Mozilla Addons Blog: Extensions in Firefox 78 |
In Firefox 78, we’ve done a lot of the changes under the hood. This includes preparation for changes coming up in Firefox 79, improvements to our tests, and improvements to make our code more resilient. There are three things I’d like to highlight for this release:
saveAs option set to true, the recently used directory is now remembered on a per-extension basis. For example, a user of a video downloader would benefit from not having to navigate to their videos folder every time the extension offers a file to download.These and other changes were brought to you by Atique Ahmed Ziad, Tom Schuster, Mark Smith, as well as various teams at Mozilla. A big thanks to everyone involved in the subtle but important changes to WebExtensions in Firefox.
The post Extensions in Firefox 78 appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2020/06/29/extensions-in-firefox-78/
|
|
Firefox UX: The Poetics of Product Copy: What UX Writers Can Learn From Poetry |
Excerpts: “This Is Just To Say” by William Carlos Williams and a Firefox error message
Word nerds make their way into user experience (UX) writing from a variety of professional backgrounds. Some of the more common inroads are journalism and copywriting. Another, perhaps less expected path is poetry.
I’m a UX content strategist, but I spent many of my academic years studying and writing poetry. As it turns out, those years weren’t just enjoyable — they were useful preparation for designing product copy.
Poetry and product copy wrestle with similar constraints and considerations. They are each often limited to a small amount of space and thus require an especially thoughtful handling of language that results in a particular kind of grace.
While the high art of poetry and the practical, business-oriented work of UX are certainly not synonymous, there are some key parallels to learn from as a practicing content designer.
Poets look closely at the human experience. We use the details of the personal to communicate a universal truth. And how that truth is communicated — the context, style, and tone — reflect the culture and moment in time. When a poem makes its mark, it hits a collective nerve.

“Tired” by Langston Hughes
Like poetry, product copy looks closely at the human experience, and its language reflects the culture from which it was born. As technology has become omnipresent in our lives, the language of the interface has, in turn, become more conversational. “404 Not Found” messages are (ideally) replaced with plain language. Emojis and Hmms are sprinkled throughout the digital experience, riding the tide of memes and tweets that signify an increasingly informal culture. You can read more about the relationship between technology and communication in Erika Hall’s seminal work, Conversational Design.
While the topic at hand is often considerably less exalted than that of poetry, a UX writer similarly considers the details of a moment in time. Good copy is informed by what the user is experiencing and feeling — the frustration of a failed page load or the success of a saved login — and crafts content sensitive to that context.
Product copy strikes the wrong note when it fails to be empathetic to that moment. For example, it’s unhelpful to use technical jargon or make a clever joke when a user encounters a dead end. This insensitivity is made more acute if the person is using the interface to navigate a stressful life event, like filing for leave when a loved one is ill. What they need in that moment is plain language and clear instructions on a path forward.
Poetry helps us make sense of complexity through language. We turn to poetry to feel our way through dark times — the loss of a loved one or a major illness — and to commemorate happy times — new love, the beauty of the natural world. Poetry finds the words to help us understand an experience and (hopefully) move forward.

Excerpt: “Toad” by Diane Seuss
UX writers also use the building blocks of language to help a user move forward and through an experience. UX writing requires a variety of skills, including the ability to ask good questions, to listen well, to collaborate, and to conduct research. The foundational skill, however, is using language to bring clarity to an experience. Words are the material UX writers use to co-create experiences with designers, researchers, and developers.
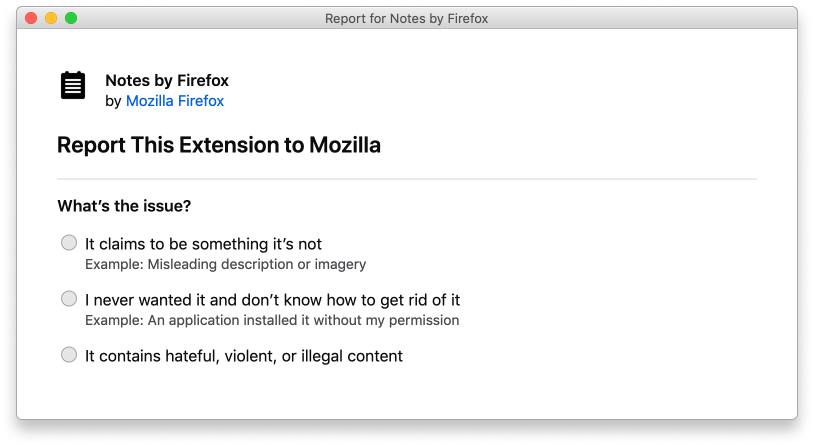
Excerpt of a screen for Firefox users to report an issue with a browser extension. The flow enables the user to report an extension, troubleshoot issues, and remove the extension. Co-created with designer Philip Walmsley.
“Poetry is your best source of deliberate intentional language that has nothing to do with your actual work. Reading it will descale your mind, like vinegar in a coffee maker.” — Conversational Design, Erika Hall
Poetry considers word choice carefully. And, while poetry takes many forms and lengths, its hallmark is brevity. Unlike a novel, a poem can begin and end on one page, or even a few words. The poet often uses language to get the reader to pause and reflect.
Product copy should help users complete tasks. Clarity trumps conciseness, but we often find that fewer words — or no words at all — are what the user needs to get things done. While we will include additional language and actions to add friction to an experience when necessary, our goal in UX writing is often to get out of the user’s way. In this way, while poetry has a slowing function, product copy can have a streamlining function.
Working within these constraints requires UX writers to also consider each word very carefully. A button that says “Okay!” can mean something very different, and has a different tone, than a button that says, “Submit.” Seemingly subtle changes in word choice or phrasing can have a big impact, as they do in poetry.
