Set the Flux Capacitor for 12/30/1899 |
I mentally think of the early 2000s as "the XML Age". XML was everywhere. Everyone wanted to put XML into their applications. Java was the XML king, using XML for everything. People were starting to ask themselves, "do we need the big expensive RDBMS, when we can just use XML instead?"
In other words, just like JSON today, but worse. Tomislav A inherited one such database- a clunky pile of XML documents with only the vaguest hint of a schema to them, and a mix of valuable, useful data, and a mountain of crap. With the assumption that all data validation was happening in the application layer, the database was mostly "garbage in, garbage sits there forever and can never be deleted because it might be important".
Tomislav's job was to filter out the garbage, find the actually useful information, and move it into a real datastore. There were loads of problems and inconsistencies in the data, but with a little Python in his toolkit, Tomislav could mostly handle those.
For example, dates. Dates were stored in the XML as just text strings, because why would you use a structured document format to represent structured data? Since they were just strings, and since there was no data validation/sanitization in the application layer, there was no system to the strings. "31-DEC-2002" sat next to "12/31/2002" and "31/12/2002". With some help from dateutil.parser, Tomislav could handle most of those glitches without difficulty.
Until, when importing a date, he got the error: ValueError: year 39002 is out of range.
One of the dates in the document was just that- 39002. Knowing that there was no validation, Tomislav was ready to dismiss it as just corrupt data, but not before taking a stab at it. Was it the number of days, or maybe weeks since the Unix Epoch?
>>> datetime(2019, 1, 1) - datetime(1970, 1, 1)
datetime.timedelta(days=17897)
Nope, not even close. The rest of the record didn't look like garbage, though. And 39002 seemed so oddly specific. Tomislav had one advantage, though: one of the original developers was still with the company.
Heidi was still writing code, mostly keeping ancient MFC-based C++ applications from falling over. Because she was elbow deep in the Windows stack, it didn't take her more than a second of looking at the "date" to figure out what was going on.
"39002? That's the number of days since December 30th, 1899."
"What? Why?"
Heidi laughed. "Let me tell you a story."
Rewind time far enough, and the most important piece of software on the planet, at least from the end users perspective, was Lotus 1-2-3, which had the killer feature: it was Excel before Excel existed. All users ever want is Excel.
Spreadsheets are large, complex systems, and in the early days of Lotus 1-2-3, they were running on computers that had limitations on doing large, complex things. Compact representations which could be manipulated quickly were important. So, if you wanted to represent a date, for example, you wanted a single number. If you limit yourself to dates (and not times), then counting the number of days since an arbitrary threshold date seems reasonable. If you want times, you can make it a floating point, and use fractional days.
If you wanted to set a landmark, you could pick any date, but a nice round number seems reasonable. Let's say, for example, January 1st, 1900. From there, it's easy to just add and subtract numbers of days to produce new dates. Oh, but you do have to think about leap years. Leap years are more complicated- a year is a leap year if it's divisible by four, but not if it's divisible by 100, unless it's also divisible by 400. That's a lot of math to do if you're trying to fit a thousand rows in a spreadsheet on a computer with less horsepower than your average 2019 thermostat.
So you cheat. Checking if a number is divisible by four doesn't require a modulus operation- you can check that with a bitmask, which is super fast. Unfortunately, it means your code is wrong, because you think 1900 is a leap year. Now all your dates after February 28th are off-by-one. Then again, you're the one counting. Speaking of being the one counting, while arrays might start at zero, normal humans start counting at one, so January 1st should be 1, which makes December 31st, 1899 your "zero" date.
You've got a spreadsheet app with working dates that can handle thousands of cells in under 640k of RAM. It's time to ship it. The problem is solved.
Until Microsoft comes back into the picture, anyway. As previously stated, what users really want is Excel, but Excel doesn't exist yet. So you need to make it. Lotus 1-2-3 owns the spreadsheet space, so Microsoft is actually the plucky upstart here, and like all plucky upstarts, they have to start out by being compatible with the established product. Excel needs to be able to handle Lotus files. And that means it needs to handle Lotus dates. So it replicates the Lotus behavior, down to thinking 1900 is a leap year.
Lotus, and Excel, both think that 60 days after December 31st, 1899 is February 29th.
Time marches on. Excel needs to have macros, and the thought is to bolt on some of the newfangled Object-Oriented Basic folks have been experimenting with. This is a full-fledged programming language, so there's already an assumption that it should be able to handle dates correctly, and that means counting leap years properly. So this dialect of Basic doesn't think 1900 is a leap year.
This macro language thinks that 60 days after December 31st, 1899 is March 1st.
No problem. Move your start date back one more, to December 30th, 1899. Now Excel, Lotus, and our macro language all agree that March 1st, 1900, is day number 61. Our macro language is off-by-one for the first few months of 1900, but that discrepancy is acceptable, and no one at Microsoft, including Bill Gates who signed off on it, cares.
The Basic-derived macro language is successful enough inside of Excel that it grows up to be Visual Basic. It is "the" Microsoft language, and when they start extending it with features like COM for handling library linking and cross-process communication, it lays the model. Which means when they're figuring out how to do dates in COM… they use the Visual Basic date model. And COM was the whole banana, as far as Windows was concerned- everything on Windows touched COM or its successors in some fashion. It wasn't until .NET that the rule of December 30th, 1899 was finally broken, but it still crops up in Office products and SQL Server from time to time.
Tomislav writes:
I don't use any Microsoft technologies, and never did much. I always believed that if there was one common thing across all systems and technologies, it was 1970-01-01, the Epoch, the magic date!
