Mozilla Addons Blog: Extensions in Firefox 80 |
Firefox 80 includes some minor improvements for developers using the downloads.download API:
saveAs option, the save dialog now shows a more specific file type filter appropriate for the file type being saved.Special thanks goes to Harsh Arora and Dave for their contributions to the downloads API. This release was also made possible by a number of other folks from within Mozilla for diligent behind-the-scenes work to improve and maintain WebExtensions in Firefox.
The post Extensions in Firefox 80 appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2020/08/25/extensions-in-firefox-80/
|
|
The Mozilla Blog: Fast, personalized and private by design on all platforms: introducing a new Firefox for Android experience |
Big news for mobile: as of today, Firefox for Android users in Europe will find an entirely redesigned interface and a fast and secure mobile browser that was overhauled down to the core. Users in North America will receive the update on August 27. Like we did with our “Firefox Quantum” desktop browser revamp, we’re calling this release “Firefox Daylight” as it marks a new beginning for our Android browser. Included with this new mobile experience are lots of innovative features, an improved user experience with new customization options, and some massive changes under the hood. And we couldn’t be more excited to share it.
We have made some very significant changes that could revolutionize mobile browsing:
Privacy & security
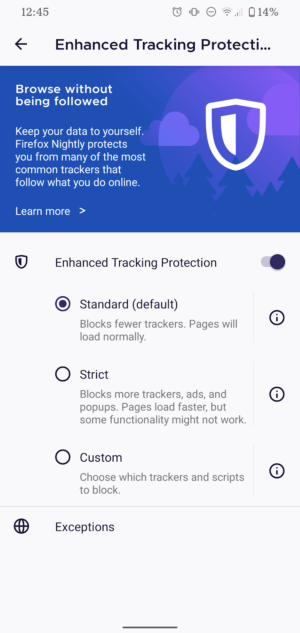
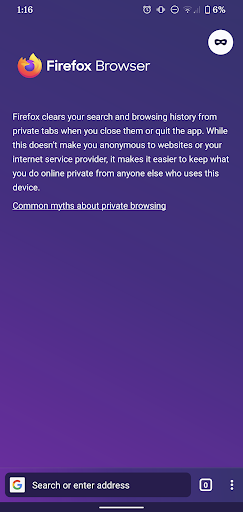
