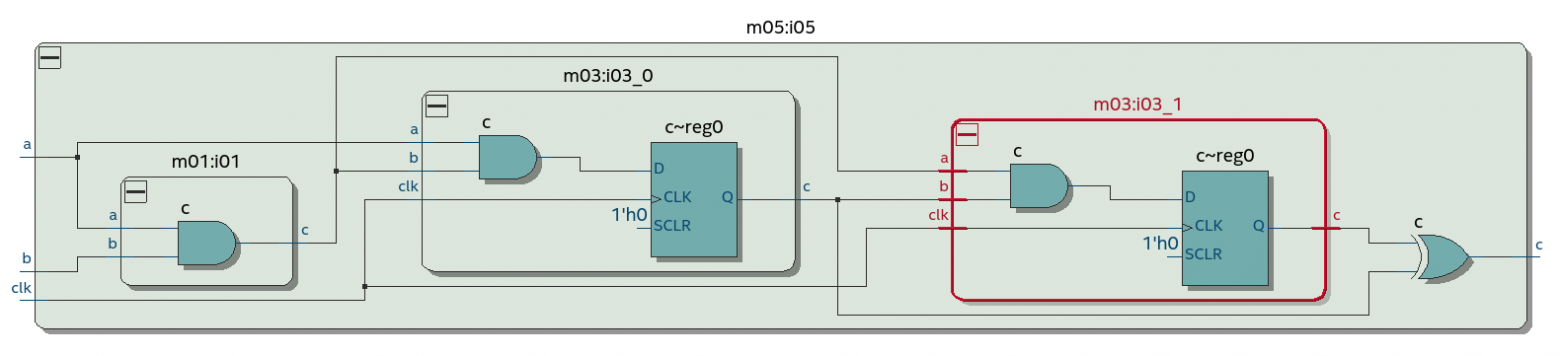
А вот как выглядит код, порождающий D-триггер. В нем есть неблокирующее присваивание ("<=") к переменной "c" которая объявлена как выходной порт и имеет размер 1 бит.
Неблокирующее присваивание находится внутри always-блока по фронту тактового сигнала (хакатонное решение может игнорировать этот факт, обращая внимание только на переменную, к которой применяется неблокирующее присваивание).
Также важно не спутать неблокирующее присваивание с операцией "меньше или равно" которая тоже пишется как "<=".

Этот код соответствует следующей схеме. Квадратик на ней - это D-триггер:
Несколько неблокирующих присваиваний к одной и той же переменной не порождают несколько D-триггеров. Но неблокирующие присваивания к разным переменным - порождают. В примере слева неблокирующие присваивания делаются двум однобитовым переменным, что порождает два D-триггера. Синхронные сбросы у этих D-триггеров перед оптимизацией превращаются в мультиплексоры, но это не важно для нашей цели подсчета D-триггеров:

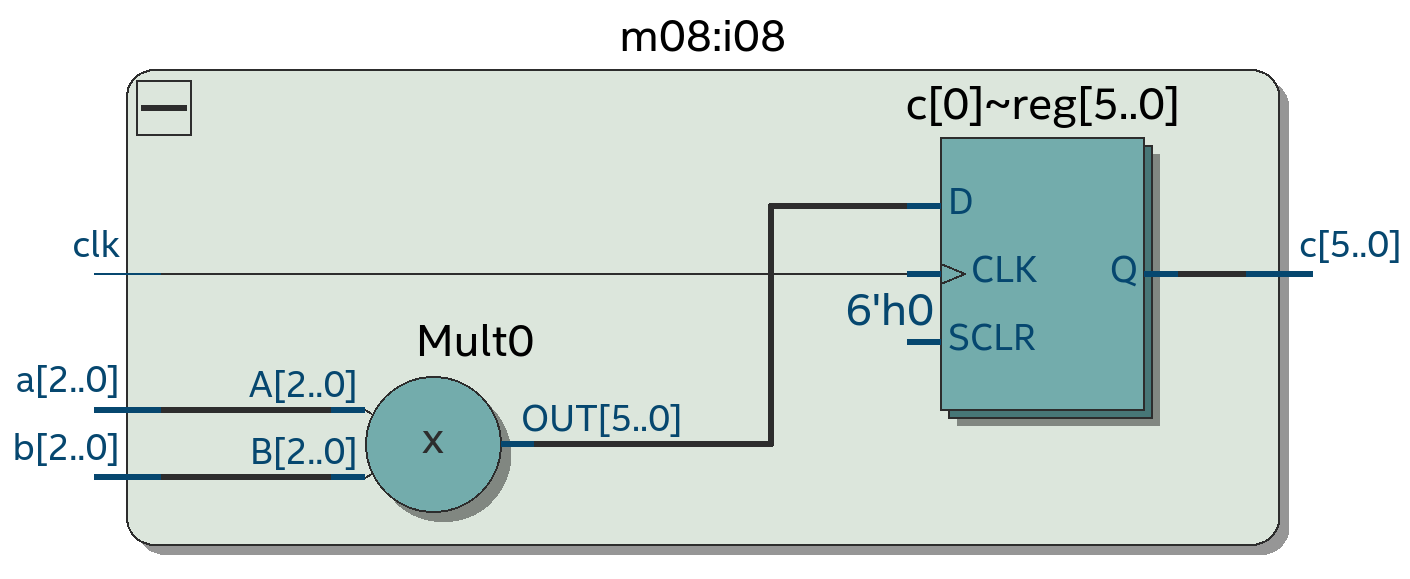
Следующее усложнение хакатона - это добавление переменных шириной в несколько бит. В примере ниже результат умножения двух 3-битных чисел "a" и "b" помещается в регистр "c" шириной 6 бит. Регистр - это просто группа из D-триггеров, которая в данном случае состоит из D-триггеров c[5], c[4], c [3], c [2], c[1] и c[0]:

Если усложнить задачу вне рамок хакатона, такой модуль можно параметризовать - либо с помощью препроцессора (слева), либо с помощью ключевого слова "parameter" справа:

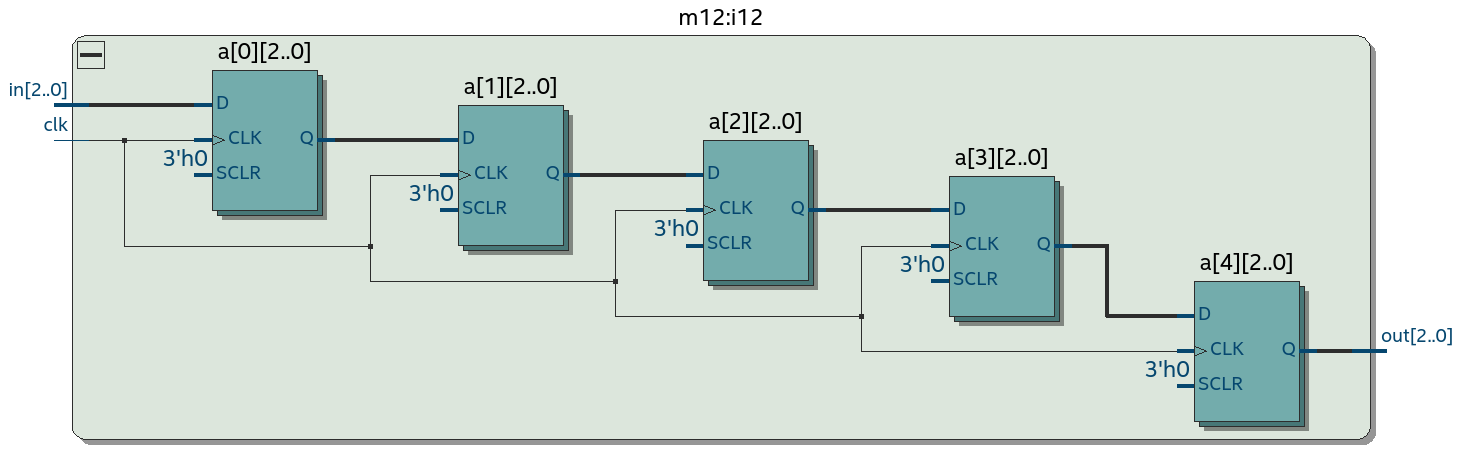
Другое важное усложнение, которое стоит сделать во время хакатона - это неупакованные массивы с размерностью справа от идентификатора. Слева пример схемы сдвигового регистра шириной 3 бита и глубиной 5 элементов, который использует 3 * 5 = 15 D-триггеров.

Вот как выглядит схема такого сдвигового регистра, обратите внимание что D-триггеры одного элемента собраны в "книжечки" по 3:
Стандарт SystemVerilog также поддерживает синтаксис "logic [2:0] a [5]" вместо "logic [2:0] a [0:4]". Вне рамок хакатона можно было бы написать программу, которая подсчитывает D-триггеры для сложных типов данных, например структур:

Наконец, было бы хорошо (возможно не на хакатоне, а после него) написать программу, которая бы парсировала иерархию модулей и подсчитывала D-триггеры на всех уровнях. Модули в верилоге как матрешки, за исключением того, что одной и той же матрешки может быть несколько экземпляров - D-триггеры во всех экземплярах нужно суммировать, это не как в софтвере с вызовами функций;


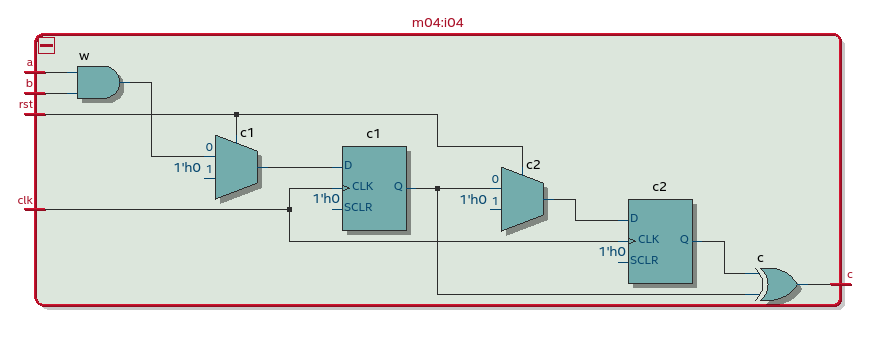
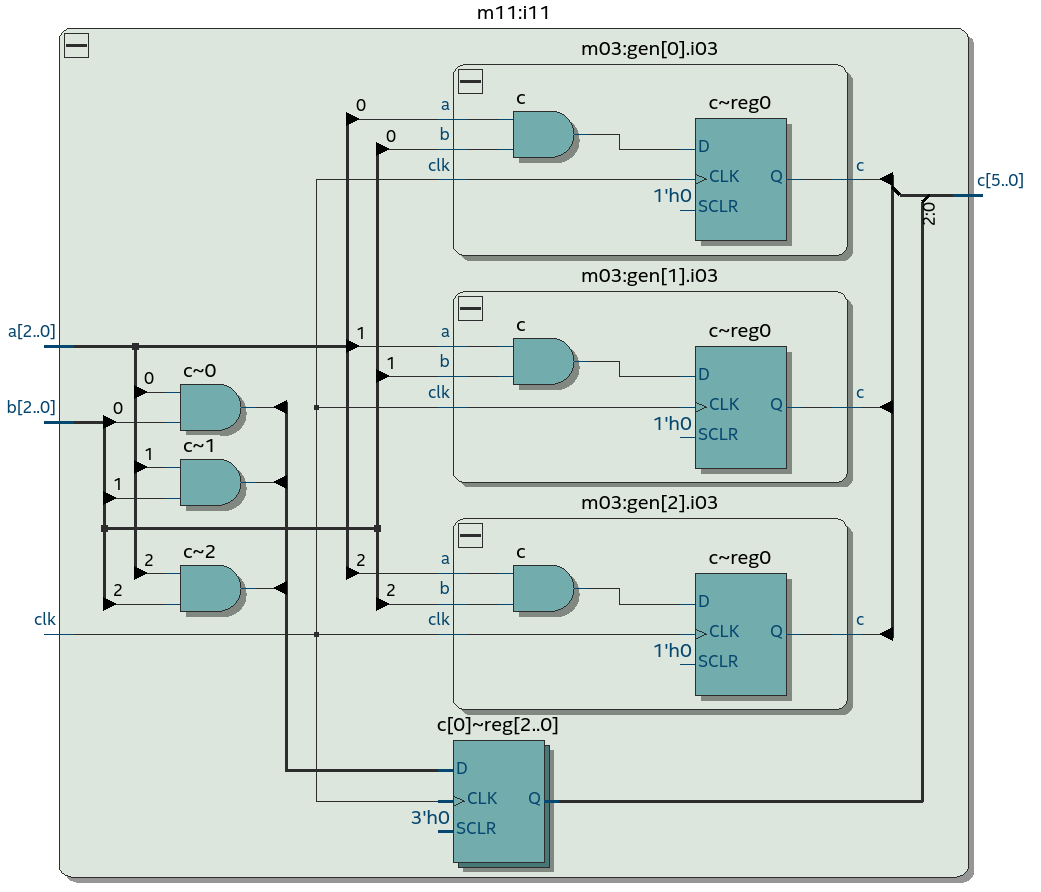
А вот случай использования конструкции generate. Его имхо можно покрыть на хакатоне только если использовать чей-то готовый open-source парсер:

