Daniel Stenberg: daniel.haxx.se episode 8 |
Today I hesitated to make my new weekly video episode. I looked at the viewers number and how they basically have dwindled the last few weeks. I’m not making this video series interesting enough for a very large crowd of people. I’m re-evaluating if I should do them at all, or if I can do something to spice them up…
… or perhaps just not look at the viewers numbers at all and just do what think is fun?
I decided I’ll go with the latter for now. After all, I enjoy making these and they usually give me some interesting feedback and discussions even if the numbers are really low. What good is a number anyway?
This week’s episode:
Personal
Firefox
Fun
HTTP/2
TALKS
curl
wget
http://daniel.haxx.se/blog/2014/10/27/daniel-haxx-se-episode-8/
|
|
John O'Duinn: “Oughta See” by General Fuzz |
 Well, well, well… I’m very happy to discover that General Fuzz just put out yet another album. Tonight was a great first-listen, and I know this will make a happy addition to tomorrow’s quiet Sunday morning first-coffee. Thanks, James!
Well, well, well… I’m very happy to discover that General Fuzz just put out yet another album. Tonight was a great first-listen, and I know this will make a happy addition to tomorrow’s quiet Sunday morning first-coffee. Thanks, James!
Click here to jump over to the music and listen for yourself. On principle, his music is free-to-download, so try it and if you like it, help spread the word.
(ps: if you like this album, check out his *6* other albums, also all available for free download on the same site – donations welcome!)
http://oduinn.com/blog/2014/10/26/oughta-see-by-general-fuzz/
|
|
Gregory Szorc: Implications of Using Bugzilla for Firefox Patch Development |
Mozilla is very close to rolling out a new code review tool based on Review Board. When I became involved in the project, I viewed it as an opportunity to start from a clean slate and design the ideal code development workflow for the average Firefox developer. When the design of the code review experience was discussed, I would push for decisions that were compatible with my utopian end state.
As part of formulating the ideal workflows and design of the new tool, I needed to investigate why we do things the way we do, whether they are optimal, and whether they are necessary. As part of that, I spent a lot of time thinking about Bugzilla's role in shaping the code that goes into Firefox. This post is a summary of my findings.
The primary goal of this post is to dissect the practices that Bugzilla influences and to prepare the reader for the potential to reassemble the pieces - to change the workflows - in the future, primarily around Mozilla's new code review tool. By showing that Bugzilla has influenced the popularization of what I consider non-optimal practices, it is my hope that readers start to question the existing processes and open up their mind to change.
Since the impetus for this post in the near deployment of Mozilla's new code review tool, many of my points will focus on code review.
Before I go into my findings, I'd like to explicitly state that while many of the things I'm about to say may come across as negativity towards Bugzilla, my intentions are not to put down Bugzilla or the people who maintain it. Yes, there are limitations in Bugzilla. But I don't think it is correct to point fingers and blame Bugzilla or its maintainers for these limitations. I think we got where we are following years of very gradual shifts. I don't think you can blame Bugzilla for the circumstances that led us here. Furthermore, Bugzilla maintainers are quick to admit the faults and limitations of Bugzilla. And, they are adamant about and instrumental in rolling out the new code review tool, which shifts code review out of Bugzilla. Again, my intent is not to put down Bugzilla. So please don't direct ire that way yourself.
So, let's drill down into some of the implications of using Bugzilla.
The stream of changes on a bug in Bugzilla (including review comments) is a flat, linear list of plain text comments. This works great when the activity of a bug follows a nice, linear, singular topic flow. However, real bug activity does not happen this way. All but the most trivial bugs usually involve multiple points of discussion. You typically have discussion about what the bug is. When a patch comes along, reviewer feedback comes in both high-level and low-level forms. Each item in each group is its own logical discussion thread. When patches land, you typically have points of discussion tracking the state of this patch. Has it been tested, does it need uplift, etc.
Bugzilla has things like keywords, flags, comment tags, and the whiteboard to enable some isolation of these various contexts. However, you still have a flat, linear list of plain text comments that contain the meat of the activity. It can be extremely difficult to follow these many interleaved logical threads.
In the context of code review, lumping all review comments into the same linear list adds overhead and undermines the process of landing the highest-quality patch possible.
Review feedback consists of both high-level and low-level comments. High-level would be things like architecture discussions. Low-level would be comments on the code itself. When these two classes of comments are lumped together in the same text field, I believe it is easy to lose track of the high-level comments and focus on the low-level. After all, you may have a short paragraph of high-level feedback right next to a mountain of low-level comments. Your eyes and brain tend to gravitate towards the larger set of more concrete low-level comments because you sub-consciously want to fix your problems and that large mass of text represents more problems, easier problems to solve than the shorter and often more abstract high-level summary. You want instant gratification and the pile of low-level comments is just too tempting to pass up. We have to train ourselves to temporarily ignore the low-level comments and focus on the high-level feedback. This is very difficult for some people. It is not an ideal disposition. Benjamin Smedberg's recent post on code review indirectly talks about some of this by describing his has rational approach of tackling high-level first.
As review iterations occur, the bug devolves into a mix of comments related to high and low-level comments. It thus becomes harder and harder to track the current high-level state of the feedback, as they must be picked out from the mountain of low-level comments. If you've ever inherited someone else's half-finished bug, you know what I'm talking about.
I believe that Bugzilla's threadless and contextless comment flow disposes us towards focusing on low-level details instead of the high-level. I believe that important high-level discussions aren't occurring at the rate they need and that technical debt increases as a result.
Code review feedback consists of multiple items of feedback. Each one is related to the review at hand. But oftentimes each item can be considered independent from others, relevant only to a single line or section of code. Style feedback is one such example.
I find it helps to model code review as a tree. You start with one thing you want to do. That's the root node. You split that thing into multiple commits. That's a new layer on your tree. Finally, each comment on those commits and the comments on those comments represent new layers to the tree. Code review thus consists of many related, but independent branches, all flowing back to the same central concept or goal. There is a one to many relationship at nearly every level of the tree.
Again, Bugzilla lumps all these individual items of feedback into a linear series of flat text blobs. When you are commenting on code, you do get some code context printed out. But everything is plain text.
The result of this is that tracking the progress on individual items of feedback - individual branches in our conceptual tree - is difficult. Code authors must pour through text comments and manually keep an inventory of their progress towards addressing the comments. Some people copy the review comment into another text box or text editor and delete items once they've fixed them locally! And, when it comes time to review the new patch version, reviewers must go through the same exercise in order to verify that all their original points of feedback have been adequately addressed! You've now redundantly duplicated the feedback tracking mechanism among at least two people. That's wasteful in of itself.
