Armen Zambrano Gasparnian: Mozilla's Pushes - February 2014 |





http://armenzg.blogspot.com/2014/03/mozillas-pushes-february-2014.html
|
|
Austin King: Pick Your Battles |
I was quite surprised by the calls for BE’s resignation.
I’ve found the vitriolic attacks and misinformation I see flowing through my
Twitter feed disgusting. Emotionally, I feel like the tweets come from people with no real skin in the game, nor do they understand how damaging Mozilla can be bad for everyone in the long run.
These attacks are the viral spread and distortion, of some valid concerns from MoFo staff. Unfortunately, these concerns carried the ultimatum asking for BE to resign; which is sadly the fuel for this ad-selling media hype.
For reasons Myk does a great job of capturing, I’m somewhat conflicted on some of the nuances of this topic. Prop hate was horrible and still echos through our lives.
But, to try to add something new to the conversation…
Ultimately this comes down to picking your battles.
There is a lot wrong with the world and not much time to fix it.
In my mind Mitchell and Brendan have been fighting to keep the web open and accessible for over a decade. They ARE Mozilla. Mitchell is the spirit and BE is the tech.
It is a privilege to have been paid staff for the last 5+ years, because together, we’ve created an amazing platform to try keep the web open and to improve our world.
I’m at Mozilla, because it’s the best place I can find to participate as a progressive technologist.
Attacking Brendan for something he did 6 years ago, which was disclosed through a leak for a private action without much context is simply not worth damaging the project over.
The Mozilla project is getting quite large. When I joined as a webdev, I was on the outskirts. I didn’t work shoulder to shoulder with BE, but I already had a mental model of him from my community participation.
Now, our project is even larger, working on important topics like rural broadband access, education and news. Perhaps many people fighting the good fight on those fronts have not gotten a chance to build up a mental model of BE.
Progress and inclusion requires forgiveness and benefit of the doubt. Making a change in the world requires picking your battles.
Time machine thought police is not the battle ground I would pick. Resignation is a high-stakes tactic.
I will fight for people’s rights. I know Christie Koehler will be there fighting. I know of dozens and dozens of folks I work with everyday that would stick their necks out to fight for your rights.
Yes, we should monitor BE, as we should monitor and help debug each other.
There are many ways we can start carving up our community to attack each other, but let’s make sure we’re fighting over something that needs changing and not fighting the wrong battle for the right reasons.
|
|
Ben Hearsum: This week in Mozilla RelEng – March 28th, 2014 |
Major Highlights:
Completed work (resolution is ‘FIXED’):
In progress work (unresolved and not assigned to nobody):
http://hearsum.ca/blog/this-week-in-mozilla-releng-march-28th-2014/
|
|
Geoffrey MacDougall: What’s Happening Inside Mozilla |
Is not a conversation about inclusion. That was settled long ago. And Mozilla, unlike many organizations, treats our mission and our guidelines as sacred texts.
It’s also not a conversation about quality of life and the culture of the workplace. I’ll let my colleagues speak for themselves.
So if it’s not about the applied and the tangible, it’s about the symbolic and the intangible.
Our conversation is about rights.
Specifically, two rights: Equality and Free Speech. And which one this is.
The free speech argument is that we have no right to force anyone to think anything. We have no right to prevent people from pursuing their lives based on their beliefs. That what matters is their actions. And as long as they act in the best interests of the mission, as long as they don’t impose their beliefs on those around them, they are welcome.
The equality argument is that this isn’t a matter of speech. That believing that 1/n of us aren’t entitled to the same rights as the rest of us isn’t a ‘belief’. That the right to speech is only truly universal if everyone is equal, first.
Both sides are well represented inside Mozilla. Often by the same, conflicted people.
Our current situation is forcing us to choose between them.
And that sucks more than most of us can express in words. And we’re desperately trying to find a path forward that doesn’t wreck this beautiful thing we’ve built.

http://intangible.ca/2014/03/28/whats-happening-inside-mozilla/
|
|
Matt Thompson: Open when it matters: please help Mozilla |

Best tweet I saw yesterday
Mozilla needs your love and help right now. More than just a debate about our CEO, this threatens to divide us in other ways if we let it. We need dialogue, and to bring open hearts and minds around the two crucial issues here — both of which are meaty and substantive and vitally important to Mozilla:
This is hard. It deserves to be treated that way. Many of us feel very strongly about either or both of these issues — and so it requires nuanced, Mozilla-style reasoning that weighs both sides to find a solution.
That’s why I’m so proud of thoughtful, emotionally complex posts from colleagues working this through in the open. Like this, or this. And disappointed by stories like this one.
If you believe in (2), as I do, I think we’re served by demonstrating patience and compassion here. The difference between marriage equality as a right versus a matter of political or personal opinion is nuanced, historically recent, and culturally complex for a global community like Mozilla’s. And it’s on us to demonstrate that we understand and show respect for (1) as well, and not skip it over casually. For a lot of people, it’s at the heart of the Mozilla project.
Our ability to work this through — together in the open, with open hearts and minds — is even more important than any decision about our CEO. It will determine our strength once all this is done.
|
|
Rick Eyre: WebVTT (vtt.js) on Nodejs |
Good news! You can now use vtt.js on Nodejs. There
are two different ways you can get it on npm:
WebVTT, VTTCue, and
VTTRegion implementations into a nice Node package for you. Using
this method you will have to provide your own window object for
vtt.js to run on. See the docs
for more information.
vtt.js. node-vtt runs
vtt.js on an instance of PhantomJS. This means that you
don't have to provide your own window object for vtt.js
since it will already be running in the context of a web page. It also provides
a couple of convenience functions such as parseFile, processFile,
and others. See the docs for more information.
|
|
Chelsea Novak: Upgrade Banners Revisited |
Earlier this week, I posted about a planned change to the way smart-banners behave in the Firefox Affiliates program. Our dev team had proposed that we start using JavaScript on these particular buttons to get the images to change state.
