Cameron Kaiser: systemsetupusthebomb |
This problem exists in 10.10, and is fixed in 10.10.3, but Apple will not fix it for 10.9 (or 10.8, or 10.7; the reporters confirmed it as far back as 10.7.2), citing technical limitations. Thanks, Apple!
The key is a privileged process called writeconfig which can be tricked into writing files anywhere using a cross-process attack. You would ask, reasonably, why such a process would exist in the first place, and the apparent reason is to allow these later versions of systemsetup et al to create user-specific Apache webserver configurations for guest users. If systemsetup doesn't have this functionality in your version of Mac OS X, then this specific vulnerability, at least, does not exist.
Fortunately, 10.6 and earlier do not support this feature; for that matter, there's no ToolLiaison or WriteConfigClient Objective-C class to exploit either. In fact, systemsetup isn't even in /usr/sbin in non-Server versions of OS X prior to 10.5: it's actually in /System/Library/CoreServices/RemoteManagement/ARDAgent.app/Contents/Support/, as a component of Apple Remote Desktop. I confirmed all this on my local 10.4 and 10.6 systems and was not able to replicate the issue with the given proof of concept or any reasonable variation thereof, so I am relieved to conclude that Power Macs and Snow Leopard do not appear to be vulnerable to this exploit. All your PowerPC-base systems are still belong to you.
Meanwhile, on the TenFourFox 38 front, IonPower is almost passing the first part of V8. Once I get Richards, DeltaBlue and Crypto working the rest of it should bust wide open. Speed numbers are right in line with what I'd expect based on comparison tests on my 2014 i7 MacBook Air. It's gonna be nice.
http://tenfourfox.blogspot.com/2015/04/systemsetupusthebomb.html
|
|
Air Mozilla: Bay Area Rust Meetup April 2015 |
 Rust meetup for April.
Rust meetup for April.
|
|
The Servo Blog: This Week In Servo 30 |
In the past week, we merged 66 pull requests
We now use homu to queue pull requests and coordinate with buildbot, in place of bors. Homu is a bit more efficient when it comes to API usage, and responds immediately to changes (bors needs to wait till it can hit the queue again after three minutes). It’s also got a bunch of other useful features like prioritization and efficient usage of build machines when retrying on a failure. You can try it out for yourself!
Last week’s post was discussed on Hacker News.
./mach test-unit, unit test compile time has now been reduced by 96%!drawImage()lineWidth, globalAlpha and miterLimitobject in WebIDL:focus selector and element.focus() methodWe had some issues with James’ CSS test PR breaking GitHub’s API, and the fallout on our CI. At the time of writing, the issue seems fixed. There were a couple of annoucements regarding the switch to homu and the new CSS tests, along with some discussion on the growing pull request backlog. We’re moving all our submodules to crates.io, with many of them running on Rust beta – please help if you can!
|
|
Air Mozilla: German speaking community bi-weekly meeting |
 Zweiw"ochentliches Meeting der deutschsprachigen Community. ==== German speaking community bi-weekly meeting.
Zweiw"ochentliches Meeting der deutschsprachigen Community. ==== German speaking community bi-weekly meeting.
https://air.mozilla.org/german-speaking-community-bi-weekly-meeting-2/
|
|
Air Mozilla: Community Education Call |
 The Community Education Working Group exists to merge ideas, opportunities, efforts and impact across the entire project through Education & Training.
The Community Education Working Group exists to merge ideas, opportunities, efforts and impact across the entire project through Education & Training.
|
|
Soledad Penades: Getting logs of your Firefox OS device |
Often you want to output debugging data from your app, but the space on the screen is limited! And perhaps you don’t want to connect to the app with WebIDE and launch the debugger and etc, etc…
One solution is to use any of the console. functions in your code. They will be sent to the device’s log. For example:
console.log('hello friends!');and you can also use console.error, console.info, etc.
Then, if you have the adb utility installed, you can get instant access to those logs when your device is connected to your computer with USB.
You can get adb from the Android Developer Toolkit or if you just want that binary, with package managers such as brew on a Mac:
brew install android-platform-toolsOnce adb is installed, if you execute this in a terminal:
adb logcatit will start to print everything that is sent to the device’s log. This includes your app’s messages AND EVERYTHING ELSE! It’s like a huge kitchen sink where all the debug data goes.