Another consequence of this unstructured feedback tracking mechanism is that points of feedback tend to get lost. On complex reviews, you may be sorting through dozens of individual points of feedback. It is extremely easy to lose track of something. This could have disastrous consequences, such as the accidental creation of a 0day bug in Firefox. OK, that's a worst case scenario. But I know from experience that review comments can and do get lost. This results in new bugs being filed, author and reviewer double checking to see if other comments were not acted upon, and possibly severe bugs with user impacting behavior. In other words, this unstructured tracking of review feedback tends to lessen code quality and is thus a contributor to technical debt.
Bugzilla's user interface encourages the writing of fewer, larger patches. (The opposite would be many, smaller patches - sometimes referred to as micro commits.)
This result is achieved by a user interface that handles multiple patches so poorly that it effectively discourages that approach, driving people to create larger patches.
The stream of changes on a bug (including review comments) is a flat, linear list of plain text comments. This works great when the activity of a bug follows a nice, linear flow. However, reviewing multiple patches doesn't work in a linear model. If you attach multiple patches to a bug, the review comments and their replies for all the patches will be interleaved in the same linear comment list. This flies in the face of the reality that each patch/review is logically its own thread that deserves to be followed on its own. The end result is that it is extremely difficult to track what's going on in each patch's review. Again, we have different contexts - different branches of a tree - all living in the same flat list.
Because conducting review on separate patches is so painful, people are effectively left with two choices: 1) write a single, monolithic patch 2) create a new bug. Both options suck.
Larger, monolithic patches are harder and slower to review. Larger patches require much more cognitive load to review, as the reviewer needs to capture the entire context in order to make a review determination. This takes more time. The increased surface area of the patch also increases the liklihood that the reviewer will find something wrong and will require a re-review. The added complexity of a larger patch also means the chances of a bug creeping in are higher, leading to more bugs being filed and more reviews later. The more review cycles the patch goes through, the greater the chances it will suffer from bit rot and will need updating before it lands, possibly incurring yet more rounds of review. And, since we measure progress in terms of code landing, the delay to get a large patch through many rounds of review makes us feel lethargic and demotivates us. Large patches have intrinsic properties that lead to compounding problems and increased development cost.
As bad as large patches are, they are roughly in the same badness range as the alternative: creating more bugs.
When you create a new bug to hold the context for the review of an individual commit, you are doing a lot of things, very few of them helpful. First, you must create a new bug. There's overhead to do that. You need to type in a summary, set up the bug dependencies, CC the proper people, update the commit message in your patch, upload your patch/attachment to the new bug, mark the attachment on the old bug obsolete, etc. This is arguably tolerable, especially with tools that can automate the steps (although I don't believe there is a single tool that does all of what I mentioned automatically). But the badness of multiple bugs doesn't stop there.
Creating multiple bugs fragments the knowledge and history of your change and diminishes the purpose of a bug. You got in the situation of creating multiple bugs because you were working on a single logical change. It just so happened that you needed/wanted multiple commits/patches/reviews to represent that singular change. That initial change was likely tracked by a single bug. And now, because of Bugzilla's poor user interface around mutliple patch reviews, you now find yourself creating yet another bug. Now you have two bug numbers - two identifiers that look identical, only varying by their numeric value - referring to the same logical thing. We've started with a single bug number referring to your logical change and created what are effectively sub-issues, but allocated them in the same namespace as normal bugs. We've diminished the importance of the average bug. We've introduced confusion as to where one should go to learn about this single, logical change. Should I go to bug X or bug Y? Sure, you can likely go to one and ultimately find what you were looking for. But that takes more effort.
Creating separate bugs for separate reviews also makes refactoring harder. If you are going the micro commit route, chances are you do a lot of history rewriting. Commits are combined. Commits are split. Commits are reordered. And if those commits are all mapping to individual bugs, you potentially find yourself in a huge mess. Combining commits might mean resolving bugs as duplicates of each other. Splitting commits means creating yet another bug. And let's not forget about managing bug dependencies. Do you set up your dependencies so you have a linear, waterfall dependency corresponding to commit order? That logically makes sense, but it is hard to keep in sync. Or, do you just make all the review bugs depend on a single parent bug? If you do that, how do you communicate the order of the patches to the reviewer? Manually? That's yet more overhead. History rewriting - an operation that modern version control tools like Git and Mercurial have enabled to be a lightweight operation and users love because it doesn't constrain them to pre-defined workflows - thus become much more costly. The cost may even be so high that some people forego rewriting completely, trading their effort for some poor reviewer who has to inherit a series of patches that isn't organized as logically as it could be. Like larger patches, this increases cognitive load required to perform reviews and increases development costs.
As you can see, reviewing multiple, smaller patches with Bugzilla often leads to a horrible user experience. So, we find ourselves writing larger, monolithic patches and living with their numerous deficiencies. At least with monolithic patches we have a predictable outcome for how interaction with Bugzilla will play out!
I have little doubt that large patches (whose existence is influenced by the UI of Bugzilla) slows down the development velocity of Firefox.
The heavy involvement of Bugzilla in our code development lifecycle has influenced how we write commit messages. Let's start with the obvious example. Here is our standard commit message format for Firefox:
Bug 1234 - Fix some feature foo; r=gps
The bug is right there at the front of the commit message. That prominent placement is effectively saying the bug number is the most important detail about this commit - everything else is ancillary.
Now, I'm sure some of you are saying, but Greg, the short description of the change is obviously more important than the bug number. You are right. But we've allowed ourselves to make the bug and the content therein more important than the commit.
Supporting my theory is the commit message content following the first/summary line. That data is almost always - wait for it - nothing: we generally don't write commit messages that contain more than a single summary line. My repository forensics show that that less than 20% of commit messages to Firefox in 2014 contain multiple lines (this excludes merge and backout commits). (We are doing better than 2013 - the rate was less than 15% then).
Our commit messages are basically saying, here's a highly-abbreviated summary of the change and a pointer (a bug number) to where you can find out more. And of course loading the bug typically reveals a mass of interleaved comments on various topics, hardly the high-level summary you were hoping was captured in the commit message.
Before I go on, in case you are on the fence as to the benefit of detailed commit messages, please lead Phabricator's recommendations on revision control and writing reviewable code. I think both write-ups are terrific and are excellent templates that apply to nearly everyone, especially a project as large and complex as Firefox.
Anyway, there are many reasons why we don't capture a detailed, multi-line commit message. For starters, you aren't immediately rewarded for doing it: writing a good commit message doesn't really improve much in the short term (unless someone yells at you for not doing it). This is a generic problem applicable to all organizations and tools. This is a problem that culture must ultimately rectify. But our tools shouldn't reinforce the disposition towards laziness: they should reward best practices.