То что выглядит синтаксически как софтверный цикл - на самом деле не цикл, а своего рода макро, порождающее несколько экземпляров модуля m03 (D-триггеры в них нужно суммировать).
В этой схеме при w=3 будет шесть D-триггеров - три из always-блока на верхнем уровне и три из трех экземпляров модуля второго уровня m03.
Я надеюсь, что какая-нибудь команда в Иннополисе не напугается и примет мою задачу. Она, при разумной формулировке, проще, чем может показаться из моей заметки. В худшем случае можно сделать "grep '<=' | sed ... | sort -u | wc -l" - и объявить задачу выполненной (это вполне ответ для формулировки задачи без иерархии и с однобитовыми переменными).
Так что успехов и вперед. Это поможет вам нарастить скиллы в компиляторах, скриптинге и разумеется основах цифрового проектирования - очень ценный рабочий навык в современной международной обстановке.
Задание уже выложено на сайт
Вот описание на английском:
Electronic Design Automation (EDA)
Yuri Panchul is an electronic chip designer (MIPS, Juniper and other companies); a founder of an EDA startup C Level Design acquired by Synopsys, an editor of a book published by HSE MIEM and an author of an online course developed by RUSNANO.
Context: When a chip architect gives a hardware block designer the architectural specification for a new block, he also gives the designer a set of requirements. These requirements include:
1. The performance or bandwidth: a number of instructions, transactions, network packets or graphical primitives processed by the block in a number of clock cycles.
2. The timing budget: the number of picoseconds available for the combinational logic to stabilize within one clock period. In order words, the required clock frequency.
3. The total area budget, which includes the area for the embedded SRAMs and the ASIC standard cells.
In addition, the designer gets guidance on power optimization. One of the key metrics related to both area and power is the count of D-flip-flops (DFFs), the main state elements in digital design. DFFs are used to build hardware pipelines, state machines, FIFO queues and CPU scoreboards. The designer:
1. Receives the DFF budget from the chip architect;
2. Estimates the number of DFFs required for each sub-block early in the design cycle; and
3. Tracks this number every week till the chip tapeout.
A digital design is almost always done using a hardware description language: Verilog, SystemVerilog or VHDL. The technology that converts a Verilog code into a graph of logic elements is called logic synthesis. The synthesis technology is complicated and not suitable for a hackathon. However it is possible to approximately count the number of DFFs even without full synthesis, just by finding so-called non-blocking assignments in Verilog code and adding the sizes of the variables on the left-hand sides of non-blocking assignments.
Task: Write a program that estimates the number of D-flip-flops in an electronic circuit by a quick analysis of its Verilog source code.
Instruments: this problem has multiple levels of difficulty, depending on how much Verilog syntax we are willing to support:
1. If we restrict the input code to single-bit variables within a single module, we can write just a few Linux commands that do the job. We can grep for '<=' non-blocking assignment characters, then collect the unique identifiers on the left-hand sides of non-blocking assignments and report their number. An experienced Linux user can write a simple "grep|sed|sort|wc" pipeline for it in a few minutes.
2. A more complicated case, with parsing bit vectors and unpacked arrays, would take longer, up to several hours. You can use regular expressions in Python or Lex & Yacc - style parsers in C or Java.
3. If we are going to support counting DFFs in the Verilog module hierarchy, we need to parse module instantiations and build the instance tree. This adds hours of programming but can still be done during a short hackathon.
4. If we extend the task to support Verilog preprocessor, parameterized modules, "generate" constructs, "struct" types and the assignments inside Verilog "tasks", we probably need a "real" Verilog parser. There are some open-source parsers of Verilog, including Yosys, Icarus Verilog and Verilator. Your hackathon team can study and utilize them if you wish to go this way.
Whatever you decide to do you are likely to get a good experience in scripting, compilers and digital design.
For more details see the description of the project in an article on the Habr website (in Russian) https://habr.com/ru/post/702186/
|
|
Как Америка любила и бодалась с Huawei |

10 лет назад в Санта-Клара, Калифорния, неподалеку от Интела и NVidia, стоял кампус Huawei. В нем работали не только китайцы, но и вообще обычная публика Silicon Valley - индусы, американцы, даже русские попадались. Бизнесмены калифорнийских электронных компаний говорили "Huawei - это дверь в Китай" и заключали с ними крупные сделки.
Но американское правительство Huawei невзлюбило. Можно обсусоливать те или иные поводы, но коренная причина понятна - американскому правительству хочется, чтобы Америка сохраняла технологическое преимущество. Ибо если технология коммодифицируется и айфон не будет ничем особенным, то кто будет читать брошурки про продвижение демократии, распостраняемые американскими посольствами в других странах? Над ними будут просто смеяться.
И вот правительство начало Huawei жучить - и от Андроида отлучило, и от других критических технологий. Но на всяких хитрецов найдется гайка с левой резьбой. И вот что Huawei стал делать по этому поводу.
Но начнем по порядку. Вот как выглядел кампус Huawei на пересечении Central Expressway с San Tomas Expressway (Центральное Шоссе и Шоссе Святого Фомы Аквинского) в Санта-Кларе:
Я в эти здания заходил, так как работал с Huawei в совместном проекте от лица MIPS и даже получил за это табличку на стену:
Про сам проект прессе были известны только слухи, хотя с Huawei / HiSilicon работал не только MIPS, но и например IBM Microelectronics. Про IBM я узнал совершенно случайно, наткнувшись на инженера из этого проекта во время отпуска в Юте. Главное СМИ электронной промышленности, Electronic Engineering Times, писало про проект загадочно, в рубрике EE Times Confidential:
Потом настало это:
Но Huawei - не такая компания, чтобы покорно ползти в могилу из-за каких-то госдеповских бюрократов. Они бодро начали импортозамещение, в том числе в области программ для проектировщиков микросхем, и сразу наняли 50 молодых PhD на разработку алгоритмов EDA (Electronic Design Automation - автоматизация проектирования электроники, по русски САПР):
Я вспомнил про случай Huawei / HiSilicon, когда на днях мне прислал емейл Андрей Садовых из казанского Иннополиса и попросил придумать задачку для их хакатона по программам автоматизации проектирования CASE in Tools 2022.
Я уже участвовал в таком хакатоне как задачкодатель в 2020 году и описал задачку по трассировке и размещению логических элементов микросхемы на Хабре (пост до хакатона и после). Вот команда, которая решила мою задачку и получила приз:
Итак, новая задачка. Назовем ее "Подсчет количества D-триггеров в схеме на основе анализа кода на языке описания аппаратуры SystemVerilog (без учета оптимизации)".
Немного картины с высоты птичьего полета.
Разработчика блока микросхемы оценивают не только по отсутствию функциональных багов, но и по PPA - Power-Performance- Area или Энергопотребление-Производительность-Площадь. При этом:
Для грубой оценки площади под стандартные ячейки в микросхемах ASIC удобно использовать количество D-триггеров, минимальных элементов состояния / памяти. Это связано с тем, что пропорция ячеек комбинационной логики к количеству D-триггеров во многих типах схем статистически сходна и именно количество D-триггеров является узким местом. В FPGA ситуация несколько другая - там D-триггеров по сравнению с комбинационной логикой много и их не нужно так сильно экономить как в ASIC-ах.
Количество D-триггеров важно еще и потому, что своими переключениями они жрут много электроэнергии.
Короче, на проектировщика блока архитекторы чипа как правило спускают:
Суть задачи
Подсчитать количество комбинационных логических элементов в схеме, описанной на языке SystemVerilog - это однозначно не хакатонная задача - она требует сложной технологии логического синтеза. Но вот количество D-триггеров подсчитать гораздо проще - достаточно найти в коде все так называемые неблокирующие присваивания и суммировать размеры всех переменных, к которым они применяются.
Варианты задачи разной сложности
Разумеется, при этом возникает много трудностей. В зависимости от формулировки задачу подсчета D-триггеров на основе кода можно решить за любое время от 1 часа до 1 года. Перечислим эти трудности (потом мы перечислим их снова, но уже с картинками):
Инструментарий
Мне честно говоря самому интересно, до чего дойдут студенты. Как я уже сказал:
1) Простейший вариант (без иерархии, параметризации и с однобитовыми переменными) можно написать на языке типа питона или джавы за час.
2) Если использовать многобитовые переменные и многомерные массивы, на решение может уйти еще полдня, но того же питона тоже должно хватить. Возможно понадобиться применить регулярные выражения.
3) Модульная иерархия вносит дополнительные сложности. Помимо быстрого кодирования на питоне или джаве (на что может уйти день) стоит рассмотреть вариант освоить чужой парсер верилога на C++ (Icarus Verilog или Yosys) и модифицировать его для этой задачи.
Иллюстрации частных случаев
Теперь то же самое, но с картинками. Первые два модуля вообще не содержат никаких D-триггеров - в них нет ни always-блока по фронту, ни неблокирующих присваиваний ("<="). Только блокирующее внутри "always_comb" ("=") :
Такая схема синтезируется в двух-входовый логический элемент И:
А вот как выглядит код, порождающий D-триггер. В нем есть неблокирующее присваивание ("<=") к переменной "c" которая объявлена как выходной порт и имеет размер 1 бит.
Неблокирующее присваивание находится внутри always-блока по фронту тактового сигнала (хакатонное решение может игнорировать этот факт, обращая внимание только на переменную, к которой применяется неблокирующее присваивание).
Также важно не спутать неблокирующее присваивание с операцией "меньше или равно" которая тоже пишется как "<=".
Этот код соответствует следующей схеме. Квадратик на ней - это D-триггер:
Несколько неблокирующих присваиваний к одной и той же переменной не порождают несколько D-триггеров. Но неблокирующие присваивания к разным переменным - порождают. В примере слева неблокирующие присваивания делаются двум однобитовым переменным, что порождает два D-триггера. Синхронные сбросы у этих D-триггеров перед оптимизацией превращаются в мультиплексоры, но это не важно для нашей цели подсчета D-триггеров:
Следующее усложнение хакатона - это добавление переменных шириной в несколько бит. В примере ниже результат умножения двух 3-битных чисел "a" и "b" помещается в регистр "c" шириной 6 бит. Регистр - это просто группа из D-триггеров, которая в данном случае состоит из D-триггеров c[5], c[4], c [3], c [2], c[1] и c[0]:
Если усложнить задачу вне рамок хакатона, такой модуль можно параметризовать - либо с помощью препроцессора (слева), либо с помощью ключевого слова "parameter" справа:
Другое важное усложнение, которое стоит сделать во время хакатона - это неупакованные массивы с размерностью справа от идентификатора. Слева пример схемы сдвигового регистра шириной 3 бита и глубиной 5 элементов, который использует 3 * 5 = 15 D-триггеров.
Вот как выглядит схема такого сдвигового регистра, обратите внимание что D-триггеры одного элемента собраны в "книжечки" по 3:
Стандарт SystemVerilog также поддерживает синтаксис "logic [2:0] a [5]" вместо "logic [2:0] a [0:4]". Вне рамок хакатона можно было бы написать программу, которая подсчитывает D-триггеры для сложных типов данных, например структур:
Наконец, было бы хорошо (возможно не на хакатоне, а после него) написать программу, которая бы парсировала иерархию модулей и подсчитывала D-триггеры на всех уровнях. Модули в верилоге как матрешки, за исключением того, что одной и той же матрешки может быть несколько экземпляров - D-триггеры во всех экземплярах нужно суммировать, это не как в софтвере с вызовами функций;
А вот случай использования конструкции generate. Его имхо можно покрыть на хакатоне только если использовать чей-то готовый open-source парсер:
То что выглядит синтаксически как софтверный цикл - на самом деле не цикл, а своего рода макро, порождающее несколько экземпляров модуля m03 (D-триггеры в них нужно суммировать).
В этой схеме при w=3 будет шесть D-триггеров - три из always-блока на верхнем уровне и три из трех экземпляров модуля второго уровня m03.
Я надеюсь, что какая-нибудь команда в Иннополисе не напугается и примет мою задачу. Она, при разумной формулировке, проще, чем может показаться из моей заметки. В худшем случае можно сделать "grep '<=' | sed ... | sort -u | wc -l" - и объявить задачу выполненной (это вполне ответ для формулировки задачи без иерархии и с однобитовыми переменными).
Так что успехов и вперед. Это поможет вам нарастить скиллы в компиляторах, скриптинге и разумеется основах цифрового проектирования - очень ценный рабочий навык в современной международной обстановке.
|
|
Миротворец: как я на нем оказался — и другой дискурс русскоязычного украинского американца |
Записал с Ruslan Gurzhiy из "Славянского Сакраменто" видео своего обычного дискурса на 1 час 20 минут.
Обычная тема: главный источник бед Украины заключается в том, что:
1. Сначала люди воспринимают "Запад" как одно целое, вместо разделения его на части: политизированной группы в Госдепе и коммерческих компаний.
2. Потом они вместо того чтобы работать с коммерческими компанями над экономическим и технологическим развитием, слушаются Госдепа и всяких активистов.
3. Госдеп Украину развить не может, так как условный Макфол не может научить украинцев делать айфоны, а также не может приказать компаниям Silicon Valley приехать на Украину что-то там направить и обустроить.
4. Украинские активисты-националисты в технологическом и экономическом развитии ничего не понимают, а замкнуты в цикле магического мышления, что если бить себя в грудь "мы не русские", то прилетит с Запада волшебник на голубом вертолете, всех выстроит в шеренгу, даст европейские зарплаты и скажет как идти. "Мы к этому готовы" типа "в ожидании этого на украинский язык переходим".
5. На самом деле европейским и американским компаниям вообще наплевать, на каком языке говорят на Украине. Именно с ними нужно было работать проактивно, как это делали например российкие электронные компании последние 10 лет - сами лицензировали всякие процессорные ядра и заключали контракты. Также в России развели курсы по обучению студентов FPGA и ASIC design, на которые российские студенты сейчас активно ходят и которые приведут к реальному развитию, когда вся ситуация как-то утрясется через какое-то время. Совершенно независимо от того, чей будет Крым и Донбасс.
Короче, кто работает, учится и проактивен - то и прав. Кто ожидает у моря золотую рыбку и пытается только требовать у заокеанских господ прижучить тех, кто работает - то остается у разбитого корыта.
Пояснение к слову "работа": "работа" означает вначале решать всякие задачки по верилогу, потом делать open-source проекты, а потом коммерческие маркетируемые проекты. А не "работа" в смысле "мы работает с комитетом Slush, чтобы они отняли миллион у русских победителей конкурса". Это не работа, а фигня, победителем таким образом стать нельзя.
Больше такого - в видео
|
|
Обнаружил баг американской системы образования |

