CodeSOD: Users That Bug You |
I frequently write bad code. I mean, we all do, but I frequently write bad code with full knowledge that it's bad, because I first want to test out an idea. Or, I want to inject some additional behavior just for one run, because I'm trying to debug something. If that idea or debugging hook turns out to be valuable, I'll frequently refactor it into something useful and enable it via a flag or something.
Which brings us to the crash Doug was investigating in a VB.Net application. For some reason, the username field was an empty string after logging in, and a bunch of methods which expected the username to have a value misbehaved after that.
Well, one of the debugging hooks was turned on, and it called GetReplacementUser, which… is interesting.
'Similar to the Debug class, hard coded items in this function are intentional.
'
Private Shared Function GetReplacementUser() As String
Dim line As String
Dim userName As String = String.Empty
Try
Using sr As System.IO.StreamReader = New System.IO.StreamReader("C:\Temp Files\DeleteThisfile.txt")
line = sr.ReadLine
If line.Contains(My.User.Name) Then
userName = line.Split("-"c)(3)
End If
End Using
Catch ex As Exception
End Try
Return userName
End Function
I'm a little afraid about what might be going on over in the Debug class, but this is the one we have in front of us, so let's dig in. The goal, I suspect, is to allow the user running the program to impersonate another user, hopefully not in production, but let's be realistic- it probably could be used that way.
Regardless, the way that we do this impersonation is by reading a file name C:\TempFiles\DeleteThisFile.txt. If the first line of that file contains My.User.Name- a convenient accessor for your OS-level logged in user- then we split the line and take the fourth field in it and use that as the username. So, during debugging, by writing a character-separated file, where the fourth field in the first line is someone's user name, you can impersonate that user. But, if the file doesn't exist, or the first line doesn't contain your user name, the userName field is returned as an empty string.
The bad choices were intentional, as the comment says, but I'm not sure the developer responsible knew they were bad choices. Or maybe the believed that intentionally bad choices are actually good, because you meant to do that.
Fixing the crash issue was easy for Doug- just disabled those hooks. Picking apart all the weird and dangerous bits of debug-hackery in there, however, was a much larger effort.
|
Метки: CodeSOD |
Committed Database |
Database administrators tend to be pretty conservative about how databases are altered. This is for good reason- that data is mission critical, it's availability is vital, and any change you make threatens that stability and reliability. This conservatism ranges from "we have well defined processes for making changes" all the way to "developers are dangerous toddlers playing with guns and we can't allow them to do anything lest it break our precious database."
"Grumpy" Gus worked with some DBAs that fell much more on the "developers can't be trusted" end of the spectrum. This meant they had big piles of rigorous processes to make sure only the most important, definitely required changes to the database ever got made. The process involved filing several documents, marking an entry on a spreadsheet, emailing a dba@initech.com inbox, and then waiting. Your request would snake its way through a Database Management Subcommittee, then get kicked over to a Business Need Evaluation Working Group. If the working group agreed that this change met a level of business need, it went back to the subcommittee, which reviewed the findings and if they agreed escalated it to the monthly Database Administration Steering Committee and Database Users Group meeting. Once again, it would get reviewed. If accepted, the DBAs could write a change script, and apply it in the next database maintenance window.
From start to end, the process took a month, if not longer, and your request could be kicked back at any step in the process. If you didn't fill out the initial documents in the correct order, and to the satisfaction of the groups, down to using, commas, correctly, it could be rejected. You may or may not be told why.
All this created a problem: the "big boss" wanted three new boolean fields in the database, and wanted it yesterday. There was no guarantee that the committees would even let Gus finish the process. And it was impossible to get it done in any sort of timely fashion.
But Gus was smart, creative, and aware that the FAX_PHONE_NUMBER field on all of their customer records were blank. Gus couldn't change the schema, but he could change the way his application used the database fields.
UPDATE CUSTOMER_TABLE SET FAX_PHONE_NUMBER = CAST (HAS_DOCK * 64 + HAS_LOCK * 32 + HAS_DOORBELL * 16 as varchar(10));
Problem "solved".
|
Метки: Feature Articles |
CodeSOD: Patching Over Your Problem |
Deanna inherited some code which had gone through many, many previous hands. Like a lot of JavaScript/TypeScript code, it needed to be able to compare objects for deep equality. This is fraught and complicated, and there are many many many solutions available in NPM.
NPM, of course, is its own fraught thing. Widely used libraries frequently have vulnerabilities, and even if you don't use them directly, the nature of dependency management via NPM means that libraries your libraries depend on might.
If you want to avoid that, you could whip up your own deep equals function, with a little recursion. Or, if you're a real hack, you might gamble on JSON.stringify(a) == JSON.stringify(b) working (which is a gamble, as it depends on key insertion order being the same).
Deanna's predecessors found a different solution. They did go off to use a library- but the library they chose is a bit surprising for this task.
import * as JsonDiff from 'rfc6902';
/**
* Checks if objects are equal
*/
function isDeepEqual(o1: Object, o2: Object): boolean {
return JsonDiff.createPatch(o1, o2).length === 0;
}
This calls the library rfc6902, which implements that RFC. RFC6902 includes conventions for describing JSON documents and methods of mutating them, like patch documents. This entire library is included for just this method, and specifically that createPatch call. That walks through the objects, recursively, to build a patch document, which contains instructions to add, delete, modify or move fields in order to make the object identical. As you can imagine, that task is much more complex and expensive than just comparing for equality, and unlike equality, where you can stop the process on the first failure, this has to look at every field in the input document.
Finally, if the patch document is empty, then the two objects match.
This is overkill. This is swatting a fly with a wrecking ball. If they had more use for the library, this might make sense, but this is the one call they make. And of course, because they've added a new dependency, they've also added its security vulnerabilities.
In this case, that's "Prototype Pollution", which isn't the most severe flaw you could have, but it does mean that a maliciously crafted object could inject its own code into the object prototype, replacing built in methods with its own methods. It's hard to exploit, but it's still a vulnerability- a vulnerability that's existed in every version of the library. A library which hasn't seen updates in 7 months, and there's a pull request even older which fixes it.
It's good to use libraries and third party code to help you solve problems. But it can't be done blindly or carelessly.
|
Метки: CodeSOD |
CodeSOD: Read the Comments |
Many many years ago, when I took my first programming course in high school, our instructor had… opinions. One of those opinions was that you should manually syntax check your code and not rely on compiler errors, because back in her day, you had to punch your program into cards, drop it off in the computer lab, wait for the technician to run your batch, and then pick up the results on the printer. It needed to work the first try or you might be waiting a whole day before you could try again.
One of her other opinions was that your code should contain as many comments as it contained lines of code. Everything needed comments. Everything. Which brings us to this code from Doug.
