David Boswell: Becoming a Mozilla volunteer again |
I got involved with Mozilla as a volunteer in 1999 because I was excited about the idea of an open project that gave people the opportunity to contribute to a cause they believe in.
Since 2007, I have had the privilege to work here and help many other volunteers pursue their passion and get involved with Mozilla.
This Friday, the 13th, will be my last day as an employee and I will return to being a Mozilla volunteer.
I hope to stay in touch with both the staff and volunteers who I have met during my Mozilla journey. Please feel free to reach out—my contact information is on my Mozillians profile.

https://davidwboswell.wordpress.com/2015/02/09/becoming-a-mozilla-volunteer-again/
|
|
Chris Finke: Implementing Mozilla Persona on Interpr.it |
When I first launched Interpr.it as a Google Chrome extension translation platform four years ago, I used Google OpenID to authenticate users, because:
a) I didn’t want people to have to create a new username and password.
and
b) It made sense that Chrome extension authors and translators would already have Google accounts.
Years passed, and Google announced that they’re shutting down their OpenID support. I spent three hours following their instructions for upgrading the replacement system (“Google+ Enterprise Connect+” or something like that), and not surprisingly, it was time wasted. The instructions didn’t match up with the UIs of the pages they were referencing, so it was an exercise in futility. I’ve noticed this to be typical of Google’s developer-facing offerings.
I made the decision to drop Google and switch to Mozilla’s Persona authentication system. Persona is like those “Sign in with Twitter/Facebook/Google” buttons, except instead of being tied to a social network, it’s tied to an email address — something everyone has. My site never has access to your password, and you don’t have to remember yet another username.
In stark contrast to my experience with Google’s new auth system, Persona took less than an hour to implement. Forty-five minutes passed from when I read the first line of documentation to the first time I successfully logged in to Interpr.it via Persona.

If you originally signed in to Interpr.it with your GMail address, you won’t notice much of a difference, since Persona automatically uses Google’s newest authentication system anyway.
Mozilla does so many things to enhance the Open Web, and Persona is no exception. Developers: use it. Users: enjoy it.
http://www.chrisfinke.com/2015/02/09/mozilla-persona-interprit/
|
|
Doug Belshaw: Help us redefine the skills underpinning three Web Literacy Map competencies! |
As Jamie Allen, long-standing contributor reminded me, last week the Web Literacy Map community turned two. Happy Birthday to us! We’ve come a long way (baby). Many thanks to all of the people who have helped us so far.

We’re currently hard at work defining Web Literacy Map v1.5 and on track to ship this at the end of Q1 2015 (i.e. end of March). As part of that process we’ve re-scoped three competencies. Specifically:
‘Web Mechanics’ and 'Infrastructure’ from v1.1 will merge to become Web Mechanics in v1.5. Meanwhile 'Design & Accessibility’ will separate out into Designing for the Web and Accessibility.
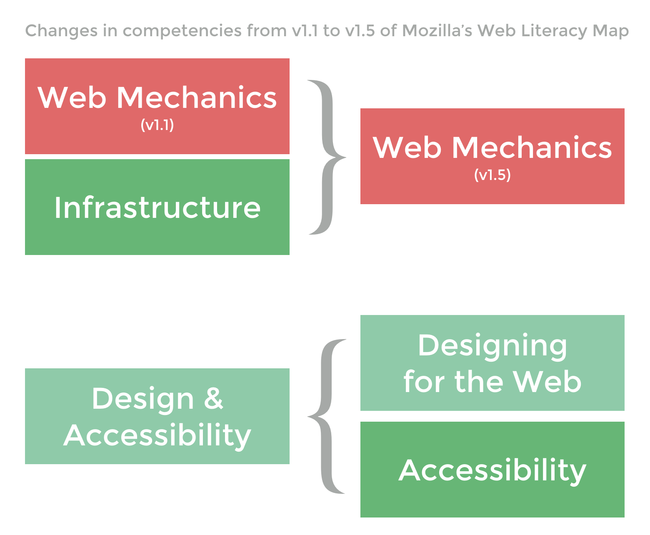
As Linus Torvalds famously stated, “given enough eyes, all bugs are shallow.” That’s why we need your help in nailing down the skills underpinning these newly-defined competencies. The more people involved, the better!
The Infrastructure competency under the Building strand of the Web Literacy Map was deemed problematic, so we’ve combined the two. This competency will continue to live under the Exploring strand.
Discuss/debate: https://github.com/mozilla/webliteracymap/issues/14
The only real combined competency in v1.1 of the Web Literacy Map was Design & Accessibility.* We were keen for v1.5 to separate out design from accessibility, so that’s what we’ve done here. With the designing part we’re focusing mainly on CSS (as this is the Web Literacy Map) but also other design considerations.
Discuss/debate: https://github.com/mozilla/webliteracymap/issues/15
* The other competency that looks as if it’s combined is 'Coding/scripting’/ However, this gains its title due to purists who deem JavaScript a 'scripting’ rather than a coding language. ;)
This is an extremely important issue and one that has risen in status through iterations of the Web Literacy Map. Originally a couple of skills under one of the competencies, we’re now giving it prominence in it’s own right.
Discuss/debate: https://github.com/mozilla/webliteracymap/issues/16
Even if you haven’t taken part in our discussions up until this point, you’re very welcome to do so - even in just one of the above threads! We appreciate the expertise and knowledge of those dealing with these issues on a daily basis. Please do jump in +1'ing an idea helps give weight to ideas and formulations of skills.
Comments? Questions? Do jump into the GitHub issues, but I’m also available on Twitter (@dajbelshaw and email (doug@mozillafoundation.org).
|
|
Mozilla Release Management Team: Firefox 36 beta6 to beta7 |
In this beta, we disabled MSE. The feature was not ready for the release channel. The work on this feature will continue in aurora (currently, 37). In the meantime, some various crashers have been fixed.