Armed with a better picture of how weird dates could actually be, Tomislav was able to get back to work on trying to make sense of that XML database. Heidi still has her hands deep in the guts of ancient C++ applications that barely compile on modern Windows environments.
For me, the key take away is how small choices made ages ago, decisions which made sense at the time, keep cropping up. It's not just dates, although the Y2K bug and the 2038 problem both highlight how often this happens with dates. You never know when today's quick little cheat or hack becomes tomorrow's standard.
For more information on this topic:
COleDateTime and Excel's dateshttps://thedailywtf.com/articles/set-the-flux-capacitor-for-12-30-1899
|
Метки: Feature Articles |
CodeSOD: Collect Your Garbage Test |
Alex L works for a company with a bunch of data warehousing tools. One of the primary drivers for new features is adding bits which make the sales demos shinier, or in marketing speak, "delivers a value add for a prospective customer".
One of those "shinies" was a lightweight server which would gather stats from the data warehousing engine and provide a dashboard with those stats, and notifications about them. Prospective customers really love it when the machine goes "bing" and shows them an interesting notification.
As the notifications were becoming a bigger feature, the system needed a way to remember notification configuration between sessions, and that meant there needed to be a better persistence layer.
To add the feature, Alex started by looking at the existing tests for the notification system.
public class NotificationFeatureTest extends TestBase { @BeforeClass public static void init(){ start(new File(TestUtil.TEST_DIR, "notification")); } @Test public void testSetNotificationLevel() { NotifyClient client = new NotifyClient(connectionUrl); client.setNotifyAbove(0); //notify at 0% used client.publish(TestUtils.randomRow()); Assert.assertTrue(client.isNotified()); } /* and about 20 more simple such tests */ }
Pretty reasonable. The init method calls the base class's start method, which spins up a notification server and a notification client.
Using that as a model, Alex whipped up a test which would shut down the server, then restart it, and confirm that the data is still there.
@Test public void testPersistNotificationLevel() { NotifyClient client = new NotifyClient(connectionUrl); client.setNotifyAbove(32); //notify at 32% used testInst.shutdown(); testInst.start(); client = new NotifyClient(connectionUrl); Assert.assertEquals(32, client.getNotifyAbove()); }
testInst is the service instance created during the start. Unfortunately, when Alex ran this test, it exploded on testInst.start(), complaining: "Configuration not specified". But wasn't the point of the base-class start method to do that configuration step?
public abstract class TestBase { static int port = 8080; static String connectionUrl = null; static DashboardServer testInst =null; public static void start(File config) { testInst = new DashboardServer(port); testInst.setConfigurationFile(config.getAbsolutePath()); testInst.start(); connectionUrl = testInst.getUrl(); testInst = new DashboardServer(port); } /* stripped unnecessary variables and methods */ }
Well, sort of. The start method creates a testInst, configures it, and then starts it. So far so good. It then stuffs the URL of that instance into connectionUrl, which is also the url the NotifyClient uses to connect to the server in all of the tests.
And then they replace the started testInst with an entirely new, and unconfigured, testInst.
Alex went back through the history here, and found that this line had always been part of the TestBase class. The fact that any of the 400 tests in their test suite actually worked was basically an accident. It would start a server, release the reference to the server, and since the unit tests didn't live long enough for garbage collection to hit them, the server kept running even though there were no live references to it. Since NotifyClient was initialized with the connectionUrl from that living instance, everything worked.
Alex's test was the first one to directly touch testInst as a test step. It was easy for Alex to fix that line and get the test to pass. It was much harder to understand how and why that line got there in the first place, or why no one had ever noticed it before.
|
Метки: CodeSOD |
Error'd: Please Select All Errors that Apply |
"It doesn't impact me, but just wondering...which one would I pick if my spouse was named Elisabeth?" wrote Jon T.
Mark R. writes, "When it absolutely has to be there ...Yesterday!"
"Hmmmm...'Cancel' or 'Cancel Cancel'...which to pick..." writes Dave L.
Phil R. wrote, "Thankfully Levi's omitted 'Gent', 'Guy', 'Dude', 'Dude-Bro', and 'Fella'...or it might be REALLY confusing."
"So my wife was browsing the Domino's Canada menu and came across this gem...Yes, please! I'd love a side of delicious Collect Coupons!" Steve H. wrote.
Irving M. writes, "Umm, wasn't I already doing that? Am I supposed to see something special?"
 [Advertisement]
Forget logs. Next time you're struggling to replicate error, crash and performance issues in your apps - Think Raygun! Installs in minutes. Learn more.
[Advertisement]
Forget logs. Next time you're struggling to replicate error, crash and performance issues in your apps - Think Raygun! Installs in minutes. Learn more.
https://thedailywtf.com/articles/please-select-all-errors-that-apply
|
Метки: Error'd |
CodeSOD: A Date with a Consultant |
Management went out and hired a Highly Paid Consultant to build some custom extensions for Service Now, a SaaS tool for IT operations management. HPC did their work, turned over the product, and vanished the instant the last check cleared. Matt was the blessed developer who was tasked with dealing with any bugs or feature requests.
Everything was fine for a few days, until the thirthieth of January. One of the end users attempted to set the “Due Date” for a hardware order to 03-FEB–2019. This failed, because "Start date cannot be in the past".