I don't Bugzilla and our interactions with it do an adequate job rewarding good commit message writing. Chances are your mechanism for posting reviews to Bugzilla or posting the publishing of a commit to Bugzilla (pasting the URL in the simple case) brings up a text box for you to type review notes, a patch description, or extra context for the landing. These should be going in the commit message, as they are the type of high-level context and summarizations of choices or actions that people crave when discerning the history of a repository. But because that text box is there, taunting you with its presence, we write content there instead of in the commit message. Even where tools like bzexport exist to upload patches to Bugzilla, potentially nipping this practice in the bug, it still engages in frustrating behavior like reposting the same long commit message on every patch upload, producing unwanted bug spam. Even a tool that is pretty sensibly designed has an implementation detail that undermines a good practice.
I have a challenge for you: identify all patches currently under consideration for incorporation in the Firefox source tree, run static analysis on them, and tell me if they meet our code style policies.
This should be a solved problem and deployed system at Mozilla. It isn't. Part of the problem is because we're using Bugzilla for conducting review and doing patch management. That may sound counter-intuitive at first: Bugzilla is a centralized service - surely we can poll it to discover patches and then do stuff with those patches. We can. In theory. Things break down very quickly if you try this.
We are uploading patch files to Bugzilla. Patch files are representations of commits that live outside a repository. In order to get the full context - the result of the patch file - you need all the content leading up to that patch file - the repository data. When a naked patch file is uploaded to Bugzilla, you don't always have this context.
For starters, you don't know with certainly which repository the patch belongs to because that isn't part of the standard patch format produced by Mercurial or Git. There are patches for various repositories floating around in Bugzilla. So now you need a way to identify which repository a patch belongs to. It is a solvable problem (aggregate data for all repositories and match patches based on file paths, referenced commits, etc), albeit one Mozilla has not yet solved (but should).
Assuming you can identify the repository a patch belongs to, you need to know the parent commit so you can apply this patch. Some patches list their parent commits. Others do not. Even those that do may lie about it. Patches in MQ don't update their parent field when they are pushed, only after they are refreshed. You could be testing and uploading a patch with a different parent commit than what's listed in the patch file! Even if you do identify the parent commit, this commit could belong to another patch under consideration that's also on Bugzilla! So now you need to assemble a directed graph with all the patches known from Bugzilla applied. Hopefully they all fit in nicely.
Of course, some patches don't have any metadata at all: they are just naked diffs or are malformed commits produced by tools that e.g. attempt to convert Git commits to Mercurial commits (Git users: you should be using hg-git to produce proper Mercurial commits for Firefox patches).
Because Bugzilla is talking in terms of patch files, we often lose much of the context needed to build nice tools, preventing numerous potential workflow optimizations through automation. There are many things machines could be doing for us (such as looking for coding style violations). Instead, humans are doing this work and costing Mozilla a lot of time and lost developer productivity in the process. (A human costs ~$100/hr. A machine on EC2 is pennies per hour and should do the job with lower latency. In other words, you can operate over 300 machines 24 hours a day for what you may an engineer to work an 8 hour shift.)
I have outlined a few of the side-effects of using Bugzilla as part of our day-to-day development, review, and landing of changes to Firefox.
There are several takeways.
First, one cannot argue the fact that Firefox development is bug(zilla) centric. Nearly every important milestone in the lifecycle of a patch involves Bugzilla in some way. This has its benefits and drawbacks. This article has identified many of the drawbacks. But before you start crying to expunge Bugzilla from the loop completely, consider the benefits, such as a place anyone can go to to add metadata or comments on something. That's huge. There is a larger discussion to be had here. But I don't want to be inviting it quite yet.
A common thread between many of the points above is Bugzilla's unstructured and generic handling of code and metadata attached to it (patches, review comments, and landing information). Patches are attachments, which can be anything under the sun. Review comments are plain text comments with simple author, date, and tag metadata. Landings are also communicated by plain text review comments (at least initially - keywords and flags are used in some scenarios).
By being a generic tool, Bugzilla throws away a lot of the rich metadata that we produce. That data is still technically there in many scenarios. But it becomes extremely difficult if not practically impossible for both humans and machines to access efficiently. We lose important context and feedback by normalizing all this data to Bugzilla. This data loss creates overhead and technical debt. It slows Mozilla down.
Fortunately, the solutions to these problems and shortcomings are conceptually simple (and generally applicable): preserve rich context. In the context of patch distribution, push commits to a repository and tell someone to pull those commits. In the context of code review, create sub-reviews for different commits and allow tracking and easy-to-follow (likely threaded) discussions on found issues. Design workflow to be code first, not tool or bug first. Optimize workflows to minimize people time. Lean heavily on machines to do grunt work. Integrate issue tracking and code review, but not too tightly (loosely coupled, highly cohesive). Let different tools specialize in the handling of different forms of data: let code review handle code review. Let Bugzilla handle issue tracking. Let a landing tool handle tracking the state of landings. Use middleware to make them appear as one logical service if they aren't designed to be one from the start (such as is Mozilla's case with Bugzilla).
Another solution that's generally applicable is to refine and optimize the whole process to land a finished commit. Your product is based on software. So anything that adds overhead or loss of quality in the process of developing that software is fundamentally a product problem and should be treated as such. Any time and brain cycles lost to development friction or bugs that arise from things like inadequate code reviews tools degrade the quality of your product and take away from the user experience. This should be plain to see. Attaching a cost to this to convince the business-minded folks that it is worth addressing is a harder matter. I find management with empathy and shared understanding of what amazing tools can do helps a lot.
If I had to sum up the solution in one sentence, it would be: invest in tools and developer happiness.
I hope to soon publish a post on how Mozilla's new code review tool addresses many of the workflow deficiencies present today. Stay tuned.
http://gregoryszorc.com/blog/2014/10/27/implications-of-using-bugzilla-for-firefox-patch-development
|
|
Martijn Wargers: T-Dose event in Eindhoven |

http://mwargers.blogspot.com/2014/10/last-saturday-and-sunday-i-went-to-t.html
|
|
Kim Moir: Release Engineering in the classroom |
.JPG) |
| View looking down from the university |
.JPG) |
| Universit'e de Montr'eal administration building |
.JPG) |
| 'Ecole Polytechnique building. Each floor is painted a different colour to represent a differ layer of the earth. So the ground floor is red, the next orange and finally green. |
.JPG) |
| The first day, Jack Jiang from York University gave a talk about software performance engineering. |
http://relengofthenerds.blogspot.com/2014/10/release-engineering-in-classroom.html
|
|
Kim Moir: Beyond the Code 2014: a recap |
.JPG) |
| View of the Parliament Buildings and Chateau Laurier from the MacKenzie street bridge over the Rideau Canal |
.JPG) |
| Ottawa Conference Centre, location of Beyond the Code |
http://relengofthenerds.blogspot.com/2014/10/beyond-code-2014-recap.html
|
|
Karl Dubost: How to deactivate UA override on Firefox OS |
Some Web sites do not send the right version of the content to Firefox OS. Some ill-defined server side and client side scripting do not detect Firefox OS as a mobile device and they send the desktop content instead. To fix that, we sometimes define UA override for certain sites.