Обнаружил интересный баг американской системы образования:
У многих студентов в резюме стоит "делал курсовой проект по алгоритму Томасуло, out-of-order суперскаляру, многопоточному процессору итд".
На это я спрашиваю: "Прекрасно, давайте возьмем два процессорных ядра - одно со статическим конвейером, а у другого с динамическим, как в вашем курсовике. Насколько ваш процессор будет производительнее?"
На это они отвечают "процессор будет производительнее, потому что" - и начинают ковыряться в деталях зависимостей между инструкциями.
На это я машу руками и говорю "стоп-стоп-стоп. Я не просил вас объяснить мне что такое RaW (read-after-write), WaR и WaW зависимости. Я вообще не спрашивал у вас "почему?" Я спросил у вас "сколько?" Я просил вас грубо оценить пользу от вашей разработки.
Вот вы вместе с другими студентами, под руководством профессора проектировали процессор, делали довольно сложную, продвинутую оптимизацию. Теперь возьмем написанный вами верилог, запустим его в симуляторе и пропустим через него бенчмарку, скажем Dhrystone или CoreMark. Допустим у процессора со статическим конвейером сколько-то итераций бенчмарки прошли за сто тысяч тактов. За сколько тактов пройдет эта же бенчмарка на вашем процессоре - за сто тактов или за миллион? Или за что-то посередине? Сколько вы покупаете вашей оптимизацией - 1%, 10%, 100%? Какой ценой в размере логики? Может такты изменятся мало, но повысится максимальная тактовая частота? На сколько?"
И представляете, что они мне отвечают? "Мы не запускали бенчмарки".
Бенчмарки у них в учебниках есть - это я не думаю, а знаю, так как все их учебники стоят у меня на полке. Это выглядит для меня чисто как плохая работа преподавателей: преподаватели должны:
Впрочем, в России и Украине проблем больше, чем у американских вузов: мне говорили несколько лет назад, что в МФТИ вообще обучали конвейерным процессорам с помощью cycle-accurate модели на C++, при этом без измерения статического анализа тайминга для разных вариантов микроархитектуры. Ну это как учить электричеству без магнетизма. Хотя с тех пор прошло время, и я надеюсь, что они это исправили.
|
|
По поводу выборов |

Помимо выборов в конгресс и сенат, мне как калифорнийскому избирателю, предложили проголосовать за следущее:
Prop 1. Поправка к конституции Калифорнии, гарантирующая аборты и презервативы.
Как человек с биологическим образованием (я получил associate degree по биологии в Foothill College) я рассматриваю аборт как несомненное убийство. Оплодотворенная яйцеклетка - уже диплоидный Homo sapiens, просто на ранней стадии своего развития.
Но я не против того, чтобы те или иные люди сами своими руками убирали свой геном из популяции. Это их личное дело, пусть убивают.
Насчет презервативов - я за только при условии, если государство поощрит налоговыми льготами производителей lambskin condoms (презервативов из кишки ягнят) - с ними секс для мужчины интереснее (женщинам вроде все равно - lambskin или latex).

Prop 26. Разрешать ли индейским племенам делат спортивные ставки а-ля ипподром в дополнение к азартным играм в своих резервациях.
и Prop 27. Разрешать такое же вне резервации, если это крышуется индейским племенем.
Я против. Пусть играют в трехмерные шутеры на телефонах - от этого мне идет зарплата.
Prop 28. Увеличить траты в школа на обучение искусству.
Я за. Работа в области искусства меня влекла к себе давно.
Prop 29. Увеличить количество левых ставок и бюрократии в больницах по диализу почек.
Против. Фельдшера или медсестры для базовых процедур должно быть достаточно. Или я не прав, что скажут медики и люди с больными почками?
Prop 30. Налоговые льготы для покупателей электрических автомобилей.
Мне электрический автомобиль не нужен. Я собираюсь на старости полгода в году жить в Москве, где буду ездить на метро и Яндекс-такси, а другие полгода в Калифорнии, где ходить пешком и ездить на трамвае VTA, иногда на юбере. Я вообще не фанат автомобилевождения. Кроме этого, электрические автомобили вреднее для природы чем бензиновые из-за производства литиевых аккумуляторов. Так что против.
Prop 31. Запрет на продажу ароматизированного табака.
Я бросил курить больше 20 лет назад, когда обнаружил, что страховые компании берут с курильщиков двое больше чем с некурящих. Так как страхование жизни - очень конкурентный бизнес, за этим должен стоять очень трезвый статистический анализ. Наверное стоит запретить.
При этом я на выборы не пошел. Я посмотрел на предварительные результаты и понял, что 1) с выборами в конгресс и сенат мой голос ничего не решает и 2) избиратели уже проголосовали за поправки как проголосовал бы я.

|
|
Как подготовиться к собеседованию в Samsung Advanced Computing Lab |

Я работаю проектировщиком аппаратного блока графического процессора в телефонах Samsung, в рамках совместного проекта с AMD. Сейчас наш менеджмент расширяет команду и поощряет инженеров распостранять информацию о новых позициях среди своих знакомых. Я решил написать это пост для более широкой аудитории, так как множество людей, способных пройти интервью на RTL или DV позицию - больше, чем множество моих знакомых. Если вы сможете прислать мне ответ на задачку в моем посте вместе с вашим резюме, я перешлю его нанимающему менеджеру и рекрутеру нашей группы (в комментах прошу ответ не писать). Если резюме им понравится, вам нужно будет пройти стандартное собеседование на несколько часов, с несколькими инженерами, у каждого из которых свой набор задачек.
Также я покажу материалы, по которым можно готовиться к собеседованию, особенно если вы студент или у вас ограниченный опыт в электронной промышлености.
Скажу сразу что для данных позиций нужно разрешение на работу в США. Если у вас его нет, я агитировать компанию за петицию на H-1 визу для вас не могу, но вы можете решить задачку чисто для расширения кругозора или демонстрации молодецкой удали.
Для опытных инженеров задачка слишком простая, но для недавних выпускников вузов по специальности Electrical Engineering или Computer Engineering - в самый раз. Это должен уметь решать выпускник практически любого американского вуза который брал курс типа MIT 6.111 Introductory Digital Systems Laboratory, а также выпускники российких вузов МИЭТ, МИРЭА, ВШЭ МИЭМ, ИТМО, Иннополис, МГУ ..., украинских КПИ, черниговского политеха, топ технических вузов Беларуси, Армении, Киргизии итд.
Ожидается, что вы владеете основами проектирования цифровых схем на уровне регистровых передач (Register Transfer Level - RTL), используя синтез с языка описания аппаратуры Verilog/SystemVerilog. Если вы напишете решение на VHDL - это тоже пойдет. Вы также можете приколоться и написать решение, используя high-level synthesis, графическую схему (schematic entry) или экзотические языки типа BlueSpec или Chisel, можете даже собрать ответ на советских микросхемах К155, транзисторах, радиолампах, реле или гидравлике - но все это я менеджменту не перешлю, хотя мне будет на это интересно посмотреть.
Итак, формулировка задачки:
Вам нужно спроектировать блок, который превращает поток данных шириной w бит в поток данных шириной w*2. Как прием узких данных в блок, так и передача широких данных из блока должна делаться с помощью valid/ready интерфейса в духе протокола AMBA AXI-Stream или каналов AXI4:

Вам также нужно написать тестовое окружение к блоку, которое обосновывает функциональную корректность и демонстрирует оптимальную пропускную способность блока. Большим плюсом будет, если вы еще и напишете код для проверки функционального покрытия, а также утверждения темпоральной логики, которые можно было бы проверить с помощью формальной верификации.
Valid/ready протокол должен следовать правилам, описанным для AXI (это все не ARM-specific и не AXI-specific, просто в армовской документации эти правила сформулированы лучше всего), в частности Valid не должен ждать Ready=1 для перехода от Valid=0 к Valid=1. Ведущий блок должен выставить Valid=1 не глядя на Ready, и потом ждать момента когда и Valid=1, и Ready=1 на положительном фронте тактового сигнала:

Ready может быть выставлен как через несколько тактов перед Valid, так и после Valid, или в том же такте что и Valid. Протокол Valid/Ready должен работать даже если Ready меняется случайно (в нашей задачке случайным может быть Downstream Ready для широкой шины). Также для оптимальной пропускной способности полезно обратить внимание на вот такое замечание в спецификации AXI (читать всю спецификацию не обязательно, я уже привел все что нужно для решения в этом после):

В отсутствие backpressure (то бишь когда downstream_rdy всегда равен 1), блок должен позволять прием данных каждый такт и выдачу данных через такт:

Полезная литература для подготовки к интервью
Вот самый лучший учебник начального уровня по вопросу, доступный сейчас на русском языке. Если вы не понимаете все, что в нем написано, то ваши шансы на трудоустройство в микроэлектронную компанию на RTL или DV (Design Verification) позицию не очень:

Вы также можете можете использовать более старый вариант учебника ниже. Главы 1-5 у учебников совпадают, но в главах 6-7 белый учебник использует модную молодежную архитектуру RISC-V, а зеленый - олдовую архитектуру MIPS. С точки зрения интервью на джуниор позицию RTL или DV инженера для проектирования или верификации GPU - это все равно.
Даже если вы будете проектировать не блок в подсистеме геометрии (как я) и не блок в pixel pipe, а шейдеры или управляющее ядро - даже в этом случае совершенно все равно, вы учились на MIPS или на RISC-V. Хотя с другой стороны, если вы учились (допустим) на микрокалькуляторе МК-54 или (допустим) на компьютерах ДВК и Радио-86, то вам нужно подучить концепцию конвейера (глава 7 и одного и другого учебника) для того, чтобы утверждать, что вы разбираетесь в основах архитектуры и микроархитектуры ЭВМ:

Подспорьем к учебнику Харрисов является вот такая книжка, которая привязывает его к упражнениям на платах с микросхемами регонфигурируемой логики ПЛИС / FPGA:

Но на одном учебнике Харрисов интервью вы не пройдете, так как в нем нет ряда тем, которые регулярно спрашивают на интервью, в частности задачки с очередями FIFO, арбитры, пересечение тактового домена, многопортовые памяти итд. Некоторые из тем, не разобранных у Харрисов, можно найти вот в такой книжке, по которой учатся в Стенфорде.
Например в ней есть про двойные буфера (skid buffers), асинхронные очереди FIFO для пересечения тактового домена (Clock Domain Crossing - CDC), работу с числами с плавающей точкой, немножко про банки памяти итд.