Note that, for this beta, Windows updates have not been enabled for our users (only GNU/Linux and Mac OS X) because Youtube is proposed MSE videos for 36 beta users. This should be fixed today (Monday).
| Extension | Occurrences |
| cpp | 30 |
| js | 19 |
| h | 18 |
| java | 5 |
| svg | 2 |
| xml | 1 |
| mk | 1 |
| list | 1 |
| jsx | 1 |
| jsm | 1 |
| ini | 1 |
| html | 1 |
| build | 1 |
| Module | Occurrences |
| image | 25 |
| browser | 16 |
| dom | 12 |
| js | 8 |
| mobile | 5 |
| layout | 4 |
| toolkit | 2 |
| testing | 2 |
| netwerk | 2 |
| gfx | 2 |
| security | 1 |
| mozglue | 1 |
| modules | 1 |
List of changesets:
| Michael Comella | Bug 1096958 - Part 2: Null mGrid's OnItemClickListener when destroying the view. r=liuche, a=sylvestre - c860bf9bc4a8 |
| Chris Pearce | Bug 1123535 - Revert bbc98a8c8142 to reland Bug 1123535. r=me a=sledru - 41fac15f269a |
| Chris Pearce | Bug 1123535 - Make dormant ResetPlayback assertion more lenient. r=me a=KWierso on a CLOSED TREE - f74e583e724f |
| Jon Coppeard | Bug 1127246 - Add a post barrier to the baseShapes table r=terrence a=sylvestre - e0a36c5bdf4c |
| JW Wang | Bug 1105720 - Have a larger timeout value for the very slow B2G emulator. r=cpearce, a=test-only - f8616422302f |
| Brian Hackett | Bug 1127987 - Fix transposed parent/metadata arguments in EmptyShape::getInitialShape. r=jandem, a=sledru - e8ae7bc725af |
| Naoki Hirata | Bug 1128113 - Skip mSharedDecoderManager which is part of MozMP4. r=jya, a=sledru - 07cc8d56cde8 |
| Michael Comella | Bug 1090287 - Check that the selected tab is not null before updating progress visibility. r=rnewman, a=lmandel - 0a9d521bf670 |
| James Willcox | Bug 1108709 - Don't chdir on Android. r=glandium, a=sledru - 2e542912a7c0 |
| Patrick McManus | Bug 1128038 - h2 DAV methods set end_stream bit twice r=hurley a=sledru - 13fa209bd0b0 |
| Glenn Randers-Pehrson | Bug 1102048 - Make image/src files comply with the Mozilla Coding Style Guide. r=seth, a=NPOTB - 5c93fa7cc6d5 |
| Ryan VanderMeulen | Temporarily backout Bug 1120149 because it conflicts with other uplifts. - 914dfaa20eef |
| Seth Fowler | Bug 1112956 - Add IProgressObserver to permit more than one class to observe ProgressTracker. r=tn, a=sledru - 842d25881e21 |
| Seth Fowler | Bug 1112972 - Part 1: Minor refactoring to prepare for MultipartImage. r=tn, a=sledru - 28f4806f60ee |
| Seth Fowler | Bug 1112972 - Part 2: Add MultipartImage and use it for multipart/x-mixed-replace image loading. r=tn, a=sledru - 438fed84c7c3 |
| Seth Fowler | Bug 1112972 - Part 3: Remove almost all special handling of multipart images in RasterImage. r=tn, a=sledru - c858f34b8153 |
| Seth Fowler | Bug 1112972 - Part 4: Remove Image::OnNewSourceData. r=tn, a=sledru - c4689eff54db |
| Seth Fowler | Bug 1112972 - Part 5: Remove almost all special handling of multipart images in ProgressTracker. r=tn, a=sledru - 274a8354e230 |
| Seth Fowler | Bug 1120149 - Add a hack to resolve an AWSY regression in Gecko 36. r=tn, a=sledru - 7422906b1a32 |
| James Long | Bug 1107682 - Clean up the way we set breakpoints on newly introduced scripts. r=fitzgen, a=sledru - 484b4f09fa9f |
| James Willcox | Bug 1062758 - Try to shutdown gracefully on Android. r=mfinkle, a=sledru - 8f1e0a224fb4 |
| Jon Coppeard | Bug 1123394 - Stop spurious re-entry of shell interrupt callback. r=shu, a=sledru - 6d9a99b090f5 |
| Jonathan Watt | Bug 1127507 - Get transforms on the children of SVG |
| Seth Fowler | Bug 1125401 - Replace ProgressTracker::IsLoading() with checks of the correct progress flags. r=tn, a=sledru - 41f8742f7c93 |
| Milan Sreckovic | Bug 1081911 - Null pointer check (wallpaper) for destDTBufferOnWhite. r=mattwoodrow, a=sledru - 8f52ac825ba7 |
| Bobby Holley | Bug 1120241 - Schedule the state machine when setting logical decoder state. r=cpearce a=lmandel - b0684ad8a47c |
| Matthew Noorenberghe | Bug 1122830 - Remove pinned tab APIs from UITour. r=Unfocused, a=sledru - 32f28bbf1fb4 |
| Matthew Noorenberghe | Bug 1110602 - Don't remove tour tabs from originTabs when switching tabs so they can continue to get notifications. r=Unfocused, a=sledru - ba8e83fca8f2 |
| Matthew Noorenberghe | Bug 1089000 - UITour: Remove broken code for detaching a tab to a new window. r=Unfocused, a=sledru - fe2ce463edba |
| Justin Dolske | Bug 1118831 - Loop: Click to add Hello icon to toolbar. r=mattn, a=sledru - b005871a2349 |
| Matthew Noorenberghe | Bug 1125764 - Allow tour pages to hide UITour annotations and menus when losing visibility. r=Unfocused, a=sledru - 756c22d18cdf |
| Jared Wein | Bug 1115153 - Loop: Create API to allow web to retrieve the loop.gettingStarted.seen pref. r=MattN, a=sledru - 5690b3943d75 |
| Rail Aliiev | Bug 1128953 - Rename win64 FTP directory. r=mshal, a=lmandel - e7fd0d7ff120 |
| Jon Coppeard | Bug 1124563 - Fixup base shape table after moving GC r=terrence a=sylvestre - 5eae334a2b31 |
| Dave Townsend | Bug 1129567: Revert page-mod to a non-e10s compliant version to fix jank when loading amazon.com. r=jsantell, a=sledru - 18d9d9422db6 |
| Seth Fowler | Bug 1126490 - Part 1: Recover when catastrophic circumstances cause us to lose frames in RasterImage. r=tn, a=sledru - b1db02330579 |
| Seth Fowler | Bug 1126490 - Part 2: Recover from loss of surfaces in VectorImage. r=dholbert, a=sledru - 3be92206bfd0 |
| Mark Banner | Bug 1127557 - Invalid preference type getting/setting loop.ot.guid. r=jaws, a=sledru - 4155bf349dbb |
| Matt Woodrow | Bug 1128179 - Avoiding crash when appending data after decoder initialization failed. r=jya, a=lmandel - a5992bd7d600 |
| Margaret Leibovic | Bug 1128521 - Don't use API 17+ method in search activity. r=mfinkle, a=sledru - 9b1ff4e3ca58 |
| Matt Woodrow | Bug 1114976 - Don't try to free TextureClients if allocation failed. r=nical, a=sledru - 74c4e5bdde78 |
| Ralph Giles | Bug 1129039 - Disable MSE support entirely. r=cajbir, a=sledru - 14d3deb83b7f |
| Ryan VanderMeulen | Bug 1029545 - Disable browser_dbg_variables-view-popup-14.js for frequent failures on all platforms. a=test-only - 0ee8df1c21d6 |
| Masatoshi Kimura | Bug 1116891 - Do fallback with RC4 cipher suites after PR_CONNECT_RESET_ERROR. r=bsmith, a=sledru - 886561600f49 |
| Maire Reavy | Bug 1109467 - Appear.in added to screensharing whitelist. r=jesup, a=sledru - 2807adaccd5f |
http://release.mozilla.org/statistics/36/2015/02/09/fx-36-b6-to-b7.html
|
|
David Tenser: Brace for impact (in a good way!) |
Happy belated new year! And what a year this will be for Mozilla. I’ll talk about 2015 in a bit, but I want to start with some context to make it clearer why this will be the year where we brace for impact, and how a new team I’m helping get off the ground will be at the center of the action.