It may improve the life of users but as damaging consequences when it's time for Web developers to test the site they are working on. The device is downloading the list on the server side at a regular pace. Luckily enough, you can deactivate it through preferences.
There are two places in Firefox OS where you may store preferences:
/system/b2g/defaults/pref/user.js/data/b2g/mozilla/something.default/prefs.js (where something is a unique id)To change the UA override preferences, you need to set useragent.updates.enabled to true (default) for enabling and to false for disabling. If you put in /system/, each time you update the system, the file and its preferences will be crushed and replace by the update. On the other if you put it in /data/, it will be kept with all the data of your profiles.
On the command line, using adb, you can manipulate the preferences:
# Prepare set -x adb shell mount -o rw,remount /system # Local copy of the preferences adb pull /system/b2g/defaults/pref/user.js /tmp/user.js # Keep a local copy of the correct file. cp /tmp/user.js /tmp/user.js.tmp # Let's check if the preference is set and with which value grep useragent.updates.enabled /tmp/user.js # If not set, let's add it echo 'pref("general.useragent.updates.enabled", true);' >> /tmp/user.js.tmp # Push the new preferences to Firefox OS adb push /tmp/user.js.tmp /system/b2g/defaults/pref/user.js adb shell mount -o ro,remount /system # Restart adb shell stop b2g && adb shell start b2g
We created a script to help for this. If you find bugs, do not hesitate to tell us.
Otsukare.
|
|
Justin Dolske: Stellar Paparazzi |
Last Thursday (23 Oct 2014), North America was treated to a partial solar eclipse. This occurs when the moon passes between the Earth and Sun, casting its shadow onto part of our planet. For observers in the California Bay Area, the moon blocked about 40% of the sun. Partial eclipses are fairly common (2-5 times a year, somewhere on the Earth), but they can still be quite interesting to observe.
The first two eclipses I recall observing were on 11 July 1991 and 10 May 1994. The exact dates are not memorable; they’re just easy to look up as the last eclipses to pass through places I lived ! But I do remember trying to observe them with some lackluster-but-easily-available methods of the time. Pinhole projection seems to be most commonly suggested, but I never got good results from it. Using a commercial audio CD (which uses a thin aluminum coating) had worked a bit better for me, but this is highly variable and can be unsafe.
I got more serious about observing in 2012. For the annular solar eclipse and transit of Venus which occurred that May/June, I made an effort to switch to higher-quality methods. My previous blog post goes into detail, but I first tried a pinhead mirror projection, which gave this better-but-not-awesome result:

(In fairness, the equipment fits into a pocket, and it was a last-minute plan to drive 6 hours, round trip, for better viewing.)
For the transit of Venus a few days later — a very rare event that occurs only once ever 105 years — I switched to using my telescope for even better quality. You don’t look through it, but instead use it to project a bright image of the sun onto another surface for viewing.

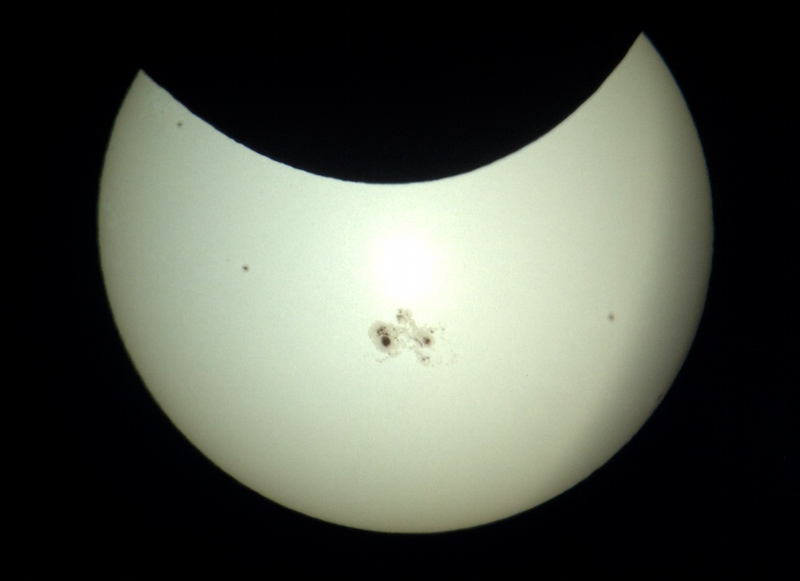
I was excited to catch last week’s eclipse because there was an unusually large sunspot (“AR2192'') that was going to be visible. It’s one of the larger sunspots of the last century, so it seemed like a bit of an historic opportunity to catch it.
This time I took the unusual step of observing from indoors, looking out a window. This basically allows for projecting into a darker area (compared to full sunlight), resulting in better image contrast. Here’s a shot of my basic setup — a Celestron C8 telescope, with a right angle adapter and 30mm eyepiece, projecting the full image of the sun (including eclipse and sunspots) onto the wall of my home:

The image was obviously quite large, and made it easy to examine details of the large sunspot AR2192, as well as a number of smaller sunspots that were present.
I also switched to a 12.5mm eyepiece, allowing for a higher magnification, which made the 2-tone details of the main sunspot even more obvious. The image is a little soft, but not too bad — it’s hard to get sharp contrast at high zoom, and the image was noticeably wavering as a result of thermal convection withing the telescope and atmosphere. (Not to mention that a telescope mounted on carpet in a multistory building isn’t the epitome of stability — I had to stand very still or else the image would shake! Not ideal, but workable.)
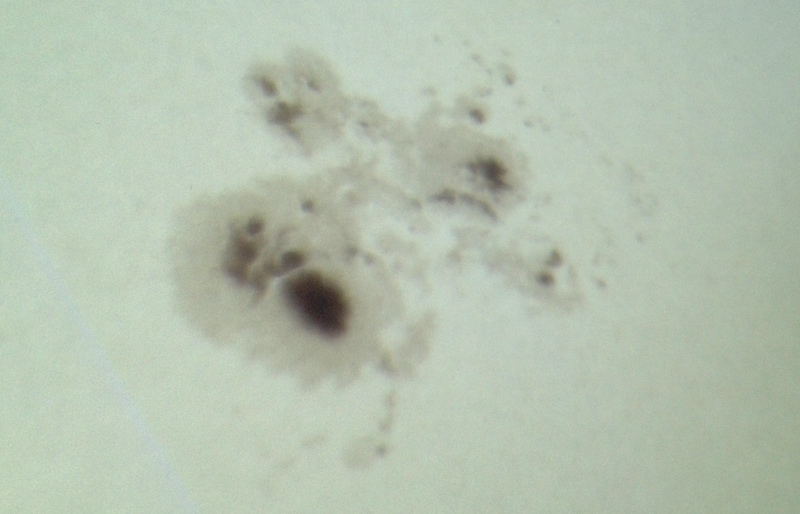
As with the transit of Venus, it’s fun to compare my picture with that from NASA’s $850-million Solar Dynamics Observatory.