For example:
I/HelloApp(21456): Content JS LOG: hello friends
I/HelloApp(21456): at hello (app://5ae38330-dde0-11e4-9397-fd926d95d498/js/app.js:87:4)
D/wpa_supplicant( 900): RX ctrl_iface - hexdump(len=11): 53 49 47 4e 41 4c 5f 50 4f 4c 4c
D/wpa_supplicant( 900): wlan0: Control interface command 'SIGNAL_POLL'Although sometimes you want to see the whole bunch of messages, more often than not you’re just interested in your app’s messages. You can use grep to filter the output of adb logcat. Stop the current process with CTRL+C and then type this:
adb logcat | grep HelloAppThe result:
I/HelloApp(21456): Content JS LOG: hello friends
I/HelloApp(21456): at hello (app://5ae38330-dde0-11e4-9397-fd926d95d498/js/app.js:87:4)What we’re saying is: only show me lines that contain HelloApp. This depends on your app’s name, so adjust accordingly—if you enter the wrong argument for grep, you won’t see anything at all ![]()
When you connect multiple devices and run adb logcat, you get this message:
error: more than one device and emulatoradb doesn’t know what do you actually want to see, so it just resorts to not showing you anything.
To tell it what you want to look at, you need to find the label for each device first:
adb devicesThis will produce a list similar to this:
List of devices attached
3739ce99 device
356cd099 deviceWhere the first column represents each device’s label. Then you can use that to filter when calling adb logcat, like this:
adb -s 3739ce99 logcat | grep HelloAppYou could also open another terminal window and run logcat on it, but for another device, simultaneously.
Often when you file a bug you’re asked to produce a log. You can create one by redirecting the output of adb to a file! The way to do this is to go to a terminal, and type:
adb logcat > debug.txt
# or also...
adb -s 356cd099 logcat > debug.txtInstead of outputting the logs to the screen, they will be stored in debug.txt until you press CTRL+C. You should run the steps to reproduce the bug while adb is logging to debug.txt, and then stop it afterwards, and then you can append said debug.txt file to the bug in bugzilla–it contains valuable debug information, specially if you don’t filter by your app name!
And there are more useful adb bits and pieces on this MDN page.
Happy logging ![]()
![]()
http://soledadpenades.com/2015/04/09/getting-logs-of-your-firefox-os-device/
|
|
Emma Irwin: On being forces of good for each other |
This is two one of two – on recognition.
My last post focused on personalized recognition design. We need be deliberate about designing recognition that’s valuable to community (staff and volunteers), recognition that aligns with participation goals, recognition that provides a sustainable vision for the future between project and person.
If that sounds like a big task, it’s actually not, compared with the scale of what we need to accomplish. The truly big task is to make the Mozilla community a place worth hanging your hat. Hoping you’ve read Leslie’s “A place to hang my hat” now about surfacing the accomplishments of others:
And I want the same things for everyone I know. For all those folks who pour their heart into things and are unsung heroes. For people who give freely of their time and knowledge, and don’t expect a big party in return, just respect for having contributed. I’d rather none of us had to spend the time proving what we know.
(And this is especially true for women.)
I’d rather we all spent some time concentrating our energies on being forces for good for each other.
I watched the huge and positive response to Leslie’s post with interest – because awesome. There were tons of Mozilla tweets for this initiative #LABHR, but then – none in the last month or so. Why is that? Perhaps because the rush of participation felt good, but that we fail to personalize why surfacing the efforts of others on a regular basis matters.
Possibly, many of us are in privileged place of already being appreciated; and because the consequences are silent, it does little to erode our personal glow. Perhaps we feel we’re doing enough (and some teams to be fair do this really well already) or we’re just bad at time management – I’m sure there are a few reasons but I know it’s not because we’re out of people who need recognized :)
Here’s my proposal: Let’s reboot, or actually *start* the #mozlove idea that everyone loved (posted to CBT list) earlier year , and breathe life into it:
Find a community member(volunteer or staff) you admire and write/blog about their impact on the project, perhaps on you personally : encouraging stories about people who you haven’t seen highlighted previously – as inspirations for 2015. Tag your shares with #mozlove

There are lots of suggestions for how to do that on Leslie’s Blog post, but I want to emphasis one of key suggestion:
Ultra-mega-bonus points if your first few write ups are for people who are not like you.