Let’s be frank here: over the last few years, Mozilla has gradually shifted its culture into becoming an organization where it’s harder to contribute as a volunteer. There are many reasons why this is the case, such as the fact that we 10x the number of paid staff over the course of just seven years. Rapid growth like that tends to shift the culture of an org like that and Mozilla is no different. And as volunteer participation becomes harder, so does the perception of working with volunteers change among paid staff. It becomes a vicious circle that can be hard to stop.
To put things in context, by any objective standard Mozilla is still one of the (if not the most) open, transparent and collaborative organizations in the world — but it’s no longer as obvious to an “outsider” trying to identify opportunities to have an impact where to start. And that’s what makes me so excited about 2015, because we’re going to do some pretty radical things to shift that culture around and put a clear focus around Participation to turn the vicious circle into a virtuous circle instead.
Mozilla used to have two separate community teams: one focusing internally on working with business units within MoCo to open up opportunities for volunteer participation to happen — “designing for participation”. And then another team that focused on growing healthy local volunteer communities and ensuring that there was a robust governance structure to hold these volunteer communities together. Focusing on these two aspects of participation is crucial because it definitely takes two to tango. However, in order to maximize impact, the two aspects need to get really close to each other:
That’s where 2015 comes in. I’m devoting part of my time to lead a newly formed team called the Community Development Team, sitting in the new Participation org at Mozilla and consisting of truly amazing people who will focus on two things at the same time: maximizing impact for our volunteer leadership on the ground (Reps, regional communities) and connecting that with our product teams within the org. It’s worth noting that there are lots of people and teams across the org where community is already a core part of what they do. This includes teams like QA, SUMO, MDN, QA, l10n, Webmaker, Community Marketing, etc. That’s a key reason why Mozilla has been so successful over the years. The Community Development team will focus on broadening this success across the org by helping more projects and teams reach the level of success that these prime examples already demonstrate. And that may also mean working directly with these already very participatory teams amplify their efforts even more.
Our team goal is pretty simple: we will help key initiatives achieve more, move faster and better meet Mozilla’s core goals by helping them integrate new participatory approaches and by investing in volunteer skills and know how. We’ve set a 2015 goal to get at least 15 projects that meet this criteria of the virtuous circle.
How is it different from how we’ve done things in the past? The key change is a new center of gravity: acting as a liaison between product teams and volunteer leadership on the ground. In a nutshell, we’ll be holding business units and product teams with one hand, and our amazing volunteer leadership in the other hand, and we’ll make sure these two connect in a meaningful way that benefits both.
Our basic strategy is built around certain theories and hypotheses of what constitutes successful participation that we intend to test out. The formula looks like this:
The theory part is crucial here: we’re taking a scientific approach to participation, where everything we do to enable impact in the organization is also seen as an opportunity to validate our theories. Some of the great people on the Community Development team will get into more specifics around what those theories are in upcoming blog posts, and I will update this blog post when their posts are up. For now, I wanted to just present everyone on the team:
Mitchell Baker and Mark Surman are also heavily involved in our efforts around Participation. In fact, they are the instigators and I consider them my part-time bosses. Mark recently wrote about his thoughts on the Participation plan, which provides more depth to the concept of the virtuous circle of impact both in our volunteer communities and in our business units.
On a more personal note, in addition to the exciting work around Participation, I continue to lead the User Success team (SUMO + User Advocacy + more) as well and I will blog more about the exciting stuff we’re doing there in a future blog post. Reflecting on my own journey at Mozilla, starting as a volunteer back in 2001, seeing a leadership opportunity in 2002 to develop the first support site for Firefox (then Phoenix), building up a new community support initiative called SUMO in 2007, and today seeing how it has become a movement of hundreds of contributors in any given month, it feels like I’m going full circle by joining the new Participation initiatives. The focus is once more on volunteer leadership, meaningful connections with our organizational goals and key initiatives, and a goal to maximize impact by working together.
What’s next?
If you’re a manager of a product or functional team, expect to hear from us as we being the discovery phase in the next couple of weeks to better understand the participation opportunities we have in front of us. If you’re impatiently waiting for us and have ideas already of where you need help with expanding your reach through our amazing community, please beat us to it and reach out!
If you’re a volunteer participant to the Mozilla project, there are two things I’d like to see happen. First off, I expect that our efforts in the Community Development team to meet with various business units at Mozilla to lead to new and meaningful ways where you could have a direct impact on the products that we build to serve our mission, either locally or globally. And second, I would be thrilled to hear from you about your personal journey so far and what you have learned and what things you’d like to see change around Participation at Mozilla. Ping me (djst on IRC, djst on Mozilla’s email, djst on Twitter) and let’s talk. I hope to be having lots of conversations with people across the world in the next month to learn more about the opportunities we have in front of us.

|
|
Hannes Verschore: Year in review: Spidermonkey in 2014 part 2 |
In the first part of this series I noted that the major changes in Spidermonkey in 2014 were about EcmaScript 6.0 compliance, JavaScript performance and GC improvements. I also enumerated the major changes that happened starting from Firefox 29 till Firefox 31 related to Spidermonkey. If you haven’t read the first part yet, I would encourage you to do that first. In part two I will continue iterating the major changes from Firefox 32 till Firefox 34.
<- Year in review: Spidermonkey in 2014 part 1
Recover instructions
During the Firefox 32 release recover instructions were introduced. This adds the possibility to do more aggressive optimizations in IonMonkey. Before we couldn’t eliminate some instructions since the result was needed if we had to switch back to a lower compiler tier (bailout from IonMonkey to Baseline). This new infrastructure makes it possible to recover the needed result by adding instructions to this bailout path. As a result, we still have the needed results to bailout, but don’t have to keep a normally unused instruction in the code stream.