Private Sub BuildActuarial04_14Row(exportString As StringBuilder, record As ap_Actuarial04_14_Result)
'Card Type
exportString.Append(record.CardType)
'SSN
exportString.Append(record.SSN)
'Name
exportString.Append(helper.FormatData(record.Name, 25, Helpers.DataType.StringFormat))
'Sex
exportString.Append(record.Sex)
'Birth Date
exportString.Append(record.BirthDate)
'Hire Date
exportString.Append(helper.FormatData(record.HireDate, 8, Helpers.DataType.StringFormat))
'Plan Number
exportString.Append(record.PlanNumber)
'Parish Or Other Codes 1
exportString.Append(record.ParishOrOtherCodes1)
'Parish Or Other Codes 2
exportString.Append(record.ParishOrOtherCodes2)
'Service Code
exportString.Append(record.ServiceCode)
'Years Of Eligible Service
exportString.Append(record.YearsOfEligibleService)
'Years Of Credited Service
exportString.Append(record.YearsOfCreditedService)
'Final Average Compensation Monthly
exportString.Append(record.FinalAverageCompensationMonthly)
'Annual Member Contributions For Fye
exportString.Append(record.AnnualMemberContributionsForFye)
'Accumulated Member Contributions
exportString.Append(record.AccumulatedMemberContributions)
'Contribution Interest
exportString.Append(record.ContributionInterest)
'Termination Date
exportString.Append(record.TerminationDate)
'Rehired
exportString.Append(record.Rehired)
'Ibo
exportString.Append(record.Ibo)
'Retirement Date
exportString.Append(record.RetirementDate)
'Estimated Accrued Benefit
exportString.Append(record.EstimatedAccruedBenefit)
'Original Retirement Benefit
exportString.Append(record.OriginalRetirementBenefit)
'Option Code
exportString.Append(record.OptionCode)
'Retirement Code
exportString.Append(record.RetirementCode)
'Sex Of Beneficiary
exportString.Append(record.SexOfBeneficiary)
'Beneficiary Birth Date
exportString.Append(record.BeneficiaryBirthDate)
'Childs Monthly Benefit
exportString.Append(record.ChildsMonthlyBenefit)
'Childs Birth Date
exportString.Append(record.ChildsBirthDate)
'Years Of Military Service
exportString.Append(record.YearsOfMilitaryService)
'Beneficiarys SSN
exportString.Append(record.BeneficiarysSSN)
'Total Accumulated Years Of Service Purchased
exportString.Append(record.TotalAccumulatedYearsOfServicePurchased)
'End Line
exportString.AppendLine()
End Sub
Doug's co-worker may have been in my high school class.
What's particularly ironic about this overcommenting is the method name: BuildActuarial04_14Row. What does the 04_14 mean? Why does this merit its own code path? Is that a date? A special internal code? Are there 05_14 rows?
There's a big code smell on that part, because it implies a whole suite of ap_Actuarial…Result classes that probably have the same fields, but don't have the same interface, and someone hacked together this private polymorphism.
|
Метки: CodeSOD |
Error'd: Outages, Prices, and Catastrophe |
Shaun F noticed an outage.

"Maybe," Shaun writes, "they should use the Cloudflare Always Online service."
Meanwhile, at Subway, Maurice R has found the deal of a lifetime.

And as we get into Autumn, Lincoln Ramsay warns you to be on the lookout for sudden cold snaps.

https://thedailywtf.com/articles/outages-prices-and-catastrophe
|
Метки: Error'd |
Performance Tuning for Exabyte Queries |
While NoSQL databases have definitely made their mark and have an important role in applications, there's also still a place for RDBMSes. The key advantage of an RDBMS is that, with a well normalized schema, any arbitrary query is possible, and instead of optimizing the query, you optimize the database itself to ensure you hit your performance goals- indexes, statistics, materialized views, etc..
The reality, of course, is wildly different. While the execution plan used by the database shouldn't be dependent upon how we write the query, it frequently is, managing statistics and indexes is surprisingly hard, and when performance problems crop up, without the right monitoring, it can be difficult to track down exactly which query is causing the problem.
Which brings us to this query, which TJ found while analyzing a performance problem.
select Min(the.moddate) "ModifiedDate"
From T_91CDDC57 what , T_91CDDC57 the , T_91CDDC57 f
where f.rdate > sysdate-1095;
First, let's just congratulate whoever named the table T_91CDDC57. I assume that's generated, and presumably so was this query. There's clearly a bug- there's no reason to have the same table in the FROM clause three times, when we just want to find the earliest moddate.
And that's the problem. T_91CDDC57 isn't a particularly large table. It's no pipsqueak- at 4.5M rows and 34M of data, it's certainly got some heft, but it's no giant, either. But that's 4.5M rows which have to be joined to 4.5M rows with no join condition, and then that gets joined to 4.5M rows again with no join condition.
Here's the explain plan of how this query executes:
-----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|
-----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 16 | 19P (1)|
| 1 | SORT AGGREGATE | | 1 | 16 | |
| 2 | MERGE JOIN CARTESIAN | | 18E| 15E| 19P (1)|
| 3 | MERGE JOIN CARTESIAN | | 4328G| 31T| 5321M (1)|
|* 4 | TABLE ACCESS FULL | T_91CDDC57 | 959K| 7499K| 18967 (2)|
| 5 | BUFFER SORT | | 4509K| | 5321M (1)|
| 6 | INDEX FAST FULL SCAN| T_91CDDC57_TYPE_INDEX | 4509K| | 5544 (1)|
| 7 | BUFFER SORT | | 4509K| 34M| 19P (1)|
| 8 | INDEX FAST FULL SCAN | T_91CDDC57_MODDATE_INDEX | 4509K| 34M| 4410 (1)|
-----------------------------------------------------------------------------------------------
A few notable entries here. Line 4 does a TABLE ACCESS FULL. This is the f iteration of our table, and you can see that it pulls in just 959K rows thanks to our where clause. On line 8, you can see that it scans the T_91CDDC57_MODDATE_INDEX- it's using that index to sort so we can find the Min(the.moddate). You can also see that it touches 4509K rows. Line 6, also for 4509K rows, is our what access in the query.
Once we've accessed our three piles of data, we have to connect them. Since there's no ON or WHERE clause that links the tables, this connects each row from each table with each row in each other table. And you can see on line 3, where we join the first pair of tables, we suddenly have 4.3T rows, and a total of 31 terabytes of data. And when we join the third table it on line 2, that bloats to 18,000,000,000,000,000,000 rows and 15 exabytes of data.