Many of you had thoughts about this (awesome, thank you) and shared them with us in the comments and in other channels. As such, our devs have decided to try reworking the feature without using JavaScript, while fixing our major problems with the current implementation of these buttons.
I’m going to be starting maternity leave at the end of today, but our developer Mike Kelly will be watching my blog comments to respond to questions and thoughts on this. We’re also working to get our mailing list fixed so this can be discussed there as well.
Stay tuned!

http://chelseanovak.wordpress.com/2014/03/28/upgrade-banners-revisited/
|
|
Jan Odvarko: Firebug Internals I. – Data Providers and Viewers |
One of the achievements of Firebug 2 alpha 1 release has been adoption of new JSD2 API and this task required significant changes and improvements in our code base. Among other things, we have also introduced a new concept that allows to nicely build asynchronously updated UI.
There are other concepts in Firebug 2 and this version is with no doubt the best one we have released. Try it and let us know how it works for you (Firefox 30+ needed).
In order to implement remote access to the server side debugger API, Firebug UI needs to know how to deal with asynchronous update. We applied Viewer Provider pattern and extended it with support for asynchronous data processing.
If you like using Document View, Model View Controller or similar design patterns to build your code base, you'll probably like Viewer Provider too.
So, follow this post if you are interested to know what Viewer Provider looks like.
This design pattern represents a concept of data providers that mediate data access through an unified interface. Providers are usually consumed by Views (or Viewers) that use them to query for data and asynchronously populate their content when results are available.
First let's see simpler, but related Document View pattern:
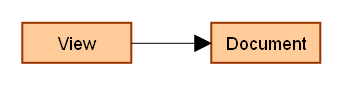
The problem with this concept is that View needs to know the interface (API) of the Document. This makes it hard for the View to switch to another data source, in other words, it's hard to reuse the same View for other Documents.
An improvement of this simple concept is incorporating a Provider in between the Document and View. The provider knows the Document API and expose them in unified way to the Viewer.

There is typically one provider for one specific data source/document, but in complex application (like Firebug) there can be even a hierarchy of providers.
Having data providers implemented for various data sources means that existing viewers can easily consume any data and can be simply reused.
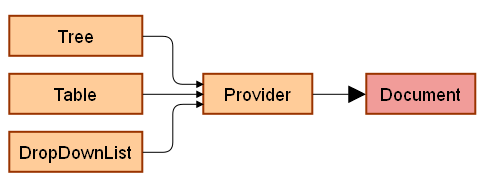
Here is how Provider interface looks like:
One of the challenges when consuming data is support for asynchronous processing. Especially in case on web applications toady. If you need a data you send XHR and wait for the asynchronous response. Viewer and Provider pattern has a solution fort this too.
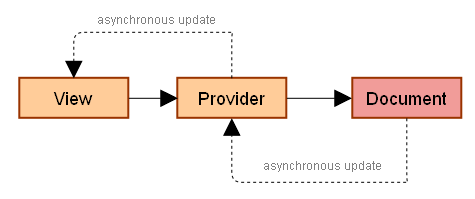
The main difference is that getChildren returns a Promise. The solid line (on the image above) represents synchronous data querying, the dashed line represents asynchronous update. The promise object usually comes from the data source and is passed through the provider to the view. Of course, the update happens when queried data are available.
You can also check out a simple web application that shows how viewers and providers can be implemented.
The demo application implements the following objects:
The application's entry point is main.js
Read more about Data Provider and how they are implemented in Firebug 2.
http://feedproxy.google.com/~r/SoftwareIsHardPlanetMozilla/~3/iEIGgti2ugQ/
|
|
Daniel Stenberg: curl and the road to IPv6 |
I’d like to comment Paul Saab’s presentation from the other day at the World IPv6 Congress titled “The Road To IPv6 – Bumpy“. Paul works for Facebook and in his talk he apparently mentioned curl (slide 24 of the PDF set).
Lots of my friends have since directed my attention to those slides and asked for my comment. I haven’t seen Paul’s actual presentation, only read the slides, but I have had a shorter twitter conversation with him about what he meant with his words.
The slide in question says exactly this:
Curl
- Very hostile to the format of the IPv6 address
- Wants everything bracket enclosed
- Many IPv6 bugs that only recently were fixed
Let’s see what those mean. Very hostile to the format of the IPv6 address and Wants everything bracket enclosed are basically the same thing.
Paul makes a big point about the fact that if you want to write a URL with an IP address instead of a host name, you have to put that IP address within [brackets] when the IP address is an IPv6 one, which you don’t do if it is an IPv4 one.
Right. Sure. You do. That’s certainly an obstacle when converting slightly naive applications from IPv4 to IPv6 environments. This syntax is mandated by RFCs and standards (RFC3986 to be exact). curl follows the standards and you’ll do it the same way in other tools and clients that use URLs. The problem manifests itself if you use curl for your task, but if you’d use something else instead that something else would have the same issue if it follows the standards. The reason for the brackets requirements is of course that IPv6 numerical addresses contain colons and colons already have a reserved meaning in the host part of URLs so they had to come up with some way to handle that.
Then finally, Many IPv6 bugs that only recently were fixed he said.