Read more about this change
Read more about this in the bug report
Irregexp
Internally there has been a lot of discussion around the regular expression engine used in Spidermonkey. We used to use yarr, which is the regular expression engine of Webkit. Though there were some issues here. We sometimes got wrong results, there were security issues and yarr hasn’t been updated in a while. As a result we switched to irregexp, the regular expression engine in v8 (the JS engine in Chrome). In the long run this helps by having a more up to date engine, which has jit to jit support and is more actively tested for security issues.
Read more about this in the bug report
Keep Ion code during GC
Another achievement that landed in Firefox 29 was the ability to keep ionmonkey jit code during GC. This required Type Inference changes. Type information (TI) was always cleared during GC and since ionmonkey code depends on it, the code became invalid and we had to throw the Ion code away. Since a few releases we can release Type information in chunks and since Firefox 32 we keep ionmonkey code that is active on the stack. This result in less bumps in performance during GC, since we don’t lose the Ion code.
Read more about this in the bug report
Generational GC
Already going back to 2011 Generational GC was announced. But it took a lot of work before finally accomplishing this. In Firefox 29 exact rooting landed, which was a prerequisite. Now we finally use a more advanced GC algorithm to collect the memory and this also paves the way for even more advanced GC algorithms. This narrowed the performance gap we had on the Octane benchmark compared to V8, which already had Generational GC.
8 bit strings
Since the first Spidermonkey release strings were always stored as a sequence of UTF-16 code units. So every string takes 16 bits per character. This is quite wasteful, since most of the strings don’t need the extended format and the characters actually fit nicely into 8 bits (Latin1 strings). From this release on strings will be stored in this smaller format when possible. The main idea was to decreases memory, but there were also some performance increases for string intensive tasks, since they now only need to operate over half the length.
ES6 template strings
ES6 will introduce something called template strings. These template strings are surrounded by backticks ( ` ) and among others will allow to create multi-line strings, which weren’t possible before. Template strings also enable to embed expressions into strings without using concatenation. Support for this feature has been introduced in Firefox 34.
Read more about ES6 template strings.
Copy on write
Some new optimization has been added regarding arrays. Before, when you copied an array, the JavaScript Engine had to copy every single item from the original array to the new array. Which can be an intensive operation for big arrays. In this release this pain has been decreased with the introduction of “Copy on write” arrays. In that case we only copy the content of an array when we start modifying the new array. That way we don’t need to allocate and copy the contents for arrays that get copied but not modified.
Read more about this in the bug report.
Inline global variable
A second optimization was about inlining constant global names and constant name access from singleton scope objects. This optimization will help performance for people having constant variables defined in the global scope. Instead of reading the constants out of memory every time the constant will get embedded into the code, just like if you would have written that constant. So now it is possible to have a “var DEBUG = false” and everywhere you test for DEBUG it will get replaced with ‘false’ and that branch will be removed.
Read more about this in the bug report
SIMD in asm.js
SIMD or Single Instruction Multiple Data makes it possible to execute the same operations on multiple inputs at the same time. Modern cpu’s already have support for this using 128-bits long vectors, but currently we don’t really have access to these speedups in JavaScript. SIMD.js is a proposition to expose this to JavaScript. In Firefox 34 experimental support (only available in Firefox Nightly builds) for these instructions in asm.js code were added. As a result making it possible to create code that can run up to 4x faster (Amdahl’s law) using SIMD. Now work is underway to fully optimize SIMD.js in all Ion-compiled JS. When this work is complete, and assuming continued progress in the standards committee, SIMD.js will be released to all Firefox users in a future version.
Read more about this change
Read more about this in the bug report
View the SIMD.js demos
|
|
Mike Conley: The Joy of Coding (or, Firefox Hacking Live!) |
A few months back, I started publishing my bug notes online, as a way of showing people what goes on inside a Firefox engineer’s head while fixing a bug.
This week, I’m upping the ante a bit: I’m going to live-hack on Firefox for an hour and a half for the next few Wednesday’s on Air Mozilla. I’m calling it The Joy of Coding1. I’ll be working on real Firefox bugs2 – not some toy exercise-bug where I’ve pre-planned where I’m going. It will be unscripted, unedited, and uncensored. But hopefully not uninteresting3!
Anyhow, the first episode airs this Wednesday. I’ll be using #livehacking on irc.mozilla.org as a backchannel. Not sure what bug(s) I’ll be hacking on – I guess it depends on what I get done on Monday and Tuesday.
Anyhow, we’ll try it for a few weeks to see if folks are interested in watching. Who knows, maybe we can get a few more developers doing this too – I’d enjoy seeing what other folks do to fix their bugs!
Anyhow, I hope to see you there!
http://mikeconley.ca/blog/2015/02/08/the-joy-of-coding-or-firefox-hacking-live/
|
|
Aaron Train: {{ post.title }} |
|
|
Liz Henry: Automated test harnesses for Firefox, zooming out a bit |
In December I was going through some of the steps to be able to change, fix, and interpret the results of a small subset of the gazillion automated tests that Mozilla runs on Firefox builds. My last post arrived at the point of being able to run mochitests locally on my laptop on the latest Firefox code. Over the holidays I dug further into the underlying situation and broaded my perspective. I wanted to make sure that I didn’t end up grubbing away at something that no one cared about or wasn’t missing the big picture.
My question was, how can I, or QA in general, understand where Firefox is with e10s (Electrolysis, the code name for the multiprocess Firefox project). Can I answer the question, are we ready to have e10s turned on by default in Firefox — for the Developer Edition (formerly known as Aurora), for Beta, and for a new release? What criteria are we judging by? Complicated. And given those things, how can we help move the project along and ensure good quality; Firefox that works as well as or, we hope, better than, Firefox with e10s not enabled? My coworker Juan and I boiled it down to basically, stability (lowering the crash rate) and automated test coverage. To answer my bigger questions about how to improve automated test coverage I had to kind of zoom out, and look from another angle. For Firefox developers a lot of what I am about to describe is basic knowledge. It seems worth explaining, since it took me significant time to figure out.
First of all let’s look at treeherder. Treeherder is kind of the new TBPL, which is the old new Tinderbox. It lets us monitor the current state of the code repositories and the tests that run against them. It is a window into Mozilla’s continuous integration setup. A battery of tests are poised to run against Firefox builds on many different platforms. Have a look!
Current view of mozilla-central on treeherder

Edward Tufte would have a cow. Luckily, this is not for Tufte to enjoy. And I love it. You can just keep digging around in there, and it will keep telling you things. What a weird, complicated gold mine.
Digression! When I first started working for Mozilla I went to the Automation and Tools team work week where they all came up with Treeherder. We wanted to name it something about Ents, because it is about the Tree(s) of the code repos. I explained the whole thing to my son, I think from the work week, which awesomely was in London. He was 11 or 12 at the time and he suggested the name “Yggdrazilla” keeping the -zilla theme and in reference to Yggdrasil, the World-Tree from Norse mythology. My son is pretty awesome. We had to reject that name because we can’t have more -zilla names and also no one would be able to spell Yggdrasil. Alas! So, anyway, treeherder.