Now, at the time of this writing, Feburary 3rd, 2019 is not yet in the past, so Matt dug in to investigate.
function onChange(control, oldValue, newValue, isLoading) {
if (isLoading /*|| newValue == ''*/) {
return;
}
//Type appropriate comment here, and begin script below
var currentDate = new Date();
var selectedDate = new Date(g_form.getValue('date_for'));
if (currentDate.getUTCDate() > selectedDate.getUTCDate() || currentDate.getUTCMonth() > selectedDate.getUTCMonth() || currentDate.getUTCFullYear() > selectedDate.getUTCFullYear()) {
g_form.addErrorMessage("Start date cannot be in the past.");
g_form.clearValue('date_for');
}
}The validation rule at the end pretty much sums it up. They check each part of the date to see if a date is in the future. So 05-JUN–2019 obviously comes well before 09-JAN–2019. 21-JAN–2020 is well before 01-JUL–2019. Of course, 01-JUL-2019 is also before 21-JAN-2020, because this type of date comparison isn't actually orderable at all.
How could this code be wrong? It’s just common sense, obviously.
Speaking of common sense, Matt replaced that check with if (currentDate > selectedDate) and got ready for the next landmine left by the HPC.
[Advertisement]
Forget logs. Next time you're struggling to replicate error, crash and performance issues in your apps - Think Raygun! Installs in minutes. Learn more.
|
Метки: CodeSOD |
Temporal Obfuscation |
We've all been inflicted with completely overdesigned overly generalized systems created by architects managers who didn't know how to scope things, or when to stop.
We've all encountered premature optimization, and the subtle horrors that can spawn therefrom.
For that matter, we've all inherited code that was written by individuals cow-orkers who didn't understand that this is not good variable naming policy.
Jay's boss was a self-taught programmer from way back in the day and learned early on to write code that would conserve both memory and CPU compilation cycles for underpowered computers.
He was assigned to work on such a program written by his boss. It quickly became apparent that when it came to variable names, let's just say that his boss was one of those people who believed that usefully descriptive variable names took so much longer to compile that he preemptively chose not to use them, or comments, in order to expedite compiling. Further, he made everything global to save the cost of pushing/popping variables to/from the stack. He even had a convention for naming his variables. Integers were named I1, I2, I3..., strings were named S1, S2, S3..., booleans were named F1, F2, F3...
Thus, his programs were filled with intuitively self-explanatory statements like I23 = J4 + K17. Jay studied the program files for some time and had absolutely no clue as to what it was supposed to do, let alone how.
He decided that the only sane thing that could be done was to figure out what each of those variables represented and rename it to something appropriate. For example, he figured out that S4 was customer name, and then went through the program and replaced every instance of S4 with customer_name. Rinse and repeat for every variable declaration. He spent countless hours at this and thought that he was finally making sense of the program, when he came to a line that, after variable renaming, now said: account_balance = account_balance - zip_code.
Clearly, that seemed wrong. Okay, he must have made a mistake somewhere, so he went back and checked what made him think that those variables were account balance and zip code. Unfortunately, that's exactly what they represented... at the top of the program.
To his chagrin, Jay soon realized that his boss, to save memory, had re-used variables for totally different purposes at different places in the program. The variable that contained zip code at the top contained item cost further down, and account balance elsewhere. The meaning of each variable changed not only by code location and context, but also temporally throughout the execution of the program.
It was at this point that Jay began his nervous breakdown.
|
Метки: Feature Articles |
A Mean Game of Pong |
Mark J spent some time as a contractor in the Supply & Inventory division of a Big Government Agency. He helped with the coding efforts on an antiquated requisition system, although as he would come to find, his offers to help went unappreciated.
The requisition system allowed a user to enter in a part number they needed and have it ordered for them. Behind the scenes, a database lookup by part number returned all warehouses that had it stocked. Then it determined the closest warehouse to where the request came from. Finally, it would create an order to have the part shipped from Warehouse X to the user's location. It was quite simple and worked fine for what Big Government Agency needed, except when it didn't.
Every now and then, chosen Warehouse X would reject the order. Milliseconds later, it would run back through the system and be rejected again Warehouse X. As a result, the message bounced back and forth thousands of times, creating enough traffic to crash the system.
Eager to be a problem solver, Mark asked Jacob, the head project manager, about the order rejection flaw. "It's a timing issue, depending on when the order is made," Jacob explained. There's a separate copy of the database on the server and at the warehouse. They sync up every night, but if the warehouse shipped its last of a part during the day and someone else orders it, it gets rejected."
Ignoring the asinine practice of not having a centralized database, Mark pressed on, "Ok, but why does the same order then come back to the same warehouse? Shouldn't it find the next closest warehouse and create an order from there?"
"I suppose that would be ideal," Jacob said, shrugging. "But the rejection just sends it back to the routing engine unaltered. So it's treated as a brand new order with the same out-of-sync inventory count. Thus, it's sent right back to the same warehouse, and so on. It's this dumb thing we call ping-ponging."
Mark furrowed his brow at Jacob's acceptance of this fundamental logic flaw. "That sounds absurd. Say the word and I will find a way to address this ping-pong nonsense. Then if I have time, I'll re-architect the data structure to have up-to-the-minute inventory statistics kept in a single copy of the database."
"Mark, we have too much else to do. We can't be worrying about technical debt like this," Jacob responded, growing irritated. "When it causes the system to crash, we just start it back up and go about our business."
Mark decided to drop his argument and began calculating how long his Big Government Agency contract had left. The following week he came in to find a ping pong paddle on his desk. Next to it lay a note from Jacob, "Hey Mark. Since you're so interested in helping with the ping-pong problem, I'm assigning you the duty of restarting the system whenever it goes down. Thanks for being a team player. ~ Jacob."