I’m the main developer and maintainer of the curl project. This is news to me. Sure we always fix bugs and we always find stupid things we fix so there’s no doubt about that we’ve had IPv6 related bugs that we’ve fixed – and that we still have IPv6 related bugs we haven’t yet found – but saying that we fixed many such bugs recently? That isn’t something I’m aware of. My guess is that he’s talking about hiccups we’ve had after introducing happy eyeballs, a change we introduced in release 7.34.0 in December 2013.
curl has had IPv6 support since January 2001. We’re on that bumpy road to IPv6!
http://daniel.haxx.se/blog/2014/03/28/curl-and-the-road-to-ipv6/
|
|
Myk Melez: qualifications for leadership |
http://mykzilla.blogspot.com/2014/03/qualifications-for-leadership.html
|
|
Benjamin Kerensa: Sponsor Debconf14 |
 Debconf14 is just around the corner and although we are making progress on securing sponsorships there is still a lot of progress that needs to be made in order to reach our goal. I’m writing this blog post to drum up some more sponsors. So if you are reading this and are a decision maker at your company or know a decision maker and are interested in supporting Debconf14, then please check out the Debconf14 Sponsor Brochure and if still interested then reach out to us at sponsors@debconf.org. I think it goes without saying that we would love to fill some of the top sponsorship tiers.
Debconf14 is just around the corner and although we are making progress on securing sponsorships there is still a lot of progress that needs to be made in order to reach our goal. I’m writing this blog post to drum up some more sponsors. So if you are reading this and are a decision maker at your company or know a decision maker and are interested in supporting Debconf14, then please check out the Debconf14 Sponsor Brochure and if still interested then reach out to us at sponsors@debconf.org. I think it goes without saying that we would love to fill some of the top sponsorship tiers.
I hope to see you in August in Portland, OR for Debconf14!
DebConf is the annual Debian developers meeting. An event filled with discussions, workshops and coding parties – all of them highly technical in nature. DebConf14, the 15th Debian Conference, will be held Portland, Oregon, USA, from August 23rd to 31st, 2014 at Portland State University. For more detailed logistical information about attending, including what to bring, and directions, please visit the DebConf14 wiki.
This year’s schedule of events will be exciting, productive and fun. As in previous years (final report 2013 [PDF]), DebConf14 features speakers from around the world. Past Debian Conferences have been extremely beneficial for developing key components of the Debian system, infrastructure and community. Next year will surely continue that tradition.
http://feedproxy.google.com/~r/BenjaminKerensaDotComMozilla/~3/o98-oali_FQ/sponsor-debconf14
|
|
Jan Odvarko: Firebug 2: Support for dynamic scripts |
Firebug 2 (first alpha) has been released this week and it's time to checkout some of the new features. Note that you need at least Firefox 30 to run it.
This brand new version introduces a lot of changes where the most important one is probably the fact that it's based on new Firefox debugging engine known as JSD2.
Also Firebug UI has been polished to match Australis theme introduced in Firefox 29.
Let's see how debugging of dynamically created scripts has been improved in this release and how Firebug UI deals with this common task. We'll cover following dynamic scripts in this post:
There are other ways how to create scripts dynamically.
Inline event handlers are little pieces of JavaScript placed within HTML attributes designed to handle basic events like onclick.
These scripts are compiled dynamically when needed (before executed for the first time). That's why they are considered dynamic and you don't have to see them in the Script location list (until compiled by the browser).
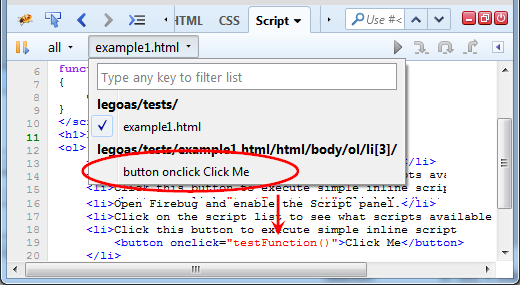
Script's URL is composed dynamically (there is no real URL for dynamic scripts) and event handlers scripts follow this scheme:
If you select the script from the script location menu, you should see the source that is placed within the onclick attribute.
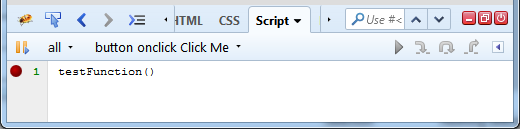
Of course, you can create a breakpoint as usual. Try live example page if you have Firebug 2 installed.
Another way how to dynamically compile a piece of script is using
http://feedproxy.google.com/~r/SoftwareIsHardPlanetMozilla/~3/clhBVGprAL8/
|
|
David Boswell: Community Building Team |
For the past few months I’ve been working with a new team that is focused on understanding the talent gaps of our core initiatives and connecting potential contributors to the most impactful work of the project.
The members of the Community Building team (Dino Anderson, Christie Koehler, Michelle Marovich, Pierros Papadeas, William Quiviger and Larissa Shapiro) have extensive experience in this area and I’m excited to learn from them.

Since we’re a new team, we’ve spent this first quarter of 2014 getting our ducks in a row so that we’re set up to achieve the goal of increasing active contributors to Mozilla’s target initiatives by 10x. We’ll do this by coordinating closely with the Engagement and Foundation teams.

Image from sweet_redbird
Our plans for the year are to partner with teams across Mozilla that want to build communities around their projects and help them connect with contributors and support them as they grow.
To help them with that, we’ll be making use of what is being created by the community building working groups. These are places where both staff and volunteers get together to create participation resources that will serve everyone across Mozilla.
You can learn more about these working groups by checking out the brown bag from our meetup in December. This features Mozillians from across the project sharing roadmaps for working groups focused on pathways, systems, education, recognition and events.

If you’re interested in taking part in our efforts to create shared participation resources, please feel free to sign up to the community building mailing list or join an upcoming Grow Mozilla discussion.