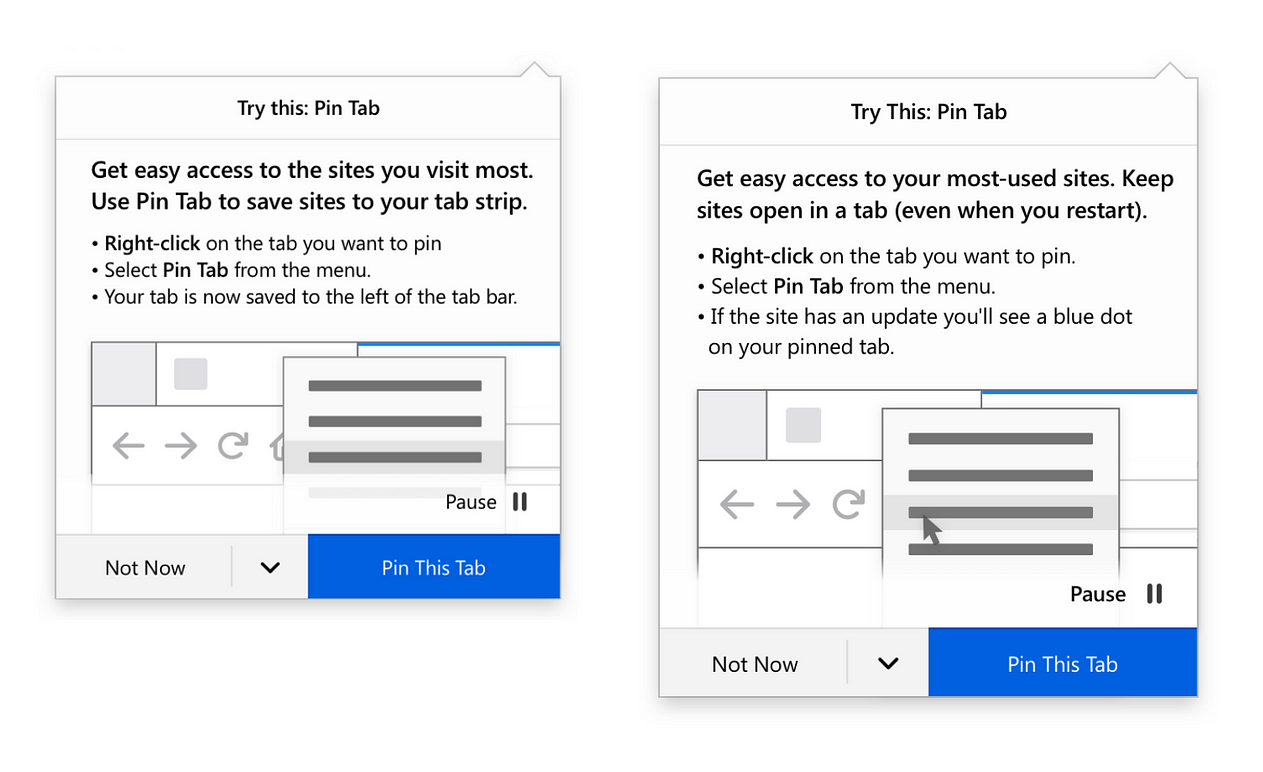
Left: Early draft of a recommendation panel for the Firefox Pin Tab feature. Right: final copy, which does not include the descriptors “tap strip” or “tab bar” because users might not be familiar with these terms. A small copy change like using “open in a tab” instead of “tab strip” can have a big impact on user comprehension. Co-created with designer Amy Lee.
Reading a poem can feel like you are walking into the middle of a conversation. And you have — the poet invites you to reflect on a moment in time, a feeling, a place. And yet, even as you pause, poetry has a sense of moment — metaphor and imagery connect and build quickly in a small amount of space. You tumble over one line break on to the next.

Excerpt: “Bedtime Story” by Franny Choi
Product copy captures a series of moments in time. But, rather than walking into a conversation, you are initiating it and participating in it. One of the hallmarks of product copy, in contrast to other types of professional writing, is its movement — you aren’t writing for a billboard, but for an interface that is responsive and conditional.
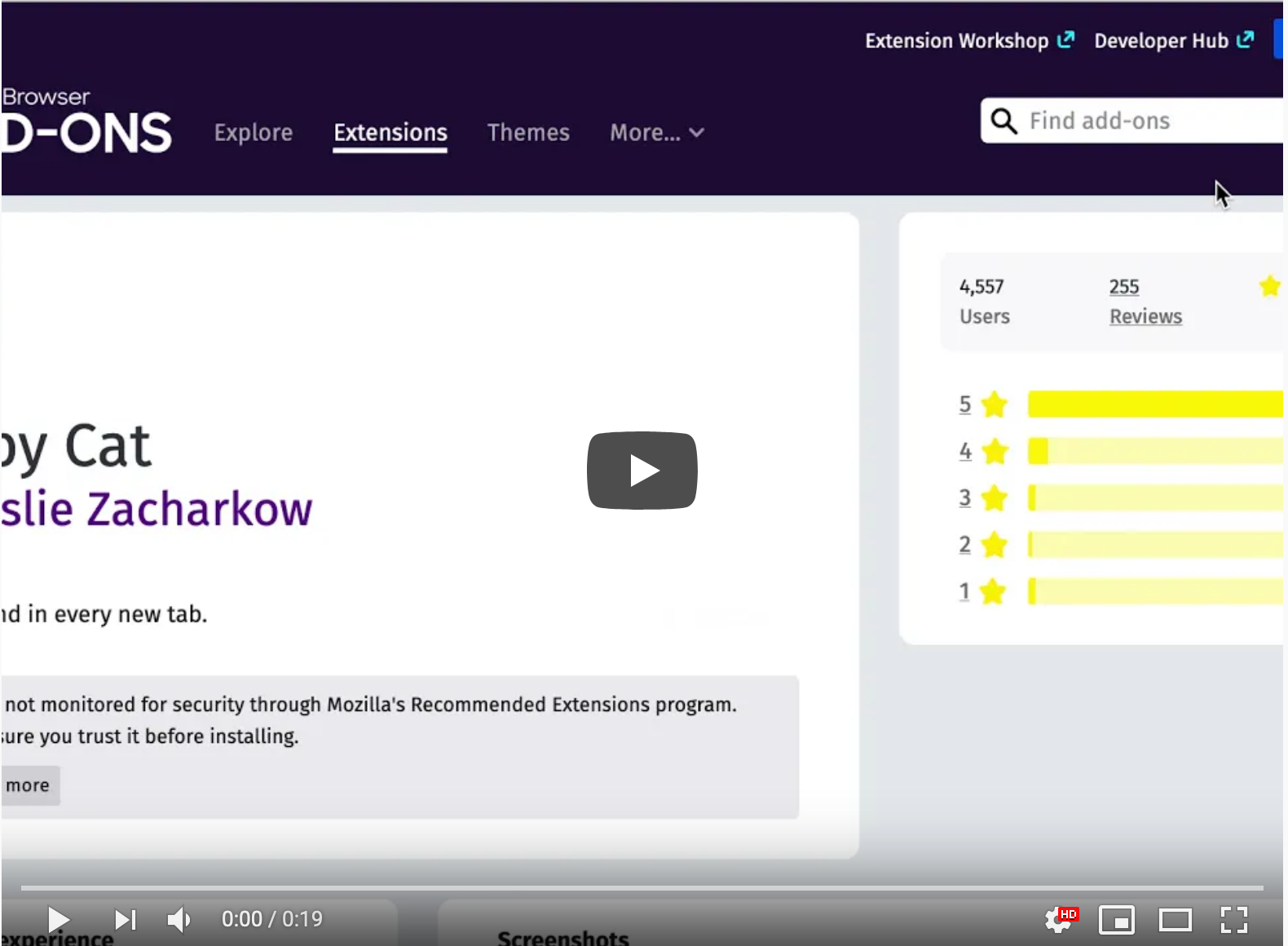
The installation flow for the browser extension, Tabby Cat, demonstrates the changing nature of UX copy. Co-created with designer Emanuela Damiani.
