[Перевод] Конвейер обработки текста в Sphinx
|
|
Среда, 24 Декабря 2014 г. 13:25
+ в цитатник
Обработка текста в поисковом движке выглядит достаточно простой снаружи, однако на самом деле это сложный процесс. При индексации текст документов должен быть обработан стриппером HTML, токенайзером, фильтром стопслов, фильтром словоформ и морфологическим процессором. А ещё при этом нужно помнить про исключения (exceptions), слитные (blended) символы, N-граммы и границы предложений. При поиске всё становится ещё сложнее, поскольку помимо всего вышеупомянутого нужно вдобавок обрабатывать синтаксис запроса, который добавляет всевозможные спец. символы (операторы и маски). Сейчас мы расскажем, как всё это работает в Sphinx.
Картина в целом
Упрощённо конвейер обработки текста (в движке версий 2.х) выглядит примерно так:

Выглядит достаточно просто, однако дьявол кроется в деталях. Есть несколько очень разных фильтров (которые применяются в особом порядке); токенайзер занимается ещё чем-то помимо разбиения текста на слова; и наконец под «и т.д.» в блоке морфологии на самом деле находится ещё по меньшей мере три разных варианта.
Поэтому более точной будет следующая картина:
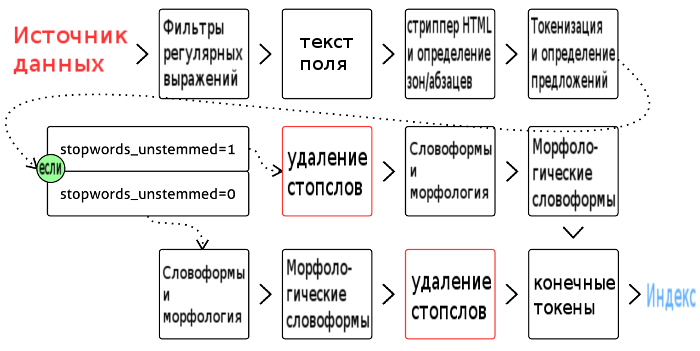 А теперь перейдём к деталям
А теперь перейдём к деталям http://habrahabr.ru/post/246679/
Метки:
Sphinx
*nix
Поисковые машины и технологии
сфинкс
морфология
лемматизация
обработка текста
индексация
-
Запись понравилась
-
0
Процитировали
-
0
Сохранили
-