Enhanced Tracking Protection automatically blocks many known third-party trackers, by default, in order to improve user privacy online. Private Mode adds another layer for better privacy on device level.
Appearance & productivity
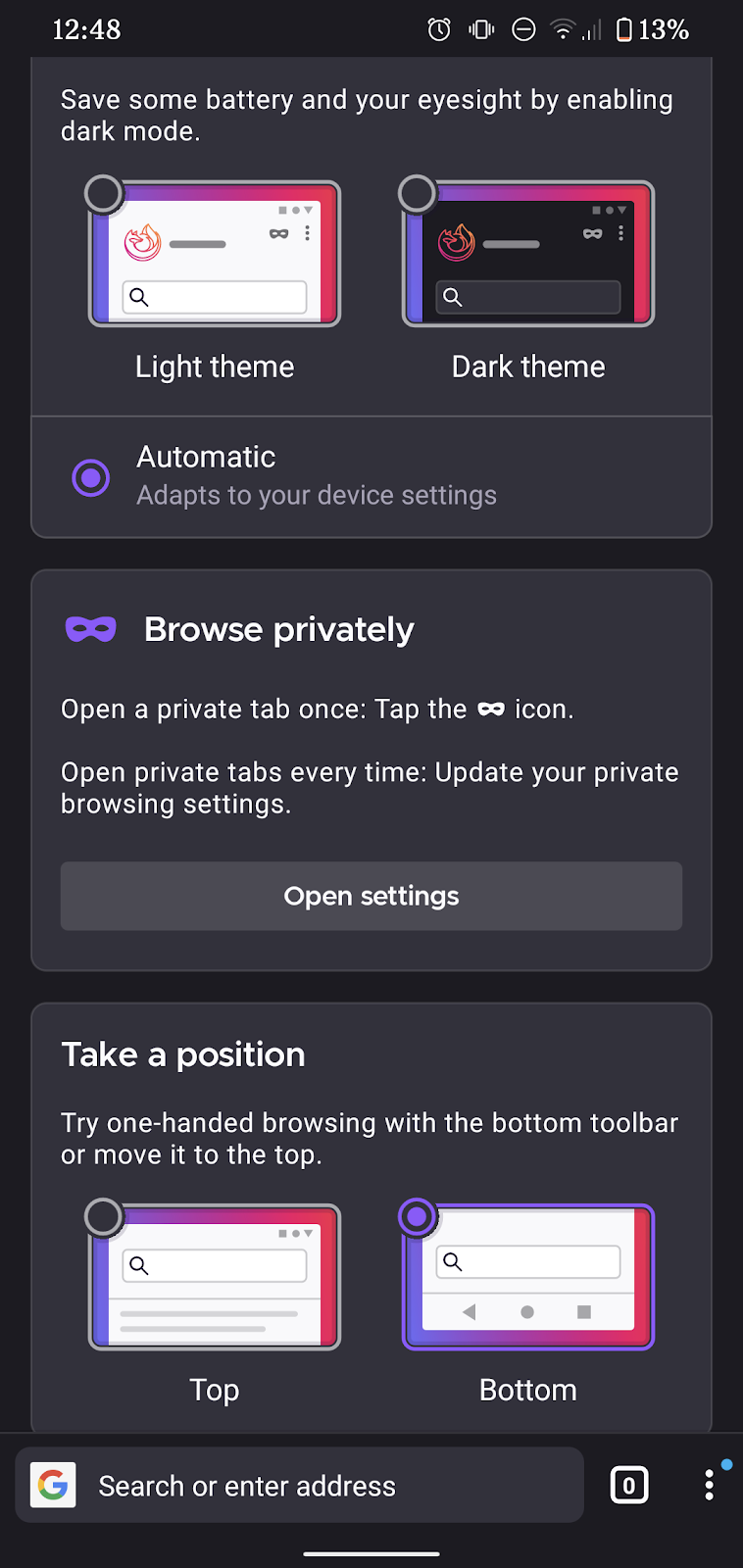
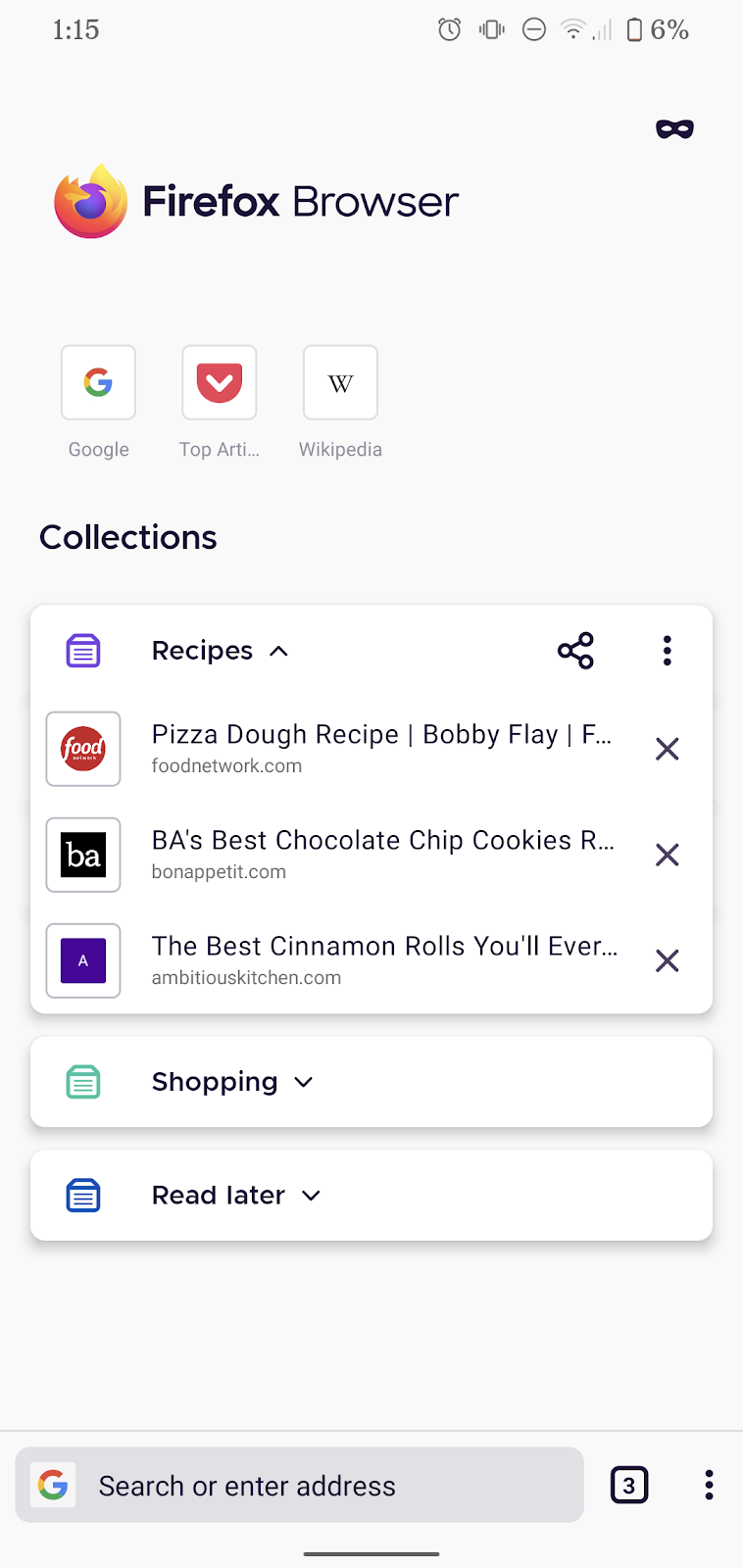
Productivity is key on mobile. That’s why the new Firefox for Android comes with an adjustable URL bar and a convenient solution to organize bookmarks: Collections.
Firefox users love add-ons! Our overhauled Android browser therefore comes with the top add-ons for enhanced privacy and user experience from our Recommended Extensions program.
The improvements in Firefox for Android don’t just stop here: they even go way beyond the surface as Firefox for Android is now based on GeckoView, Mozilla’s own mobile browser engine. What does that mean for users?
Completely overhauling an existing product is a complex process that comes with a high potential for pitfalls. In order to avoid them and create a browsing experience users would truly appreciate, we looked closely at existing features and functionalities users love and we tested – a lot – to make sure we’d keep the promise to create a whole new browsing experience on Android.
We’re proud to say that we provided Firefox for Android with an entirely new shape and foundation and we’re equally happy to share the result with Android users now. Here’s how to get our overhauled browser:
Make sure to let us know what you think about the overhauled browsing experience with Firefox for Android and stay tuned for more news in the upcoming months!