Но учебников недостаточно - стоит еще и читать всякие тексты из интернета, в частности статьи Клифа Каммингса (он на фото справа), особенно про пересечение тактовых доменов, синхронные и асинхронные сбросы. А также материалы сайтов rtlery.com и zipcpu.com, особенно если у вас ограниченный опыт в промышленности. Еще пять материалов про арбитры, credit-based flow control и работе с памятью, которые помогут поднять тонус перед собеседованиями:
Credit Based Flow Control. Архитектура ЭВМ, Принстонский университет
Arbiters: Design Ideas and Coding Styles by Matt Weber
Generating fast logic circuits for m-select n-port Round Robin Arbitration
Building Multiport Memories with Block RAMs
Composing Multi-Ported Memories on FPGAs

Кроме тем, связанных с проектированием, и RTL, и DV инженеру нужно четко понимать, как работает симулятор, иначе вы будете плодить баги, связанные с гонками (race conditions) и различными результатами симуляции до и после синтеза (pre- and post-synthesis simulation mismatch). Из этого понимания следует правильная методология использования блокирующих и неблокирующих присваиваний, которая вскользь упоминается у Харрисов. На тему работы симулятора есть очень полезный Appendix вот в такой книжке, которую я тоже рекомендую:

Для инженеров, которые идут на позиции по design verification, я рекомендую проштудировать следующие три книжки от начала до конца.
В первой книжке (Chris Spear) по человечески описана coverage-driven constrained random verification methodology, а также отличия SystemVerilog от Verilog-95 и Verilog-2001 (если вы их учили в вузе). Без этой книжки вам придется копаться в стандарте, который во-первых написан более мутным языком, а во вторых не объясняет зачем нужны те или иные фичи языка.
Вторая книжка (Vanessa Cooper) - это короткий тьюториал по UVM, который можно изучить быстро. UVM не так широко используется в электронных компаниях, как утверждает маркетинг компаний, которые продают тулы, поддерживающие UVM. Но что такое UVM и с чем его едят должен в 2022 году знать каждый верификатор, так как шанс нарваться на кусок UVM-а в том или ином проекте существует. Только не копируйте из этой книжки шаблон писания драйвера шины - он совершенно не подходит для более сложных шин, типа AXI с конвейерностью и внеочередным получением ответов (для них нужно поддерживать табличку "транзакций в полете" и строить конечный автомат, использующий такую табличку).
Третья книжка (Janick Bergeron) описывает философию верификации и индустриальные практики. Если вы никогда не работали в команде верификации чипа или блока, эта книжка съэкономит время вас и ваших коллег, когда вы будете задавать им вопросы.
Помимо книжек есть полезные сайты, например www.testbench.in

Если у вас нет доступа к дорогим промышленным тулам для симуляции Synopsys VCS, Cadence Xcelium и платной Mentor / Siemens EDA Questa, то я рекомендую вам получить бесплатный доступ через сайт под названием edaplayground.com . Бесплатные тулы вне этого сайта (Icarus Verilog и бесплатная версия Questa) достаточны для тренировки решения интервьюшных задач на тему RTL, но в них нет поддержки covergroups, constrained random generation и concurrent assertions, чем необходимо владеть для позиций по DV.

Кстати о concurrent assertions, утверждениях темпоральной логики. Они в последние годы становятся важным инструментом не только инженеров-верификаторов (DV), но и инженеров -проектировщиков (RTL), особенно в связи с развитием тулов формальной верификации типа Jasper Gold. Эти тулы позволяют автоматически получать ответы на вопросы типа "допустим на входе в блок у меня такие-то сигналы установлены так-то. Следует ли из этого, что потом, через много тактов, на выходе будет (или не будет) то-то?" Тул автоматически проанализирует ваш RTL и ответит "увы, вот контрпример" и покажет сценарий, когда ваше предположение нарушается, например в логике участвует сигнал, который вы забыли.
Очень полезно для анализа чужого кода. Я вообще думаю, что вузы могли бы вводить такие тулы для обучения студентов в самом начале учебной программы, чтобы они сразу правильно ставили мозг на анализ событий в конвейерах и вообще сложных последовательностных схемах.

"А как же графика?" - спросите вы, - "ведь железо, которое я буду проектировать, предназначено для быстрого вывода на экран монстров в шутерах, не так ли?" Да, вам нужно будет в конце-концов изучить графику, начиная с софтверного API, посколько все эти объекты - треугольники, матрицы преобразований координат, плоскости для отрезания и т.д. будут приходить к вам в виде данных на шинах и всяких установок извлекаемых из регистров, в которые будет писать софтверный драйвер. Но это необязательно учить сразу. Сразу нужно уметь решать микроархитектурные задачки, писать на верилоге и понимать что такое статический анализ тайминга. А монстры и шутеры - это потом, в процессе.

|
|
В КНР появилась работоспособная альтернатива учебным FPGA платам от Intel/Altera и Xilinx/AMD |

Исторический момент! Александр Белиц запустил китайскую плату Tang Primer 20K с китайским же FPGA Gowin, освобождающим мировую общественности от зависимости от американских компаний Intel/Altera, Xilinx/AMD и Lattice (последний лично Трамп запретил продавать инвесторам из КНР). От зависимости по крайней мере на рынке образовательных FPGA плат, лабы на которых - стандартный элемент подготовки будущих проектировщиков микросхем ASIC внутри смартфонов, суперкомпьютеров, инфраструктуры интернета, быстрого AI для распознавания лиц террористов в толпе, кораблей бороздящих просторы вселенной итд итп.
Подвиг Белица был непрост - помимо кучи проблем с USB, у коннектора для платы не хватало проводка, плюс нужно было перепрошить firmware программатора (не путать с прошивкой FPGA) из бинарного файла, найденного на российском форуме electronix.ru. То, что большинство документации на китайском языке - это были сущие мелочи.
Теперь все это нужно задокументировать, опубликовать, спортировать на эту плату мои примеры и (если все будет выглядеть лучше чем у Интела/Альтеры и Xilinx/AMD) пересадить на Gowin будущих студентов моих семинаров.
UPD: для тех, кто не знает что такое ПЛИС/ FPGA: это плата с микросхемой реконфигурируемой логики, пригодная для лабораторных работ типа курс MIT 6.111. Такие курсы проходят все будущие дизайнеры микросхем в айфонах итд. Внутри микросхемы Gowin на плате - матрица ячеек, логическая функция которых меняется с помощью изменения битов конфигурационной памяти. Это позволяет строить схемы типа учебных процессоров итд.
UPD2: для проектирования любой современной микросхемы - от микроконтроллера в кофеварке до системы на кристалле в смартфоне - требуются инженеры, которые владеют навыком проектирования на уровне регистровых передач с помощью языков описания аппаратуры (RTL Design Engineer). Это ключевой навык для команд проектирования процессоров, графических процессоров, сетевых чипов, нейроускорителей итд. Для тренировки таких инженеров изготавливать их учебные проекты на фабрике было бы слишком дорого. Поэтому их учат на FPGA, где можно описание схемы на языке описания аппаратуры Verilog превратить не в дорожки и транзисторы, а в прошивку конфигурационной памяти FPGA. В России команды RTL Design Engineers есть в таких компаниях как Байкал, Syntacore, Миландр (микроконтроллеры), Элвис (умные камеры) итд.
UPD3: пара скупых деталей для желающих повторить (потом сделаю пост на Хабре):
RV-Debugger-BL702.zip is downloaded from
https://electronix.ru/forum/index.php?app=forums&module=forums&controller=topic&id=166408&page=2#comment-1810016
bflb-mcu-tool-1.8.0.tar.gz is downloaded from
https://pypi.org/project/bflb-mcu-tool
cat /etc/udev/rules.d/99-sipeed.rules
SUBSYSTEM=="usb", ENV{DEVTYPE}=="usb_device", ATTRS{idVendor}=="0403", ATTRS{idProduct}=="6010", MODE:="0666", RUN+="/sbin/rmmod ftdi_sio"
К плате есть дополнительная периферия, про это будут дополнительные посты.
UPD4: для сравнения - introductory образовательная FPGA плата с чипом от Интел Terasic DE10-Lite стоит $135, от Xilinx/AMD - Digilent Basys2 — $165. Даже с учетом докупки дополнительной периферии плата с чипом от Gowin не хуже, сильно дешевле и схемы для нее быстрее синтезируются.





|
|
Беснование и опера в Сан-Франциско |
Сейчас в Сан-Франциско идет опера Евгений Онегин. Перед премьерой к зданию подошла художница Юлия Косивчук, которая принялась агитировать американцев туда не ходить. Выглядело это художественно, как имитация наркотического психоза:
Юлию охраняли два активиста, но оперу охраняли три охранника, поэтому вовнутрь она не прошла:

Помимо Юлии с комрадами, на протест пришла и другая группа людей, в составе 27 человек, которая вызвала у меня недоумение. Они несли украинские флаги, но украинцев среди них было очень мало.

Сначала я подумал, что это китайские студенты-воки, но потом заметил у них плакаты "буряты против войны". Ну хорошо, допустим, что буряты области сан-францисского залива беспокоятся о своих родственниках, попавших под мобилизацию в России. Но в этой толпе я заметил и человека с скорее латиноамериканской чем среднеазиатской внешностью.
Когда я поделился удивлением «что это за люди?» у себя на фейсбуке, мне рассказали, что у нас в Калифорнии оказывается есть компания, которая за небольшие деньги организовывает толпу для протеста на любую тему:

Других протестантов было немного - товарищ с громкоговорителем, который читал что-то по бумажке и семейная пара с жовто-блакытнымы флагами.

Несмотря на уверения протестующих, что «пока вы смотрите, Россия убивает», около трех тысяч американцев вошли в здание оперы чтобы посмотреть творение Пушкина и Чайковского.

Опера в Сан-Франциско большая, с несколькими ресторанами и барами. Многие зрители пришли заранее, чтобы пообедать свежайшим мясом, выпить вина и почитать программу:





В опере есть магазинчик с мини-музеем, в котором есть например про немецкого композитора Вагнера:


Пришел полный зал:
Опера оказалась неожиданно увлекательной. Я думал, что буду сидеть три часа с томлением "боже, прошло всего 20 минут", но реально действие захватывало внимание - это синтез хорошо структурированного повествования, стихов , музыки, пения, актерской игры, костюмов и постановки.
Как начинающий игрок на флейте я также посматривал когда в каких местах вступают флейтистки - их было три - первая, вторая и пикколо. В антракте я пошел посмотреть на флейтисток поближе:
Потом вышел в коридор:
И съел в буфете бутербродик:

В конце действа много хлопали:

В общем получилось очень душевно. Буду ходить на оперы еще.

