Если вы родились в 1980—90-е, то, вероятно, слышали об игре «Змейка» (Snake). И под «слышали» я подразумеваю «потратили огромное количество времени, выращивая гигантскую дурацкую змею на маленьком экранчике Nokia 3310».
Что ещё вы помните о телефонах Nokia? Их очень долгую работу от аккумулятора, верно? Как такой «примитивный» телефон позволял своему владельцу часами играть в «Змейку», не опустошая аккумулятор?
24 января 2018 года на конференции безопасности Microsoft BlueHat исследователями Benjamin Delpy и Vincent Le Toux была продемонстрирована новая технология атаки против инфраструктуры Active Directory.
Название новой техники атаки — DCShadow. Такая атака позволяет злоумышленнику создать поддельный контроллер домена в среде Active Directory для репликации вредоносных объектов в рабочую инфраструктуру Active Directory. Читать дальше ->
Привет, Хабр! Мы запускаем Академию e-Legion — онлайн-школу для мобильных разработчиков.
Всё серьёзно: 9 месяцев обучения, лекции топовых разработчиков, практические задания, тестирования, чат с преподавателями и материалы для самостоятельной работы.
Под катом — необходимые знания для старта, план обучения iOS-разработчиков, знакомство с преподавателями и программа трудоустройства для выпускников Академии. Читать дальше ->
Привет, Хабр! Мы запускаем Академию e-Legion — онлайн-школу для мобильных разработчиков.
Всё серьёзно: 9 месяцев обучения, лекции топовых разработчиков, практические задания, тестирования, чат с преподавателями и материалы для самостоятельной работы.
Под катом — необходимые знания для старта, план обучения Android-разработчиков, знакомство с преподавателями и программа трудоустройства для выпускников Академии. Читать дальше ->
Недавно на Хабре была статья про «необычные» DEF-номера. Под необычностью скрывалась «многоканальность» — возможность принимать на номер несколько параллельных звонков (а разговаривать по ним будут операторы колл-центра). Целых пять одновременных разговоров и восклицательный знак в конце фразы! Под катом я расскажу про многоканальность не с маркетинговой, а с технической точки зрения. Как операторы «принимают» звонки, чем «необычный DEF-номер» отличается от «обычного ABC-номера», и много это или мало — целых пять параллельных звонков? Кстати, почему именно пять, а не двадцать или сто? Читать дальше ->
Привет, Хаброжители! Предлагаем вашему вниманию главу «Шаблоны для построения приложений на основе микросервисов» из нашей новой книги К. Хорсдала, посвященной программированию микросервисов на платформе .NET
Составные приложения: интеграция на фронтенде
Первым шаблоном для построения приложений на основе микросервисов является шаблон «Составное приложение». Такое приложение состоит из функциональности, взятой из нескольких мест — в нашем случае из нескольких микросервисов, — с каждым из которых оно связывается непосредственно. Микросервисы могут общаться друг с другом для выполнения своих задач — для составного приложения это неважно.
На рис. 12.3 мы возвращаемся к примеру со страховкой — у нас есть универсальное приложение, которое включает в себя всю функциональность системы. Система для работы со страховками построена с использованием микросервисов, поэтому для того, чтобы предоставить всю функциональность системы, приложение должно получать бизнес-возможности от нескольких микросервисов. Микросервисов в системе больше, чем показано на рисунке, и приложение не будет непосредственно наследовать функциональность от всех них. Такое приложение сосредоточивает всю функциональность в одном месте, отсюда и возник термин «составное приложение». Читать дальше ->
DISCLAMER!
Описанная в статье уязвимость исправлена и не несет в себе никакой опасности. Публикация написана в целях академического просвещения читателей и демонстрации важности вопросов ИБ. Описанная уязвимость присутствовала на E-GOV несколько лет и позволяла получить доступ к паролям пользователей электронного правительства Казахстана.
Недавно на портале электронного правительства Республики Казахстан egov.kz закрыли критическую уязвимость. Так как баг уже закрыт и его раскрытие больше не представляет угрозы, было принято решение обсудить его с вами, так как с технической и академической точки зрения случай представляет большой интерес для исследователей. Еще один немаловажный момент: в определенных кругах такие ошибки, в частности конкретно эта, известны очень длительное время, и их наличие вызывает много вопросов к уровню компетентности ответственных лиц.
Те, кто всегда пользуется web-сервисами через прокси, чтобы контролировать обмен данными, могли заметить в мобильной версии сайта egov.kz передаваемые на сервер запросы в виде XML. Многие исследователи пробовали подгрузить в запрос сущность, или, простым языком, провести атаку типа XXE.