[Advertisement]
Forget logs. Next time you're struggling to replicate error, crash and performance issues in your apps - Think Raygun! Installs in minutes. Learn more.
|
Метки: Feature Articles |
CodeSOD: Sort Sort Sort Your Map, Functionally Down the Stream |
A while back, we saw "Frenk"'s approach to making an unreadable pile of lambda-based Java code. Antonio has some more code, which didn't come from Frenk, but possibly from one of Frenk's disciples, who we'll call "Grenk".
Imagine you have a list of users. You want to display those users in order by "lastname, firstname". Your usernames happen to be in the form "firstname.lastname". You also have actual "firstname" and "lastname" fields in your dataset, but ignore those for the moment, because for whatever reason, they never made it to this block of code.
There are a lot of relatively straightforward ways you can solve this problem. Especially, as there is already a TreeMap implementation in Java, which accepts a comparator and ensures the keys are sorted. That wouldn't let Grenk show off the cool new things they learned to do with streams and lambdas. There's a (relatively) new toy in the Java language, and gosh darn it, it needs to be used.
Map mapUsers = getSomeUserDataFromWherever();
Map mapUsersSorted = mapUsers.entrySet().stream().sorted(Map.Entry.comparingByKey((s1, s2) -> {
if (s1.split("\\.").length < 2)
s1 = s1 + "." + s1;
if (s2.split("\\.").length < 2)
s2 = s2 + "." + s2;
return s1.split("\\.")[1].compareToIgnoreCase(s2.split("\\.")[1]);
})).collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue, (oldValue, newValue) -> oldValue, LinkedHashMap::new));
An "elegant" solution using "functional" programming techniques. The logic is… interesting. The key comparison is the return s1.split… line, which grabs the bit after the first period, so if the username were joebob.bobsen it compares bobsen with the other string. It's wrong, of course, and it will break in the "unlikely" case that two users have the same last name.
More interesting is the "sanity" check above. Some users, like prince, may not have a last name. Or a first name, I suppose, depending on how you want to look at it. Lots of naming traditions around the world might not guarantee a distinct surname/given-name distinction. So, with that in mind, Grenk solved the problem once and for all… by duplicating the first part of their name as if it were the last name as well.
What we have here is code written in the most complex way it could be, that also happens to be wrong, and frenkly was the absolute worst way to solve the problem.
[Advertisement]
Forget logs. Next time you're struggling to replicate error, crash and performance issues in your apps - Think Raygun! Installs in minutes. Learn more.
https://thedailywtf.com/articles/sort-sort-sort-your-map-functionally-down-the-stream
|
Метки: CodeSOD |
Error'd: The Results are (Almost) In! |
"Oh man! This results of this McDonalds vote look like they're going to be pretty close...or miles apart...," Pascal writes.
"Yeah the Kindle Edition is a pretty sweet deal, but I think that I'll just wait for the movie to come out," writes Wesley F.
Dustin S. wrote, "My password is soooo close to being done updating. Just a little bit longer."
George B. wrote, "Well, Emojipedia, you're close I'll give you that."
"I suppose I could earn enough caps eventually," Jose B. writes.
Walter wrote, "Well, sure, it's easy to save on kitchen appliances whose size is null."
[Advertisement]
Forget logs. Next time you're struggling to replicate error, crash and performance issues in your apps - Think Raygun! Installs in minutes. Learn more.
|
Метки: Error'd |
CodeSOD: Giving 104% |
Dates, as we have explored exhaustively, are hard. And yet, no matter how much we explore dates, and the myriad ways developers can completely screw them up, there are constantly new borders of date-related idiocy ahead of us.
The app Michael supported was running on a server running an Ubuntu version that was more than a little ancient, so as a test, he upgraded to the latest LTS version. That also included upgrades to the MySQL version they were running.
And right after doing the upgrade, errors like this started to appear: ERROR 1292 (22007): Incorrect datetime value: '2019-07-23 24:59:59' for column 'update_endDate'
Well, obviously, 24:59:59 is not a valid datetime value. Obviously, someone rolled a custom date-handling function, and something in the upgrade revealed an off-by-one error. Off-by-one bugs (or “OBOB” as one professor I had liked to call them) are common and easy.
Michael’s guess was technically correct. There was an off-by-one error, only it wasn’t in the code. It was in the original developer’s brain:
$temp_epoch_update_endDate=mktime(24,59,59,$TCMonth+6,$TCDay,$TCYear);
$EUMonth=date("m",$temp_epoch_update_endDate);
$EUDay=date("d",$temp_epoch_update_endDate);
$EUYear=date("Y",$temp_epoch_update_endDate);
$Cust_update_endDate="$EUYear-$EUMonth-$EUDay 24:59:59";I’d say this code was designed for Mars, but even a Martian day is a smidge under 25 hours. The real WTF is that, somehow, this code worked at one time.
|
Метки: CodeSOD |
CodeSOD: Internal Validation |
If you’re doing anything financial in Brazil, you have to manage “CNPJ” numbers. These numbers are unique identifiers for every business and every branch of that business, along with a pair of check-digits to validate that it’s a correct code. Everyone from banks to accountants to businesses needs to track and manage these.
When Patria joined a microscopic startup as an intern. The startup made an accounting package, and thus needed to track CNPJs. She asked the lead developer, “Hey, how do I validate those check-digits?”
“Actually, as an intern, that’s probably a really good beginner task for you.”
They were a very new startup, so it wasn’t a surprise that the current validation routine was simply return True. Patria, with no industry experience, had her task, and ran off to solve the problem.
“Could you review my code before I merge?” she asked the lead dev.