The post Fast, personalized and private by design on all platforms: introducing a new Firefox for Android experience appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2020/08/25/introducing-a-new-firefox-for-android-experience/
|
|
Mozilla Addons Blog: Introducing a scalable add-ons blocklist |
When we become aware of add-ons that go against user expectations or risk user privacy and security, we take steps to block them from running in Firefox using a mechanism called the add-ons blocklist. In Firefox 79, we revamped the blocklist to be more scalable in order to help keep users safe as the add-ons ecosystem continues to grow.
One of the constraints of the previous blocklist was that it required parsing of a large number of regular expressions. Each Firefox instance would need to check if any of its user’s installed add-ons matched any of the regular expressions in the blocklist. As the number of blocks increased, the overhead of loading and parsing the blocklist in Firefox became greater. In late 2019, we began looking into a more efficient way for Firefox to determine if an add-on is blocked.
After investigating potential solutions, we decided the new add-ons blocklist would be powered by a data structure created from cascading bloom filters, which provides an efficient way to store millions of records using minimal space.
Using a single bloom filter as a data structure would have carried a risk of false positives when checking if an add-on was blocked. To prevent this, the new add-on blocklist uses a set of filter layers to eliminate false-positives using the data from addons.mozilla.org (AMO) as a single source of truth.
The same underlying technology used here was first used for Certificate Revocation in CRLite. Adapting this approach for add-ons provided an important head-start for the blocklist project.
To reduce the need to ship entire blocklists each time blocks are added, an intermediate data structure is created to record new blocks. These “stash-lists” are queried first, before the main blocklist database is checked. Once the stash-lists grow to a certain size they are automatically folded into a newly generated cascading bloom filter database.
We are currently evaluating additional optimizations in order to further minimize the size of the blocklist for use on Fenix, the next major release of Firefox for Android.
Firefox Extended Support Release (ESR) is a Firefox distribution that is focused on feature stability. It gets a major feature update about once per year and only critical security updates in between. When we first identified the need to move the blocklist to a cascading bloom filter in late 2019, we knew we had to land the new blocklist for ESR 78 or we would risk having to maintain two different blocklists in parallel until the next ESR cycle.
In order to land this feature in time for Firefox 78, which was slated to hit the Nightly pre-release channel in May, we needed to coordinate efforts between our add-ons server, add-ons frontend and Firefox Add-ons engineering teams, as well the teams in charge of hosting the blocklist and the still-in-development bloom filters library. We also needed to make sure this new solution cleared all security reviews and QA, as well as coordinate its rollout with Release Engineering, and make sure we had enough data to measure its success.
Our leadership encouraged us to land the new blocklist in Firefox 78 and ensured that we would get the cross-team support necessary to achieve it. Having all these hurdles cleared was very exciting and nerve-wracking at the same time, since now our main challenge was to deliver this huge project on time. While a late-breaking bug prevented us from landing the new blocklist in Firefox 78, we have been able to gradually roll it out with the Firefox 79 release and will enable it in an ESR 78 update.
This was an ambitious project, as it had many moving parts that required the support of many teams across Mozilla. During the project Crypto Engineering, Kinto, Security, Release Engineering, QA and data teams all made significant contributions to enable the Add-ons Engineering team to ship this feature in five months.
None of this would have been possible without the help and support of the following people: Simon Bennetts, Shane Caraveo, Alexandru Cornestean, Shell Escalante, Luca Greco, Mark Goodwin, Joe Hildebrand, JC Jones, Dana Keeler, Gijs Kruitbosch, Thyla van der Merwe, Alexandra Moga, Mathieu Pillard, Victor Porof, Amy Tsay, Ryan VanderMeulen, Dan Veditz, Julien Vehent, Eric Smyth, Jorge Villalobos, Andreas Wagner, Andrew Williamson and Rob Wu.
The post Introducing a scalable add-ons blocklist appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2020/08/24/introducing-a-scalable-add-ons-blocklist/
|
|
Nick Fitzgerald: Writing a Test Case Generator for a Programming Language |
|
|
Cameron Kaiser: TenFourFox FPR26 available |
For FPR27 we will be switching over the EV and TLS roots that we usually do for an ESR switch, and I would like to make a first pass at "sticky Reader mode" as well. More soon.
http://tenfourfox.blogspot.com/2020/08/tenfourfox-fpr26-available.html
|
|
Karl Dubost: Khmer Line Breaking |
I'm not an expert in Khmer language, it's just me stumbling on a webcompat issue and trying to make sense of it.
The Khmer language, apart of being the official language of Cambodia (South-East Asia), is spoken by some people in Thailand and Vietnam.
We receive a webcompat issue recently where a long Khmer line on a mobile device was not wrapping hence breaking the layout of the site. Jonathan Kew helped me figure out if the issue was with the fonts or with the browser.
I don't think this is about fonts, it's that we don't have Khmer line-breaking support on Android. Line-breaking for SEAsian languages that are written without word spaces (e.g. Thai, Lao, Khmer) is based on calling an operating system API to find potential word-break positions. Hence the results are platform-dependent. Unfortunately on Android we don't have any such API to call, and so we don't find break positions within long runs of text. We have an internal line-breaker for Thai (and recently implemented some basic support for Tibetan), but nothing for Khmer.
So that intrigued me the "find potential word-break positions".
In western language like French and English, there are breaking opportunities, usually spaces in between words. So for example,
a sentence can break like this
because there are spaces in between words, but in Khmer language, there are no space in between words inside a phrase.
Thai, Lao, and Khmer are languages that are written with no spaces between words. Spaces do occur, but they serve as phrase delimiters, rather than word delimiters. However, when Thai, Lao, or Khmer text reaches the end of a line, the expectation is that text is wrapped a word at a time.