I’ll share what I’ve been doing in the past month (so it’s possible!)
Thank you SO MUCH @_Tripad & @Debloper for recent contributions to the Community Education Portal! #mozlove
— Emma Irwin (@sunnydeveloper) April 2, 2015
Feels good, and important. #LABHR and #mozlove – hope you to see you there.
Firefox Image Credit – Faisal !
|
|
Emma Irwin: Personalizing Community Recognition |
This is part one of two – on recognition.
Something I’m thinking a LOT about these days is community recognition: meaningful and personalized recognition. Especially for community education, and especially to celebrate milestones of success navigating contribution ladders/pathways.
Earlier this year, we sent out a survey asking Mozilla Community (staff and volunteers) to evaluate, from a provided list, methods of recognition they most valued. Interestingly, no single method had more than 75% approval, with most hovering around 30% negative response. From digital badges, to shout-outs and printable-certificates there was no clear winner, and I think this is a compelling thing to solve for.
Early thinking around this includes solutions that add ‘preferred recognition’ as a choice in our Mozillians.org and/or Reps profiles, so that when we want to acknowledge someone’s accomplishments, we can literally ‘look up’ what is most valued by that individual, and do that thing. I’m also mid-journey with community infrastructure friends to add badges to our profiles – which I hope finally, help Mozillians share those badges they’ve been collecting.
The panic starts when we add the word ‘scalable’.
How can we design scalable, personalized recognition when we have so many amazing people moving the needle every day? When those people are in tiny corners of the project, or lost in a sea of greater community initiatives – how can we ever, ever manage to make recognition part of our reputation?
Well I’ll tell you how we can do it: stop thinking of recognition as this huge thing we to set aside our precious time to do. That’s not to say all of what we’re building doesn’t need dedicated planning – it does, but the majority of what we can accomplish by making recognition part of our workflow.
My next post will talk a bit about that, and how I hope a rebooted version of the #mozlove initiative can help. But first read this blog post from Leslie Hawthorn, and you’ll see where I’m going.
If you are working on recognition, or have thoughts, ideas and inventions that relate to personalized recognition I would love to hear from you!
|
|
Air Mozilla: Kids' Vision - Mentorship Series |
 Mozilla hosts Kids Vision Bay Area Mentor Series
Mozilla hosts Kids Vision Bay Area Mentor Series
https://air.mozilla.org/kids-vision-mentorship-series-20150408/
|
|
Pomax: Touch events, Reactjs, and Android. Good luck. |
We're doing a bit of prototype work over at the Mozilla Foundation, playing around with what possible future ways of interacting with makable web things could look like (can that be more vague?), and one of these prototypes takes the shape of dropping HTML elements onto a page and, photo book style, moving them around (or rather, moving, rotating, and scaling, using CSS3) without necessarily affecting the markup ordering.
And that works well! We're currently exploring React.js (which comes with a refreshing look at what programming for the web can look like) and so I figured I'd try my hand at the idea by writing a React component/mixin that could be used in conjunction with arbitrary content to magically make it movable, rotatable and scalable. And in desktop browsers, it works really well!
Unfortunately, we also need things to work on mobile devices, where there are no mouse cursors, and instead you have to work with touch. Touch changes some things (the CSS :hover state, for instance, becomes meaningless) but for the most part if your code worked with mousedown, mousemove and mouseup, those map fairly straight forward to touchstart, touchmove and touchend. Add the touch listeners and make them do the same as the mouse listeners, and done. Or, you would be, if these generated the same data. They don't, so you have a bit more work to do for getting the correct coordinates out of the touch events (mouse events have evt.clientX, touch events are an array of possible multitouch, so you end up with evt.touches[0].pageX, for instance). Still, entirely doable.