TJ says:
Processing over 15 exabytes of information probably may have something to do with the performance…
Yeah, probably.
https://thedailywtf.com/articles/performance-tuning-for-exabyte-queries
|
Метки: Feature Articles |
CodeSOD: A Ritual Approach |
Frequent contributor Russell F stumbled across this block, which illustrates an impressive ability to make a wide variety of bad choices. It is written in C#, but one has the sense that the developer didn't really understand C#. Or, honestly, programming.
if (row["Appointment_Num"].ToString() == row["Appointment_Num"].ToString())
{
bool b1 = String.IsNullOrEmpty(results.messages[0].error_text);
if (b1 == true)
{
row["Message_Id"] = ($"{results.messages[0].message_id}");
row["message_count"] = ($"{results.message_count[0] }");
row["message_cost"] = ($"{results.messages[0].message_price }");
row["error_text"] = ($"{results.messages[0].error_text }");
row["network"] = ($"{results.messages[0].network }");
row["to"] = ($"{results.messages[0].to }");
row["status"] = ($"{results.messages[0].status }");
row["communicationtype_num"] = ($"1");
row["Sent_Date"] = (String.Format("{0:yyyy-MM-dd hh:mm:ss}", DateTime.Now));
row["Sent_Message"] = row["Sent_Message"].ToString();
}
if (b1 == false)
{
row["Message_Id"] = "0000000000000000";
row["message_count"] = ($"{results.message_count[0] }");
row["message_cost"] = ($"{results.messages[0].message_price }");
row["error_text"] = ($"{results.messages[0].error_text }");
row["network"] = ($"{results.messages[0].network }");
row["to"] = ($"{results.messages[0].to }");
row["status"] = ($"{results.messages[0].status }");
row["communicationtype_num"] = ($"1");
row["Sent_Date"] = (String.Format("{0:yyyy-MM-dd hh:mm:ss}", DateTime.Now));
row["Sent_Message"] = row["Sent_Message"].ToString();
}
}
Let's just start on the first line. This entire block is surrounded by a condition: row["Appointment_Num"].ToString() == row["Appointment_Num"].ToString(). If appointment num, as a string, matches appointment num, as a string, we can execute this code.
Inside of that block, we check to see if the error message IsNullOrEmpty. If it is, we'll turn it into a database row. If it's not, we'll also turn it into a database row, but with a hard-coded ID. At first glance, it's weird that they assign the IsNullOrEmpty check to a variable, but when you see that this code is written as two conditionals, instead of an if/else, you realize they forgot that else existed. They didn't want to do the IsNullOrEmpty check twice, so they stuffed it into a boolean.
It's also worth noting that the only difference between the two branches is the Message_Id, so there's a lot of duplicated code in there.
And that duplicated code is its own pile of WTFs. Clearly, the database itself is stringly-typed, as everything gets converted into a string. We mostly avoid using ToString, though, and instead use C#'s string interpolation. Which is'nt really a problem, but most of these fields are already strings. error_text, network, to, status, all strings. And `row["Sent_Message"] is a string, too- and we convert it to a string and store it in the same field.
After all that, I barely have the energy to wonder why they wrapped all of those assignments in parentheses. I suspect they misunderstood C# enough to think it's necessary. This whole thing has the vibe of "programming by incantation and ritual"- if we get the symbols in the right order and express them the right way, it will work, even if we don't understand it.
|
Метки: CodeSOD |
CodeSOD: Low (Quality) Code |
Like the tides, the popularity of low-code development environments comes in ebbs and flows. With each cycle, the landscape changes, old tools going away and new tools washing up on shore. One one hand, democratizing access to technology is good, on the other, these tools inevitably fail to actually do that. Instead, we get mission critical developed by people who don't understand how to develop, and are thus fragile, and released on platforms that are almost certainly going to be on legacy support in the next cycle.
I don't want to imply that low-code tools are automatically bad, or insult non-developers who want to give developing in a low-code environment a shot, though. Especially when professional developers can't really do any better.
John F's company has adopted one of the new tools in this cycle of low-code tools, Microsoft Power Apps, using the Power FX scripting language. One of the screens in their application needs to display a table of sales data, organized by month. This is how one of their developers decided to generate the list of months to draw:
FirstN([0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,
22,23,24,25,26,27,28,29], 17)
These numbers are meant to be an offset from the current month. The original developer wasn't sure how many months would be correct for their application, and wanted to experiment. This was their solution: hard-code a list that's longer than you'd reasonably want, and take the FirstN, changing N until it looks right.
Of course, "generating a sequential list of numbers of a certain length" is one of those infamous solved problems. In the case of Power FX, it's solved via the sequence function. Sequence(17, 0) would accomplish the same result.
|
Метки: CodeSOD |
CodeSOD: An Hourly Rate |
When someone mentioned to Abraham, "Our product has an auto-sync feature that fires every hour," Abraham wasn't surprised. He was new to the team, didn't know the code well, but an auto-sync back to the server sounded reasonable.
The approach, however, left something to be desired.
syncTimer = new Timer(1000);
syncTimer.Elapsed += new System.Timers.ElapsedEventHandler(syncTimer_Elapsed);
syncTimer.Enabled = true;
syncTimer.AutoReset = true;
//...
void syncTimer_Elapsed(object sender, System.Timers.ElapsedEventArgs e)
{
if (DateTime.Now.Second == 0 && DateTime.Now.Minute == 0)
{
//... do what you have to do
}
}
The .NET Timer object does exactly what you expect. In this case, 1,000 milliseconds after getting Enabled, it fires an event. Because AutoReset is true, it will fire that event every 1,000 milliseconds.
Now, this is supposed to trigger the auto-sync once every hour, but instead it fires once a second. On that second, we check the time- if we're on the first second of the first minute in the hour, then we fire the auto-sync operations.
There are a few problems with this. The first, and arguably most minor, is that it's just silly. Firing every second turns this timer into an "Are we there yet? Are we there yet? Are we there yet?" nuisance. It makes more sense to set the timer of 3600000 milliseconds and just have it fire once an hour.
The second problem is that this means nearly every client is going to sync at roughly exactly the same time. All of the load is going to spike all at once, at the top of the hour, every hour. That's manageable, but there's no business requirement that the sync happens at the top of the hour- any time would be fine, it should just only happen once in any given hour.
But the third problem is that this code doesn't guarantee that. This is .NET code running on Windows, and the Windows system clock can have a variety of different resolutions depending on version and configuration. In newer server versions, it could be as small as 1ms, if the sysadmin configured it for high accuracy. But this ran on clients, running desktop OSes, where the number would be closer to 15.6ms- which doesn't divide evenly into 1000ms. Which means this interval isn't going to fire exactly 1000ms apart- but 1005ms apart. Depending on what the OS is doing, it might drift even farther apart than that. But the key point is, some hours, this timer won't fire in the first second of the first minute.
The good news is that fixing this code by converting it to just fire once an hour at any time is a lot less than an hour's worth of work. Validating that in testing, on the other hand…
|
Метки: CodeSOD |
Error'd: Counting to One |
Two of today's ticklers require a little explanation, while the others require little.
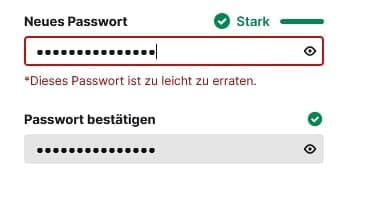
Kicking things off this week, an anonymous reporter wants to keep their password secure by not divulging their identity. It won't work, that's exactly the same as my Twitch password. "Twitch seems to be split between thinking whether my KeePass password is strong or not," they wrote. Explanation: The red translates to "This password is too easy to guess", while the green 'Stark' translates as "you've chosen a very good password indeed."