Observing this sunspot wasn’t nearly as exciting as the Carrington Event of 1859, but it was still a beautiful sight to behold. I’m definitely looking forward to the 21 August 2017 eclipse, which should be a fantastic total eclipse visible from a wide swath of the US!

|
|
Daniel Stenberg: Stricter HTTP 1.1 framing good bye |
I worked on a patch for Firefox bug 237623 to make sure Firefox would use a stricter check for “HTTP 1.1 framing”, checking that Content-Length is correct and that there’s no broken chunked encoding pieces. I was happy to close an over 10 years old bug when the fix landed in June 2014.
The fix landed and has not caused any grief all the way since June through to the actual live release (Nightlies, Aurora, Beta etc). This change finally shipped in Firefox 33 and I had more or less already started to forget about it, and now things went south really fast.
The amount of broken servers ended up too massive for us and we had to backpedal. The largest amount of problems can be split up in these two categories:
We recognize that not everyone can have the servers fixed – even if all these servers should still be fixed! We now make these HTTP 1.1 framing problems get detected but only cause a problem if a certain pref variable is set (network.http.enforce-framing.http1), and since that is disabled by default they will be silently ignored much like before. The Internet is a more broken and more sad place than I want to accept at times.
We haven’t fully worked out how to also make the download manager (ie the thing that downloads things directly to disk, without showing it in the browser) happy, which was the original reason for bug 237623…
Although the code may now no longer alert anything about HTTP 1.1 framing problems, it will now at least mark the connection not due for re-use which will be a big boost compared to before since these broken framing cases really hurt persistent connections use. The partial transfer return codes for broken SPDY and HTTP/2 transfers remain though and I hope to be able to remain stricter with these newer protocols.
This partial reversion will land ASAP and get merged into patch releases of Firefox 33 and later.
Finally, to top this off. Here’s a picture of an old HTTP 1.1 frame so that you know what we’re talking about.

http://daniel.haxx.se/blog/2014/10/26/stricter-http-1-1-framing-good-bye/
|
|
Mozilla Release Management Team: Firefox 34 beta2 to beta3 |
| Extension | Occurrences |
| cpp | 14 |
| css | 7 |
| jsm | 5 |
| js | 5 |
| xml | 4 |
| h | 4 |
| java | 3 |
| html | 2 |
| mm | 1 |
| ini | 1 |
| Module | Occurrences |
| toolkit | 10 |
| mobile | 8 |
| dom | 6 |
| browser | 6 |
| security | 5 |
| layout | 4 |
| widget | 2 |
| netwerk | 1 |
| media | 1 |
| gfx | 1 |
| content | 1 |
| browser | 1 |
List of changesets:
| Mike Hommey | Bug 1082910, race condition copyhing sdk/bootstrap.js, r=mshal a=lmandel - 8c63e1286d75 |
| Ed Lee | Bug 1075620 - Switch to GET for fetch to allow caching of links data from redirect. r=ttaubert, a=sledru - da489398c483 |
| Steven Michaud | Bug 1069658 - The slide-down titlebar in fullscreen mode is transparent on Yosemite. r=mstange a=lmandel - a026594416c7 |
| Martin Thomson | Bug 1076983 - Disabling SSL 3.0 with pref, r=keeler a=lmandel - 8c9d5c14b866 |
| Randall Barker | Bug 1053426 - Fennec crashes when tab sharing is active. r=jesup, a=lmandel - 4ff961ace0d0 |
| Kearwood (Kip) Gilbert | Bug 1074165 - Prevent out of range scrolling in nsListboxBodyFrame. r=mats, a=lmandel - 9d9abce3b2f2 |
| Randall Barker | Bug 1080012 - Fennec no longer able to mirror tabs on chromecast. r=mfinkle, a=lmandel - 25b64ba60455 |
| Gijs Kruitbosch | Bug 1077304 - Fix password manager to not fire input events if not changing input field values. r=gavin, a=lmandel - 65f5bf99d815 |
| Wes Johnston | Bug 966493 - Mark touchstart and end events as handling user input. r=smaug, a=lmandel - f6c14ee20738 |
| Lucas Rocha | Bug 1058660 - Draw divider at the bottom of about:home's tab strip. r=margaret, a=lmandel - 7d2f3db4567d |
| Lucas Rocha | Bug 1058660 - Use consistent height in about:home's tab strip. r=margaret, a=lmandel - a73c379cfa5f |
| Lucas Rocha | Bug 1058660 - Use consistent bg color in about:home's tab strip. r=margaret, a=lmandel - 47ef137f046f |
| Michael Wu | Bug 1082745 - Avoid reoptimizing optimized SourceSurfaceCairos. r=bas, a=lmandel - 5e3fc9d8a99b |
| D~ao Gottwald | Bug 1075435 - Adjust toolbar side borders for customization mode. r=gijs, a=lmandel - e57353855abf |
| Gijs Kruitbosch | Bug 1083668 - Don't set color for menubar when lwtheme is in use. r=dao, a=lmandel - 1af716db5215 |
| Gavin Sharp | Bug 1060675 - Only cap local form history results for the search bar if there are remote suggestions. r=MattN, a=lmandel - a963eab53a09 |
| Jed Davis | Bug 1080165 - Allow setpriority() to fail without crashing in media plugins on Linux. r=kang, a=lmandel - 5c014e511661 |
| Jeff Gilbert | Bug 1083611 - Use UniquePtr and fallible allocations. r=kamidphish, a=lmandel - 42f43b1c896e |
| Tanvi Vyas | Bug 1084513 - Add a null check on callingDoc before we try and get its principal. r=smaug, a=lmandel - e84f980d638e |
| Christoph Kerschbaumer | Bug 1073316 - CSP: Use nsRefPtr to store CSPContext in CSPReportSenderRunnable. r=sstamm, a=lmandel - 290442516a98 |
| Jared Wein | Bug 1085451 - Implement new design for Loop's green call buttons. r=Gijs, a=lmandel - 5aecfcba7559 |
| Gijs Kruitbosch | Bug 1082002 - Fix urlbar to stay white. r=dao, a=lmandel - 605c6938c9d3 |
| Birunthan Mohanathas | Bug 960757 - Fix test_bug656379-1.html timeouts. r=ehsan, a=test-only - 27b0655c1385 |
| Martin Thomson | Bug 1083058 - Add a pref to control TLS version fallback. r=keeler, a=lsblakk - ae15f14a1db1 |
| Irving Reid | Bug 1081702 - Check that callback parameters are defined before pushing onto result arrays. r=Mossop, a=lsblakk - 79560a3c511f |
| Jared Wein | Bug 1083396 - Update the Hello icon. r=Unfocused, a=lsblakk - a80d4ca56309 |
http://release.mozilla.org/statistics/34/2014/10/26/fx-34-b2-to-b3.html
|
|
Soledad Penades: MozFest 2014 days 0, 1 |
I’ll try to not let something like past year happen and do a quick blogging now!