The left side of the screen describes the latest batch of commits that were merged into mozilla-central. (The “tree” of code that is used to build Nightly.) On the right, there are a lot of operating systems/platforms listed. Linux opt (optimized version of Firefox for release) is at the top, along with a string of letters and numbers which we hope are green. Those letter and numbers represent batches of tests. You can hover over them to see a description. The tests marked M (1 2 3 etc) are mochitests, bc1 is mochitest-browser-chrome, dt are developer tools tests, and so on. For linux-opt you can see that there are some batches of tests with e10s in the name. We need the mochitest-plain tests to run on Firefox if it has e10s not enabled, or enabled. So the tests are duplicated, possibly changed to work under e10s, and renamed. We have M(1 2 3 . . .) tests, and also M-e10s(1 2 3 . . . ). Tests that are green are all passing. Orange means they aren’t passing. I am not quite sure what red (busted) means (bustage in the tree! red alert!) but let’s just worry about orange. (If you want to read more about the war on orange and what all this means, read Let’s have more green trees from Vaibhav’s blog. )
I kept asking, in order to figure out what needed doing that I could usefully do within the scope of As Soon As Possible, “So, what controls what tests are in which buckets? How do I know how many there are and what they are? Where are they in the codebase? How can I turn them on and off in a way that doesn’t break everything, or breaks it productively?” Good questions. Therefore the answers are long.
There are many other branches of the code other than mozilla-central. Holly is a branch where the builds for all the platforms have e10s enabled. (Many of these repos or branches or twigs or whatever, are named after different kinds of tree.) The tests are the standard set of tests, not particularly tweaked to allow for e10s. We can see what is succeeded and failing on treeherder’s view of holly. A lot of tests are orange on holly! Have a look at holly by clicking through on the link above. Here is a picture of the current state of holly.

If you click a batch of tests where there are some failures — an orange one — then a new panel will open up in treeherder! I will pick a juicy looking one. Right now, for MacOS 10.6 opt, M(2) is orange. Clicking it gives me a ton of info. Scrolling down a bit in the bottom left panel tells me this:
mochitest-plain-chunked 164546/12/14136
The first number is how many tests ran. Scary. Really? 164546 tests ran? Kind of. This is counting assertions, in other words, “is” statements from SimpleTest. The first number lists how many assertions passed. The second number is for assertion failures and the third is for “todo” statements.
The batches of tests running on holly are all running against an e10s build of Firefox. Anything that’s consistently green on holly, we can move over to mozilla-central by making some changes in mozharness. I asked a few people how to do this, and Jim Matthies helpfully pointed me at a past example in Bug 1061014. I figured I could make a stab at adding some of the newly passing tests in Bug 1122901.
As I looked at how to do this, I realized I needed commit access level 2 so I filed a bug to ask for that. And, I also tried merging mozilla-central to holly. That was ridiculously exciting though I hadn’t fixed anything yet. I was just bringing the branch up to date. On my first try doing this, I immediately got a ping on IRC from one of the sheriffs (who do merges and watch the state of the “tree” or code repository) asking me why I had done something irritating and wrong. It took us a bit to figure out what had happened. When I set up mercurial, the setup process and docs told me to install a bunch of Mozilla specific hg extensions. So, I had an extension set up to post to bugzilla every time I updated something. Since I was merging several weeks of one branch to another this touched hundreds of bugs, sending bugmail to untold numbers of people. Mercifully, Bugzilla cut this off after some limit was reached. It was so embarrassing I could feel myself turning beet red as I thought of how many people just saw my mistake and wondered what the heck I was doing. And yet just had to forge onwards, fix my config file, and try it again. Super nicely, Clint Talbert told me that the first time he tried pushing some change he broke all branches of every product and had no idea what had happened. Little did he know I would blog about his sad story to make myself feel less silly….. That was years ago and I think Mozilla was still using cvs at that point! I merged mozilla-central to holly again, did not break anything this time, and watched the tests run and gradually appear across the screen. Very cool.
I also ended up realizing that the changes to mozharness to turn these batches of tests on again were not super obvious and to figure it out I needed to read a 2000-line configuration file which has somewhat byzantine logic. I’m not judging it, it is clearly something that has grown organically over time and someone else probably in release engineering is an expert on it and can tweak it casually to do whatever is needed.
Back to our story. For a batch of tests on holly that have failures and thus are showing up on treeherder as orange, it should be possible to go through the logs for the failing tests, figure out how to turn them off with some skip-if statements, filing bugs for each skipped failing test. Then, keep doing that till a batch of tests is green and it is ready to be moved over.
That seems like a reasonable plan for improving the automated test landscape, which should help developers to know that their code works in Firefox whether e10s is enabled or not. In effect, having the tests should mean that many problems are prevented from ever becoming bugs. The effect of this test coverage is hard to measure. How do you prove something didn’t happen? Perhaps by looking at which e10s tests fail on pushes to the try server. Another issue here is that there are quite a lot of tests that have been around for many years. It is hard too know how many of them are useful, whether there are a lot of redundant tests, in short whether there is a lot of cruft and there probably is. With a bit more experience in the code and fixing and writing tests it would be easier to judge the usefulness of these tests.
I can also see that, despite this taking a while to figure out (and to even begin to explain) it is a good entry point to contributing to Firefox. It has more or less finite boundaries. If you can follow what I just described in this post and my last post, and you can read and follow a little python and javascript, then you can do this. And, if you were to go through many of the tests, over time you would end up understanding more about how the codebase is structured.
As usual when I dive into anything technical at Mozilla, I think it’s pretty cool that most of this work happens in the open. It is a great body of data for academics to study, it’s an example of how this work actually happens for anyone interested in the field, and it’s something that anyone can contribute to if they have the time and interest to put in some effort.
This post seems very plain with only some screenshots of Treeherder for illustration. Here, have a photo of me making friends with a chicken.

http://bookmaniac.org/automated-test-harnesses-for-firefox-zooming-out-a-bit/
|
|
Daniel Glazman: CSS Parser and Tokenizer API |
The first time I mentioned the need to reach the internal CSS parser of a rendering engine from JavaScript was 17 years ago during the CSS WG meeting I hosted at 'Electricit'e de France in 1998, during a corridor discussion. All the people around said it was out of question. Then I put it back on the table in 2002, with little success again. Today, I was actioned by the CSS WG and the TAG in the Houdini Task Force to start editing a new document (with Tab Atkins, Shane Stevens and Brian Kardell) called CSS Parser and Tokenizer API. It does not say it's going to be accepted or anything, but at least it went beyond the 5 minutes chat and rebuttal. I am extremely happy and proud  If we succeed making it happen, this is going to be a game-changer for a lot of web applications!!!