Poetry communicates through language, but also through visual presentation. Unlike a novel, where words can run from page to page like water, a poet conducts flow more tightly in its physical space. Line breaks are chosen with intention. A poem can sit squat, crisp and contained as a haiku, or expand like Allen Ginsburg’s Howl across the page, mirroring the wild discontent of the counterculture movement it captures.
Product copy is also conscious of space, and uses it to communicate a message. We parse and prioritize UX copy into headers and subheadings. We chunk explanatory content into paragraphs and bullet points to make the content more consumable.
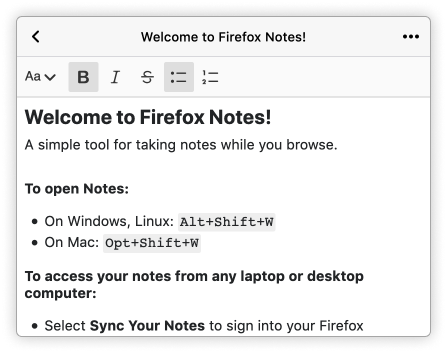
The introductory note for the Firefox Notes extension uses type size, bold text, and bullet points to organize the instructions and increase scannability.
Poetry often plays with the rules of grammar. Words can be untethered from sentences, floating off across the page. Sentences are uncontained with no periods, frequently enjambed.

Excerpt: “[i carry your heart with me(i carry it in]” by E. E. Cummings
In product writing, we also play with grammar. We assign different rules to text elements for purposes of clarity — for example, allowing fragments for form labels and radio buttons. While poetry employs these devices to make meaning, product writing bends or breaks grammar rules so content doesn’t get in the way of meaning — excessive punctuation and title case can slow a reader down, for example.
“While mechanics and sentence structure are important, it’s more important that your writing is clear, helpful, and appropriate for each situation.” — Michael Metts and Andy Welfle, Writing is Designing
While people come to this growing profession from different fields, there’s no “right” one that makes you a good UX writer.
As we continue to define and professionalize the practice, it’s useful to reflect on what we can incorporate from our origin fields. In the case of poetry, key points are constraint and consideration. Both poet and product writer often have a small amount of space to move the audience — emotionally, as is the case for poetry, and literally as is the case for product copy.
If we consider the metaphor of baking, a novel would be more like a Thanksgiving meal. You have many hours and dishes to choreograph an experience. Many opportunities to get something wrong or right. A poem, and a piece of product copy, have just one chance to make an impression and do their work.
In this way, poetry and product copy are more like a single scallop served at a Michelin restaurant — but one that has been marinated in carefully chosen spices, and artfully arranged with a puff of lemon truffle foam and Timut pepper reduction. Each element in this tiny concert of flavors carefully, painstakingly composed.
Acknowledgements
Thank you to Michelle Heubusch and Betsy Mikel for your review.
|
|
Daniel Stenberg: curl ootw: –remote-time |
Previous command line options of the week.
--remote-time is a boolean flag using the -R short option. This option was added to curl 7.9 back in September 2001.
One of the most basic curl use cases is “downloading a file”. When the URL identifies a specific remote resource and the command line transfers the data of that resource to the local file system:
curl https://example.com/file -O
This command line will then copy every single byte of that file and create a duplicated resource locally – with a time stamp using the current time. Having this time stamp as a default seems natural as it was created just now and it makes it work fine with other options such as --time-cond.
There are times when you rather want the download to get the exact same modification date and time as the remote file has. We made --remote-time do that.
By adding this command line option, curl will figure out the exact date and time of the remote file and set that same time stamp on the file it creates locally.
This option works with several protocols, including FTP, but there are and will be many situations in which curl cannot figure out the remote time – sometimes simply because the server won’t tell – and then curl will simply not be able to copy the time stamp and it will instead keep the current date and time.
This option is not by default because.
As mentioned briefly above, the --remote-time command line option can be really useful to combine with the --time-cond flag. An example of a practical use case for this is a command line that you can invoke repeatedly, but only downloads the new file in case it was updated remotely since the previous time it was downloaded! Like this:
curl --remote-name --time-cond cacert.pem https://curl.haxx.se/ca/cacert.pem
This particular example comes from the curl’s CA extract web page and downloads the latest Mozilla CA store as a PEM file.
https://daniel.haxx.se/blog/2020/06/29/curl-ootw-remote-time/
|
|
Mark Banner: Thunderbird Conversations 3.1 Released |
Thunderbird Conversations is an add-on for Thunderbird that provides a conversation view for messages. It groups message threads together, including those stored in different folders, and allows easier reading and control for a more efficient workflow.

Over the last couple of years, Conversations has been largely rewritten to adapt to changes in Thunderbird’s architecture for add-ons. Conversations 3.1 is the result of that effort so far.

The new version will work with Thunderbird 68, and Thunderbird 78 that will be released soon.

The one feature that is currently missing after the rewrite is inline quick reply. This has been of lower priority, as we have focussed on being able to keep the main part of the add-on running with the newer versions of Thunderbird. However, now that 3.1 is stable, I hope to be able to start work on a new version of quick reply soon.
More rewriting will also be continuing for the foreseeable future to further support Thunderbird’s new architecture. I’m planning a more technical blog post about this in future.
If you find an issue, or would like to help contribute to Conversations’ code, please head over to our GitHub repository.