“Nah, just go ahead and merge, I’m sure it’s fine.”
This is what Patria merged.
public static bool ValCNPJ(string cnpj)
{
string cnpj_a = Util.fillWith(Util.trimZero(cnpj.Trim()), 14, "0");
int[] cnpj_n;
cnpj_n = new int[14];
int um, dois, tres, quatro, cinco, seis, sete, oito, nove, dez, onze, doze, treze, soma, dv1 = -1, dv2;
Boolean cnpj_v = true;
//Checando tamanho do numero
if (cnpj_a.Length != 14)
{
cnpj_v = false;
}
else
{
for (int i = 0; i < 14; i++)
cnpj_n[i] = Convert.ToInt32(cnpj_a.Substring(i, 1));
//Checando primeiro digito verificador
um = cnpj_n[0] * 5;
dois = cnpj_n[1] * 4;
tres = cnpj_n[2] * 3;
quatro = cnpj_n[3] * 2;
cinco = cnpj_n[4] * 9;
seis = cnpj_n[5] * 8;
sete = cnpj_n[6] * 7;
oito = cnpj_n[7] * 6;
nove = cnpj_n[8] * 5;
dez = cnpj_n[9] * 4;
onze = cnpj_n[10] * 3;
doze = cnpj_n[11] * 2;
soma = (um + dois + tres + quatro + cinco + seis + sete + oito + nove + dez + onze + doze) % 11;
if (soma < 2)
{
if (cnpj_n[12] != 0) cnpj_v = false;
else dv1 = 0;
}
else
{
dv1 = 11 - soma;
if (cnpj_n[12] != dv1) cnpj_v = false;
}
// Checagem do segundo digito verificador
um = cnpj_n[0] * 6;
dois = cnpj_n[1] * 5;
tres = cnpj_n[2] * 4;
quatro = cnpj_n[3] * 3;
cinco = cnpj_n[4] * 2;
seis = cnpj_n[5] * 9;
sete = cnpj_n[6] * 8;
oito = cnpj_n[7] * 7;
nove = cnpj_n[8] * 6;
dez = cnpj_n[9] * 5;
onze = cnpj_n[10] * 4;
doze = cnpj_n[11] * 3;
treze = dv1 * 2;
soma = (um + dois + tres + quatro + cinco + seis + sete + oito + nove + dez + onze + doze + treze) % 11;
if (soma < 2)
{
if (cnpj_n[13] != 0) cnpj_v = false;
}
else
{
dv2 = 11 - soma;
if (cnpj_n[13] != dv2) cnpj_v = false;
}
}
return cnpj_v;
}The underlying goal is to do a checksum with a mod–11 rule. If you aren’t comfortable with for-loops, and only passingly comfortable with arrays of integers, it looks pretty good. Patria writes, “It’s not The Brilliant Paula Bean and it does actually work as it should, but dear Lord do I look at this snippet of code and cringe.”
This is definitely bad code, but in its badness, I actually appreciate how clear it makes the rules for applying the checksum. Well, mostly clear, some of those conditionals get a little ugly, and nobody likes it when you if (someCondition) foo=False.
This story has a much happier ending than usual. Patria is now the lead developer at the same company. She’s happily thrown away this code, replaced it with something much cleaner, and always helps interns and juniors with scrupulous and constructive code reviews.
|
Метки: CodeSOD |
CodeSOD: Why Is This Here? |
Oma was tracking down a bug where the application complained about the wrong parameters being passed to an API. As she traced through the Java code, she spotted a construct like this:
Long s = foo.getStatusCode();
if (s != null) {
//do stuff
} else {
//raise an error
}
Now, this wasn't the block which was throwing the error Oma was looking for, but she noticed a lot of if (s != null) type lines in the code. It reeked of copy/paste coding. Knowing what was about to happen, Oma checked the implementation of getStatusCode.
protected Long getStatusCode() throws ProductCustomException{
Long statusCode = null;
try{
statusCode = Long.valueOf(1); //Why is this here?
} catch (Exception ex) {
throw new ProductCustomException(ProductMessages.GENERIC_PRODUCT_MESSAGES, ex);
}
return statusCode;
}
//Why is this here? is part of the original code. It's also the first question which popped into my head, followed by "why am I here" and "what am I doing with my life?"
For bonus points, what's not immediately clear here is that the indenting is provided via a mix of spaces and tabs.
|
Метки: CodeSOD |
Relative Versioning |
Today's submission comes from someone going by Albert Einstein. Before we look at what they sent us, let's talk a little bit about version numbers.
Version numbers, if you think about it, are a deeply weird construct, and they're trying to balance a lot of difficult goals. At its simplest, a version number is meant to order your releases. Version 2 comes after version 1. Version 3 comes next. But even this simple goal is surprisingly difficult, because your releases only exist in order if you only have one chain of history for your product. The instant you have to have a custom build for one customer, or you start doing AB testing, or your library has to provide multiple interfaces for different deployment conditions, or one developer down in the basement decides to fork and not tell anyone- releases cease to have a linear order.
Well, those kinds of disordered changes and branching versions sounds like a directed acyclic graph, which not only sounds extremely clever, but is how Git manages your history. We could theoretically just tag our releases with the commit hash, giving us a unique version number that allows us to quickly and cleanly know what version of the code we're talking about. But commit hashes are opaque and meaningless- which brings us to the other goal of version numbers.