If we succeed making it happen, this is going to be a game-changer for a lot of web applications!!!
http://www.glazman.org/weblog/dotclear/index.php?post/2015/02/08/CSS-Parser-and-Tokenizer-API
|
|
Hannah Kane: User testing results |
This week I had the opportunity to conduct some user tests on Matthew’s wireframes for the Teach site.*
The goal of the user test was to validate the information architecture. We tested two nav variations:

Variation A

Variation B
Nav B performed slightly better, but both variations had some challenges. We shouldn’t draw any solid conclusions from the tests, partially because it wasn’t a large enough sample (we had five user testers, which meets the best practice standard, but since we tested two variations, we should have had more), and partially because most of the participants were highly familiar with our work already, making them a somewhat biased sample.
However, the user testers were fantastic, and we were able to generate some valuable insights that will be useful moving forward. Here are some of the key learnings:
That last point hints at a critical discussion we need to have about the various audiences we’re serving. Mentors who have regular access to learners have different needs from the mentors who don’t have that access. There are some overlapping needs, of course—namely, access to high-quality activities and professional development—but how we package those offerings will be different.
We’ll be exploring some options through the ongoing design process over the next few heartbeats.
Thanks to the very rad user testers who volunteered their time to help with this!
*I’m tempted to call this The Site That Shall Not Be Named, because the name is a little bit up in the air. It’s unlikely that we’ll go with “Teach.webmaker.org,” at least in part because our resources for teachers are not entirely tied to the Webmaker tools. In fact, our curriculum and resources are pretty tool-agnostic. “Mozilla Learning” might be a better encapsulation of our product offering.

|
|
Chris Ilias: My Installed Add-ons – gTranslate |
I love finding new extensions that do things I never even thought to search for. One of the best ways to find them is through word of mouth. In this case, I guess you can call it “word of blog”. I’m doing a series of blog posts about the extensions I use, and maybe you’ll see one that you want to use.
The first one is Context Search, which I’ve already blogged about.
The second is Clippings, which I’ve also blogged about.
The third is gTranslate. gTranslate is pretty simple – it translates text you’ve selected using Google’s translator. I find that I use it most on Facebook. Sure, Facebook has a built in translation tool, but that uses Bing, and I find that the Google translator works better.
On that note, if you prefer a different translation tool, there are probably other extensions that do the same thing, but use your preferred tool.
To translate text on the fly, just select the text you want to translate, right-click on it, and move the pointer to the context menu item called “Translate“. It should auto-detect the which language you are translating from, and show you the translation. If you want to change the language being translated, you can do so using the sub-menus.
![]()
You can install it via the Mozilla Add-ons site.
http://ilias.ca/blog/2015/02/my-installed-add-ons-gtranslate/
|
|
Stormy Peters: Who controls what you see online? |
During my FOSDEM talk, I spoke about how your phone company, hardware and operating system control what apps you have access to. Some phones bring internet access to those with no access but without the choice and freedom we expect on the web.
For example, in Zambia people are getting free internet from Facebook but they only have access to certain websites. As Eric Hal Schwartz from DCInno says, it’s a bit scary:
anyone in Zambia can get free access via the Internet.org website or its Android app to a limited number of websites and apps. While this is of course great for those who otherwise would have no Internet access at all, the arbitrary limits put on what they are allowed to do online arguably cedes way too much gatekeeper power to the companies behind the offering.
Kudos to Facebook and their partners for bringing internet access to people that didn’t have it. Hopefully they will also give them freedom and choice as well.
Related posts:
|
|
Daniel Pocock: Lumicall's 3rd Birthday |
Today, 6 February, is the third birthday of the Lumicall app for secure SIP on Android.

Lumicall's 1.0 tag was created in the Git repository on this day in 2012. It was released to the Google Play store, known as the Android Market back then, while I was in Brussels, the day after FOSDEM.
Since then, Lumicall has also become available through the F-Droid free software marketplace for Android and this is the recommended way to download it.
Most of the work on Lumicall itself has taken place in Switzerland. Many of the building blocks come from Switzerland's neighbours:
Lumicall also uses the reSIProcate project for server-side infrastructure. The repro SIP proxy and TURN server run on secure and reliable Debian servers in a leading Swiss data center.
Free communications is not just about avoiding excessive charges for phone calls. Free communications is about freedom.
In the three years Lumicall has been promoting freedom, the issue of communications privacy has grabbed more headlines than I could have ever imagined.
On 5 June 2013 I published a blog about the Gold Standard in Free Communications Technology. Just hours later a leading British newspaper, The Guardian, published damning revelations about the US Government spying on its own citizens. Within a week, Edward Snowden was a household name.
Google's Eric Schmidt had previously told us that "If you have something that you don't want anyone to know, maybe you shouldn't be doing it in the first place.". This statement is easily debunked: as CEO of a corporation listed on a public stock exchange, Schmidt and his senior executives are under an obligation to protect commercially sensitive information that could be used for crimes such as insider trading.
There is no guarantee that Lumicall will keep the most determined NSA agent out of your phone but nonetheless using a free and open source application for communications does help to avoid the defacto leakage of your conversations to a plethora of marketing and profiling companies that occurs when using a regular phone service or messaging app.
As I mentioned in my previous blog on Lumicall, the best way you can help Lumicall is by helping the F-Droid team. F-Droid provides a wonderful platform for distributing free software for Android and my own life really wouldn't be the same without it. It is a privilege for Lumicall to be featured in the F-Droid eco-system.
That said, if you try Lumicall and it doesn't work for you, please feel free to send details from the Android logs through the Lumicall issue tracker on Github and they will be looked at. It is impossible for Lumicall developers to test every possible phone but where errors are obvious in the logs some attempt can be made to fix them.
Another thing that has emerged in the three years since Lumicall was launched is WebRTC, browser based real-time communications and VoIP.
In its present form, WebRTC provides tremendous opportunities on the desktop but it does not displace the need for dedicated VoIP apps on mobile handsets. WebRTC applications using JavaScript are a demanding solution that don't integrate as seamlessly with the Android UI as a native app and they currently tend to be more intensive users of the battery.
Lumicall users can receive calls from desktop users with a WebRTC browser using the free calling from browser to mobile feature on the Lumicall web site. This service is powered by JSCommunicator and DruCall for Drupal.
|
|
Joel Maher: SETA – Search for Extraneous Test Automation |
Here at Mozilla we run dozens of builds and hundreds of test jobs for every push to a tree. As time has gone on, we have gone from a couple hours from push to all tests complete to 4+ hours. With the exception of a few test jobs, we could complete our test results in <2 hours if we had idle machines ready to run tests when the builds are finished. This doesn’t scale well, in fact we are only adding more platforms, more tests, and of course more pushes each month.