Unfortunately, things get weird when you do these things and then try to use them on, say, Android. Android has bugs when it comes touch events. Outside of the expected, that is. First, it turns out that Android won't fire off touchend events, even if they occur, if you never told Android to "prevent the default behaviour" on a touchstart or touchmove. Why? Because if you don't, Android will treat the finger gesture first as what you needed to do, and then as "oh but the default behaviour should still happen, the user wants to scroll the page" and then the touchend that stops Android from listening to page scroll gets consumed and never sent on to your code. If you didn't know about that, you're wasting quite a bit of time figuring out what the heck is going on.
But now you know about that, so adding evt.preventDefault() in your start and move handling should fix things, right? Well... no. It turns out there's another, far more magical, feature in Android that does what should reasonably be impossible in any programming setting. Have a look at this code:
var element = ...;
element.addEventListener("touchstart", handleTouchStart);
element.addEventListener("touchmove", handleTouchMove);
element.addEventListener("touchend", handleTouchEnd);
function touchStart(evt) {
console.log("touch started);
}
function touchMove(evt) {
console.log("touch move);
}
function touchEnd(evt) {
console.log("touch ended);
}
This works great. Loading pages with code like this on Android will show that all three events fire if you put down your finger, move it around a bit, and take it off the screen again. But, we might want to know where all those events happen, so let's write a helper function and modify the handlers:
function fixEvtCoords(evt) {
evt.clientX = evt.clientX || evt.touches[0].pageX;
evt.clientY = evt.clientY || evt.touches[0].pageY;
}
...
function touchStart(evt) {
fixEvtCoords(evt);
console.log("touch started at " + evt.clientX + "," + evt.clientY);
}
function touchMove(evt) {
fixEvtCoords(evt);
console.log("touch move at " + evt.clientX + "," + evt.clientY);
}
function touchStart(evt) {
fixEvtCoords(evt);
console.log("touch ended at " + evt.clientX + "," + evt.clientY);
}
That looks perfectly reasonable, and start and move now show the coordinates at which the events are generated. But touchend no longer works... what? It gets more interesting: what if we don't fix the coordinates for the end event?
function touchStart(evt) {
console.log("touch ended at " + evt.clientX + "," + evt.clientY);
}
This logs "touch ended at undefined,undefined", which makes sense because touch events don't have the .clientX and .clientY properties. So, let's change those to the real thing:
function touchStart(evt) {
console.log("touch ended at " + evt.touches[0].pageX + "," + evt.touches[0].pageY);
}
This won't actually do anything. There is nothing in .touches[0] anymore, so there will be a JS error and the code won't run. So what do we do? The simplest solution is to rely on the fact that we're only using single finger interaction, and just assume that if a touchend fired at all, we no longer have any fingers on the screen:
function touchStart(evt) {
console.log("touch ended");
}
This is weird for several reasons: if we want to deal with multi touch, how do we track which finger just stopped being on the screen? You'd be tempted to try something like this:
function touchStart(evt) {
console.log("touch ended", JSON.stringify(evt, false, 2));
}
To get an easy to debug bit of string data to tell us what's in that event, but if we do this, more JS errors and the log call will throw instead of logging useful data.
The worst is you just read this in a matter of a few minutes, but discovering all this, if you don't really work with Android all that much, is pretty much hours and hours of trying things, not understanding why they work on desktop but not on Android, trying more things, case reducing, starting from scratch, noticing things do work, slowly building things back up, noticing they break at some point, going back to where things weren't broken, and slowly figuring out what's going wrong because you home in on specific calls and patterns that just don't seem to work.
Over the course of 6 hours I went from not knowing these things to knowing both how to deal with this in the future, as well as knowing how to write my React code in such a way that touch events will propagate properly. Fun fact: if you're using React in an Android WebView "browser", there are some things you can do that work perfectly fine on desktop, and will not work at all on Android, too.
For instance, React has onTouchStart, onTouchMove and onTouchEnd component event handlers, with augmented events to make sure every browser will work the same. That's great, except it has bugs. The event augmentation does something (and without looking at the React source code, I have no real idea what that something is) that breaks event propagation. So, this code doesn't work:
var Positionable = ... ({
render: function() {
return (
You might think it would, but nope: not on Android. While this works fine on desktop, trying this on Android and tapping the RotationControls element actually gets sent to the higher level Positionable instead. No matter how much you tap, that touch event is not going to make it into the handler defined in RotationControls to rotate our element. So, ultimately, despite React having code in place to make working with touch events nicer, we actually need to go back to the drawing board and use the good old low level addEventListener('touchstart', ...) and friends in order to make sure that nothing interferes with event propagation.
var TouchMixin = {
componentDidMount: function() {
var localNode = this.getDOMNode();
localNode.addEventListener('touchstart', this.handleTouchStart);
},
componentWillUnmount: function() {
var localNode = this.getDOMNode();
localNode.removeEventListener('touchstart', this.handleTouchStart);
}
};
var Positionable = ... ({
mixins: [
TouchMixin
],
render: function() {
return (
With similar changes in RotationControls and ScaleControls. Fun!