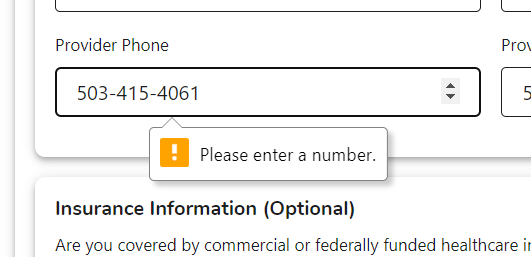
Stymied in an attempted online drugs purchase, Carl C. sums up: "Apparently a phone number is a number. I'm waiting for them to reject my credit card number because I typed it with dashes." We here at TDWTF are wondering what they'd make of a phone number like 011232110330.
Unstoppered Richard B. tops Carl's math woes, declaring "hell, after a shot of this I can't even *count* to one, let alone do advanced higher functions!"
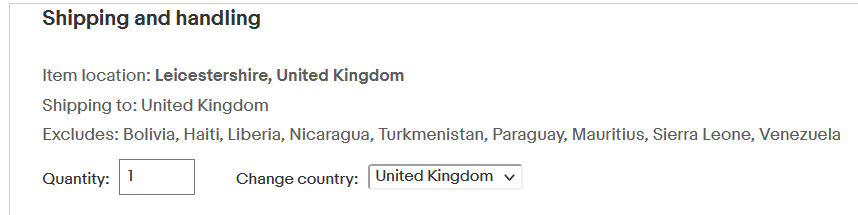
Regular contributor Peter G. highlights "This eBay auction will ship to anywhere in the UK except the bits of the UK that are in Bolivia, Liberia, Turkmenistan, Venezuela, and a few others." Pedantically, Peter, there is no error here, unless there is in fact some bit of the UK somewhere in Sierra Leone.
Pseudonymous spelunker xyzzyl murmurs "Something tells me the rest of videos and movies is also called undefined." Don't go in there! That's a horror flick, my friend.
|
Метки: Error'd |
CodeSOD: Joining the Rest of Us |
Using built-in methods is good and normal, but it's certainly boring. When someone, for example, has a list of tags in an array, and calls string.Join(" ", tags), I don't really learn anything about the programmer as a person. There's no relationship or connection, no deeper understanding of them.
Which, let's be honest, is a good thing when it comes to delivering good software. But watching people reinvent built in methods is a fun way to see how their brain works. Fun for me, because I don't work with them, probably less fun for Mike, who inherited this C# code.
public List<string> Tags {get; set;}
/// It's important to note that ToDelimitedString is only called by ToSpaceDelimitedString, which starts us off with a lovely premature abstraction. But what I really love about this, the thing that makes me feel like I'm watching somebody's brain work, is their approach to making sure they don't have leading or training delimiters.
delimitedTags.AppendFormat("{0}{1}",
delimitedTags.Length > 0 ? delimiter.ToString()
: string.Empty, tag)
On the first run of the loop, delimitedTags is empty, so we append string.Empty, tag- so just tag. Every other iteration of the loop, we append the delimiter character. I've seen lots of versions of solving this problem, but I've never seen this specific approach. It's clever. It's not good, but it's clever.
And, as is good practice, it's got a unit test:
[Test]
public void ToSpaceDelimitedString() {
TagList list = new TagList(_blogKey);
string expected = "tag1 tag2 tag3";
foreach (string tag in expected.Split(' ')) {
list.Add(tag);
}
string actual = list.ToSpaceDelimitedString();
Assert.AreEqual(expected, actual, "ToSpaceDelimitedString failed");
}
What's interesting here is that they know about string.Split, but not string.Join. They're so close to understanding none of this code was needed, but still just a little too far away.
|
Метки: CodeSOD |
CodeSOD: Supporting Standards |
Starting in the late 2000s, smartphones and tablets took off, and for a lot of people, they constituted a full replacement for a computer. By the time the iPad and Microsoft Surface took off, every pointy-haired-boss wanted to bring a tablet into their meetings, and do as much work as possible on that tablet.
Well, nearly every PHB. Lutz worked for a company where management was absolutely convinced that tablets, smartphones, and frankly, anything smaller than the cheapest Dell laptop with the chunkiest plastic case was nothing more than a toy. It was part of the entire management culture, led by the CEO, Barry. When one of Lutz's co-workers was careless enough to mention in passing an article they'd read on mobile-first development, Barry scowled and said "We are a professional software company that develops professional business software."
Back in the mid 2010s, their customers started asking, "We love your application, but we'd love to be able to access it from our mobile devices," Barry's reply was: "We should support standards. The standard is Microsoft Windows."
"Oh, but we already access your application on our mobile devices," one of the customers pointed out. "We just have to use the desktop version of the page, which isn't great on a small screen."
Barry was livid. He couldn't take it out on his customers, not as much as he wanted to, but he could "fix" this. So he went to one of his professional software developers, at his professional software company, and asked them to professionally add the following check to their professional business software:
Public Sub OnActionExecuting(filterContext As ActionExecutingContext) Implements IActionFilter.OnActionExecuting
Dim userAgent As String = filterContext.HttpContext.Request.UserAgent
If Not userAgent.Contains("Windows NT") OrElse userAgent.Contains("; ARM;") Then
filterContext.Result = New ContentResult With {.Content = "Your operating system is not supported. Please use Microsoft Windows."}
End If
End Sub
Filtering users based on User-Agent strings is a bad idea in general, requiring it to contain "Windows NT" is foolish, but banning UA-strings which contain "ARM" is pure spite. It was added specifically to block, at the time, Windows RT- the version of Windows built for the Surface tablet.
There's no word from Lutz about which lasted longer: this ill-conceived restriction or the company itself.
|
Метки: CodeSOD |
CodeSOD: Like a Tree, and… |
Duncan B was contracting with a company, and the contract had, up to this point, gone extremely well. The last task Duncan needed to spec out was incorporating employee leave/absences into the monthly timesheets.
"Hey, can I get some test data?" he asked the payroll system administrators.
"Sure," they said. "No problem."
{
"client": "QUX",
"comp": "FOO1",
"employee": "000666",
"employeename": { "empname": "GOLDFISH, Bob MR", "style": "bold" },
"groupname": "manager GOLDFISH, Bob MR",
"drillkey": { "empcode": { "companyid": "FOO1", "employeeid": "000666" } },
"empleaves": {
"empleave": [
{
"empcode": { "companyid": "FOO1", "employeeid": "000333" },
"name": "AARDVARK, Alice MS",
"candrill": 0,
"shortname": "AARDVARK, Alice",
"subposition": "",
"subpositiontitle": "",
"leavedays": {
"day": [
"","","","","","","","","AL","","","","","",
"","","","","","","","","","","","","","",
"","","",""
]
}
},
{
"empcode": { "companyid": "FOO1", "employeeid": "000335" },
"name": "AARDWOLF, Aaron MR",
"candrill": 0,
"shortname": "AARDWOLF, Aaron",
"subposition": "",
"subpositiontitle": "",
"leavedays": {
"day": [
"","","","","","","","","","","","","","",
"","","","","","","","","","","","","","",
"",""
]
}
}
]
}
}
}
Well, there were a few problems. The first of which was that the admins could provide test data, but they couldn't provide any documentation. It was, of course, the leavedays field which was the most puzzling for Duncan. On the surface, it seems like it should be a list of business days within the requested range. If an employee was absent one day, it would get marked with a tag, like "AL", presumably shorthand for "allowed" or similar.