The question becomes, how do we manage to keep up test coverage without growing the number of machines? Right now we do this with buildbot coalescing (we queue up the jobs and skip the older ones when the load is high). While this works great, it causes us to skip a bunch of jobs (builds/tests) on random pushes and sometimes we need to go back in and manually schedule jobs to find failures. In fact, while keeping up with the automated alerts for talos regressions, the coalescing causes problems in over half of the regressions that I investigate!
Knowing that we live with coalescing and have for years, many of us started wondering if we need all of our tests. Ideally we could select tests that are statistically most significant to the changes being pushed, and if those pass, we could run the rest of the tests if there were available machines. To get there is tough, maybe there is a better way to solve this? Luckily we can mine meta data from treeherder (and the former tbpl) and determine which failures are intermittent and which have been fixed/caused by a different revision.
A few months ago we started looking into unique failures on the trees. Not just the failures, but which jobs failed. Normally when we have a failure detected by the automation, many jobs fail at once (for example: xpcshell tests will fail on all windows platforms, opt + debug). When you look at the common jobs which fail across all the failures over time, you can determine the minimum number of jobs required to detected all the failures. Keep in mind that we only need 1 job to represent a given failure.
As of today, we have data since August 13, 2014 (just shy of 180 days):
To phrase this another way, we could have run 77 jobs per push and caught every regression in the last 6 months. Lets back up a bit and look at the regressions found- how many are there and how often do we see them:

Cumulative and per day regressions
This is a lot of regressions, yay for automation. The problem is that this is historical data, not future data. Our tests, browser, and features change every day, this doesn’t seem very useful for predicting the future. This is a parallel to the stock market, there people invest in companies based on historical data and make decisions based on incoming data (press releases, quarterly earnings). This is the same concept. We have dozens of new failures every week, and if we only relied upon the 77 test jobs (which would catch all historical regressions) we would miss new ones. This is easy to detect, and we have mapped out the changes. Here it is on a calendar view (bold dates indicate a change was detected, i.e. a new job needed in the reduced set of jobs list):
 This translates to about 1.5 changes per week. To put this another way, if we were only running the 77 reduced set of jobs, we would have missed one regression December 2nd, and another December 16th, etc., or on average 1.5 regressions will be missed per week. In a scenario where we only ran the optional jobs once/hour on the integration branches, 1-2 times/week we would see a failure and have to backfill some jobs (as we currently do for coalesced jobs) for the last hour to find the push which caused the failure.
This translates to about 1.5 changes per week. To put this another way, if we were only running the 77 reduced set of jobs, we would have missed one regression December 2nd, and another December 16th, etc., or on average 1.5 regressions will be missed per week. In a scenario where we only ran the optional jobs once/hour on the integration branches, 1-2 times/week we would see a failure and have to backfill some jobs (as we currently do for coalesced jobs) for the last hour to find the push which caused the failure.
To put this into perspective, here is a similar view to what you would expect to see today on treeherder:
 For perspective, here is what it would look like assuming we only ran the reduced set of 77 jobs:
For perspective, here is what it would look like assuming we only ran the reduced set of 77 jobs:
 * keep in mind this is weighted such that we prefer to run jobs on linux* builds since those run in the cloud.
* keep in mind this is weighted such that we prefer to run jobs on linux* builds since those run in the cloud.
With all of this information, what do we plan to do with it? We plan to run the reduced set of jobs by default on all pushes, and use the [285] optional jobs as candidates for coalescing. Currently we force coalescing for debug unittests. This was done about 6 months ago because debug tests take considerably longer than opt, so if we could run them on every 2nd or 3rd build, we would save a lot of machine time. This is only being considered on integration trees that the sheriffs monitor (mozilla-inbound, fx-team).
Some questions that are commonly asked:
Thanks for reading so far! This project wouldn’t be here it it wasn’t for the many hours of work by Vaibhav, he continues to find more ways to contribute to Mozilla. If anything this should inspire you to think more about how our scheduling works and what great things we can do if we think out of the box.

https://elvis314.wordpress.com/2015/02/06/seta-search-for-extraneous-test-automation/
|
|
Mozilla WebDev Community: Webdev Extravaganza – February 2015 |
Once a month, web developers from across Mozilla get together to build a physical symbol of our cooperation in the form of a bikeshed. While we thoughtfully determine what color to paint it, we find time to talk about the work that we’ve shipped, share the libraries we’re working on, meet new folks, and talk about whatever else is on our minds. It’s the Webdev Extravaganza! The meeting is open to the public; you should stop by!
You can check out the wiki page that we use to organize the meeting, or view a recording of the meeting in Air Mozilla. Or just read on for a summary!
The shipping celebration is for anything we finished and deployed in the past month, whether it be a brand new site, an upgrade to an existing one, or even a release of a library.
ErikRose shared news about the release of peep 2.2, which, among other things, adds a progress bar to the install process. He also called out sugardough and AirMozilla, both of which now use peep for installing dependencies.
Erik also announced the 1.0 release of pyelasticsearch. The release adds support for modern versions of ElasticSearch, Python 3.x support, and a 15x improvement in speed from optimizations made for DXR.
I myself shared news about a recent fix we deployed on the Snippets Service that allows us to send much more data without crashing the service. Previously, we could only send about 1.5 megabytes of snippet data to each user before the service stopped being able to keep up with data transfer, but by pre-generating snippet bundles and sending users redirects to them instead of returning them directly, we were able to send upwards of 4 megabytes with only a 10ms increase in average response time.
lorchard is interested in working on badges.mozilla.org again, and started by modernizing the codebase by switching from vendor submodules to peep + virtualenv, starting to move away from Playdoh, replacing Vagrant and Puppet with Docker and Fig, upgrading the dependencies, and more!
Peterbe shared the news that mozillians.org and Marketplace both have contribute.json files now. He also shared a list he generated of Webdev websites that still don’t have contribute.json files.
Hoosteeno wanted to let us know about the release of the results of MDN’s Web Developer Services survey. MDN surveyed over a thousand web developers and asked them what services they use as part of their development. The results will be used to inform work on developer services and is also freely available to anyone else who finds the data useful.
Mythmon shared a small note about how SUMO is now running on Python 2.7, allowing them to stay up-to-date with the latest Django releases and avoid the oncoming apocalypse of having no version of Django that supports Python 2.6 and is receiving security patches. Get to upgrading, kids!
In a sudden turn of events, pmac called for a Scuttling Celebration to announce the end of ScrumBugz. The website will be taken down by the end of the quarter, as no one seems to be using it anymore.