But wait, there's more. The component I'm writing also has a ZIndexController, which gives you two buttons for changing a number, and that number gets communicated up, and used as z-index for the element on the page:
var Positionable = ... ({
render: function() {
return (
|
|
Christian Heilmann: Keeping it simple: coding a carousel |
One of the things that drives me crazy in our “modern development” world is our fetish of over-complicating things. We build solutions, and then we add layers and layers of complexity for the sake of “making them easier to maintain”. In many cases, this is a fool’s errand as the layers of complexity and with them the necessary documentation make people not use our solutions. Instead, in many cases, people build their own, simpler, versions of the same thing and call it superior. Until this solution gets disputed and the whole dance happens once again.
In this article I want to approach the creation of a carousel differently: by keeping it as simple as possible whilst not breaking backwards compatibility or have any dependencies. Things break on the web. JavaScript might not be loaded, CSS capabilities vary from browser to browser. It is not up to us to tell the visitor what browser to use. And as good developers we shouldn’t create interfaces that look interactive but do nothing when you click them.
So, let’s have a go at building a very simple carousel that works across browsers without going overboard. You can see the result and get the code on GitHub.
Let’s start very simple: a carousel in essence is an ordered list in HTML. Thus, the basic HTML is something like this:
span> class="carouselbox"> span> class="content"> >1> >2> >3> >4> > > |
Using this, and a bit of CSS we have something that works and looks good. This is the base we are starting from.
The CSS used here is simple, but hints at some of the functionality we rely on later:
.carouselbox { font-family: helvetica,sans-serif; font-size: 14px; width: 100px; position: relative; margin: 1em; border: 1px solid #ccc; box-shadow: 2px 2px 10px #ccc; overflow: hidden; } .content { margin: 0; padding: 0; } .content li { font-size: 100px; margin: 0; padding: 0; width: 100%; list-style: none; text-align: center; } |
The main thing here is to position the carousel box relatively, allowing us to position the list items absolutely inside it. This is how we’ll achieve the effect. The hidden overflow ensures that later on only the current item of the carousel will be shown. As there is no height set on the carousel and the items aren’t positioned yet, we now see all the items.

A lot of carousel scripts you can find will loop through all the items, or expect classes on each of them. They then hide all and show the current one on every interaction. This seems overkill, if you think about it. All we need is two classes:
We can hard-code these for now:
|
All we need to show and hide the different carousel items is to change the height of the carousel container and position all but the current one outside this height:
.active { height: 130px; } .active li { position: absolute; top: 200px; } .active li.current { top: 30px; } |
You can see this in action here. Use your browser developer tools to move the “current” class from item to item to show a different one.
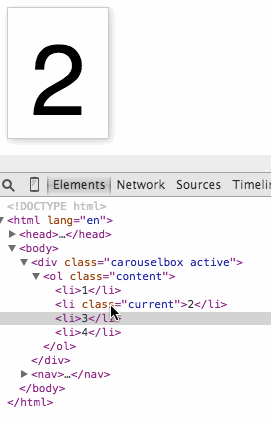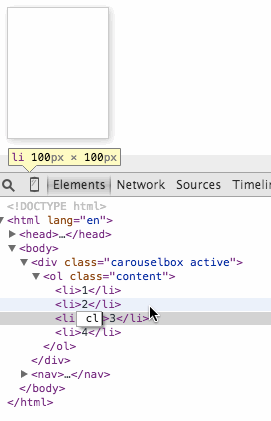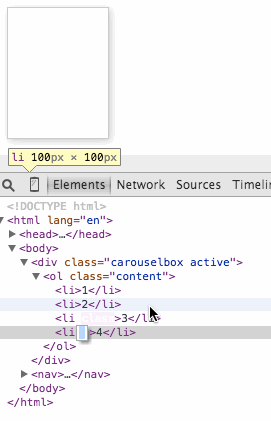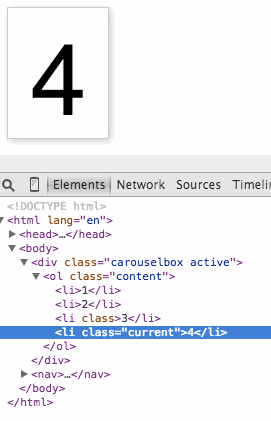
To make the carousel work, we need controls. And we also need some JavaScript. Whenever you need a control that triggers functionality that only works when JavaScript is executed, a button is the thing to use. These magical things were meant for exactly this use case and they are keyboard, mouse, touch and pen accessible. Everybody wins.