Евгений Онегин будет идти в Сан-Франциско до 12 октября. Также рядом со зданием оперы есть здание филармонии. Там вроде собираются играть Чайковского, надо и на него сходить.
|
|
Начинать воевать на авось - дурацкое решение, но зачем еще и усугублять призывом на фронт R&D? |

|
|
AMD проводит суперкомпьютерный день в Казахстане. Можно подсоединиться по Zoom |







|
|
Русский язык как Си и украинский как Bash |




|
|
Как я выиграл апелляцию против американских санкций |
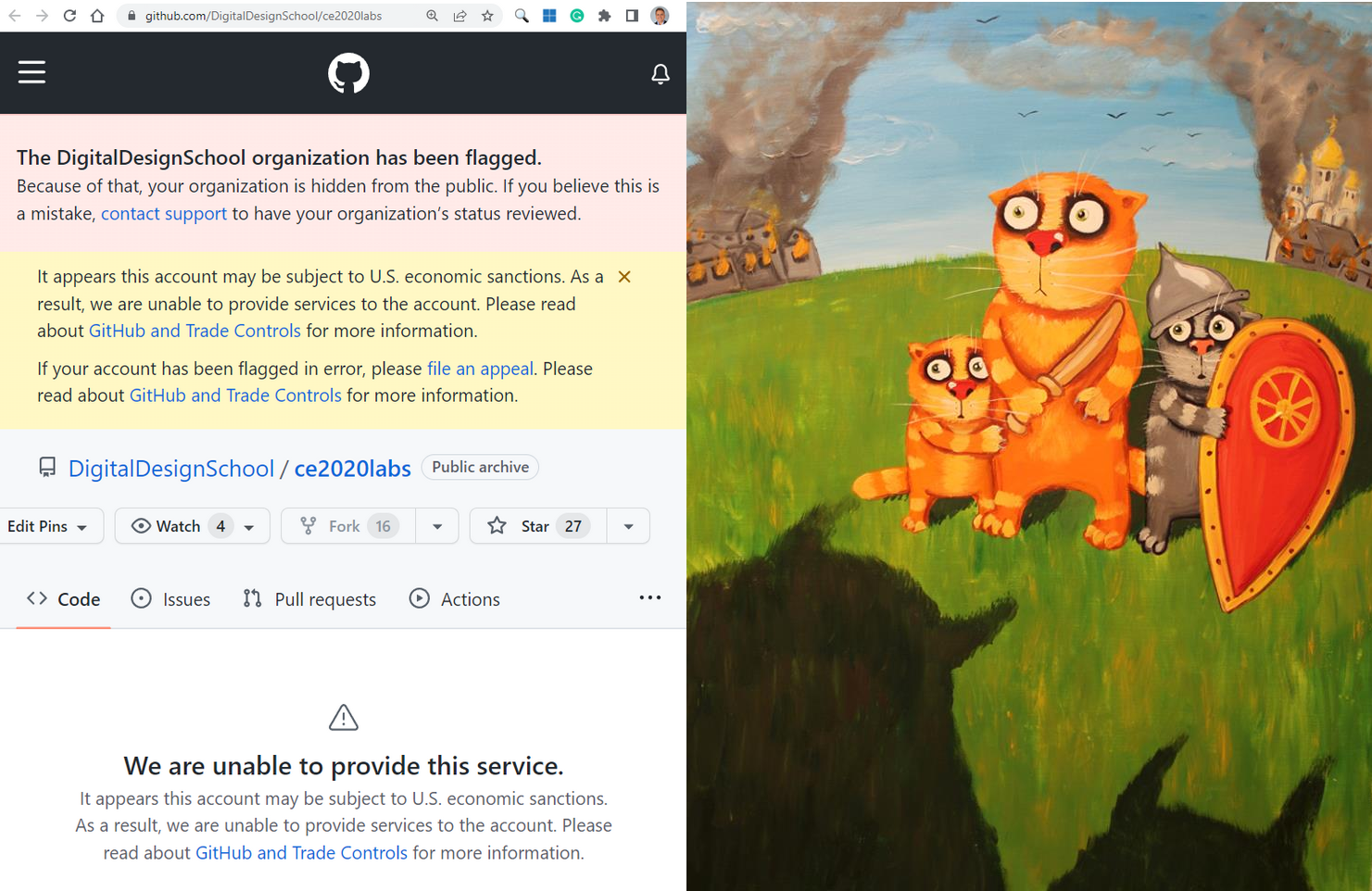
В прошлое воскресенье 4 сентября я обнаружил, что GitHub-организация DigitalDesignSchool, в которой я являюсь одним из владельцев, забанена Гитхабом с формулировкой "ваш аккаунт может быть предметом американских экономических санкций".
Пораскинув мозгами и посовещавшись с моим приятелем, основателем московского интернет-провайтера RiNet Сергеем Рыжковым, у которого в тот же день забанили счет в Ситибанке в Лондоне, я решил: нужно бороться.
Сначала я изучил страницу GitHub and Trade Control, на которой нашел несколько занятных вещей. Например, оказывается GitHub получил разрешение от U.S. Treasury Department's Office of Foreign Assets Control (OFAC) оказывать услуги разработчикам open-source проектов в Иране. Также оказывается GitHub агитирует американские органы ослабить ограничения на Крым и Сирию в честь прогресса человечества и свободы слова:
GitHub will continue advocating with U.S. regulators for the greatest possible access to code collaboration services to developers in sanctioned regions, such as Syria and Crimea, including private repositories. We believe that offering those services advances human progress, international communication, and the enduring U.S. foreign policy of promoting free speech and the free flow of information.
Когда я это прочитал, я понял, что надо не ходить с кислой рожей, а помочь прогрессу человечества и подать на апелляцию против бана DigitalDesignSchool, тем более что это моя гитхаб-организация.
Поэтому я нажал на кнопку подачи апелляции, где было много вопросов, кто состоит в организации и чем она занимается и одновременно создал тикет в поддержке Гитхаба со следующим текстом:
Hello: I got a message that my organization DigitalDesignSchool was flagged and hidden from the public.
I am the owner of this organization and I am a US citizen so I could not be under the sanctions.
I guessed this issue happened because the description of the organization references Skolkovo which is under sanctions.
However, the organization itself is not a part of Skolkovo. There was a seminar on which the presenters rented a room in Skolkovo.
So Skolkovo was used for marketing purposes and that was it.When I tried to remove the Skolkovo reference from the account, I got a message "It appears this account may be subject to U.S. economic sanctions. As a result, we are unable to provide services to the account. Please read about GitHub and Trade Controls for more information."
Please review the status of the account. It has a set of basic Verilog examples used for seminars in many places - not only in Russia but also in Ukraine, Kazakhstan, Kyrgyzstan - worldwide. It is a pity if mentioning Skolkovo once because of a past seminar jeopardizes basic Verilog learning for many people.
Thank you,
Yuri Panchul
Одновременно я начал изучать альтернативы GitHub-у: GitLab, Gitee и Bitbucket. Из них мне показался самым перспективным Gitee, который находится в Китайской Народной Республике. В процессе изучения GitLab и Gitee я обнаружил новые для меня фичи CI/CD с использованием YAML (не делайте рука-лицо, я писатель на верилоге, а не DevOps), так что из инциндента я даже извлек некую для себя пользу.
Но пока суть да дело, суппорт GitHub-а посовещался со своими юристами и они решили меня разбанить. Сначала мне пришел такой емейл:
GitHub and Trade Controls
From: GitHub Trade AppealsThank you for submitting additional information regarding the trade restrictions placed on your GitHub account. Based on the information you provided, we have enabled full service on your account.
We appreciate your patience and cooperation during this compliance process.
Please note that your organization and/or user account may be flagged again in the future if our system determines the organization is based out of, or the key individuals or membership of the organization shows sufficient ties to, a sanctioned jurisdiction, or if the organization otherwise appears to be restricted by U.S. economic sanctions.
а потом такой:
GitHub (GitHub Support)
Hi Yuri,
Thanks for reaching out to us with these details, and the details you shared through our appeals form. After a legal review we have lifted restrictions on this organization. You should now be able to resume normal GitHub use.
To avoid future difficulties I will recommend you remove any references to Skoltech now that you can access your profile again.
Thanks for your patience during this process.
Regards,
GitHub Support
Также я осознал, что как в воду смотрел, когда три недели назад создал отдельную гитхаб-организацию для создания материалов для мероприятий в Средней Азии - Digital Design & Verification in Central Asia . Эти материалы уже использовались на семинаре "Модели бизнеса и основы технологий микроэлектроники для Центральной Азии" в Бишкеке. Семинар организовали Siemens EDA и Американский Университет в Центральной Азии. Все видео лекций и часть видео лабораторных упражнений выложены на сайт ddvca.com.
Сейчас мы с коллегами планируем подобные семинары и в других столицах Средней Азии и вообще стран бывшего СССР. Мне может понадобится помощь в подготовке к ним слайдов и новых примеров, если кто хочет поучаствовать и заодно потренироваться.

Дополнение: как определить, что та или иная организация находится под санкциями? (В данном случае не гитхаб-организация, а организация в реале) . Для этого есть ссылка:
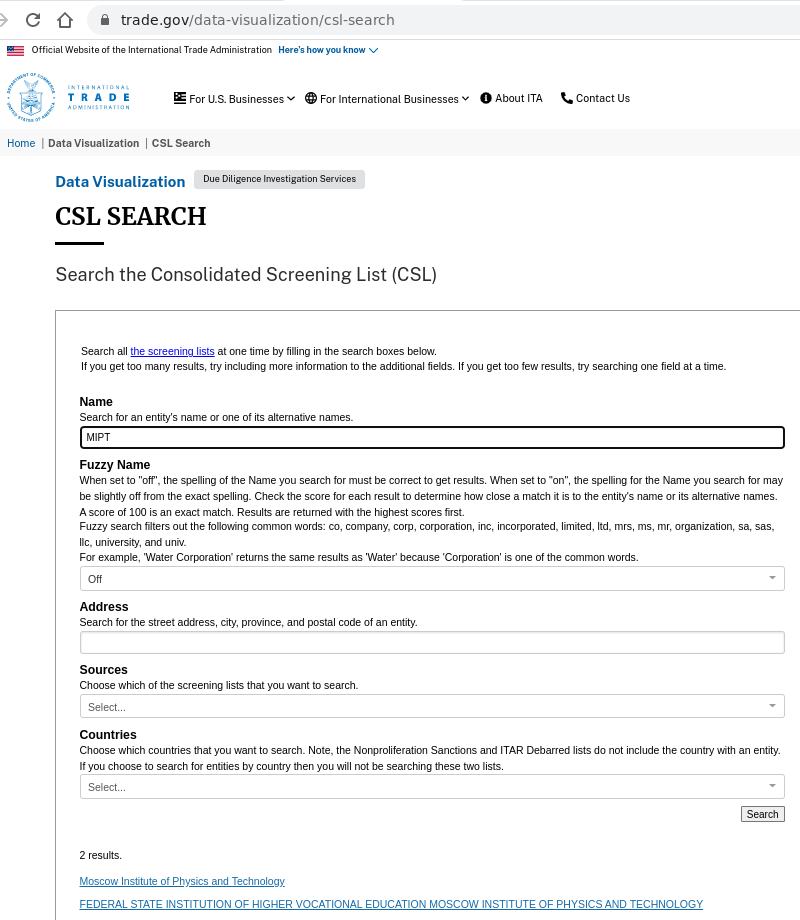
https://www.trade.gov/data-visualization/csl-search
Вот например скриншоты про санкции по отношению к Московскому Физико-Техническому Институту. Идем по ссылке, вводим MIPT и смотрим:

|
|
Объясните чайнику про GitLab, Gitee и CI/CD |
|
|
Беснование перед Евгением Онегиным в Сан-Франциско и вопрос заядлым театралам |


















|
|
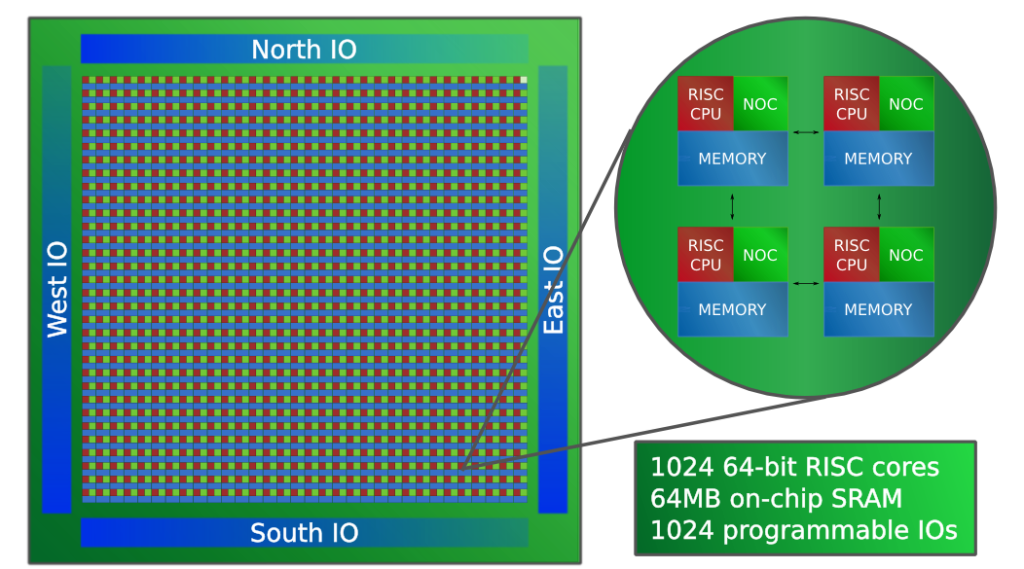
От Шёлкового Пути — to the Road to Silicon: в Средней Азии есть RTL-дизайнеры |