But that didn't explain why "AARDWOLF Aaron" had fewer days that "AARDVARK Alice". Did the list of strings somehow tie back to whether the employee were scheduled to work on a given day? Did it tie to some sort of management action? Duncan was hopeful that the days lined up with the requested range in a meaningful way, but without documentation, it was just guessing.
For Duncan, this was… good enough. He just needed to count the non-empty strings to drive his timesheets. But he feared for any other developer that might want to someday consume this data.
Duncan also draws our attention to their manager, "GOLDFISH, Bob MR", and the "style" tag:
I'm fairly sure that's a hint to the UI layer, rather than commentary on the Mr. Goldfish's management style.
|
Метки: CodeSOD |
CodeSOD: Price Conversions |
Russell F has an object that needs to display prices. Notably, this view object only ever displays a price, it never does arithmetic on it. Specifically, it displays the prices for tires, which adds a notable challenge to the application: not every car uses the same tires on the front and rear axles. This is known as a "staggered fitment", and in those cases the price for the front tires and the rear tires will be different.
The C# method which handles some of this display takes the price of the front tires and displays it quite simply:
sTotalPriceT1 = decTotalPriceF.ToString("N2");
Take the decTotalPriceF and convert it to a string using the N2 format- which is a number with thousands separators and two digits behind the decimal place. So this demonstrates that the developer responsible for this code understands how to format numbers into strings.
Which is why it's odd when, a few lines later, they do this, for the rear tires:
sTotalPriceT2 = decimal.Parse(decTotalPriceR.ToString("F2")).ToString("N2");
We take the price, convert it to a string without thousands separators, then parse it back into a decimal and then convert it to a string with thousands separators.
Why? Alone, this line would just be mildly irksome, but when it's only a few lines below a line which doesn't have this kind of ridiculousness in it, the line just becomes puzzling.
But the puzzle doesn't end. sTotalPriceT1 and sTotalPriceT2 are both string variables that store the price we're going to display. Because this price information may need to be retained across requests, though, someone decided that the prices also need to get stored in a session variable. In another method in the same class:
Session["FOS_TPriceF"] = bStaggered ? decimal.Parse(sTotalPriceT1).ToString("N2") : null;
Session["FOS_TPriceR"] = bStaggered ? decimal.Parse(sTotalPriceT2).ToString("N2") : null;
Once again, we're taking a string in a known format, turning it back into the base numeric type, then formatting back to the format it already was. And I suppose it's possible that some other bit of code may have modified the instance variables sTotalPriceTN and broken the formatting, but it seems to me the solution is to not store numbers as strings and just format them at the moment of display.
|
Метки: CodeSOD |
Error'd: Money for Nothin' |
... and gigs for free.
"Apple is magical," rhapsodizes music-lover Daniel W.
Meanwhile, in the overcast business district of Jassans-Riottier, where the stores are all closed but there's a bustle in the hedgerow, local resident Romain belts "I found the Stairway to Heaven just 100m from my house!"
Yes, there are two paths you can go by.
But in the long run ... you won't get there on any of these buses, shared by Alex Allan, wailing "you wait for one, and XXX all come together!"
Nor on this train of the damned from Finn Jere
~ ~
No, it's very clear the mandatory mode is Zeppelin.
|
Метки: Error'd |
CodeSOD: Making Newlines |
I recently started a new C++ project. As it's fairly small and has few dependencies, I made a very conscious choice to just write a shell script to handle compilation. Yes, a Makefile would be "better", but it also adds a lot of complexity my project doesn't need, when I can have essentially a one-line build command. Still, my code has suddenly discovered the need for a second target, and I'll probably migrate to Makefiles- it's easier to add complexity when I need it.
Kai's organization transitioned from the small shell-scripts approach to builds to using Makefiles about a year ago. Kai wasn't involved in that initial process, but has since needed to make some modifications to the Makefiles. In this case, there's a separate Makefile for each one of their hundreds of microservices.
Each one of those files, near the top, has this:
# Please note two empty lines, do not change
define newline
endef
The first time Kai encountered this, a CTRL+F showed that the newline define was never used. The second time, newline was still unused. Eventually, Kai tracked back to one of the first Makefiles, and found a case where it was actually used. Twice.
It was easy to understand what happened: someone was writing a new Makefile, and looked at an older one for an example, and probably copy/pasted a lot of it. They saw a comment "do not change", and took this to mean that they needed to include this for reasons they didn't understand. And now, every Makefile has this do-nothing define for no real reason.
Kay writes:
Since finding out about this, I kept wondering what would happen if I started adding ASCII cows into those files with the comment: "Please note this cow, do not change"
_____________________________________
< Please note this cow, do not change >
-------------------------------------
\ ^__^
\ (oo)\_______
(__)\ )\/\
||----w |
|| ||
|
Метки: CodeSOD |
Editor's Soapbox: Eff Up Like It's Your Job |
This past Monday, Facebook experienced an outage which lasted almost six hours. This had rattle-on effects. Facebook's pile of services all failed, from the core application to WhatsApp to Oculus. Many other services use Facebook for authentication, so people lost access to those (which highlights some rather horrifying dependencies on Facebook's infrastructure). DNS servers were also strained as users and applications kept trying to find Facebook, and kept failing.
CloudFlare has more information about what went wrong, but at its core: Facebook's network stopped advertising the routes to its DNS servers. The underlying cause of that may have been a bug in their Border Gateway Protocol automation system:
How could a company of Facebook’s scale get BGP wrong? An early candidate is that aforementioned peering automation gone bad. The astoundingly profitable internet giant hailed the software as a triumph because it saved a single network administrator over eight hours of work each week.
Facebook employs more than 60,000 people. If a change designed to save one of them a day a week has indeed taken the company offline for six or more hours, that's quite something.
Now, that's just speculation, but there's one thing that's not speculation: someone effed up.
IT in general, and software in specific, is a rather bizarre field in terms of how skills work. If, for example, you wanted to get good at basketball, you might practice free-throws. As you practice, you'd expect the number of free-throws you make to gradually increase. It'll never be 100%, but the error rate will decline, the success rate will increase. Big-name players can expect a 90% success rate, and on average a professional player can expect about an 80% success rate, at least according to this article. I don't actually know anything about basketball.