.@kaythaney&@billdoesphysics flying the @MozillaScience "flag" this morning during facilitators session at #mozfest pic.twitter.com/TUYIeuGPf0
— solendid (@supersole) October 24, 2014
I went to the facilitators session. Gunner, Michelle and co explained how to a) get ready for the chaos b) seed the chaos that is MozFest.
I was equally amused and scared, and a bit of embarrassed. That is good.
Idea being that you have to make new connections and new friends during MozFest. Do not hang with people you already know!
It’s hard to do it because there are so many great friends I haven’t seen in months, and people I hadn’t met in person for the first time, but I try.
We mingle with facilitators and as an exercise, we have to explain to each other what our session will consist of. I am told that they are surprised I have got a technical background, right after I mention “HTTP requests” and “API endpoints”. Very ironic/sad specially after I wrote this on diversity past week.
I also got a terrible headache and ended up leaving back home before the Science Fair happened. Oh well!
Chaos unravels.
EMBRACE THE CHAOS @mozillafestival #mozfest pic.twitter.com/JOF4CWAcF8
— solendid (@supersole) October 25, 2014
Our table for WebIDE sessions is taken over by a group of people hanging out. I kindly ask them to make some room as we need space for a session. They sort of leave and then an AppMaker bunch of people drags the table about 1 meter away from where it was and start a session of their own (??). I was in the middle of explaining WebIDE to someone but they are OK with the chaos, so we drag ourselves 1 m away too and continue as if nothing happened. This guy is pretty cool and perhaps wants to contribute with templates! We discuss Grunt and Gulp and dependency requirements. It’s a pity Nicola is not yet there but I explain him the work he did this summer and we’re working on (node.js + devtools = automated Firefox OS development).
A bit later my session co-facilitators show up in various states of confusion. Nothing unexpected here…
Bobby brings us a big screen so sessions are easier/more obvious and we can explain WebIDE to more than one person at the time. Potch shows his Windows XP wallpaper in all his glory.
.@potch uses the XP wallpaper for maximum irony #mozfest pic.twitter.com/KBuMOtvkaq
— solendid (@supersole) October 25, 2014
Nobody shows up so we go to find lunch. The queue is immense so I give up and go grab “skinny burgers” without buns somewhere else.
Back there Potch proposes a hypothesis for the sake of argument: “Say there are going to be a bunch more people with Flame devices tomorrow. How do we get them started in five minutes?”
We write a script for what we’d say to people, as we reproduce the steps on my fully flashed phone. This is how you activate Developer mode. This is how you connect to the phone, etc.
Potch: “can I take screenshots with WebIDE?”
Sole: “Yes, yes you can!”
Potch: “Awesome!”
Potch takes screenshots for the guide.
People come to the WebIDE table and we show them how it works. They ask us questions, we answer. When we cannot answer, we show them how to file bugs. Please file bugs! We are not omniscient and cannot know what you are missing.
People leave the table. I leave to find some water as my throat is not happy with me. I stumble upon a bunch of people I know, I get delayed and somehow end up in the art room organised by Kat and Paula, and someone from the Tate explains me a process for creating remixed art with X-Ray and WebMaker: think of an art movement, find what is it that categorises that art movement. Then use google images to look for those elements in the net and use them in the initial website as replacements or as additions. Seems mechanical but the slight randomness of whatever google images can come up with looks funny. I don’t want to do this now and I have to come back to my table, but I get this idea about automating this.
Back to the MEGABOOTH Bobby says someone was looking for me. I end up speaking to someone from Mozilla whose face looked familiar but I did not know why. I had been to their office twice, that’s why!
They have a custom built version of Firefox OS that takes over the WiFi and replaces it with an adhoc mesh network. So they have a bunch of devices on the table who are able to discover nearby devices and establish this network without intermediaries. They’re also working on getting this to be a standard thing—or at least a thing that will be in the operating system, not on a custom build. Pretty cool!
We end up discussing WebRTC, latency, synchronisation of signals for distributed processing, and naive synchronisation signals using a very loud tone if all the devices are in the same place. Fantastic conversation!
I move to the flashing station. A bunch of people are helping to flash Firefox OS phones to the latest version. Somebody even tries his luck with resuscitating a ZTE “open” but it’s hard…
Jan Jongboom shows up. I say hi, he tells me about the latest developments in JanOS, and I feel compelled to high five him! Pro tip: never high five Jan. He’ll destroy your hand!
It’s about time for the speeches. Most important take out: this thing you have in your pocket is not a phone or a TV, it’s a computer and you can program it. Be creative!.
Announcement is made that people that contributed in an interestingly special way during the sessions and had got a glittery star sticker in their badge will be rewarded with a Flame phone, but please only take it if you can/want to help us make it better.
“For the sake of argument” becomes “a solid argument”. I see one of the flashing station volunteers rush in panic, smiling.
Here’s the guide Potch and me devised: Flame-what now?
Time for party, Max Ogden opens his Cat Umbrella. These are the true JS illuminati.
panopticat #mozfest @maxogden pic.twitter.com/yPo6ZWUPMs
— j d e n (@jden415) October 25, 2014
My throat is definitely not happy with me; I go home.
![]()
|
|
Daniel Stenberg: Pretending port zero is a normal one |
Speaking the TCP protocol, we communicate between “ports” in the local and remote ends. Each of these port fields are 16 bits in the protocol header so they can hold values between 0 – 65535. (IPv4 or IPv6 are the same here.) We usually do HTTP on port 80 and we do HTTPS on port 443 and so on. We can even play around and use them on various other custom ports when we feel like it.
But what about port 0 (zero) ? Sure, IANA lists the port as “reserved” for TCP and UDP but that’s just a rule in a list of ports, not actually a filter implemented by anyone.
In the actual TCP protocol port 0 is nothing special but just another number. Several people have told me “it is not supposed to be used” or that it is otherwise somehow considered bad to use this port over the internet. I don’t really know where this notion comes from more than that IANA listing.
Frank Gevaerts helped me perform some experiments with TCP port zero on Linux.
In the Berkeley sockets API widely used for doing TCP communications, port zero has a bit of a harder situation. Most of the functions and structs treat zero as just another number so there’s virtually no problem as a client to connect to this port using for example curl. See below for a printout from a test shot.