http://davidwboswell.wordpress.com/2014/03/27/community-building-team/
|
|
Daniel Stenberg: groups.google.com hates greylisting |
Dear Google,
Here’s a Wikipedia article for you: Greylisting.
After you’ve read that, then consider the error message I always get for my groups.google.com account when you disable mail sending to me due to “bouncing”:
Bounce status Your email address is currently flagged as bouncing. For additional information or to correct this, view your email status here [link].
“Google tried to deliver your message, but it was rejected by the server for the recipient domain haxx.se by [mailserver]. The error that the other server returned was: 451 4.7.1 Greylisting in action, please come back later”
See, even the error message spells out what it is all about!
Thanks to this feature of Google groups, I cannot participate in any such lists/groups for as long as I keep my greylisting activated since it’ll keep disabling mail delivery to me.
Enabling greylisting decreased my spam flood to roughly a third of the previous volume (and now I’m at 500-1000 spam emails/day) so I’m not ready to disable it yet. I just have to not use google groups.
Update: I threw in the towel and I now whitelist google.com servers to get around this problem…
http://daniel.haxx.se/blog/2014/03/27/google-groups-com-hates-greylisting/
|
|
Marco Zehe: What is WAI-ARIA, what does it do for me, and what not? |
On March 20, 2014, the W3C finally published the WAI-ARIA standard version 1.0. After many years of development, refinement and testing, it is now a web standard.
But I am often asked again and again: What is it exactly? What can it do for me as a web developer? And what can it not do?
I often find that there are assumptions made about WAI-ARIA that are not correct, and the use of it with such wrong assumptions often lead to sites that are less accessible than when ARIA is not being used at all.
In addition, Jared W Smith of WebAIM just yesterday wrote a very good blog post titled Accessibility Lipstick on a Usability Pig, highlighting another related problem: Even though a website may suck usability-wise, pouring WAI-ARIA sugar on it somehow forces it into compliance, but it still sucks big time.
So with all these combined, and after receiving encouragement by Jason Kiss on Twitter, I decided to write this post about what WAI-ARIA is, what it can do for you as a web developer, and what it cannot do. Or rather: When should you use it, and more importantly, when not.
I realize such articles have been written before, and these facts have also all been stressed time and again in talks by various good people in the field of web accessibility. But it is such an important topic that it is finally time for this blog to have such an all-encompassing article as well.
So without further due, let’s jump in!
WAI-ARIA stands for “Web Accessibility Initiative – Accessible Rich Internet Applications”. It is a set of attributes to help enhance the semantics of a web site or web application to help assistive technologies, such as screen readers for the blind, make sense of certain things that are not native to HTML. The information exposed can range from something as simple as telling a screen reader that activating a link or button just showed or hid more items, to widgets as complex as whole menu systems or hierarchical tree views.
This is achieved by applying roles and state attributes to HTML 4.01 or later markup that has no bearing on layout or browser functionality, but provides additional information for assistive technologies.
One corner stone of WAI-ARIA is the role attribute. It tells the browser to tell the assistive technology that the HTML element used is not actually what the element name suggests, but something else. While it originally is only a div element, this div element may be the container to a list of auto-complete items, in which case a role of “listbox” would be appropriate to use. Likewise, another div that is a child of that container div, and which contains a single option item, should then get a role of “option”. Two divs, but through the roles, totally different meaning. The roles are modeled after commonly used desktop application counterparts.
An exception to this are document landmark roles, which don’t change the actual meaning of the element in question, but provide information about this particular place in a document. You can read more about landmarks in my WAI-ARIA tip #4. Also, if you’re using HTML5, there are equivalent elements you might want to use as well.
The second corner stone are WAI-ARIA states and properties. They define the state of certain native or WAI-ARIA elements such as if something is collapsed or expanded, a form element is required, something has a popup menu attached to it or the like. These are often dynamic and change their values throughout the lifecycle of a web application, and are usually manipulated via JavaScript.
WAI-ARIA is not intended to influence browser behavior. Unlike a real button element, for example, a div which you pour the role of “button” onto does not give you keyboard focusability, an automatic click handler when Space or Enter are being pressed on it, and other properties that are indiginous to a button. The browser itself does not know that a div with role of “button” is a button, only its accessibility API portion does.
As a consequence, this means that you absolutely have to implement keyboard navigation, focusability and other behavioural patterns known from desktop applications yourself. A good example can be read about in my Advanced ARIA tip about tabs, where I clearly define the need to add expected keyboard behavior.
Yes, that’s correct, this section comes first! Because the first rule of using WAI-ARIA is: Don’t use it unless you absolutely have to! The less WAI-ARIA you have, and the more you can count on using native HTML widgets, the better! There are some more rules to follow, you can check them out here.
I already mentioned the example with buttons versus clickable divs and spans with a role of “button”. This theme continues throughout native roles vs. ARIA roles and also extends to states and properties. An HTML5 required attribute has an automatic evaluation attached to it that you have to do manually if you’re using aria-required. The HTML5 invalid attribute, combined with the pattern attribute or an appropriate input type attribute will give you entry verification by the browser, and the browser will adjust the attribute for you. All of these things have to be done manually if you were using aria-invalid only. A full example on the different techniques for form validation can be found in a blog post I wrote after giving a talk on the subject in 2011.
Fortunately, this message seems to finally take hold even with big companies. For example, the newest version of Google Maps is using button elements where they used to use clickable divs and spans. Thanks to Chris Heilmann for finding this and pointing it out during an accessibility panel at Edge Conf (link to Youtube video) in March 2014!