Version numbers not only order our releases, they also are meant to convey information about the content and delta between those releases. Semantic versioning, for example, tries to guarantee that we can make certain assumptions about the difference between version 1.0.1, 1.0.5, 1.1.2, and 2.1.1. Changes to the last digit imply that it's only patches and bugfixes, and shouldn't change behavior. That can get you pretty far, assuming you don't bump into one of those cases where "every change breaks somebody's workflow". Even then, though, incrementing the major version number means there might be breaking changes, but doesn't require that there are, which is why Angular is on version 247 but hasn't seen much by way of breaking changes since version 4.
And that's another thing version numbers need to accomplish: they're a marketing/communication tool to educate your public about your product. Anyone who can count can understand that higher version numbers must be newer, and thus be the preferred version. People watch those version numbers tick up, and it gives them a sense that active development is ongoing.
With all of these goals, I don't think there is a single way to solve the version numbering problem. Maybe you use semantic versioning. Maybe you go the Chrome route and just increment the major version every Tuesday. Maybe you go the Microsoft route and have piles of hot patches and fixes with no clear order or relationship to their application.
What you probably don't want to do is go the route which Albert Einstein's company has gone. What follows is a full listing of every version, in chronological order of release, for a single product. Each entry on this list represents a single release.
v2.4.2
v2.4.2
v2.4.2
v2.4.2
v2.4.2
v2.4.2
v2.4.2
v2.4.2
v2.5
v2.6
v3.0
v3.0
v3.0.1
v0.1
v0.1
v0.1
v0.1.1
v0.1.2
v0.0.1
v0.0.2
v0.0.3
v0.0.4
v0.0.5
v0.2
v0.2
v0.2
v0.2.1
v0.2.1
v0.2.2
v0.2.3
v0.2.4
v0.2.5
v0.2.6
v1.0.0
v1.0.2
v1.0.3
v1.0.4
v1.0.5
v1.0.4
v1.0.5
v1.0.6
v1.0.7
v1.3.4
1.3.5
v1.3.6
v1.3.5
v1.3.7
v1.3.8
v1.3.9
v1.3.10
I believe there's no guaranteed good way to generate version numbers. But there's definitely bad ways to do it, and whatever this is, it's one of the bad ones. God might not play dice with the universe, but someone's been playing dice to generate version numbers.
|
Метки: Feature Articles |
Error'd: An Internet of Crap |
"One can only assume the CEO of Fecebook is named Mark Zuckerturd," writes Eric G..
"Crucial's website is all about consumer choice and I just can't decide!" writes Charles.
"Countdown started? I had better get a move on! Only 364.97 days left on this auction," Wesley F. wrote.
Pascal wrote, "The 'connected device table' lists 9 devices total, but when my router counts them -3 times each?"
"Looking forward to round 2's deal, which I'm guessing will offer a game at lbYY.YY," writes Richard S.
"In a case like this, the name of the tab kind of explains what's going on, but hey, at least the login prompt is still there!" Geoff G. writes.
|
Метки: Error'd |
CodeSOD: The Pair of All Sums |
Learning about data structures- when to use them, how to use them, and why- is a make-or-break moment for a lot of programmers. Some programmers master this. Some just get as far as hash maps and call it a day, and some… get inventive.
Let’s say, for example, that you’re Jim J’s coworker. You have an object called a Closing. A Closing links two Entrys. This link is directed, so entry 1->2 is one Closing, while 2->1 is another. In real-world practice, though, two Closings that are linked together in both directions should generally be interacted with as pairs. So, 1->2 and 2->1 may not be the same object, but they’re clearly related.
Jim’s coworker wanted to gather all the pairs were together, and put them into groups, so 1->2 and 2->1 are one group, while 3->1 and 1->3 are another. This was their approach.
// go through all closings
// ordered by sum of entryId and refEntryId to get all pairs together
foreach (var closing in closings.OrderBy(c => c.EntryId + c.RefEntryId))
{
// exit condition for group
// if the sum of the entry ids is different then its another group
if (entryIdRefEntryId != closing.EntryId + closing.RefEntryId)
{
// get new sum
entryIdRefEntryId = closing.EntryId + closing.RefEntryId.Value;
// return and reset
if (closingGroup != null)
{
yield return closingGroup;
closingGroup = null;
}
}
// the rest of the logic omitted
}Jim claims the “original comments preserved” here, though I suspect that // the rest of the logic omitted might not be an original comment. Then again, looking at the code, that might not be the case.
This sorts the closings by the sum of their entry IDs. For each Closing in that list, if the sum of its refs are the same, we add it to a closingGroup (that’s some of the omitted code). If the sum isn’t the same, well, we’ve reached the end of a group. Update our sum, and yield the current closingGroup back to the calling code.
For funsies, follow that chain of logic on pairs like: 11<->14, 12<->13, and 10<->15.
Jim adds: “These pairings are not very probable, but still possible, and that makes the reproduction of the bug quite challenging.”
|
Метки: CodeSOD |
CodeSOD: Ternt Up GUID |
UUIDs and GUIDs aren’t as hard as dates, but boy, do they get hard, don’t they. Just look at how many times they come up. It’s hard to generate a value that’s guaranteed to be unique. And there’s a lot of ways to do it- depending on your needs, there are some UUIDs that can be sorted sequentially, some which can be fully random, some which rely on hash algorithms, and so on.
Of course, that means, for example, your UUIDs aren’t sequential. Even with time-based, they’re not in sequence. They’re just sortable.