So how do you discover the word boudaries?
Most applications do this by using dictionary lookup. It’s not 100% perfect, and authors may need to adjust things from time to time.
It means you would like to have a better rendering in a browser, you need to either include a dictionary of words inside the browser or call a dictionary loaded on the system. And there are subtleties for compound words.
How is Khmer line-breaking handled on the Web? is trying to understand what is the status.
But let's go back to Gecko on mobile.
I found this reference in gecko source code for line breaking for these specific languages in LineBreaker.h
I opened an issue on bugzilla so we can try to implement line breaking for Khmer language. I was wondering if it would be a simple modification, but Makoto Kato jumped in and commented
Old Android doesn't have native line break API, but Android 24+ can use ICU from Java (
android.icu.text.BreakIterator). Since we still support Android 5+ on Fenix, so not easy.
Chromium in Issue 136148: Add Khmer and Lao Line-Breaking layout tests has some tests, that might help if Mozilla decides to solve this issue.
I don't know if there's a big usage of Firefox in khmer but definitely on mobile that kind of bugs would have a strong impact on the usability of the browser. It is important to report bugs, it helps to improve the platform. It shows also how challenging it can be to implement a browser with all the diversity and variability of context.
A small report might benefit a lot of people.
Otsukare!
|
|
Daniel Stenberg: curl ping pong |
Pretend that a ping pong ball represents a single curl installation somewhere in the world. Here’s a picture of one to help you get an image in your head.

Moving on with this game, you get one ball for every curl installation out there and your task is to put all those balls on top of each other. Okay, that’s hard to balance but for this game we can also pretend you have glue enough to make sure they stay like this. A tower of ping pong balls.
You soon realize that this is quite a lot of work. The balls keep pouring in.
If you manage to do this construction work non-stop at the rate of one ball per second (which seems like it maybe would be hard after a while but let’s not make that ruin the fun), it will keep you occupied for no less than a little bit over 317 years. (That also assumes the number of curl installations doesn’t grow significantly in the mean time.)
That’s a lot of ping pong balls. Ten billion of them, give or take.
Assuming you have friends to help you build this tower you can probably build it faster. If you can instead sustain a rate of 1000 balls per second, you’d be done in less than four months.
One official ping pong ball weighs 2.7 grams. It makes a total of 27,000 tonnes of balls. That’s quite some pressure on such a small surface. You better make sure to build the tower on something solid. The heaviest statue in the world is the Statue of Liberty in New York, clocking in at 24,500 tonnes.
But wait, the biggest ping pong ball manufacturer in the world (Double Happiness, in China – yes it’s really called that) “only” produces 200 million balls per year. It would take them 50 years to make balls for this tower. You clearly need to engage many factories.
You can get 100 balls for roughly 10 USD on Amazon right now. Maybe not the best balls to play with, but I think they might still suit this game. That’s a billion US dollars for the balls. Maybe you’d get a discount, but you’d also drastically increase demand, so…
A tower of ten billion ping pong balls, how tall is that? It would reach the moon.
The diameter of a ping pong ball is 40 mm (it was officially increased from 38 mm back in 2000). This makes 25 balls per meter of tower. Conveniently aligned for our game here.
10,000,000,000 balls / 25 balls per meter = 400,000,000 meters. 400,000 km.
Distance from earth to moon? 384,400 km. The fully built tower is actually a little taller than the average distance to the moon! Here’s another picture to help you get an image in your head. (Although this image is not drawn to scale!)

A challenge will of course be to keep this very thin tower steady when that tall. Winds and low temperatures should be challenging. And there’s the additional risk of airplanes or satellites colliding with it. Or even just birds interfering in the lower altitudes. I suspect there are also laws prohibiting such a construction.
Come to think of it. This was just a mind game. Forget about it now. Let’s move on with our lives instead. We have better things to do.
|
|
Mozilla Accessibility: Early Mac Firefox VoiceOver Support |
We’ve made some great early progress with Firefox VoiceOver support on macOS and we’d love it if web developers could give it a test run and provide feedback on any issues you run into while evaluating web page accessibility. Please grab Firefox Dev Edition 80 and try it out. Thanks.
The post Early Mac Firefox VoiceOver Support appeared first on Mozilla Accessibility.
https://blog.mozilla.org/accessibility/early-mac-firefox-voiceover-support/
|
|
The Mozilla Blog: A look at password security, Part IV: WebAuthn |
|
|
David Teller: Why Did Mozilla Remove XUL Add-ons? |
TL;DR: Firefox used to have a great extension mechanism based on the XUL and XPCOM. This mechanism served us well for a long time. However, it came at an ever-growing cost in terms of maintenance for both Firefox developers and add-on developers. On one side, this growing cost progressively killed any effort to make Firefox secure, fast or to try new things. On the other side, this growing cost progressively killed the community of add-on developers. Eventually, after spending years trying to protect this old add-on mechanism, Mozilla made the hard choice of removing this extension mechanism and replacing this with the less powerful but much more maintainable WebExtensions API. Thanks to this choice, Firefox developers can once again make the necessary changes to improve security, stability or speed.
During the past few days, I’ve been chatting with Firefox users, trying to separate fact from rumor regarding the consequences of the August 2020 Mozilla layoffs. One of the topics that came back a few times was the removal of XUL-based add-ons during the move to Firefox Quantum. I was very surprised to see that, years after it happened, some community members still felt hurt by this choice.
And then, as someone pointed out on reddit, I realized that we still haven’t taken the time to explain in-depth why we had no choice but to remove XUL-based add-ons.