Here’s a quick list of widget roles that have equivalents in HTML where the HTML element should be preferred whenever possible:
| WAI-ARIA role | Native element | Notes |
|---|---|---|
| button | button | use type=”button” if it should not act as a submit button |
| checkbox | input type=”checkbox” | - |
| radiogroup and radio | fieldset/legend and input type=”radio” | fieldset is the container, legend the prompt for which the radio buttons are the answer for, and the input with type of “radio” are the actual radio buttons |
| combobox | select size=”1'' | Only exception is if you need to create a very rich compond widget. But even then, combobox is a real mess which warrants its own blog post. |
| listbox | select with a size greater than 1 | Only exception is if you create a rich auto/complete widget |
| option | option | As children of select elements or combobox or listbox role elements |
| list | ul or ol | Not to be confused with listbox! list is a non-interactive list such as an unordered or ordered list. Those should always be preferred. Screen readers generally also supporting nesting them and get the level right automatically. |
| spinbutton | input type=”number” | If the browser supports it. |
| link | a with href attribute | Should, in my humble opinion, never ever ever be used in an HTML document! |
| form | form | Nobody I know from the accessibility community can actually explain to me why this one is even in the spec. I suspect it has to do primarily with SVG, and maybe EPUB. |
The reason all these roles to native elements mappings are in there at all are because of the fact that WAI-ARIA can also be applied to other markup such as EPUB 3 and SVG 2. Also, some elements such as spin buttons and others are new in HTML5, but because WAI-ARIA was originally meant to complement HTML 4.01 and XHTML 1.x, and HTML5 was developed in parallel, roles, states and properties were bound to overlap, but got more defined behaviors in browsers for HTML5.
Likewise, you should prefer states such as disabled and required over the WAI-ARIA equivalents aria-disabled and aria-required if you’re writing HTML5. If you write HTML 4.01 still, this rule does not apply. If you’re specifically targetting HTML5, though, there is not really a need for the aria-required, aria-disabled and aria-invalid states, since the browsers take care of that for you. And yes, I know that I am in disagreement with some other accessibility experts, who advise to use both the HTML5 and WAI-ARIA attributes in parallel. Problem with that is, in my opinion, that it is then extra work to keep the WAI-ARIA attributes in sync. Especially with the aria-invalid attribute, this means that you’ll still have to put in some JavaScript that responds to the state of the HTML5 form validation state.
This is a question I am getting a lot. The simple answer is: Because WAI-ARIA was never meant to change browser behavior, only expose extra information to assistive technologies. The more complex answer is: WAI-ARIA can be applied to XHTML 1.0 and 1.1, HTML 4.01, and HTML5. The HTML5 attributes can only be applied to HTML5 capable browsers, including mobile, but will give you all kinds of extra features defined in the standard for these attributes. If the WAI-ARIA attributes were suddenly made to influence actual browser behavior, the level of inconsistency would be enormous. To keep WAI-ARIA clean and on a single purpose, it was therefore decided to not make WAI-ARIA attributes influence browser behavior ever.
Whenever you create a widget that is not indiginous to your host language, e. g. HTML. Examples of such widgets include:
In all of the above cases, it is your responsibility to:
If you do not adhere to the common interaction patterns associated with certain of these roles, your WAI-ARIA sugar might very quickly turn into sour milk for users, because they get frustrated when their expected keyboard interaction patterns don’t work. I strongly recommend studying the WAI-ARIA 1.0 Authoring Practices and keeping them handy for reference because they provide a comprehensive list of attributes and roles associated to one another, as well as more tips on many of the things I just mentioned. Another very good resource is the afore mentioned Using WAI-ARIA in HTML document which provides an extensive technical, yet easy to understand, reference to best practices on how to apply WAI-ARIA code, and also, when not to do it.
I realize that to someone just getting started with web accessibility, these topics may seem daunting. However, please remember that, like learning HTML, CSS and JavaScript, learning the intricacies of web accessibility means you’re learning a new skill. The more often you use these techniques, the more they become second nature. So don’t be discouraged if you at first feel overwhelmed! Don’t be shy to ask questions, or pull in people for testing! The accessibility community is generally a very friendly and helpful bunch.
One thing that may also help with motivation, and it’s been thankfully mentioned more and more often: Accessibility and usability go hand in hand. The more you improve the usability, the more it gets you there in terms of accessibility, too. And first and foremost, it’s about people! Not about some WCAG technique, not about a law that needs to be fulfilled, but about people actually using your web site or web application. Fulfilling legal requirements and WCAG techniques then come naturally.
So: Make WAI-ARIA one of your tools in your arsenal of tools for web development, but take its first rule to heart: Don’t use it unless you absolutely have to. Get the usability right for keyboard users, make sure stuff is properly visible to everyone even when they’re standing outside with the sun shining down on their shiny mobile phones or tablets (thanks to Eric Eggert for that tip!), and use WAI-ARIA where necessary to provide the extra semantic screen readers need to also make sense of the interactions. With people in mind first, you should be good to go!
Happy coding!
![]()
http://www.marcozehe.de/2014/03/27/what-is-wai-aria-what-does-it-do-for-me-and-what-not/
|
|
Alex Vincent: FastEventLog.jsm: A quick and dirty event log viewing tool |
About this time last year, I introduced a tree views module to my Verbosio XML editing project, which I’m still building infrastructure for. One piece of that infrastructure uses the TreeViews module, and adapts it for simple sequences of objects in a common format. Event logs were the use-case for this.
(This is currently independent of Mozilla Firefox’s own Log.jsm support, which is pretty nice itself!)