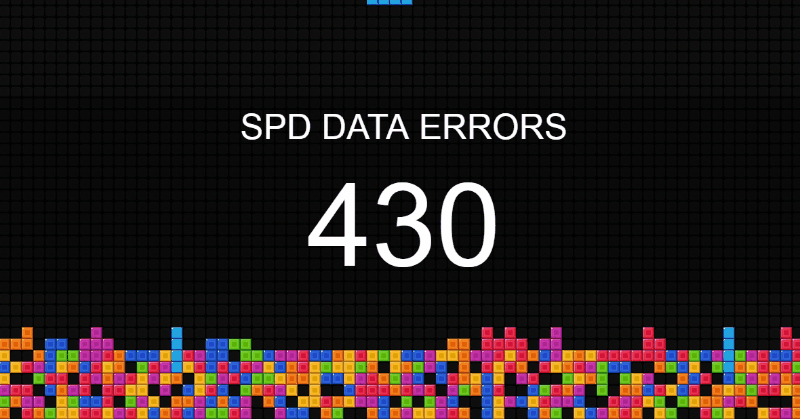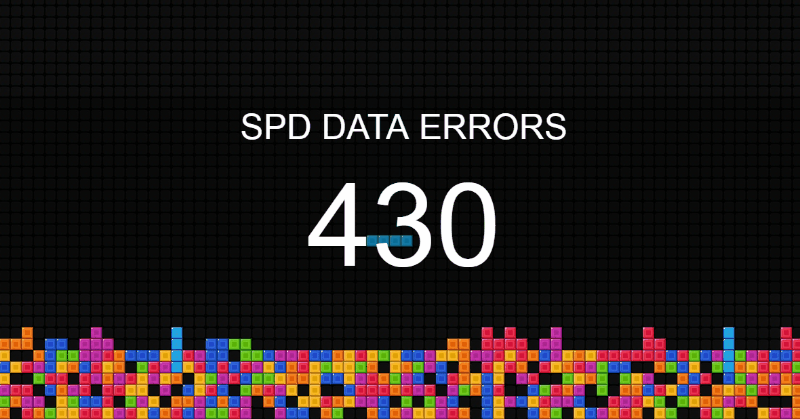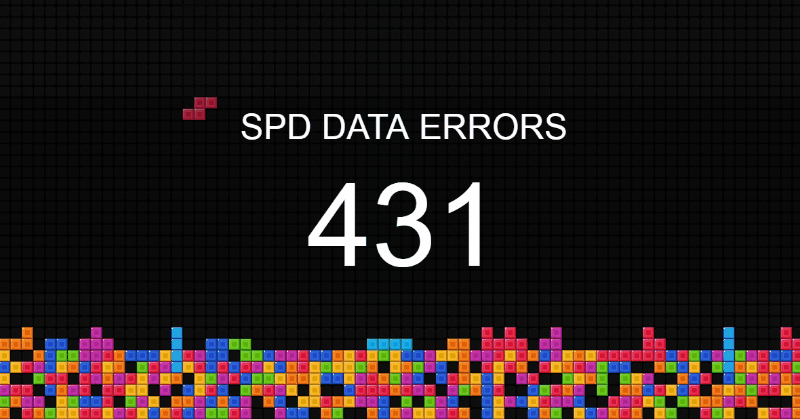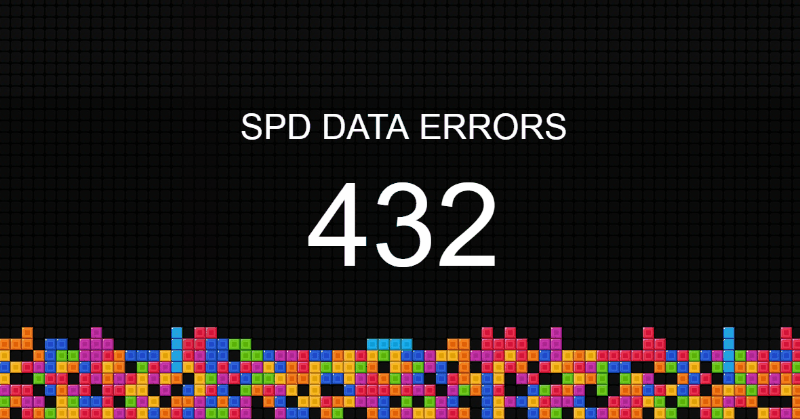
Управление качеством данных – новая дисциплина. Постепенно направление набирает обороты в нефтяной отрасли, банковском деле и ритейле. Каждый идет своим путем, практически наощупь.
Я работаю аналитиком качества данных. В статье расскажу, как у нас устроено управление качеством данных, с какими трудностями мы сталкивались, и как их преодолевали.