Pitming S had a co-worker which wanted them to be sequential.
private String incrementGuid(String g)
{
if (String.IsNullOrWhiteSpace(g))
return "Error";
//else
try
{
//take last char and increment
String lastChar = g.Substring(g.Length - 1);
Int32 nb = 0;
if (Int32.TryParse(lastChar, out nb))
{
++nb;
if (nb == 10)
{
return String.Format("{0}a", g.Substring(0, g.Length - 1));
}
return String.Format("{0}{1}", g.Substring(0, g.Length - 1), nb);
}
else
{
return String.Format("{0}{1}", g.Substring(0, g.Length - 1), lastChar == "a" ? "b" : lastChar == "b" ? "c" : lastChar == "c" ? "d" : lastChar == "d" ? "e" : lastChar == "e" ? "f" : lastChar == "f" ? "0" : "error");
}
}
catch (Exception ex)
{
return ex.Message;
}
}So, this method, theoretically accepts a GUID and returns the “next” GUID by incrementing the sequence. Sometimes, the next GUID is “Error”. Or “error”. Assuming that there isn’t an error, this code picks off the last character, and tries to turn it into an int. If that works, we add one, and put the result on the end of the string. Unless the result is 10, in which case we put “a”. And if the result isn’t a number, then it must be a letter, so we’ll plop a pile of ternary abuse in place of hexadecimal arithmetic.
The best part of “incrementing” the GUID is that it doesn’t guarantee continued uniqueness. The last bytes in the GUID (depending on the generating method) probably won’t impact its uniqueness (probably, anyway). Unless, of course, you only modify the last digit in the sequence. When this code hits “f”, we wrap back around to “0”. So we have 16 increments before we definitely aren’t unique.
Why? To what end? What’s the point of all this? Pitming has no idea. I have no idea. I suspect the original developer has no idea. But they can increment a GUID.
|
Метки: CodeSOD |
CodeSOD: Switch the Dropdown |
Bogdan Olteanu picked up a simple-sounding bug. There was a drop-down list in the application which was missing a few entries. Since this section of the app wasn't data-driven, that meant someone messed up when hard-coding the entries into the dropdown.
Bogdan was correct. Someone messed up, alright.
Destinatii = new List(4);
for (int i = 0; i < Destinatii.Capacity; i++)
{
switch (i)
{
case 0: Destinatii.Add(new Destinatii { code = "ANGAJARE", description = "ANGAJARE" });
break;
case 1: Destinatii.Add(new Destinatii { code = "INSCRIERE", description = "^INSCRIERE" });
break;
case 2: Destinatii.Add(new Destinatii { code = "EXAMEN AUTO", description = "EXAMEN AUTO" });
break;
case 3: Destinatii.Add(new Destinatii { code = "SOMAJ", description = "SOMAJ" });
break;
case 4: Destinatii.Add(new Destinatii { code = "AJUTOR SOCIAL", description = "AJUTOR SOCIAL" });
break;
case 5: Destinatii.Add(new Destinatii { code = "TRATAMENT", description = "TRATAMENT" });
break;
case 6: Destinatii.Add(new Destinatii { code = "GRADINITA", description = "GRADINITA" });
break;
}
}
Once again, we have the fairly standard WTF of the loop-switch sequence, or the duffer device. Except this is dumber than even that, since there's absolutely no reason to do it this way. Normally, a loop-switch is meant to perform different behaviors on each iteration, here it just appends a value on each loop. This is an anti-pattern within the anti-pattern. They used the anti-pattern wrong! The cases are irrelevant.
Well, mostly irrelevant. Combined with the loop condition, based on Destinatii.Capacity, it's easy to understand why some values don't appear in the output.
Since you can initialize a list in .NET with a literal array, Bogdan went ahead and did that, replacing this block with essentially a one-liner.
|
Метки: CodeSOD |
Crushing Performance |

Many years ago, Sebastian worked for a company which sold self-assembled workstations and servers. One of the company's top clients ordered a server as a replacement for their ancient IBM PS/2 Model 70. The new machine ran Windows NT Server 4.0 and boasted an IPC RAID controller, along with other period-appropriate bells and whistles. Sebastian took a trip out to the client site and installed the new server in the requested place: a table in front of the receptionist's desk, accessible by anyone walking through the main entrance. Not the best location from a security standpoint, but one of the new server's primary tasks in life would be to serve the company's telephone directory, installed on CD-ROM.
Two weeks later, the client called back, irate over the fact that the new server performed terribly compared to their old one. Troubleshooting efforts via phone were ineffective; the client demanded on-site support. After several frantic conference calls involving Sales, Support, and nosebleed-level management, Sebastian was on a plane back to the client site.
Once back within the client's stuffy lobby, he could see that the server setup had in fact changed since he'd last been there, despite the client's repeated insistence to the contrary. Someone had placed both the old and new server boxes under the table. Two CRT monitors sat side-by-side on the table along with their corresponding mice. The keyboards were on a roll-out drawer just under the surface. Both machines were already logged in as administrator, waiting for anyone to come along and not exploit that fact.
After checking in with his on-site contact and securing a cup of coffee, Sebastian got to troubleshooting. First thing, he used the mouse to open the Start menu on the new server—but as soon as he released the mouse button, the Start menu collapsed. He tried a few more times with no success.
Frowning, Sebastian rolled out the keyboard drawer, hoping to try a keyboard shortcut next. When he did so, he found the keyboards set up one in front of the other. The strain relief on the back of the old server's keyboard was sitting right on top of the space bar of the new server's keyboard. Apparently, it'd been holding down the space bar for the past two weeks straight.
Sebastian pulled the old server keyboard onto the table. Sure enough, the new server behaved normally from then on. Thousands of dollars spent, hundreds of miles flown—all to lift one keyboard away from another.
