Вводная часть (со ссылками на все статьи)
Лет 10-15 назад, когда программы состояли из исходников и небольшого количества двоичных файлов с работой по сборке итоговых программ отлично справлялись всевозможные «?make». Однако сейчас современные программы и подходы к разработке сильно изменились – это:
множество различных файлов (не считаю исходников) – стили, шаблоны, ресурсы, конфигурации, скрипты, бинарные данные и.т.д;
- предпроцессоры;
- системы проверки стиля исходников или всего проекта (lint, checkstyle и т.д.);
- методики разработки, основанные на тестах, с их запуском при сборке;
- различного типа стенды;
- системы развёртывания на базе облачных технологий и т.д. и.т.п.
Причём через этапы сборки итоговых или промежуточных артефактов с использованием перечисленных средств и методик среднестатистическому разработчику приходится проходить по несколько раз в день. Запуск командных файлов руками (с возможной проверкой результатов) в данном случае слишком обременительная процедура: необходим инструмент, отслеживающий изменения в ваших данных проекта и запускающий необходимые средства в зависимости от обнаруженных изменений.
Мой путь в использовании систем сборки был непонятное_количество_*make ->
ant ->
maven ->
gradle (то обстоятельство, что android Studio под капотом использует gradle меня сильно порадовало).
Gradle меня привлёк:
- своей простой моделью (из которой правда можно вырастить монстра, соизмеримого с самим создаваемым продуктом);
- гибкостью (как в части настройки самих скриптов, так и организации их распределения в рамках больших проектов);
- постоянным развитием (как и со всеми остальными вещами в разработке — тут надо постоянно изучать что-то новое);
- лёгкостью адаптации (знание groovy и gradle DSL обязательно);
- наличием системы plugin’ов, разрабатываемых сообществом — это и разные предпроцессоры, генераторы кода, системы доставки и публикации и прочее, прочее (см. login.gradle.org)
Ознакомиться с возможностями Gradle можно на сайте разработчиков в
разделе документации (можно узнать всё!). Для тех, кто хочет сравнить gradle и maven есть
интересное видео от JUG.
В моём случае скрипты для сборки выглядят таким образом:
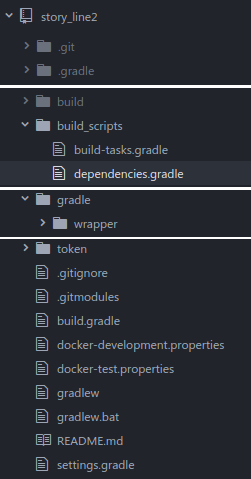
,
где:
- build_scripts/build-tasks.gradle — все задачи для сборки с указанием их зависимостей;
- build_scripts/dependencies.gradle — описания зависимостей и способов публикации;
- build.gradle — основной скрипт, определяющий зависимые модули, библиотеки и включающий другие скрипты сборки;
- settings.gradle — перечень зависимых модулей и настройки самого скрипта (можно переопределить ч/з аргументы запуска gradle).
В такой конфигурации все изменения скрипта сборки производятся в централизованных файлах (не даются на откуп каждому проекту) и могут/должны корректироваться централизованно лицом, ответственным за сборку проекта.
Tips
Из интересных вещей/советов, которыми я хотел бы поделиться, при настройке gradle в моём проекте есть следующие:
Вынос версий артефактов (шарится по блокам модулей было скучным занятием)
Объявляем блок с зависимостями:
// project dependencies
ext {
COMMONS_POOL_VER='2.4.2'
DROPWIZARD_CORE_VER='1.1.0'
DROPWIZARD_METRICS_VER='3.2.2'
DROPWIZARD_METRICS_INFLUXDB_VER='0.9.3'
JSOUP_VER='1.10.2'
STORM_VER='1.0.3'
...
GROOVY_VER='2.4.7'
// test
TEST_JUNIT_VER='4.12'
TEST_MOCKITO_VER='2.7.9'
TEST_ASSERTJ_VER='3.6.2'
}
И используем его в проекте:
project(':crawler_scripts') {
javaProject(it)
javaLogLibrary(it)
javaTestLibrary(it)
dependencies {
testCompile "org.codehaus.groovy:groovy:${GROOVY_VER}"
testCompile "edu.uci.ics:crawler4j:${CRAWLER4J_VER}"
testCompile "org.jsoup:jsoup:${JSOUP_VER}"
testCompile "joda-time:joda-time:${JODATIME_VER}"
testCompile "org.apache.commons:commons-lang3:${COMMONS_LANG_VER}"
testCompile "commons-io:commons-io:${COMMONS_IO_VER}"
}
}
- Вынос настроек во внешний файл
Создаём или уже имеем файл с конфигурацией:
---
# presented - for test/development only - use artifact from ""/provision/artifacts" directory
storyline_components:
crawler_scripts:
version: "0.5"
crawler:
version: "0.6"
server_storm:
version: "presented"
server_web:
version: "0.1"
И используем его в проекте:
import com.fasterxml.jackson.databind.ObjectMapper
import com.fasterxml.jackson.dataformat.yaml.YAMLFactory
buildscript {
repositories {
jcenter()
}
dependencies {
// reading YAML
classpath "com.fasterxml.jackson.core:jackson-databind:2.8.6"
classpath "com.fasterxml.jackson.dataformat:jackson-dataformat-yaml:2.8.6"
}
}
....