Визуализация качества данных на экране в офисе. Уровень блоков пропорционален количеству ошибок. Читать дальше →
Это четвёртая статья серии, посвящённая использованию класса Optional при обработке объектов с динамической структурой. В первой статье было рассказано о способах избежания NullPointerException в ситуациях, когда вы не можете или не хотите использовать Optional. Вторая статья посвящена описанию методов класса Optional в том виде, как он появился в Java 8. Третья — методам, добавленным в класс в Java 9.
Класс о котором я хочу рассказать в этой статье возник при попытке найти решение реальной задачи. На абстрактном уровне постановка задачи звучит так: вы обращаетесь к некому сервису, который в случае успеха должен вернуть объект. Но запрос может закончится и неудачей. Причин для неудачи может быть несколько. И логика дальнейшей обработки ошибочной ситуации зависит от того, какова была причина неудачи.
Если сервис возвращает Optional, о причине мы ничего не узнаем. Значит надо использовать что-то похожее на Optional, но содержащее информацию об ошибке в случае неуспеха. Читать дальше ->
Привет, Хабр! В ближайшие месяцы в России появится Google Ассистент, чтобы сделать ваше общение с поисковиком более естественным и похожим на настоящий диалог. Ассистент поможет находить голосом необходимую информацию — будь то погода, загруженность дорог по пути на работу, данные о любимых актерах и многое другое. А еще он позволит юзерам взаимодействовать с приложениями — благодаря Actions on Google.
С помощью Actions on Google вы сможете разрабатывать свои приложения (экшены) для Ассистента и — таким образом — расширять его функционал и, следовательно, сделать его еще полезнее для пользователей. И начать делать это стоит уже сегодня, так как Google Ассистент появится в России совсем скоро. Как только сервис станет доступным, пользователи смогут взаимодействовать с вашими приложениями путем диалога — ровно так же, как и в других ситуациях, где можно использовать Ассистент, например, при поиске Информации в интернете.
Даже годы спустя после выхода фильма Avatar остаётся кое-что, с чем не может справиться даже Райан Гослинг — использование шрифта Papyrus в логотипе фильма. В пародии, снятой Saturday Night Live, дизайнер шрифтов открывает меню, перебирает шрифты и случайным образом выбирает Papyrus.
Главная проблема выбора шрифтов — одновременно слишком много и слишком мало вариантов.
С одной стороны, выбор только из системных шрифтов может привести к плохому решению, потому что среди стандартных шрифтов ничего интересного просто не представлено.
С другой стороны, библиотеки веб-шрифтов с сотнями и тысячами наименований поражают изобилием, что иногда приводит к парадоксальным выборам шрифтов. Читать дальше ->
Это продолжение рассказа о лучших (по мнению участников) докладах HighLoad++ 2017. В предыдущей статье я писал о двух лидерах рейтинга. Идем дальше. В этом материале — доклад Вадима Антонюка о фродах и Макса Лапшина - о прошивке для IP-камеры на Rust.
Спросите любого инди-разработчика игр, в чём заключается секрет маркетинга инди-игр, и от каждого слышите почти одинаковый ответ: нужно попасть в список рекомендаций Steam или магазина мобильных приложений, добиться обзоров в прессе, сделать так, чтобы в вашу игру сыграл популярный стример. В противном случае, игра, в которую вы вложили кучу сил и времени, просто провалится.
Но представьте рынок, на котором такие рекомендации неприменимы. На нём нет таких вещей, как Steam Launch Visibility Round или рекомендации в App Store. Что, если нет прессы, с радостью пишущей обзоры? И что, если вместо 7667 игр, выпущенных в Steam в 2017 году, в тот же год выпущено больше 100 000 новых книг? А общее количество книг на рынке превышает 4 000 000 наименований? Читать дальше ->
В предыдущей статье на примере доменной сущности товара мы рассмотрели собственные типы данных для многоязычных приложений. Мы научились описывать и использовать атрибуты сущностей, имеющие значения на различных языках. Но вопросы хранения и обработки в реляционной СУБД, а также проблемы эффективной работы в коде приложения до сих пор актуальны.
IT-сообщество использует различные способы хранения многоязычных данных. Способы эти кардинально различаются эффективностью запросов, устойчивостью к добавлению новых локализаций, объемом данных, удобством для приложения-потребителя.
Однако в индустрии все еще нет решения Database Internationalization for Dummies. Вместе с вами мы попробуем немного заполнить этот пробел: опишем возможные способы, оценим их преимущества и недостатки, выберем эффективные. Мы не собираемся изобретать серебряную пулю, но сценарий который будем рассматривать, довольно типичен для корпоративных приложений. Надеемся, многим он окажется полезен.