Running a TCP server on port 0 however, is tricky since the bind() function uses a zero in the port number to mean “pick a random one” (I can only assume this was a mistake done eons ago that can’t be changed). For this test, a little iptables trickery was run so that incoming traffic on TCP port 0 would be redirected to port 80 on the server machine, so that we didn’t have to patch any server code.
Entering a URL with port number zero to Firefox gets this message displayed:
This address uses a network port which is normally used for purposes other than Web browsing. Firefox has canceled the request for your protection.
… but Chrome accepts it and tries to use it as given.
The only little nit that remains when using curl against port 0 is that it seems glibc’s getpeername() assumes this is an illegal port number and refuses to work. I marked that line in curl’s output in red below just to highlight it for you. The actual source code with this check is here. This failure is not lethal for libcurl, it will just have slightly less info but will still continue to work. I claim this is a glibc bug.
$ curl -v http://10.0.0.1:0 -H "Host: 10.0.0.1"
* Rebuilt URL to: http://10.0.0.1:0/
* Hostname was NOT found in DNS cache
* Trying 10.0.0.1...
* getpeername() failed with errno 107: Transport endpoint is not connected
* Connected to 10.0.0.1 () port 0 (#0)
> GET / HTTP/1.1
> User-Agent: curl/7.38.1-DEV
> Accept: */*
> Host: 10.0.0.1
>
< HTTP/1.1 200 OK
< Date: Fri, 24 Oct 2014 09:08:02 GMT
< Server: Apache/2.4.10 (Debian)
< Last-Modified: Fri, 24 Oct 2014 08:48:34 GMT
< Content-Length: 22
< Content-Type: text/html
testpage
Why doing this experiment? Just for fun to to see if it worked.
(Discussion and comments on this post is also found at Reddit.)
http://daniel.haxx.se/blog/2014/10/25/pretending-port-zero-is-a-normal-one/
|
|
Christian Heilmann: The things browsers can do – SAE Alumni Conference, Berlin 2014 |
Two days ago I was in Berlin for a day to present at the SAE alumni Conference in Berlin, Germany. I knew nothing about SAE before I went there except for the ads I see on the Tube in London. I was pretty amazed to see just how big a community the alumni and chapters of this school are. And how proud they are.

My presentation The things browsers can do – go play with the web was a trial-run of a talk I will re-hash a bit at a few more conferences to come.
In essence, the thing I wanted to bring across is that HTML5 has now matured and is soon a recommendation.
And along the way we seem to have lost the excitement for it. One too many shiny HTML5 demo telling us we need a certain browser to enjoy the web. One more polyfill and library telling us without this extra overhead HTML5 isn’t ready. One more article telling us just how broken this one week old experimental implementation of the standard is. All of this left us tainted. We didn’t believe in HTML5 as a viable solution but something that is a compilation target instead.

In this talk I wanted to remind people just how much better browser support for the basic parts of HTML5 and friends is right now. And what you can do with it beyond impressive demos. No whizzbang examples here, but things you can use now. With a bit of effort you can even use them without pestering browsers that don’t support what you want to achieve. It is not about bringing modern functionality to all – browsers; it is about giving people things that work.
I recorded a screencast and put it on YouTube
All in all I enjoyed the convention and want to thank the organizers for having me and looking after me in an excellent fashion. It was refreshing to meet students who don’t have time to agonize which of the three task runners released this week to use. Instead who have to deliver something right now and in a working fashion. This makes a difference
|
|
Rizky Ariestiyansyah: Firefox OS App Days STPI |
For Firefox Student Ambassadors at Sekolah Tinggi Perpajakan Indonesia let’s make application together. Event Information : Speaker : Rizky Ariestiyansyah (RAL) Target audience : 35 Student There will be free Wifi and please...
The post Firefox OS App Days STPI appeared first on oonlab.
|
|
Peter Bengtsson: Go vs. Python |
tl;dr; It's not a competition! I'm just comparing Go and Python. So I can learn Go.
So recently I've been trying to learn Go. It's a modern programming language that started at Google but has very little to do with Google except that some of its core contributors are staff at Google.
The true strength of Go is that it's succinct and minimalistic and fast. It's not a scripting language like Python or Ruby but lots of people write scripts with it. It's growing in popularity with systems people but web developers like me have started to pay attention too.
The best way to learn a language is to do something with it. Build something. However, I don't disagree with that but I just felt I needed to cover the basics first and instead of taking notes I decided to learn by comparing it to something I know well, Python. I did this a zillion years ago when I tried to learn ZPT by comparing it DTML which I already knew well.
My free time is very limited so I'm taking things by small careful baby steps. I read through An Introduction to Programming in Go by Caleb Doxey in a couple of afternoons and then I decided to spend a couple of minutes every day with each chapter and implement something from that book and compare it to how you'd do it in Python.
I also added some slightly more full examples, Markdownserver which was fun because it showed that a simple Go HTTP server that does something can be 10 times faster than the Python equivalent.
Go is very unforgiving but I kinda like it. It's like Python but with pyflakes switched on all the time.
Go is much more verbose than Python. It just takes so much more lines to say the same thing.
Goroutines are awesome. They're a million times easier to grok than Python's myriad of similar solutions.
In Python, the ability to write to a list and it automatically expanding at will is awesome.
Go doesn't have the concept of "truthy" which I already miss. I.e. in Python you can convert a list type to boolean and the language does this automatically by checking if the length of the list is 0.
Go gives you very few choices (e.g. there's only one type of loop and it's the for loop) but you often have a choice to pass a copy of an object or to pass a pointer. Those are different things but sometimes I feel like the computer could/should figure it out for me.
I love the little defer thing which means I can put "things to do when you're done" right underneath the thing I'm doing. In Python you get these try: ...20 lines... finally: ...now it's over... things.
The coding style rules are very different but in Go it's a no brainer because you basically don't have any choices. I like that. You just have to remember to use gofmt.
Everything about Go and Go tools follow the strict UNIX pattern to not output anything unless things go bad. I like that.
godoc.org is awesome. If you ever wonder how a built in package works you can just type it in after godoc.org like this godoc.org/math for example.
You don't have to compile your Go code to run it. You can simply type go run mycode.go it automatically compiles it and then runs it. And it's super fast.
go get can take a url like github.com/russross/blackfriday and just install it. No PyPI equivalent. But it scares me to depend on peoples master branches in GitHub. What if master is very different when I go get something locally compared to when I run go get weeks/months later on the server?
|
|
Mic Berman: What's your daily focus practice? |
I have a daily and weekly practice to support and nuture myself - one of my core values is discipline and doing what I say. This for me is how I show up with integrity both for myself and the commitments I make to others. So, I enjoy evolving and living my practice
Each day I meditate, as close to waking and certainly before my first meeting. I get clear on what is coming up that day and how I want to show up for myself and the people I’m spending time with. I decide how I want to be, for example, is being joyful and listening to my intuition the most important way for today, or curiosity, humour?