Let’s say you have a simple array of simple objects. They all have a certain minimal set of properties. If you want to visualize these objects laid out in a table, then each row can represent an object, and each column a property of the object. XUL trees can build this table-like view, but they need some help. First, they need a tree view that supports objects of the same basic type (TreeViews.jsm). Second, they need to be built with the columns you want.
FastEventLog.jsm does this. There’s two methods: addPropertyColumn() and appendTree(). The first takes a property name, a label, the column width, and a couple other optional details. The second method takes a box to hold the XUL tree element, a specialized “id prefix”, a tree height, and the array of objects you want to show to the user.
If you have two separate arrays with the same structure, you can call appendTree twice. (Think expected results versus actual results.)
When working on my asynchronous transaction manager idea (more on that in a future post), I realized I couldn’t easily visualize what had happened. The Firefox devtools debugger is awesome, especially with Thunderbird’s Remote Developer Tools Server extension. But the debugger’s JavaScript object tree showed arrays of objects in an ordinary key: value hierarchy. The data I wanted was buried very deep, and impractical to really analyze. So I built FastEventLog.jsm and a helper XUL file to turn the tree branches I needed into XUL trees.

The above is a screenshot with a bug deliberately introduced into the underlying transactions test to show what FastEventLog and TreeObjectModel (from TreeViews.jsm) can produce. This little table view made diagnosing bugs in the async transaction manager very easy!
As usual, this FastEventLog.jsm is available under MPL / GPL / LGPL tri-license.
|
|
Gavin Sharp: even more new firefox reviewers |
I’m pleased to announce two additions to the list of Firefox reviewers:
Please join me in congratulating Mike and Florian!
http://www.gavinsharp.com/blog/2014/03/26/even-more-new-firefox-reviewers/
|
|
Andrew Truong: Last week was Rough! |
Last week has been a very rough, tough and dramatic week. A really close friend of mine lost an immediate family member causing him to miss out at school. I've been helping and coping with him but not that very much. I'm certainly confused on the direction I should take and go with this as it's the first time something like this has happened to me. I'm not reaching out to your awesome folks to give me direction on what to do.
Saturday is always work day for me, and work hasn't been smooth since I've been hired, slip ups, doing things incorrectly leading me to doing all the other things people don't really do. Being out in the real workforce is just hard as open communication/ verbal communication wasn't actually that easy and things weren't getting around effectively even in a small work force. Maybe it's time for me to look for a new job as this one is no longer working out for me.
This week however was a big week and a not so great week for Mozilla but we still need to roll along and put the past behind us and look into the future.
|
|
Dave Hunt: Hunting for performance regressions in Firefox OS |
At Mozilla we’re running performance tests against Firefox OS devices several times a day, and you can see these results on our dashboard. Unfortunately it takes a while to run these tests, which means we’re not able to run them against each and every push, and therefore when a regression is detected we can have a tough time determining the cause.
We do of course have several different types of performance testing, but for the purposes of this post I’m going to focus on the cold launch of applications measured by b2gperf. This particular test launches 15 of the packaged applications (each one is launched 30 times) and measures how long it takes. Note that this is how long it takes to launch the app, and not how long it takes for the app to be ready to use.
In order to assist with tracking down performance regressions I have written a tool to discover any Firefox OS builds generated after the last known good revision and before the first known bad revision, and trigger additional tests to fill in the gaps. The results are sent via e-mail for the recipient to review and either revise the regression range or (hopefully) identify the commit that caused the regression.
Before I talk about how to use the tool, there’s a rather important prerequisite to using it. As our continuous integration solution involves Jenkins, you will need to have access to an instance with at least one job configured specifically for this purpose.
The simplest approach is to use our Jenkins instance, which requires Mozilla-VPN access and access to our tinderbox builds. If you have these you can use the instance running at http://selenium.qa.mtv2.mozilla.com:8080 and the b2g.hamachi.perf job.
Even if you have the access to our Jenkins instance and the device builds, you may still want to set up a local instance. This will allow you to run the tests without tying up the devices we have dedicated to running these tests, and you wont be contending for resources. If you’re going to set up a local instance you will of course need at least one Firefox OS device and access to tinderbox builds for the device.
You can download the latest long-term support release (recommended) of Jenkins from here. Once you have that, run java -jar jenkins.war to start it up. You’ll be able to see the dashboard at http://localhost:8080 where you can create a new job. The job must accept the following parameters, which are sent by the command line tool when it triggers jobs.
BUILD_REVISION – This will be populated with the revision of the build that will be tested.
BUILD_TIMESTAMP – A formatted timestamp of the selected build for inclusion in the e-mail notification.
BUILD_LOCATION – The URL of build to download.
APPS – A comma separated names of the applications to test.
NOTIFICATION_ADDRESS – The e-mail address to send the results to.
Your job can then use these parameters to run the desired tests. There are a few things I’d recommend, which we’re using for our instance. If you have access to our instance it may also make sense to use the b2g.hamachi.perf job as a template for yours:
$BUILD_LOCATION so you’ll need to make sure you include a valid username and password. You can inject passwords to the build as environment variables to prevent them from being exposed.wget to download the file using a wildcard:wget -r -l1 -nd -np -A.en-US.android-arm.tar.gz --user=$USERNAME --password=$PASSWORD $BUILD_LOCATION mv b2g-*.en-US.android-arm.tar.gz b2g.en-US.android-arm.tar.gz
$APPS variable and run your main command against each entry. The following shell script shows how we’re doing this for running b2gperf:while [ "$APPS" ]; do
APP=${APPS%%,*}
b2gperf --delay=10 --sources=sources.xml --reset "$APP"
[ "$APPS" = "$APP" ] && APPS='' || APPS="${APPS#*,}"
done
${BUILD_LOG_REGEX, regex=".* Results for (.*)", maxMatches=0, showTruncatedLines=false, substText="$1"}Once you have a suitable Jenkins instance and job available, you can move onto triggering your tests. The quickest way to install the b2ghaystack tool is to run the following in a terminal:
pip install git+git://github.com/davehunt/b2ghaystack.git#egg=b2ghaystack
Note that this requires you to have Python and Git installed. I would also recommend using virtual environments to avoid polluting your global site-packages.