Here we talk about libraries we’re maintaining and what, if anything, we need help with for them.
Peterbe, on behalf of Pomax, shared the in-development project template for client-side apps being developed by the Mozilla Foundation folks, mofo-example-app. The template aims to implement the wisdom contained in the MoFo Engineering Handbook.
Here we introduce any newcomers to the Webdev group, including new employees, interns, volunteers, or any other form of contributor.
Though not really new hires, espressive and I have swapped teams, so that I am now on the Engineering Tools team and he is on the Web Productions team. Espressive will be focusing on frontend work for Engagement campaigns, while I’ll be focusing on developing tools and any other engineering work that makes Web Developers at Mozilla happier. Everyone wins!
The Roundtable is the home for discussions that don’t fit anywhere else.
Peterbe wanted to share a new page on AirMozilla: the contributor list! A list of contributors is stored in the AirMo settings file, and their info and pictures are pulled from Mozillians and displayed on the site as a way to give thanks for their help. Contributors must opt-in by joining a moderated group on Mozillians as well. Neat!
Unfortunately, the Burgundy and Celadon camps couldn’t come to an agreement in time for us to finish the shed. There’s always next month!
If you’re interested in web development at Mozilla, or want to attend next month’s Extravaganza, subscribe to the dev-webdev@lists.mozilla.org mailing list to be notified of the next meeting, and maybe send a message introducing yourself. We’d love to meet you!
See you next month!
https://blog.mozilla.org/webdev/2015/02/06/webdev-extravaganza-february-2015/
|
|
Air Mozilla: Webmaker Demos February 6 2015 |
 Webmaker Demos February 6 2015
Webmaker Demos February 6 2015
|
|
Gijs Kruitbosch: YEINU – Your Experience Is Not Universal – continued! |
Working on Firefox front-end code, I am often reminded of Nicholas’ excellent post on people’s experiences and how those experiences shape their opinions.
The most recent example concerns the beforeunload event and the resulting dialog.
On the one hand there are people who see it as the bane of a usable web. They mostly encounter it when it is abused by malicious websites to trap users on a page they don’t want them to leave, and so they view it as a misfeature that should have been removed from the relevant specs 10 years ago. Websites shouldn’t be able to keep a tab open at all! They honestly and sincerely see no reason why on earth Firefox (and most other desktop browsers) still support it.
On the other there are people who see it as critical web infrastructure to ensure users can’t accidentally close a tab/window while in the middle of a task, causing data loss, and for that reason they honestly and sincerely see no reason why we’re even talking about getting rid of it. “Even” Facebook and Google Apps, who otherwise have decent facilities for saving drafts etc., will use it in some cases.
Even when this discrepancy in experience and their resulting opinions is pointed out, people who hold opinions on the extreme end of this spectrum seem reluctant to accept that really, there might be both pros and cons involved here, and a solution is not so straightforward as either believed.
If/when they do, the solution offered is usually “make it a preference”, with resulting debate about what the default should be (NB: in this case, such a (hidden) preference was already added). However, this is not what we prefer doing when working on Firefox, we historically haven’t, and still don’t.
I’d be interested if people have suggestions on how we could concretely address both usecases in the example I used, in a way that makes life better for both groups of users. For the latter, note that the event causes other technical difficulties even when not used for ‘trapping’ users, and that mobile browsers have already started disregarding it in some cases.
At this point, the best plan I know of is not showing a dialog when closing a single tab, perhaps while keeping the dialog for application/window closes and navigation. (For concrete followups regarding this particular issue, please consider writing to firefox-dev instead of commenting here.)
However, finding a solution for “beforeunload” and its dialog doesn’t solve the more general problem: how do you bridge the gap in the general case and explain why we are not “just” doing what seems “obvious”? How do you turn the fierce disagreement into a constructive solution-oriented discussion?
http://www.gijsk.com/blog/2015/02/yeinu-your-experience-is-not-universal-continued/
|
|
Ben Kero: Trends in Mozilla’s central codebase |
UPDATE: By popular demand I’ve added numbers for beta, aurora, and m-c tip
As part of my recent duties I’ve been looking at trends in Mozilla’s monolithic source code repository mozilla-central. As we’re investigating growth patterns and scalability I thought it would be useful to get metrics about the size of the repositories over time, and in what ways it changes.
It should be noted that the sizes are for all of mozilla-central, which is Firefox and several other Mozilla products. I chose Firefox versions as they are useful historical points. As of this posting (2015-02-06) version 36 is Beta, 37 is Aurora, and 38 is tip of mozilla-central.

UPDATE: This newly generated graph shows that there was a sharp increase in the amount of code around v15 without a similarly sharp rise of working copy size. As this size was calculated with ‘du’, it will not count hardlinked files twice. Perhaps the size of the source code files is insignificant compared to other binaries in the repository. The recent (v34 to v35) increase in working copy size could be due to added assets for the developer edition (thanks hwine!)
My teammate Gregory Szorc has reminded me that since this size is based off a working copy, it is not necessarily accurate as stored in Mercurial. Since most of our files are under 4k bytes they will use up more space (4k) when in a working copy.
From this we can see a few things. The line count scales linearly with the size of a working copy. Except at the beginning, where it was about half the ratio until about Firefox version 18. I haven’t investigated why this is, although my initial suspicion is that it might be caused by there being more image glyphs or other binary data compared to the amount of source code.
Also interesting is that Firefox 5 is about 3.4 million lines of code while Firefox 35 is almost exactly 6.6 million lines. That’s almost a doubling in the amount of source code comprising mozilla-central. For reference, Firefox 5 was released around 2011/06/21 and Firefox 35 was released on 1/13/2015. That’s about two and a half years of development to double the codebase.
If I had graphed back to Firefox 1.5 I am confident that we would see an increasing rate at which code is being committed. You can almost begin to see it by comparing the difference between v5 and v15 to v20 and v30.
I’d like to continue my research into how the code is evolving, where exactly the large size growth came from between v34 and v35, and some other interesting statistics about how individual files evolve in terms of size, additions/removals per version, and which areas show the greatest change between versions.
If you’re interested in the raw data collected to make this graph, feel free to take a look at this spreadsheet.
The source lines of code count was generated using David A. Wheeler’s SLOCCount.
|
|
Giorgio Maone: NoScript Does Accept Bitcoin Donations |
It just occurred to me that Google did not know about tweets at the time I wrote this one:
So you want to donate in #bitcoin to help NoScript's development? Now you can, bitcoin:1H4kTbFK1zVWiXjvZxhmxoaJW4dukJHcdb
Since I routinely receive inquiries from potential bitcoin donors, I hope this post to be easier to find.
https://hackademix.net/2015/02/06/noscript-does-accept-bitcoin-donations/
|
|