So, if you’re ready for a dive into some of the internals of add-ons and Gecko, I’d like to take this opportunity to try and give you a bit more detail.
https://yoric.github.io/post/why-did-mozilla-remove-xul-addons/
|
|
Mozilla Privacy Blog: Practicing Lean Data and Defending “Lean Data” |
At Mozilla, we put privacy first. We do this in our own products with features like tracking protection. We also promote privacy in our public advocacy. A key feature of our privacy work is a commitment to reducing the amount of user data that is collected in the first place. Focusing on the data you really need lowers risk and promotes trust. Our Lean Data Practices page describes this framework and includes tools and tips for staying lean. For years, our legal and policy teams have held workshops around the world, advising businesses on how they can use lean data practices to reduce their data footprint and improve the privacy of their products and services.
Mozilla is not the only advocate for lean data. Many, many, many, many, many, many, many, many, many others use the term “lean data” to refer to the principle of minimizing data collection. Given this, we were very surprised to receive a demand letter from lawyers representing LeanData, Inc. claiming that Mozilla’s Lean Data Practices page infringes the company’s supposed trademark rights. We have responded to this letter to stand up for everyone’s right to use the words “lean data” in digital advocacy.
Our response to LeanData explains that it cannot claim ownership of a descriptive term such as “lean data.” In fact, when we investigated its trademark filings we discovered that the US Patent and Trademark Office (USPTO) had repeatedly rejected the company’s attempts to register a wordmark that covered the term. The USPTO has cited numerous sources, including the very Mozilla page LeanData accused of infringing, as evidence that “lean data” is descriptive. Also, the registration for LeanData’s logo cited in the company’s letter to Mozilla was recently cancelled (and it wouldn’t cover the words “lean data” in any event). LeanData’s demand is without merit.
In a follow-up letter, LeanData, Inc. acknowledged that it does not have any currently registered marks on “lean data.” LeanData’s lawyer suggested, however, the company will continue to pursue its application for a “LeanData” wordmark. We believe the USPTO should, and will, continue to reject this application. Important public policy discussions must be free from intellectual property overreach. Scholars, engineers, and commentators should be allowed to use a descriptive term like “lean data” to describe a key digital privacy principle.
The post Practicing Lean Data and Defending “Lean Data” appeared first on Open Policy & Advocacy.
https://blog.mozilla.org/netpolicy/2020/08/20/practicing-lean-data-and-defending-lean-data/
|
|
Daniel Stenberg: curl 7.72.0 – more compression |
Welcome to another release, seven weeks since we did the patch release 7.71.1. This time we add a few new subtle features so the minor number is bumped yet again. Details below.
the 194th release
3 changes
49 days (total: 8,188)
100 bug fixes (total: 6,327)
134 commits (total: 26,077)
0 new public libcurl function (total: 82)
0 new curl_easy_setopt() option (total: 277)
0 new curl command line option (total: 232)
52 contributors, 29 new (total: 2,239)
30 authors, 14 new (total: 819)
1 security fix (total: 95)
500 USD paid in Bug Bounties (total: 2,800 USD)
CVE-2020-8132: “libcurl: wrong connect-only connection”. This a rather obscure issue that we’ve graded severity Low. There’s a risk that an application that’s using libcurl to do connect-only connections (ie not doing the full transfer with libcurl, just using it to setup the connection) accidentally sends or reads data over the wrong connection, as libcurl could mix them up internally in rare circumstances.
We rewarded 500 USD to the reporter of this security flaw.
This is the first curl release that supports zstd compression. zstd is a yet another way to compressed content data over HTTP and if curl supports it, it can then automatically decompress it on the fly. zstd is designed to compress better and faster than gzip and if I understand the numbers shown, it is less CPU intensive than brotli. In pure practical terms, curl will ask for this compression in addition to the other supported algorithms if you tell curl you want compressed content. zstd is still not widely supported by browsers.
For clients that supports HTTP/2 and server push, libcurl now allows the controlling callback (“should this server push be accepted?”) to return an error code that will tear down the entire connection.
There’s a new option for curl_easy_getinfo called CURLINFO_EFFECTIVE_METHOD that lets the application ask libcurl what the most resent request method used was. This is relevant in case you’ve allowed libcurl to follow redirects for a POST where it might have changed the method as a result of what particular HTTP response the server responded with.
Here are a collection of bug-fixes I think stood out a little extra in this cycle.
I just love the fact that someone actually tried to build curl for Windows XP, noticed it failed in doing so and provided the fix to make it work again…
There were some minor mistakes in the code that checks if the file you get when you use -J already existed. That logic has now been tightened. Presumably not a single person ever actually had an actual problem with that before either, but…
We landed an FTPS regression in 7.71.1 where we accidentally did the wrong function call when closing down the data connection. It could make consecutive FTPS transfers terribly slow.
We had another regression reported where HTTP trailers when using HTTP/2 really didn’t work. Obviously not a terribly well-used feature…
Another little HTTP/2 polish: make sure that connections that have received a GOAWAY is marked for closure so that it gets closed sooner rather than later as no new streams can be created on it anyway!
“connect-only connections” are those where the application asks libcurl to just connect to the site and not actually perform any request or transfer. Previously when that was done, the connection would remain in the multi handle until it was closed and it couldn’t be reused. Starting now, when the easy handle that “owns” the connection is removed from the multi handle the associated connect-only connection will be closed and removed. This is just sensible.
ngtcp2 is a QUIC library and is used in one of the backends curl supports for HTTP/3. HTTP/3 in curl is still marked experimental and we aim at keeping the latest curl code work with the latest QUIC libraries – since they’re both still “pre-beta” versions and don’t do releases yet. So, if you find that the HTTP/3 build fails, make sure you use the latest git commits of all the h3 components!