Once installed, you can get the full usage by running b2ghaystack --help but I’ll cover most of these by providing the example of taking a real regression identified on our dashboard and narrowing it down using the tool. It’s worth calling out the --dry-run argument though, which will allow you to run the tool without actually triggering any tests.
The tool takes a regression range and determines all of the pushes that took place within the range. It will then look at the tinderbox builds available and try to match them up with the revisions in the pushes. For each of these builds it will trigger a Jenkins job, passing the variables mentioned above (revision, timestamp, location, apps, e-mail address). The tool itself does not attempt to analyse the results, and neither does the Jenkins job. By passing an e-mail address to notify, we can send an e-mail for each build with the test results. It is then up to the recipient to review and act on them. Ultimately we may submit these results to our dashboard, where they can fill in the gaps between the existing results.
The regression I’m going to use in my example was from February, where we actually had an issue preventing the tests for running for a week. When the issue was resolved, the regression presented itself. This is an unusual situation, but serves as a good example given the very wide regression range.
Below you can see a screenshot of this regression on our B2G dashboard. The regression is also available to see on our generic dashboard.

Performance regression shown on B2G dashboard
It is necessary to determine the last known good and first known bad gecko revisions in order to trigger tests for builds in between these two points. At present, the dashboard only shows the git revisions for our builds, but we need to know the mercurial equivalents (see bug 979826). Both revisions are present in the sources.xml available alongside the builds, and I’ve been using this to translate them.
For our regression, the last known good revision was 07739c5c874f from February 10th, and the first known bad was 318c0d6e24c5 from February 17th. I first ran this against the mozilla-central branch:
b2ghaystack -b mozilla-central --eng -a Settings -u username -p password -j http://localhost:8080 -e dhunt@mozilla.com hamachi b2g.hamachi.perf 07739c5c874f 318c0d6e24c5
-b mozilla-central specifies the target branch to discover tinderbox builds for.
--eng means the builds selected will have the necessary tools to run my tests.
-a Settings limits my test to just the Settings app, as it’s one of the affected apps, and means my jobs will finish much sooner.
-u username and -p password are my credentials for accessing the device builds.
-j http://localhost:8080 is the location of my Jenkins instance.
-e dhunt@mozilla.com is where I want the results to be sent.
hamachi is the device I’m testing against.
b2g.hamachi.perf is the name of the job I’ve set up in Jenkins. Finally, the last two arguments are the good and bad revisions as determined previously.
This discovered 41 builds, but to prevent overloading Jenkins the tool only triggers a maximum of 10 builds (this can be overridden using the -m command line option). The ten builds are interspersed from the 41, and had the range of f98c5c2d6bba:4f9f58d41eac.
Here’s an example of what the tool will output to the console:
Getting revisions from: https://hg.mozilla.org/mozilla-central/json-pushes?fromchange=07739c5c874f&tochange=318c0d6e24c5 --------> 45 revisions found Getting builds from: https://pvtbuilds.mozilla.org/pvt/mozilla.org/b2gotoro/tinderbox-builds/mozilla-central-hamachi-eng/ --------> 301 builds found --------> 43 builds within range --------> 40 builds matching revisions Build count exceeds maximum. Selecting interspersed builds. --------> 10 builds selected (f98c5c2d6bba:339f0d450d46) Application under test: Settings Results will be sent to: dhunt@mozilla.com Triggering b2g.hamachi.perf for revision: f98c5c2d6bba (1392094613) Triggering b2g.hamachi.perf for revision: bd4f1281c3b7 (1392119588) Triggering b2g.hamachi.perf for revision: 3b3ac98e0dc1 (1392183487) Triggering b2g.hamachi.perf for revision: 7920df861c8a (1392222443) Triggering b2g.hamachi.perf for revision: a2939bac372b (1392276621) Triggering b2g.hamachi.perf for revision: 6687d299c464 (1392339255) Triggering b2g.hamachi.perf for revision: 0beafa155ee9 (1392380212) Triggering b2g.hamachi.perf for revision: f6ab28f98ee5 (1392434447) Triggering b2g.hamachi.perf for revision: ed8c916743a2 (1392488927) Triggering b2g.hamachi.perf for revision: 339f0d450d46 (1392609108)
None of these builds replicated the issue, so I took the last revision, 4f9f58d41eac and ran again in case there were more builds appropriate but previously skipped due to the maximum of 10:
b2ghaystack -b mozilla-central --eng -a Settings -u username -p password -j http://localhost:8080 -e dhunt@mozilla.com hamachi b2g.hamachi.perf 4f9f58d41eac 318c0d6e24c5
This time no builds matched, so I wasn’t going to be able to reduce the regression range using the mozilla-central tinderbox builds. I move onto the mozilla-inbound builds, and used the original range:
b2ghaystack -b mozilla-inbound --eng -a Settings -u username -p password -j http://localhost:8080 -e dhunt@mozilla.com hamachi b2g.hamachi.perf 07739c5c874f 318c0d6e24c5
Again, no builds matched. This is most likely because we only retain the mozilla-inbound builds for a short time. I moved onto the b2g-inbound builds:
b2ghaystack -b b2g-inbound --eng -a Settings -u username -p password -j http://localhost:8080 -e dhunt@mozilla.com hamachi b2g.hamachi.perf 07739c5c874f 318c0d6e24c5
This found a total of 187 builds within the range 932bf66bc441:9cf71aad6202, and 10 of these ran. The very last one replicated the regression, so I ran again with the new revisions:
b2ghaystack -b b2g-inbound --eng -a Settings -u username -p password -j http://localhost:8080 -e dhunt@mozilla.com hamachi b2g.hamachi.perf e9025167cdb7 9cf71aad6202
This time there were 14 builds, and 10 ran. The penultimate build replicated the regression. Just in case I could narrow it down further, I ran with the new revisions:
b2ghaystack -b b2g-inbound --eng -a Settings -u username -p password -j http://localhost:8080 -e dhunt@mozilla.com hamachi b2g.hamachi.perf b2085eca41a9 e9055e7476f1
No builds matched, so I had my final regression range. The last good build was with revision b2085eca41a9 and the first bad build was with revision e9055e7476f1. This results in a pushlog with just four pushes.