|
|
Улыбающаяся улитка — на технологиях от бумеров, Интела и Пентагона |

В модном и молодежном учебнике электроники от Харрисов есть пример простого конечного автомата - "улыбащейся улитки". Я решил наглядно показать, как можно в домашних условиях реализовать улитку на трех технологиях:
Микросхемы малой степени интеграции CMOS 4000. Первая массовая КМОП-серия, выпущенная в 1968 году. 20 микрон то бишь 20 тысяч нанометров. На таких микросхемах учились электронике бумеры, то бишь люди, родившиеся во время бэби-бума 1950-х годов и вошедшие в технологию в начале 1970-х. В том числе Стив Джобс и Стив Возняк.
Микросхемы программируемой логики Altera Cyclone IV, ныне Intel FPGA Cyclone IV. 2009 год, 60 нанометров. Интеловская микросхема, в которой вообще нет никакого процессора, только набор логических ячеек, между которыми можно программировать соединения. Удобна как тренажер для будущих проектировщиков микропроцессоров, так как для построения схемы внутри FPGA не нужно делать заказ на фабрике.
ASIC-технологии фабрики Skywater - лидера американского импортозамещения. 2019 год, 130 нанометров. На своем вебсайте компания пишет что они единственная в США контрактная фабрика микросхем, у которой нет инвесторов-иностранцев: "SkyWater is the only US-investor owned pure-play semiconductor and technology foundry". Поэтому в них инвестировал 10 миллиардов рублей Пентагон.
На работе у меня есть доступ и к технологии 3 нанометра, но показать ее вам на Хабре не могу, поэтому прошу вас поверить мне на слово, что и на 3 нанометра "улыбающаяся улитка" работает. Кстати, все это будет на семинаре в Бишкеке на следущей неделе. Итак:
Сначала условие задачи в Харрис & Харрис:

Диаграммы переходов между состояниями двух вариантов конечного автомата:
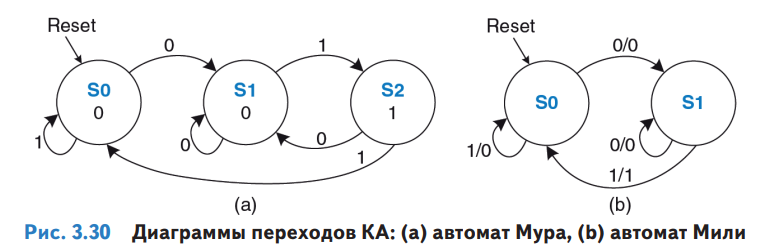
Если порисовать ручкой на бумаге карты Карно, из диаграмм выше можно построить схемы с логическими элементами И и НЕ и сохранением состояния в D-триггерах. Для схемы слева нужно два D-триггера (два бита состояния для трех состояний - 00, 01, 02), для схемы справа достаточно одного бита состояния:
Теперь берем микросхемы CMOS 4081 (4 элемента И), 4069 (6 элементов НЕ) и 4013 (два D-триггера), втыкаем их в макетную плату снизу, соединяем ножки проводами - и конечный автомат готов. Для наглядности добавляем лампочек и кнопочек, к которым приклепляем дюжину резисторов чтобы ничего не перегорело и не подвисало (это не сложнее чем вязать шарфики крючком).

Вот как микросхемы 4081, 4069 и 4013 выглядят внутри:

Макетная плата сверху - это не часть конечного автомата. Слева на ней находится генератор тактовой частоты, справа - сдвиговый регистр, чисто для наглядности, чтобы видеть, какие мы скармливаем конечному автомату последовательности нулей и единиц. Все это работает вот как:
Теперь переносимся в 21 век и скачиваем с вебсайта Интела программное обеспечение Quartus Prime Lite Edition 21-1-1 (причем важно скачать именно Lite, а не Pro, если вы не собираетесь подарить Интелу 5 тысяч долларов). Для Windows или для Linux. Когда вы запускаете Quartus в первый раз, также важно сказать "Run" здесь, то бишь запустить бесплатную версию. Иначе может быть возня с переключением ее с лицензируемой на бесплатную:
Теперь вы можете скачать с гитхаба пакет с упражениями для семинара в Бишкеке, раззиповать его в любой директории, найти файл проекта day_3/lab_8_snail_fsm/top.qpf, и открыть его в квартусе с помощью меню "File | Open Project", который все время путают с "File | Open". Дальше нужно дважды кликнуть на Compile Design и через пару минут вы увидите следующее:
Если кликнуть в разные меню, вы увидите, как код на языке описания аппаратуры Verilog превратился в схему и как Quartus распознал состояния конечного автомата (он правда добавил в диаграмму сброс, но это нюансы):

В другом меню вы можете увидеть как схема отобразилась на ячейки ПЛИС-а / FPGA. Она все еще представлена в виде графа:.
А вот граф размещен внутри микросхемы. Логические функции ячеек изменяются с помощью мультиплексоров, подсоединенных к битам программируемой пользователем памяти, отсюда сокращение ПЛИС - "Программируемые Логические Интегральные схемы", или ППВМ - "Программируемые Пользователем Вентильные Матрицы":

Заливаем это в микросхему на плате и вот как она работает вживую:
Теперь перейдем к фиксированным микросхемам, которые выпускаются на фабрике. Вот так выглядит фабрика Skywater:

Фабрика дает проектировщикам так называемую ASIC standard cell library - библиотеку ячеек, которые фабрика может произвести, построить рядами на силиконе и соединить дорожками из меди. Примитивы функционально похожи на то, что мы видели в CMOS 4000: логические элементы И, ИЛИ, НЕ, их простые комбинации, мультиплексоры, простейшие сумматоры сумматоры и разнообразные D-триггеры - с синхронным или асинхронным сбросом, разрешением итд.
.

Физически ячейка выглядит как несколько слоев кремния с примесями бора и фосфора. Про каждую ячейку известны ее физические параметры - задержки в пикосекундах при разных условиях, размер, параметры энергопотребления - все это учитывает софт, который превращает код на верилоге в GDSII файл, который отправляется на фабрику, чтобы по нему сделать набор фотошаблонов для печати микросхемю
Skywater скооперировалась не только с Пентагоном для его радиационно-устойчивых нужд, но и с компанией Гугл, которая спонсирует молодых гениев, решивших спроектировать свои микросхемы с помощью вышедшего года три назад набора открытых средств проектирования под названием OpenLane. Превращение кода на верилоге в фотошаблон с помощью OpenLane выглядит так:

Я установил OpenLane на компьютере с Lubuntu 22.04 LTS по инструкции с гитхаба.
Сначала устанавливаются пререквизиты:
sudo apt install -y build-essential python3 python3-venv python3-pip
Потом устанавливается Докер:
sudo apt-get remove docker docker-engine docker.io containerd runc
sudo apt-get update
sudo apt-get install ca-certificates curl gnupg lsb-release
sudo mkdir -p /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg
| sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
echo "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu
\
$(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-compose-plugin
apt-cache madison docker-ce
sudo apt-get install docker-ce=5:20.10.17~3-0~ubuntu-jammy docker-ce-cli=5:20.10.17~3-0~ubuntu-jammy containerd.io docker-compose-plugin
sudo docker run hello-world
Потом надо добавить себя в группу, которая может запускать докер:
sudo usermod -aG docker $USER
, после чего перелогиниться. Теперь можно клонировать репозиторию OpenLane:
mkdir -p ~/github
cd ~/github
git clone https://github.com/The-OpenROAD-Project/OpenLane.gitВсе, инсталляция закончена, но нужно создать свой проект. Копируем наш исходник улыбающейся улитки на верилоге в директорию $HOME/github/OpenLane/designs/snail_moore_fsm/src , потом добавляем в $HOME/github/OpenLane/designs/snail_moore_fsm два скрипта на TCL (один - общий для контроля OpenLane, второй - для контроля библиотек от SkyWater) - и можно запустить синтез.
Но сначала нужно запустить докер. Это делается так:
cd $HOME/github/OpenLane
make mountТеперь вы видите промпт типа "OpenLane Container (xxxxxxx):/openlane$ ", под которым можно запускать скрипт на TCL:
./flow.tcl -design snail_moore_fsmСкрипт выполнит все 39 шагов синтеза и произведет вот такой главный лог. Интересно, что из исходного верилога синтезируется тоже верилог, но только низкоуровневый, и на каждой стадии в него добавляются всякие физические детали. В самом начале процесса компонент OpenLane под названием Yosys превращает верилог на уровне регистровых передач в верилог, который представляет сосбой просто создание экземпляров ячеек библиотеки Skywater и соединение их проводами. Вот посмотрите на это синтезированный код. Он ничего вам не напоминает? Конечно что, это те самые И, НЕ и D-триггеры, которые мы видели на макетной плате с технологией 50-летней давности. Только это технология 2018-го года, а не 1968-го:
/* Generated by Yosys 0.12+45 (git sha1 UNKNOWN, gcc 8.3.1 -fPIC -Os) */
module snail_moore_fsm(clk, reset, en, a, y);
wire _00_; wire _01_; wire _02_; wire _03_; wire _04_;
input a;
input clk;
input en;
input reset;
wire \state[2] ;
output y;
sky130_fd_sc_hd__nor2_2 _05_ ( .A(reset), .B(en), .Y(_03_) );
sky130_fd_sc_hd__or3b_2 _06_ ( .A(reset), .B(a), .C_N(en), .X(_04_) );
sky130_fd_sc_hd__a21bo_2 _07_ ( .A1(\state[2] ), .A2(_03_), .B1_N(_04_), .X(_01_) );
sky130_fd_sc_hd__and4b_2 _08_ ( .A_N(reset), .B(en), .C(\state[2] ), .D(a), .X(_02_) );
sky130_fd_sc_hd__a21o_2 _09_ ( .A1(y), .A2(_03_), .B1(_02_), .X(_00_) ); sky130_fd_sc_hd__dfxtp_2 _10_ ( .CLK(clk), .D(_00_), .Q(y) );
sky130_fd_sc_hd__dfxtp_2 _11_ ( .CLK(clk), .D(_01_), .Q(\state[2] ) );
endmoduleМы можем использовать современную инкарнацию древнего, из 1980-х, редактора Magic, чтобы посмотреть на результат на физическом уровне. Выглядит он так:a
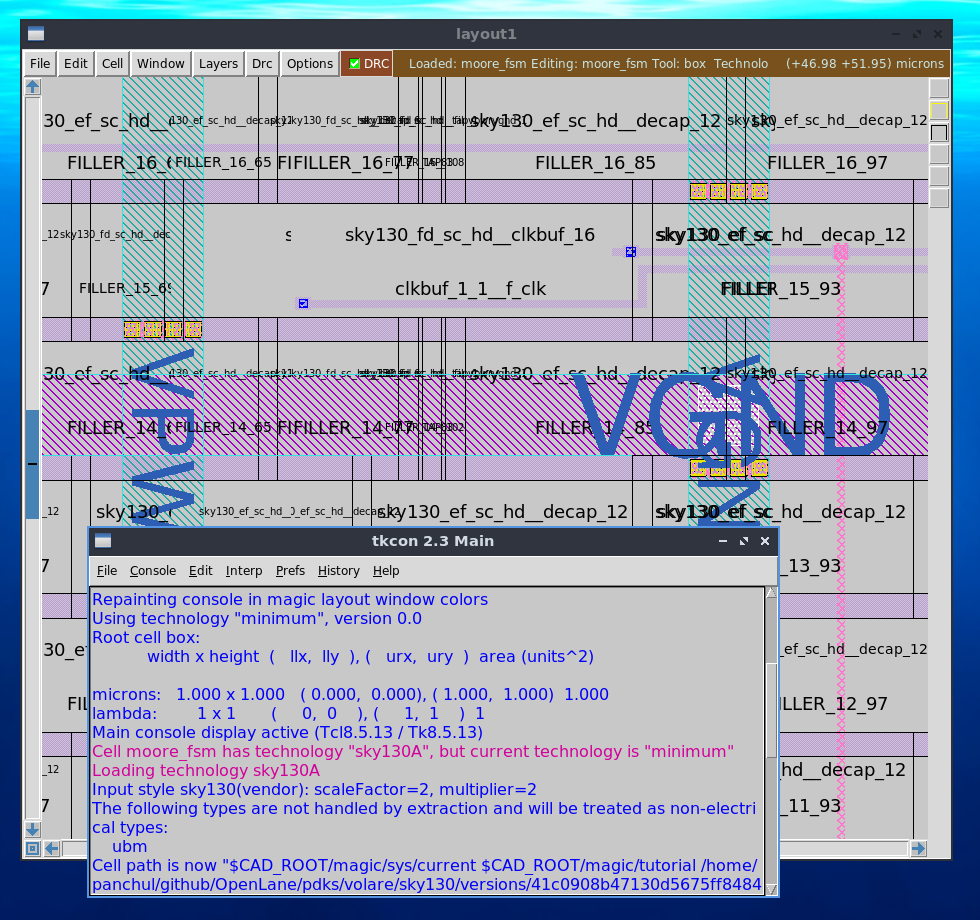
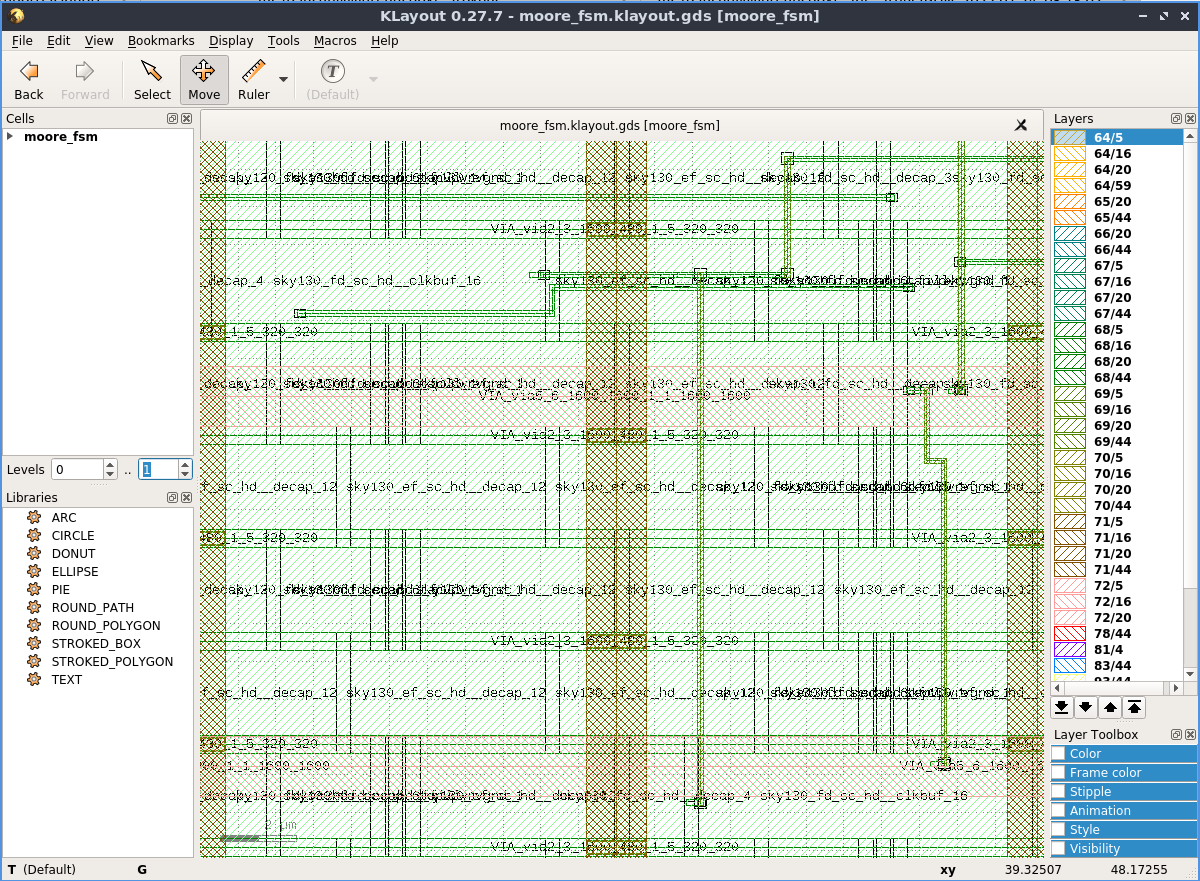
Magic запускается из докера просто как magic &. Затем вам нужно открыть файлы с расширением .mag, который вы можете найти в signoff внутри директории RUNS внутри вашего проекта. Также можно запустить редактор поновее, klayout, но он использует другой формат данных, файл с расширением .gds..
Также OpenLane производит стандартные для тулов такого рода отчеты о максимальной тактовой частоте, размерах, энергопортреблению итд - я собрал самые важные отчеты в репозитории файлов для семинара в Бишкеке.
Но перед тем, как улыбающуюся улитку синтезировать, ее нужно симулировать и отлаживать на временных диаграммах (это то, чем проектировщик микросхем на уровне регистровых передач занимается полдня, помимо митингов, писания кода и рисования микроархитектурных диаграмм). Вот так выглядят временные диаграммы "улыбающейся улитки" в бесплатной программе GTKWave после симуляции в бесплатном симуляторе Icarus Verilog:
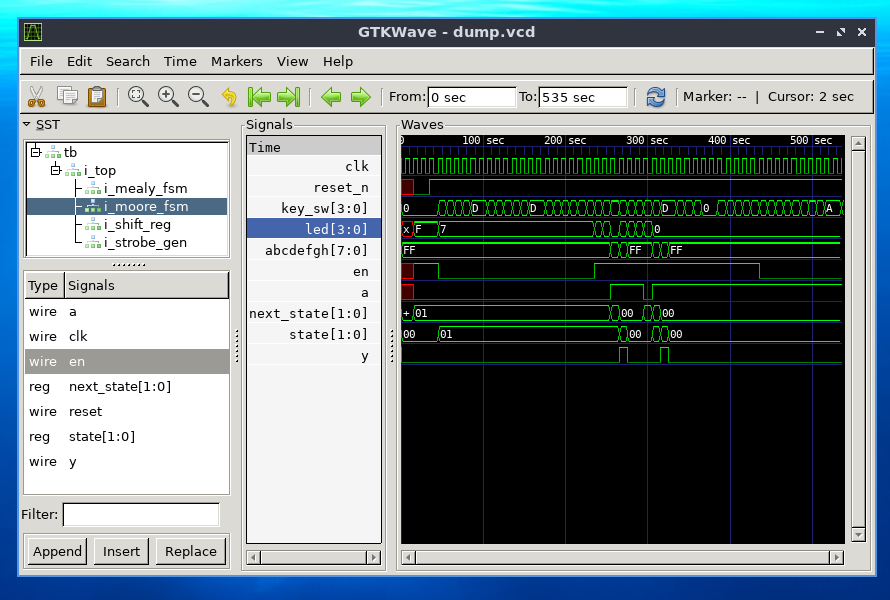
Однако Icarus медленный и не поддерживает всего языка SystemVerilog. А GTKWave очень тормозит когда у вас чуть больше сигналов, чем в игрушечном примере. К счастью, в Бишкеке будет компания Siemens EDA (в прошлом - Mentor Graphics), у которой есть симулятор Questa. У него лучше и поддержка языка, и скорость, и возможности отладки
.

Вот так выглядит "улыбающаяся улитка" в Квесте:

Про семинар в Бишкеке я уже писал, но ниже его детальное расписание. Еще не поздно сесть на самолет и туда прилететь. Заодно можете там со мной к исследованию среднеазиатской кухни:

.



До встречи!
|
|
Как вырастить культуру чиподелов в стране, где есть только программисты? |

Как показывает пример Южной Кореи и Тайваня, для небольшой страны очень выгодно интегрироваться в международную экосистему проектирования и производства микроэлектронных чипов. Каким же образом может интегрироваться страна, у которой есть опыт разработки программного обеспечения, но нет сообщества разработчиков микросхем? Она может создать группу по аутсорсу так называемой функциональной верификации. Эта группа технологий очень востребована и имеет реалистичный порог входа. Японская компания Seiko Epson создала такую группу на Филиппинах, корейская компания SK Hynix купила такую компанию в Беларуси.
Микросхемы внутри смарфонов, компьютеров и сетевого оборудования построены из блоков, спроектированных с помощью языка описания аппаратуры Verilog. Для этих блоков пишутся тесты на SystemVerilog, которые во многом похожи на программы на таких языках как Java. Кроме этого, для создания среды верификации блоков используют скриптовый язык Python. Для задач верификации аппаратных блоков можно переучить программистов с Java и Python на SystemVerilog, если добавить к их умениям понимание, как работает цифровая логика.
Это всё не абстрактные рассуждения. Американский Университет в Центральной Азии и Siemens Electronic Design Automation GmbH решили провести 1-3 августа пилотный семинар в Бишкеке, чтобы: 1) выяснить интерес у бизнесменов Кыргызстана к такого рода проектам и 2) показать студентам бишкекских вузов и коледжей, как работать с верилогом на ПЛИС, чтобы понять, пойдет ли им эта тематика. Участники из других стран тоже могут приехать.
Немного деталей. Типичная команда, разрабатывающая блок чипа в игровой приставке или роутере, работает так:
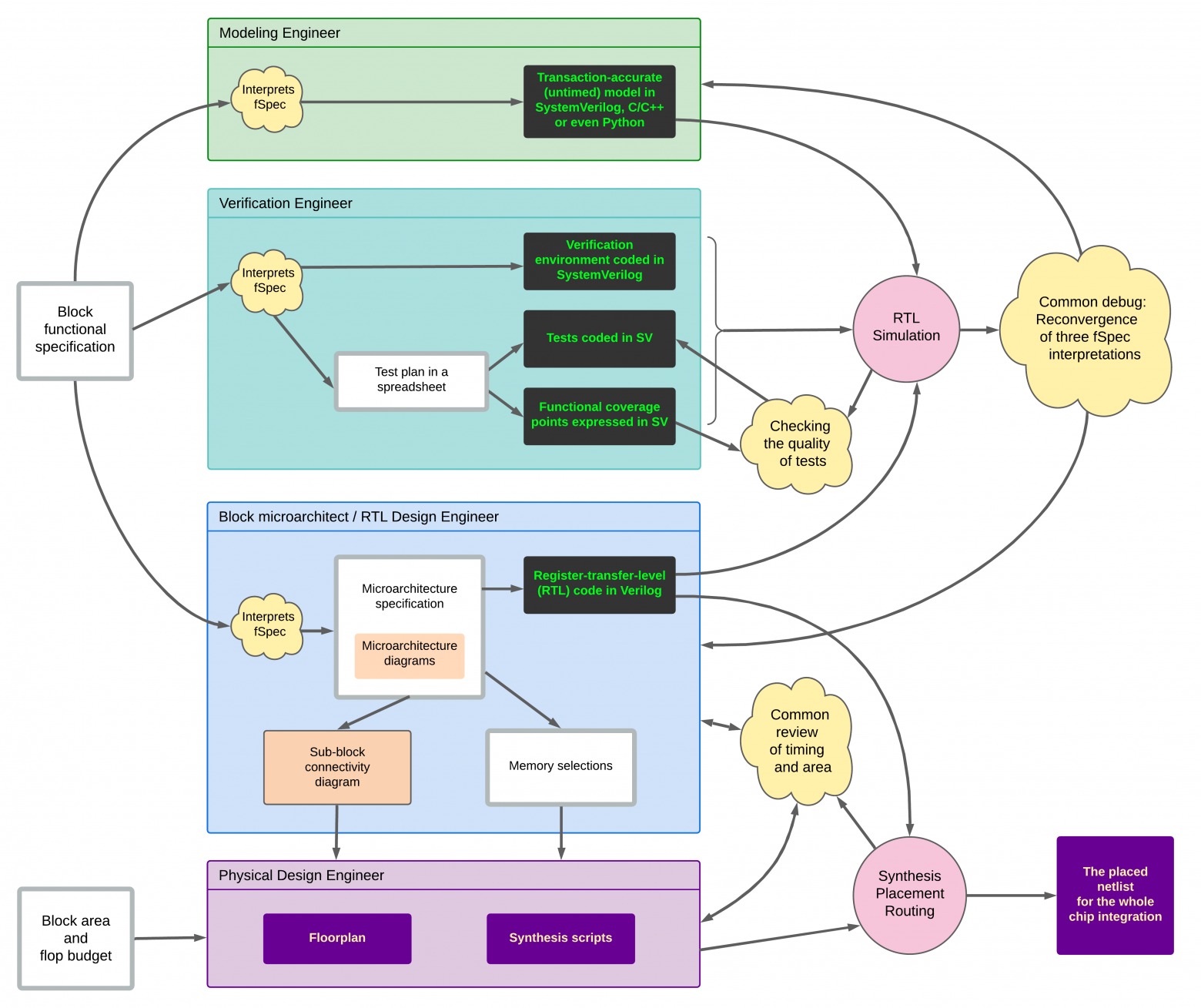
Четыре инженера получают архитектурную спецификацию от архитектора, после чего:
Инженер по моделированию пишет программу, которая имитирует, как ведет себя блок, но без погружения в детали на уровне тактов.
Инженер по логическому проектированию добавляет от себя эти детали, то бишь пишет микроархитектурную спецификацию (не путать с просто архитектурной), а затем и код на языке Verilog, который описывает, что блок делает в каждом такте. Эту специальность также называют "проектировщих на уровне регистровых передач", RTL Design Engineer (RTL = Register Transfer Level).
Инженер-верификатор пишет тесты, которые проверяют, что модель первого инженера и RTL код второго инженера одинаково реагируют на одинаковые события.
Инженер по физическому проектированию помогает RTL инженеру превратить его код на верилоге в схему, которая вписывается в тактовую частоту, бюджет размера и энергопотребления.
При наличии хороших программистов построить аутсорс функциональной верификации (3) и высокоуровневого моделирования (1) проще, чем аутсорс логического и физического проектирования. Квалификацию для верификации можно построить на основе курсов, плотной работы с консультантами из компаний типа Siemens EDA и представителями заказчиков.
С (2) и (4) сложнее. Для нетривиального логического проектирования нужен опыт в микроархитектуре, который развить без соответcтвующей среды нереально. А у физического проектирования высокий барьер входа, из-за бОльшей близости к физическим эффектам транзисторов и дорожек. Но это следующие ступени - в верификации и моделировании даже больше работ, чем в RTL и физике.