If curl would call the QUIC disconnect function twice, using the quiche backend, it would crash hard. Would happen if you tried to connect to a host that didn’t listen to the UDP port at all for example…
We recently fixed a bug for storing the HTTP method internally and due to refactored code, the behavior of unsetting the CURLOPT_NOBODY option changed slightly. There was never any promise as to what exactly that would do – but apparently several users had already drawn conclusions and written applications based on that. We’ve now adapted somewhat to that presumption on undocumented behavior by documenting better what it should do and by putting back some code to back it up…
Yet another HTTP/2 fix. In a recent release we fixed a problem that materialized when libcurl received a GOAWAY on a stream for a HTTP/2 connection, and it would then instead try a new connection to issue the request over and that too would get a GOAWAY. libcurl will do these retry attempts up to 5 times but due to a mistake, the counter was stored wrongly and was cleared when each new connection was made…
libcurl supports two ways of setting the URL to work with. The good old string to the entire URL and the option CURLOPT_CURLU where you provide the handle to an already parsed URL. The latter is of course a much newer option and it turns out that libcurl didn’t properly handle redirects when the URL was set with this latter option!
There are already several Pull Requests waiting in line to get merged that add new features and functionality. We expect the next release to become 7.73.0 and ship on October 14, 2020. Fingers crossed.
https://daniel.haxx.se/blog/2020/08/19/curl-7-72-0-more-compression/
|
|
Eric Shepherd: Moz-eying along… |
By now, most folks have heard about Mozilla’s recent layoff of about 250 of its employees. It’s also fairly well known that the entire MDN Web Docs content team was let go, aside from our direct manager, the eminently-qualified and truly excellent Chris Mills. That, sadly, includes myself.
Yes, after nearly 14 1/2 years writing web developer documentation for MDN, I am moving on to new things. I don’t know yet what those new things are, but the options are plentiful and I’m certain I’ll land somewhere great soon.
But it’s weird. I’ve spent over half my career as a technical writer at Mozilla. When I started, we were near the end of documenting Firefox 1.5, whose feature features (sorry) were the exciting new element and CSS improvements including CSS columns. A couple of weeks ago, I finished writing my portions of the documentation for Firefox 40, for which I wrote about changes to WebRTC and Web Audio, as well as the Media Source API.
Indeed, in my winding-down days, when I’m no longer assigned specific work to do, I find myself furiously writing as much new material as I can for the WebRTC documentation, because I think it’s important, and there are just enough holes in the docs as it stands to make life frustrating for newcomers to the technology. I won’t be able to fix them all before I’m gone, but I’ll do what I can.
Because that’s how I roll. I love writing developer documentation, especially for technologies for which no documentation yet exists. It’s what I do. Digging into a technology and coding and debugging and re-coding (and cursing and swearing a bit, perhaps) until I have working code that ensures that I understand what I’m going to write about is a blast! Using that code, and what I learned while creating it, to create documentation to help developers avoid at least some of the debugging (and cursing and swearing a bit, perhaps) that I had to go through.
The thrill of creation is only outweighed by the deep-down satisfaction that comes from knowing that what you’ve produced will help others do what they need to do faster, more efficiently, and—possibly most importantly—better.
That’s the dream.
Anyway, I will miss Mozilla terribly; it was a truly wonderful place to work. I’ll miss working on MDN content every day; it was my life from the day I joined as the sole full-time writer, through the hiring and departure of several other writers, until the end.
First, let me thank the volunteer community of writers, editors, and translators who’ve worked on MDN in the past—and who I hope will continue to do so going forward. We need you more than ever now!

Me, if I’ve forgotten to mention anyone.
Then there are our staff writers, both past and present. Jean-Yves Perrier left the team a long while ago, but he was a fantastic colleague and a great guy. J'er'emie Pattonier was a blast to work with and a great asset to our team. Paul Rouget, too, was a great contributor and a great person to work with (until he moved on to engineering roles; then he became a great person to get key information from, because he was so easy to engage with).
Chris Mills, our amazing documentation team manager and fabulous writer in his own right, will be remaining at Mozilla, and hopefully will find ways to make MDN stay on top of the heap. I’m rooting for you, Chris!
Florian Scholz, our content lead and the youngest member of our team (a combination that tells you how amazing he is) was a fantastic contributor from his school days onward, and I was thrilled to have him join our staff. I’m exceptionally proud of his success at MDN.
Janet Swisher, who managed our community as well as writing documentation, may have been the rock of our team. She’s been a steadfast and reliable colleague and a fantastic source of advice and ideas. She kept us on track a lot of times when we could have veered sharply off the rails and over a cliff.
Will Bamberg has never been afraid to take on a big project. From developer tools to browser extensions to designing our new documentation platform, I’ve always been amazed by his focus and his ability to do big things well.
Thank you all for the hard work, the brilliant ideas, and the devotion to making the web better by teaching developers to create better sites. We made the world a little better for everyone in it, and I’m very, very proud of all of us.
Farewell, my friends.
|
|
Mozilla Attack & Defense: Bug Bounty Program Updates: Adding (another) New Class of Bounties |
Recently we increased bounty payouts and also included a Static Analysis component in our bounty program; and we are expanding our bug bounty program even further with a new Exploit Mitigation Bounty. Within Firefox, we have introduced vital security features, exploit mitigations, and defense in depth measures. If you are able to bypass one of these measures, even if you are operating from privileged access within the browser, you are now eligible for a bounty even if before it would not have qualified.