Of these pushes, one stood out as a possible cause for the regression: Bug 970895: Use I/O loop for polling memory-pressure events, r=dhylands The code for polling sysfs for memory-pressure events currently runs on a separate thread. This patch implements this functionality for the I/O thread. This unifies the code base a bit and also safes some resources.
It turns out this was reverted for causing bug 973824, which was a duplicate of bug 973940. So, regression found!
Here’s an example of the notification e-mail content that our Jenkins instance will send:
b2g.hamachi.perf - Build # 54 - Successful: Check console output at http://selenium.qa.mtv2.mozilla.com:8080/job/b2g.hamachi.perf/54/ to view the results. Revision: 2bd34b64468169be0be1611ba1225e3991e451b7 Timestamp: 24 March 2014 13:36:41 Location: https://pvtbuilds.mozilla.org/pvt/mozilla.org/b2gotoro/tinderbox-builds/b2g-inbound-hamachi-eng/20140324133641/ Results: Settings, cold_load_time: median:1438, mean:1444, std: 58, max:1712, min:1394, all:1529,1415,1420,1444,1396,1428,1394,1469,1455,1402,1434,1408,1712,1453,1402,1436,1400,1507,1447,1405,1444,1433,1441,1440,1441,1469,1399,1448,1447,1414
Hopefully this tool will be useful for determining the cause for regressions much sooner than we are currently capable of doing. I’m sure there are various improvements we could make to this tool – this is very much a first iteration! Please file bugs and CC or needinfo me (:davehunt), or comment below if you have any thoughts or concerns.
http://blargon7.com/2014/03/hunting-for-performance-regressions-in-firefox-os/
|
|
Mitchell Baker: Building a Global, Diverse, Inclusive Mozilla Project: Addressing Controversy |
Monday’s announcement of Brendan Eich as the new CEO of Mozilla brought a lot of reactions. Many people were excited about what this meant for Mozilla, and our emphasis on protecting the open Web. In the next few days we’ll see more from Brendan and the leadership team on the opportunities in front of us. Before that, however, both Brendan and I want to address a particular concern that has been raised about Mozilla’s commitment to inclusiveness for LGBT individuals and community, and whether Brendan’s role as CEO might diminish this commitment at Mozilla.
The short answer: Mozilla’s commitment to inclusiveness for our LGBT community, and for all underrepresented groups, will not change. Acting for or on behalf of Mozilla, it is unacceptable to limit opportunity for *anyone* based on the nature of sexual orientation and/or gender identity. This is not only a commitment, it is our identity.
This commitment is a key requirement for all leadership within Mozilla, including for the CEO, and Brendan shares this commitment as the new Chief Executive Officer.
Second, I’ll point to Brendan’s comments on this topic.
Third, I’ll note that two years ago we had an open conversation and co-creation process about how we make sure our community supports all members, including all forms of gender and sexual orientation. The process, with me as the draftsperson, resulted in the Community Participation Guidelines. These Guidelines mandate that (1) each of us must be inclusive of all community members, regardless of sexual orientation, gender identity and more, and (2) any exclusionary approach you might practice elsewhere must be left at the door, and not be brought into Mozilla’s spaces.
We expect everyone, regardless of role or title, to be committed to the breadth of inclusiveness described in the Guidelines. These Guidelines are in addition to our inclusive and non-discriminatory policies which apply particularly to employees. As a practical, concrete example we’ve also been pushing the boundaries to offer excellent health benefits across the board, to domestic partners and all married couples, same-sex and otherwise.
My experience is that Brendan is as committed to opportunity and diversity inside Mozilla as anyone, and more so than many. This commitment to opportunity for all within Mozilla has been a key foundation of our work for many years. I see it in action regularly.
The CEO role is obviously a key role, with a large amount of authority. The CEO must have a commitment to the inclusive nature of Mozilla. This includes of course a commitment to the Community Participation Guidelines, inclusive HR practices and the spirit that underlies them. Brendan has made this commitment.
Finally, I’ve been asked a few times about my own personal views, and so I’ll add a short comment.
I am an avid supporter of equal rights for all. I support equal rights for the LGBT community, I support equal rights for underrepresented groups, and I have some pretty radical views about the role of underrepresented groups in social institutions. I was surprised in 2012, when his donation in support of Proposition 8 came to light, to learn that Brendan and I aren’t in close alignment here, since I’ve never seen any indication of anything other than inclusiveness in our work together (note: I’ve edited this sentence to give clarity).
I spend most of my time focused on building an open Internet, which I think is a required infrastructure for empowerment for everyone and where I think I can add something that’s tricky to replace. If I weren’t doing this, I’d probably be spending a good chunk of my life focused more directly on equality issues.
|
|