The post Thunderbird Conversations 3.1 Released appeared first on Standard8's Blog.
https://www.thebanners.uk/standard8/2020/06/28/thunderbird-conversations-3-1-released/
|
|
Cameron Kaiser: TenFourFox FPR24 available |
I don't have a clear direction for FPR25. As I said, a lot of the low hanging fruit is already picked, and some of the bigger projects are probably too big for a single developer trying to keep up with monthly releases (and do not lend themselves well to progressive implementation). I'll do some pondering in the meantime.
http://tenfourfox.blogspot.com/2020/06/tenfourfox-fpr24-available.html
|
|
The Mozilla Blog: More details on Comcast as a Trusted Recursive Resolver |
 Yesterday Mozilla and Comcast announced that Comcast was the latest member of Mozilla’s Trusted Recursive Resolver program, joining current partners Cloudflare and NextDNS. Comcast is the first Internet Service Provider (ISP) to become a TRR and this represents a new phase in our DoH/TRR deployment.
Yesterday Mozilla and Comcast announced that Comcast was the latest member of Mozilla’s Trusted Recursive Resolver program, joining current partners Cloudflare and NextDNS. Comcast is the first Internet Service Provider (ISP) to become a TRR and this represents a new phase in our DoH/TRR deployment.
When Mozilla first started looking at how to deploy DoH we quickly realized that it wasn’t enough to just encrypt the data; we had to ensure that Firefox used a resolver which they could trust. To do this, we created the Trusted Recursive Resolver (TRR) program which allowed us to partner with specific resolvers committed to strong policies for protecting user data. We selected Cloudflare as our first TRR (and the current default) because they shared our commitment to user privacy and security because we knew that they were able to handle as much traffic as we could send them. This allowed us to provide secure DNS resolution to as many users as possible but also meant changing people’s resolver to Cloudflare. We know that there have been some concerns about this. In particular:
If we were able to verify that the ISP had strong privacy policies then we could use their resolver instead of a public resolver like Cloudflare. Verifying this would of course require that the ISP deploy DoH — which more and more ISPs are doing — and join our TRR program, which is exactly what Comcast has done. Over the next few months we’ll be experimenting with using Comcast’s DoH resolver when we detect that we are on a Comcast network.
Jason Livingood from Comcast and I have published an Internet-Draft describing how resolver selection works, but here’s the short version of what we’re going to be experimenting with. Note: this is all written in the present tense, but we haven’t rolled the experiment out just yet, so this isn’t what’s happening now. It’s also US only, because this is the only place where we have DoH on by default.
First, Comcast inserts a new DNS record on their own recursive resolver for a “special use” domain called doh.test with a value of doh-discovery.xfinity.com The meaning of this record is just “this network supports DoH and here is the name of the resolver.”
When Firefox joins a network, it uses the ordinary system resolver to look up doh.test. If there’s nothing there, then it just uses the default TRR (currently Cloudflare). However, if there is a record there, Firefox looks it up in an internal list of TRRs. If there is a match to Comcast (or a future ISP TRR) then we use that TRR instead. Otherwise, we fall back to the default.
What’s special about the “doh.test” name is that nobody owns “.test”; it’s specifically reserved for local use so it’s fine for Comcast to put its own data there. If another ISP were to want to do the same thing, they would populate doh.test with their own resolver name. This means that Firefox can do the same check on every network.
The end result is that if we’re on a network whose resolver is part of our TRR program then we use that resolver. Otherwise we use the default resolver.
One natural question to ask is how this impacts user privacy? We need to analyze this in two parts.
First, let’s examine the case of someone who only uses their computer on a Comcast network (if you never use a Comcast network, then this has no impact on you). Right now, we would send your DNS traffic to Cloudflare, but the mechanism above would send it to Comcast instead. As I mentioned above, both Comcast and Cloudflare have committed to strong privacy policies, and so the choice between trusted resolvers is less important than it otherwise might be. Put differently: every resolver in the TRR list is trusted, so choosing between them is not a problem.
With that said, we should also look at the technical situation (see here for more thoughts on technical versus policy controls). In the current setting, using your ISP resolver probably results in somewhat less exposure of your data to third parties because the ISP has a number of other — albeit less convenient — mechanisms for learning about your browsing history, such as the IP addresses you are going to and the TLS Server Name Indication field. However, once TLS Encrypted Client Hello starts being deployed, the Server Name Indication will be less useful and so there will be less difference between the cases.
The situation is somewhat more complicated for someone who uses both a Comcast and non-Comcast network. In that case, both Comcast and Cloudflare will see pieces of their browsing history, which isn’t totally ideal and is something we otherwise try to avoid. Our current view is that the advantages of using a trusted local resolver when available outweigh the disadvantages of using multiple trusted resolvers, but we’re still analyzing the situation and our thinking may change as we get more data.
One thing I want to emphasize here is that if you have a DoH resolver you prefer to use, you can set it yourself in Firefox Network Settings and that will override the automatic selection mechanisms.
As we said when we started working on DoH/TRR deployment two years ago, you can’t practically negotiate with your resolver, but Firefox can do it for you, so we’re really pleased to have Comcast join us as a TRR partner.
The post More details on Comcast as a Trusted Recursive Resolver appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2020/06/26/more-details-on-comcast-as-a-trusted-recursive-resolver/
|
|
Daniel Stenberg: bug-bounty reward amounts in curl |
A while ago I tweeted the good news that we’ve handed over our largest single monetary reward yet in the curl bug-bounty program: 700 USD. We announced this security problem in association with the curl 7.71.0 release the other day.
Someone responded to me and wanted this clarified: we award 700 USD to someone for reporting a curl bug that potentially affects users on virtually every computer system out there – while Apple just days earlier awarded a researcher 100,000 USD for an Apple-specific security flaw.
The difference in “amplitude” is notable.
I think first we should start with appreciating that we have a bug-bounty program at all! Most open source projects don’t, and we didn’t have any program like this for the first twenty or so years. Our program is just getting started and we’re getting up to speed.
How can we in the curl project hand out any money at all? We get donations from companies and individuals. This is the only source of funds we have. We can only give away rewards if we have enough donations in our fund.
When we started the bug-bounty, we also rather recently had started to get donations (to our Open Collective fund) and we were careful to not promise higher amounts than we would be able to pay, as we couldn’t be sure how many problems people would report and exactly how it would take off.
Over time it has gradually become clear that we’re getting donations at a level and frequency that far surpasses what we’re handing out as bug-bounty rewards. As a direct result of that, we’ve agreed in the the curl security team to increase the amounts.
For all security reports we get now that end up in a confirmed security advisory, we will increase the handed out award amount – until we reach a level we feel we can be proud of and stand for. I think that level should be more than 1,000 USD even for the lowest graded issues – and maybe ten times that amount for an issue graded “high”. We will however never get even within a few magnitudes of what the giants can offer.