Эти темы мы обсудим на семинаре в АУЦА, который пройдет 1-3 августа 2022 года в Бишкеке. В начале каждого из трех дней будут выступать представители Siemens EDA, одного из трех мировых лидеров в области средств автоматизации проектирования микросхем. Они расскажут о бизнес-модели аутсорса функциональной верификации, маршруте разработки современных микросхем RTL-to-GDSII, и представят Questa Advanced Simulator, программное обеспечение для симуляции и отладки проектов.

БОльшая часть каждого из трех дней будет занята практическим семинаром. Он предназначен для студентов, которые умеют программировать на языках типа C или Java и хотят понять, чем проектирование чипов на верилоге отличается от программирования. Мы введем базовые элементы цифровой схемотехники: комбинационную и последовательностную логику, а также конечные автоматы. Затем мы проиллюстрируем эти понятия на трех уровнях сложности: с помощью микросхем малой степени интеграции, с помощью элементарных упражнений с синтезом кода на верилоге для FPGA, и с помощью более сложных упражнений с графикой и звуком.
Мы также затронем темы, которые возникают в повседневной работе проектировщика: как вычисляется максимальная тактовая частота, на которой может работать схема; что такое конвейерные вычисления; как организованы процессоры, графические чипы и сетевые маршрутизаторы. И расскажем об организации труда команд, разрабатывающих массовые устройства в крупных электронных компаниях.
Для практического семинара мы будем использовать платы Omdazz с ПЛИС IntelFPGA Cyclone IV и средой Intel® Quartus® Prime Lite Edition Version 21.1.1 которую можно скачать отсюда для Windows и отсюда для Linux.

Программа семинара:
Модели бизнеса и основы технологий микроэлектроники для Центральной Азии
Совместный семинар Американского Университета в Центральной Азии и Siemens EDA
1 августа 2022
9:30 - 10:00. Утренний кофе и открытие семинара.
Алмаз Бакенов, директор департамента информационных технологий АУЦА.
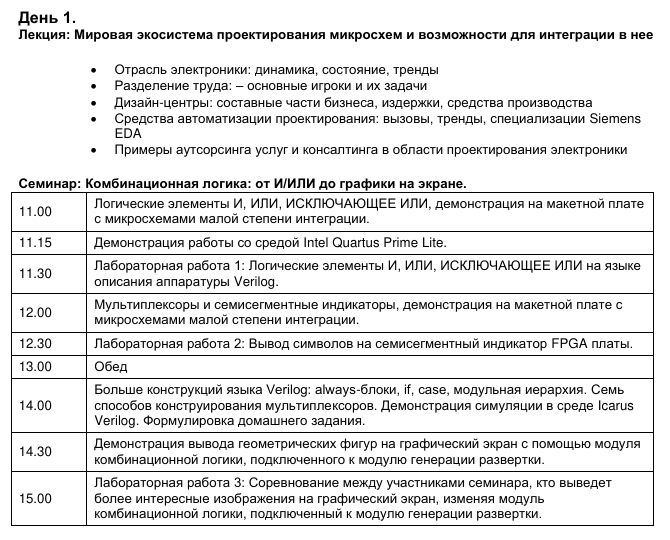
10:00 - 11:00. Лекция: Мировая экосистема проектирования микросхем и возможности для интеграцию в нее новых стран.
Денис Лобзов, Siemens Electronic Design Automation GmbH
11:00 - 13.00. Практический семинар: Основы современного маршрута проектирования цифровой логики.
Юрий Панчул, проектировщик микросхем для смартфонов и сетевых устройств
Часть 1. Синтез комбинационных схем из описаний на языке Verilog для микросхем программируемой логики.
13:00 - 14:00. Обед.
14:00 - 16.00. Практический семинар. Часть 2. Использование выученного материала для генерации изображений на графическом экране.
2 августа 2022
9:30 - 10:00. Утренний кофе.
10:00 - 11:00. Лекция: Обзор маршрута проектирования и производства микросхем
Siemens Electronic Design Automation GmbH
11:00 - 13.00. Практический семинар. Часть 3. Последовательностная логика и анализ временных задержек.
13:00 - 14:00. Обед.
14:00 - 16.00. Практический семинар. Часть 4. Использование выученного материала для распознавания звуков из микрофона.
3 августа 2022
9:30 - 10:00. Утренний кофе.
10:00 - 11:00. Лекция: Questa Advanced Simulator, программное обеспечение для симуляции и отладки проектов.
Siemens Electronic Design Automation GmbH
11:00 - 13.00. Практический семинар. Часть 5. Конечные автоматы и отладка в симуляторе.
13:00 - 14:00. Обед.
14:00 - 16.00. Практический семинар. Часть 6. Использование выученного материала для создания графической игры и распознавания мелодий флейты.
16:00 - 16.30. Закрытие семинара.

Для регистрации на семинаре вы можете прислать емейл Директору департамента информационных технологий Американского Университета в Центральной Азии Алмазу Бакенову bakenov_a@auca.kg
|
|
Тезисы, сформулированнные во время распития чая, о процессе интервью, с позиции интервьирующего |

|
|
Бодание с OpenLane. Часть 2. |

cd /home/panchul/github/OpenLane make mount
OpenLane Container (9accacf):/openlane$
./flow.tcl -design spm


cd /openlane ./flow.tcl -design yuri -init_design_config
/openlane/designs/yuri
/home/panchul/github/OpenLane/designs/yuri
# User config
set ::env(DESIGN_NAME) yuri
# Change if needed
set ::env(VERILOG_FILES) [glob $::env(DESIGN_DIR)/src/*.v]
# Fill this
set ::env(CLOCK_PERIOD) "10.0"
set ::env(CLOCK_PORT) "clk"
set filename $::env(DESIGN_DIR)/$::env(PDK)_$::env(STD_CELL_LIBRARY)_config.tcl
if { [file exists $filename] == 1} {
source $filename
}
./flow.tcl -design yuri

OpenLane Container (9accacf):/openlane$ ./flow.tcl -design picorv32a
OpenLane 9accacfc19f9c26ad094e2f7143b53d2cb6a859a
All rights reserved. (c) 2020-2022 Efabless Corporation and contributors.
Available under the Apache License, version 2.0. See the LICENSE file for more details.
[INFO]: Using design configuration at /openlane/designs/picorv32a/config.tcl
[INFO]: Sourcing Configurations from /openlane/designs/picorv32a/config.tcl
[INFO]: PDKs root directory: /home/panchul/github/OpenLane/pdks
[INFO]: PDK: sky130A
[INFO]: Setting PDKPATH to /home/panchul/github/OpenLane/pdks/sky130A
[INFO]: Standard Cell Library: sky130_fd_sc_hd
[INFO]: Optimization Standard Cell Library is set to: sky130_fd_sc_hd
[INFO]: Sourcing Configurations from /openlane/designs/picorv32a/config.tcl
[INFO]: Current run directory is /openlane/designs/picorv32a/runs/RUN_2022.06.26_16.50.38
[INFO]: Preparing LEF files for the nom corner...
[INFO]: Preparing LEF files for the min corner...
[INFO]: Preparing LEF files for the max corner...
[STEP 1]
[INFO]: Running Synthesis...
[STEP 2]
[INFO]: Running Single-Corner Static Timing Analysis...
[STEP 3]
[INFO]: Running Initial Floorplanning...
[INFO]: Extracting core dimensions...
[INFO]: Set CORE_WIDTH to 683.1, CORE_HEIGHT to 682.72.
[STEP 4]
[INFO]: Running IO Placement...
[STEP 5]
[INFO]: Running Tap/Decap Insertion...
[INFO]: Power planning with power {VPWR} and ground {VGND}...
[STEP 6]
[INFO]: Generating PDN...
[STEP 7]
[INFO]: Running Global Placement...
[STEP 8]
[INFO]: Running Placement Resizer Design Optimizations...
[STEP 9]
[INFO]: Writing Verilog...
[STEP 10]
[INFO]: Running Detailed Placement...
[STEP 11]
[INFO]: Running Clock Tree Synthesis...
[STEP 12]
[INFO]: Writing Verilog...
[STEP 13]
[INFO]: Running Placement Resizer Timing Optimizations...
[STEP 14]
[INFO]: Writing Verilog...
[INFO]: Routing...
[STEP 15]
[INFO]: Running Global Routing Resizer Timing Optimizations...
[STEP 16]
[INFO]: Writing Verilog...
[STEP 17]
[INFO]: Running Detailed Placement...
[STEP 18]
[INFO]: Running Global Routing...
[INFO]: Starting FastRoute Antenna Repair Iterations...
[STEP 19]
[INFO]: Running Fill Insertion...
[STEP 20]
[INFO]: Writing Verilog...
[STEP 21]
[INFO]: Running Detailed Routing...
[INFO]: No DRC violations after detailed routing.
[STEP 22]
[INFO]: Writing Verilog...
[INFO]: Running parasitics-based static timing analysis...
[STEP 23]
[INFO]: Running SPEF Extraction at the min process corner...
[STEP 24]
[INFO]: Running Multi-Corner Static Timing Analysis at the min process corner...
[STEP 33]
[INFO]: Running Magic Spice Export from LEF...
[STEP 34]
[INFO]: Writing Powered Verilog...
[STEP 35]
[INFO]: Writing Verilog...
[STEP 36]
[INFO]: Running LEF LVS...
[STEP 37]
[INFO]: Running Magic DRC...
[INFO]: Converting Magic DRC Violations to Magic Readable Format...
[INFO]: Converting Magic DRC Violations to Klayout XML Database...
[INFO]: No DRC violations after GDS streaming out.
[INFO]: Running Antenna Checks...
[STEP 38]
[INFO]: Running OpenROAD Antenna Rule Checker...
[STEP 39]
[INFO]: Running CVC...
[INFO]: Saving current set of views in 'designs/picorv32a/runs/RUN_2022.06.26_16.50.38/results/final'...
[INFO]: Saving runtime environment...
[INFO]: Generating final set of reports...
[INFO]: Created manufacturability report at 'designs/picorv32a/runs/RUN_2022.06.26_16.50.38/reports/manufacturability.rpt'.
[INFO]: Created metrics report at 'designs/picorv32a/runs/RUN_2022.06.26_16.50.38/reports/metrics.csv'.
[WARNING]: There are max slew violations in the design at the typical corner. Please refer to 'designs/picorv32a/runs/RUN_2022.06.26_16.50.38/reports/signoff/28-rcx_sta.slew.rpt'.
[INFO]: There are no hold violations in the design at the typical corner.
[INFO]: There are no setup violations in the design at the typical corner.
[SUCCESS]: Flow complete.
[INFO]: Note that the following warnings have been generated:
[WARNING]: There are max slew violations in the design at the typical corner. Please refer to 'designs/picorv32a/runs/RUN_2022.06.26_16.50.38/reports/signoff/28-rcx_sta.slew.rpt'.
|
|