[Advertisement]
Forget logs. Next time you're struggling to replicate error, crash and performance issues in your apps - Think Raygun! Installs in minutes. Learn more.
|
Метки: Feature Articles |
Announcements: TheDailyWtf.com Server Migration Complete |
If you're reading this message, then it means that I managed to successfully migrate TheDailyWTf.com and the related settings from our old server (74.50.110.120) to the new server (162.252.83.113).
Shameless plug: I did all of this by setting up a configuration role in our internally-hosted Otter instance for both old and new servers (to make sure configuration was identical), deploying the last successful build to the new server using our internally-hosted BuildMaster instance, and then manually installing the certificate and configuring the database.
Here's what the OtterScript looks like for the server's configuration. I'd love to move this to a publically-hosted instance, soon!
# TheDailyWtf.com and Aliases
{
IIS::Ensure-AppPool WtfAppPool
(
Runtime: v4.0,
Pipeline: Integrated,
IdentityType: ApplicationPoolIdentity
);
IIS::Ensure-Site TheDailyWtf.com
(
AppPool: WtfAppPool,
Path: C:\Websites\TheDailyWTF\thedailywtf.com
);
IIS::Ensure-VirtualDirectory Images
(
Site: TheDailyWtf.com,
PhysicalPath: c:\Websites\TheDailyWTF\WTF Images
);
IIS::Ensure-SiteBinding
(
Site: TheDailyWtf.com,
Protocol: https,
HostName: thedailywtf.com,
Port: 443,
Certificate: thedailywtf.com,
CertificateStoreLocation: CurrentUser,
CertificateStore: WebHosting
);
foreach $HostName in @(img.worsethanfailure.com, www.worsethanfailure.com,
worsethanfailure.com,img.thedailywtf.com,www.thedailywtf.com,thedailywtf.com)
{
IIS::Ensure-SiteBinding
(
Site: TheDailyWtf.com,
HostName: $HostName
);
}
}
# Novelty Sites
{
IIS::Ensure-AppPool StaticHtmlAppPool
(
Runtime: No Managed Code
);
foreach $Site in @(TheDailyWth.com, Virtudyne.com, Codethulhu.com)
{
IIS::Ensure-Site $Site
(
AppPool: DefaultAppPool,
Path: C:\Websites\Novelty\$Site,
Bindings: @(%(IPAddress: *, Port: 80, HostName: $Site, Protocol: http))
);
}
}Let me know if you notice any issues -- apapadimoulis at inedo dot com!
Update: Someone mentioned that the certificate on the new server doesn't include the img.thedailywtf.com sudomain, and that on some images that still use that subdomain, you may find images not loading if you're browsing over HTTPS. I forgot to add that to our certificate when we bought it, so I'll try to fix it soon.
https://thedailywtf.com/articles/thedailywtf-com-server-migration-complete
|
Метки: Announcements |
Error'd: Next Stop...Errortown |
"Rather than tell me when the next train is supposed to arrive, this electronic sign is helpfully informing me that something's IP address is...disabled?" Ashley A. writes.
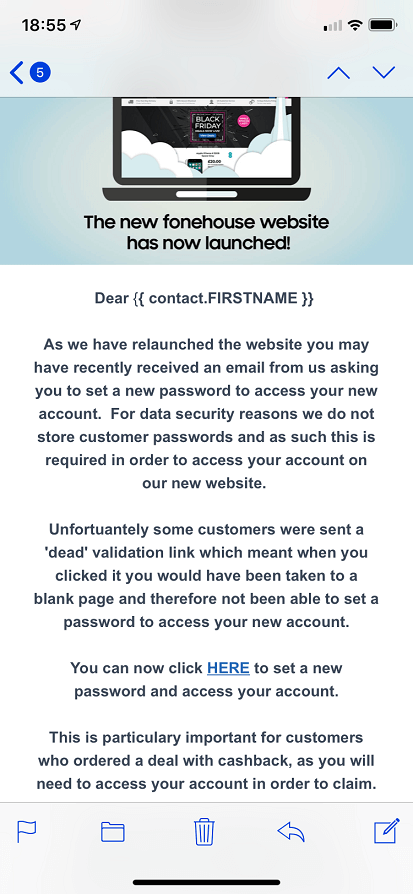
"I think that fonehouse may need to apologize for their apology," writes Paul B.
Brian C. wrote, "Many new riders don't expect it, but my commuter train goes through several dimensions where time is kept quite differently.
"When your email about keeping messages out of the spam folder, ends up in the spam folder, you may want to reconsider your marketing stragtegy," John Z. writes.
"I upgraded to macOS Mojave yesterday and Adobe decided it wanted to reactivate everything. Honestly, I think I can let it slide," wrote Wayne W.
Rob spotted this at the Computer History Museum in San Francisco proving that even classic pieces of software are exempt from Flash issues.
|
Метки: Error'd |
CodeSOD: Certifiable Success |
“Hey, apparently, the SSL cert on our web-service expired… in 2013.”
Laura’s company had a web-service that provided most of their business logic, and managed a suite of clients for interacting with that service. Those clients definitely used SSL to make calls to that web-service. And Laura knew that there were a bunch of calls to ValidateServerCertificate as part of the handshaking process, so they were definitely validating it, right?
private static bool ValidateServerCertificate(
object sender,
System.Security.Cryptography.X509Certificates.X509Certificate certificate,
System.Security.Cryptography.X509Certificates.X509Chain chain,
System.Net.Security.SslPolicyErrors sslPolicyErrors)
{
return true;
}Well, that’s one kind of validation rule. It’s guaranteed to never fail, if nothing else.
|
Метки: CodeSOD |