The graph with number of reported CVEs per year shows that we started to get a serious number of reports in 2013 (5 reports) and it also seems to show that we’ve passed the peak. I’m not sure we have enough enough data and evidence to back this up, but I’m convinced we do a lot of things much better in the project now that should help to keep the amount of reports down going forward. In a few years when we look back we can see if I was right.
We’re at mid year 2020 now with only two reports so far, which if we keep this rate will make this the best CVE-year after 2012. This, while we offer more money than ever for reported issues and we have a larger amount of code than ever to find problems in.

One company suggests that they will chip in and pay for an increased curl bug bounty if the problem affects their use case, but for some reason the problems just never seem to affect them and I’ve pretty much stopped bothering to even ask them.
curl is shipped with a large number of operating systems and in a large number of applications but yet not even the large volume users participate in the curl bug bounty program but leave it to us (and they rarely even donate). Perhaps you can report curl security issues to them and have a chance of a higher reward?
You would possibly imagine that these companies should be keen on helping us out to indirectly secure users of their operating systems and applications, but no. We’re an open source project. They can use our products for free and they do, and our products improve their end products. But if there’s a problem in our stuff, that issue is ours to sort out and fix and those companies can then subsequently upgrade to the corrected version…
This is not a complaint, just an observation. I personally appreciate the freedom this gives us.
Help us review code. Report bugs. Report all security related problems you can find or suspect exists. Get your company to sponsor us. Write awesome pull requests that improve curl and the way it does things. Use curl and libcurl in your programs and projects. Buy commercial curl support from the best and only provider of commercial curl support.

https://daniel.haxx.se/blog/2020/06/25/bug-bounty-reward-amounts-in-curl/
|
|
The Mozilla Blog: Comcast’s Xfinity Internet Service Joins Firefox’s Trusted Recursive Resolver Program |
Committing to Data Retention and Transparency Requirements That Protect Customer Privacy
Today, Mozilla, the maker of Firefox, and Comcast have announced Comcast as the first Internet Service Provider (ISP) to provide Firefox users with private and secure encrypted Domain Name System (DNS) services through Mozilla’s Trusted Recursive Resolver (TRR) Program. Comcast has taken major steps to protect customer privacy as it works to evolve DNS resolution.
“Comcast has moved quickly to adopt DNS encryption technology and we’re excited to have them join the TRR program,” said Eric Rescorla, Firefox CTO. “Bringing ISPs into the TRR program helps us protect user privacy online without disrupting existing user experiences. We hope this sets a precedent for further cooperation between browsers and ISPs.”
For more than 35 years, DNS has served as a key mechanism for accessing sites and services on the internet. Functioning as the internet’s address book, DNS translates website names, like Firefox.com and xfinity.com, into the internet addresses that a computer understands so that the browser can load the correct website.
Over the last few years, Mozilla, Comcast, and other industry stakeholders have been working to develop, standardize, and deploy a technology called (DoH). DoH helps to protect browsing activity from interception, manipulation, and collection in the middle of the network by encrypting the DNS data.
Encrypting DNS data with DoH is the first step. A necessary second step is to require that the companies handling this data have appropriate rules in place – like the ones outlined in Mozilla’s TRR Program. This program aims to standardize requirements in three areas: limiting data collection and retention from the resolver, ensuring transparency for any data retention that does occur, and limiting any potential use of the resolver to block access or modify content. By combining the technology, DoH, with strict operational requirements for those implementing it, participants take an important step toward improving user privacy.
Comcast launched public beta testing of DoH in October 2019. Since then, the company has continued to improve the service and has collaborated with others in the industry via the Internet Engineering Task Force, the Encrypted DNS Deployment Initiative, and other industry organizations around the world. This collaboration also helps to ensure that users’ security and parental control functions that depend on DNS are not disrupted in the upgrade to encryption whenever possible. Also in October, Comcast announced a series of key privacy commitments, including reaffirming its longstanding commitment not to track the websites that customers visit or the apps they use through their broadband connections. Comcast also introduced a new Xfinity Privacy Center to help customers manage and control their privacy settings and learn about its privacy policy in detail.
“We’re proud to be the first ISP to join with Mozilla to support this important evolution of DNS privacy. Engaging with the global technology community gives us better tools to protect our customers, and partnerships like this advance our mission to make our customers’ internet experience more private and secure,” said Jason Livingood, Vice President, Technology Policy and Standards at Comcast Cable.
Comcast is the latest resolver, and the first ISP, to join Firefox’s TRR Program, joining Cloudflare and NextDNS. Mozilla began the rollout of encrypted DNS over HTTPS (DoH) by default for US-based Firefox users in February 2020, but began testing the protocol in 2018.
Adding ISPs in the TRR Program paves the way for providing customers with the security of trusted DNS resolution, while also offering the benefits of a resolver provided by their ISP such as parental control services and better optimized, localized results. Mozilla and Comcast will be jointly running tests to inform how Firefox can assign the best available TRR to each user.
The post Comcast’s Xfinity Internet Service Joins Firefox’s Trusted Recursive Resolver Program appeared first on The Mozilla Blog.
|
|
The Mozilla Blog: Immigrants Remain Core to the U.S.’ Strength |
By its very design the internet has accelerated the sharing of ideas and information across borders, languages, cultures and time zones. Despite the awesome reach and power of what the web has enabled, there is still no substitute for the chemistry that happens when human beings of different backgrounds and experiences come together to live and work in the same community.
Immigration brings a wealth of diverse viewpoints, drives innovation and creative thinking, and is central to building the internet into a global public resource that is open and accessible to all.
This is why the current U.S. administration’s recent actions are so troubling. On June 22, 2020 President Donald Trump issued an Executive Order suspending entry of immigrants under the premise that they present a risk to the United States’ labor market recovery from the COVID-19 pandemic. This decision will likely have far-reaching and unintended consequences for industries like Mozilla’s and throughout the country.
Technology companies, including Mozilla, rely on brilliant minds from around the globe. This mix of people and ideas has generated significant technological advances that currently fuel our global economy and will undoubtedly be essential for future economic recovery and growth.
This is also why we’re eager to see lawmakers create a permanent solution for (DACA (Deferred Action for Childhood Arrivals). We hope that in light of the recent U.S. Supreme Court ruling, the White House does not continue to pursue plans to end the program that currently protects about 700,000 young immigrants known as Dreamers from deportation. These young people were brought to the U.S. as minors, and raised and educated here. We’ve made this point before, but it bears repeating: Breaking the promise made to these young people and preventing these future leaders from having a legal pathway to citizenship is short-sighted and morally wrong. We owe it to them and to the country to give them every opportunity to succeed here in the U.S.