But my ignorance aside, I want you to imagine writing a non-trivial block of code and having it compile, run, and pass its tests on the first try. Now, imagine doing that 80% of the time.

It's a joke in our industry, right? It's a joke that's so overplayed that perhaps it should join "It's hard to exit VIM" in the bin of jokes that needs a break. But why is this experience so universal? Why do we have a moment of panic when our code just works the first time, and we wonder what we screwed up?
It's because we already know the truth of software development: effing up is actually your job.
You absolutely don't get a choice. Effing up is your job. You're going to watch your program crash. You're going to make a simple change and watch all the tests go from green to red. That semicolon you forgot is going to break the build. And you will stare at one line of code for six hours, silently screaming, WHY DON'T YOU WORK?
And that's because programming is hard. It's not one skill, it's this whole complex of vaguely related skills involving language, logic, abstract reasoning, and so many more cognitive skills I can't even name. We're making thousands of choices, all the time, and it's impossible to do this without effing up.
Athletes and musicians and pretty much everybody else practices repeating the same tasks over and over again, to cut down on how often they eff up. The very nature of our job is that we rarely do exactly the same task- if you're doing the same task over and over again, you'd automate it- and thus we never cut down on our mistakes.
Your job is to eff up.
You can't avoid it. And when something goes wrong, you're stuck with the consequences. Often, those consequences are just confusion, frustration, and wasted time, but sometimes it's much worse than that. A botched release can ruin a product's reputation. You could take down Facebook. In the worst case, you could kill someone.
But wait, if our job is to eff up, and those mistakes have consequences, are we trapped in a hopeless cycle? Are we trapped in an existential crisis where nothing we do has meaning, god is dead, and technology was a mistake?
No. Because here's the secret to being a good developer:
You gotta get good at effing up.
The difference between a novice developer and an experienced one is how quickly and efficiently they screw up. You need to eff up in ways that are obvious and have minimal consequences. You need tools, processes, and procedures that highlight your mistakes.
Take continuous integration, for example. While your tests aren't going to be perfect, if you've effed up, it's going to make it easier to find that mistake before anybody else does. Code linting standards and code reviews- these are tools that are designed to help spot eff ups. Even issue tracking on your projects and knowledge bases are all about remembering the ways we effed up in the past so we can avoid them in the future.
Your job is to eff up.
When looking at tooling, when looking at practices, when looking at things like network automation (if that truly is what caused the Facebook outage), our natural instinct is to think about the features they offer, the pain points they eliminate, and how they're better than the thing we're using right now. And that's useful to think about, but I would argue that thinking about something else is just as important: How does this help me eff up faster and more efficiently?
New framework's getting good buzz? New Agile methodology promises to make standups less painful? You heard about a new thing they're doing at Google and wonder if you should do it at your company? Ask yourself these questions:
Your job is to eff up.
The more mistakes you make, the better a programmer you are. Embrace those mistakes. Breaking the build doesn't make you an imposter. Spending a morning trying to track down a syntax error that should be obvious but you can't spot it for the life of you doesn't mean you're a failure as a programmer. Shipping a bug is inevitable.
Effing up is the job, and those eff ups aren't impediments, but your stepping stones. The more mistakes you make, the better you'll get at spotting them, at containing the fallout, and at learning from the next round of mistakes you're bound to make.
Now, get out there and eff up. But try not to take down Facebook while you do it.
|
Метки: Editor's Soapbox |
CodeSOD: Unzipped |
When you promise to deliver a certain level of service, you need to live up to that promise. When your system is critical to your customers, there are penalties for failing to live up to that standard. For the mission-critical application Rich D supports, that penalty is $10,000 a minute for any outages.
Now, one might think that such a mission critical system has a focus on testing, code quality, and stability. You probably don't think that, but someone might expect that.
This Java application contains a component which needs to take a zip file, extract an executable script from it, and then execute that script. The code that does this is… a lot, so we're going to take it in chunks. Let's start by looking at the core loop.
private void extractAndLaunch(File file, String fileToLaunch) {
try {
ZipInputStream zipIn = new ZipInputStream(new FileInputStream(file));
ZipEntry entry = zipIn.getNextEntry();
byte[] buffer = new byte[1024];
while (entry != null) {
if (!entry.isDirectory() && entry.getName().compareToIgnoreCase(fileToLaunch) == 0) {
// SNIP, for now
}
}
zipIn.closeEntry();
entry = zipIn.getNextEntry();
zipIn.close();
} catch (Exception e) {
LOG.error("Failed to load staging file {}", file, e);
}
}
So, we create a ZipInputStream to cycle through the zip file, and then get the first entry from it. While entry != null, we do a test: if the entry isn't a directory, and the name of the entry is the file we want to launch, we'll do all the magic of launching the executable. Otherwise, we go back to the top of the loop, and repeat the same check, on the same entry, forever. If the first file in this zip file isn't the file we want to execute, this falls into an infinite loop, because the code for cycling to the next entry is outside of the loop.
This may be a good time to point out that this code has been in production for four years.
Okay, so how do we extract the file?
// Extract the file
File newFile = new File(top + File.separator + entry.getName());
LOG.debug("Extracting and launching {}", newFile.getPath());
// Create any necessary directories
try {
new File(newFile.getParent()).mkdirs();
} catch (NullPointerException ignore) { // CS:NO IllegalCatch
// No parent directory so dont worry about it
}
int len;
FileOutputStream fos = new FileOutputStream(newFile);
while ((len = zipIn.read(buffer)) > 0) {
fos.write(buffer, 0, len);
}
fos.close();
zipIn.closeEntry();
So, first, we build a file path with string concatenation, which is ugly and avoidable. At least they use File.separator, instead of hard-coding a "/" or "\". But there's a problem with this: top comes from a configuration file and is loaded by System.getProperty(), which may not be set, or may be an empty string. This means we might jam things into a directory called null, or worse, try and extract to the root of the filesystem.
Which also means that newFile.getParent() may be null. Instead of checking that, we'll just catch any exceptions it throws.
We also call zipIn.closeEntry() here, and we close the same entry again after the loop. I assume the double close doesn't hurt anything, but it's definitely annoying.
Okay, so how do we execute the file?
OsHelper.execute(newFile.getName(), newFile.getParentFile());
// Execute the file
// TODO Fix this to work under linux
List cmdAndArgs = Arrays.asList("cmd", "/c", fileToLaunch);
ProcessBuilder pb = new ProcessBuilder(cmdAndArgs);
pb.directory(new File(System.getProperty("top")));
Process p = pb.start();
InputStream error = p.getErrorStream();
byte[] errBuf = new byte[1024];
if (error.available() > 0) {
error.read(errBuf);
LOG.error("Script {} had error {}", fileToLaunch, errBuf);
}
int exitValue = 0;
while (true) {
try {
exitValue = p.exitValue();
break;
} catch (IllegalThreadStateException ignore) {} // Just waiting for the batch to end
}
LOG.info("Script " + fileToLaunch + " exited with status of " + exitValue);
newFile.delete();
break;
OsHelper.execute does not, as the name implies, execute the program we want to run. It actually sets the executable bit on Linux systems. It doesn't use any Java APIs to do this, but just calls chmod to mark the file as executable.