In this case, I added the following controls in our HTML:
span> class="carouselbox">
span> class="buttons">
span> class="prev">
|
http://christianheilmann.com/2015/04/08/keeping-it-simple-coding-a-carousel/
|
|
Ehsan Akhgari: Intercepting beacons through service workers |
Beacons are a way to send asynchronous pings to a server for the purposes such as logging and analytics. The API itself doesn’t give you a way to get notified when the ping has been successfully sent, which is intentional since the ping may be sent a while after the page has been closed or navigated away from. There are use cases where the web developer wants to send a ping to the server which is a candidate to use a beacon for, but they also need to know when/if the ping is delivered successfully, which makes beacons an unsuitable solution.
Service worker is a new technology that allows (among other things) intercepting the network requests made by the browser. It recently occurred to me that mixing these two technologies can solve the use case very well. The idea is to intercept the beacon fetch inside a service worker and then tell the web page about whether the beacon was successfully sent. I made a demo which shows how this can work. This demo works on Firefox Nightly if you toggle the dom.serviceWorkers.enabled pref. It currently doesn’t work on Chrome, because it doesn’t allow a service worker to intercept the beacon, and I filed a bug about it.
Here is how this demo works: It registers a service worker as you would usually do, and then for sending the beacon, we create a new iframe to make sure the document where we call sendBeacon is indeed intercepted by the service worker, and call sendBeacon as usual in that iframe. Inside the service worker, we intercept the beacon. So at this point the beacon fetch has gotten to our service worker. My simple demo just sends a message to all controlled windows about this. A real service worker however would probably do a fetch on its own for sending the beacon to the network, wait for the returned promise to resolve, and then record a log of some sort such as in the DOM Cache, or send a message back to the controlled document.
It’s nice that service workers give you a way to delve into the guts of the platform and retrieve the information that interests you even if the rest of the platform hides that information! I hope this demo is useful to people who have this use case.
http://ehsanakhgari.org/blog/2015-04-08/intercepting-beacons-through-service-workers
|
|
Sean McArthur: hyper on beta |
Since I announced hyper in December of last year, it has continued to grow as Rust’s http library.
Of course, a lot of the effort this past few months has been keeping up with all the changes to Rust and the standard library. A million thanks to all those who helped with these upgrades. I can’t overstate the joy it is to wake up in the morning, read that there are breaking changes in the latest nightly, and then see in my inbox that a pull request has already been filed fixing hyper.
Now that the breaking changes are behind us, developement can focus entirely on making hyper do things better-er. Specifically, here’s things that are either in progress, or highly desired (hint hint).
I could imagine aiming for a 1.0 of hyper once we have asynchronous IO.
Again, all of this is thanks to you guys, the amazing community. And if you want to get involved, please join in. Perhaps try tackling one of the easy issues first.
Or you can check the Releases. I try to keep them in sync.
|
|
Air Mozilla: Product Coordination Meeting |
 Duration: 10 minutes This is a weekly status meeting, every Wednesday, that helps coordinate the shipping of our products (across 4 release channels) in order...
Duration: 10 minutes This is a weekly status meeting, every Wednesday, that helps coordinate the shipping of our products (across 4 release channels) in order...
https://air.mozilla.org/product-coordination-meeting-20150408/
|
|
Air Mozilla: The Joy of Coding (mconley livehacks on Firefox) - Episode 9 |
 Watch mconley livehack on Firefox Desktop bugs!