def loadArtifactVersions(type) {
Map result = new HashMap()
def name = "${projectDir}/deployment/${type}/hieradata/version.yaml"
println "Reading artifact versions from ${name}"
if (new File(name).exists()) {
ObjectMapper mapper = new ObjectMapper(new YAMLFactory());
result = mapper.readValue(new FileInputStream(name), HashMap.class);
}
return result['storyline_components'];
}
- Использование шаблонов
Это моя любимая часть — позволяет сформировать необходимые конфигурационные файлы из шаблонов.
Формируем шаблоны:
version: '2'
services:
...
server_storm:
domainname: story-line.ru
hostname: server_storm
build: ./server_storm
depends_on:
- zookeeper
- elasticsearch
- mongodb
links:
- zookeeper
- elasticsearch
- mongodb
ports:
- "${server_storm_ui_host_port}:8082"
- "${server_storm_logviewer_host_port}:8083"
- "${server_storm_nimbus_host_port}:6627"
- "${server_storm_monit_host_port}:3000"
- "${server_storm_drpc_host_port}:3772"
volumes:
- ${logs_dir}:/data/logs
- ${data_dir}:/data/db
....
И используем его в проекте:
// выполнить копирование скриптов для подготовки сервера
task copyTemplates (type: Copy, dependsOn: ['createStandDir']){
description "выполнить копирование шаблонов"
from "${projectDir}/deployment/docker_templates"
into project.ext.stand.deploy_dir
expand(project.ext.stand)
filteringCharset = 'UTF-8'
}
В итоге получаете конфигурационный файл, данные которого заполнены значениями переменных, получившими значения в ходе работы скрипта.Однако необходимо отметить, что если вам потребуется более сложная логика с переменными (например скрытие при отсутствии значений) — вам потребуется другой движок шаблонов в системе сборке. Я эту ситуацию обошел используя формат YAML по ходу проекта.
- Использование списков и замыканий groovy для специфичной обработки конкретных модулей
Это фактически обычное использование groovy в скрипте сборки, но мне это помогло решить пару нетривиальных задач.
Объявляем или получаем переменные множественного значения:
ext {
// образы, создаваемые docker'ом
docker_machines = ['elasticsearch', 'zookeeper', 'mongodb', 'crawler', 'server_storm', 'server_web']
// образы, создаваемые docker'ом для которых необходимо копировать артефакты
docker_machines_w_artifacts = ['crawler', 'server_storm', 'server_web']
}
И используем их в проекте:
// выполнить копирование шаблонов для docker с подстановкой значений
docker_machines.each { machine ->
task "copyProvisionScripts_${machine}" (type: Copy, dependsOn: ['createStandDir']){
...
}
}
- Интеграция с репозитариями maven — больно громоздкое описание для включения в статью (и сама работа достаточно бесполезная с учётом наличия примеров в документации)
- Возможность задачи блоков зависимостей для модулей, копирование и вставка которых отсутствует для каждого модуля
Объявляем блоки:
def javaTestLibrary(project) {
project.dependencies {
testCompile "org.apache.commons:commons-lang3:${COMMONS_LANG_VER}"
testCompile "commons-io:commons-io:${COMMONS_IO_VER}"
testCompile "junit:junit:${TEST_JUNIT_VER}"
testCompile "org.mockito:mockito-core:${TEST_MOCKITO_VER}"
testCompile "org.assertj:assertj-core:${TEST_ASSERTJ_VER}"
}
}
И используем их в проекте:
project(':token') {
javaProject(it)
javaLogLibrary(it)
javaTestLibrary(it)
}
Запуск всего этого богатого функционала с консоли одной командой, при которой определяются низменные фрагменты проекта, обновляются необходимые зависимости, выполняются необходимые проверки и генерируется требуемые артефакты позволяют говорить о системах сборки как об инструментах, которые при правильной настройке могут радикально изменить скорость доставки вашего проекта до конченых потребителей.
Спасибо за внимание!

https://habrahabr.ru/post/334592/