Of course, that doesn't matter, because as the comment explains: this doesn't actually work on Linux. They actually shell out to cmd to run it, the Windows shell.
Then we launch the script, running it in the working directory specified by top, but instead of re-using the variable, we fetch it from the configuration again. We read from standard error on the process, but we don't wait, so most of the time this won't give us anything. We'd have to be very lucky to get any output from this running process.
Then, we wait for the script to complete. Now, it's worth noting that there's a Java built-in for this, Process#waitFor() which will idle until the process completes. Idle, instead of busy wait, which is what this code does. It's also worth noting that Process#exitValue() throws an exception if the process is still running, so in practice this code spams IllegalThreadStateExceptions as fast as it can.
Finally, none of these exception handlers have finally blocks, so if we do get an error that bubbles up, we'll never call newFile.delete(), leaving our intermediately processed work sitting there.
The code, in its entirety:
private void extractAndLaunch(File file, String fileToLaunch) {
try {
ZipInputStream zipIn = new ZipInputStream(new FileInputStream(file));
ZipEntry entry = zipIn.getNextEntry();
byte[] buffer = new byte[1024];
while (entry != null) {
if (!entry.isDirectory() && entry.getName().compareToIgnoreCase(fileToLaunch) == 0) {
// Extract the file
File newFile = new File(top + File.separator + entry.getName());
LOG.debug("Extracting and launching {}", newFile.getPath());
// Create any necessary directories
try {
new File(newFile.getParent()).mkdirs();
} catch (NullPointerException ignore) { // CS:NO IllegalCatch
// No parent directory so dont worry about it
}
int len;
FileOutputStream fos = new FileOutputStream(newFile);
while ((len = zipIn.read(buffer)) > 0) {
fos.write(buffer, 0, len);
}
fos.close();
zipIn.closeEntry();
OsHelper.execute(newFile.getName(), newFile.getParentFile());
// Execute the file
// TODO Fix this to work under linux
List cmdAndArgs = Arrays.asList("cmd", "/c", fileToLaunch);
ProcessBuilder pb = new ProcessBuilder(cmdAndArgs);
pb.directory(new File(System.getProperty("censored")));
Process p = pb.start();
InputStream error = p.getErrorStream();
byte[] errBuf = new byte[1024];
if (error.available() > 0) {
error.read(errBuf);
LOG.error("Script {} had error {}", fileToLaunch, errBuf);
}
int exitValue = 0;
while (true) {
try {
exitValue = p.exitValue();
break;
} catch (IllegalThreadStateException ignore) {} // Just waiting for the batch to end
}
LOG.info("Script " + fileToLaunch + " exited with status of " + exitValue);
newFile.delete();
break;
}
}
zipIn.closeEntry();
entry = zipIn.getNextEntry();
zipIn.close();
} catch (Exception e) {
LOG.error("Failed to load staging file {}", file, e);
}
}
|
Метки: CodeSOD |
Totally Up To Date |

The year was 2015. Erik was working for LibCo, a company that offered management software for public libraries. The software managed inventory, customer tracking, fine calculations, and everything else the library needed to keep track of their books. This included, of course, a huge database with all book titles known to the entire library system.
Having been around since the early 90s, the company had originally not implemented Internet connectivity. Instead, updates would be mailed out as physical media (originally floppies, then CDs). The librarian would plug the media into the only computer the library had, and it would update the catalog. Because the libraries could choose how often to update, these disks didn't just contain a differential; they contained the entire catalog over again, which would replace the whole database's contents on update. That way, the database would always be updated to this month's data, even if it hadn't changed in a year.
Time marched on. The book market grew exponentially, especially with the advent of self-publishing, and the Internet really caught on. Now the libraries would have dozens of computers, and all of them would be connected to the Internet. There was the possibility for weekly, maybe even daily updates, all through the magic of the World Wide Web.
For a while, everything Just Worked. Erik was with the company for a good two years without any problems. But when things went off the rails, they went fast. The download and update times grew longer and longer, creeping ever closer to that magic 24-hour mark where the device would never finish updating because a new update would be out before the last one was complete. So Erik was assigned to find some way, any way, to speed up the process.
And he quickly found such a way.
Remember that whole drop the database and replace the data thing? That was still happening. Over the years, faster hardware had been concealing the issue. But the exponential catalogue growth had finally outstripped Moore's Law, meaning even the newest library computers couldn't keep up with downloading the whole thing every day. Not on library Internet plans.
Erik took it upon himself to fix this issue once and for all. It only took two days for him to come up with a software update, which was in libraries across the country after 24 hours. The total update time afterward? Only a few minutes. All he had to do was rewrite the importer/updater to accept lists of changed database entries, which numbered in the dozens, as opposed to full data sets, which numbered in the millions. No longer were libraries skipping updates, after all.
Erik's reward for his hard work? A coupon for a free personal pizza, which he suspected his manager clipped from the newspaper. But at least it was something.