While previously, bypassing a mitigation in a testing scenario – such as directly testing the HTML Sanitizer – would be classified as a sec-low or sec-moderate; it will now be eligible for a bounty equivalent to a sec-high. Additionally, if the vulnerability is triggerable without privileged access, this would count as both a regular security vulnerability eligible for a bounty and a mitigation bypass, earning a bonus payout. We have an established list of the mitigations we consider in scope for this bounty, they and more details are available on the Client Bug Bounty page.
Finally, based on our experience with our Nightly channel, we are making a change to how we handle recent regressions. Occasionally we will introduce a new issue that is immediately noticed. These breaking changes are frequently caught by multiple systems including Mozilla’s internal fuzzing efforts, crash reports, internal Nightly dogfooding, and telemetry – and also sometimes by external bounty participants performing fuzzing on Nightly.
We still want to encourage bounty hunting on Nightly – even if other bounty programs don’t – but issuing bounties for obvious transient issues we find ourselves is not improving the state of Firefox security or encouraging novel fuzzer improvements. While some bounty programs won’t issue a bounty if an issue is also found internally at all, we will continue to do so. However, we are implementing a four-day grace period beginning when a code change that exposes a vulnerability is checked-in to the primary repository for that application. If the issue is identified internally within this grace period it will be ineligible for a bounty. After four days, if no one working on the project has reported the issue it is eligible.
We’re excited to expand our program by providing more specific targets of Firefox internals we would appreciate attention to – keep watch here and on Twitter for more tips, tricks, and targets for Firefox bounty hunting!
https://blog.mozilla.org/attack-and-defense/2020/08/18/exploit-mitigation-bounty/
|
|
The Rust Programming Language Blog: Laying the foundation for Rust's future |
The Rust project was originally conceived in 2010 (depending on how you count, you might even say 2006!) as a Mozilla Research project, but the long term goal has always been to establish Rust as a self-sustaining project. In 2015, with the launch of Rust 1.0, Rust established its project direction and governance independent of the Mozilla organization. Since then, Rust has been operating as an autonomous organization, with Mozilla being a prominent and consistent financial and legal sponsor.
Mozilla was, and continues to be, excited by the opportunity for the Rust language to be widely used, and supported, by many companies throughout the industry. Today, many companies, both large and small, are using Rust in more diverse and more significant ways, from Amazon’s Firecracker, to Fastly’s Lucet, to critical services that power Discord, Cloudflare, Figma, 1Password, and many, many more.
On Tuesday, August 11th 2020, Mozilla announced their decision to restructure the company and to lay off around 250 people, including folks who are active members of the Rust project and the Rust community. Understandably, these layoffs have generated a lot of uncertainty and confusion about the impact on the Rust project itself. Our goal in this post is to address those concerns. We’ve also got a big announcement to make, so read on!
There’s no denying the impact these layoffs have had on all members of the Rust community, particularly the folks who have lost their jobs in the middle of a global pandemic. Sudden, unexpected layoffs can be a difficult experience, and they are made no less difficult when it feels like the world is watching. Impacted employees who are looking for job assistance can be found on Mozilla’s talent directory.
Notwithstanding the deep personal impact, the Rust project as a whole is very resilient to such events. We have leaders and contributors from a diverse set of different backgrounds and employers, and that diversity is a critical strength. Further, it is a common misconception that all of the Mozilla employees who participated in Rust leadership did so as a part of their employment. In fact, many Mozilla employees in Rust leadership contributed to Rust in their personal time, not as a part of their job.
Finally, we would like to emphasize that membership in Rust teams is given to individuals and is not connected to one’s employer. Mozilla employees who are also members of the Rust teams continue to be members today, even if they were affected by the layoffs. Of course, some may choose to scale back their involvement. We understand not everyone might be able to continue contributing, and we would fully support their decision. We're grateful for everything they have done for the project so far.
As the project has grown in size, adoption, and maturity, we’ve begun to feel the pains of our success. We’ve developed legal and financial needs that our current organization lacks the capacity to fulfill. While we were able to be successful with Mozilla’s assistance for quite a while, we’ve reached a point where it’s difficult to operate without a legal name, address, and bank account. “How does the Rust project sign a contract?” has become a question we can no longer put off.
Last year, we began investigating the idea of creating an independent Rust foundation. Members of the Rust Team with prior experience in open source foundations got together to look at the current landscape, identifying the things we’d need from a foundation, evaluating our options, and interviewing key members and directors from other foundations.
Building on that work, the Rust Core Team and Mozilla are happy to announce plans to create a Rust foundation. The Rust Core Team's goal is to have the first iteration of the foundation up and running by the end of the year.
This foundation’s first task will be something Rust is already great at: taking ownership. This time, the resource is legal, rather than something in a program. The various trademarks and domain names associated with Rust, Cargo, and crates.io will move into the foundation, which will also take financial responsibility for the costs they incur. We see this first iteration of the foundation as just the beginning. There’s a lot of possibilities for growing the role of the foundation, and we’re excited to explore those in the future.
For now though, we remain laser-focused on these initial narrow goals for the foundation. As an immediate step the Core Team has selected members to form a project group driving the efforts to form the foundation. Expect to see follow-up blog posts from the group with more details about the process and opportunities to give feedback. In the meantime, you can email the group at foundation@rust-lang.org.
While we have only begun the process of setting up the foundation, over the past two years the Infrastructure Team has been leading the charge to reduce the reliance on any single company sponsoring the project, as well as growing the number of companies that support Rust.