I use mindful breathing many times in a day - particularly when I’m feeling strong emotions, maybe because I’ve just come from a fierce conversation or a situation that warrants some deep empathy - simply breath gets me grounded and clear before my next meeting or activity.
Exercise - feeling my body, connecting to my physical being and what’s going on for me. Maybe I’m relying too much on a coffee buzz and wanting an energy boost - listening to my cues and taking care throughout the day. How much water have I had? etc As well as honouring my value around fitness and health.
I also write - my daily journal and always moving a blog post or article forward. And most importantly - mindfulness, being fully present in each activity. Several years ago I broke my right foot and ‘lost’ my ability to multi-task in the healing process. It was a huge gift ultimately - choosing to only do one thing at a time. To have all of my mind and body focused on the thing I am doing or person i am talking with and nothing else. What a beautiful way to be, to honour those around me and the purpose or agenda of the company I’m working for. Weekly, I enjoy a mindful Friday night dinner with my family and turn off all technology to Saturday night and on Sunday's I reflect on my past week and prepare for my next - what worked, what didn't, what's important, what's not. etc.
Joy to you in finding a practice that works :)
http://michalberman.typepad.com/my_weblog/2014/10/whats-your-daily-focus-practice.html
|
|
Tarek Ziad'e: Web Application Firewall |
Web Application Firewall (WAF) applied to HTTP web services is an interesting concept.
It basically consists of extracting from a web app a set of rules that describes how the endpoints should be used. Then a Firewall proxy can enforce those rules on incoming requests.
Le't say you have a search api where you want to validate that:
Such a rule could look like this:
"/search": {
"GET": {
"parameters": {
"before": {
"validation":"datetime",
"required": false
}
},
"limits": {
"rates": [
{
"seconds": 60,
"hits": 10,
"match": "header:Authorization AND header:User-Agent or remote_addr"
}
]
}
}
}
Where the rate limiter will use the Authorization and the User-Agent header to uniquely identify a user, or the remote IP address if those fields are not present.
Note
We've played a little bit around request validation with Cornice, where you can programmatically describe schemas to validate incoming requests, and the ultimate goal is to make Cornice generate those rules in a spec file independantly from the code.
I've started a new project around this with two colleagues at Mozilla (Julien & Benson), called Videur. We're defining a very basic JSON spec to describe rules on incoming requests:
https://github.com/mozilla/videur/blob/master/spec/VAS.rst
What makes it a very exciting project is that our reference implementation for the proxy is based on NGinx and Lua.
I've written a couple of Lua scripts that get loaded in Nginx, and our Nginx configuration roughly looks like this for any project that has this API spec file:
http {
server {
listen 80;
set $spec_url "http://127.0.0.1:8282/api-specs";
access_by_lua_file "videur.lua";
}
}
Instead of manually defining all the proxy rules to point to our app, we're simply pointing the spec file that contains the description of the endpoints and use the lua script to dynamically build all the proxying.
Videur will then make sure incoming requests comply with the rules before passing them to the backend server.
One extra benefit is that Videur will reject any request that's not described in the spec file. This implicit white listing is in itself a good way to avoid improper calls on our stacks.
Last but not least, Lua in Nginx is freaking robust and fast. I am still amazed by the power of this combo. Kudos to Yichun Zhang for the amazing work he's done there.
Videur is being deployed on one project at Mozilla to see how it goes, and if that works well, we'll move forward to more projects and add more features.
And thanks to NginxTest our Lua script are fully tested.
|
|
Jess Klein: Hive Labs at the Mozilla Festival: Building an Ecosystem for Innovation |




http://jessicaklein.blogspot.com/2014/10/hive-labs-at-mozilla-festival-building.html
|
|
Yunier Jos'e Sosa V'azquez: Firefox incorpora OpenH.264 y m'as seguridad |
Sin darnos cuenta ya est'a con nosotros una nueva versi'on de tu navegador favorito. En esta ocasi'on disfrutar'as de interesantes caracter'isticas como la implementaci'on de c'odigo abierto del c'odec H.264, m'as seguridad y en el caso de los usuarios de Windows, gozar'an de un mejor rendimiento.
La misi'on de Mozilla plantea apoyar y defender la web abierta, cosa que es muy dif'icil debido al reclamo de los usuarios en reproducir contenido en formatos cerrados, por lo que Mozilla debe pagar a sus propietarios la inclusi'on del c'odigo en Firefox. Poco a poco se fueron dando pasos de avance, primero con la posibilidad de usar los c'odecs instalados (Windows) y despu'es si ten'iamos instalado el adecuado plugin de Gstreamer (Linux). Ahora se a~nade el soporte a OpenH264 y proporciona seguridad al navegador pues se ejecuta en sandbox.
La experiencia de b'usqueda desde la barra de direcciones ha recibido mejoras. Si intentas ir a un sitio que no es real, Firefox verifica si existe y alerta si deseas ir all'i o realizar una b'usqueda con el motor elegido por ti. Tambi'en desde la p'agina de inicio (about:home) y nueva pesta~na (about:newtab) se mostrar'an sugerencias de b'usqueda mientras escribes en los campos de b'usqueda.
Una nueva Pol'itica de Seguridad sobre el Contendio (CSP) har'a m'as seguro al navegador y proteger'a mejor tu informaci'on almacenada en tu computadora. Adem'as, se ha dado soporte para conectarse a servidores proxy HTTP a trav'es de HTTPS.
Mientras tanto, los usuarios de Windows recibir'an nuevos cambios en la arquitectura de Firefox que propician un mejor rendimiento pues ahora varias tareas se separan del proceso principal. M'as adelante veremos muchos m'as radicales con respecto a la arquitectura.
Firefox ahora habla azerbaiyano, se mejor'o la seguridad al restaurar una sesi'on y se han a~nadido muchos cambios para desarrolladores.
Si deseas conocer m'as, puedes leer las notas de lanzamiento.
Puedes obtener esta versi'on desde nuestra zona de Descargas en espa~nol e ingl'es para Linux, Mac, Windows y Android. Recuerda que para navegar a trav'es de servidores proxy debes modificar la preferencia network.negotiate-auth.allow-insecure-ntlm-v1 a true desde about:config.
http://firefoxmania.uci.cu/firefox-incorpora-videollamadas-y-mas-seguridad/
|
|
Mozilla Reps Community: Reps Weekly Call – October 23th 2014 |
Last Thursday we had our regular weekly call about the Reps program, where we talk about what’s going on in the program and what Reps have been doing during the last week.

https://air.mozilla.org/reps-weekly-20141023/
Don’t forget to comment about this call on Discourse and we hope to see you next week!
https://blog.mozilla.org/mozillareps/2014/10/24/reps-weekly-call-october-23th-2014/
|
|