Приведенные в статье фрагменты кода — на языке C#. На GitHub можно найти примеры реализации механизмов интернационализации с использованием двух различных связок ORM и СУБД: NHibernate + Oracle Database и Entity Framework Core + SQL Server. Разработчикам, использующим упомянутые ORM, будет интересно узнать конкретные приемы и трудности работы с многоязычными данными, а также блокирующие дефекты фреймворков и перспективы их устранения. Изложенные ниже принципы и примеры работы с многоязычными данными легко перенести и на другие языки и технологии.
Предлагаем вашему вниманию цикл статей, посвященных рекомендациям по написанию качественного кода на примере ошибок, найденных в проекте Chromium. Это четвёртая часть, которая будет посвящена проблеме опечаток и написанию кода с помощью «Copy-Paste метода».
От опечаток в коде никто не застрахован. Опечатки можно встретить в коде самых квалифицированных программистов. Квалификация и опыт, к сожалению, не защищают от того, чтобы перепутать название переменной или забыть что-то написать. Поэтому опечатки были, есть и будут. Читать дальше ->
jq — самая популярная утилита для обработки JSON из командной строки, написана на C и имеет свой собственный синтаксис для работы с JSON.
Однако, обрабатывать JSON в командной строке не нужно очень часто, а когда потребность возникает, приходится мучиться с незнакомым языком программирования.
Так и появилась идея написать fx с простым и понятным синтаксисом, который никогда не забудешь. А какой язык программирования знают все? Правильно — JavaScript.
Random numbers should not be generated with a method chosen at random. — Donald Knuth
Копаясь как-то в исходниках одного сервиса в поисках уязвимостей, я наткнулся на генерацию одноразового кода для аутентификации через SMS. Обработчик запросов на отправку кода упрощённо выглядел так:
class AuthenticateByPhoneHandler
{
/* ... */
static string GenerateCode() => rnd.Next(100000, 1000000).ToString();
readonly static Random rnd = new Random();
}
Проблема видна невооруженным глазом: для генерации 6-тизначного кода используется класс Random — простой некриптографический генератор псевдослучайных чисел (ГПСЧ). Займёмся им вплотную: научимся предсказывать последовательность случайных чисел и прикинем возможный сценарий атаки на сервис.
Если проследить эволюцию создания сайтов и сервисов, то можно заметить, что сначала было важно, чтобы они хотя бы были и работали. Затем создатели стали задумываться о внешней красоте и привлекательности для клиентов, ну а потом постепенно стали ориентироваться и на удобство для пользователей.
Теперь же возник новый тренд — “доступность”. Ведь сейчас сайты просматривают не только с больших мониторов в спокойной обстановке, но и со смартфонов в трясущихся автобусах и ноутбуков в шумных кафе, а среди пользователей появляется все больше пенсионеров и даже людей с ограниченными возможностями.
Сегодня мы немного поговорим про EntityFramework. Совсем чуть-чуть. Да, я знаю что к нему можно относиться по-разному, многие от него плюются, но за неимением лучшей альтернативы — продолжают использовать.
Так вот. Часто ли вы используете в своём C#-проекте с настроенным ORM-ом прямые SQL-запросы в базу? Ой, да бросьте, не отнекивайтесь. Используете. Иначе как бы вы реализовывали удаление/обновление сущностей пачками и оставались живы…
Что мы больше всего любим в прямом SQL? Скорость и простоту. Там, где "в лучших традициях ORM" надо выгрузить в память вагончик объектов и всем сделать context.Remove (ну или поманипулировать Attach-ем), можнo обойтись одним мааааленьким SQL-запросом.
Что мы больше всего не любим в прямом SQL? Правильно. Отсутствие типизации и взрывоопасность. Прямой SQL обычно делается через DbContext.Database.ExecuteSqlCommand, а оно на вход принимает только строку. Следовательно, Find Usages в студии никогда не покажет вам какие поля каких сущностей ваш прямой SQL затронул, ну и помимо прочего вам приходится полагаться на свою память в вопросе точных имён всех таблиц/колонок которые вы щупаете. А ещё молиться, что никакой лоботряс не покопается в вашей модели и не переименует всё в ходе рефакторинга или средствами EntityFramework, пока вы будете спать.
Так ликуйте же, адепты маленьких raw SQL-запросов! В этой статье я покажу вам как совместить их с EF, не потерять в майнтайнабильности и не наплодить детонаторов. Ныряйте же под кат скорее!






 Привет, Хаброжители! Предлагаем вашему вниманию главу «Шаблоны для построения приложений на основе микросервисов» из нашей новой книги К. Хорсдала, посвященной программированию микросервисов на платформе .NET
Привет, Хаброжители! Предлагаем вашему вниманию главу «Шаблоны для построения приложений на основе микросервисов» из нашей новой книги К. Хорсдала, посвященной программированию микросервисов на платформе .NET