These efforts have been quite successful, and — as you can see on our sponsorship page — Rust’s infrastructure is already supported by a number of different companies throughout the ecosystem. As we legally transition into a fully independent entity, the Infrastructure Team plans to continue their efforts to ensure that we are not overly reliant on any single sponsor.
We’re excited to start the next chapter of the project by forming a foundation. We would like to thank everyone we shared this journey with so far: Mozilla for incubating the project and for their support in creating a foundation, our team of leaders and contributors for constantly improving the community and the language, and everyone using Rust for creating the powerful ecosystem that drives so many people to the project. We can’t wait to see what our vibrant community does next.
https://blog.rust-lang.org/2020/08/18/laying-the-foundation-for-rusts-future.html
|
|
Support.Mozilla.Org: Adjusting to changes at Mozilla |
Earlier last week, Mozilla announced a number of changes and these changes include aspects of SUMO as well.
For a high level overview of these changes, we encourage you to read Mitchell’s address to the community. For Support, the most immediate change is that we will be creating a more focused team that combines Pocket Support and Mozilla Support into a single team.
We want to take a moment to stress that Mozilla remains fully committed to our Support team and community, and the team changes are in no way a reflection on Mozilla’s focus on Support moving forward. The entire organization is grateful for all the hard work the community does everyday to support the products we all love. Community is the heart of Mozilla, and that can be said for our support functions as well. As we make plans as a combined Support team, we’d love to hear from you as well, so please feel free to reach out to us.
We very much appreciate your patience while we adjust to these changes.
On behalf of the Support team – Rina
https://blog.mozilla.org/sumo/2020/08/17/adjusting-to-changes-at-mozilla/
|
|
Cameron Kaiser: TenFourFox FPR26b1 available (after all, Mozilla's not dead yet) |
With much of the low-hanging fruit gone that a solo developer can reasonably do on their own, for FPR27 I would like to resurrect an old idea I had about a "permanent Reader mode" where once you enter Reader mode, clicking links keeps you in it until you explicitly exit. I think we should be leveraging Reader mode more as Readability improves because it substantially lowers the horsepower needed to usefully render a page, and we track current releases of Readability fairly closely. I'm also looking at the possibility of implementing a built-in interface to automatically run modifier scripts on particular domains or URLs, similar to Classilla's stelae idea but operating at the DOM level a la Greasemonkey like TenFourFox's AppleScript-JavaScript bridge does. The browser would then ship with a default set of modifier scripts and users could add their own. This might have some performance impact, however, so I have to think about how to do these checks quickly.
A few people have asked what the Mozilla layoffs mean for TenFourFox. Not much, frankly, because even though the layoffs affect the Mozilla security team there will still be security updates, and we'll continue to benefit as usual from backporting those to TenFourFox's modified Firefox 45 base (as well as downstream builders that use our backports for their own updates to Fx45). In particular I haven't heard the layoffs have changed anything for the Extended Support Releases of Firefox, from which our continued security patches derive, and we don't otherwise rely on Mozilla infrastructure for anything else; the rest is all local Floodgap resources for building and hosting, plus Tenderapp for user support, SourceForge for binaries and mirrors and Github for source code, wiki and issues.
But it could be a bigger deal for OpenPOWER systems like the Talos II next to the G5 if Mozilla starts to fade. I wrote on Talospace a good year and a half ago how critical Firefox is to unusual platforms, not least because of Google's general hostility to patches for systems they don't consider market relevant; I speak from personal experience on how accepting Mozilla is of Tier 3 patches as long as they don't screw up Tiers 1 and 2. Although the requirement of a Rust compiler is an issue for 32-bit PowerPC (and Tiger and Leopard specifically, since we don't have thread-local storage either), much of the browser still generally "just builds" even in the absence of architecture-specific features. Besides, there's the larger concern of dealing with a rapidly changing codebase controlled by a single entity more interested in the promulgation of its own properties and designing their browser to be those services' preferred client, which is true whether you're using mainline Chrome or any of the Chromium-based third-party browsers. That may make perfect business sense for them and for certain values of "good" it may even yield a good product, but it's in service of the wrong goal, and it's already harming the greater community by continuing to raise the barrier to entry for useful browser competition. We damned IE when Microsoft engaged in embrace, extend and extinguish; we should make the same judgment call when Google engages in the same behaviour. We have no spine for meaningful anti-trust actions in the United States anymore and this would be a good place to start.
http://tenfourfox.blogspot.com/2020/08/tenfourfox-fpr26b1-available-after-all.html
|
|
Daniel Stenberg: Video: Landing code in curl |
A few hours ago I ended my webinar on how to get your code contribution merged into curl. Here’s the video of it:
Here are the slides.
https://daniel.haxx.se/blog/2020/08/13/video-landing-code-in-curl/
|
|
Daniel Stenberg: Fiber breakage, day 4 |
Aaaaaaah.
Warning to sensitive viewers, this is seriously scary stuff. So this happened Monday and I’m still to see any service people show up here to help me restore my life (I of course requested help within minutes). What you see here is a fiber that’s been cut off – the fiber that goes into my house. Turns out even a small excavator can do great damage. Who knew?!

We’re now forced to survive on LTE only and the household suddenly has gotten a much bigger appreciation for the regular 1000/1000 mbit connectivity…
Friday 14th: a service guy was here, repaired the “cable” but failed to “blow in” a new fiber into the tube. According to him, there’s some kind of dust/rubbish now in the tube that’s in the way so it became a larger issue. He had to take off again and says they need to come back next week…
https://daniel.haxx.se/blog/2020/08/13/fiber-breakage-day-4/
|
|