|
Метки: Feature Articles |
Error'd: Persnickety Sticklers Redux |
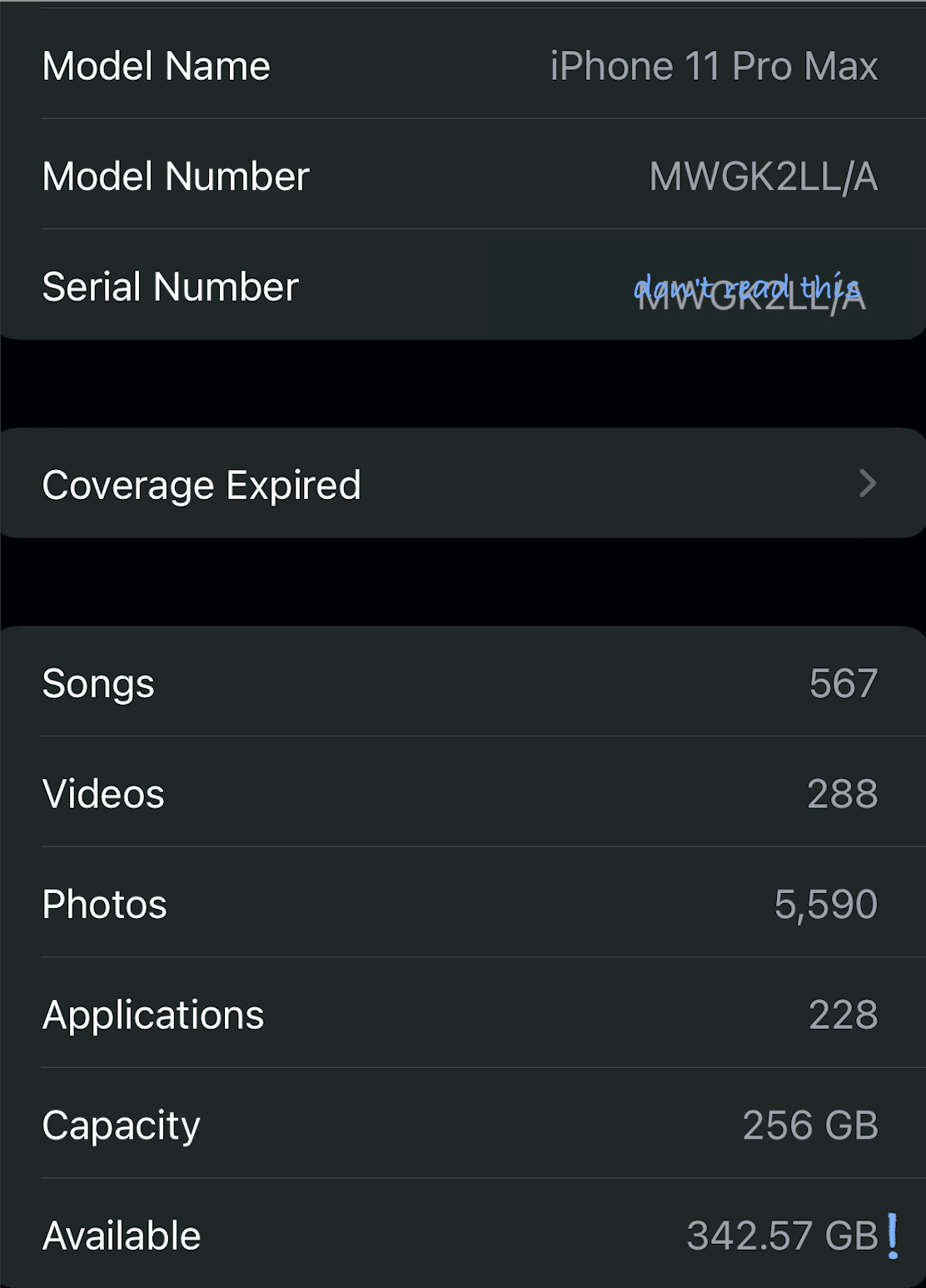
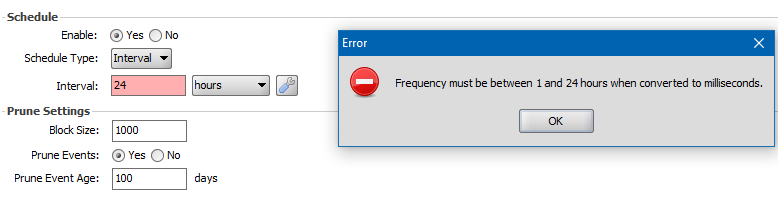
This week's installation of Error'd includes a few submissions which honestly don't seem all that WTFy. In particular, this first one from the unsurnamed Steve. I've included it solely so I can pedantically proclaim "24 is not between 1 and 24!" There is still a wtf here though. What is with this error message?
Insufficiently pedantic Steve humorlessly grumbles "Configuring data pruning on our Mirth Integration Engine. Mirth can do many things, just can't count up to 24."
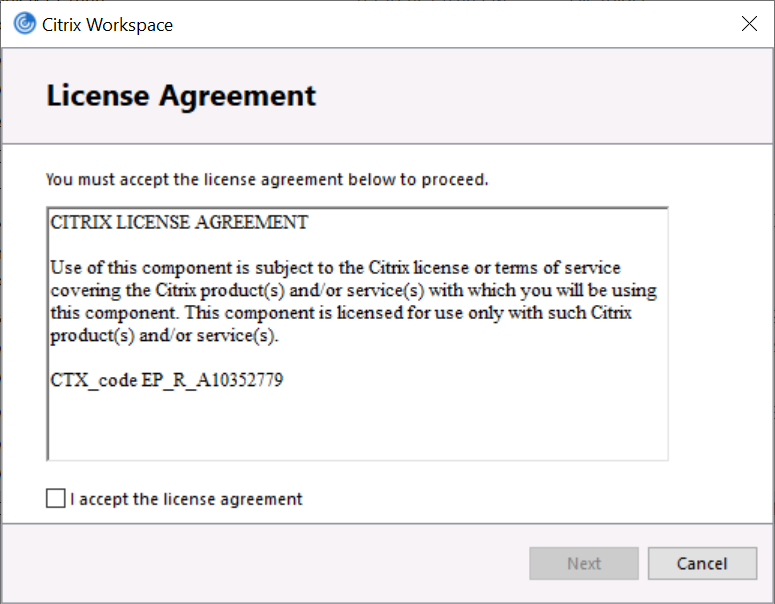
Appalachian Eric insists "Even the fussiest accountant doesn't need to be that precise."
Critic Bruce C. comments "I wonder what fancy lawyer came up with this agreement." To be fair, this doesn't seem at all unreasonable to me. Readers, what say you?
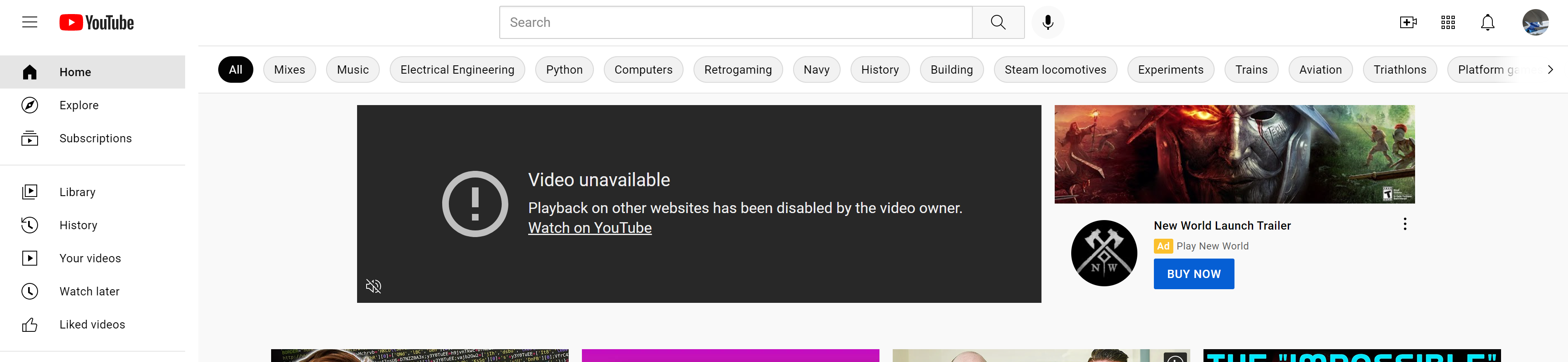
Little lost Lincoln KC searches for directions: "All this time I thought I was on YouTube."
Finally, foodie Bruce W. declares "My smart refrigerator has a unique perspective on lunch." I'll say. At my house, we call that dinner.
https://thedailywtf.com/articles/persnickety-sticklers-redux
|
Метки: Error'd |