Watch mconley livehack on Firefox Desktop bugs!
https://air.mozilla.org/the-joy-of-coding-mconley-livehacks-on-firefox-episode-9/
|
|
Anthony Ricaud: Electrolysis without tabs underlined |
Electrolysis has been re-enabled in Nightly. It brings lots of end-user benefits but it also brings a new style for tabs. I guess this underlining is to help users easily notice the difference with a non-Electrolysis build.
But you can easily disable that:
.tabbrowser-tab[remote] {
text-decoration: none !important;
}Thanks Jonathan Kew for the tip.
http://ricaud.me/blog/post/2015/04/Electrolysis-without-tabs-underlined
|
|
Zbigniew Braniecki: One year with the Firefox OS L10n framework |
For several years now, the Localization team at Mozilla has been working on a modern localization framework based on the following set of principles and architectural choices that we consider fundamental for the next generation multilingual UI’s.
Exactly one year ago, on April 8th 2014, Stas landed the initial rewrite of l10n.js – the localization framework used in Firefox OS. This set us on the path to enable the vision of a modern localization framework driven by the design principles outlined above.
Since then, we have a dedicated, two person team, working full time on advancing this vision and learning how to improve upon it in the process.
The full year of work has resulted in many important features being developed for the platform, including:
A couple weeks ago we have finalized the work scheduled for Firefox OS 2.2 and begun development for the next major release. The clean and reliable API has given us a good base to start implementing the remaining components of the vision behind L20n in this cycle.
For the current cycle we have scheduled:
With ever-growing understanding of the environment and how the web stack matures, we are also getting close to start extracting the core of our framework to offer for standardization, and that’s an exciting opportunity to fulfill the vision of both Firefox OS and L20n and bring the modern localization framework to the whole web, making it more multilingual and global.
http://diary.braniecki.net/2015/04/08/one-year-with-the-firefox-os-l10n-framework/
|
|
Adam Lofting: ‘As pretty as an airport’ (or a standing desk) |
 It was a long weekend here in the UK which gave me some time to make some final adjustments to a desk I’ve been building and take a photo. And, here it is.
It was a long weekend here in the UK which gave me some time to make some final adjustments to a desk I’ve been building and take a photo. And, here it is.
Many years ago I read Douglas Adams’ Last Chance to See (which on a side note was one of my original motivators for wanting to work at WWF). Though I was maybe fifteen when I read this book, one of several notions that stuck with me was:
“It’s no coincidence that in no known language does the phrase ‘As pretty as an airport’ appear”
In the twenty years following, airports have been upping their game when it comes to design. Standing Desks however are severely lacking in the ‘pretty’ department (even if they’re currently trendy). If you haven’t looked into this yourself, try an image search now for ‘Standing Desk’. Even try a Pinterest search where you limit the results to the things that design conscious human beings think are worth looking at, and you’ll see standing desks are struggling.
There are a few exceptions, including the craftsmanship of MoFo’s own Simon Wex. But mostly, standing desks are not very pretty.
But still, I wanted a standing desk, and one that I’d want to look at for the many many of the hours in my life spent working. And I didn’t feel like spending hundreds of pounds buying an ugly office version, so I challenged myself to build something not-ugly. For relatively little money.
To credit my sources, I basically combined the two desks below into the thing I wanted (and added an extra shelf to stash the laptop):


The three horizontal shelves were IKEA shelves left in our house by the previous owners, so I spent about lb25 on the remaining timber and carriage bolts to hold the frame together.
I’ve been using it for a few weeks now, and am thoroughly enjoying it.
Also, making things is fun.
http://feedproxy.google.com/~r/adamlofting/blog/~3/349xQGdhrIk/
|
|
Air Mozilla: Starring Events on Air Mozilla |
 This is an informal overview of the 'Starred Event' feature I added to Air Mozilla. What's it like, as a junior level developer, to implement...
This is an informal overview of the 'Starred Event' feature I added to Air Mozilla. What's it like, as a junior level developer, to implement...
|
|







 Weekly Mozilla Reps call
Weekly Mozilla Reps call