Immigrants have been a core part of the United States’ strength since its inception. A global pandemic hasn’t changed that. At a time when the United States is grappling with how to make right so many of the wrongs of its past, the country can’t afford to double down on policies that shut out diverse voices and contributions of people from around the world. As they have throughout the country’s history, our immigrant family members, friends, neighbors and colleagues must be allowed to continue playing a vital role in moving the U.S. forward.
The post Immigrants Remain Core to the U.S.’ Strength appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2020/06/24/immigrants-remain-core-to-the-u-s-strength/
|
|
The Firefox Frontier: Celebrate Pride with these colorful browser themes for Firefox |
As June comes to a close, we wanted to share some of our favorite LGBTQ browser themes, so you can celebrate Pride well into the summer and beyond. Gay Pride … Read more
The post Celebrate Pride with these colorful browser themes for Firefox appeared first on The Firefox Frontier.
https://blog.mozilla.org/firefox/pride-browser-themes-for-firefox/
|
|
The Mozilla Blog: We’re proud to join #StopHateForProfit |
Mozilla stands with the family of companies and civil society groups calling on Facebook to take strong action to limit hateful and divisive content on their platforms. Mozilla and Firefox have not advertised on Facebook and Instagram since March of 2018, when it became clear the company wasn’t acting to improve the lack of user privacy that emerged in the Cambridge Analytica scandal.
This is a crucial time for democracy, and internet platforms must play a constructive role. That means protecting people’s privacy and not becoming a willing vehicle for misinformation, hate, and lies. Now is the time for action, and we call upon Facebook to be on the right side of history.
The post We’re proud to join #StopHateForProfit appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2020/06/24/were-proud-to-join-stophateforprofit/
|
|
Cameron Kaiser: The Super Duper Universal Binary |
But it's actually more amazing than that because you can have multiple subtypes. Besides generic PPC or PPC64, you can have binaries that run specifically on the G3 (ppc750), G4 (ppc7400 or ppc7450) or G5 (ppc970). The G5 subtype in particular can be 32-bit or 64-bit. I know this is possible because LAMEVMX is already a three-headed binary that selects the non-SIMD G3, AltiVec G4 or special superduper AltiVec G5 version at runtime from a single file. The main reason I don't do this in TenFourFox is that the resulting executable would be ginormous (as in over 500MB in size).
But ARM has an even more dizzying array of subtypes, at least nine, and the Apple ARM in the new AARM Macs will probably be a special subtype of its own. This means that theoretically a Super Duper Universal Binary ("SDUB") could have all of the following:
http://tenfourfox.blogspot.com/2020/06/the-super-duper-universal-binary.html
|
|
Firefox UX: Designing for voice |
In the future people will use their voice to access the internet as often as they use a screen. We’re already in the early stages of this trend: As of 2016 Google reported 20% of searches on mobile devices used voice, last year smart speakers sales topped 146 million units — a 70% jump from 2018, and I’m willing to bet your mom or dad have adopted voice to make a phone call or dictate a text message.
I’ve been exploring voice interactions as the design lead for Mozilla’s Emerging Technologies team for the past two years. In that time we’ve developed Pocket Listen (a Text-to-Speech platform, capable of converting any published web article into audio) and Firefox Voice (an experiment accessing the internet with voice in the browser). This blog post is an introduction to designing for voice, based on the lessons our team learned researching and developing these projects. Luckily, if you’re a designer transitioning to working with voice, and you already have a solid design process in place, you’ll find many of your skills transfer seamlessly. But, some things are very different, so let’s dive in.
As with any design it’s best to ground the work in the value it can bring people.
The accessibility benefits to a person with a physical impairment should be clear, but voice has the opportunity to aid an even larger population. Small screens are hard to read with aging eyes, typing on a virtual keyboard can be difficult, and understanding complex technology is always a challenge. Voice is emerging as a tool to overcome these limitations, turning cumbersome tasks into simple verbal interactions.
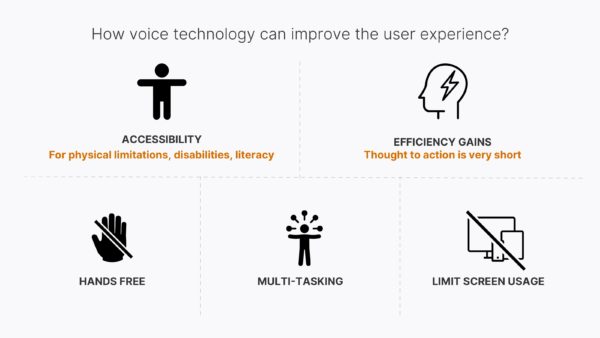
As designers, we’re often tasked with creating efficient and effortless interactions. Watch someone play music on a smart speaker and you’ll see how quickly thought turns to action when friction is removed. They don’t have to find and unlock their phone, launch an app, scroll through a list of songs and tap. Requesting a song happens in an instant with voice. A quote from one of our survey respondents summed it up perfectly:
“Being able to talk without thinking. It’s essentially effortless information ingestion.“
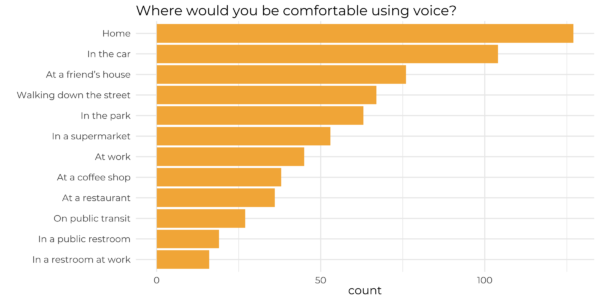
Talking out loud to a device isn’t always appropriate or socially acceptable. We see this over and over again in research and real world usage. People are generally uncomfortable talking to devices in public. The more private, the better.
Hands-free and multi-tasking also drive voice usage — cooking, washing the dishes, or driving in a car. These situations present opportunities to use voice because our hands or eyes are otherwise occupied.
But, voice isn’t just used for giving commands. Text-to-Speech can generate content from anything written, including articles. It’s a technology we successfully used to build and deploy Pocket Listen, which allows you to listen to articles you’d saved for later.
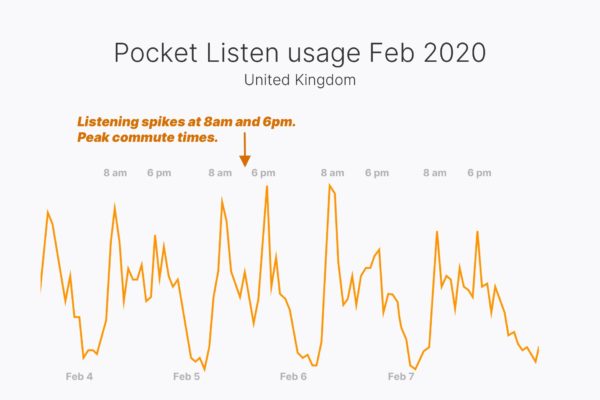
In the graph above you’ll see that people primarily use Pocket Listen while commuting. By creating a new format to deliver the content, we’ve expanded when and where the product provides value.
Now that you know ‘why’ and ‘when’ voice is valuable, let’s talk about what makes it hard. These are the pitfalls to watch for when building a voice product.

Voice is still a new technology, and, as such, it can feel open ended. There’s a wide variety of uses and devices it works well with. It can be incorporated using input (Speech-to-Text) or output (Text-to-Speech), with a screen or without a screen. You may be designing with a “Voice first mindset” as Amazon recommends for the Echo Show, or the entire experience might unfold while the phone is buried in someone’s pocket.
In many ways, this kind of divergence is familiar if you’ve worked with mobile apps or responsive design. Personally, the biggest adjustment for me has been the infinite nature of voice. The limited real estate of a screen imposes constraints on the number and types of interactions available. With voice, there’s often no interface to guide an action and it’s more personal than a screen, so request and utterance vary greatly by personality and culture.
In a voice user interface, a person can ask anything and they can ask it a hundred different ways. A list is a great example: on a screen it’s easy to display a handful of options. In a voice interface, listing more than two options quickly breaks down. The user can’t remember the first choice or the exact phrasing they should say if they want to make a selection.
Which brings us to discovery — often cited as the biggest challenge facing voice designers and developers. It’s difficult for a user to know what features are available, what can they say, how do they have to say it? It becomes essential to teach a systems capabilities but difficult in practice. Even when you teach a few key phrases early in the experience, human recall of proper voice commands and syntax is limited. People rarely remember more than a few phrases.
It’s still early days for voice interactions and while the challenges are real, so are the opportunities. Voice brings the potential to deliver valuable new experiences that improve our connections to each other and the vast knowledge available on the internet. These are just a few examples of what I look forward to seeing more of:
“I like that my voice is the interface. When the assistant works well, it lets me do what I wanted to do quickly, without unlocking my phone, opening an app / going on my computer, loading a site, etc.“
As you can see, we’re at the beginning of an exciting journey into voice. Hopefully this intro has motivated you to dig deeper and ask how voice can play a role in one of your projects. If you want to explore more, have questions or just want to chat feel free to get in touch.
|
|
Hacks.Mozilla.Org: Mozilla WebThings Gateway Kit by OKdo |
We’re excited about this week’s news from OKdo, highlighting a new kit built around Mozilla’s WebThings Gateway. OKdo is a UK-based global technology company focused on IoT offerings for hobbyists, educators, and entrepreneurs. Their idea is to make it easy to get a private and secure “web of things” environment up and running in either home or classroom. OKdo chose to build this kit around the Mozilla WebThings Gateway, and we’ve been delighted to work with them on it.
The WebThings Gateway is an open source software distribution focused on privacy, security, and interoperability. It provides a web-based user interface to monitor and control smart home devices, along with a rules engine to automate them. In addition, a data logging subsystem monitors device changes over time. Thanks to extensive contributions from our open source community, you’ll find an add-on system to extend the gateway with support for a wide range of existing smart home products.
With the WebThings Gateway, users always have complete control. You can directly monitor and control your home and devices over the web. In fact, you’ll never have to share data with a cloud service or vendor. This diagram of our architecture shows how it works:

The Mozilla WebThings Gateway Kit, available now from OKdo, includes:

You can find out more about the OKdo kit and how to purchase it for either home or classroom from their website.
To learn more about WebThings, visit Mozilla’s IoT website or join in the discussion on Discourse. WebThings is completely open source. All of our code is freely available on GitHub. We would love to have you join the community by filing issues, fixing bugs, implementing new features, or adding support for new devices. Also, you can help spread the word about WebThings by giving talks at conferences or local maker groups.
The post Mozilla WebThings Gateway Kit by OKdo appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2020/06/mozilla-webthings-gateway-kit-by-okdo/
|
|
Daniel Stenberg: curl 7.71.0 – blobs and retries |
Welcome to the “prose version” of the curl 7.71.0 change log. There’s just been eight short weeks since I last blogged abut a curl release but here we are again and there’s quite a lot to say about this new one.
the 192nd release
4 changes
56 days (total: 8,132)
136 bug fixes (total: 6,209)
244 commits (total: 25,911)
0 new public libcurl function (total: 82)
7 new curl_easy_setopt() option (total: 277)
1 new curl command line option (total: 232)
59 contributors, 33 new (total: 2,202)
33 authors, 17 new (total: 803)
2 security fixes (total: 94)
1,100 USD paid in Bug Bounties
This is a nasty bug in user credential handling when doing authentication and HTTP redirects, which can lead to a part pf the password being prepended to the host name when doing name resolving, thus leaking it over the network and to the DNS server.
This bug was reported and we fixed it in public – and then someone else pointed out the security angle of it! Just shows my lack of imagination. As a result, even though this was a bug already reported – and fixed – and therefor technically not subject for a bug bounty, we decide to still reward the reporter, just maybe not with the full amount this would otherwise had received. We awarded the reporter 400 USD.
When curl -J is used it doesn’t work together with -i and there’s a check that prevents it from getting used. The check was flawed and could be circumvented, which the effect that a server that provides a file name in a Content-Disposition: header could overwrite a local file, since the check for an existing local file was done in the code for receiving a body – as -i wasn’t supposed to work… We awarded the reporter 700 USD.
We’re counting four “changes” this release.
CURLSSLOPT_NATIVE_CA – this is a new (experimental) flag that allows libcurl on Windows, built to use OpenSSL to use the Windows native CA store when verifying server certificates. See CURLOPT_SSL_OPTIONS. This option is marked experimental as we didn’t decide in time exactly how this new ability should relate to the existing CA store path options, so if you have opinions on this you know we’re interested!
CURLOPT-BLOBs – a new series of certificate related options have been added to libcurl. They all take blobs as arguments, which are basically just a memory area with a given size. These new options add the ability to provide certificates to libcurl entirely in memory without using files. See for example CURLOPT_SSLCERT_BLOB.
CURLOPT_PROXY_ISSUERCERT – turns out we were missing the proxy version of CURLOPT_ISSUERCERT so this completed the set. The proxy version is used for HTTPS-proxy connections.
--retry-all-errors is the new blunt tool of retries. It tells curl to retry the transfer for all and any error that might occur. For the cases where just --retry isn’t enough and you know it should work and retrying can get it through.
This is yet another release with over a hundred and thirty different bug-fixes. Of course all of them have their own little story to tell but I need to filter a bit to be able to do this blog post. Here are my collected favorites, in no particular order…
There are more changes coming and some PR are already pending waiting for the feature window to open. Next release is likely to become version 7.72.0 and have some new features. Stay tuned!
https://daniel.haxx.se/blog/2020/06/24/curl-7-71-0-blobs-and-retries/
|
|
The Firefox Frontier: Firefox Relay protects your email address from hackers and spammers |
Firefox Relay is a smart, easy solution that can preserve the privacy of your email address, much like a post office box for your physical address. When a form requires … Read more
The post Firefox Relay protects your email address from hackers and spammers appeared first on The Firefox Frontier.
|
|
About:Community: Firefox 78 new contributors |
With the release of Firefox 78, we are pleased to welcome the 34 developers who contributed their first code change to Firefox in this release, 28 of whom were brand new volunteers! Please join us in thanking each of these diligent and enthusiastic individuals, and take a look at their contributions:
https://blog.mozilla.org/community/2020/06/23/firefox-78-new-contributors/
|
|
Mozilla Future Releases Blog: Update on Firefox Support for macOS 10.9, 10.10 and 10.11 |
On June 30th, macOS 10.9, 10.10 and 10.11 users will automatically be moved to the Firefox Extended Support Release (ESR).
While Apple doesn’t have an official policy governing security updates for older macOS releases, their ongoing practice has been to support the most recent three releases (i.e. version N, N-1, and N-2). The last security update applicable to macOS 10.11 was made available nearly 2 years ago in July 2018 (https://support.apple.com/en-us/HT201222). Unsupported operating systems receive no security updates, have known exploits, and can be dangerous to use, which makes it difficult and less than optimal to maintain Firefox for those versions.
Users do not need to take additional action to receive those updates. On June 30th, these macOS users will automatically be moved to the ESR channel through application update.
In the meantime, we strongly encourage our users to upgrade to mac OS X 10.12 or higher to benefit from the security and privacy updates.
For more information please visit the Firefox support page.
The post Update on Firefox Support for macOS 10.9, 10.10 and 10.11 appeared first on Future Releases.
|
|
Hacks.Mozilla.Org: Welcoming Safari to the WebExtensions Community |
Browser extensions provide a convenient and powerful way for people to take control of how they experience the web. From blocking ads to organizing tabs, extensions let people solve everyday problems and add whimsy to their online lives.
At yesterday’s WWDC event, Apple announced that Safari is adopting a web-based API for browser extensions similar to Firefox’s WebExtensions API. Built using familiar web technologies such as JavaScript, HTML, and CSS, the API makes it easy for developers to write one code base that will work in Firefox, Chrome, Opera, and Edge with minimal browser-specific changes. We’re excited to see expanded support for this common set of browser extension APIs.
Interested in porting your browser extension to Safari? Visit MDN to see which APIs are currently supported. Developers can start testing the new API in Safari 14 using the seed build for macOS Big Sur. The API will be available in Safari 14 on macOS Mojave and macOS Catalina in the future.
Or, maybe you’re new to browser extension development. Check out our guides and tutorials to learn more about the WebExtensions API. Then, visit Firefox Extension Workshop to find information about development tools, security best practices, and tips for creating a great user experience. Be sure to take a look at our guide for how to build a cross-browser extension.
Ready to share your extension with the world (or even just a few friends!)? Our documentation will guide you through the process of making your extension available for Firefox users.
Happy developing!
The post Welcoming Safari to the WebExtensions Community appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2020/06/welcoming-safari-to-the-webextensions-community/
|
|
Daniel Stenberg: curl ootw: –connect-timeout |
--connect-timeout [seconds] was added in curl 7.7 and has no short option version. The number of seconds for this option can (since 7.32.0) be specified using decimals, like 2.345.
curl shipped with support for the -m option already from the start. That limits the total time a user allows the entire curl operation to spend.
However, if you’re about to do a large file transfer and you don’t know how fast the network will be so how do you know how long time to allow the operation to take? In a lot of of situations, you then end up basically adding a huge margin. Like:
This operation usually takes 10 minutes, but what if everything is super overloaded at the time, let’s allow it 120 minutes to complete.
Nothing really wrong with that, but sometimes you end up noticing that something in the network or the remote server just dropped the packets and the connection wouldn’t even complete the TCP handshake within the given time allowance.
If you want your shell script to loop and try again on errors, spending 120 minutes for every lap makes it a very slow operation. Maybe there’s a better way?
To help combat this problem, the --connect-timeout is a way to “stage” the timeout. This option sets the maximum time curl is allowed to spend on setting up the connection. That involves resolving the host name, connecting TCP and doing the TLS handshake. If curl hasn’t reached its “established connection” state before the connect timeout limit has been reached, the transfer will be aborted and an error is returned.
This way, you can for example allow the connect procedure to take no more than 21 seconds, but then allow the rest of the transfer to go on for a total of 120 minutes if the transfer just happens to be terribly slow.
Like this:
curl --connect-timeout 21 --max-time 7200 https://example.com
You can even set the connection timeout to be less than a second (with the exception of some special builds that aren’t very common) with the use of decimals.
Require the connection to be established within 650 milliseconds:
curl --connect-timeout 0.650 https://example.com
Just note that DNS, TCP and the local network conditions etc at the moment you run this command line may vary greatly, so maybe restricting the connection time a lot will have the effect that it sometimes aborts a connection a little too easily. Just beware.
If you prefer a way to detect and abort transfers that stall after a while (but maybe long before the maximum timeout is reached), you might want to look into using –limit-speed.
Also, if a connection goes down to zero bytes/second for a period of time, as in it doesn’t send any data at all, and you still want your connection and transfer to survive that, you might want to make sure that you have your –keepalive-time set correctly.
https://daniel.haxx.se/blog/2020/06/23/curl-ootw-connect-timeout/
|
|






